Hola Habr!
Trabajo para una empresa de juegos que desarrolla juegos en línea. Actualmente, todos nuestros juegos están divididos en muchos "mercados" (un "mercado" por país) y en cada "mercado" hay una docena de mundos entre los cuales los jugadores se distribuyen durante el registro (bueno, o a veces pueden elegirlo ellos mismos). Cada mundo tiene una base de datos y uno o más servidores web / de aplicaciones. Por lo tanto, la carga se divide y distribuye en todos los mundos / servidores de manera casi uniforme y, como resultado, obtenemos el máximo en línea de 6K-8K jugadores (este es el máximo, en su mayoría varias veces menos) y 200-300 solicitudes por tiempo "prime" para un mundo.
Tal estructura con la división de jugadores en mercados y mundos se está volviendo obsoleta; los jugadores quieren algo global. En los últimos juegos, dejamos de dividir a las personas por país y dejamos solo uno o dos mercados (América y Europa), pero aún con muchos mundos en cada uno. El siguiente paso será el desarrollo de juegos con una nueva arquitectura y la unificación de todos los jugadores en un solo mundo con
una sola base de datos .
Hoy quería hablar un poco sobre cómo se me asignó la tarea de verificar qué pasa si todo el en línea (y son 50-200 mil usuarios a la vez) de uno de nuestros juegos populares "envía" para jugar el próximo juego basado en la nueva arquitectura y si todo el sistema, especialmente la base de datos (
PostgreSQL 11 ) prácticamente puede soportar tal carga y, si no puede, averiguar dónde está nuestro máximo. Te contaré un poco sobre los problemas que han surgido y las decisiones de preparación para probar a tantos usuarios, el proceso en sí y un poco sobre los resultados.
Introducción
En el pasado, en
InnoGames GmbH, cada equipo de juego creaba un proyecto de juego a su gusto y color, a menudo utilizando diferentes tecnologías, lenguajes de programación y bases de datos. Además, tenemos muchos sistemas externos responsables de pagos, envío de notificaciones push, marketing y más. Para trabajar con estos sistemas, los desarrolladores también crearon sus interfaces únicas lo mejor que pudieron.
Actualmente en el negocio de los juegos móviles hay mucho
dinero y, en consecuencia, mucha competencia. Aquí es muy importante recuperarlo de cada dólar gastado en marketing y un poco más de lo anterior, por lo tanto, todas las compañías de juegos a menudo “cierran” juegos incluso en la etapa de pruebas cerradas, si no cumplen con las expectativas analíticas. En consecuencia, perder tiempo en la invención de la próxima rueda no es rentable, por lo que se decidió crear una plataforma unificada que proporcionará a los desarrolladores una solución preparada para la integración con todos los sistemas externos, una base de datos con replicación y todas las mejores prácticas. Todo lo que los desarrolladores necesitan es desarrollar y "poner" un buen juego además de esto y no perder el tiempo en el desarrollo no relacionado con el juego en sí.
Esta plataforma se llama
GameStarter :

Entonces, al punto. Todos los futuros juegos de InnoGames se construirán en esta plataforma, que tiene dos bases de datos: master y game (PostgreSQL 11). Master almacena información básica sobre los jugadores (inicio de sesión, contraseña, etc.) y participa, principalmente, solo en el proceso de inicio de sesión / registro en el juego mismo. Juego: la base de datos del juego en sí, donde, en consecuencia, se almacenan todos los datos y entidades del juego, que es el núcleo del juego, donde irá toda la carga.
Por lo tanto, surgió la pregunta de si toda esta estructura podría soportar un número tan potencial de usuarios igual al máximo en línea de uno de nuestros juegos más populares.
Desafío
La tarea en sí misma era esta: verificar si la base de datos (PostgreSQL 11), con la replicación habilitada, puede soportar toda la carga que tenemos actualmente en el juego más cargado, teniendo a su disposición todo el hipervisor PowerEdge M630 (HV).
Aclararé que la tarea en este momento era
solo verificar , utilizando las configuraciones de bases de datos existentes, que formamos teniendo en cuenta las mejores prácticas y nuestra propia experiencia.
Diré de inmediato la base de datos, y todo el sistema se mostró bien, con la excepción de un par de puntos. Pero este proyecto de juego en particular estaba en la etapa de prototipo y en el futuro, con la complicación de la mecánica del juego, las solicitudes a la base de datos se volverán más complicadas y la carga en sí misma puede aumentar significativamente y su naturaleza puede cambiar. Para evitar esto, es necesario probar iterativamente el proyecto con cada hito más o menos significativo. La automatización de la capacidad de ejecutar este tipo de pruebas con un par de cientos de miles de usuarios se ha convertido en la tarea principal en esta etapa.
Perfil
Como cualquier prueba de carga, todo comienza con un perfil de carga.
Nuestro valor potencial CCU60 (CCU es el número máximo de usuarios durante un cierto período de tiempo, en este caso 60 minutos) se considera
250,000 usuarios. El número de usuarios virtuales competitivos (VU) es menor que el CCU60 y los analistas han sugerido que se puede dividir de forma segura en dos. Redondee y acepte
150,000 VU competitivos.
