
La base de datos de series temporales (TSDB) en Prometheus 2 es un gran ejemplo de una solución de ingeniería que ofrece mejoras importantes sobre el almacenamiento v2 en Prometheus 1 en términos de velocidad de almacenamiento de datos y ejecución de consultas, eficiencia de recursos. Implementamos Prometheus 2 en Percona Monitoring and Management (PMM), y tuve la oportunidad de comprender el rendimiento de Prometheus 2 TSDB. En este artículo hablaré sobre los resultados de estas observaciones.
Prometheus carga de trabajo promedio
Para aquellos que están acostumbrados a tratar con bases de datos primarias, la carga de trabajo regular de Prometheus es bastante curiosa. La velocidad de acumulación de datos tiende a un valor estable: por lo general, los servicios que supervisa envían aproximadamente la misma cantidad de métricas, y la infraestructura cambia relativamente lentamente.
Las solicitudes de información pueden provenir de diferentes fuentes. Algunos de ellos, como las alertas, también luchan por un valor estable y predecible. Otros, como las consultas de los usuarios, pueden causar picos, aunque esto no es típico para la mayor parte de la carga.
Prueba de carga
Durante las pruebas, me concentré en la capacidad de acumular datos. Implementé Prometheus 2.3.2 compilado con Go 1.10.1 (como parte de PMM 1.14) en el servicio Linode usando este script:
StackScript . Para la generación de carga más realista, usando este
StackScript, lancé varios nodos MySQL con una carga real (Prueba Sysbench TPC-C), cada uno de los cuales emuló 10 nodos Linux / MySQL.
Todas las siguientes pruebas se llevaron a cabo en un servidor Linode con ocho núcleos virtuales y 32 GB de memoria, en el que se lanzaron 20 simulaciones de carga de monitoreo de doscientas instancias MySQL. O, en términos de Prometheus, 800 objetivos, 440 raspados por segundo, 380 mil muestras por segundo y 1.7 millones de series de tiempo activas.
Diseño
El enfoque habitual de las bases de datos tradicionales, incluida la utilizada por Prometheus 1.x, es el
límite de memoria . Si no es suficiente para soportar la carga, encontrará grandes retrasos y algunas solicitudes no se cumplirán.
El uso de memoria en Prometheus 2 se configura utilizando la clave
storage.tsdb.min-block-duration , que determina cuánto tiempo se almacenarán los registros en la memoria antes de vaciarlos en el disco (de manera predeterminada, esto es 2 horas). La cantidad de memoria necesaria dependerá de la cantidad de series de tiempo, etiquetas y la intensidad de la recopilación de datos (raspados) en total con el flujo de entrada neto. En términos de espacio en disco, Prometheus pretende utilizar 3 bytes por registro (muestra). Por otro lado, los requisitos de memoria son mucho más altos.
A pesar de que es posible configurar el tamaño del bloque, no se recomienda configurarlo manualmente, por lo que se enfrenta a la necesidad de darle a Prometheus tanta memoria como le pida su carga.
Si no hay suficiente memoria para admitir el flujo de métricas entrantes, Prometheus se quedará sin memoria o el asesino OOM lo alcanzará.
Agregar intercambio para retrasar el bloqueo cuando Prometheus se queda sin memoria realmente no ayuda, porque usar esta característica causa un consumo explosivo de memoria. Creo que la cosa es Go, su recolector de basura y cómo funciona con el intercambio.
Otro enfoque interesante es configurar el bloque de cabeza para que se restablezca en el disco en un momento específico, en lugar de contarlo desde el inicio del proceso.
