Cuando se trabaja con varios clientes a la vez, se hace necesario analizar rápidamente mucha información en diferentes cuentas e informes. Cuando hay más de 10 clientes, el vendedor ya no tiene tiempo para monitorear constantemente las estadísticas. Pero hay un camino.
En este artículo, hablaré sobre cómo monitorear cuentas publicitarias usando la API y Python.
A la salida, recibiremos una solicitud para la API Yandex.Direct, con la que recibiremos estadísticas sobre campañas publicitarias y podremos procesar estos datos.
Para esto necesitamos:
- Obtenga Yandex Direct API Token
- Escribir una solicitud de servidor
- Importar datos a DataFrame
Importar bibliotecas
Debe importar las bibliotecas que se utilizan en la consulta, así como pandas y DataFrame.
Todas las importaciones se verán así:
import requests from requests.exceptions import ConnectionError from time import sleep import json import pandas as pd import numpy as np from pandas import Series,DataFrame
Recibiendo token
En este momento no puedo decir mejor que la documentación de API Direct, por lo que dejaré un enlace.
(
Instrucciones para obtener un token )
Estamos escribiendo una solicitud al servidor Yandex.Direct API
Copie la solicitud de la documentación de la APICambiar la solicitud- Prescribe tu token e inicia sesión
Token
token = 'blaBlaBLAblaBLABLABLAblabla'
Iniciar sesión
clientLogin = 'e-66666666'
- Ajustamos el cuerpo de la solicitud por nosotros mismos.
De esto
body = { "params": { "SelectionCriteria": { "DateFrom": "_", "DateTo": "_" }, "FieldNames": [ "Date", "CampaignName", "LocationOfPresenceName", "Impressions", "Clicks", "Cost" ], "ReportName": u("_"), "ReportType": "CAMPAIGN_PERFORMANCE_REPORT", "DateRangeType": "CUSTOM_DATE", "Format": "TSV", "IncludeVAT": "NO", "IncludeDiscount": "NO"
Hazlo
body = { "params": { "SelectionCriteria": { "Filter": [ { "Field": "Clicks", "Operator": "GREATER_THAN", "Values": [ "0" ] }, ] }, "FieldNames": [ "CampaignName", "Impressions", "Clicks", "Ctr", "Cost", "AvgCpc", "BounceRate", "AvgPageviews", "ConversionRate", "CostPerConversion", "Conversions" ], "ReportName": u("Report4"), "ReportType": « ", "DateRangeType": "LAST_5_DAYS", "Format": "TSV", "IncludeVAT": "NO", "IncludeDiscount": "NO" } }
En
SelectionCriteria escribimos cómo seleccionaremos los datos. Por defecto, se escriben 2 fechas allí, pero para no tener que cambiarlas constantemente, reemplazaremos el período de tiempo con "Últimos 5 días".
Configuramos el filtro para los datos . Esto se requiere principalmente para no obtener valores vacíos. El problema es que Direct muestra los datos faltantes como dos desventajas, debido a que cambia el tipo de datos de toda la columna, después de lo cual no puede realizar operaciones matemáticas sin gestos innecesarios.
FieldNames Escribimos aquí los datos que necesita. Registré los campos que uso para el análisis, su lista puede diferir.
ReportType El tipo de informe se escribe en este campo, para las campañas se necesita este informe.
Deberías obtener algo como esto.
