En este artículo, consideraremos la aplicación inusual de las redes neuronales en general y las máquinas de Boltzmann limitadas en particular para resolver dos problemas complejos de la mecánica cuántica: encontrar la energía del estado fundamental y aproximar la función de onda de un sistema de muchos cuerpos.
Podemos decir que esta es una narración gratuita y simplificada de un artículo [2], publicado en Science en 2017 y algunos trabajos posteriores. No encontré exposiciones científicas populares de este trabajo en ruso (y solo
esta de las versiones en inglés), aunque me pareció muy interesante.
Conceptos mínimos esenciales de la mecánica cuántica y el aprendizaje profundo.Quiero señalar de
inmediato que estas definiciones están
extremadamente simplificadas . Los traigo para aquellos para quienes el problema descrito es un bosque oscuro.
Un estado es simplemente un conjunto de cantidades físicas que describen un sistema. Por ejemplo, para un electrón que vuela en el espacio serán sus coordenadas y su momento, y para una red cristalina será un conjunto de espines de átomos ubicados en sus nodos.
La función de onda del sistema es una función compleja del estado del sistema. Cierto cuadro negro que toma una entrada, por ejemplo, un conjunto de giros, pero devuelve un número complejo. La propiedad principal de la función de onda que es importante para nosotros es que su cuadrado es igual a la probabilidad de este estado:
Es lógico que el cuadrado de la función de onda se normalice a la unidad (y este es también uno de los problemas importantes).
Espacio de Hilbert - en nuestro caso, tal definición es suficiente - el espacio de todos los estados posibles del sistema. Por ejemplo, para un sistema de 40 giros que puede tomar los valores +1 o -1, el espacio de Hilbert es todo
posibles condiciones. Para coordenadas que pueden tomar valores
, la dimensión del espacio de Hilbert es infinita. La enorme dimensión del espacio de Hilbert para cualquier sistema real es el problema principal que no permite resolver ecuaciones analíticamente: en el proceso habrá integrales / sumas sobre todo el espacio de Hilbert que no pueden calcularse "de frente". Un dato curioso: durante toda la vida del Universo puedes conocer solo una pequeña parte de todos los estados posibles incluidos en el espacio de Hilbert. Esto está muy bien ilustrado por una imagen de un artículo sobre Tensor Networks [1], que representa esquemáticamente todo el espacio de Hilbert y aquellos estados que se pueden cumplir después de un polinomio a partir de la característica de la complejidad del espacio (número de cuerpos, partículas, espines, etc.)
Una máquina de Boltzmann limitada : si es difícil de explicar, es un modelo probabilístico gráfico no dirigido, cuya limitación es la independencia condicional de las probabilidades de los nodos de una capa de los nodos de la misma capa. Si es de una manera simple, entonces esta es una red neuronal con una entrada y una capa oculta. Los valores de salida de las neuronas en la capa oculta pueden ser 0 o 1. La diferencia con la red neuronal habitual es que las salidas de las neuronas de la capa oculta son variables aleatorias seleccionadas con una probabilidad igual al valor de la función de activación:
donde
-
función de activación sigmoidea ,
- compensación para la i-ésima neurona,
- el peso de la red neuronal,
- capa visible. Las máquinas de Boltzmann limitadas pertenecen a los llamados "modelos de energía", ya que podemos expresar la probabilidad de un estado particular de una máquina utilizando la energía de esta máquina:
donde
v y
h son las capas visibles y ocultas,
a y
b son los desplazamientos de las capas visibles y ocultas,
W son los pesos. Entonces la probabilidad del estado es representable en la forma:
donde
Z es el término de normalización, también llamado suma estadística (es necesario para que la probabilidad total sea igual a la unidad).
Introduccion
Hoy en día, existe una opinión entre los especialistas en aprendizaje profundo que limita
Las máquinas de Boltzmann (en adelante, OMB) son un concepto obsoleto que prácticamente no es aplicable en tareas reales. Sin embargo, en 2017, apareció
un artículo [2] en Science que mostraba el uso muy eficiente de OMB para problemas de mecánica cuántica.
