
La lógica de las máquinas es impecable, no cometen errores si su algoritmo funciona correctamente y los parámetros establecidos corresponden a los estándares necesarios. Pídale al automóvil que elija una ruta desde el punto A hasta el punto B, y construirá el más óptimo, teniendo en cuenta la distancia, el consumo de combustible, la presencia de estaciones de servicio, etc. Este es un puro cálculo. El auto no dirá: "Vamos por este camino, siento esta ruta mejor". Quizás los autos sean mejores que nosotros en la velocidad de los cálculos, pero la intuición sigue siendo una de nuestras cartas de triunfo. La humanidad ha pasado docenas de años creando una máquina similar al cerebro humano. ¿Pero hay tanto en común entre ellos? Hoy consideraremos un estudio en el que los científicos, dudando de la incomparable "visión" de la máquina sobre la base de redes neuronales convolucionales, realizaron un experimento para engañar a un sistema de reconocimiento de objetos utilizando un algoritmo cuya tarea era crear imágenes "falsas". ¿Qué tan exitosa fue la actividad de sabotaje del algoritmo, la gente hizo frente al reconocimiento mejor que los automóviles, y qué aportará este estudio al futuro de esta tecnología? Encontraremos respuestas en el informe de los científicos. Vamos
Base de estudio
Las tecnologías de reconocimiento de objetos que utilizan redes neuronales convolucionales (SNS) permiten a la máquina, en términos generales, distinguir un cisne del número 9 o un gato de una bicicleta. Esta tecnología se está desarrollando con bastante rapidez y actualmente se está aplicando en varios campos, el más obvio de los cuales es la producción de vehículos no tripulados. Muchos opinan que el SCN del sistema de reconocimiento de objetos puede considerarse como un modelo de visión humana. Sin embargo, esta declaración es demasiado ruidosa, debido al factor humano. La cuestión es que engañar a un automóvil resultó ser más fácil que engañar a una persona (al menos en materia de reconocimiento de objetos). Los sistemas SNA son muy vulnerables a los efectos de algoritmos maliciosos (hostiles, si lo desea), lo que evitará que realicen correctamente su tarea, creando imágenes que el sistema SNA clasificará incorrectamente.
Los investigadores dividen esas imágenes en dos categorías: "engañar" (cambiar completamente el objetivo) y "vergonzoso" (cambiar parcialmente el objetivo). Las primeras son imágenes sin sentido que el sistema reconoce como algo familiar. Por ejemplo, un conjunto de líneas puede clasificarse como un "béisbol" y el ruido digital multicolor como un "armadillo". La segunda categoría de imágenes ("vergonzoso") son imágenes que, en condiciones normales, se clasificarían correctamente, pero el algoritmo malicioso las distorsiona ligeramente, exagerando diciendo, a los ojos del sistema SNA. Por ejemplo, el número 6 escrito a mano se clasificará como número 5 debido a un pequeño complemento de varios píxeles.
Solo imagine qué daño pueden hacer tales algoritmos. Vale la pena cambiar la clasificación de las señales de tráfico para el transporte autónomo y los accidentes serán inevitables.
A continuación se muestran las imágenes "falsas" que engañan al sistema SNA, capacitadas para reconocer objetos, y cómo un sistema similar los clasificó.
 Imagen No. 1
Imagen No. 1Explicación de la serie:
- y - imágenes "fraudulentas" codificadas indirectamente;
- b - imágenes "fraudulentas" codificadas directamente;
- c - imágenes "embarazosas", obligando al sistema a clasificar un dígito como otro;
- d - El ataque LaVAN (ruido adversario / malicioso localizado y visible) puede conducir a una clasificación incorrecta, incluso cuando el "ruido" se encuentra solo en un punto (en la esquina inferior derecha).
- e - objetos tridimensionales que se clasifican incorrectamente desde diferentes ángulos.
