¿Qué puede hacer que una gran empresa como Lamoda con un proceso simplificado y docenas de servicios interconectados cambie significativamente el enfoque? La motivación puede ser completamente diferente: desde el legislativo hasta el deseo inherente a todos los programadores de experimentar.
Pero esto no significa en absoluto que uno no pueda contar con beneficios adicionales. Sergey Zaika (
fewald ) dirá qué se puede ganar exactamente si implementa la API basada en eventos en Kafka. Sobre golpes y descubrimientos interesantes, también habrá, sin duda, un experimento no puede prescindir de ellos.
 Descargo de responsabilidad: este artículo se basa en los materiales del mitap que Sergey realizó en noviembre de 2018 en HighLoad ++. La experiencia en vivo de Lamoda con Kafka atrajo a los oyentes no menos que otros informes de horarios. Nos parece que este es un gran ejemplo del hecho de que siempre es posible y necesario encontrar personas con ideas afines, y los organizadores de HighLoad ++ continuarán tratando de crear una atmósfera propicia para esto.
Descargo de responsabilidad: este artículo se basa en los materiales del mitap que Sergey realizó en noviembre de 2018 en HighLoad ++. La experiencia en vivo de Lamoda con Kafka atrajo a los oyentes no menos que otros informes de horarios. Nos parece que este es un gran ejemplo del hecho de que siempre es posible y necesario encontrar personas con ideas afines, y los organizadores de HighLoad ++ continuarán tratando de crear una atmósfera propicia para esto.Sobre el proceso
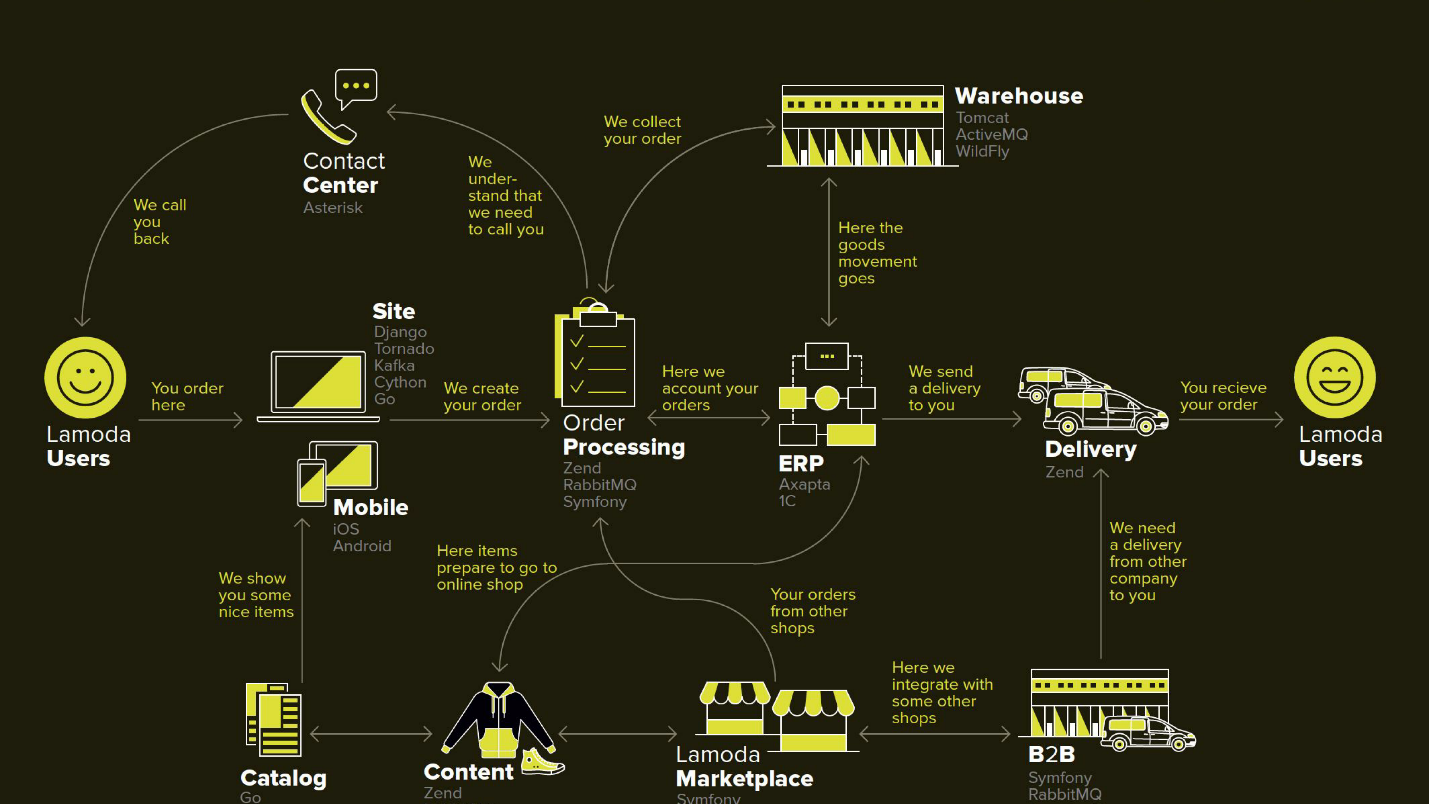
Lamoda es una gran plataforma de comercio electrónico que tiene su propio centro de contacto, servicio de entrega (y muchos afiliados), un estudio fotográfico, un gran almacén y todo funciona en su software. Hay docenas de métodos de pago, socios B2B que pueden usar parte o la totalidad de estos servicios y desean conocer la información más reciente sobre sus productos. Además, Lamoda opera en tres países además de la Federación de Rusia y allí todo es un poco diferente. En total, probablemente haya más de cien formas de configurar un nuevo pedido, que deben procesarse a su manera. Todo esto funciona con la ayuda de docenas de servicios que a veces se comunican de manera no obvia. También hay un sistema central cuya responsabilidad principal es el estado de los pedidos. La llamamos BOB, yo trabajo con ella.