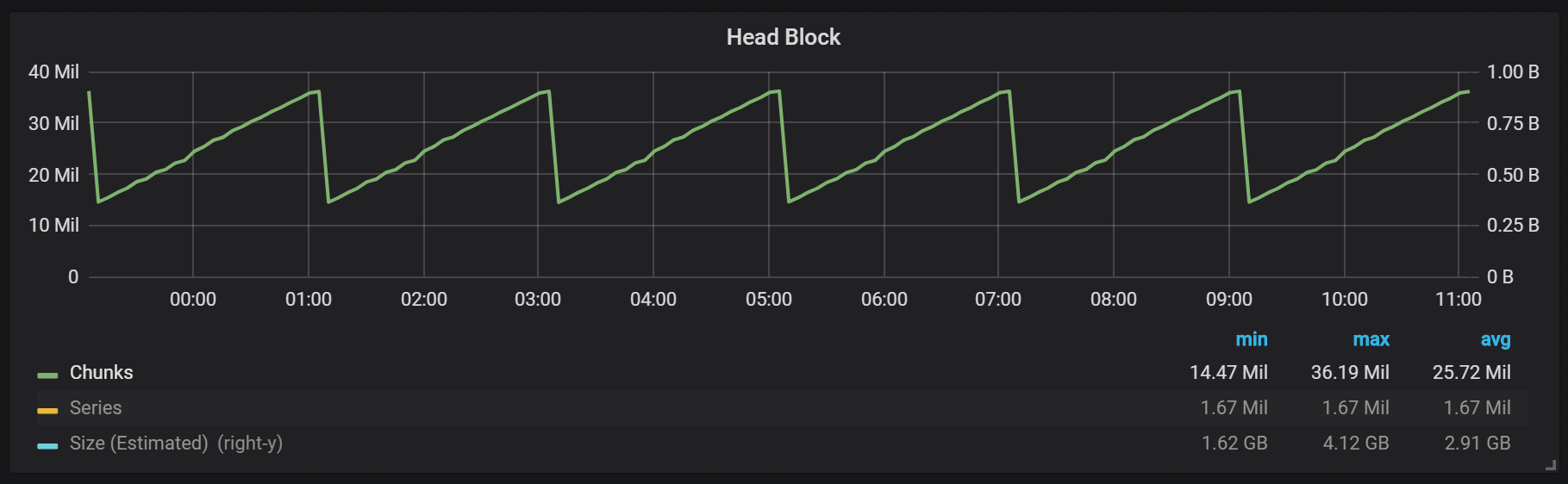
Como puede ver en el gráfico, los enjuagues de disco ocurren cada dos horas. Si cambia el parámetro de duración mínima de bloque a una hora, estas descargas ocurrirán cada hora, comenzando en media hora.
Si desea usar este y otros gráficos en su instalación de Prometheus, puede usar este tablero . Fue desarrollado para PMM, pero, con modificaciones menores, es adecuado para cualquier instalación de Prometheus.Tenemos un bloque activo llamado bloque de cabeza, que se almacena en la memoria; Se puede acceder a los bloques con datos más antiguos a través de
mmap() . Esto elimina la necesidad de configurar la memoria caché por separado, pero también significa que debe dejar suficiente espacio para la memoria caché del sistema operativo si desea realizar solicitudes de datos anteriores al bloque principal.
Esto también significa que el consumo de memoria virtual de Prometheus se verá bastante alto, por lo que no vale la pena preocuparse.

Otro punto de diseño interesante es el uso de WAL (registro de escritura anticipada). Como puede ver en la documentación de almacenamiento, Prometheus usa WAL para evitar pérdidas debido a caídas. Lamentablemente, los mecanismos específicos para garantizar la supervivencia de los datos no están bien documentados. La versión 2.3.2 de Prometheus descarga el WAL al disco cada 10 segundos, y este parámetro no es configurable por el usuario.
Sellos (compactaciones)
Prometheus TSDB está diseñado en la imagen de un repositorio LSM (fusión estructurada de registro: un árbol estructurado de registro con fusión): el bloque principal se vacía periódicamente en el disco, mientras que el mecanismo de compresión combina varios bloques para evitar el escaneo de demasiados bloques durante las solicitudes. Aquí puede ver la cantidad de bloques que observé en el sistema de prueba después de un día de trabajo.