Lo más curioso de esto es que una persona puede no sucumbir a engañar a un algoritmo malicioso y clasificar las imágenes correctamente, según la intuición. Anteriormente, como dicen los científicos, nadie hizo una comparación práctica de las habilidades de una máquina y una persona en un experimento para contrarrestar algoritmos maliciosos de imágenes falsas. Eso es lo que los investigadores decidieron hacer.
Para esto, se prepararon varias imágenes hechas por algoritmos maliciosos. A los sujetos se les dijo que la máquina clasificaba estas imágenes (frontales) como objetos familiares, es decir. la máquina no los reconoció correctamente. La tarea de los sujetos era determinar exactamente cómo la máquina clasificaba estas imágenes, es decir. Lo que creen que la máquina vio en las imágenes, es esta clasificación verdadera, etc.
Se llevaron a cabo un total de 8 experimentos, en los que se utilizaron 5 tipos de imágenes maliciosas creadas sin tener en cuenta la visión humana. En otras palabras, son creados por máquina para máquinas. Los resultados de estos experimentos resultaron ser muy entretenidos, pero no los estropearemos y consideraremos todo en orden.
Resultados del experimento
Experimento 1: Imágenes engañosas con etiquetas inválidas
En el primer experimento, se utilizaron 48 imágenes engañadas, creadas por el algoritmo para contrarrestar el sistema de reconocimiento basado en el SNA llamado AlexNet. Este sistema clasificó estas imágenes como "engranaje" y "rosquilla" (
2a ).
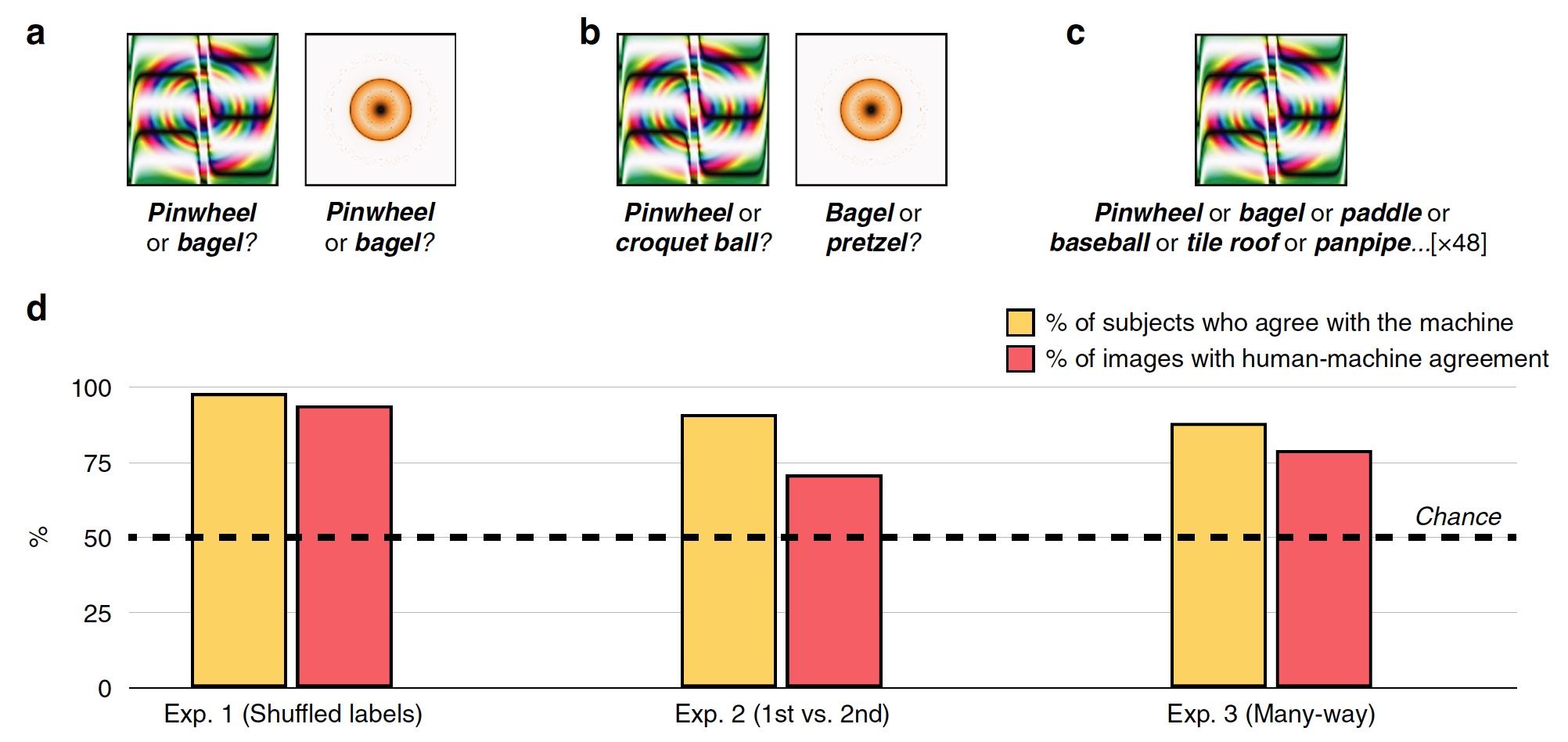 Imagen No. 2
Imagen No. 2Durante cada intento, la persona de prueba, de los cuales había 200, vio una imagen duplicada y dos marcas, es decir etiquetas de clasificación: etiqueta SNS del sistema y aleatoria de las otras 47 imágenes. Los sujetos tenían que elegir la etiqueta creada por la máquina.
Como resultado, la mayoría de los sujetos eligieron elegir una etiqueta creada por la máquina, en lugar de la etiqueta de un algoritmo malicioso. Precisión de clasificación, es decir El grado de consentimiento del sujeto con la máquina fue del 74%. Estadísticamente, el 98% de los sujetos eligieron las etiquetas de la máquina en un nivel más alto que la aleatoriedad estadística (