Los autores notaron dos hechos importantes que pueden parecer obvios, pero nunca antes se le habían ocurrido a nadie:
- OMB es una red neuronal que, según el teorema universal de Tsybenko , teóricamente puede aproximar cualquier función con una precisión arbitrariamente alta (todavía hay muchas restricciones, pero puede omitirlas).
- OMB es un sistema cuya probabilidad de cada estado es una función de la entrada (capa visible), pesos y desplazamientos de la red neuronal.
Bueno y más allá, los autores dijeron: dejemos que nuestro sistema sea completamente descrito por la función de onda, que es la raíz de la energía OMB, y las entradas OMB son las características de nuestro estado del sistema (coordenadas, giros, etc.):
donde s son características del estado (por ejemplo, giros), h son las salidas de la capa oculta de OMB, E es la energía de OMB, Z es la constante de normalización (suma estadística).
Eso es todo, el artículo en Science está listo, solo quedan algunos pequeños detalles. Por ejemplo, es necesario resolver el problema de la función de partición no computable debido al gran tamaño del espacio de Hilbert. Y el teorema de Tsybenko nos dice que una red neuronal puede aproximarse a cualquier función, pero no dice en absoluto cómo encontrar un conjunto adecuado de pesos y compensaciones de red para esto. Bueno, y como siempre, la diversión comienza aquí.
Entrenamiento modelo
Ahora hay bastantes modificaciones del enfoque original, pero solo consideraré el enfoque del artículo original [2].
Desafío
En nuestro caso, la tarea de entrenamiento será la siguiente: encontrar una aproximación de la función de onda que haga más probable el estado con energía mínima. Esto es intuitivamente claro: la función de onda nos da la probabilidad de un estado, el valor propio del Hamiltoniano (el operador de energía, o incluso más simple, energía; en el marco de este artículo, esta comprensión es suficiente) para que la función de onda sea energía. Todo es simple
En realidad, nos esforzaremos por optimizar otra cantidad, la llamada energía local, que siempre es mayor o igual que la energía del estado fundamental:
aqui
Es nuestra condición
- todos los estados posibles del espacio de Hilbert (en realidad consideraremos un valor más aproximado),
Es el elemento matriz del hamiltoniano. Depende mucho del Hamiltoniano específico, por ejemplo, para el
modelo Ising, esto es solo
si
y
en todos los demás casos. No te detengas aquí ahora; Es importante que estos elementos se puedan encontrar para varios hamiltonianos populares.
Proceso de optimización
Muestreo
Una parte importante del enfoque del artículo original fue el proceso de muestreo. Se utilizó una variación modificada del algoritmo
Metropolis-Hastings . La conclusión es:
- Partimos de un estado aleatorio.
- Cambiamos el signo de un giro seleccionado al azar al opuesto (para las coordenadas hay otras modificaciones, pero también existen).
- Con probabilidad igual a P (\ sigma '| \ sigma) = \ Big | {\ frac {\ Psi (\ sigma')} {\ Psi (\ sigma)} \ Big | ^ 2 , muévete a un nuevo estado.
- Repite N veces.
Como resultado, obtenemos un conjunto de estados aleatorios seleccionados de acuerdo con la distribución que nos da nuestra función de onda. Puede calcular los valores de energía en cada estado y la expectativa matemática de energía
.
Se puede demostrar que la estimación del gradiente de energía (más precisamente, el valor esperado del Hamiltoniano) es igual a:
ConclusiónEsto es de una conferencia dada por G. Carleo en 2017 para la Escuela Avanzada de Ciencia Cuántica y Tecnología Cuántica. Hay entradas en Youtube.
Denotar:
Entonces:
Luego solo resolvemos el problema de optimización:
- Demostramos estados de nuestro OMB.
- Calculamos la energía de cada estado.
- Estima el gradiente.
- Actualizamos el peso de OMB.
