Continuamos publicando videos y transcripciones de los mejores informes de la conferencia
PGConf.Russia 2019 . Un informe de Oleg Bartunov sobre el tema "Postgres profesionales" abrió la parte plenaria de la conferencia. Revela la historia de Postgres DBMS, la contribución rusa al desarrollo, características de arquitectura.
Materiales anteriores de esta serie: "Errores típicos al trabajar con PostgreSQL" por Ivan Frolkov, partes
1 y
2 .

Hablaré de Postgres profesionales. No confunda con la empresa que represento ahora: Postgres Professional.

Realmente hablaré sobre cómo Postgres, que comenzó como un desarrollo académico aficionado, se convirtió en profesional, tal como lo vemos ahora. Solo expresaré mi opinión personal, no refleja la opinión de nuestra empresa ni de ningún grupo.

Dio la casualidad de que uso y no hago fragmentos de Postgres, sino de forma continua desde 1995 hasta el presente. Toda su historia pasó ante mis ojos, participo en los eventos principales.
La historia
En esta diapositiva, describí brevemente los proyectos en los que participé. Muchos de ellos te son familiares. Y comenzaré la historia de Postgres de inmediato con una imagen que pinté hace muchos, muchos años y luego simplemente la dibujé: el número de versiones aumenta y aumenta. Refleja la evolución de las bases de datos relacionales. A la izquierda, si alguien no lo sabe, este es
Michael Stonebreaker , quien se llama el padre de Postgres. A continuación se presentan nuestros primeros desarrolladores "nucleares". La persona sentada a la derecha es Vadim Mikheev de Krasnoyarsk, fue uno de los primeros desarrolladores principales.
Comenzaré la historia del modelo relacional con IBM, que ha hecho una gran contribución a la industria. Fue IBM quien trabajó para
Edgar Codd , el primer libro blanco sobre
IBM System R apareció de sus entrañas: fue la primera base de datos relacional. Mike Stonebreaker trabajaba en ese momento en Burkeley. Leyó este artículo y se incendió con sus muchachos: necesitamos crear una base de datos.

En esos años, a principios de los años 70, como sospechas, no había muchas computadoras. Había un PDP-11 para todo el departamento de informática en Berkeley, y todos los estudiantes y profesores lucharon por el tiempo de la máquina. Esta máquina se usó principalmente para cálculos. Yo mismo trabajé así cuando era joven: le das una tarea al operador, él la inicia. Pero los estudiantes y desarrolladores querían trabajo interactivo. Era nuestro sueño: sentarnos en el control remoto, ingresar a programas, depurarlos. Y cuando Mike Stonebreaker y sus amigos hicieron la primera base, lo llamaron
Ingres : el Sistema de Recuperación Gráfica INractiva. La gente no entendió: ¿por qué interactiva? Y fue solo el sueño de sus desarrolladores lo que se hizo realidad. Tenían un cliente de consola con el que podían trabajar con Ingres. Dio mucho de nuestra industria. ¿Ves cuántas flechas hay de Ingres? Estas son las bases de datos en las que él influyó, que confundieron su código. Michael Stonebreaker tuvo muchos estudiantes de desarrollo que se fueron y luego desarrollaron
Sybase y
MS SQL ,
NonStop SQL ,
Illustra ,
Informix .
Cuando Ingres desarrolló tanto que se volvió comercialmente interesante,
se formó Illustra (este fue el año 1992), y
Informix compró el código DBMS de
Illustra , que luego fue comido por
IBM , y por lo tanto el código fue a
DB2 . ¿Pero qué le interesaba a
IBM en
Ingres ? En primer lugar, la extensibilidad: esas ideas revolucionarias que Michael Stonebreaker estableció desde el principio, pensando que la base de datos debería estar lista para resolver cualquier problema comercial. Y para esto es necesario que pueda agregar sus tipos de datos, métodos de acceso y funciones a la base de datos. Ahora, para nosotros los postgresistas, esto parece natural. En esos años, fue una revolución. Desde la época de Ingres y Postgres, estas características, esta funcionalidad se han convertido en el estándar de facto para todas las bases de datos relacionales. Ahora todas las bases de datos tienen funciones de usuario, y cuando Stonebreaker escribió que las funciones de usuario son necesarias,
Oracle , por ejemplo, gritó que era peligroso y que esto no se podía hacer porque los usuarios podrían dañar los datos. Ahora vemos que existen funciones definidas por el usuario en todas las bases de datos, que puede hacer sus propios agregados y tipos de datos.

