TL; DR: Hace cuatro años, dejé Google con la idea de una nueva herramienta para monitorear servidores. La idea era combinar las funciones generalmente aisladas de
recopilar y analizar registros, recopilar métricas,
alertas y un tablero en un solo servicio. Uno de los principios: el servicio debe ser realmente
rápido , proporcionando a los desarrolladores un trabajo fácil, interactivo y agradable. Esto requiere procesar conjuntos de datos de varios gigabytes en una fracción de segundo, sin exceder el presupuesto. Las herramientas existentes para trabajar con registros son a menudo lentas y torpes, por lo que nos enfrentamos a una buena tarea: desarrollar correctamente una herramienta para dar a los usuarios nuevas sensaciones del trabajo.
Este artículo describe cómo en Scalyr resolvimos este problema aplicando los métodos de la vieja escuela, el enfoque de fuerza bruta, eliminando capas redundantes y evitando estructuras de datos complejas. Puede aplicar estas lecciones a sus propias tareas de ingeniería.
La fuerza de la vieja escuela.
El análisis de registros generalmente comienza con una búsqueda: encuentre todos los mensajes que coincidan con una plantilla determinada. En Scalyr, estos son decenas o cientos de gigabytes de registros de muchos servidores. Los enfoques modernos, como regla, implican la construcción de una estructura de datos compleja optimizada para la búsqueda. Por supuesto, vi esto en Google, donde son bastante buenos en tales cosas. Pero nos decidimos por un enfoque mucho más duro: escaneo lineal de registros. Y funcionó: proporcionamos una interfaz con búsqueda de un orden de magnitud más rápido que el de los competidores (vea la animación al final).
La idea clave es que los procesadores modernos son realmente muy rápidos en operaciones simples y directas. Esto se pasa por alto fácilmente en sistemas complejos de varias capas que dependen de la velocidad de E / S y las operaciones de red, y estos sistemas son muy comunes en la actualidad. Por lo tanto, hemos desarrollado un diseño que minimiza el número de capas y el exceso de basura. Con múltiples procesadores y servidores en paralelo, la velocidad de búsqueda alcanza 1 TB por segundo.
Hallazgos clave de este artículo:
- La búsqueda aproximada es un enfoque viable para resolver problemas reales a gran escala.
- La fuerza bruta es una técnica de diseño, no una liberación del trabajo. Como cualquier técnica, es más adecuada para algunos problemas que para otros, y puede implementarse mal o bien.
- La fuerza bruta es especialmente buena para un rendimiento estable .
- El uso efectivo de la fuerza bruta requiere la optimización del código y el uso oportuno de recursos suficientes. Es adecuado si sus servidores están sometidos a grandes cargas de trabajo de no usuarios y las operaciones de los usuarios siguen siendo una prioridad.
- El rendimiento depende del diseño de todo el sistema, y no solo del algoritmo de bucle interno.
(Este artículo describe cómo buscar datos en la memoria. En la mayoría de los casos, cuando un usuario busca registros, los servidores Scalyr ya los han almacenado en caché. En el siguiente artículo discutiremos la búsqueda de registros no almacenados en caché. Se aplican los mismos principios: código eficiente, método de fuerza bruta con gran cálculo computacional recursos).
Método de fuerza bruta
Tradicionalmente, una búsqueda en un gran conjunto de datos se realiza mediante un índice de palabras clave. Tal como se aplica a los registros del servidor, esto significa buscar cada palabra única en el registro. Para cada palabra, debe hacer una lista de todas las inclusiones. Esto hace que sea fácil encontrar todos los mensajes con esta palabra, por ejemplo, 'error', 'firefox' o 'transacción_16851951', solo busque en el índice.
Utilicé este enfoque en Google y funcionó bien. Pero en Scalyr, buscamos en los registros byte por byte.
Por qué Desde un punto de vista algorítmico abstracto, los índices de palabras clave son mucho más efectivos que una búsqueda cruda. Sin embargo, no vendemos algoritmos; vendemos rendimiento. Y el rendimiento no es solo algoritmos, sino también ingeniería de sistemas. Debemos considerar todo: la cantidad de datos, el tipo de búsqueda, el hardware disponible y el contexto del software. Decidimos que para nuestro problema particular, una opción como 'grep' es mejor que un índice.