Herramienta de reembolso con API controlada por eventos
La palabra impulsada por eventos es bastante trillada, un poco más adelante definiremos con más detalle lo que significa esto. Comenzaré con el contexto en el que decidimos probar el enfoque de API basado en eventos de Kafka.

En cualquier tienda, además de los pedidos por los que pagan los clientes, hay ocasiones en que la tienda debe devolver el dinero, porque el producto no se ajusta al cliente. Este proceso relativamente corto: aclaramos la información, si es necesario, y transferimos el dinero.
Pero el retorno fue complicado debido a cambios en la legislación, y tuvimos que implementar un microservicio separado para ello.

Nuestra motivación:
- Ley FZ-54 : brevemente, la ley requiere que informe a la oficina de impuestos sobre cada transacción monetaria, ya sea un reembolso o recibo, en un SLA bastante corto en unos minutos. Nosotros, como comercio electrónico, llevamos a cabo bastantes operaciones. Técnicamente, esto significa una nueva responsabilidad (y, por lo tanto, un nuevo servicio) y mejoras en todos los sistemas involucrados.
- División de BOB : el proyecto interno de la compañía para librar a BOB de una gran cantidad de responsabilidades no esenciales y reducir su complejidad general.

Este diagrama representa los principales sistemas de Lamoda. Ahora la mayoría de ellos son más como una
constelación de 5-10 microservicios alrededor de un monolito decreciente . Están creciendo lentamente, pero estamos tratando de hacerlos más pequeños, porque da miedo desplegar el fragmento resaltado en el medio; no se puede permitir que caiga. Todos los intercambios (flechas) nos obligan a reservar y basarnos en el hecho de que alguno de ellos puede no estar disponible.
También hay bastantes intercambios en BOB: pago, entrega, sistemas de notificación, etc.
Técnicamente, BOB es:
- ~ 150k líneas de código + ~ 100k líneas de pruebas;
- php7.2 + Zend 1 y Symfony Components 3;
- > 100 API y ~ 50 integraciones salientes;
- 4 países con su propia lógica de negocios.
La implementación de BOB es costosa y dolorosa, la cantidad de código y las tareas que resuelve es tal que nadie puede pensarlo. En general, hay muchas razones para simplificarlo.
Proceso de devolución
Inicialmente, hay dos sistemas involucrados en el proceso: BOB y Pago. Ahora aparecen dos más:
- Servicio de Fiscalización, que se ocupará de los problemas de fiscalización y comunicación con servicios externos.
- Herramienta de reembolso, en la que simplemente se toman nuevos intercambios para no inflar el BOB.
Ahora el proceso se ve así:
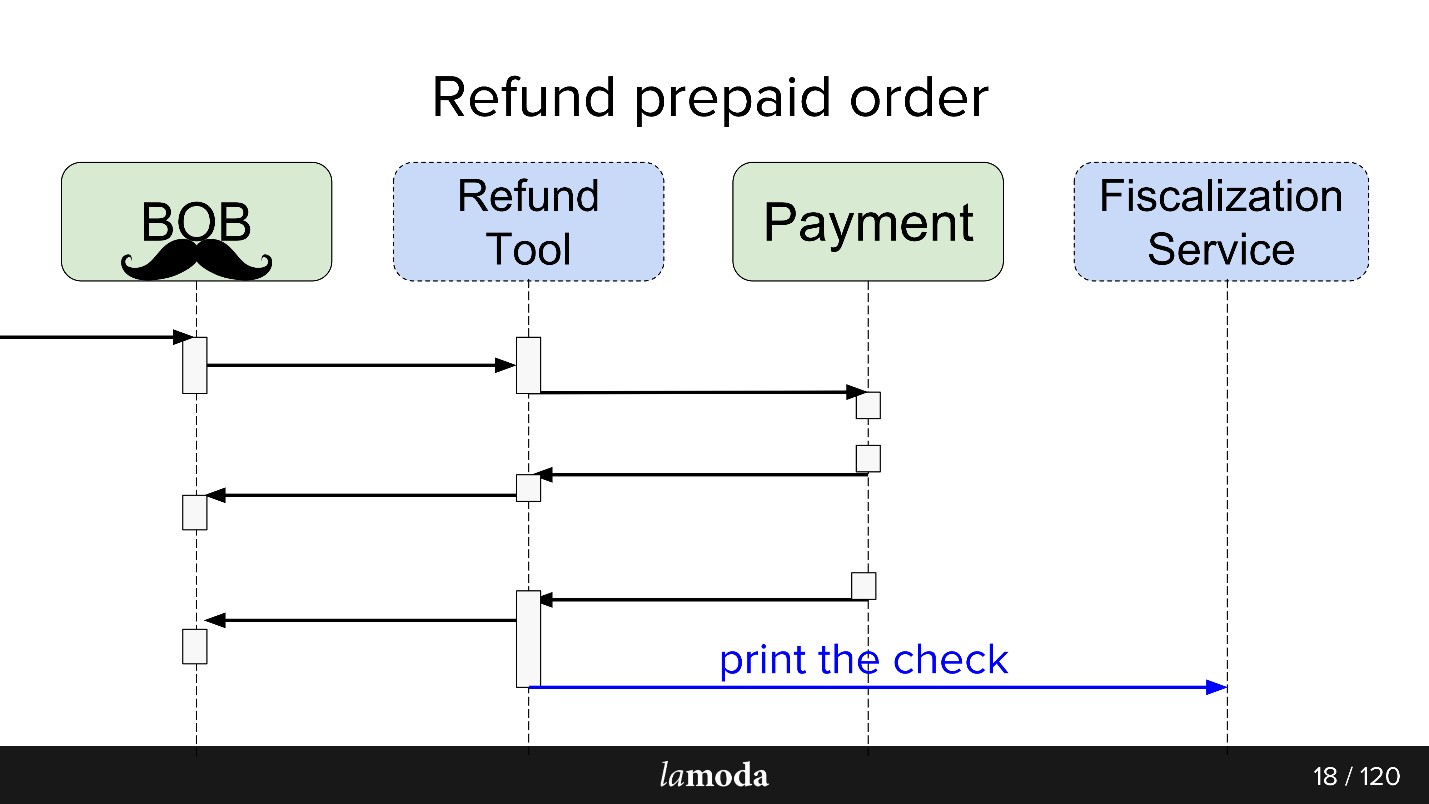
- BOB recibe una solicitud de reembolso.
