
Fuente de la imagen: www.nikonsmallworld.com
El antiplagio es un motor de búsqueda especializado, sobre el que ya se escribió anteriormente . Y cualquier motor de búsqueda, sea lo que sea que se diga, para funcionar rápidamente, necesita su propio índice, que tenga en cuenta todas las características del área de búsqueda. En mi primer artículo sobre Habr, hablaré sobre la implementación actual de nuestro índice de búsqueda, el historial de su desarrollo y las razones para elegir una u otra solución. Los algoritmos .NET efectivos no son un mito, sino una realidad dura y productiva. Nos sumergiremos en el mundo del hash, la compresión bit a bit y los cachés prioritarios de varios niveles. ¿Qué sucede si necesita una búsqueda más rápida que O (1) ?
Si alguien más no sabe dónde están las tejas en esta imagen, bienvenido ...
El herpes zóster, el índice y por qué buscarlos
Una teja es un texto de unas pocas palabras de tamaño. Las ripias se superponen una tras otra, de ahí el nombre (inglés, ripias - escamas, mosaico). Su tamaño específico es un secreto a voces: 4 palabras. O 5? Bueno, depende Sin embargo, incluso este valor da poco y depende de la composición de las palabras de detención, el algoritmo para normalizar las palabras y otros detalles que no son significativos en el marco de este artículo. Al final, calculamos el hash de 64 bits en función de esta tabla, que llamaremos tabla en el futuro.
Según el texto del documento, puede crear muchas tejas, cuyo número es comparable al número de palabras en el documento:
texto: cadena → ripias: uint64 []
Si varias tejas coinciden en dos documentos, suponemos que los documentos se cruzan. Cuanto más coinciden las tejas, el texto más idéntico está en este par de documentos. El índice busca documentos que tengan el mayor número de intersecciones con el documento que se está verificando.

Fuente de la imagen: Wikipedia
El índice de herpes zóster le permite realizar dos operaciones principales:
Indice las tejas de los documentos con sus identificadores:
index.Add (docId, ripias)
Busque y muestre una lista clasificada de identificadores para documentos superpuestos:
index.Search (culebrilla) → (docId, score) []
El algoritmo de clasificación, creo, es digno de un artículo separado en general, por lo que no vamos a escribir sobre él aquí.
El índice de herpes zóster es muy diferente de los conocidos hermanos de texto completo, como Sphinx, Elastic o más grandes: Google, Yandex, etc. ... Por un lado, no requiere ninguna PNL y otras alegrías de la vida. Todo el procesamiento de texto se elimina y no afecta el proceso, así como la secuencia de las tejas en el texto. Por otro lado, la consulta de búsqueda no es una palabra o una frase de varias palabras, sino hasta varios cientos de miles de hashes , que son importantes en conjunto, y no por separado.
Hipotéticamente, puede usar el índice de texto completo como reemplazo del índice de herpes zóster, pero las diferencias son demasiado grandes. La forma más fácil de usar un almacenamiento clave-valor conocido, se mencionará a continuación. Estamos aserrando nuestra implementación de bicicleta , que se llama - ShingleIndex.
¿Por qué nos molestamos tanto? Pero por qué.
- Volúmenes :
- Hay muchos documentos Ahora tenemos alrededor de 650 millones de ellos, y este año obviamente habrá más;
- El número de tejas únicas está creciendo a pasos agigantados y ya está llegando a cientos de miles de millones. Estamos esperando un billón.
- Velocidad :
- Durante el día, durante la sesión de verano, se verifican más de 300 mil documentos a través del sistema antiplagio . Esto es un poco para los estándares de los motores de búsqueda populares, pero se mantiene en tono;
- Para una verificación exitosa de los documentos para la unicidad, el número de documentos indexados debe ser de un orden de magnitud mayor que los documentos que se verifican. La versión actual de nuestro índice en promedio puede llenarse a una velocidad de más de 4000 documentos medianos por segundo.