2d , "% de sujetos están de acuerdo con la máquina"). El 94% de las imágenes mostraron una alineación humano-máquina muy alta, es decir, de 48, solo 3 imágenes fueron clasificadas por personas de manera diferente a una máquina.
Así, los sujetos mostraron que una persona es capaz de compartir una imagen real y un tonto, es decir, actuar de acuerdo con un programa basado en el SCN.
Experimento No. 2: primera opción versus segunda
Los investigadores hicieron la pregunta: ¿debido a qué sujetos pudieron reconocer las imágenes tan bien y separarlas de las marcas erróneas y las imágenes duplicadas? Quizás los sujetos notaron el anillo amarillo anaranjado como una "dona", porque en realidad la dona tiene exactamente esta forma y es aproximadamente del mismo color. En reconocimiento, las asociaciones y las elecciones intuitivas basadas en la experiencia y el conocimiento podrían ayudar a una persona.
Para verificar esto, la etiqueta aleatoria fue reemplazada por la seleccionada por la máquina como la segunda opción de clasificación posible. Por ejemplo, AlexNet clasificó el anillo naranja-amarillo como una "dona", y la segunda opción para este programa fue "pretzel".
Los sujetos se enfrentaron a la tarea de elegir la primera marca de la máquina o la que ocupaba el segundo lugar para las 48 imágenes (
2s ).
El gráfico en el centro de la imagen
2d muestra los resultados de esta prueba: el 91% de los sujetos eligió la primera versión de la etiqueta, y el nivel de correspondencia hombre-máquina fue del 71%.
Experimento No. 3: clasificación multihilo
Los experimentos descritos anteriormente son bastante simples en vista del hecho de que los sujetos pueden elegir entre dos respuestas posibles (etiqueta de máquina y etiqueta aleatoria). De hecho, la máquina en el proceso de reconocimiento de imágenes recorre cientos e incluso miles de opciones de etiquetas antes de elegir la más adecuada.