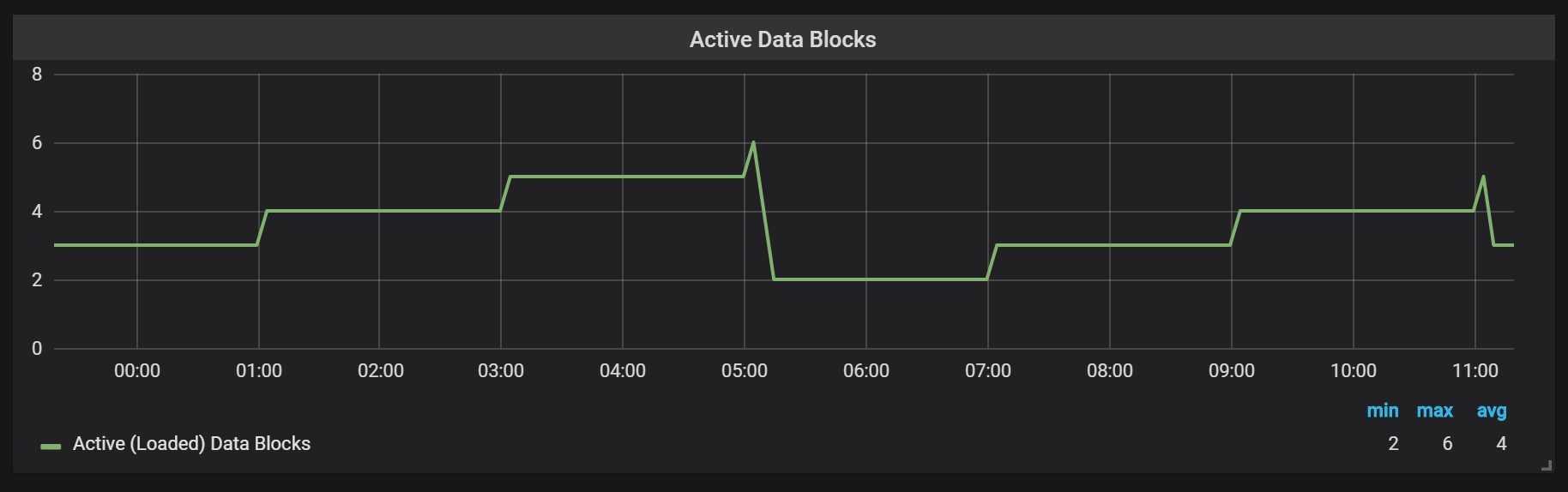
Si desea saber más sobre el repositorio, puede estudiar el archivo meta.json, que contiene información sobre los bloques disponibles y cómo aparecieron.
{ "ulid": "01CPZDPD1D9R019JS87TPV5MPE", "minTime": 1536472800000, "maxTime": 1536494400000, "stats": { "numSamples": 8292128378, "numSeries": 1673622, "numChunks": 69528220 }, "compaction": { "level": 2, "sources": [ "01CPYRY9MS465Y5ETM3SXFBV7X", "01CPYZT0WRJ1JB1P0DP80VY5KJ", "01CPZ6NR4Q3PDP3E57HEH760XS" ], "parents": [ { "ulid": "01CPYRY9MS465Y5ETM3SXFBV7X", "minTime": 1536472800000, "maxTime": 1536480000000 }, { "ulid": "01CPYZT0WRJ1JB1P0DP80VY5KJ", "minTime": 1536480000000, "maxTime": 1536487200000 }, { "ulid": "01CPZ6NR4Q3PDP3E57HEH760XS", "minTime": 1536487200000, "maxTime": 1536494400000 } ] }, "version": 1 }
Los sellos en Prometeo están atados al momento en que un bloque de cabeza se enjuagó al disco. En este punto, se pueden realizar varias de estas operaciones.