Postgres se desarrolló como un desarrollo académico, lo que significa: hay un profesor, él tiene una beca para el desarrollo, estudiantes y estudiantes graduados que trabajan con él. Una base seria, lista para la producción, no puede hacerse así. Sin embargo, la última versión de Berkeley,
Postgres95 , ya ha agregado
SQL . Los desarrolladores de estudiantes en ese momento ya comenzaron a trabajar en Illustra, hicieron Informix y perdieron interés en el proyecto. Dijeron: tenemos Postgres95, ¡tómalo quien lo necesite! Recuerdo todo esto muy bien porque yo mismo fui uno de los que recibió esta carta: había una lista de correo y había menos de 400 suscriptores. La comunidad
Postgres95 comenzó con estas 400 personas. Todos votamos juntos para tomar este proyecto. Encontramos un entusiasta que recogió el servidor CVS y lo arrastramos todo a Panamá, ya que los servidores estaban allí.
La historia de
PostgreSQL [simplemente Postgres en adelante] comienza con la versión 6.0, ya que las versiones 1, 4, 5 todavía eran Postgres95. El 3 de abril de 1997 apareció nuestro logotipo: un elefante. Antes de eso, teníamos diferentes animales. En mi página, por ejemplo,
hubo un guepardo durante mucho tiempo , insinuando que Postgres es muy rápido. Luego surgió una pregunta en la lista de correo: nuestra gran base de datos necesita un animal serio. Y alguien escribió: que sea un elefante. Todos votaron juntos, luego nuestros muchachos de San Petersburgo dibujaron este logotipo. Inicialmente, era un elefante en un diamante: si profundizas en una máquina del tiempo, lo verás. El elefante fue elegido porque los elefantes tienen muy buena memoria. Incluso Agatha Christie tiene una historia que "los elefantes pueden recordar": el elefante es muy vengativo allí, recordó la ofensa durante unos cincuenta años y luego aplastó al delincuente. Luego se separó el diamante, el patrón vectorizado, y el resultado fue este elefante. Esta es una de las primeras contribuciones rusas a Postgres.

Cheetah reemplazó a Elephant en el diamante:

Etapas de desarrollo de Postgres
La primera tarea fue estabilizar su trabajo. La comunidad ha adoptado el código fuente para desarrolladores académicos. Lo que no estaba allí! Comenzaron a palear todo esto para compilar decentemente. En esta diapositiva, destaqué el año 1997, versión 6.1: apareció la internacionalización. Lo destaqué no porque lo hice yo mismo (realmente fue mi primer parche), sino porque fue una etapa importante. Ya estás acostumbrado al hecho de que Postgres funciona con cualquier idioma, en cualquier lugar, en todo el mundo. Y luego entendió solo ASCII, es decir, sin 8 bits, sin idiomas europeos, sin ruso. Después de descubrir esto, siguiendo los principios del código abierto, acabo de tomar y hacer soporte para las configuraciones regionales. Y gracias a este trabajo, Postgres se fue al mundo. Después de mí, el japonés
Tatsuo Ishii apoyó las codificaciones multibyte y Postgres se convirtió en todo el mundo.
En 2005, se introdujo el soporte de
Windows . Recuerdo estos acalorados debates cuando discutían esto en la lista de correo. Todos los desarrolladores eran personas normales, trabajaban bajo
Unix . Estás aplaudiendo en este momento, y de la misma manera la gente reaccionó entonces. Y votó en contra. Duró años. Además,
SRA Computers lanzó su
Powergres , un puerto nativo de Windows, unos años antes. Pero era un producto puramente japonés. Cuando en 2005, en la octava versión, obtuvimos soporte para Windows, resultó que este era un paso fuerte: la comunidad estaba hinchada. Había mucha gente y muchas preguntas estúpidas, pero la comunidad se hizo grande, atrapamos a los usuarios de vinduzovye.
En 2010, tuvimos una replicación incorporada. Esto es un dolor Recuerdo cuántos años la gente luchó por la replicación para estar en Postgres. Al principio, todos dijeron: no necesitamos replicación, esto no es una cuestión de base de datos, se trata de utilidades externas. Si alguien recuerda,
Slony hizo a Jan Wieck. Por cierto, "elefantes" también vino del idioma ruso: Jan me preguntó cuántos "elefantes" habría en ruso, y yo respondí: "elefantes". Entonces hizo Slony. Estos elefantes funcionaron como una replicación lógica en los disparadores, configurarlos fue una pesadilla, recuerdan los veteranos. Además, todos escucharon durante mucho tiempo a
Tom Lane , quien, recuerdo, gritó desesperadamente: ¿por qué deberíamos complicar el código con la replicación, si esto se puede hacer fuera de la base? Pero como resultado, todavía apareció la replicación en línea. Esto arrojó inmediatamente una gran cantidad de usuarios empresariales, porque antes de eso, dichos usuarios decían: ¿cómo podemos vivir incluso sin replicación? Esto es imposible!
En 2014, apareció jsonb. Este es mi trabajo,
Fedor Sigaev y
Alexander Korotkov . Y también la gente gritó: ¿por qué necesitamos esto? En general, ya teníamos la hstore, que creamos en 2003, y en 2006 ingresó a Postgres. La gente lo usó maravillosamente en todo el mundo, le encantó, y si escribe
hstore en google,
aparecerá una gran cantidad de documentos. Extensión muy popular. Y promovimos fuertemente la idea de datos no estructurados en Postgres. Desde el comienzo de mi trabajo, solo estaba interesado en esto, y cuando hicimos
jsonb , recibí muchas cartas de agradecimiento y preguntas. ¡Y la comunidad tiene usuarios de
NoSQL ! Antes de jsonb, las personas zombificadas por el bombo se dirigían al valor clave de la base de datos. Al mismo tiempo, se vieron obligados a sacrificar la integridad, la identidad
ACID . Y les dimos la oportunidad, sin sacrificar nada, de trabajar con su hermosa json. La comunidad ha vuelto a crecer fuertemente.
En 2016, obtuvimos la ejecución de consultas paralelas. Si alguien no sabe, esto, por supuesto, no es para
OLTP. Si tiene una máquina cargada, todos los núcleos ya están ocupados. La ejecución simultánea de consultas es valiosa para los usuarios
OLAP . Y lo apreciaron, es decir, una cierta cantidad de usuarios
OLAP comenzaron a llegar a la comunidad.
Luego vinieron los procesos acumulativos. En 2017, recibimos replicación lógica y particionamiento declarativo; también fue un paso grande y serio porque la replicación lógica hizo posible crear sistemas muy, muy interesantes, las personas obtuvieron libertad ilimitada para su imaginación y comenzaron a hacer grupos. Usando la partición declarativa, se hizo posible no crear particiones manualmente, sino usar SQL.
En 2018, en la versión 11, obtuvimos
JIT . Quién no sabe, este es el compilador Just In Time: compila solicitudes, y realmente puede acelerar mucho la ejecución. Esto es importante para acelerar las consultas lentas porque las consultas rápidas ya son rápidas, y la sobrecarga para la compilación sigue siendo significativa.
En 2019, lo más básico que esperamos es el
almacenamiento conectable, una API para que los desarrolladores puedan crear sus propios repositorios, un ejemplo de los cuales es
zheap , el repositorio que
EnterpriseDB está desarrollando.
Y aquí está nuestro desarrollo: SQL / JSON. Realmente esperaba que
Sasha Korotkov lo comprometiera antes de la conferencia, pero hubo algunos problemas allí, y ahora esperamos que, de todos modos, obtengamos
SQL / JSON este año. La gente lo ha estado esperando durante dos años [una parte importante del SQL / JSON: el parche jsonpath se ha comprometido ahora, esto se describe en detalle
aquí ].