El número total de solicitudes por segundo se tomó de un juego bastante cargado:
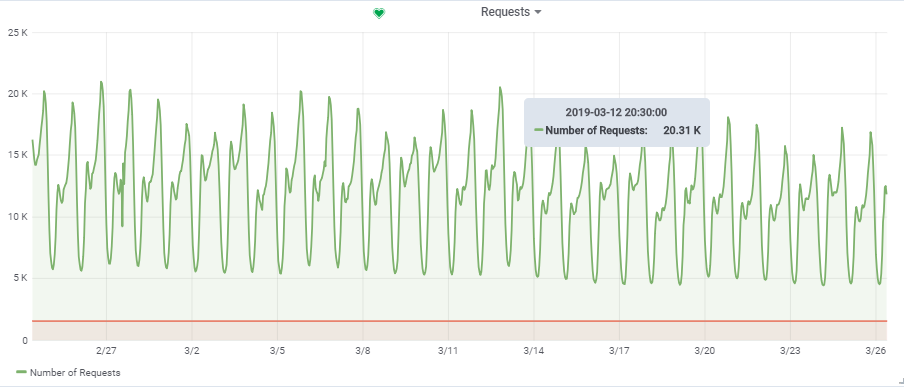
Por lo tanto, nuestra carga objetivo es de ~
20,000 solicitudes / s a
150,000 VU.
Estructura
Características del "stand"
En un
artículo anterior
, ya hablé sobre la automatización de todo el proceso de prueba de carga. Además, puedo repetirme un poco, pero te contaré algunos puntos con más detalle.

En el diagrama, los cuadrados azules son nuestros hipervisores (HV), una nube que consta de muchos servidores (Dell M620 - M640). En cada HV, se lanzan una docena de máquinas virtuales (VM) a través de KVM (web / app y db en la mezcla). Cuando se crea una nueva VM, se produce el equilibrio y la búsqueda a través del conjunto de parámetros de un HV adecuado y no se sabe inicialmente en qué servidor estará.
Base de datos (Game DB):
Pero para nuestro propósito db1, reservamos un HV
targer_hypervisor separado basado en el M630.
Breves características de targer_hypervisor:
Dell M_630
Nombre del modelo: CPU Intel® Xeon® E5-2680 v3 @ 2.50GHz
CPU (s): 48
Hilo (s) por núcleo: 2
Núcleo (s) por zócalo: 12
Zócalo (s): 2
RAM: 128 GB
Debian GNU / Linux 9 (estiramiento)
4.9.0-8-amd64 # 1 SMP Debian 4.9.130-2 (2018-10-27)
Especificaciones detalladasDebian GNU / Linux 9 (estiramiento)
4.9.0-8-amd64 # 1 SMP Debian 4.9.130-2 (2018-10-27)
lscpu
Arquitectura: x86_64
Modo (s) de CPU: 32 bits, 64 bits
Orden de bytes: Little Endian
CPU (s): 48
Lista de CPU (s) en línea: 0-47
Hilo (s) por núcleo: 2
Núcleo (s) por zócalo: 12
Zócalo (s): 2
NUMA nodo (s): 2
ID del vendedor: GenuineIntel
Familia de CPU: 6
Modelo: 63
Nombre del modelo: CPU Intel® Xeon® E5-2680 v3 @ 2.50GHz
Paso a paso: 2
CPU MHz: 1309.356
CPU máx. MHz: 3300.0000
CPU min MHz: 1200.0000
BogoMIPS: 4988.42
Virtualización: VT-x
Caché L1d: 32K
Caché L1i: 32K
Caché L2: 256K
Caché L3: 30720K
NUMA nodo0 CPU (s): 0,2,4,6,8,10,12,14,16,18,20,22,24,26,28,30,32,34,36,38,40,42 44,46
NUMA nodo1 CPU (s): 1,3,5,7,9,11,13,15,17,19,21,23,25,27,29,31,33,35,37,39,41,43 45,47
Banderas: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constante qtsopmopcoptsoptsoptsoptsoptsoptsoptsoptsoptsoptsoptsoptsoptsoptsopt SMX est TM2 SSSE3 sdbg FMA CX16 XTPR PDCM PCID DCA sse4_1 sse4_2 x2apic movbe POPCNT tsc_deadline_timer aes xSave AVX F16C rdrand lahf_lm ABM EPB invpcid_single ssbd CCRI ibpb stibp Kaiser tpr_shadow vnmi FlexPriority EPT VPID fsgsbase tsc_adjust IMC1 AVX2 SMEP bmi2 erms invpcid cqm xsaveopt cqm_llc cqm_occup_llc dtherm ida arat pln pts flush_l1d
/ usr / bin / qemu-system-x86_64 --version
Emulador QEMU versión 2.8.1 (Debian 1: 2.8 + dfsg-6 + deb9u5)
Copyright © 2003-2016 Fabrice Bellard y los desarrolladores del Proyecto QEMU
Breves características de db1:
Arquitectura: x86_64
CPU (s): 48
RAM: 64 GB
4.9.0-8-amd64 # 1 SMP Debian 4.9.144-3.1 (2019-02-19) x86_64 GNU / Linux
Debian GNU / Linux 9 (estiramiento)
psql (PostgreSQL) 11.2 (Debian 11.2-1.pgdg90 + 1)
Configuración de PostgreSQL con algunas explicacionesseq_page_cost = 1.0
random_page_cost = 1.1 # Tenemos SSD
incluye '/etc/postgresql/11/main/extension.conf'
log_line_prefix = '% t [% p-% l]% q% u @% h'
log_checkpoints = on
log_lock_waits = on
log_statement = ddl
log_min_duration_statement = 100
log_temp_files = 0
autovacuum_max_workers = 5
autovacuum_naptime = 10s
autovacuum_vacuum_cost_delay = 20ms
vacuum_cost_limit = 2000
maintenance_work_mem = 128MB
synous_commit = off
checkpoint_timeout = 30min
listen_addresses = '*'
work_mem = 32MB
efectividad_caché_tamaño = 26214MB # 50% de memoria disponible
shared_buffers = 16384MB # 25% de memoria disponible
max_wal_size = 15GB
min_wal_size = 80MB
wal_level = hot_standby
max_wal_senders = 10
wal_compression = on
archive_mode = on
archive_command = '/ bin / true'
archive_timeout = 1800
hot_standby = on
wal_log_hints = on
hot_standby_feedback = on
El valor predeterminado de
hot_standby_feedback es apagado, lo encendimos, pero más tarde tuvo que apagarse para realizar una prueba exitosa. Más adelante explicaré por qué.