Los índices son geniales, pero tienen limitaciones. Una palabra es fácil de encontrar. Pero encontrar mensajes con algunas palabras, como 'googlebot' y '404', ya es mucho más complicado. La búsqueda de frases como 'excepción no capturada' requiere un índice más engorroso que no solo registra todos los mensajes con esa palabra, sino también la ubicación específica de la palabra.
La verdadera dificultad viene cuando no estás buscando palabras. Suponga que quiere ver cuánto tráfico proviene de los bots. El primer pensamiento es buscar en los registros la palabra 'bot'. Encontrará algunos bots: Googlebot, Bingbot y muchos otros. Pero aquí 'bot' no es una palabra, sino parte de ella. Si buscamos 'bot' en el índice, no encontraremos mensajes con la palabra 'Googlebot'. Si revisa cada palabra en el índice y luego escanea el índice en busca de las palabras clave encontradas, la búsqueda se ralentizará considerablemente. Como resultado, algunos programas para trabajar con registros no permiten la búsqueda en partes de una palabra o (en el mejor de los casos) permiten el uso de sintaxis especial con menor rendimiento. Queremos evitar esto.
Otro problema es la puntuación. ¿Quiere encontrar todas las solicitudes de
50.168.29.7 ? ¿Qué pasa con la depuración de registros que contienen
[error] ? Los índices generalmente omiten la puntuación.
Finalmente, a los ingenieros les encantan las herramientas poderosas y, a veces, un problema solo se puede resolver con una expresión regular. El índice de palabras clave no es muy adecuado para esto.
Además, los índices
son complejos . Cada mensaje debe agregarse a varias listas de palabras clave. Estas listas siempre deben mantenerse en un formato fácil de buscar. Las consultas con frases, fragmentos de palabras o expresiones regulares deben traducirse en operaciones con múltiples listas, y los resultados escaneados y combinados para obtener un conjunto de resultados. En el contexto de un servicio multiusuario a gran escala, esta complejidad crea problemas de rendimiento que no son visibles al analizar los algoritmos.
Los índices de palabras clave también ocupan mucho espacio, y el almacenamiento es el elemento de costo principal en el sistema de gestión de registros.
Por otro lado, se puede gastar mucha potencia informática en cada búsqueda. Nuestros usuarios valoran las búsquedas de alta velocidad para consultas únicas, pero tales consultas son relativamente raras. Para consultas de búsqueda típicas, por ejemplo, para el panel de control, utilizamos técnicas especiales (las describiremos en el próximo artículo). Otras consultas son bastante raras, por lo que rara vez necesita procesar más de una a la vez. Pero esto no significa que nuestros servidores no estén ocupados: están ocupados con el trabajo de recibir, analizar y comprimir nuevos mensajes, evaluar alertas, comprimir datos antiguos, etc. Por lo tanto, tenemos un suministro bastante sustancial de procesadores que se pueden utilizar para cumplir con las solicitudes.
La fuerza bruta funciona si tienes un problema de fuerza bruta (y mucha fuerza)
La fuerza bruta funciona mejor en tareas simples con pequeños bucles internos. A menudo puede optimizar el bucle interno para trabajar a velocidades muy altas. Si el código es complejo, es mucho más difícil optimizarlo.
Inicialmente, nuestro código de búsqueda tenía un bucle interno bastante grande. Almacenamos mensajes en páginas 4K; cada página contiene algunos mensajes (en UTF-8) y metadatos para cada mensaje. Los metadatos son una estructura en la que se codifican la longitud del valor, la ID del mensaje interno y otros campos. El ciclo de búsqueda se veía así:

Esta es una opción simplificada en comparación con el código real. Pero incluso aquí puede ver varias ubicaciones de objetos, copias de datos y llamadas a funciones. La JVM optimiza bastante bien las llamadas a funciones y asigna objetos efímeros, por lo que este código funcionó mejor de lo que merecíamos. Durante las pruebas, los clientes lo usaron con bastante éxito. Pero al final nos mudamos a un nuevo nivel.