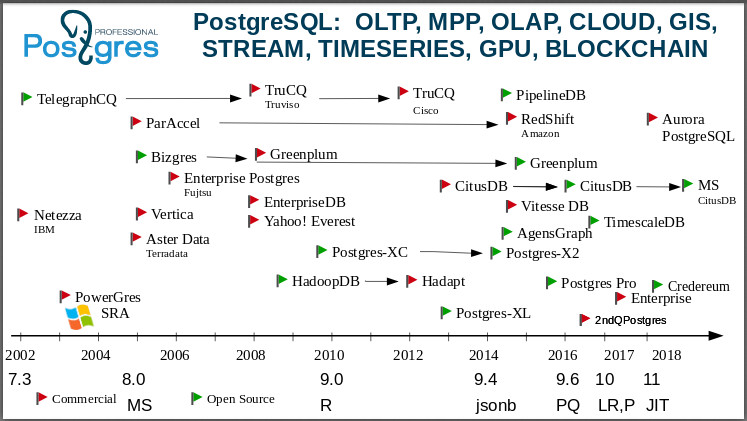
A continuación, paso a una diapositiva que muestra: Postgres es una base de datos universal. Puede estudiar esta imagen durante horas, contar un montón de historias sobre el surgimiento de empresas, la adquisición, la muerte de empresas. Comenzaré en el año 2000. Uno de los primeros tenedores de Postgres es el IBM
Netezza . ¡Imagínense: el "Gigante Azul" tomó el código de Postgres y construyó una base para OLAP para soportar su BI!
Aquí hay una bifurcación de
TelegraphCQ : ya en 2000, la gente creó una base de datos de transmisión basada en Postgres en Berkeley. Si alguien no lo sabe, esta es una base de datos que no está interesada en los datos en sí, pero sí en sus agregados. Ahora hay muchas tareas en las que no necesita conocer cada valor, por ejemplo, la temperatura en algún momento, pero necesita un valor promedio en esta región. Y en TelegraphCQ tomaron esta idea (también surgida en Berkeley), una de las ideas más avanzadas de la época, y desarrollaron una base basada en Postgres. Evolucionó aún más, y en 2008, sobre la base, se lanzó un producto comercial: la base
TruCQ , ahora su propietario es
Cisco .
Olvidé decir que no todos los tenedores están en esta página, hay el doble de ellos. Elegí lo más importante e interesante, para no saturar la imagen. La
página wiki postgresql enumera todos los tenedores. ¿Quién conoce una base de datos de código abierto que tendría tantos tenedores? No hay tales bases.
Postgres difiere de otras bases de datos no solo en su funcionalidad, sino también en que
Una comunidad muy interesante, normalmente acepta tenedores. En el mundo del código abierto, generalmente se acepta: hice una bifurcación porque estaba ofendido; no me apoyaste, así que decidí llevar a cabo mi propio desarrollo. En el mundo post-griego, la aparición de una bifurcación significa: algunas personas o alguna compañía decidieron hacer un prototipo y comprobar la funcionalidad que inventaron para experimentar. Y si tiene suerte, cree una base comercial que pueda venderse a los clientes, bríndeles servicio, etc. Al mismo tiempo, como regla general, los desarrolladores de todos estos tenedores devuelven sus logros y parches a la comunidad. El producto de nuestra empresa también es un tenedor, y está claro que devolvimos un par de parches a la comunidad. En la última versión 11, devolvimos más de 100 parches a la comunidad. Si nos fijamos en sus notas de lanzamiento, habrá 25 nombres de nuestros empleados. Este es un comportamiento normal de la comunidad. Usamos la versión de la comunidad y hacemos nuestra bifurcación para probar nuestras ideas o brindar a los clientes funcionalidad antes de que la comunidad madure para su adopción. Los tenedores en la comunidad de Postgres son muy bienvenidos.
La famosa
Vertica vino de la
C-Store , también creció de Postgres. Algunas personas afirman que Vertica no tenía el código fuente de Postgres en absoluto, sino que solo era compatible con el protocolo de postgres. Sin embargo, se acostumbra clasificarlo como un tenedor post-griego.
Greenplum . Ahora puede descargarlo y usarlo como un clúster. Se originó en
Bizgres , una base de datos paralela masiva. Luego fue comprado por Greenplum, se convirtió y durante mucho tiempo se mantuvo comercial. Pero se ve que alrededor de 2015, se dieron cuenta de que el mundo había cambiado: el mundo se estaba moviendo hacia protocolos abiertos, comunidades abiertas, bases de datos abiertas. Y abrieron los códigos de Greenplum. Ahora se están poniendo al día activamente con Postgres porque se han rezagado, por supuesto, mucho. Se han movido a 8.2, y ahora dicen que alcanzaron 9.6.
Todos amamos y no nos gusta
Amazon . Ya sabes cómo sucedió. Sucedió ante mis ojos. Había una empresa, había
ParAccel con procesamiento de vectores, también en Postgres, un producto comunitario abierto. En 2012, la astuta Amazon compró el código fuente y, literalmente, seis meses después anunció que ahora tenemos
RDS en Amazon. Luego les preguntamos, dudaron mucho tiempo, pero luego resultó que era Postgres. RDS aún vive, y este es uno de los servicios más populares de Amazon, tienen alrededor de 7,000 bases girando allí. Pero no se calmaron al respecto, y en 2010 apareció Amazon Aurora: Postgres 10 con una historia reescrita que se cose directamente en la infraestructura de Amazon, en su almacenamiento distribuido.
Echa un vistazo ahora a
Teradata . Una gran y buena empresa de análisis antigua,
OLAP . Después del G8 [PostgreSQL 8.0], surgieron los
datos de Aster .
Hadoop : tenemos Postgres en Hadoop -
HadoopDB . Después de un tiempo, se convirtió en una base cerrada de
Hadapt propiedad de
Teradata . Si ve Hadapt, sepa qué Postgres está adentro.
Un destino muy interesante con
Citus . Todos saben que esto es Postgres distribuido para análisis en línea. No admite transacciones.