Como resultado, el gradiente de energía tiende a cero, el valor de la energía disminuye, al igual que el número de nuevos estados únicos en el proceso Metropolis-Hastings, porque al tomar muestras de la función de onda verdadera casi siempre obtendremos el estado fundamental. Intuitivamente, esto parece lógico.
En el trabajo original, para sistemas pequeños, se obtuvieron los valores de la energía del estado fundamental, muy cerca de los valores exactos obtenidos analíticamente. Se realizó una comparación con los enfoques bien conocidos para encontrar la energía del estado fundamental, y NQS ganó, especialmente teniendo en cuenta la complejidad computacional relativamente baja de NQS en comparación con los métodos conocidos.
NetKet - una biblioteca desde el enfoque de "inventores"
Uno de los autores del artículo original [2] con su equipo desarrolló la excelente biblioteca NetKet [3], que contiene un núcleo C muy bien optimizado (en mi opinión), así como la API de Python, que funciona con abstracciones de alto nivel.
La biblioteca se puede instalar a través de pip. Los usuarios de Windows 10 deberán usar Linux Subsystem para Windows.
Consideremos trabajar con la biblioteca como un ejemplo de una cadena de 40 giros tomando los valores + -1 / 2. Consideraremos el modelo de Heisenberg, que tiene en cuenta las interacciones vecinas.
NetKet tiene una excelente documentación que le permite descubrir rápidamente qué y cómo hacer. Hay muchos modelos incorporados (respaldos, bosones, modelos Ising, Heisenberg, etc.), y la capacidad de describir completamente el modelo usted mismo.
Descripción del conteo
Todos los modelos se presentan en gráficos. Para nuestra cadena, el modelo Hypercube incorporado con una dimensión y condiciones de contorno periódicas es adecuado:
import netket as nk graph = nk.graph.Hypercube(length=40, n_dim=1, pbc=True)
Descripción del espacio de Hilbert
Nuestro espacio de Hilbert es muy simple: todos los giros pueden tomar valores ya sea +1/2 o -1/2. Para este caso, el modelo incorporado para giros es adecuado:
hilbert = nk.hilbert.Spin(graph=graph, s=0.5)
Descripción del hamiltoniano
Como ya escribí, en nuestro caso, el hamiltoniano es el hamiltoniano de Heisenberg para el que hay un operador incorporado:
hamiltonian = nk.operator.Heisenberg(hilbert=hilbert)
Descripción de RBM
En NetKet, puede usar una implementación RBM ya preparada para giros, este es solo nuestro caso. Pero en general hay muchos autos, puedes probar diferentes.
nk.machine.RbmSpin(hilbert=hilbert, alpha=4) machine.init_random_parameters(seed=42, sigma=0.01)
Aquí alfa es la densidad de las neuronas en la capa oculta. Para 40 neuronas visibles y alfa 4, habrá 160 de ellas. Hay otra forma de indicar directamente por número. El segundo comando inicializa pesos al azar de
. En nuestro caso, sigma es 0.01.
Samler
Una muestra es un objeto que nos devolverá una muestra de nuestra distribución, que viene dada por la función de onda en el espacio de Hilbert. Utilizaremos el algoritmo Metropolis-Hastings descrito anteriormente, modificado para nuestra tarea:
sampler = nk.sampler.MetropolisExchangePt( machine=machine, graph=graph, d_max=1, n_replicas=12 )
Para ser precisos, el muestreador es un algoritmo más complicado que el que describí anteriormente. Aquí verificamos simultáneamente hasta 12 opciones en paralelo para seleccionar el siguiente punto. Pero el principio, en general, es el mismo.
Optimizador
Esto describe el optimizador que se usará para actualizar los pesos del modelo. Basado en la experiencia personal trabajando con redes neuronales en áreas que les son más “familiares”, la mejor y más confiable opción es el buen descenso de gradiente estocástico con un momento (bien descrito
aquí ):
opt = nk.optimizer.Momentum(learning_rate=1e-2, beta=0.9)
Entrenamiento
NetKet tiene capacitación sin un maestro (nuestro caso) y con un maestro (por ejemplo, la llamada "tomografía cuántica", pero este es el tema de un artículo separado). Simplemente describimos a los "maestros" y eso es todo:
vc = nk.variational.Vmc( hamiltonian=hamiltonian, sampler=sampler, optimizer=opt, n_samples=1000, use_iterative=True )
El Monte Carlo variacional indica cómo evaluamos el gradiente de la función que estamos optimizando.
n_smaples es el tamaño de la muestra de nuestra distribución que devuelve la muestra.