- BOB habla sobre esta herramienta de reembolso.
- La herramienta de reembolso dice Pago: "Recupere el dinero".
- El pago devuelve el dinero.
- La herramienta de reembolso y BOB sincronizan los estados entre sí, porque por ahora ambos lo necesitan. Todavía no estamos listos para cambiar por completo a la Herramienta de reembolso, ya que BOB tiene una interfaz de usuario, informes para contabilidad y, en general, una gran cantidad de datos que no puede transferir fácilmente. Tenemos que sentarnos en dos sillas.
- La solicitud de fiscalización se va.
Como resultado, hicimos una especie de autobús de eventos en Kafka, un autobús de eventos, en el que todo comenzó. Hurra, ahora tenemos un único punto de falla (sarcasmo).

Los pros y los contras son bastante obvios. Hicimos un autobús, por lo que ahora todos los servicios dependen de él. Esto simplifica el diseño, pero introduce un único punto de falla en el sistema. Kafka caerá, el proceso se levantará.
¿Qué es una API controlada por eventos?
Una buena respuesta a esta pregunta está en el informe de Martin Fowler (GOTO 2017)
"Los muchos significados de la arquitectura dirigida por eventos" .
Brevemente, lo que hicimos:
- Envuelto todos los intercambios asincrónicos a través del almacenamiento de eventos . En lugar de informar a cada consumidor interesado sobre el cambio de estado a través de la red, escribimos un evento de cambio de estado en el repositorio centralizado, y los consumidores interesados en el tema leen todo lo que aparece a partir de ahí.
- Un evento en este caso es una notificación ( notificaciones ) de que algo ha cambiado en alguna parte. Por ejemplo, el estado del pedido ha cambiado. Un consumidor que esté interesado en algún tipo de información que acompañe el cambio de estado y que no esté en la notificación puede averiguarlo por sí mismo.
- La opción máxima es un abastecimiento de eventos completo, transferencia de estado , en cuyo evento contiene toda la información necesaria para el procesamiento: desde dónde y a qué estado cambió, cómo cambiaron exactamente los datos, etc. La única pregunta es si vale la pena y cuánta información puede permitirse almacenar.
Como parte del lanzamiento de la herramienta de reembolso, utilizamos la tercera opción. Esto simplificó el procesamiento de eventos, ya que no era necesario obtener información detallada, además excluyó el escenario cuando cada nuevo evento genera una oleada de aclaración de las solicitudes de obtención de los consumidores.
El servicio de la herramienta de reembolso
no está
cargado , por lo que Kafka es más una prueba de lápiz que una necesidad. No creo que si el servicio de reembolso se convirtiera en un proyecto de gran carga, la empresa estaría feliz.
Intercambio asíncrono TAL CUAL
Para los intercambios asincrónicos, el departamento de PHP generalmente usa RabbitMQ. Recopilamos los datos para la solicitud, los pusimos en la cola y el consumidor del mismo servicio los leyó y los envió (o no los envió). Para la API en sí, Lamoda usa Swagger activamente. Diseñamos la API, la describimos en Swagger, generamos código de cliente y servidor. También utilizamos un JSON RPC 2.0 ligeramente avanzado.
Aquí y allá, se utilizan autobuses esb, alguien vive en activeMQ, pero, en general,
RabbitMQ es el estándar .
Intercambio asincrónico SER
Al diseñar un intercambio a través del bus de eventos, se rastrea una analogía. De manera similar, describimos el intercambio futuro de datos a través de descripciones de estructura de eventos. El formato yaml, la generación del código tenía que ser realizada por nosotros mismos, el generador crea el DTO de acuerdo con las especificaciones y enseña a los clientes y servidores cómo trabajar con ellos. La generación va a dos idiomas:
golang y php . Esto mantiene las bibliotecas consistentes. El generador está escrito en golang, por lo que recibió el nombre de gogi.
El abastecimiento de eventos en Kafka es algo típico. Hay una solución de la versión empresarial principal de Kafka Confluent, hay
nakadi , una solución de nuestros "hermanos" en el área de dominio de Zalando. Nuestra
motivación para comenzar con Kafka vainilla es dejar la solución libre hasta que finalmente decidamos si usarla en todas partes, y también dejar espacio para maniobras y mejoras: queremos soporte para nuestro
JSON RPC 2.0 , generadores para dos idiomas, y ver qué más.