¡Y todo está en una máquina! Sí, podemos replicar , nos estamos acercando gradualmente a la fragmentación dinámica en un clúster, pero desde 2005 hasta hoy, el índice en una máquina con cuidado ha podido hacer frente a todas las dificultades anteriores.
Experiencia extraña
Sin embargo, ahora tenemos mucha experiencia. Nos guste o no, pero nosotros también hemos crecido y hemos intentado diferentes cosas en el curso del crecimiento, que es divertido recordar ahora.
Fuente de la imagen: Wikipedia
En primer lugar, un lector inexperto querría usar una base de datos SQL. No son los únicos que piensan que sí, la implementación de SQL nos ha servido durante varios años para implementar colecciones muy pequeñas. Sin embargo, la atención se centró inmediatamente en millones de documentos, así que tuve que ir más allá.
Como saben, a nadie le gustan las bicicletas, y LevelDB aún no era público, por lo que en 2010 nuestros ojos se posaron en BerkeleyDB. Todo es genial: una persistente base de valor-clave incorporada con métodos adecuados de acceso btree y hash y una larga historia. Todo con ella fue maravilloso, pero:
- En el caso de una implementación hash, cuando alcanzó un volumen de 2 GB, simplemente cayó. Sí, todavía estábamos trabajando en modo de 32 bits;
- La implementación del árbol B + funcionó de manera estable, pero con volúmenes de más de unos pocos gigabytes, la velocidad de búsqueda comenzó a disminuir significativamente.
Tenemos que admitir que nunca encontramos una manera de adaptarlo a nuestra tarea. Tal vez el problema está en los enlaces .net, que aún tenían que terminarse. La implementación de BDB finalmente se usó como un reemplazo para SQL como un índice intermedio antes de completar el principal.
El tiempo paso En 2014, probaron LMDB y LevelDB, pero no lo implementaron. Los chicos de nuestro Departamento de Investigación Antiplagio utilizaron RocksDB como su índice. A primera vista, fue un hallazgo. Pero la lenta reposición y la velocidad de búsqueda mediocre, incluso a pequeños volúmenes, dejaron todo en nada.
Hicimos todo lo anterior, mientras desarrollamos nuestro propio índice personalizado. Como resultado, se volvió tan bueno resolviendo nuestros problemas que abandonamos los "enchufes" anteriores y nos enfocamos en mejorarlo, que ahora usamos en la producción en todas partes.
Capas de índice
Al final, ¿qué tenemos ahora? De hecho, el índice de herpes zóster consta de varias capas (matrices) con elementos de longitud constante, de 0 a 128 bits, que depende no solo de la capa y no es necesariamente un múltiplo de ocho.
Cada una de las capas juega un papel. Algunos agilizan la búsqueda, otros ahorran espacio y otros nunca se usan, pero realmente se necesitan. Intentaremos describirlos para aumentar su eficiencia total en la búsqueda.

Fuente de la imagen: Wikipedia
1. Matriz de índice
Sin pérdida de generalidad, ahora consideraremos que se asigna una sola teja al documento,
(docId → guijarro)
Cambiaremos los elementos del par (¡invierte, porque el índice está realmente "invertido"),
(teja → docId)
Ordenar por los valores de las tejas y formar una capa. Porque los tamaños de la teja y el identificador del documento son constantes, ahora cualquiera que entienda la búsqueda binaria puede encontrar un par más allá de las lecturas O (log) del archivo. Qué mucho, muchísimo. Pero esto es mejor que solo O (n) .
Si el documento tiene varias tejas, habrá varios pares de ese tipo en el documento. Si hay varios documentos con la misma teja, entonces esto tampoco cambiará mucho: habrá varios pares seguidos con la misma teja. En ambos casos, la búsqueda durará un tiempo comparable.
2. Matriz de grupos
Dividimos cuidadosamente los elementos del índice del paso anterior en grupos de cualquier manera conveniente. Por ejemplo, para que encajen en el sector del clúster, el bloque de la unidad de asignación (lectura, 4096 bytes), teniendo en cuenta el número de bits y otros trucos, formará un diccionario efectivo. Obtenemos un conjunto simple de posiciones de tales grupos:
group_map (hash (shingle)) -> group_position.