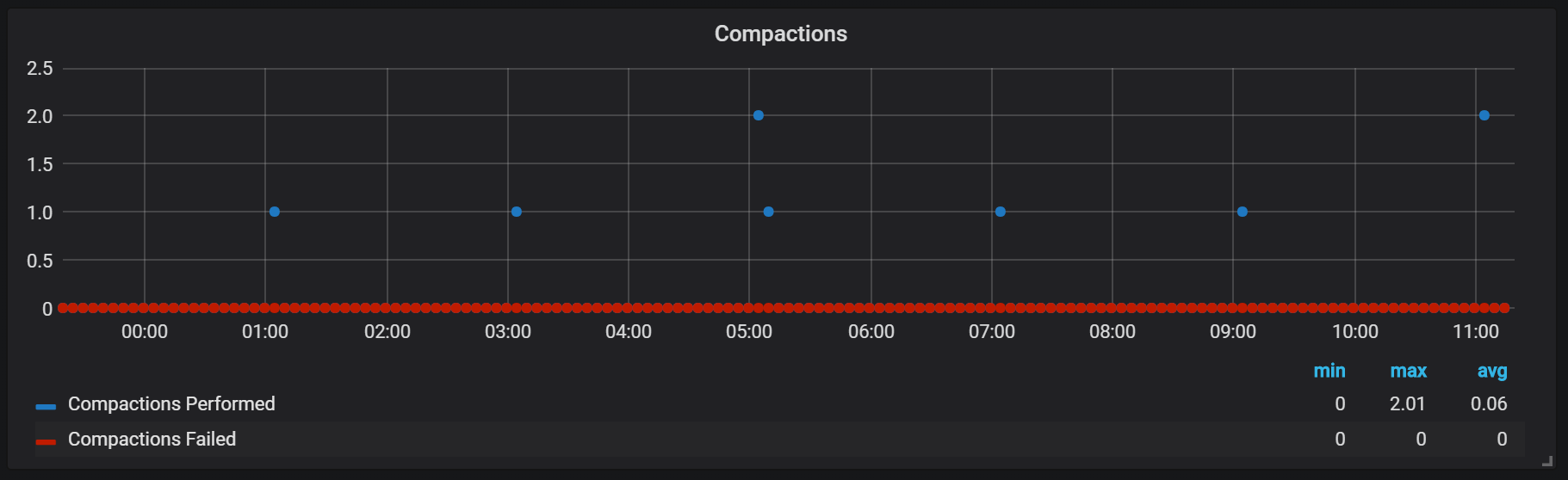
Aparentemente, los sellos son ilimitados de cualquier manera y pueden causar grandes saltos de E / S de disco en tiempo de ejecución.

Picos de descarga de la CPU

Por supuesto, esto afecta negativamente la velocidad del sistema, y también es un desafío serio para el almacenamiento LSM: ¿cómo hacer sellos para soportar altas velocidades de consulta y no causar demasiada sobrecarga?
El uso de la memoria en el proceso de compactación también parece bastante interesante.

Podemos ver cómo, después de la compactación, la mayoría de la memoria cambia de estado de caché a libre: significa que la información potencialmente valiosa se eliminó de allí. Es curioso si
fadvice() usa aquí o alguna otra técnica de minimización, o es porque el caché se liberó de los bloques destruidos durante la compactación?
Crash Recovery
La recuperación ante desastres lleva tiempo, y está justificada. Para un flujo entrante de un millón de registros por segundo, tuve que esperar unos 25 minutos mientras se realizaba la recuperación teniendo en cuenta la unidad SSD.
