En la
primera parte de la historia, basada en una
presentación de Dmitry Stogov de Zend Technologies en HighLoad ++, entendimos la estructura interna de PHP. Aprendimos en detalle y de primera mano qué cambios en las estructuras de datos básicas permitieron que PHP 7 se acelerara más de dos veces. Esto podría haberse detenido, pero ya en la versión 7.1, los desarrolladores fueron mucho más lejos, ya que todavía tenían muchas ideas para la optimización.
La experiencia acumulada trabajando en JIT antes de los siete ahora se puede interpretar, observando los resultados en 7.0 sin JIT y los resultados de HHVM con JIT. En PHP 7.1, se decidió no trabajar con JIT, sino recurrir nuevamente al intérprete. Si antes la optimización se refería al intérprete, en este artículo veremos la optimización del código de bytes, utilizando la inferencia de tipos que se implementó para nuestro JIT.
Debajo del corte, Dmitry Stogov mostrará cómo funciona todo esto, usando un ejemplo simple.
Bytecode optimization
A continuación se muestra el código de bytes en el que el compilador estándar de PHP compila la función. Es de un solo paso: rápido y tonto, pero capaz de hacer su trabajo en cada solicitud HTTP nuevamente (si OPcache no está conectado).

Optimizaciones de OPcache
Con el advenimiento de OPcache, comenzamos a optimizarlo. Algunos métodos de optimización
se han incorporado desde hace mucho tiempo a OPcache , por ejemplo, métodos de optimización de
rendijas : cuando miramos el código a través de la mirilla, buscamos patrones familiares y los reemplazamos por heurísticos. Estos métodos continúan utilizándose en 7.0. Por ejemplo, tenemos dos operaciones: suma y asignación.

Se pueden combinar en una operación de asignación compuesta, que realiza la suma directamente en el resultado:
ASSIGN_ADD $sum, $i . Otro ejemplo es una variable posterior al incremento que teóricamente podría devolver algún tipo de resultado.

Puede no ser un valor escalar y debe eliminarse. Para hacer esto, use las instrucciones
FREE le siguen. Pero si lo cambia a un incremento previo, no se requiere la instrucción
FREE .

Al final hay dos declaraciones
RETURN : la primera es un reflejo directo de la declaración RETURN en el texto fuente, y la segunda la agrega un compilador tonto con un corchete de cierre. Este código nunca se alcanzará y se puede eliminar.
Solo quedan cuatro instrucciones en el bucle. Parece que no hay nada más que optimizar, pero no para nosotros.
Mire el
$i++ y su instrucción correspondiente: el pre-incremento
PRE_INC . Cada vez que se ejecuta:
- necesita verificar qué tipo de variable vino;
- si
is_long ; - realizar incremento;
- verificar el desbordamiento;
- pasar al siguiente
- tal vez verifique la excepción.
Pero una persona, solo mirando el código PHP, verá que la variable
$i encuentra en el rango de 0 a 100, y no puede haber desbordamiento, no son necesarias verificaciones de tipo, y tampoco puede haber excepciones.
En PHP 7.1, tratamos de enseñarle al compilador a entender esto .
Optimización del gráfico de flujo de control

Para hacer esto, debe deducir los tipos, y para ingresarlos, primero debe construir una representación formal de los flujos de datos que la computadora entiende. Pero comenzaremos construyendo un Gráfico de flujo de control, un gráfico de dependencia de control. Inicialmente, dividimos el código en bloques básicos: un conjunto de instrucciones con una entrada y una salida. Por lo tanto, cortamos el código en los lugares donde ocurre la transición, es decir, las etiquetas L0, L1. También lo cortamos después de los operadores de rama condicional e incondicional, y luego lo conectamos con arcos que muestran las dependencias para el control.

Entonces tenemos CFG.
Optimización del formulario de asignación única estática
Bueno, ahora necesitamos una dependencia de datos. Para hacer esto, utilizamos el Formulario de asignación única estática, una representación popular en el mundo de la optimización de compiladores. Implica que el valor de cada variable solo se puede asignar una vez.

Para cada variable, agregamos un índice o número de reencarnación. En cada lugar donde se lleva a cabo la tarea, colocamos un nuevo índice y donde los usamos, hasta los signos de interrogación, porque no siempre se conoce en todas partes. Por ejemplo, en la instrucción
IS_SMALLER $ i puedo provenir tanto del bloque L0 con el número 4 como del primer bloque con el número 2.
Para resolver este problema, la SSA introduce
la pseudofunción Phi , que, si es necesario, se inserta al comienzo del bloque basic->, toma todo tipo de índices de una variable que llegó al bloque basic desde diferentes lugares y crea una nueva reencarnación de la variable. Son esas variables las que luego se usan para eliminar la ambigüedad.

