La semana pasada, escribí un artículo sobre la inutilidad de la plantilla del Repositorio para entidades Eloquentes , pero prometí decir cómo usarla parcialmente con beneficio. Para hacer esto, intentaré analizar cómo esta plantilla se usa generalmente en proyectos. El conjunto mínimo requerido de métodos para el repositorio:
<?php interface PostRepository { public function getById($id): Post; public function save(Post $post); public function delete($id); }
Sin embargo, en proyectos reales, si se decidió usar repositorios, a menudo agregan métodos para seleccionar registros:
<?php interface PostRepository { public function getById($id): Post; public function save(Post $post); public function delete($id); public function getLastPosts(); public function getTopPosts(); public function getUserPosts($userId); }
Estos métodos podrían implementarse a través de ámbitos Eloquent, pero sobrecargar las clases de entidad con responsabilidades para obtener ellos mismos no es una buena idea y poner esta responsabilidad en las clases de repositorio parece lógico. Es asi? Particularmente visualmente dividí esta interfaz en dos partes. La primera parte de los métodos se utilizará en operaciones de escritura.
Las operaciones de escritura estándar son:
- construyendo un nuevo objeto y llamando a PostRepository :: save
- PostRepository :: getById , manipulación de entidades y llamada PostRepository :: save
- llame al PostRepository :: eliminar
No hay métodos de muestreo en las operaciones de escritura. En las operaciones de lectura, solo se utilizan los métodos get *. Si lee sobre el Principio de segregación de interfaz (letra I en SOLID ), quedará claro que nuestra interfaz es demasiado grande y cumple al menos dos responsabilidades diferentes. Es hora de dividirlo en dos. El método getById se requiere en ambos, pero si la aplicación se vuelve más complicada, su implementación será diferente. Esto lo veremos un poco más tarde. Escribí sobre la inutilidad de la parte de escritura en un artículo anterior, así que en esto simplemente me olvido de eso.
Leer la parte me parece no tan inútil, porque incluso para Eloquent puede haber varias implementaciones. ¿Cómo nombrar una clase? Puede ReadPostRepository , pero ya tiene poca relación con la plantilla Repository . Simplemente puede publicar PostQueries :
<?php interface PostQueries { public function getById($id): Post; public function getLastPosts(); public function getTopPosts(); public function getUserPosts($userId); }
Su implementación usando Eloquent es bastante simple:
<?php final class EloquentPostQueries implements PostQueries { public function getById($id): Post { return Post::findOrFail($id); } public function getLastPosts() { return Post::orderBy('created_at', 'desc') ->limit() ->get(); } public function getTopPosts() { return Post::orderBy('rating', 'desc') ->limit() ->get(); } public function getUserPosts($userId) { return Post::whereUserId($userId) ->orderBy('created_at', 'desc') ->get(); } }
La interfaz debe estar asociada con la implementación, por ejemplo en AppServiceProvider :
<?php final class AppServiceProvider extends ServiceProvider { public function register() { $this->app->bind(PostQueries::class, EloquentPostQueries::class); } }
Esta clase ya es útil. Se da cuenta de su responsabilidad descargando controladores o una clase de entidad. En el controlador, se puede usar así:
<?php final class PostsController extends Controller { public function lastPosts(PostQueries $postQueries) { return view('posts.last', [ 'posts' => $postQueries->getLastPosts(), ]); } }
El método PostsController :: lastPosts simplemente se pregunta por alguna implementación de PostsQueries y funciona con él. En el proveedor, asociamos PostQueries con la clase EloquentPostQueries y esta clase se sustituirá en el controlador.
Imaginemos que nuestra aplicación se ha vuelto muy popular. Miles de usuarios por minuto abren la página con las últimas publicaciones. Las publicaciones más populares también se leen muy a menudo. Las bases de datos no manejan muy bien tales cargas, por lo tanto, utilizan la solución estándar: caché. Además de la base de datos, un cierto nugget de datos se almacena en un repositorio optimizado para ciertas operaciones: memcached o redis .