level=info ts=2018-09-13T13:38:14.09650965Z caller=main.go:222 msg="Starting Prometheus" version="(version=2.3.2, branch=v2.3.2, revision=71af5e29e815795e9dd14742ee7725682fa14b7b)" level=info ts=2018-09-13T13:38:14.096599879Z caller=main.go:223 build_context="(go=go1.10.1, user=Jenkins, date=20180725-08:58:13OURCE)" level=info ts=2018-09-13T13:38:14.096624109Z caller=main.go:224 host_details="(Linux 4.15.0-32-generic #35-Ubuntu SMP Fri Aug 10 17:58:07 UTC 2018 x86_64 1bee9e9b78cf (none))" level=info ts=2018-09-13T13:38:14.096641396Z caller=main.go:225 fd_limits="(soft=1048576, hard=1048576)" level=info ts=2018-09-13T13:38:14.097715256Z caller=web.go:415 component=web msg="Start listening for connections" address=:9090 level=info ts=2018-09-13T13:38:14.097400393Z caller=main.go:533 msg="Starting TSDB ..." level=info ts=2018-09-13T13:38:14.098718401Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536530400000 maxt=1536537600000 ulid=01CQ0FW3ME8Q5W2AN5F9CB7R0R level=info ts=2018-09-13T13:38:14.100315658Z caller=web.go:467 component=web msg="router prefix" prefix=/prometheus level=info ts=2018-09-13T13:38:14.101793727Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536732000000 maxt=1536753600000 ulid=01CQ78486TNX5QZTBF049PQHSM level=info ts=2018-09-13T13:38:14.102267346Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536537600000 maxt=1536732000000 ulid=01CQ78DE7HSQK0C0F5AZ46YGF0 level=info ts=2018-09-13T13:38:14.102660295Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536775200000 maxt=1536782400000 ulid=01CQ7SAT4RM21Y0PT5GNSS146Q level=info ts=2018-09-13T13:38:14.103075885Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536753600000 maxt=1536775200000 ulid=01CQ7SV8WJ3C2W5S3RTAHC2GHB level=error ts=2018-09-13T14:05:18.208469169Z caller=wal.go:275 component=tsdb msg="WAL corruption detected; truncating" err="unexpected CRC32 checksum d0465484, want 0" file=/opt/prometheus/data/.prom2-data/wal/007357 pos=15504363 level=info ts=2018-09-13T14:05:19.471459777Z caller=main.go:543 msg="TSDB started" level=info ts=2018-09-13T14:05:19.471604598Z caller=main.go:603 msg="Loading configuration file" filename=/etc/prometheus.yml level=info ts=2018-09-13T14:05:19.499156711Z caller=main.go:629 msg="Completed loading of configuration file" filename=/etc/prometheus.yml level=info ts=2018-09-13T14:05:19.499228186Z caller=main.go:502 msg="Server is ready to receive web requests."
El principal problema del proceso de recuperación es el alto consumo de memoria. A pesar de que, en una situación normal, el servidor puede funcionar de manera estable con la misma cantidad de memoria, cuando se bloquea, es posible que no aumente debido a OOM. La única solución que encontré fue desactivar la recopilación de datos, elevar el servidor, permitir que se recupere y reiniciar con la recopilación ya activada.
Calentar
Otro comportamiento que debe recordarse durante el calentamiento es la relación entre baja productividad y alto consumo de recursos justo después del inicio. Durante algunos, pero no todos los inicios, observé una carga seria en la CPU y la memoria.
