Usando un ejemplo de una descripción de la implementación del algoritmo de encriptación de acuerdo con GOST 28147–89 construido en la red Feistel, el artículo muestra las capacidades del procesador de doble núcleo BE-T1000 (también conocido como Baikal-T1) y realiza pruebas comparativas de la implementación del algoritmo usando cálculos vectoriales con y sin coprocesador SIMD. Aquí demostraremos el uso del bloque SIMD para la tarea de cifrado de acuerdo con GOST 28147-89, modo ECB.
Este artículo fue escrito el año pasado para la revista Electronic Components por Alexei Kolotnikov , un programador líder en Baikal Electronics. Y dado que no hay muchos lectores de esta revista, y el artículo es útil para aquellos que se dedican profesionalmente a la criptografía, yo, con el permiso del autor y sus pequeñas adiciones, lo publico aquí.
El procesador Baikal-T1 y el bloque SIMD dentro de él
El procesador Baikal-T1 incluye un sistema multiprocesador de doble núcleo de la familia MIPS32 P5600, así como un conjunto de interfaces de alta velocidad para intercambiar datos y de baja velocidad para controlar dispositivos periféricos. Aquí está el diagrama estructural de este procesador:
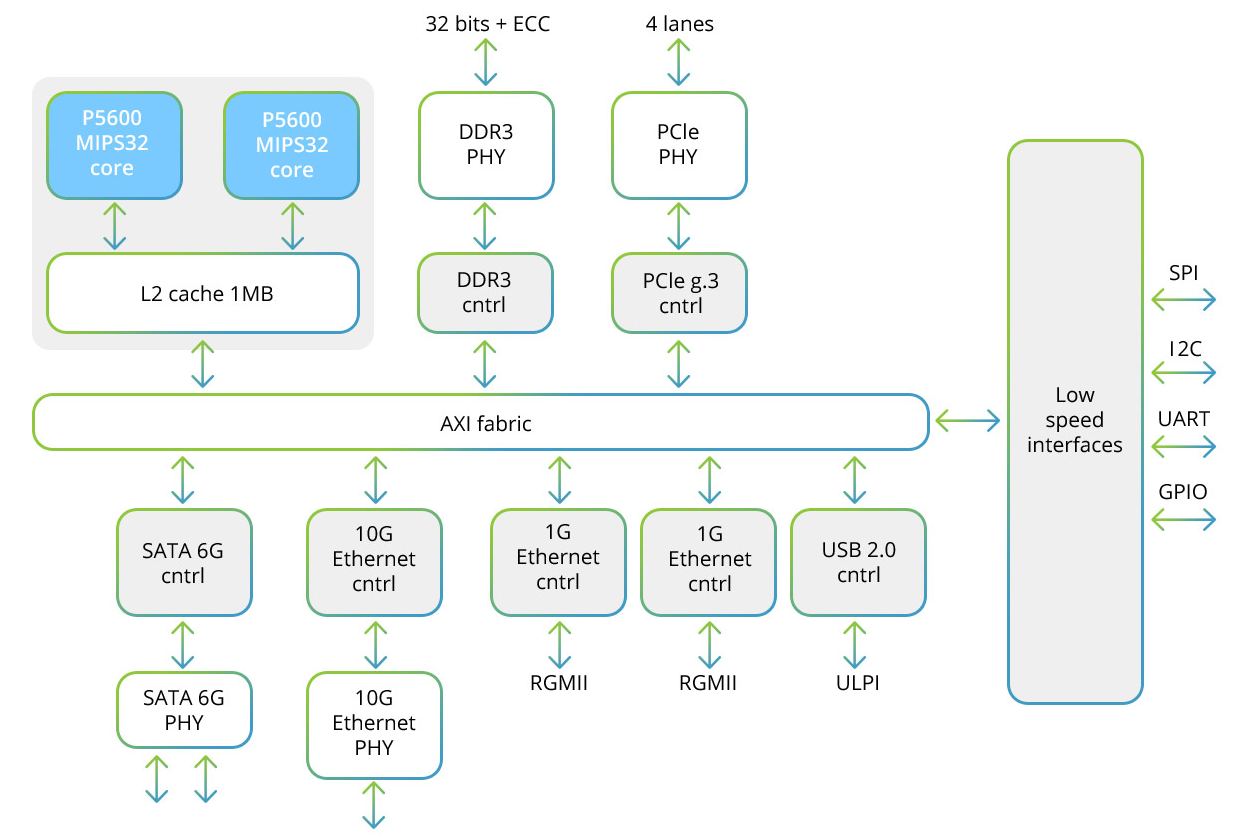
Cada uno de los dos núcleos incluye un bloque SIMD que le permite trabajar con vectores de 128 bits. Cuando se utiliza el método SIMD, se procesa más de una muestra,
y todo el vector, que puede contener varias muestras, es decir, un comando se aplica inmediatamente a todo el vector (matriz) de datos. Por lo tanto, en un ciclo de comando, se procesan varias muestras. El procesador utiliza el bloque SIMD MIPS32, que le permite trabajar con 32 piezas de registros de 128 bits.