En esta prueba, todas las marcas de 48 imágenes estaban inmediatamente delante de los sujetos. Tenían que elegir de este conjunto el más adecuado para cada imagen.
Como resultado, el 88% de los sujetos eligió exactamente las mismas etiquetas que la máquina, y el grado de coordinación fue del 79%. Un hecho interesante es que incluso al elegir la etiqueta incorrecta que eligió la máquina, los sujetos en el 63% de estos casos eligieron una de las 5 etiquetas principales. Es decir, todas las marcas en el automóvil están ordenadas en una lista desde la más adecuada hasta la más inapropiada (ejemplo exagerado: "bagel", "pretzel", "anillo de goma", "neumático", etc. hasta "halcón en el cielo nocturno" )
Experimento No. 3b: "¿Qué es?"
En esta prueba, los científicos han cambiado ligeramente las reglas. En lugar de pedirles que "adivinen" qué etiqueta elegirá la máquina para una imagen en particular, simplemente se les preguntó a los sujetos qué ven delante de ellos.
Los sistemas de reconocimiento basados en redes neuronales convolucionales seleccionan la etiqueta apropiada para una imagen en particular. Este es un proceso bastante claro y lógico. En esta prueba, los sujetos exhiben un pensamiento intuitivo.
Como resultado, el 90% de los sujetos eligieron una etiqueta, que también fue elegida por la máquina. La alineación hombre-máquina entre las imágenes fue del 81%.
Experimento 4: ruido estático de televisión
Los científicos señalan que en experimentos anteriores, las imágenes son inusuales, pero tienen características distinguibles que pueden incitar a los sujetos a elegir la etiqueta correcta (o incorrecta). Por ejemplo, la imagen "béisbol" no es una pelota, pero tiene líneas y colores que están presentes en una pelota de béisbol real. Esta es una característica distintiva sorprendente. Pero si la imagen no tiene tales características, pero es esencialmente ruido estático, ¿puede una persona reconocer al menos algo en ella? Eso es lo que se decidió verificar.
 Imagen No. 3a
Imagen No. 3aEn esta prueba, había 8 imágenes con estática frente a los sujetos, que el sistema SNS reconoce como un objeto específico (por ejemplo, un pájaro-zaryanka). Además, frente a los sujetos había una etiqueta e imágenes normales relacionadas (8 imágenes de estática, 1 etiqueta "zaryanka" y 5 fotos de esta ave). El sujeto de prueba tuvo que seleccionar 1 de 8 imágenes de estática que mejor se adapten a una u otra etiqueta.
Puedes ponerte a prueba. Arriba ves un ejemplo de tal prueba. ¿Cuál de las tres imágenes se adapta mejor a la etiqueta "zaryanka" y por qué?
El 81% de los sujetos eligió la etiqueta que eligió la máquina. Al mismo tiempo, el 75% de las imágenes fueron etiquetadas por los sujetos con la etiqueta más adecuada en la opinión de la máquina (de varias opciones, como mencionamos anteriormente).
Para esta prueba en particular, puede tener preguntas, como la mía. El hecho es que en las estadísticas propuestas (arriba), personalmente veo tres características pronunciadas que las distinguen entre sí. Y solo en una imagen, esta característica se parece mucho a la misma zaryanka (creo que entiendes qué imagen de las tres). Por lo tanto, mi opinión personal y muy subjetiva es que tal prueba no es particularmente indicativa. Aunque quizás entre otras opciones para imágenes estáticas eran realmente indistinguibles e irreconocibles.