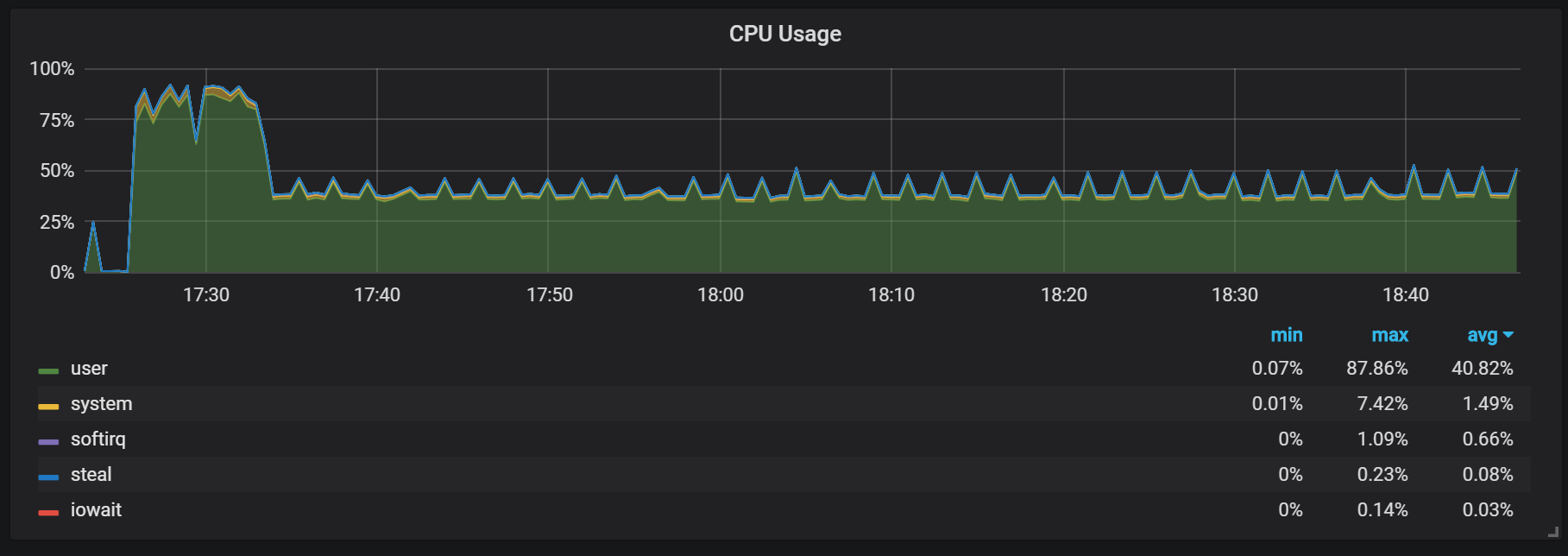

Los fallos de memoria indican que Prometheus no puede configurar todos los cargos desde el principio y se pierde parte de la información.
No descubrí las razones exactas de la alta carga en el procesador y la memoria. Sospecho que esto se debe a la creación de nuevas series de tiempo en el bloque de la cabeza con una alta frecuencia.
Picos de carga de la CPU
Además de los sellos, que crean una carga de E / S bastante alta, noté saltos serios en la carga del procesador cada dos minutos. Las