Cada registro puede contener vectores de las siguientes dimensiones: 8 × 16; 16 × 8; 4 × 32 o
2 × 64 bits. Es posible utilizar más de 150 instrucciones para procesar datos: entero, punto flotante y punto fijo, incluidas operaciones bit a bit, operaciones de comparación y operaciones de conversión.
SparF describió una tecnología MIPS SIMD muy detallada en el artículo "Tecnología SIMPS MIPS y el procesador Baikal-T1" .
Evaluación de la efectividad de la computación vectorial.
El coprocesador aritmético del núcleo del procesador Baikal-T1 combina un procesador de punto flotante tradicional y un procesador SIMD paralelo, enfocado en el procesamiento eficiente de vectores y señales digitalizadas. SparF llevó a cabo una evaluación de rendimiento independiente del coprocesador de SIMD de vector en 2017 mientras escribía el artículo "Tecnología SIMPS de MIPS y el procesador Baikal-T1" . Si lo desea, dichas mediciones se pueden repetir, realizar de forma independiente conectándose a un soporte remoto con un procesador .
Luego, la tarea de prueba fue decodificar el video codificado usando las bibliotecas gratuitas x264 (clip de demostración H.264) y x265 (archivo de video HEVC), con capturas de pantalla tomadas a intervalos regulares. Como se esperaba, se observó un aumento notable en el rendimiento central del procesador en las tareas de FFmpeg con el uso de capacidades de hardware SIMD:

Breve descripción del algoritmo GOST 28147-89
Aquí solo observaremos las características principales para comprender el código y la optimización:
- El algoritmo está construido en la red Feistel.

- El algoritmo consta de 32 rondas.
- Una ronda consiste en mezclar una clave y reemplazar 8 partes de 4 bits en una tabla con un desplazamiento de 11 bits.
Una descripción detallada del algoritmo de conversión de información de acuerdo con GOST 28147-89 se proporciona en el Estándar del Estado de la URSS .
Implementación del algoritmo GOST 28147-89 sin usar un bloque SIMD
Para fines de comparación, los algoritmos se implementaron inicialmente utilizando comandos estándar "no vectorizados".
El código de ensamblador MIPS propuesto aquí le permite encriptar un bloque de 64 bits en 450 ns (o ~ 150 Mb / s) a una frecuencia de procesador nominal de 1200 MHz. Solo un núcleo está involucrado en los cálculos.
Preparar una tabla de reemplazo implica expandirla en una representación de 32 bits para acelerar el trabajo de la ronda: en lugar de reemplazar cuatro bits con enmascaramiento y cambio por adelantado
la mesa preparada reemplaza ocho bits cada uno.