Es irónico que incluso en un caso tan feliz, cuando hay un negocio similar a Zalando, que tomó una decisión similar, no podemos usarlo de manera efectiva.
Arquitectónicamente, en el inicio, el patrón es el siguiente: lee directamente de Kafka, pero escribe solo a través del bus de eventos. Hay muchas cosas listas para leer en Kafka: corredores, equilibradores y está más o menos listo para el escalado horizontal, quería mantenerlo. El registro, queríamos pasar a través de un Gateway, también conocido como Events-bus, y es por eso.
Bus de eventos
O un autobús de eventos. Esta es solo una puerta de enlace http sin estado que asume varios roles importantes:
- Validación de la producción : verificamos que los eventos cumplan con nuestras especificaciones.
- Un sistema maestro de eventos , es decir, es el sistema principal y único en la empresa que responde a la pregunta de qué eventos con qué estructuras se consideran válidas. La validación simplemente incluye tipos de datos y enumeraciones para una especificación estricta del contenido.
- La función hash para fragmentar: la estructura del mensaje de Kafka es clave-valor, y aquí se calcula mediante la clave hash desde donde colocarla.
Porque
Trabajamos en una gran empresa con un proceso simplificado. ¿Por qué cambiar algo?
Este es un experimento y esperamos obtener varios beneficios.
1: n + 1 intercambios (uno a muchos)
Con Kafka, es muy fácil conectar nuevos consumidores a la API.
Suponga que tiene un directorio que debe mantenerse actualizado en varios sistemas a la vez (y en algunos nuevos). Anteriormente, inventamos un paquete que implementaba un conjunto de API, y las direcciones de los consumidores se informaban al sistema maestro. Ahora el sistema maestro envía actualizaciones al tema y a todos los que estén interesados en leer. Ha aparecido un nuevo sistema: lo firmaron sobre el tema. Sí, también paquete, pero más simple.
En el caso de la herramienta de reembolso, que es una pieza de BOB, nos conviene mantenerlos sincronizados a través de Kafka. El pago dice que devolvieron el dinero: BOB, RT lo descubrieron, cambiaron su estado, el Servicio de Fiscalización lo descubrió y noqueó un cheque.

Tenemos planes de hacer un único Servicio de notificaciones, que notificaría al cliente sobre las novedades en su pedido / devoluciones. Ahora esta responsabilidad se reparte entre los sistemas. Será suficiente para nosotros enseñarle al Servicio de Notificaciones a capturar y responder a la información relevante de Kafka (y deshabilitar estas notificaciones en otros sistemas). No se requerirán nuevos intercambios directos.
Datos impulsados
La información entre sistemas se vuelve transparente, no importa cuán sangrienta empresa tenga y cuán hinchada sea su cartera de pedidos. Lamoda tiene un departamento de análisis de datos que recopila datos en sistemas y los pone en una forma reutilizable, tanto para negocios como para sistemas inteligentes. Kafka le permite darles rápidamente una gran cantidad de datos y mantener esta información actualizada.
Registro de replicación
Los mensajes no desaparecen después de leer, como en RabbitMQ. Cuando el evento contiene suficiente información para procesar, tenemos un historial de cambios recientes en el objeto y, si lo desea, la capacidad de aplicar estos cambios.