ráfagas duran más tiempo con un flujo entrante alto y parece que son causadas por el recolector de basura Go, al menos algunos núcleos están completamente cargados.

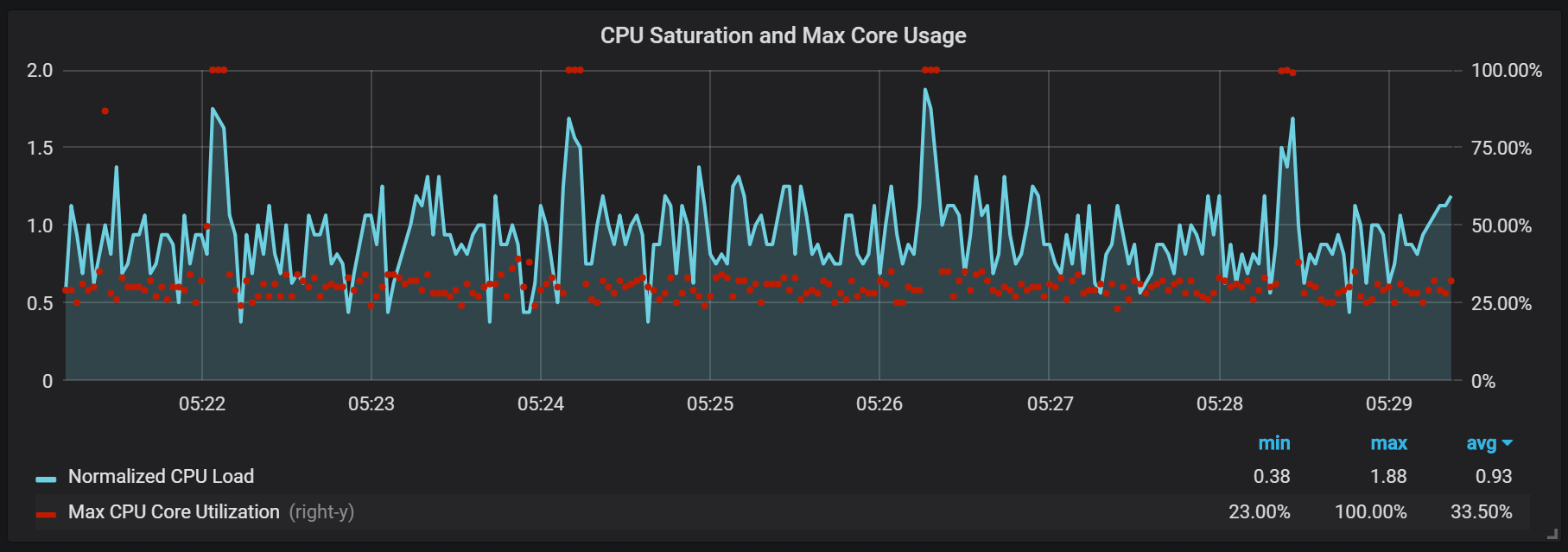
Estos saltos no son tan insignificantes. Parece que cuando ocurren, el punto de entrada interno y las métricas de Prometheus se vuelven inaccesibles, lo que provoca lagunas de datos en los mismos intervalos de tiempo.
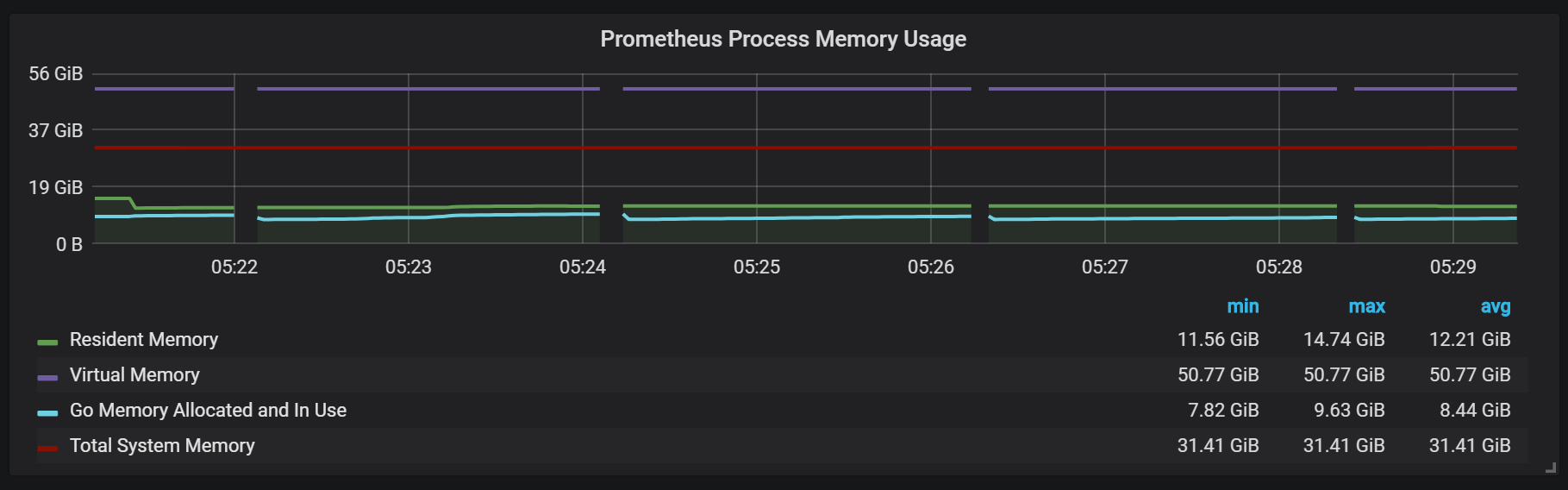
También puede notar que el exportador Prometheus se cierra por un segundo.