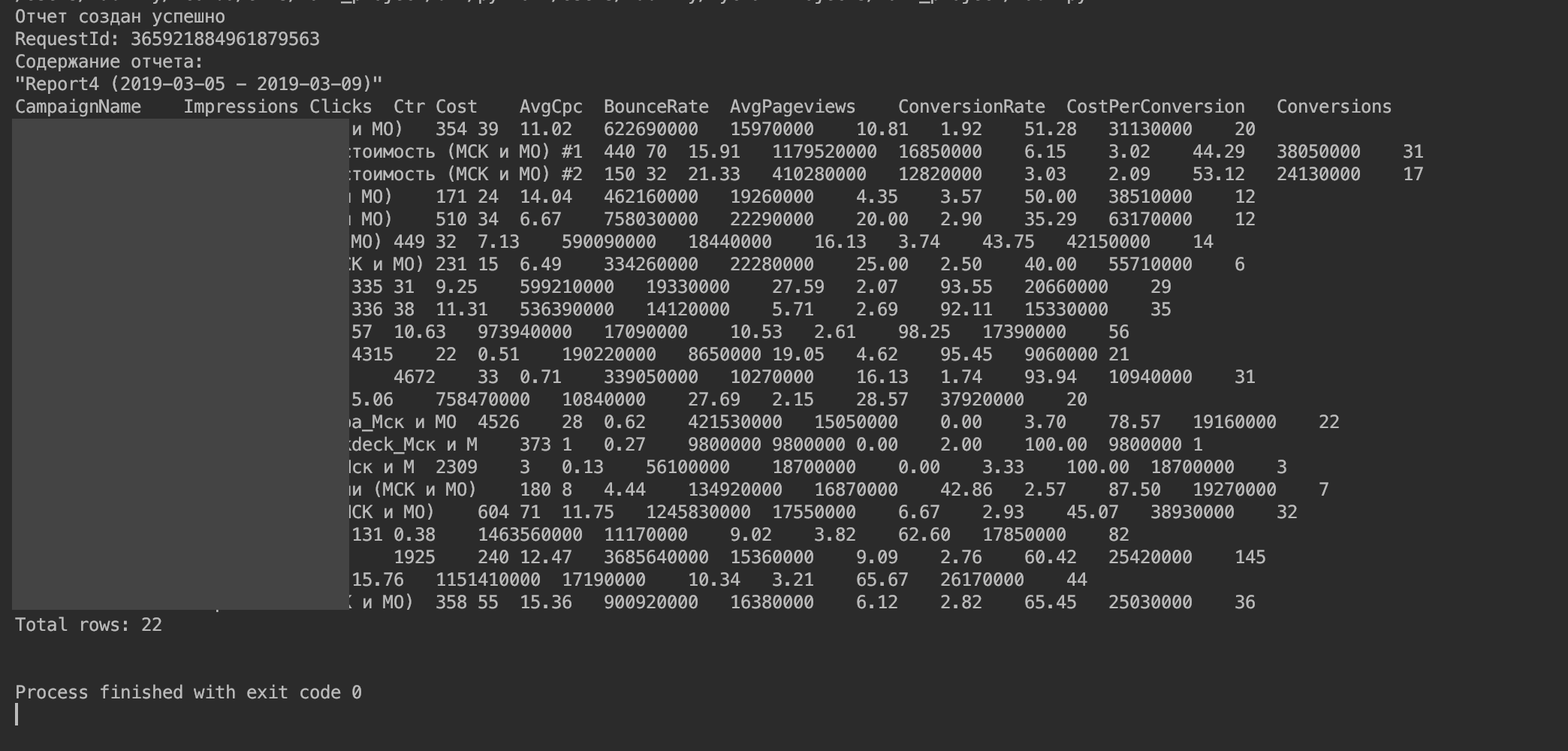
5. Importe los datos a un DataFrame.
(Un DataFrame es probablemente la forma más adecuada de trabajar con estos datos).
Pude implementar esta función escribiendo y leyendo un archivo csv.
Encontramos en la consulta la pieza responsable de la salida de estadísticas: esto es "req.text".
Eliminamos la salida estándar del programa para escribir en el archivo. Para hacer esto, cambie todas las conclusiones en el código 200.
print(" ") print("RequestId: {}".format(req.headers.get("RequestId", False))) print(" : \n{}».format(u(req.text)))
En:
format(u(req.text))
Ahora importe la respuesta del servidor al DataFrame.