Las principales tablas activas en la base de datos (construcción, producción, game_entity, building, core_inventory_player_resource, survivor) se rellenan previamente con datos (aproximadamente 80 GB) utilizando un script bash.
Replicación:
SELECT * FROM pg_stat_replication; pid | usesysid | usename | application_name | client_addr | client_hostname | client_port | backend_start | backend_xmin | state | sent_lsn | write_lsn | flush_lsn | replay_lsn | write_lag | flush_lag | replay_lag | sync_priority | sync_state -----+----------+---------+---------------------+--------------+---------------------+-------------+-------------------------------+--------------+-----------+------------+------------+------------+------------+-----------------+-----------------+-----------------+---------------+------------ 759 | 17035 | repmgr | xl1db2 | xxxx | xl1db2 | 51142 | 2019-01-27 08:56:44.581758+00 | | streaming | 18/424A9F0 | 18/424A9F0 | 18/424A9F0 | 18/424A9F0 | 00:00:00.000393 | 00:00:00.001159 | 00:00:00.001313 | 0 | async 977 | 17035 | repmgr | xl1db3 |xxxxx | xl1db3 | 42888 | 2019-01-27 08:57:03.232969+00 | | streaming | 18/424A9F0 | 18/424A9F0 | 18/424A9F0 | 18/424A9F0 | 00:00:00.000373 | 00:00:00.000798 | 00:00:00.000919 | 0 | async
Servidor de aplicaciones
Luego, en HV productivo (prod_hypervisors) de varias configuraciones y capacidades, se lanzaron 15 servidores de aplicaciones: 8 núcleos, 4 GB. Lo principal que se puede decir: openjdk 11.0.1 2018-10-16, primavera, interacción con la base de datos a través de
hikari (hikari.maximum-pool-size: 50)
Entorno de prueba de esfuerzo
Todo el entorno de prueba de carga consta de un servidor principal
admin.loadtest y varios servidores de
generadorN.loadtest (en este caso había 14).
generatorN.loadtest - VM "desnuda" Debian Linux 9, con Java 8. 32 núcleos / 32 gigabytes instalados. Están ubicados en el HV "no productivo", para no matar accidentalmente el rendimiento de máquinas virtuales importantes.
admin.loadtest :
máquina virtual Debian Linux 9, 16 núcleos / 16 gigas, ejecuta Jenkins, JLTC y otro software adicional sin importancia.
JLTC -
centro de prueba de carga jmeter . Un sistema en Py / Django que controla y automatiza el lanzamiento de pruebas, así como el análisis de resultados.
Esquema de lanzamiento de prueba

El proceso de ejecutar la prueba se ve así:
- La prueba se inicia desde Jenkins . Seleccione el trabajo requerido, luego debe ingresar los parámetros de prueba deseados:
- DURACIÓN - duración de la prueba
- RAMPUP - tiempo de "calentamiento"
- THREAD_COUNT_TOTAL : el número deseado de usuarios virtuales (VU) o subprocesos
- TARGET_RESPONSE_TIME es un parámetro importante, para no sobrecargar todo el sistema con la ayuda de él, establecemos el tiempo de respuesta deseado, en consecuencia, la prueba mantendrá la carga en un nivel en el que el tiempo de respuesta de todo el sistema no sea mayor que el especificado.
- Lanzamiento
- Jenkins clona el plan de prueba de Gitlab y lo envía a JLTC.
- JLTC funciona un poco con un plan de prueba (por ejemplo, inserta un escritor simple CSV).
- JLTC calcula la cantidad requerida de servidores Jmeter para ejecutar la cantidad deseada de VU (THREAD_COUNT_TOTAL).
- JLTC se conecta a cada generador loadgeneratorN e inicia el servidor jmeter.
Durante la prueba, el
cliente JMeter genera un archivo CSV con los resultados. Entonces, durante la prueba, la cantidad de datos y el tamaño de este archivo crece a un ritmo
loco , y no se puede usar para el análisis después de la prueba:
se inventó
Daemon (como un experimento), que lo analiza
"sobre la marcha" .
Plan de prueba
Puede descargar el plan de prueba
aquí .
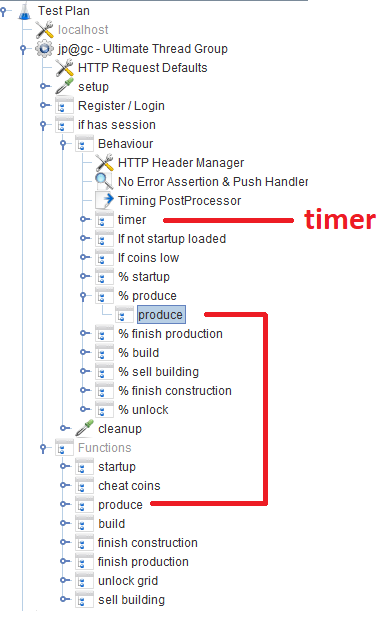
Después del registro / inicio de sesión, los usuarios trabajan en el módulo
Comportamiento , que consta de varios
controladores de rendimiento que especifican la probabilidad de una función de juego en particular. En cada controlador de rendimiento, hay un
controlador de módulo , que se refiere al módulo correspondiente que implementa la función.