La lógica de almacenamiento en caché generalmente no es tan complicada, pero implementarla en EloquentPostQueries no es muy correcta (al menos debido al Principio de responsabilidad única ). Es mucho más natural usar la plantilla Decorator e implementar el almacenamiento en caché como decoración de la acción principal:
<?php use Illuminate\Contracts\Cache\Repository; final class CachedPostQueries implements PostQueries { const LASTS_DURATION = 10; private $base; private $cache; public function __construct( PostQueries $base, Repository $cache) { $this->base = $base; $this->cache = $cache; } public function getLastPosts() { return $this->cache->remember('last_posts', self::LASTS_DURATION, function(){ return $this->base->getLastPosts(); }); }
Ignora la interfaz del repositorio en el constructor. Por alguna razón, decidieron llamar a la interfaz para el almacenamiento en caché en Laravel.
La clase CachedPostQueries implementa solo el almacenamiento en caché. $ this-> cache-> recordar comprueba para ver si la entrada dada está en el caché y si no, llama a la devolución de llamada y escribe el valor devuelto en el caché. Solo queda implementar esta clase en la aplicación. Necesitamos todas las clases que en la aplicación soliciten la implementación de la interfaz PostQueries para recibir una instancia de la clase CachedPostQueries . Sin embargo, CachedPostQueries debería recibir la clase EloquentPostQueries como parámetro en el constructor, ya que no puede funcionar sin una implementación "real". Cambiar AppServiceProvider :
<?php final class AppServiceProvider extends ServiceProvider { public function register() { $this->app->bind(PostQueries::class, CachedPostQueries::class); $this->app->when(CachedPostQueries::class) ->needs(PostQueries::class) ->give(EloquentPostQueries::class); } }
Todos mis deseos se describen de forma natural en el proveedor. Por lo tanto, implementamos el almacenamiento en caché para nuestras solicitudes solo escribiendo una clase y cambiando la configuración del contenedor. El código para el resto de la aplicación no ha cambiado.
Por supuesto, para la implementación completa del almacenamiento en caché, aún es necesario implementar la invalidación para que el artículo eliminado no se cuelgue en el sitio por más tiempo, sino que se vaya de inmediato (recientemente escribió un artículo sobre almacenamiento en caché , puede ayudar en detalles).
En pocas palabras: utilizamos no uno, sino dos patrones completos. La plantilla de segregación de responsabilidad de consulta de comando (CQRS) ofrece una separación completa de las operaciones de lectura y escritura en el nivel de la interfaz. Llegué a él a través del Principio de segregación de interfaz , lo que significa que manipulo hábilmente plantillas y principios y deduzco uno del otro como teorema :) Por supuesto, no todos los proyectos necesitan tal abstracción en las muestras de entidades, pero compartiré el enfoque con ustedes. En la etapa inicial del desarrollo de la aplicación, simplemente puede crear una clase PostQueries con una implementación regular a través de Eloquent:
<?php final class PostQueries { public function getById($id): Post { return Post::findOrFail($id); }
Cuando surja la necesidad de almacenar en caché, puede crear fácilmente una interfaz (o una clase abstracta) en lugar de esta clase PostQueries , copiar su implementación en la clase EloquentPostQueries e ir al esquema que describí anteriormente. El resto del código de la aplicación no necesita ser cambiado.
Sin embargo, sigue habiendo un problema con el uso de las mismas entidades Post que pueden modificar datos. Esto no es exactamente CQRS.

Nadie se molesta en obtener la entidad Post de PostQueries , modificarla y guardar los cambios con un simple -> save () . Y funcionará.
Después de un tiempo, el equipo cambiará a la replicación maestro-esclavo en la base de datos y PostQueries trabajará con réplicas de lectura. Las operaciones de escritura en las réplicas de lectura generalmente están bloqueadas. El error se abrirá, pero tendrá que trabajar duro para arreglar todas esas jambas.