El período de almacenamiento del registro de replicación depende de la intensidad de la escritura de este tema. Kafka le permite establecer límites flexibles en el tiempo de almacenamiento y el volumen de datos. Para temas intensivos, es importante que todos los consumidores tengan tiempo de leer la información antes de que desaparezca, incluso en el caso de inoperancia a corto plazo. Por lo general, resulta almacenar datos para
unidades de días , lo cual es suficiente para el soporte.
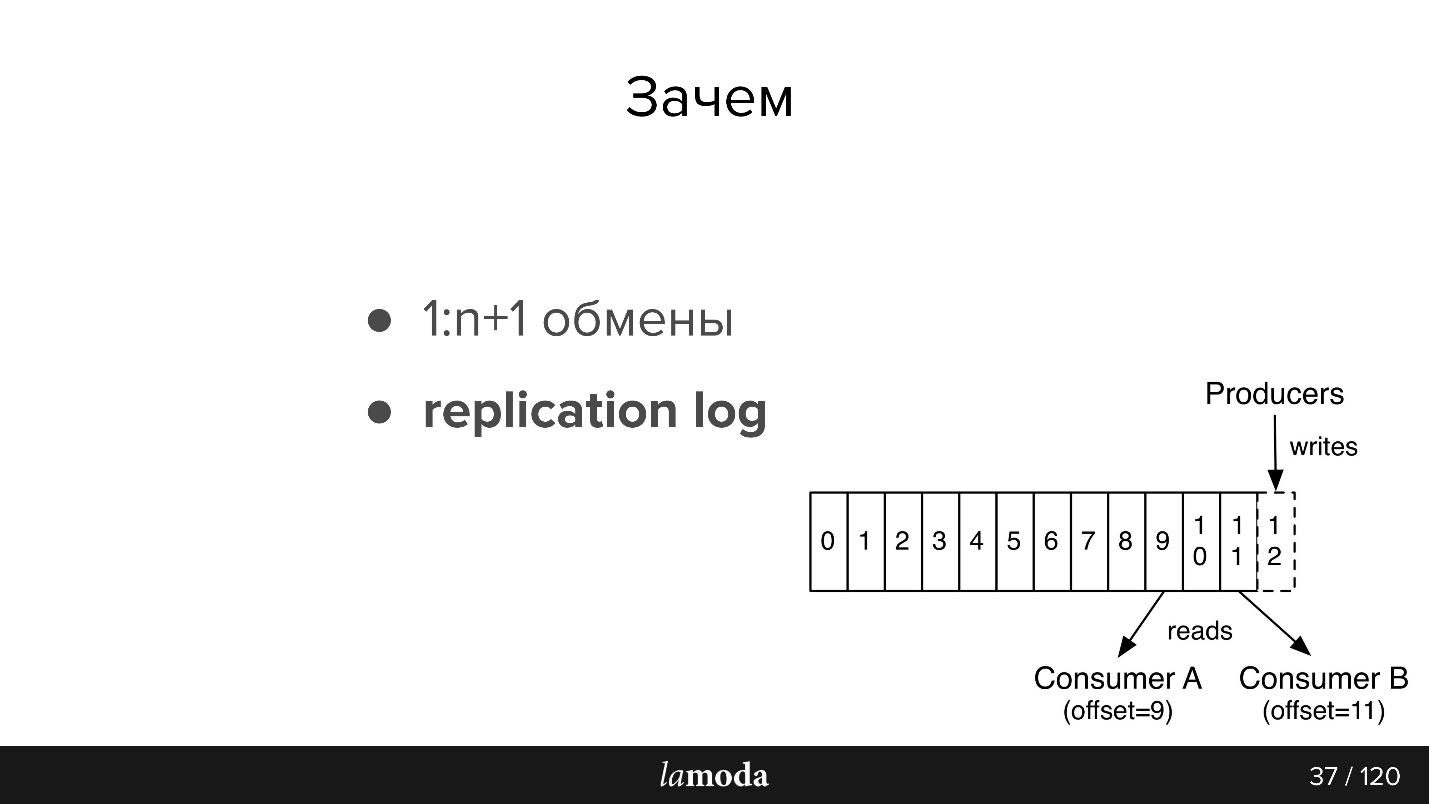
Luego un pequeño recuento de la documentación, para aquellos que no están familiarizados con Kafka (la imagen también es de la documentación)
Hay colas en AMQP: escribimos mensajes en la cola para el consumidor. Como regla, una cola es procesada por un sistema con la misma lógica de negocios. Si necesita notificar a varios sistemas, puede enseñar a la aplicación a escribir en varias colas o configurar el intercambio con el mecanismo de despliegue, que a su vez los clona.
Kafka tiene un
tema de abstracción similar en el que escribes mensajes, pero no desaparecen después de leer. De manera predeterminada, cuando se conecta a Kafka, recibe todos los mensajes y, al mismo tiempo, existe la oportunidad de guardar el lugar donde lo dejó. Es decir, si lee de forma secuencial, no puede marcar el mensaje como leído, pero guarda la identificación, de la que luego continúa leyendo. La identificación en la que se está deteniendo se llama desplazamiento, y el mecanismo es confirmación de desplazamiento.
En consecuencia, se puede implementar una lógica diferente. Por ejemplo, tenemos BOB en 4 instancias para diferentes países: Lamoda está en Rusia, Kazajstán, Ucrania, Bielorrusia. Como se implementan por separado, tienen un poco sus propias configuraciones y su propia lógica de negocios. En el mensaje indicamos a qué país se refiere. Cada consumidor de BOB en cada país lee con un ID de grupo diferente, y si el mensaje no se aplica a él, omítalo, es decir comprometer inmediatamente el desplazamiento +1. Si nuestro Servicio de pagos lee el mismo tema, lo hace con un grupo separado y, por lo tanto, la compensación no se superpone.
Requisitos del evento:- Integridad de los datos. Desearía que hubiera suficientes datos en el evento para que pudieran procesarse.
- Integridad Delegamos el bus de eventos para verificar que el evento sea consistente y que pueda manejarlo.
- El orden es importante. En el caso de un retorno, nos vemos obligados a trabajar con la historia. Con las notificaciones, el orden no es importante, si son notificaciones homogéneas, el correo electrónico será el mismo sin importar qué orden llegó primero. En el caso de una devolución, hay un proceso claro, si cambia el pedido, habrá excepciones, el reembolso no se creará ni procesará; terminaremos en un estado diferente.
- Coherencia Tenemos un repositorio y ahora, en lugar de la API, creamos eventos. Necesitamos una forma de transferir de manera rápida y económica información sobre nuevos eventos y cambios a los existentes a nuestros servicios. Esto se logra utilizando una especificación común en un repositorio git separado y generadores de código. Por lo tanto, los clientes y servidores en diferentes servicios están coordinados con nosotros.
Kafka en Lamoda
Tenemos tres instalaciones de Kafka:
- Registros
- I + D;
- Eventos-bus.
Hoy solo estamos hablando del último punto. En eventos-bus, no tenemos instalaciones muy grandes: 3 corredores (servidores) y un total de 27 temas. Como regla general, un tema es un proceso. Pero este es un momento delicado, y ahora lo tocaremos.