file = open("cashe.csv", "w") file.write(req.text) file.close() f = DataFrame.from_csv("cashe.csv",header=1, sep=' ', index_col=0,)
Paso a paso:
- Abra (y cree automáticamente) el archivo cashe.csv para escribir
- Escribimos la respuesta del servidor
- Cerrar el archivo
- Abra el archivo como un DataFrame (especifique el nombre del archivo, en qué fila están los encabezados de la tabla, cuál es el divisor entre los datos, en qué columna está el índice)
Resultó lo siguiente:
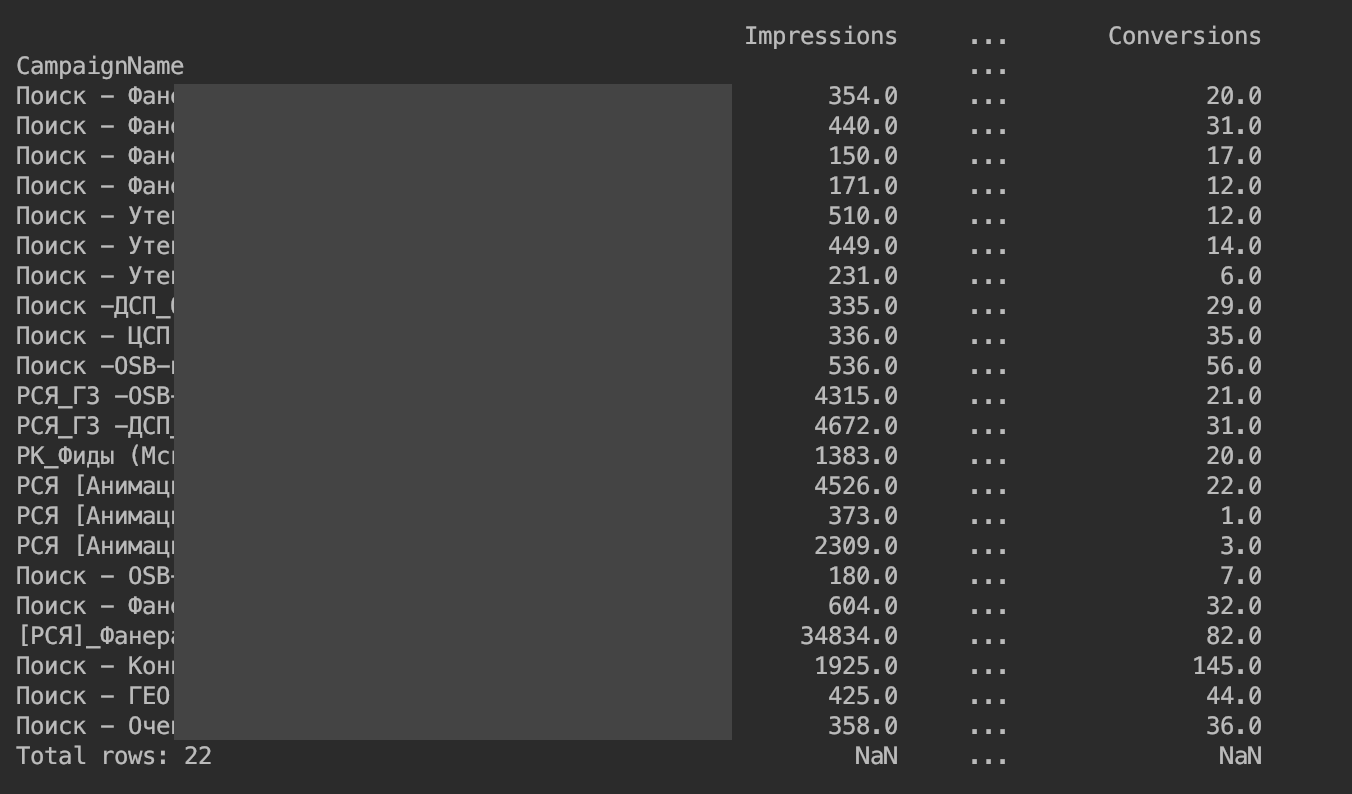
Eliminamos la restricción en la salida de columnas:
pd.set_option('display.max_columns', None) pd.set_option('display.expand_frame_repr', False) pd.set_option('max_colwidth', -1)
Ahora todo se muestra:
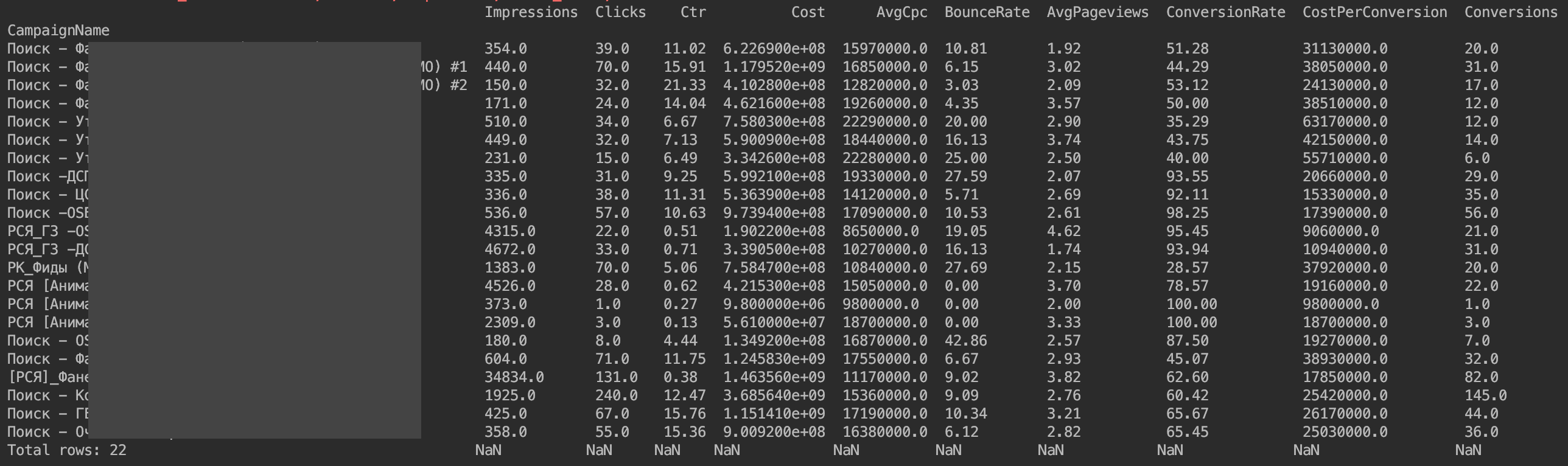