Resultados
Ejecutaremos el modelo de la siguiente manera:
vc.run(output_prefix=output, n_iter=1000, save_params_every=10)
La biblioteca está construida con OpenMPI, y el script deberá ejecutarse así:
mpirun -n 12 python Main.py (12 es el número de núcleos).
Los resultados que recibí son los siguientes:
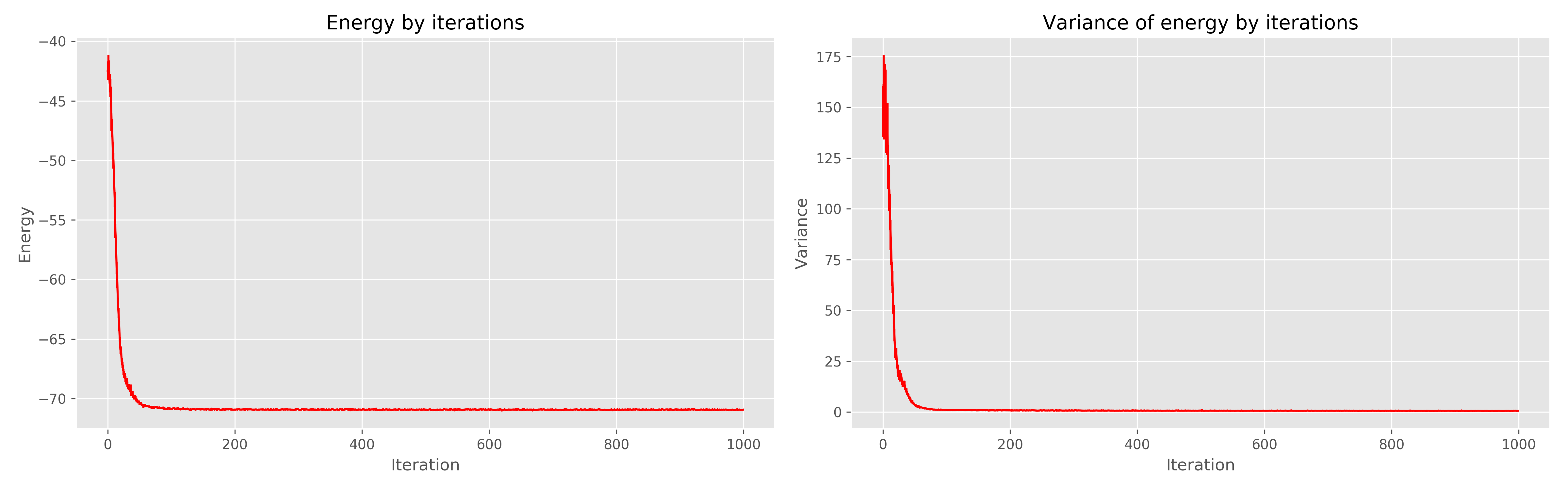
A la izquierda está el gráfico de energía de la era del aprendizaje, a la derecha está la dispersión de energía de la era del aprendizaje.
Se puede ver que 1000 eras son claramente redundantes, 300 habrían sido suficientes. En general, funciona muy bien, converge rápidamente.
Literatura
- Orús R. Una introducción práctica a las redes tensoras: estados de productos de matriz y estados de par entrelazados proyectados // Annals of Physics. - 2014 .-- T. 349. - S. 117-158.
- Carleo G., Troyer M. Resolviendo el problema cuántico de muchos cuerpos con redes neuronales artificiales // Science. - 2017. - T. 355. - No. 6325. - S. 602-606.
- www.netket.org