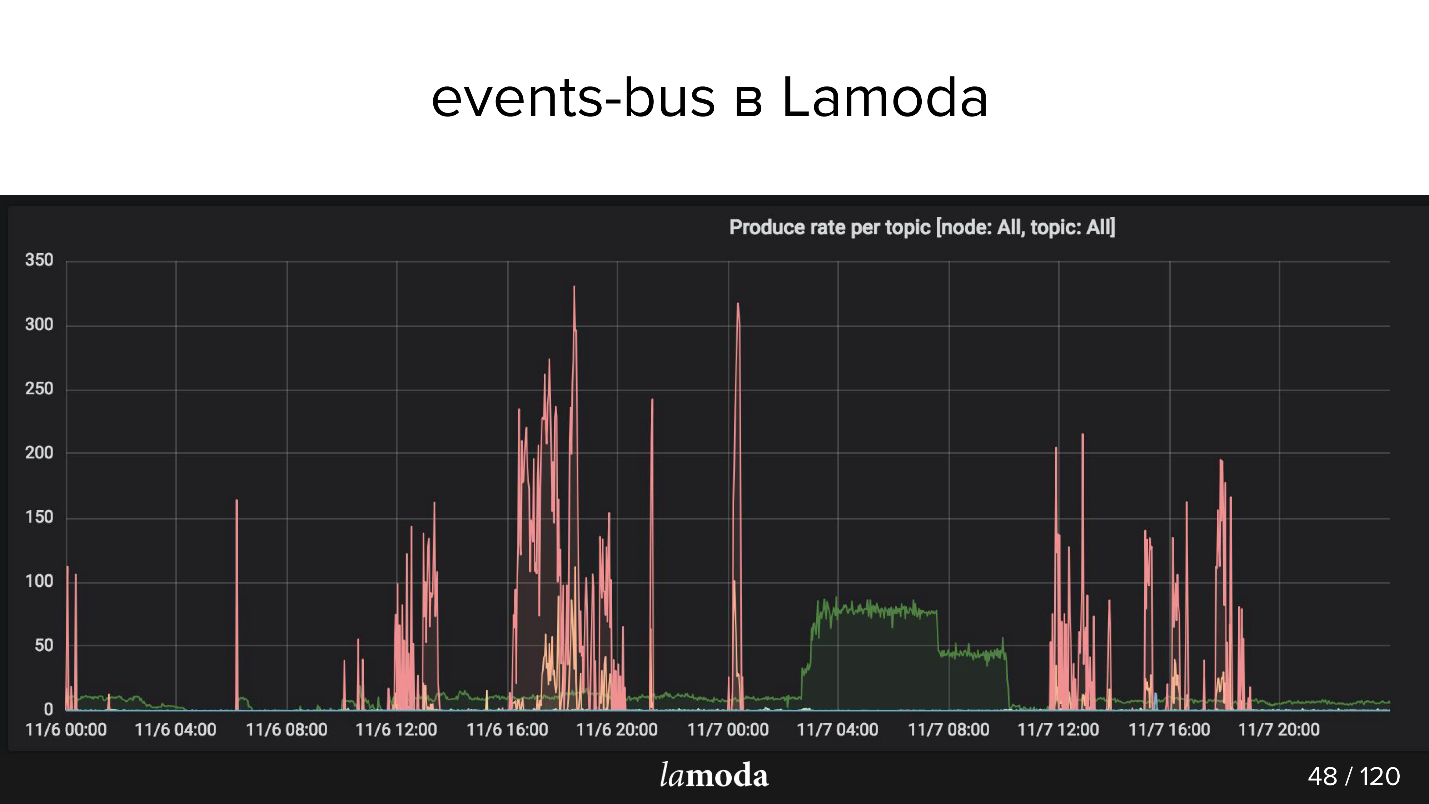
Arriba está el gráfico rps. El proceso de reembolso está marcado con una línea turquesa (sí, la que se encuentra en el eje X), y rosa es el proceso de actualización de contenido.
El catálogo de Lamoda contiene millones de productos, con datos que se actualizan todo el tiempo. Algunas colecciones pasan de moda, se lanzan nuevas en lugar de ellas, constantemente aparecen nuevos modelos en el catálogo. Intentamos predecir lo que será interesante para nuestros clientes mañana, por lo que constantemente compramos cosas nuevas, las fotografiamos y actualizamos la ventana.
Los picos rosados son una actualización del producto, es decir, cambios en los productos. Se puede ver que los chicos tomaron fotos, tomaron fotos, ¡y luego otra vez! - Descargó un paquete de eventos.
Casos de uso de Lamoda Events
Utilizamos la arquitectura construida para tales operaciones:
- Seguimiento de estados de retorno : llamado a la acción y seguimiento de estados de todos los sistemas involucrados. Pago, estados, fiscalización, notificaciones. Aquí probamos el enfoque, creamos las herramientas, recopilamos todos los errores, escribimos la documentación y les dijimos a los colegas cómo usarla.
- Actualización de tarjetas de producto: configuración, metadatos, características. Un sistema lee (que se muestra) y varios escriben.
- Correo electrónico, push y sms : el pedido se recoge, el pedido ha llegado, la devolución ha sido aceptada, etc., muchos de ellos.
- Stock, actualización de almacén : una actualización cuantitativa de los artículos, solo números: recibo en el almacén, devolución. Es necesario que todos los sistemas relacionados con la reserva de bienes operen con los datos más relevantes. Ahora el sistema de actualización de drenaje es bastante complicado, Kafka lo simplificará.
- Análisis de datos (departamento de I + D), herramientas ML, análisis, estadísticas. Queremos que la información sea transparente, para esto Kafka es muy adecuado.
Ahora, la parte más interesante es sobre conos rellenos y descubrimientos interesantes que tuvieron lugar durante seis meses.
Problemas de diseño
Supongamos que queremos hacer algo nuevo, por ejemplo, transferir todo el proceso de entrega a Kafka. Parte del proceso ahora se está implementando en el procesamiento de pedidos en BOB. Detrás de la transferencia del pedido al servicio de entrega, la transferencia a un almacén intermedio, etc., hay un modelo de estado. Hay un monolito completo, incluso dos, más un montón de API de entrega. Saben mucho más sobre la entrega.