La solución obvia es separar completamente las partes de lectura y escritura . Puede continuar usando Eloquent, pero creando una clase para modelos de solo lectura. Ejemplo: https://github.com/adelf/freelance-example/blob/master/app/ReadModels/ReadModel.php Todas las operaciones de modificación de datos están bloqueadas. Cree un nuevo modelo, por ejemplo, ReadPost (puede dejar Publicar , pero moverlo a otro espacio de nombres):
<?php final class ReadPost extends ReadModel { protected $table = 'posts'; } interface PostQueries { public function getById($id): ReadPost; }
Dichos modelos pueden ser de solo lectura y pueden almacenarse en caché de forma segura.
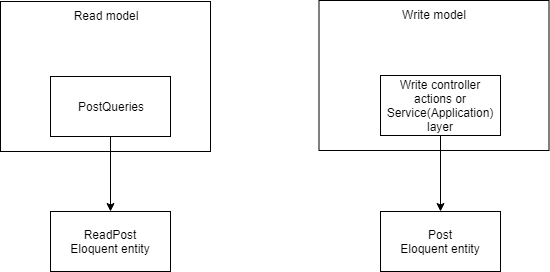
Otra opción: abandonar Eloquent. Puede haber varias razones para esto:
- Todos los campos de la tabla casi nunca son necesarios. Para la solicitud lastPosts , solo se requieren los campos id , title y, por ejemplo, updated_at . Solicitar algunos textos pesados de publicaciones solo dará una carga innecesaria en la base de datos o caché. Eloquent solo puede seleccionar los campos obligatorios, pero todo esto es muy implícito. Los clientes de PostQueries no saben exactamente qué campos se seleccionan sin entrar en la implementación.
- El almacenamiento en caché utiliza la serialización de forma predeterminada. Las clases elocuentes ocupan demasiado espacio en forma serializada. Si para entidades simples esto no es particularmente notable, entonces para entidades complejas con relaciones esto se convierte en un problema (¿cómo arrastrar objetos de un tamaño de megabyte desde el caché?). En un proyecto, una clase ordinaria con campos públicos en el caché ocupaba 10 veces menos espacio que la opción Eloquent (había muchas pequeñas subentidades). Puede almacenar en caché los atributos solo cuando se almacena en caché, pero esto complicará en gran medida el proceso.
Un ejemplo simple de cómo se vería esto:
<?php final class PostHeader { public int $id; public string $title; public DateTime $publishedAt; } final class Post { public int $id; public string $title; public string $text; public DateTime $publishedAt; } interface PostQueries { public function getById($id): Post; public function getLastPosts(); public function getTopPosts(); public function getUserPosts($userId); }
Por supuesto, todo esto parece una complicación excesiva de la lógica. "Toma los alcances elocuentes y todo estará bien. ¿Por qué inventar todo esto?" Para proyectos más simples, esto es correcto. No hay absolutamente ninguna necesidad de reinventar los ámbitos. Pero cuando el proyecto es grande y varios desarrolladores participan en el desarrollo, que a menudo cambian (se dan por vencidos y aparecen nuevos), las reglas del juego se vuelven ligeramente diferentes. El código debe estar protegido por escrito para que el nuevo desarrollador después de unos años no pueda hacer algo mal. Por supuesto, es imposible excluir por completo tal probabilidad, pero es necesario reducir su probabilidad. Además, esta es una descomposición común del sistema. Puede recopilar todos los decoradores y clases de almacenamiento en caché para invalidar la memoria caché en un cierto "módulo de almacenamiento en caché", guardando así el resto de la aplicación de información sobre almacenamiento en caché. Tuve que rebuscar en solicitudes grandes que estaban rodeadas de llamadas en caché. Se interpone en el camino. Especialmente si la lógica de almacenamiento en caché no es tan simple como se describe anteriormente.