Fuera de tema
Durante el desarrollo del script, intentamos usar Groovy al máximo, y gracias a nuestro programador Java, descubrí un par de trucos para mí (tal vez sea útil para alguien):
VU / Subprocesos
Cuando un usuario ingresa el número deseado de VU utilizando el parámetro THREAD_COUNT_TOTAL al configurar el trabajo en Jenkins, es necesario iniciar de alguna manera el número requerido de servidores Jmeter y distribuir el número final de VU entre ellos. Esta parte se encuentra con el JLTC en la parte llamada
controlador / provisión .
En esencia, el algoritmo es el siguiente:
- Dividimos el número deseado de VU threads_num en 200-300 subprocesos y, en función del tamaño más o menos adecuado -Xmsm -Xmxm, determinamos el valor de memoria requerido para un jmeter-server required_memory_for_jri (JRI - Llamo a la instancia remota de Jmeter, en lugar de Jmeter-server).
- De threads_num y required_memory_for_jri encontramos el número total de jmeter-server: target_amount_jri y el valor total de la memoria requerida : required_memory_total .
- Seleccionamos todos los generadores loadgeneratorN uno por uno y comenzamos el número máximo de servidores jmeter en función de la memoria disponible en él. Siempre que el número de instancias de current_amount_jri en ejecución no sea igual a target_amount_jri.
- (Si el número de generadores y la memoria total no es suficiente, agregue uno nuevo al grupo)
- Nos conectamos a cada generador, usamos netstat para recordar todos los puertos ocupados y ejecutamos en puertos aleatorios (que están desocupados) la cantidad requerida de servidores jmeter:
netstat_cmd= 'netstat -tulpn | grep LISTEN' stdin, stdout, stderr = ssh.exec_command(cmd1) used_ports = [] netstat_output = str(stdout.readlines()) ports = re.findall('\d+\.\d+\.\d+\.\d+\:(\d+)', netstat_output) ports_ipv6 = re.findall('\:\:\:(\d+)', netstat_output) p.wait() for port in ports: used_ports.append(int(port)) for port in ports_ipv6: used_ports.append(int(port)) ssh.close() for i in range(1, possible_jris_on_host + 1): port = int(random.randint(10000, 20000)) while port in used_ports: port = int(random.randint(10000, 20000))
- Recopilamos todos los servidores jmeter en ejecución de una vez en el formato de dirección: puerto, por ejemplo, generador13: 15576, generador9: 14015, generador11: 19152, generador14: 12125, generador2: 17602
- La lista resultante y threads_per_host se envían al cliente JMeter cuando comienza la prueba:
REMOTE_TESTING_FLAG=" -R $REMOTE_HOSTS_STRING" java -jar -Xms7g -Xmx7g -Xss228k $JMETER_DIR/bin/ApacheJMeter.jar -Jserver.rmi.ssl.disable=true -n -t $TEST_PLAN -j $WORKSPACE/loadtest.log -GTHREAD_COUNT=$THREADS_PER_HOST $OTHER_VARS $REMOTE_TESTING_FLAG -Jjmeter.save.saveservice.default_delimiter=,
En nuestro caso, la prueba se realizó simultáneamente desde 300 servidores Jmeter, 500 subprocesos cada uno, el formato de inicio de un servidor Jmeter con parámetros Java se veía así:
nohup java -server -Xms1200m -Xmx1200m -Xss228k -XX:+DisableExplicitGC -XX:+CMSClassUnloadingEnabled -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=70 -XX:+ScavengeBeforeFullGC -XX:+CMSScavengeBeforeRemark -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -Djava.net.preferIPv6Addresses=true -Djava.net.preferIPv4Stack=false -jar "/tmp/jmeter-JwKse5nY/bin/ApacheJMeter.jar" -Jserver.rmi.ssl.disable=true "-Djava.rmi.server.hostname=generator12.loadtest.ig.local" -Duser.dir=/tmp/jmeter-JwKse5nY/bin/ -Dserver_port=13114 -s -Jpoll=49 > /dev/null 2>&1
50ms
La tarea es determinar cuánto puede resistir nuestra base de datos, y no sobrecargarla ni a todo el sistema en su conjunto a un estado crítico. Con tantos servidores Jmeter, necesita de alguna manera mantener la carga a un cierto nivel y no matar todo el sistema. El parámetro
TARGET_RESPONSE_TIME especificado al iniciar la prueba es responsable de esto. Acordamos que
50 ms es el tiempo de respuesta óptimo por el cual el sistema debería ser responsable.
En JMeter, por defecto, hay muchos temporizadores diferentes que le permiten controlar el rendimiento, pero no se sabe dónde obtenerlo en nuestro caso. Pero hay
un temporizador JSR223 con el que puede encontrar algo usando el
tiempo de respuesta actual del sistema. El temporizador en sí está en el bloque de
comportamiento principal:

Análisis de los resultados (daemon)
Además de los gráficos en Grafana, también debe tener resultados de prueba agregados para que las pruebas puedan compararse posteriormente en JLTC.