Estas parecen ser áreas similares, pero para el procesamiento de pedidos en el BOB y para el sistema de entrega, los estados son diferentes. Por ejemplo, algunos servicios de mensajería no envían estados intermedios, sino solo estados finales: "entregados" o "perdidos". Otros, por el contrario, informan sobre el movimiento de mercancías con gran detalle. Todos tienen sus propias reglas de validación: para alguien, el correo electrónico es válido, por lo que se procesará; para otros, no es válido, pero el pedido aún se procesará porque hay un teléfono para la comunicación y alguien dirá que dicho pedido no se procesará en absoluto.
Flujo de datos
En el caso de Kafka, surge la cuestión de organizar el flujo de datos. Esta tarea está relacionada con la elección de la estrategia para varios puntos, los revisaremos todos.
En un tema o en diferente?
Tenemos una especificación de evento. En BOB, escribimos que dicho pedido debe entregarse e indicamos: el número de pedido, su composición, algunos códigos de barras y SKU, etc. Cuando los productos lleguen al almacén, la entrega podrá recibir estados, marcas de tiempo y todo lo que se necesita. Pero además queremos recibir actualizaciones sobre estos datos en BOB. Nos enfrentamos al proceso inverso de obtener datos de la entrega. ¿Es este el mismo evento? ¿O es un intercambio separado que merece un tema separado?
, , , — , , . .
?
, . , DTO, BOB. id, , , event-bus .
event-bus , , BOB . — .
— . , - , , , , . — . — , . JSON .
refunds . -, refund update, type, , update . «» , , type.
Kafka
Avro , Confluent. . replication log, «». , , : , . , , , .
partitions
Kafka partitions. , , , .
Kafka . partition, . . , , , . , , , Kafka partition, Kafka — , .
Kafka ? ( JSON) key. -, , partition .
refunds , partition, , . - , partition.
Events vs commands
, . Event — : , - - (something_happened), , item refund. - , «item » refund , « refund» - .
, , — , - . something_happened (item_canceled, refund_refunded), something_should_be_done. , item .
, , . , . , do_something. , - ; , ; , -, - . , do_something, , .

RabbitMQ, , http, response — , . Kafka, , Kafka, , , .
, - , - . , , - . , «item_ready_to_refund», , refund , , «money_refunded». , .
Matices
: , - , , .
, offset , .
, , . , events-bus, , PostgreSQL, MySQL UNSIGNED INT, PostgreSQL INT. , Id . Symfony . , , , , offset, , . , Symfony , offset.
- — , Kafka , . . .
Kafka tooling offset. , — , , redeployments. Kafka tooling offset, .
—
replication log vs rdkafka.so — . PHP, PHP, , , Kafka rdkafka.so, - . , , , - . , .
partitions,
consumers >= topic partitions . , . , partitions. , partition, 20 , , . , , partitions.
Monitoreo
, , , , .
, , , , , , . Kafka , . , .

, , , events-bus , . , Refund Tool , BOB - ( ).

consumer-group lag. , . , 0, . Kafka , .
Burrow , Kafka. API consumer-group , . Failed warning, , — , . , .
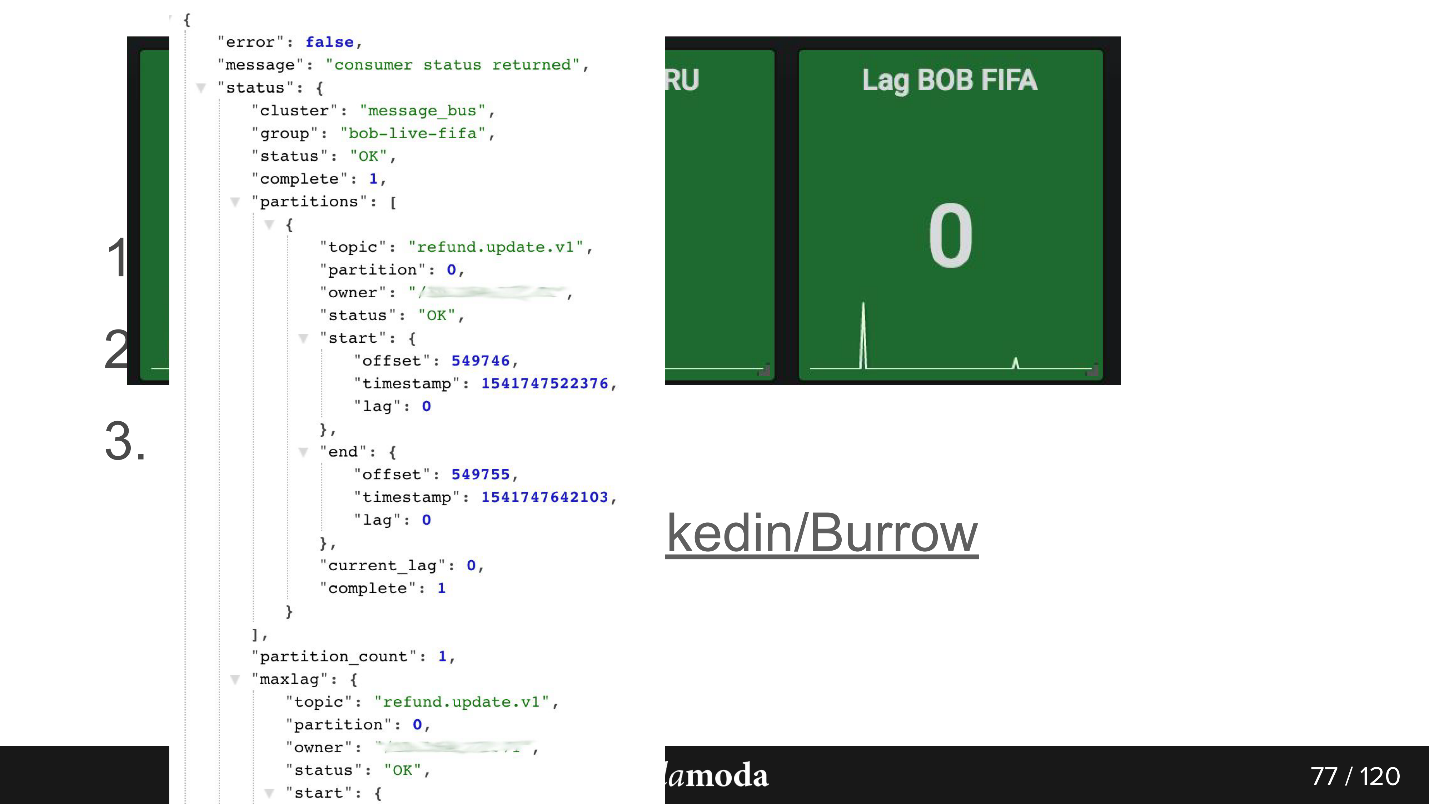
API. bob-live-fifa, partition refund.update.v1, , lag 0 — offset -.