uint8_t sbox_test[8][16] = { {0x9, 0x6, 0x3, 0x2, 0x8, 0xb, 0x1, 0x7, 0xa, 0x4, 0xe, 0xf, 0xc, 0x0, 0xd, 0x5}, {0x3, 0x7, 0xe, 0x9, 0x8, 0xa, 0xf, 0x0, 0x5, 0x2, 0x6, 0xc, 0xb, 0x4, 0xd, 0x1}, {0xe, 0x4, 0x6, 0x2, 0xb, 0x3, 0xd, 0x8, 0xc, 0xf, 0x5, 0xa, 0x0, 0x7, 0x1, 0x9}, {0xe, 0x7, 0xa, 0xc, 0xd, 0x1, 0x3, 0x9, 0x0, 0x2, 0xb, 0x4, 0xf, 0x8, 0x5, 0x6}, {0xb, 0x5, 0x1, 0x9, 0x8, 0xd, 0xf, 0x0, 0xe, 0x4, 0x2, 0x3, 0xc, 0x7, 0xa, 0x6}, {0x3, 0xa, 0xd, 0xc, 0x1, 0x2, 0x0, 0xb, 0x7, 0x5, 0x9, 0x4, 0x8, 0xf, 0xe, 0x6}, {0x1, 0xd, 0x2, 0x9, 0x7, 0xa, 0x6, 0x0, 0x8, 0xc, 0x4, 0x5, 0xf, 0x3, 0xb, 0xe}, {0xb, 0xa, 0xf, 0x5, 0x0, 0xc, 0xe, 0x8, 0x6, 0x2, 0x3, 0x9, 0x1, 0x7, 0xd, 0x4} }; uint32_t sbox_cvt[4*256]; for (i = 0; i < 256; ++i) { uint32_t p; p = sbox[7][i >> 4] << 4 | sbox[6][i & 15]; p = p << 24; p = p << 11 | p >> 21; sbox_cvt[i] = p; // S87 p = sbox[5][i >> 4] << 4 | sbox[4][i & 15]; p = p << 16; p = p << 11 | p >> 21; sbox_cvt[256 + i] = p; // S65 p = sbox[3][i >> 4] << 4 | sbox[2][i & 15]; p = p << 8; p = p << 11 | p >> 21; sbox_cvt[256 * 2 + i] = p; // S43 p = sbox[1][i >> 4] << 4 | sbox[0][i & 15]; p = p << 11 | p >> 21; sbox_cvt[256 * 3 + i] = p; // S21 }
El cifrado de bloque es 32 veces una repetición de la ronda usando la clave.
// input: a0 - &in, a1 - &out, a2 - &key, a3 - &sbox_cvt LEAF(gost_encrypt_block_asm) .set reorder lw n1, (a0) // n1, IN lw n2, 4(a0) // n2, IN + 4 lw t0, (a2) // key[0] -> t0 gostround n1, n2, 1 gostround n2, n1, 2 gostround n1, n2, 3 gostround n2, n1, 4 gostround n1, n2, 5 gostround n2, n1, 6 gostround n1, n2, 7 gostround n2, n1, 0 gostround n1, n2, 1 gostround n2, n1, 2 gostround n1, n2, 3 gostround n2, n1, 4 gostround n1, n2, 5 gostround n2, n1, 6 gostround n1, n2, 7 gostround n2, n1, 0 gostround n1, n2, 1 gostround n2, n1, 2 gostround n1, n2, 3 gostround n2, n1, 4 gostround n1, n2, 5 gostround n2, n1, 6 gostround n1, n2, 7 gostround n2, n1, 7 gostround n1, n2, 6 gostround n2, n1, 5 gostround n1, n2, 4 gostround n2, n1, 3 gostround n1, n2, 2 gostround n2, n1, 1 gostround n1, n2, 0 gostround n2, n1, 0 1: sw n2, (a1) sw n1, 4(a1) jr ra nop END(gost_encrypt_block_asm)
Una mesa redonda es solo un intercambio de mesa.
.macro gostround x_in, x_out, rkey addu t8, t0, \x_in /* key[0] + n1 = x */ lw t0, \rkey * 4 (a2) /* next key to t0 */ ext t2, t8, 24, 8 /* get bits [24,31] */ ext t3, t8, 16, 8 /* get bits [16,23] */ ext t4, t8, 8, 8 /* get bits [8,15] */ ext t5, t8, 0, 8 /* get bits [0, 7] */ sll t2, t2, 2 /* convert to dw offset */ sll t3, t3, 2 /* convert to dw offset */ sll t4, t4, 2 /* convert to dw offset */ sll t5, t5, 2 /* convert to dw offset */ addu t2, t2, a3 /* add sbox_cvt */ addu t3, t3, a3 /* add sbox_cvt */ addu t4, t4, a3 /* add sbox_cvt */ addu t5, t5, a3 /* add sbox_cvt */ lw t6, (t2) /* sbox[x[3]] -> t2 */ lw t7, 256*4(t3) /* sbox[256 + x[2]] -> t3 */ lw t9, 256*2*4(t4) /* sbox[256 *2 + x[1]] -> t4 */ lw t1, 256*3*4(t5) /* sbox[256 *3 + x[0]] -> t5 */ or t2, t7, t6 /* | */ or t3, t1, t9 /* | */ or t2, t2, t3 /* | */ xor \x_out, \x_out, t2 /* n2 ^= f(...) */ .endm
Implementación del algoritmo GOST 28147-89 utilizando un bloque SIMD
El código propuesto a continuación le permite cifrar simultáneamente cuatro bloques de 64 bits por 720 ns (o ~ 350 Mbit / s) en las mismas condiciones: frecuencia de procesador de 1200 MHz, un núcleo.