Una de esas pruebas genera 16k-20k solicitudes por segundo, es fácil calcular que en 4 horas genera un archivo CSV de un par de cientos de GB de tamaño, por lo que fue necesario crear un trabajo que analice los datos cada minuto, los envíe a la base de datos y limpie el archivo principal.
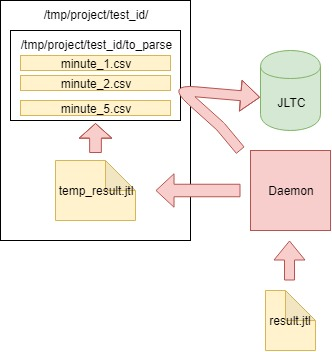
El algoritmo es el siguiente:
- Leemos los datos del archivo CSV result.jtl generado por el jmeter-client, lo guardamos y limpiamos el archivo (debe limpiarlo correctamente, de lo contrario el archivo de aspecto vacío tendrá el mismo FD con el mismo tamaño):
with open(jmeter_results_file, 'r+') as f: rows = f.readlines() f.seek(0) f.truncate(0) f.writelines(rows[-1])
- Escribimos los datos leídos en el archivo temporal temp_result.jtl :
rows_num = len(rows) open(temp_result_filename, 'w').writelines(rows[0:rows_num])
- Leemos el archivo temp_result.jtl . Distribuimos los datos leídos "en minutos":
for r in f.readlines(): row = r.split(',') if len(row[0]) == 13: ts_c = int(row[0]) dt_c = datetime.datetime.fromtimestamp(ts_c/1000) minutes_data.setdefault(dt_c.strftime('%Y_%m_%d_%H_%M'), []).append(r)
- Los datos para cada minuto de minutes_data se escriben en el archivo correspondiente en la carpeta to_parse / . (por lo tanto, en este momento, cada minuto de la prueba tiene su propio archivo de datos, luego, durante la agregación , no importará en qué orden ingresaron los datos en cada archivo):
for key, value in minutes_data.iteritems():
- En el camino, analizamos los archivos en la carpeta to_parse y si alguno de ellos no cambió en un minuto, entonces este archivo es candidato para el análisis, agregación y envío de datos a la base de datos JLTC:
for filename in os.listdir(temp_to_parse_path): data_file = os.path.join(temp_to_parse_path, filename) file_mod_time = os.stat(data_file).st_mtime last_time = (time.time() - file_mod_time) if last_time > 60: logger.info('[DAEMON] File {} was not modified since 1min, adding to parse list.'.format(data_file)) files_to_parse.append(data_file)
- Si existen dichos archivos (uno o varios), los enviamos analizados a la función parse_csv_data (cada archivo en paralelo):