Experimento No. 5: números "dudosos"
Las pruebas descritas anteriormente se basaron en imágenes que no pueden ser inmediatamente completas y sin ninguna duda clasificadas como uno u otro objeto. Siempre hay una fracción de duda. Las imágenes engañosas son bastante sencillas en su trabajo: estropear la imagen más allá del reconocimiento. Pero hay un segundo tipo de algoritmos maliciosos que agregan (o eliminan) solo un pequeño detalle en la imagen, que puede violar por completo el sistema de reconocimiento del sistema SNA. Agregue algunos píxeles, y el número 6 se convierte mágicamente en el número 5 (
1s ).
Los científicos consideran que tales algoritmos son uno de los más peligrosos. Puede cambiar ligeramente la etiqueta de la imagen, y el vehículo no tripulado considera incorrectamente la señal de límite de velocidad (por ejemplo, 75 en lugar de 45), lo que puede tener consecuencias tristes.
 Imagen # 3b
Imagen # 3bEn esta prueba, los científicos sugirieron que los sujetos elijan la respuesta incorrecta, pero más bien la incorrecta. En la prueba, se utilizaron 100 imágenes digitales modificadas por un algoritmo malicioso (el LeNet SNA cambió su clasificación, es decir, el algoritmo malicioso funcionó con éxito). Los sujetos tenían que decir qué figura en su opinión vio la máquina. Como se esperaba, el 89% de los sujetos completaron con éxito esta prueba.
Experimento 6: fotos y "distorsión" localizada
Los científicos señalan que no solo se están desarrollando sistemas de reconocimiento de objetos, sino también algoritmos maliciosos que les impiden hacerlo. Anteriormente, para que la imagen se clasificara incorrectamente, era necesario distorsionar (cambiar, eliminar, dañar, etc.) el 14% de todos los píxeles en la imagen de destino. Ahora esta cifra se ha vuelto mucho más pequeña. Es suficiente agregar una pequeña imagen dentro del objetivo y se violará la clasificación.
 Imagen No. 4
Imagen No. 4En esta prueba, se utilizó un algoritmo LaVAN malicioso bastante nuevo, que coloca una pequeña imagen localizada en un punto de la foto de destino. Como resultado, el sistema de reconocimiento de objetos puede reconocer el tren del metro como una lata de leche (
4a ). Las características más significativas de este algoritmo son precisamente la pequeña proporción de píxeles dañados (solo el 2%) de la imagen objetivo y la ausencia de la necesidad de distorsionarla en su totalidad o en la parte principal (más significativa) de la misma.
En la prueba, se utilizaron 22 imágenes dañadas por LaVAN (este algoritmo hackeó con éxito el sistema de reconocimiento SNA Inception V3). Se suponía que los sujetos clasificaban el inserto malicioso en la foto. El 87% de los sujetos pudieron hacerlo con éxito.
Experimento 7: objetos tridimensionales.
Las imágenes que vimos anteriormente son bidimensionales, como cualquier foto, fotografía o recorte de periódico. La mayoría de los algoritmos maliciosos manipulan con éxito solo esas imágenes. Sin embargo, estas plagas pueden funcionar solo bajo ciertas condiciones, es decir, tienen una serie de limitaciones:
- complejidad: solo imágenes bidimensionales;
- aplicación práctica: los cambios maliciosos solo son posibles en sistemas que leen las imágenes digitales recibidas, y no en imágenes de sensores y sensores;
- estabilidad: un ataque malicioso pierde su fuerza si gira una imagen bidimensional (cambiar el tamaño, recortar, enfocar, etc.);
- personas: vemos el mundo y los objetos que nos rodean en 3D en diferentes ángulos, iluminación y no en forma de imágenes digitales bidimensionales tomadas desde un ángulo.