Citus Data era una startup, y Citus era de código cerrado, una base de datos separada. Después de un tiempo, la gente se dio cuenta de que era mejor vivir con la comunidad, abrirse. E hicieron mucho para convertirse en una extensión de Postgres. Además, comenzaron a hacer negocios ya en la prestación de sus servicios en la nube. Todos ustedes ya saben:
MS Citus está escrito aquí porque
Microsoft los compró, literalmente hace dos semanas. Probablemente, para admitir Postgres en su
Azure , es decir, Microsoft también juega estos juegos. Tienen Postgres ejecutándose en Azure, y el equipo de desarrollo de Citus se ha unido a los desarrolladores de MS.
En general, recientemente los procesos de compra de compañías post-gres se han intensificado. Justo después de que Microsoft compró Citus, otra compañía de postgres,
credativ , compró
OmniTI para fortalecer su presencia en el mercado. Estas son dos compañías bien conocidas y sólidas. Y Amazon compró
OpenSCG . El mundo de Postgres está cambiando ahora, y te mostraré por qué hay tanto interés en Postgres.
El
aclamado TimescaleDB también
era una base de datos separada, pero ahora es una extensión: toma Postgres e instala timescaledb como una extensión y obtiene una base de datos que rompe todo tipo de bases de datos especializadas.
También hay Postgres XL, hay grupos que se están desarrollando.
Aquí en 2015, configuré nuestro tenedor:
Postgres Pro . Tenemos
Postgres Pro Enterprise , hay una versión certificada,
admitimos 1C de fábrica y somos reconocidos por
1C . Si alguien quiere probar Postgres Pro Enterprise, puede tomar el kit de distribución de forma gratuita, y si lo necesita para el trabajo, puede comprarlo.
Creamos
Credereum , una base de datos prototipo con soporte de blockchain. Ahora estamos esperando que las personas maduren para comenzar a usarlo.
Mira lo grande e interesante que es la imagen. Ni siquiera estoy hablando de
Yahoo! Everest con almacenamiento en columna, con petabytes de datos en Yahoo! - Era el año 2008. Incluso patrocinaron nuestra conferencia en Canadá, vinieron allí, en algún lugar incluso tengo una camisa desde allí :)
También hay
PipelineDB . También comenzó como una base de datos de código cerrado, pero ahora también es solo una extensión. Vemos que Citus, TimescaleDB y PipelineDB son como bases de datos separadas, pero al mismo tiempo existen como extensiones, es decir, toma el Postgres estándar y compila la extensión. PipelineDB es una continuación de la idea de las bases de datos de flujo.
¿Quieres trabajar con transmisiones? Toma Postgres, toma PipelineDB y puedes trabajar.Además, hay extensiones que le permiten trabajar con la GPU . Ver el titular? He demostrado que hay un ecosistema que abarca una gran cantidad de diferentes tipos de datos y cargas. Por lo tanto, decimos que Postgres es una base de datos universal.Base de personas favoritas
 La siguiente diapositiva tiene grandes nombres. Todas las nubes más famosas del mundo son compatibles con Postgres. En Rusia, Postgres cuenta con el apoyo de grandes empresas estatales. Lo usan y los servimos como nuestros clientes.
La siguiente diapositiva tiene grandes nombres. Todas las nubes más famosas del mundo son compatibles con Postgres. En Rusia, Postgres cuenta con el apoyo de grandes empresas estatales. Lo usan y los servimos como nuestros clientes. Ya hay muchas extensiones y muchas aplicaciones, por lo que Postgres es bueno como la base de datos desde la que se inicia el proyecto. Siempre digo a las startups: chicos, no necesitan tomar la base de datos NoSQL . Entiendo que realmente quieres, pero comienza con Postgres. Si no tiene suficiente, siempre puede desenganchar un servicio y entregarlo a una base de datos especializada. Además de la universalidad, Postgres tiene una ventaja más: una licencia BSD muy liberal, que le permite hacer cualquier cosa con su base de datos.
Ya hay muchas extensiones y muchas aplicaciones, por lo que Postgres es bueno como la base de datos desde la que se inicia el proyecto. Siempre digo a las startups: chicos, no necesitan tomar la base de datos NoSQL . Entiendo que realmente quieres, pero comienza con Postgres. Si no tiene suficiente, siempre puede desenganchar un servicio y entregarlo a una base de datos especializada. Además de la universalidad, Postgres tiene una ventaja más: una licencia BSD muy liberal, que le permite hacer cualquier cosa con su base de datos., , , Postgres — , , . Postgres ( 1984- , 1987- ), . , , . , , , ( access-), . Foreign Data Wrapper (
FDW ), , ,
Oracle ,
MySQLy otras bases.Quiero dar un ejemplo de mi propia experiencia personal. Trabajé con Postgres y cuando algo faltaba en Postgres, mis colegas y yo simplemente agregamos esta funcionalidad. Necesitábamos trabajar, por ejemplo, con el idioma ruso, e hicimos una configuración regional de 8 bits. Fue un proyecto Rambler . Por cierto, estaba en el top 5. Rambler , Postgres. Postgres , , , , . , , Postgres, , , — . , , . .