El único problema es que los valores monetarios no se muestran como les gustaría. Estas son las características de la implementación de la API Yandex.Direct. Solo necesitamos dividir los valores monetarios por 1,000,000.
f['Cost'] = f['Cost']/1000000 f['AvgCpc'] = f['AvgCpc']/1000000 f['CostPerConversion'] = f['CostPerConversion']/1000000
También sugiero ordenar inmediatamente por el número de clics
f=f.sort_values(by=['Clicks'], ascending=False)
Así que preparamos DataFrame para el análisis
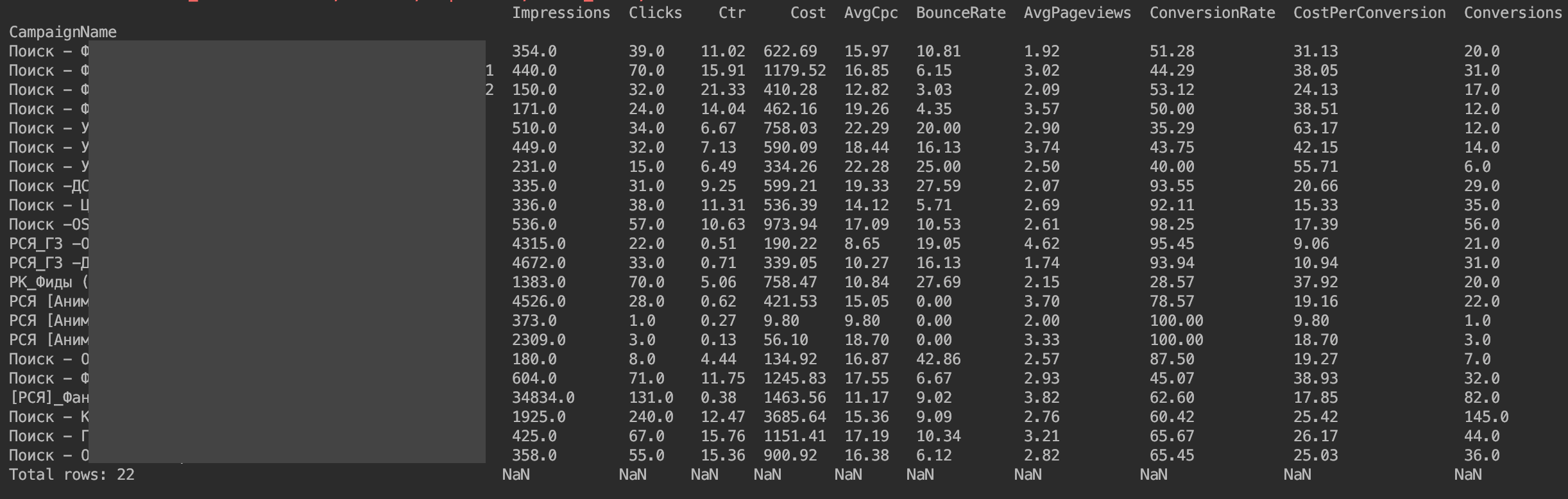
Para mí, escribí solicitudes similares de estadísticas por día y por campaña, para estar siempre al tanto de las desviaciones del tráfico y comprender dónde ocurrió aproximadamente la desviación.