for f in files_to_parse: logger.info('[DAEMON THREAD] Parse {}.'.format(f)) t = threading.Thread( target=parse_csv_data, args=( f, jmeter_results_file_fields, test, data_resolution)) t.start() threads.append(t) for t in threads: t.join()
Daemon en cron.d comienza cada minuto:
El demonio comienza cada minuto con cron.d:
* * * * * root sleep 21 && /usr/bin/python /var/lib/jltc/manage.py daemon
Por lo tanto, el archivo con los resultados no aumenta a tamaños inconcebibles, sino que se analiza
sobre la marcha y se borra.
Resultados
La aplicación
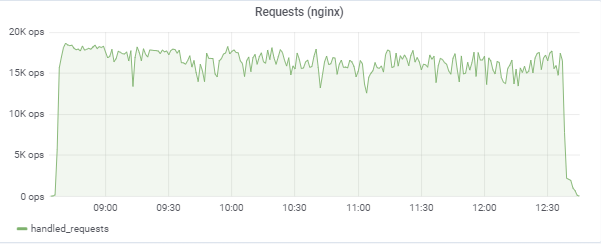
Nuestros 150,000 jugadores virtuales:

La prueba intenta "igualar" el tiempo de respuesta de 50 ms, por lo que la carga en sí misma salta constantemente en la región entre 16k-18k solicitudes / c:
Carga del servidor de aplicaciones (15 aplicaciones). Dos servidores son "desafortunados" para estar en el M620 más lento:
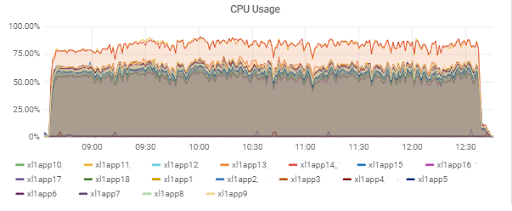
Tiempo de respuesta de la base de datos (para servidores de aplicaciones):

Base de datos
Util de CPU en db1 (VM):
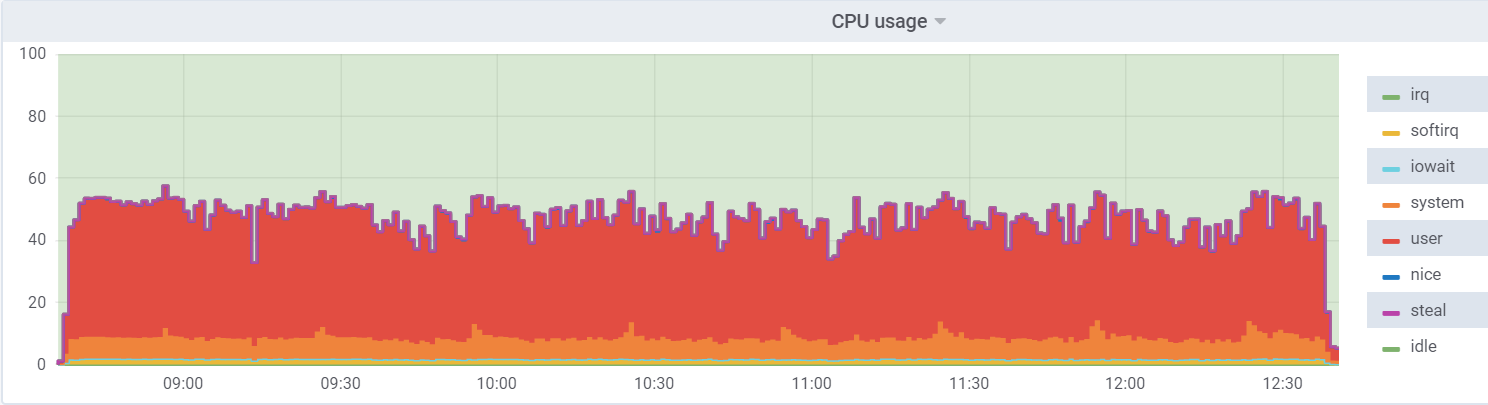
Util de la CPU en el hipervisor:
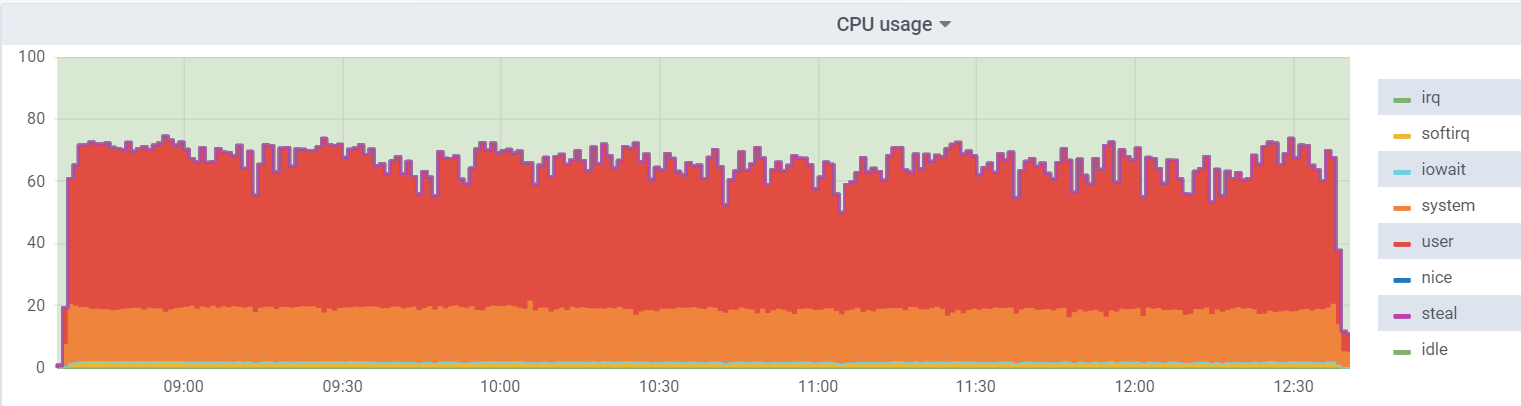
La carga en la máquina virtual es menor, ya que cree que tiene 48 núcleos reales a su disposición, de hecho, hay 24 núcleos
hyperthreading en el hipervisor.
Un
máximo de ~ 250K consultas / s va a la base de datos, que consiste en (83% selecciona, 3% - inserta, 11.6% - actualiza (90% HOT), 1.6% elimina):

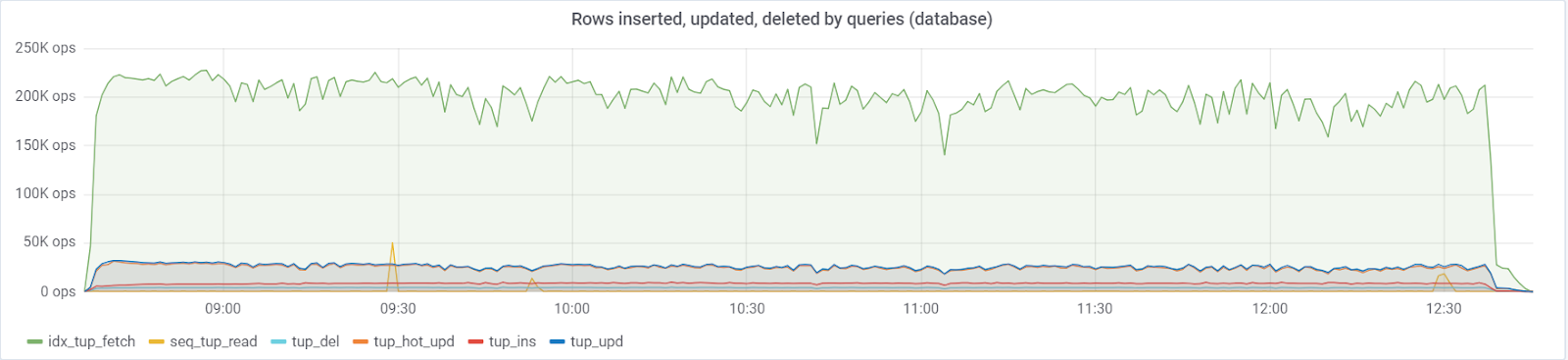
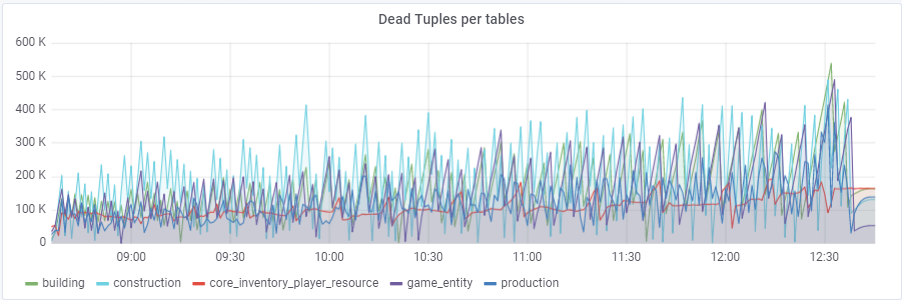
Con un valor predeterminado de
autovacuum_vacuum_scale_factor = 0.2, el número de tuplas muertas creció muy rápidamente con la prueba (con tamaños de tabla crecientes), lo que condujo varias veces a problemas cortos de rendimiento de la base de datos que arruinaron la prueba completa varias veces. Tuve que "domesticar" este crecimiento para algunas tablas asignando valores personales a este parámetro autovacuum_vacuum_scale_factor:
ALTER TABLE ... SET (autovacuum_vacuum_scale_factor = ...)ALTER TABLE construcción SET (autovacuum_vacuum_scale_factor = 0.10);
ALTER TABLE production SET (autovacuum_vacuum_scale_factor = 0.01);
ALTER TABLE game_entity SET (autovacuum_vacuum_scale_factor = 0.01);
ALTER TABLE game_entity SET (autovacuum_analyze_scale_factor = 0.01);