, . , hstore, : , .
GIN -, . (
pg_trgm ). NoSQL. , .

Postgres , , , . , — ! , — , , time series , — : - . , 75% , — , .

open source , ,
DB-Engines , , open source . , open source ( ) , () . -, . , ,
Gartner , : , 2022- 70% 50% open source.
Mira este pomosómero: vemos que Postgres se llama la base de datos de 2018. El año pasado, también fue la primera estimación experta independiente de motores DB. El ranking muestra que Postgres está realmente por delante del resto. Está en términos absolutos en cuarto lugar, pero mira cómo crece. Claro que bien. En la diapositiva, esta es una línea azul. El resto, MySQL, Oracle, MS SQL, se equilibra a su nivel o comienza a doblarse. Noticias de hackers : probablemente todos lo lean o Y Combinator
Noticias de hackers : probablemente todos lo lean o Y Combinator — , , . , - 2014- , Postgres . 1- MySQL, Postgres , ( ) .
 Stack Overflow
Stack Overflow .
most used Postgres , .
most loved — . .
Redis , Postgres .
most dreaded — , , , . « », .

,
HighLoad++ . ,
. : Postgres №1.
 HH.ru
HH.ru , Postgres. 9 Postgres Oracle 10 , : . , , 2018- . , , : 2 HH.ru Postgres. , .
 Para que sea más fácil de ver, tomé una foto donde mostraba las vacantes de Postgres con respecto a las vacantes de Oracle. Hubo menos, a partir de 2018 ya están a la par, y ahora Postgres ya se ha vuelto un poco más. Hasta ahora, es un poco deprimente que el número absoluto de vacantes de Oracle también esté creciendo, lo que en principio no debería ser. Pero, como dicen, estamos sentados cerca de la orilla del río y observamos: ¿cuándo pasará el cadáver del enemigo? Solo estamos haciendo nuestro trabajo.
Para que sea más fácil de ver, tomé una foto donde mostraba las vacantes de Postgres con respecto a las vacantes de Oracle. Hubo menos, a partir de 2018 ya están a la par, y ahora Postgres ya se ha vuelto un poco más. Hasta ahora, es un poco deprimente que el número absoluto de vacantes de Oracle también esté creciendo, lo que en principio no debería ser. Pero, como dicen, estamos sentados cerca de la orilla del río y observamos: ¿cuándo pasará el cadáver del enemigo? Solo estamos haciendo nuestro trabajo.
Comunidad rusa de Postgres
, . , , . — : - , , , .