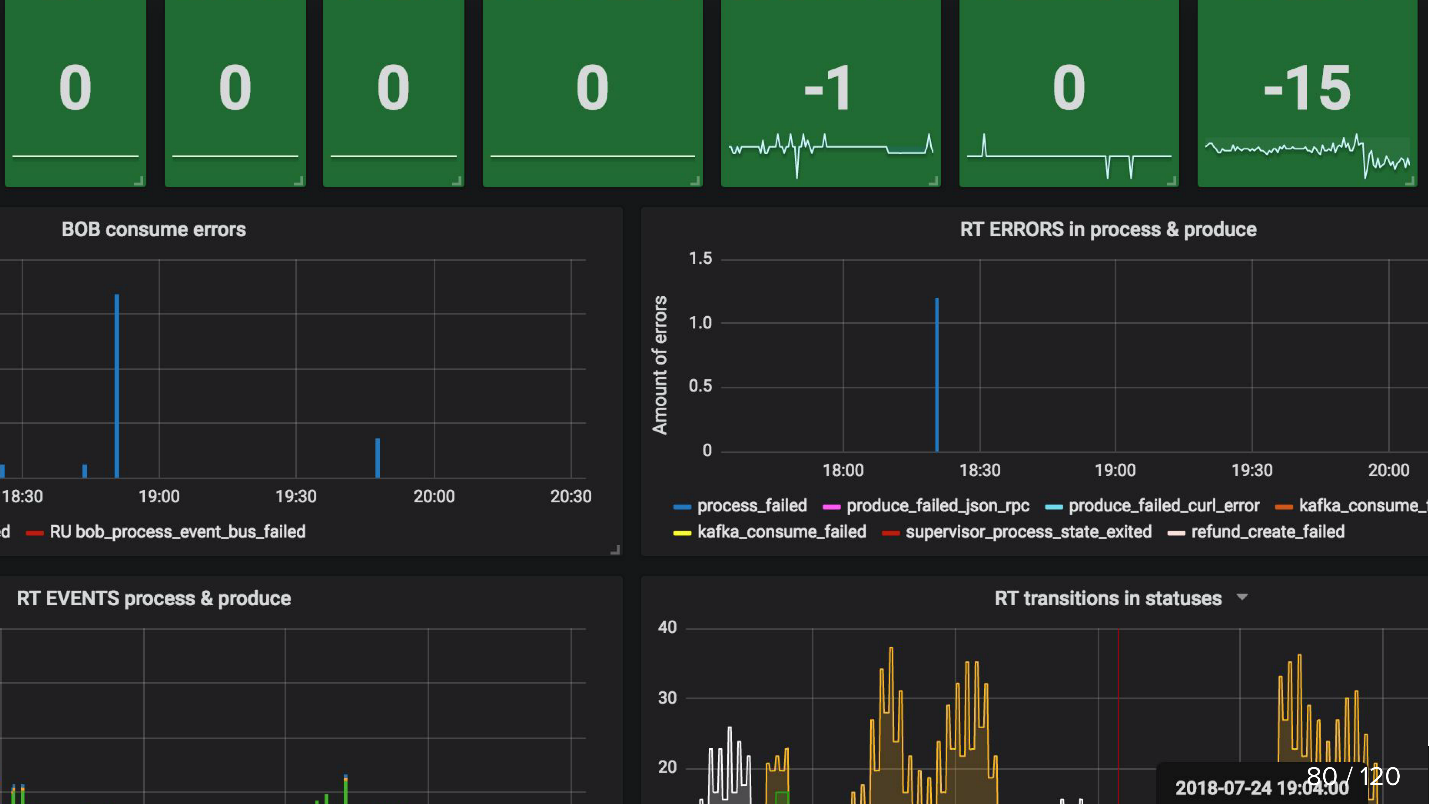 updated_at SLA (stuck)
updated_at SLA (stuck) . , , . Cron, , 5 refund ( ), - , . Cron, , 0, .
, , :
, — API Kafka, .
-, HighLoad++ , , .
-, KnowledgeConf . , 26 , .
PHP Russia ++ ( DevOpsConf ) — , .