El reemplazo se realiza en dos cuádruples e inmediatamente en 4 bloques con la instrucción shuffle y el enmascaramiento posterior de las cuatro patas significativas.
Expandir una tabla de sustitución
for(i = 0; i < 16; ++i) { sbox_cvt_simd[i] = (sbox[7][i] << 4) | sbox[0][i]; // $w8 [7 0] sbox_cvt_simd[16 + i] = (sbox[1][i] << 4) | sbox[6][i]; // $w9 [6 1] sbox_cvt_simd[32 + i] = (sbox[5][i] << 4) | sbox[2][i]; // $w10[5 2] sbox_cvt_simd[48 + i] = (sbox[3][i] << 4) | sbox[4][i]; // $w11[3 4] }
Inicializando máscaras.
l0123: .int 0x0f0f0f0f .int 0xf000000f /* substitute from $w8 [7 0] mask in w12*/ .int 0x0f0000f0 /* substitute from $w9 [6 1] mask in w13*/ .int 0x00f00f00 /* substitute from $w10 [5 2] mask in w14*/ .int 0x000ff000 /* substitute from $w11 [4 3] mask in w15*/ .int 0x000f000f /* mask $w16 x N x N */ .int 0x0f000f00 /* mask $w17 N x N x */ LEAF(gost_prepare_asm) .set reorder .set msa la t1, l0123 /* masks */ lw t2, (t1) lw t3, 4(t1) lw t4, 8(t1) lw t5, 12(t1) lw t6, 16(t1) lw t7, 20(t1) lw t8, 24(t1) fill.w $w2, t2 /* 0f0f0f0f -> w2 */ fill.w $w12, t3 /* f000000f -> w12*/ fill.w $w13, t4 /* 0f0000f0 -> w13*/ fill.w $w14, t5 /* 00f00f00 -> w14*/ fill.w $w15, t6 /* 000ff000 -> w15*/ fill.w $w16, t7 /* 000f000f -> w16*/ fill.w $w17, t8 /* 0f000f00 -> w17*/ ld.b $w8, (a0) /* load sbox */ ld.b $w9, 16(a0) ld.b $w10, 32(a0) ld.b $w11, 48(a0) jr ra nop END(gost_prepare_asm)
Cifrado de 4 bloques
LEAF(gost_encrypt_4block_asm) .set reorder .set msa lw t1, (a0) // n1, IN lw t2, 4(a0) // n2, IN + 4 lw t3, 8(a0) // n1, IN + 8 lw t4, 12(a0) // n2, IN + 12 lw t5, 16(a0) // n1, IN + 16 lw t6, 20(a0) // n2, IN + 20 lw t7, 24(a0) // n1, IN + 24 lw t8, 28(a0) // n2, IN + 28 lw t0, (a2) // key[0] -> t0 insert.w ns1[0],t1 insert.w ns2[0],t2 insert.w ns1[1],t3 insert.w ns2[1],t4 insert.w ns1[2],t5 insert.w ns2[2],t6 insert.w ns1[3],t7 insert.w ns2[3],t8 gostround4 ns1, ns2, 1 gostround4 ns2, ns1, 2 gostround4 ns1, ns2, 3 gostround4 ns2, ns1, 4 gostround4 ns1, ns2, 5 gostround4 ns2, ns1, 6 gostround4 ns1, ns2, 7 gostround4 ns2, ns1, 0 gostround4 ns1, ns2, 1 gostround4 ns2, ns1, 2 gostround4 ns1, ns2, 3 gostround4 ns2, ns1, 4 gostround4 ns1, ns2, 5 gostround4 ns2, ns1, 6 gostround4 ns1, ns2, 7 gostround4 ns2, ns1, 0 gostround4 ns1, ns2, 1 gostround4 ns2, ns1, 2 gostround4 ns1, ns2, 3 