. , , youtube «»,
DBA1 ,
DBA2 ,
DBA3 , .
— , , . : .
 A menudo preguntan: ¿cuánto ruso Postgres? La pregunta está un poco fuera de lugar: Postgres es internacional. Pero diré un poco sobre la bandera rusa. Ves en la diapositiva lo que hizo Vadim Mikheev . Quienes conocen Postgres entienden que MVCC , WAL , VACUUM , etc. significan para esta base . Esta es toda la contribución rusa. Ahora hay tres desarrolladores líderes de Postgres, de los cuales dos son committers. En la diapositiva se ve que se ha hecho mucho. Si observa las características principales de las notas de la versión, verá nuestra contribución. La contribución rusa es lo suficientemente sustancial. Trabajamos desde el principio y seguimos trabajando con la comunidad, ya a nivel de campaña.
A menudo preguntan: ¿cuánto ruso Postgres? La pregunta está un poco fuera de lugar: Postgres es internacional. Pero diré un poco sobre la bandera rusa. Ves en la diapositiva lo que hizo Vadim Mikheev . Quienes conocen Postgres entienden que MVCC , WAL , VACUUM , etc. significan para esta base . Esta es toda la contribución rusa. Ahora hay tres desarrolladores líderes de Postgres, de los cuales dos son committers. En la diapositiva se ve que se ha hecho mucho. Si observa las características principales de las notas de la versión, verá nuestra contribución. La contribución rusa es lo suficientemente sustancial. Trabajamos desde el principio y seguimos trabajando con la comunidad, ya a nivel de campaña.
— . 2 Postgres. , , . , , . . .
Postgres profesionales
Pasemos a la principal. Academic Postgres, cuando comenzó, fue diseñado para varias docenas de usuarios. La comunidad Postgres95 tenía menos de 400 personas. La comunidad estaba compuesta principalmente por desarrolladores y pocos usuarios más. Al mismo tiempo, un detalle interesante, los desarrolladores fueron principalmente clientes y contratistas. Por ejemplo, cuando lo necesitaba, lo desarrollé para mí y, al mismo tiempo, lo compartí con todos. Es decir, la comunidad se estaba desarrollando para la comunidad.
A partir del año 2000, un poco antes, comenzaron a aparecer las primeras compañías posteriores a Grace:
GreatBridge ,
2ndQuadrant ,
EDB . Ya contrataron desarrolladores de tiempo completo que trabajaban para la comunidad. Aparecieron los primeros tenedores empresariales y los primeros personalizadores empresariales. Esto llevó al hecho de que para 2015 el número principal, y casi todos los desarrolladores líderes, ya estaban organizados en algunas empresas. En 2015, se formó nuestra empresa: fuimos los últimos desarrolladores independientes independientes. Ahora prácticamente no hay tales personas. La comunidad de postgres ha cambiado, se ha convertido en una empresa, y ahora estas compañías están impulsando el desarrollo. Esto es bueno porque estas empresas llevan a cabo lo que la empresa necesita. La comunidad es un freno en el buen sentido: prueba características, condena o acepta nuevas características, nos une a todos. Y Postgres se ha
preparado para la empresa , las grandes empresas están felices de usarlo, se ha vuelto profesional.

Esta diapositiva es sobre el futuro, tal como lo veo. Con la llegada del
almacenamiento enchufable , aparecerán nuevos almacenes:
solo anexos, solo lectura ,
almacenamiento en columnas , lo que quieras (por ejemplo, sueño con el parquet). Habrá soporte para operaciones vectoriales. Hoy, por cierto, habrá un informe sobre ellos. Blockchain será compatible. No hay forma de escapar de esto, ya que nos estamos moviendo a la economía digital, a las tecnologías sin papel. Deberá usar firmas electrónicas y deberá poder autenticar su base de datos, asegurarse de que nadie haya cambiado nada, y la cadena de bloques es muy adecuada para esto.


Siguiente:
Postgres adaptativos . Este es un tema un poco triste para ti, pero aún está muy lejos de ti. El hecho es que DBA, en términos generales, es un recurso costoso, y pronto las bases de datos no los necesitarán. Las bases serán lo suficientemente inteligentes y se configurarán y ajustarán por sí mismas. Pero será dentro de otros diez años, probablemente. Todavía tenemos mucho tiempo.

Y está claro que en Postgres habrá soporte nativo para las nubes, el almacenamiento en la nube; sin esto, simplemente no podemos sobrevivir. Y, por supuesto, aquí está, la última diapositiva:
¡TODO LO QUE NECESITAS ES POSTGRES!

Gracias por su atencion