Reemplazando todos los signos de interrogación de esta manera, construiremos la SSA.
Optimización de tipo
Ahora deducimos los tipos, como si tratara de ejecutar este código directamente en la administración.

En el primer bloque, a las variables se les asignan valores constantes: ceros, y sabemos con certeza que estas variables serán de tipo largo. El siguiente es la función Phi. Long llega a la entrada, y no conocemos los valores de otras variables que provienen de otras ramas.

Creemos que la salida phi () tendremos mucho tiempo.

Distribuimos más. Llegamos a funciones específicas, por ejemplo,
ASSIGN_ADD y
PRE_INC . Suma dos largos. El resultado puede ser largo o doble si se produce un desbordamiento.

Estos valores vuelven a caer en la función Phi, se produce la unión de los conjuntos de tipos posibles que llegan a diferentes ramas. Bueno, etc., continuamos extendiéndonos hasta llegar a un punto fijo y todo se calma.

Tenemos un posible conjunto de valores de tipo en cada punto del programa. Esto ya está bien. La computadora ya sabe que
$i solo puede ser largo o doble, y puede excluir algunas verificaciones innecesarias. Pero sabemos que doble
$i no puedo ser. Como lo sabemos Y vemos una condición que limita el crecimiento de
$i en el ciclo a un posible desbordamiento. Le enseñaremos a la computadora a ver esto.
Optimización de propagación de rango
En la instrucción
PRE_INC nunca descubrimos que solo puedo ser un número entero: cuesta mucho o el doble. Esto sucede porque no intentamos inferir posibles rangos. Entonces podríamos responder la pregunta de si ocurrirá un desbordamiento o no.
Esta salida de los rangos se realiza de manera similar, pero un poco más compleja. Como resultado, obtenemos un rango fijo de variables
$i con los índices 2, 4, 6 7, y ahora podemos decir con confianza que el incremento
$i no conducirá a un desbordamiento.

Al combinar estos dos resultados, podemos decir con certeza que la variable doble
$i nunca
$i convertirse.

Todo lo que tenemos aún no es optimización, ¡es información para la optimización! Considere la
ASSIGN_ADD . En términos generales, el valor anterior de la suma que vino a esta instrucción podría ser, por ejemplo, un objeto. Luego, después de la adición, el valor anterior debería haberse eliminado. Pero en nuestro caso, sabemos con certeza que hay un valor largo o doble, es decir, un valor escalar. No se requiere destrucción, podemos reemplazar
ASSIGN_ADD con
ADD , una instrucción más fácil.
ADD usa la variable
sum como argumento y valor.

Para las operaciones previas al incremento, sabemos con certeza que el operando siempre es largo y que no se pueden producir desbordamientos. Utilizamos un controlador altamente especializado para esta instrucción, que realizará solo las acciones necesarias sin ninguna verificación.

Ahora compare la variable al final del ciclo. Sabemos que el valor de la variable solo será largo; puede verificar este valor de inmediato comparándolo con cien. Si antes registramos el resultado de la verificación en una variable temporal, y luego una vez más verificamos la variable temporal para verdadero / falso, ahora esto se puede hacer con una instrucción, es decir, simplificada.

Resultado del código de bytes en comparación con el original.

Solo quedan 3 instrucciones en el ciclo, y dos de ellas son altamente especializadas. Como resultado, el código de la derecha es
3 veces más rápido que el original.
Manipuladores altamente especializados
Cualquier
controlador de rastreo PHP es solo una función C. A la izquierda hay un controlador estándar, y en la parte superior derecha hay uno altamente especializado. El izquierdo verifica: el tipo de operando, si se ha producido un desbordamiento, si se ha producido una excepción. El correcto solo agrega uno y eso es todo. Se traduce en 4 instrucciones de máquina. Si fuimos más allá e hicimos JIT, entonces solo necesitaríamos una instrucción única,
incl .