Gracias por su atencion
Código final: import requests from requests.exceptions import ConnectionError from time import sleep import json import pandas as pd import numpy as np from pandas import Series,DataFrame pd.set_option('display.max_columns', None) pd.set_option('display.expand_frame_repr', False) pd.set_option('max_colwidth', -1) # UTF-8 Python 3, Python 2 import sys if sys.version_info < (3,): def u(x): try: return x.encode("utf8") except UnicodeDecodeError: return x else: def u(x): if type(x) == type(b''): return x.decode('utf8') else: return x # --- --- # Reports JSON- () ReportsURL = 'https://api.direct.yandex.com/json/v5/reports' # OAuth- , token = ' ' # # , clientLogin = ' ' # --- --- # HTTP- headers = { # OAuth-. Bearer "Authorization": "Bearer " + token, # "Client-Login": clientLogin, # "Accept-Language": "ru", # "processingMode": "auto" # # "returnMoneyInMicros": "false", # # "skipReportHeader": "true", # # "skipColumnHeader": "true", # # "skipReportSummary": "true" } # body = { "params": { "SelectionCriteria": { "Filter": [ { "Field": "Clicks", "Operator": "GREATER_THAN", "Values": [ "0" ] }, ] }, "FieldNames": [ "CampaignName", "Impressions", "Clicks", "Ctr", "Cost", "AvgCpc", "BounceRate", "AvgPageviews", "ConversionRate", "CostPerConversion", "Conversions" ], "ReportName": u("Report4"), "ReportType": "CAMPAIGN_PERFORMANCE_REPORT", "DateRangeType": "LAST_5_DAYS", "Format": "TSV", "IncludeVAT": "NO", "IncludeDiscount": "NO" } } # JSON body = json.dumps(body, indent=4) # --- --- # HTTP- 200, # HTTP- 201 202, while True: try: req = requests.post(ReportsURL, body, headers=headers) req.encoding = 'utf-8' # UTF-8 if req.status_code == 400: print(" ") print("RequestId: {}".format(req.headers.get("RequestId", False))) print("JSON- : {}".format(u(body))) print("JSON- : \n{}".format(u(req.json()))) break elif req.status_code == 200: format(u(req.text)) break elif req.status_code == 201: print(" ") retryIn = int(req.headers.get("retryIn", 60)) print(" {} ".format(retryIn)) print("RequestId: {}".format(req.headers.get("RequestId", False))) sleep(retryIn) elif req.status_code == 202: print(" ") retryIn = int(req.headers.get("retryIn", 60)) print(" {} ".format(retryIn)) print("RequestId: {}".format(req.headers.get("RequestId", False))) sleep(retryIn) elif req.status_code == 500: print(" . , ") print("RequestId: {}".format(req.headers.get("RequestId", False))) print("JSON- : \n{}".format(u(req.json()))) break elif req.status_code == 502: print(" .") print(", - .") print("JSON- : {}".format(body)) print("RequestId: {}".format(req.headers.get("RequestId", False))) print("JSON- : \n{}".format(u(req.json()))) break else: print(" ") print("RequestId: {}".format(req.headers.get("RequestId", False))) print("JSON- : {}".format(body)) print("JSON- : \n{}".format(u(req.json()))) break # , API except ConnectionError: # print(" API") # break # - except: # print(" ") # break file = open("cashe.csv", "w") file.write(req.text) file.close() f = DataFrame.from_csv("cashe.csv",header=1, sep=' ', index_col=0,) f['Cost'] = f['Cost']/1000000 f['AvgCpc'] = f['AvgCpc']/1000000 f['CostPerConversion'] = f['CostPerConversion']/1000000 f=f.sort_values(by=['Clicks'], ascending=False) print(f)