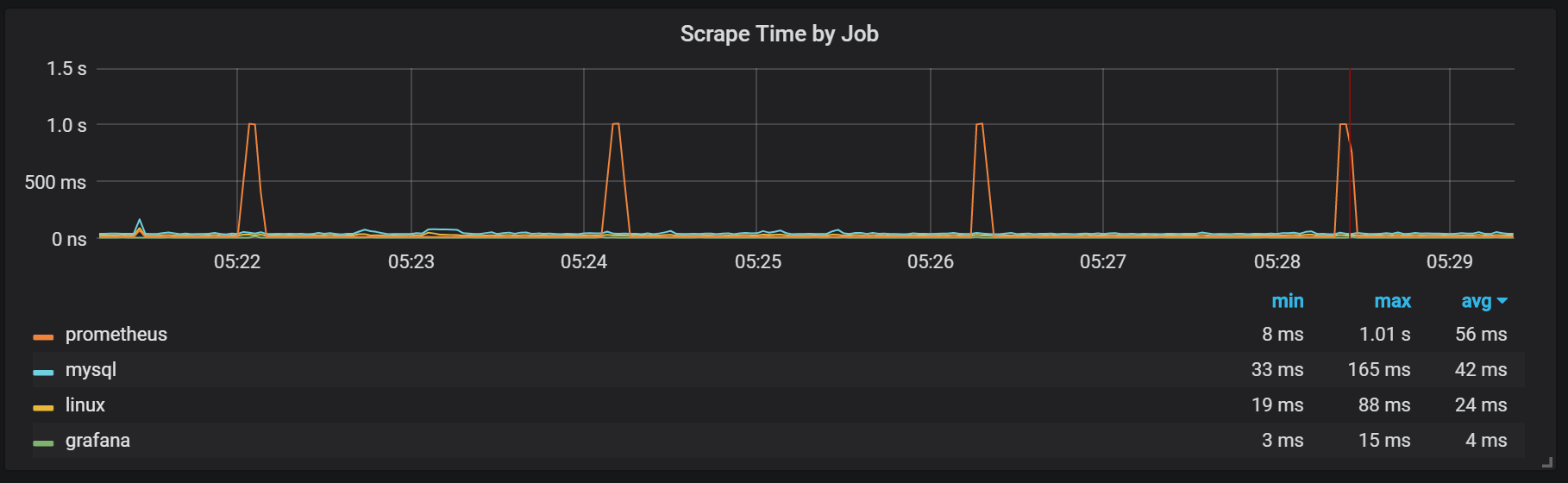
Podemos ver correlaciones con la recolección de basura (GC).

Conclusión
TSDB en Prometheus 2 es rápido, capaz de manejar millones de series de tiempo y al mismo tiempo con miles de grabaciones por segundo utilizando hardware bastante modesto. La utilización de la CPU y la E / S de disco también es impresionante. Mi ejemplo mostró hasta 200,000 métricas por segundo por núcleo utilizado.
Para planificar la extensión, debe recordar los volúmenes de memoria suficientes, y esto debería ser memoria real. La cantidad de memoria utilizada que observé fue de aproximadamente 5 GB por cada 100,000 entradas por segundo de la transmisión entrante, que combinada con el caché del sistema operativo de aproximadamente 8 GB de memoria ocupada.
Por supuesto, todavía hay mucho trabajo para dominar las ráfagas de CPU y E / S de disco, y esto no es sorprendente dado lo joven que es el TSDB Prometheus 2 en comparación con InnoDB, TokuDB, RocksDB, WiredTiger, pero todos tuvieron problemas similares al comienzo del ciclo de vida.