Que sigue
Continuamos aumentando la velocidad de PHP branch 7 sin JIT.
PHP 7.1 volverá a ser un 60% más rápido en pruebas sintéticas típicas, pero en aplicaciones reales esto casi no da una victoria, solo 1-2% en WordPress. Esto no es particularmente interesante. Desde agosto de 2016, cuando la rama 7.1 se congeló por cambios importantes, nuevamente comenzamos a trabajar en JIT para PHP 7.2 o más bien PHP 8.
En un nuevo intento, usamos
DynAsm para generar el código, que fue desarrollado por Mike Paul
para LuaJIT-2 . Es bueno porque
genera código muy rápidamente : el hecho de que los minutos se compilaron en la versión JIT en LLVM ahora ocurre en 0.1-0.2 s. Ya hoy, la
aceleración en bench.php en JIT es 75 veces más rápida que PHP 5.
No hay aceleración en aplicaciones reales, y este es el próximo desafío para nosotros. En parte, obtuvimos el código óptimo, pero después de compilar demasiados scripts PHP, obstruimos el caché del procesador, por lo que no funcionó más rápido. Y no la velocidad del código fue un cuello de botella en aplicaciones reales ...
Quizás DynAsm pueda usarse para compilar solo ciertas funciones que serán seleccionadas por un programador o por heurísticas basadas en contadores: cuántas veces se ha llamado una función, cuántas veces se repiten los ciclos, etc.
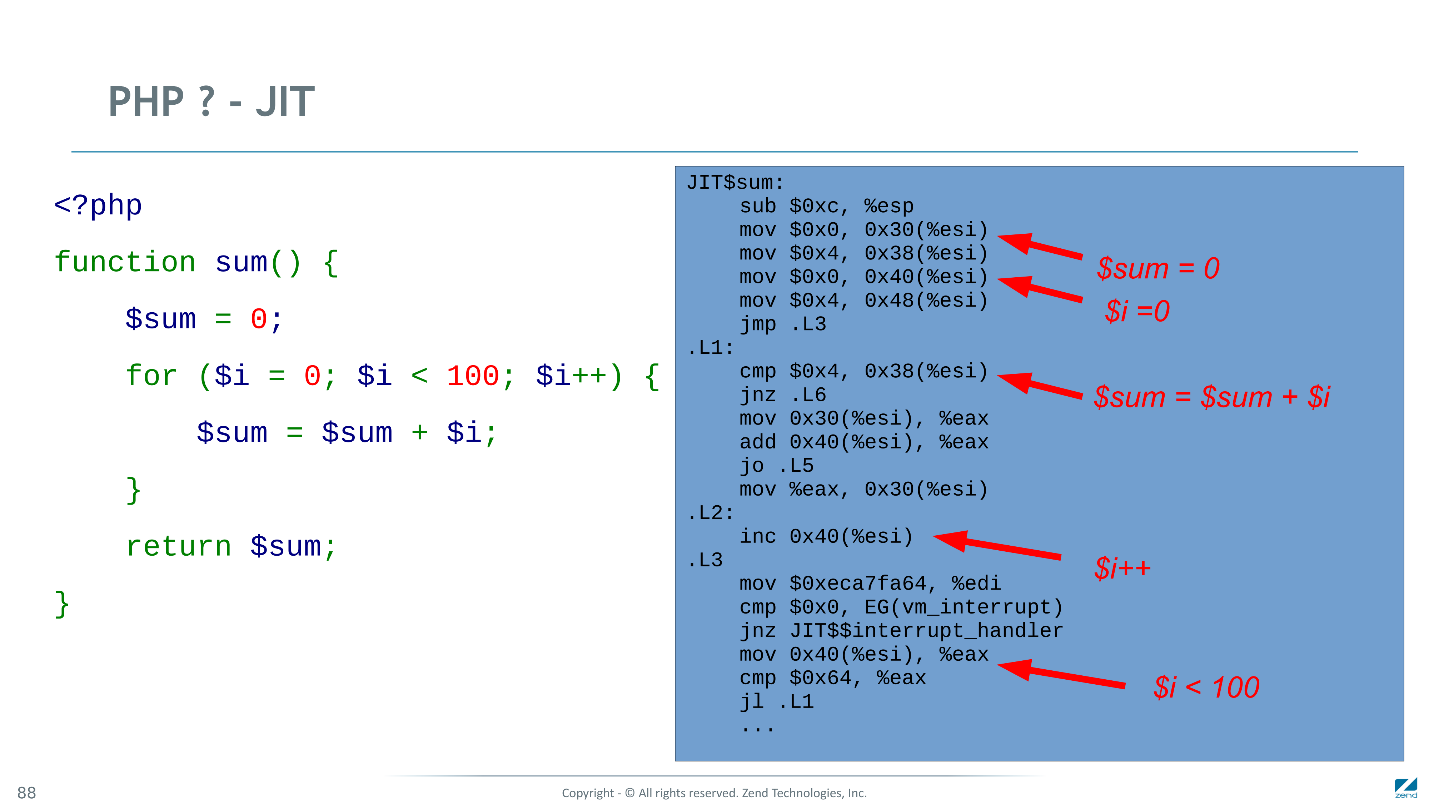