ALTER TABLE building SET (autovacuum_vacuum_scale_factor = 0.01);
ALTER TABLE building SET (autovacuum_analyze_scale_factor = 0.01);
ALTER TABLE core_inventory_player_resource SET (autovacuum_vacuum_scale_factor = 0.10);
ALTER TABLE survivor SET (autovacuum_vacuum_scale_factor = 0.01);
ALTER TABLE survivor SET (autovacuum_analyze_scale_factor = 0.01);
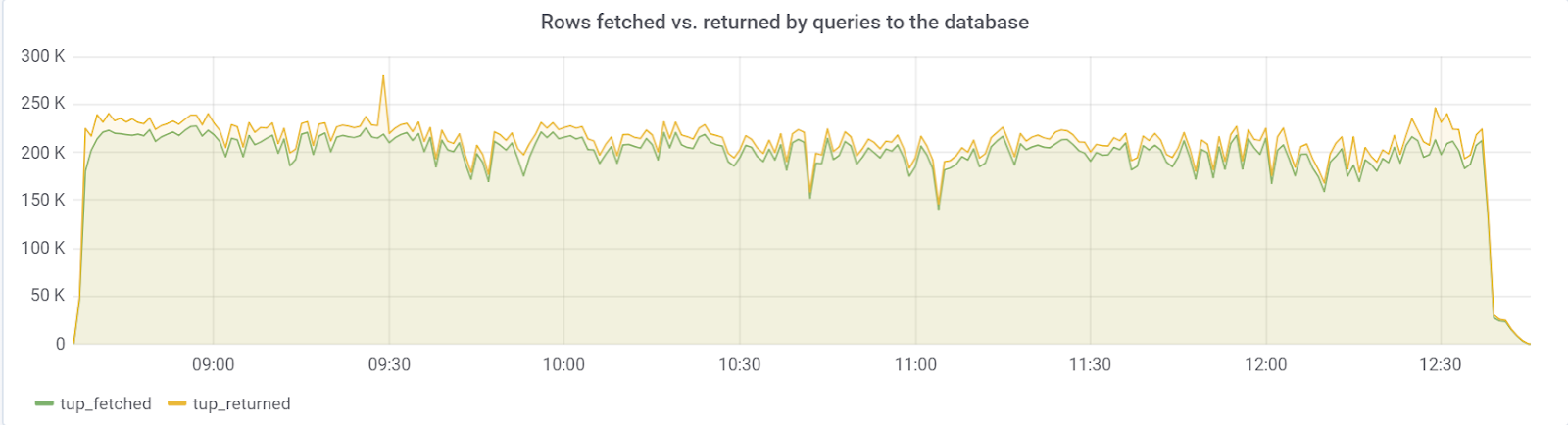
Idealmente, rows_fetched debería estar cerca de rows_returned, que, afortunadamente, observamos:
hot_standby_feedback
El problema estaba en el parámetro
hot_standby_feedback , que puede afectar en gran medida el rendimiento del servidor
principal si sus servidores en
espera no tienen tiempo para aplicar cambios desde los archivos WAL. La documentación (https://postgrespro.ru/docs/postgrespro/11/runtime-config-replication) establece que "determina si el servidor de espera activa notificará al maestro o esclavo superior sobre las solicitudes que está ejecutando actualmente". Por defecto está apagado, pero se activó en nuestra configuración. Lo que condujo a consecuencias tristes, si hay 2 servidores en espera y el retraso de la replicación durante la carga es diferente de cero (por varias razones), puede observar esa imagen, lo que puede provocar el bloqueo de toda la prueba:
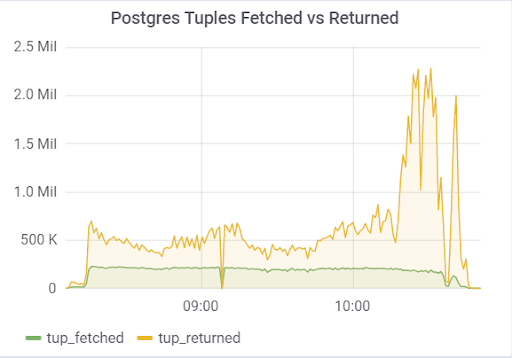

Esto se debe al hecho de que cuando hot_standby_feedback está habilitado, VACUUM no desea eliminar las tuplas "muertas" si los servidores en espera están rezagados en su ID de transacción para evitar conflictos de replicación. Artículo detallado
Lo que realmente hace hot_standby_feedback en PostgreSQL :
xl1_game=# VACUUM VERBOSE core_inventory_player_resource; INFO: vacuuming "public.core_inventory_player_resource" INFO: scanned index "core_inventory_player_resource_pkey" to remove 62869 row versions DETAIL: CPU: user: 1.37 s, system: 0.58 s, elapsed: 4.20 s ………... INFO: "core_inventory_player_resource": found 13682 removable, 7257082 nonremovable row versions in 71842 out of 650753 pages <b>DETAIL: 3427824 dead row versions cannot be removed yet, oldest xmin: 3810193429</b> There were 1920498 unused item pointers. Skipped 8 pages due to buffer pins, 520953 frozen pages. 0 pages are entirely empty. CPU: user: 4.55 s, system: 1.46 s, elapsed: 11.74 s.