Al buscar una teja, ahora primero buscaremos la posición del grupo en este diccionario, y luego descargaremos el grupo y buscaremos directamente en la memoria. Toda la operación requiere dos lecturas.
El diccionario de posiciones grupales ocupa varios órdenes de magnitud menos espacio que el índice en sí, a menudo se puede descargar simplemente en la memoria. Por lo tanto, no habrá dos lecturas, sino una. Total, O (1) .
3. Filtro de floración
En las entrevistas, los candidatos a menudo resuelven problemas emitiendo soluciones únicas con O (n ^ 2) o incluso O (2 ^ n) . Pero no hacemos cosas estúpidas. ¿Hay O (0) en el mundo, esa es la pregunta? Probemos sin mucha esperanza un resultado ...
Pasemos al área temática. Si el estudiante está bien hecho y escribió el trabajo él mismo, o simplemente no hay texto, sino basura, entonces una parte significativa de su culebrilla será única y no se encontrará en el índice. Una estructura de datos como el filtro Bloom es bien conocida en el mundo. Antes de buscar, verifique la teja en él. Si no hay guijarros en el índice, entonces no puede buscar más, de lo contrario, vaya más allá.
El filtro Bloom en sí es bastante simple, pero no tiene sentido usar un vector hash con nuestros volúmenes. Es suficiente usar uno: +1 lectura del filtro Bloom. Esto proporciona -1 o -2 lecturas de las etapas posteriores, en caso de que la teja sea única y no haya falsos positivos en el filtro. Mira tus manos!
La probabilidad de un error de filtro Bloom se establece durante la construcción; la probabilidad de una teja desconocida está determinada por la honestidad del estudiante. Los cálculos simples pueden llegar a la siguiente dependencia:
- Si confiamos en la honestidad de las personas (es decir, de hecho el documento es original), la velocidad de búsqueda disminuirá;
- Si el documento está claramente cosido, la velocidad de búsqueda aumentará, pero necesitamos mucha memoria.
Con la confianza en los estudiantes, tenemos el principio de "confiar, pero verificar", y la práctica muestra que todavía hay una ganancia del filtro Bloom.
Dado que esta estructura de datos también es más pequeña que el índice en sí y puede almacenarse en caché, en el mejor de los casos, le permite soltar la teja sin ningún acceso al disco.
4. colas pesadas
Hay herpes zóster que se encuentran en casi todas partes. Su participación en el número total es escasa, pero al construir el índice en el primer paso, en el segundo, se pueden obtener grupos de decenas y cientos de MB de tamaño. Los recordaremos por separado y los descartaremos inmediatamente de la consulta de búsqueda.
Cuando este paso trivial se utilizó por primera vez en 2011, el tamaño del índice se redujo a la mitad y la búsqueda en sí misma se aceleró.
5. Otras colas
Aun así, una teja puede tener muchos documentos. Y esto es normal. Decenas, cientos, miles ... Mantenerlos dentro del índice principal deja de ser rentable, también pueden no encajar en el grupo, esto hace que el volumen del diccionario de posiciones grupales se infle. Póngalos en una secuencia separada con un almacenamiento más eficiente. Según las estadísticas, tal decisión está más que justificada. Además, varios paquetes bit a bit pueden reducir el número de accesos al disco y el volumen del índice.
Como resultado, para facilitar el mantenimiento, imprimimos todas estas capas en un archivo grande: fragmento. Hay diez de esas capas en él. Pero la parte no se usa en la búsqueda, la parte es muy pequeña y siempre se almacena en la memoria, la parte se almacena en caché de forma activa según sea necesario / posible.