A continuación se muestra el código de máquina que genera nuestro JIT para el mismo ejemplo. Muchas instrucciones se compilan de manera óptima: incremente en una instrucción de CPU, inicialización variable a constantes en dos. Cuando los tipos no se traman, debe molestarse un poco más.
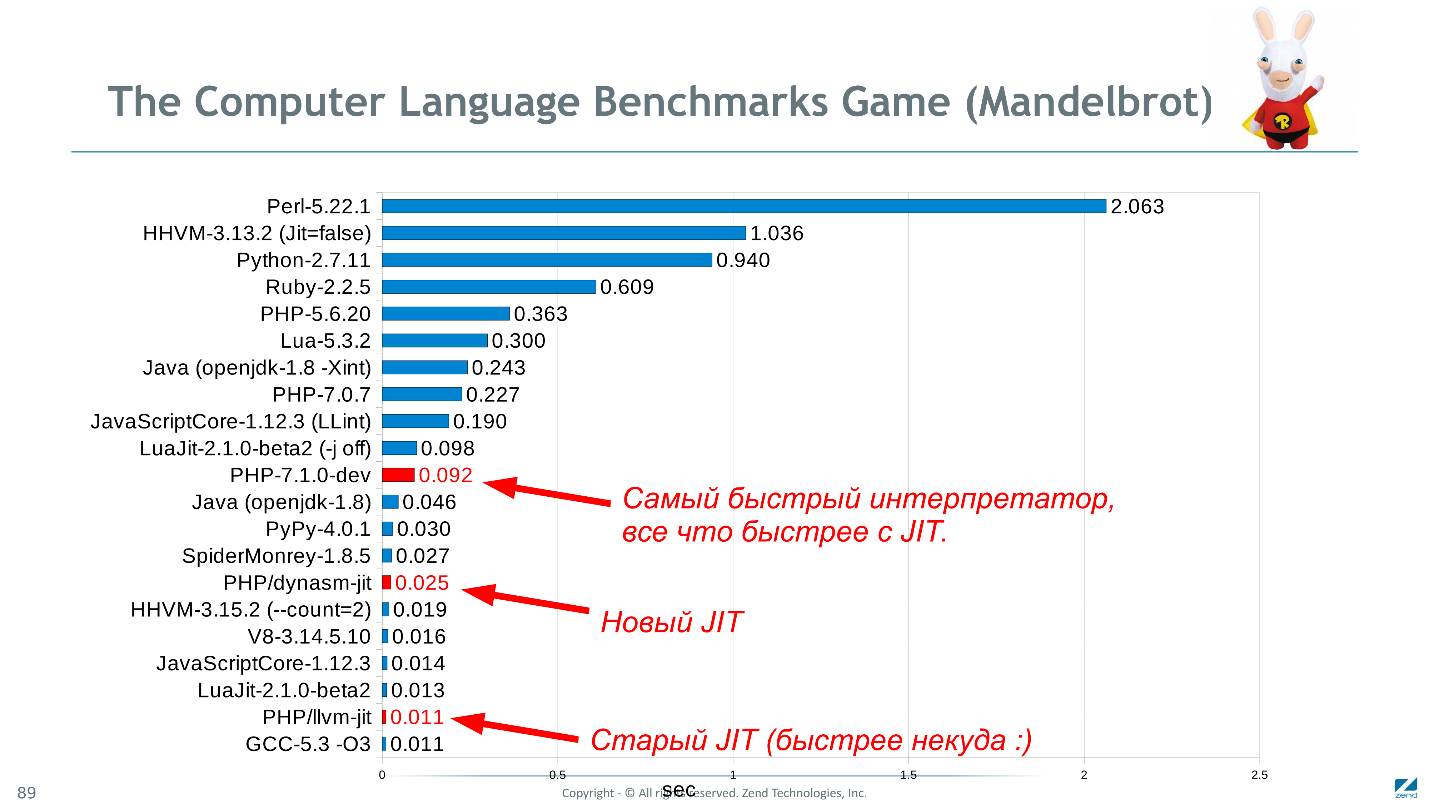
Volviendo a la imagen del título, PHP, en comparación con lenguajes similares en la prueba de Mandelbrot, muestra muy buenos resultados (aunque los datos son relevantes a finales de 2016).
El diagrama muestra el tiempo de ejecución en segundos, menos es mejor.Quizás
Mandelbrot no sea la mejor prueba. Es computacional, pero simple e implementado igualmente en todos los idiomas. Sería bueno saber qué tan rápido Wordpress funcionaría en C ++, pero casi no hay ninguna rareza lista para reescribirlo solo para verificar e incluso repetir todas las perversiones del código PHP. Si tiene ideas para un conjunto de puntos de referencia más adecuado, sugiérale.
Nos reuniremos en PHP Rusia el 17 de mayo , discutiremos las perspectivas y el desarrollo del ecosistema y la experiencia de usar PHP para proyectos realmente complejos y geniales. Ya con nosotros:
Por supuesto, esto está lejos de todo. Y Call for Papers todavía está cerrado, hasta el 1 de abril, estamos esperando solicitudes de aquellos que puedan aplicar enfoques modernos y mejores prácticas para implementar servicios PHP geniales. No tenga miedo de competir con oradores eminentes: estamos buscando experiencia en el uso de lo que hacen en proyectos reales y lo ayudaremos a mostrar los beneficios de sus casos.