Pero, como sabemos, el progreso no ha escatimado algoritmos maliciosos. Entre ellos apareció uno que es capaz de distorsionar no solo las imágenes bidimensionales, sino también las tridimensionales, lo que conduce a una clasificación incorrecta por parte del sistema de reconocimiento de objetos. Cuando se utiliza software para gráficos tridimensionales, dicho algoritmo confunde a los clasificadores basados en el SNA (en este caso, el programa Inception V3) desde diferentes distancias y ángulos de visión. Lo más sorprendente es que estas imágenes 3D engañosas se pueden imprimir en una impresora adecuada, es decir. crea un objeto físico real, y el sistema de reconocimiento de objetos aún lo clasificará incorrectamente (por ejemplo, una naranja como un taladro eléctrico). Y todo gracias a cambios menores en la textura de la imagen de destino (
4b ).
Para un sistema de reconocimiento de objetos, dicho algoritmo malicioso es un serio adversario. Pero el hombre no es una máquina; ve y piensa de manera diferente. En esta prueba, antes de los sujetos había imágenes de objetos tridimensionales en los que había cambios de textura descritos anteriormente desde tres ángulos. Los sujetos también recibieron la calificación correcta y errónea. Tenían que determinar qué etiquetas son correctas, cuáles no y por qué, es decir si los sujetos de prueba ven cambios de textura en las imágenes.
Como resultado, el 83% de los sujetos completaron con éxito la tarea.
Para un conocimiento más detallado de los matices del estudio, le recomiendo que consulte el
informe de los científicos .
Y en
este enlace encontrará los archivos de imagen, datos y código que se utilizaron en el estudio.
Epílogo
El trabajo realizado dio a los científicos la oportunidad de llegar a una conclusión simple y bastante obvia: la intuición humana puede ser una fuente de datos muy importantes y una herramienta para tomar la decisión y / o percepción correcta de la información. Una persona puede comprender intuitivamente cómo se comportará el sistema de reconocimiento de objetos, qué etiquetas elegirá y por qué.
Las razones por las cuales es más fácil para una persona ver una imagen real y reconocerla correctamente varias. El más obvio es el método de obtención de información: la máquina recibe una imagen en forma digital y una persona la ve con sus propios ojos. Para una máquina, una imagen es un conjunto de datos que realiza cambios en los cuales puede distorsionar su clasificación. Para nosotros, la imagen de un tren de metro siempre será un tren de metro, no una lata de leche, porque lo vemos.
Los científicos también enfatizan que tales pruebas son difíciles de evaluar, porque una persona no es una máquina y una máquina no es una persona. Por ejemplo, los investigadores están hablando de la prueba con una "rosquilla" y una "rueda". Estas imágenes son similares a la "rosquilla" y la "rueda", porque el sistema de reconocimiento las clasifica de esa manera. Una persona ve que se ven como una "rosquilla" y una "rueda", pero no lo son. Esta es la diferencia fundamental en la percepción de la información visual entre una persona y un programa.
Gracias por su atención, sigan curiosos y tengan una buena semana laboral, muchachos.
Gracias por quedarte con nosotros. ¿Te gustan nuestros artículos? ¿Quieres ver más materiales interesantes?
Apóyenos haciendo un pedido o recomendándolo a sus amigos, un
descuento del 30% para los usuarios de Habr en un análogo único de servidores de nivel de entrada que inventamos para usted: toda la verdad sobre VPS (KVM) E5-2650 v4 (6 núcleos) 10GB DDR4 240GB SSD 1Gbps de $ 20 o cómo dividir el servidor? (las opciones están disponibles con RAID1 y RAID10, hasta 24 núcleos y hasta 40GB DDR4).
VPS (KVM) E5-2650 v4 (6 núcleos) 10GB DDR4 240GB SSD 1Gbps hasta el verano de forma gratuita al pagar por un período de seis meses, puede ordenar
aquí .
Dell R730xd 2 veces más barato? ¡Solo tenemos
2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV desde $ 249 en los Países Bajos y los Estados Unidos! Lea sobre
Cómo construir un edificio de infraestructura. clase utilizando servidores Dell R730xd E5-2650 v4 que cuestan 9,000 euros por un centavo?