(Puede preguntar por qué almacenamos mensajes en este formato con páginas 4K, texto y metadatos, en lugar de trabajar directamente con los registros. Hay muchas razones por las cuales el motor interno Scalyr se parece más a una base de datos distribuida que sistema de archivos La búsqueda de texto a menudo se combina con filtros de estilo DBMS en los campos después del análisis de registros. Podemos buscar miles de registros al mismo tiempo, y los archivos de texto simples no son adecuados para nuestro control transaccional, replicado y distribuido. datos).
Inicialmente, parecía que dicho código no era muy adecuado para la optimización bajo el método de fuerza bruta. El "trabajo real" en
String.indexOf() ni siquiera dominaba el perfil de la CPU. Es decir, la optimización de solo este método no traería un efecto significativo.
Dio la casualidad de que almacenamos metadatos al comienzo de cada página, y el texto de todos los mensajes en UTF-8 está empaquetado en el otro extremo. Aprovechando esto, reescribimos el ciclo de búsqueda en toda la página a la vez:
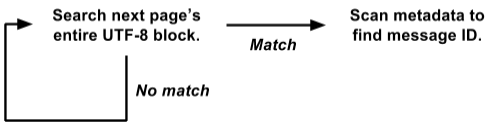
Esta versión funciona directamente en la vista de
raw byte[] y busca todos los mensajes a la vez en toda la página 4K.
Esto es mucho más fácil de optimizar para la fuerza bruta. El ciclo de búsqueda interna se llama simultáneamente para toda la página 4K, y no por separado para cada mensaje. No hay copia de datos, no hay selección de objetos. Y las operaciones más complejas con metadatos se llaman solo con un resultado positivo, y no para cada mensaje. Por lo tanto, eliminamos una tonelada de sobrecarga, y el resto de la carga se concentra en un pequeño ciclo de búsqueda interna, que es muy adecuado para una mayor optimización.
Nuestro algoritmo de búsqueda real se basa en la
gran idea de Leonid Volnitsky . Es similar al algoritmo de Boyer-Moore con saltar sobre la longitud de la cadena de búsqueda en cada paso. La principal diferencia es que verifica dos bytes a la vez para minimizar las coincidencias falsas.
Nuestra implementación requiere la creación de una tabla de búsqueda de 64K para cada búsqueda, pero esto no tiene sentido en comparación con los gigabytes de datos que estamos buscando. El bucle interno procesa varios gigabytes por segundo en un solo núcleo. En la práctica, el rendimiento estable es de alrededor de 1,25 GB por segundo en cada núcleo, y existe la posibilidad de mejorar. Puede eliminar parte de la sobrecarga fuera del ciclo interno, y planeamos experimentar con el ciclo interno en C en lugar de Java.
Aplicar fuerza
Discutimos que las búsquedas de registros se pueden implementar "aproximadamente", pero ¿cuánto "poder" tenemos? Mucho
1 núcleo : cuando se usa correctamente, un núcleo de un procesador moderno es bastante poderoso en sí mismo.
8 núcleos : actualmente estamos trabajando en servidores SSD hi1.4xlarge e i2.4xlarge de Amazon, cada uno de los cuales tiene 8 núcleos (16 hilos). Como se mencionó anteriormente, generalmente estos núcleos están ocupados con operaciones en segundo plano. Cuando el usuario realiza una búsqueda, las operaciones en segundo plano se pausan, liberando los 8 núcleos para la búsqueda. La búsqueda generalmente se completa en una fracción de segundo, después de lo cual se reanuda el trabajo en segundo plano (el programa controlador garantiza que un aluvión de consultas de búsqueda no interfiera con un importante trabajo en segundo plano).
16 núcleos : para mayor confiabilidad, organizamos los servidores en grupos maestro / esclavo. Cada maestro tiene un servidor SSD y un subordinado EBS. Si el servidor principal falla, el servidor en el SSD inmediatamente toma su lugar. Casi todo el tiempo, el maestro y el esclavo funcionan bien, por lo que cada bloque de datos se puede buscar en dos servidores diferentes (el servidor EBS esclavo tiene un procesador débil, por lo que no lo consideramos). Dividimos la tarea entre ellos, de modo que tengamos un total de 16 núcleos disponibles.