gostround4 ns2, ns1, 4 gostround4 ns1, ns2, 5 gostround4 ns2, ns1, 6 gostround4 ns1, ns2, 7 gostround4 ns2, ns1, 7 gostround4 ns1, ns2, 6 gostround4 ns2, ns1, 5 gostround4 ns1, ns2, 4 gostround4 ns2, ns1, 3 gostround4 ns1, ns2, 2 gostround4 ns2, ns1, 1 gostround4 ns1, ns2, 0 gostround4 ns2, ns1, 0 1: copy_s.w t1,ns2[0] copy_s.w t2,ns1[0] copy_s.w t3,ns2[1] copy_s.w t4,ns1[1] copy_s.w t5,ns2[2] copy_s.w t6,ns1[2] copy_s.w t7,ns2[3] copy_s.w t8,ns1[3] sw t1, (a1) // n2, OUT sw t2, 4(a1) // n1, OUT + 4 sw t3, 8(a1) // n2, OUT + 8 sw t4, 12(a1) // n1, OUT + 12 sw t5, 16(a1) // n2, OUT + 16 sw t6, 20(a1) // n1, OUT + 20 sw t7, 24(a1) // n2, OUT + 24 sw t8, 28(a1) // n1, OUT + 28 jr ra nop END(gost_encrypt_4block_asm)
Redondear usando comandos de bloque SIMD con cálculo de 4 bloques simultáneamente
.macro gostround4 x_in, x_out, rkey fill.w $w0, t0 /* key -> Vi */ addv.w $w1, $w0, \x_in /* key[0] + n1 = x */ srli.b $w3, $w1, 4 /* $w1 >> 4 */ and.v $w4, $w1, $w16 /* x 4 x 0*/ and.v $w5, $w1, $w17 /* 6 x 2 x*/ and.v $w6, $w3, $w17 /* 7 x 3 x */ and.v $w7, $w3, $w16 /* x 5 x 1 */ lw t0, \rkey * 4(a2) /* next key -> t0 */ or.v $w4, $w6, $w4 /* 7 4 3 0 */ or.v $w5, $w5, $w7 /* 6 5 2 1 */ move.v $w6, $w5 /* 6 5 2 1 */ move.v $w7, $w4 /* 7 4 3 0 */ /* 7 xx 0 */ /* 6 xx 1 */ /* x 5 2 x */ /* x 4 3 x */ vshf.b $w4, $w8, $w8 /* substitute $w8 [7 0] */ and.v $w4, $w4, $w12 vshf.b $w5, $w9, $w9 /* substitute $w9 [6 1] */ and.v $w5, $w5, $w13 vshf.b $w6, $w10, $w10 /* substitute $w10 [5 2] */ and.v $w6, $w6, $w14 vshf.b $w7, $w11, $w11 /* substitute $w11 [4 3] */ and.v $w7, $w7, $w15 or.v $w4, $w4, $w5 or.v $w6, $w6, $w7 or.v $w4, $w4, $w6 srli.w $w1, $w4, 21 /* $w4 >> 21 */ slli.w $w3, $w4, 11 /* $w4 << 11 */ or.v $w1, $w1, $w3 xor.v \x_out, \x_out, $w1 .endm
Breves conclusiones
El uso del bloque SIMD del procesador Baikal-T1 permite alcanzar una tasa de conversión de datos de aproximadamente 350 Mbit / s de acuerdo con los algoritmos GOST 28147-89, que es dos veces y media (!) Veces mayor que la implementación en los comandos estándar. Dado que este procesador tiene dos núcleos, es teóricamente posible encriptar un flujo a una velocidad de ~ 700 Mbps. Al menos la implementación de prueba de IPsec, con cifrado según GOST 28147-89, mostró el rendimiento del canal de ~ 400 Mbps en un dúplex.