Una cantidad tan grande de tuplas muertas conduce a la imagen que se muestra arriba. Aquí hay dos pruebas, con hot_standby_feedback activado y desactivado:
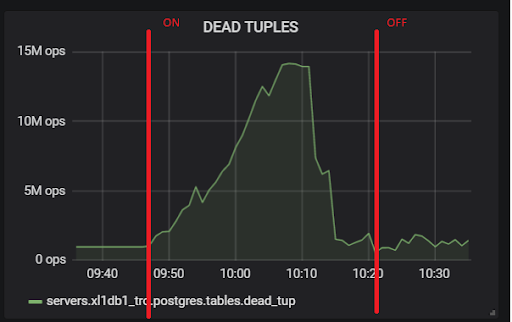
Y este es nuestro retraso de replicación durante la prueba, con el que será necesario hacer algo en el futuro:
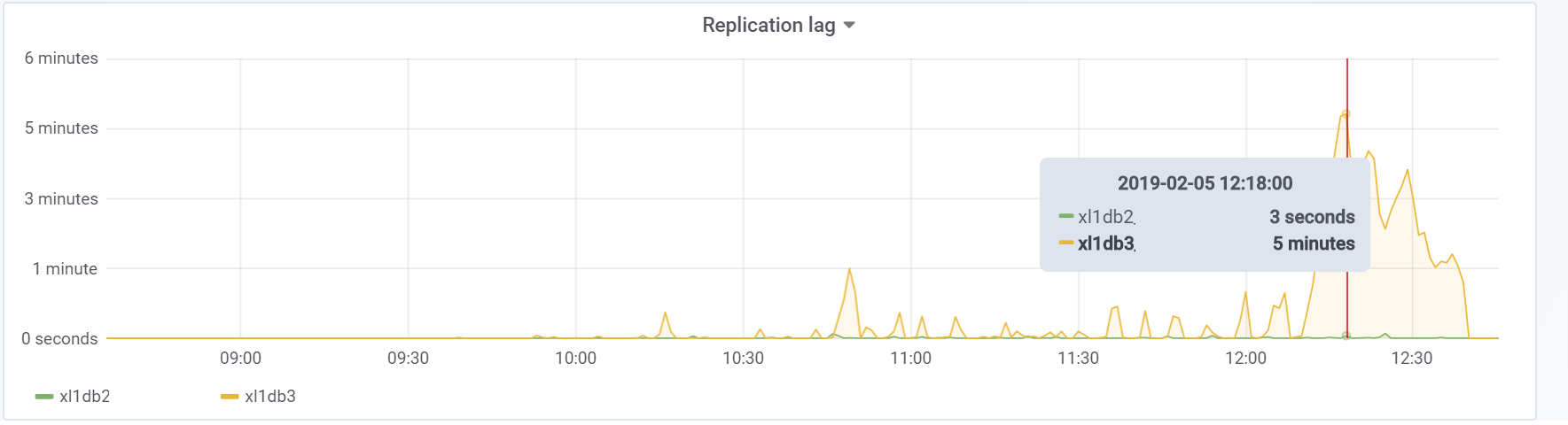
Conclusión
Esta prueba, afortunadamente (o desafortunadamente para el contenido del artículo) demostró que en esta etapa del prototipo del juego es bastante posible absorber la carga deseada por parte de los usuarios, lo que es suficiente para dar luz verde para la creación de más prototipos y desarrollo. En las etapas posteriores de desarrollo, es necesario seguir las reglas básicas (para mantener la simplicidad de las consultas ejecutadas, evitar una sobreabundancia de índices, así como lecturas no indexadas, etc.) y lo más importante, probar el proyecto en cada etapa significativa de desarrollo para encontrar y solucionar problemas. puede ser antes Quizás pronto, escribiré un artículo ya que ya hemos resuelto problemas específicos.
¡Buena suerte a todos!
Nuestro
GitHub por si acaso;)