Muchos núcleos : en el futuro cercano distribuiremos los datos entre los servidores para que todos participen en el procesamiento de cada solicitud no trivial. Cada núcleo funcionará. [Nota:
implementamos el plan y aumentamos la velocidad de búsqueda a 1 TB / s, vea la nota al final del artículo ].
La simplicidad proporciona confiabilidad
Otra ventaja de la fuerza bruta es su rendimiento relativamente estable. Como regla general, la búsqueda no es demasiado sensible a los detalles de la tarea y el conjunto de datos (creo que es por eso que se llama "grosero").
El índice de palabras clave a veces produce resultados increíblemente rápidos, pero en otros casos no lo hace. Supongamos que tiene 50 GB de registros en los que el término 'customer_5987235982' aparece exactamente tres veces. Una búsqueda por este término cuenta tres ubicaciones directamente desde el índice y finaliza instantáneamente. Pero una búsqueda compleja con comodines puede escanear miles de palabras clave y tomar mucho tiempo.
Por otro lado, las búsquedas de fuerza bruta para cualquier consulta se realizan a más o menos la misma velocidad. La búsqueda de palabras largas es mejor, pero incluso la búsqueda de un solo carácter es lo suficientemente rápida.
La simplicidad del método de fuerza bruta significa que su productividad está cerca del máximo teórico. Hay menos opciones de sobrecarga inesperada del disco, conflicto de bloqueo, persecuciones de puntero y miles de otras razones para fallas. Acabo de ver las solicitudes realizadas por los usuarios de Scalyr la semana pasada en nuestro servidor más ocupado. Hubo 14,000 solicitudes. Exactamente ocho de ellos tomaron más de un segundo; El 99% se realizó en 111 milisegundos (si no ha utilizado las herramientas de análisis de registro, créame:
esto es rápido ).
Un rendimiento estable y confiable es importante para la conveniencia de usar el servicio. Si se ralentiza periódicamente, los usuarios lo percibirán como poco confiable y son reacios a usarlo.
Búsqueda de registros en acción
Aquí hay una pequeña animación que muestra la búsqueda de Scalyr en acción. Tenemos una cuenta demo donde importamos cada evento en cada repositorio público de Github. En esta demostración, estudio los datos de la semana: aproximadamente 600 MB de registros sin procesar.
El video fue grabado en vivo, sin preparación especial, en mi escritorio (a unos 5000 kilómetros del servidor). El rendimiento que verá se debe en gran medida a la
optimización del cliente web , así como al backend rápido y confiable. Cada vez que hay una pausa sin el indicador de "carga", la detengo para que pueda leer en qué voy a hacer clic.

En conclusión
Al procesar grandes cantidades de datos, es importante elegir un buen algoritmo, pero "bueno" no significa "elegante". Piensa en cómo funcionará tu código en la práctica. Algunos factores que pueden ser de gran importancia en el mundo real quedan fuera del análisis teórico de algoritmos. Los algoritmos más simples son más fáciles de optimizar y son más estables en situaciones límite.
También piense en el contexto en el que se ejecutará el código. En nuestro caso, necesitamos servidores lo suficientemente potentes como para administrar tareas en segundo plano. Los usuarios rara vez inician una búsqueda, por lo que podemos tomar prestado un grupo completo de servidores durante el breve período necesario para completar cada búsqueda.
Utilizando la fuerza bruta, implementamos una búsqueda rápida, confiable y flexible en un conjunto de registros. Esperamos que estas ideas sean útiles para sus proyectos.
Editar: El
título y el texto cambiaron de "Buscar a 20 GB por segundo" a "Buscar a 1 TB por segundo" para reflejar el aumento en el rendimiento en los últimos años. Este aumento en la velocidad se debe principalmente a un cambio en el tipo y la cantidad de servidores EC2 que estamos criando hoy para servir a la mayor base de clientes. En el futuro cercano, se esperan cambios que proporcionarán otro aumento brusco en la eficiencia del trabajo, y esperamos tener la oportunidad de contarlo.