En la batalla, la búsqueda de guijarros se reduce a una o dos lecturas aleatorias de archivos. En el peor de los casos, tienes que hacer tres. Todas las capas son conjuntos de elementos de longitud constante (a veces bit a bit). Tal es la normalización. El tiempo para desempacar es insignificante en comparación con el precio del volumen total durante el almacenamiento y la capacidad de almacenar en caché mejor.
Al construir, los tamaños de las capas se calculan principalmente por adelantado, escritos secuencialmente, por lo que este procedimiento es bastante rápido.
¿Cómo llegaste allí? No sabía dónde
2010 , . , . , .

Fuente de la imagen: Wikipedia
Inicialmente, nuestro índice constaba de dos partes: una constante, descrita anteriormente, y una temporal, cuyo rol era SQL o BDB, o su propio registro de actualización. Ocasionalmente, por ejemplo, una vez al mes (y a veces un año), el temporal se clasifica, filtra y combina con el principal. El resultado fue unificado, y los dos viejos fueron eliminados. Si el temporal no podía caber en la RAM, entonces el procedimiento pasó por una clasificación externa.
Este procedimiento fue bastante problemático, comenzó en modo semi-manual y requería reescribir todo el archivo de índice desde cero. Reescribir cientos de gigabytes para un par de millones de documentos, bueno, más o menos placer, te digo ...
Recuerdos del pasado ...SSD. , 31 SSD wcf- . , . , .
Para que el SSD no esté particularmente tenso, y el índice se actualice con más frecuencia, en 2012 involucramos una cadena de varias piezas, fragmentos de acuerdo con el siguiente esquema:

Aquí el índice consiste en una cadena del mismo tipo de fragmentos, excepto el primero. El primero, el complemento, era un registro de solo agregado con un índice en RAM. Los fragmentos posteriores aumentaron de tamaño (y edad) hasta el último (cero, principal, raíz, ...).
Nota para los ciclistas ...A veces no deberías perder el tiempo para escribir código y ni siquiera pensar, sino simplemente buscarlo en Google más a fondo. Hasta la notación, el diagrama es similar a este del artículo de 1996
"El árbol de fusión estructurado de registro" :
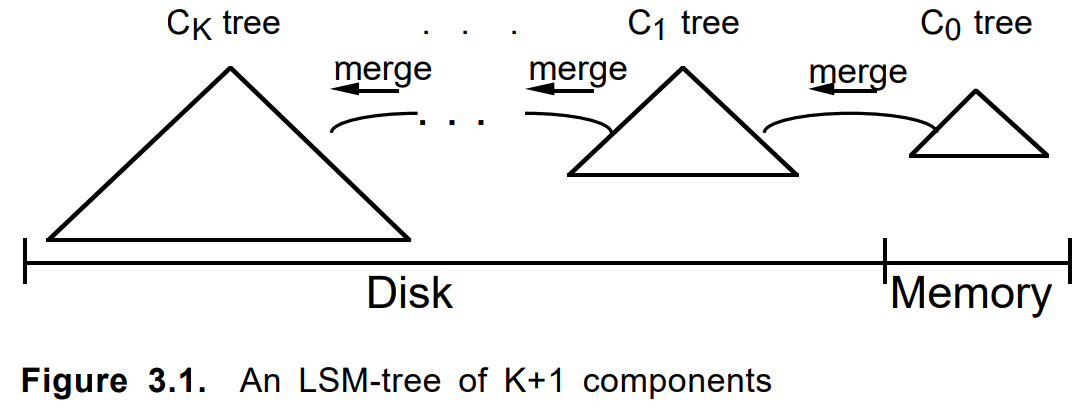
Al agregar un documento, primero se dobló en un complemento. Cuando estaba lleno o por otros criterios, se construyó un fragmento permanente sobre él. Los varios fragmentos vecinos, si es necesario, se fusionaron en uno nuevo, y los originales se eliminaron. Actualizar un documento o eliminarlo funcionó de la misma manera.
Criterios de fusión, longitud de cadena, algoritmo de derivación, contabilidad de elementos eliminados y actualizaciones, se ajustaron otros parámetros. El enfoque en sí estaba involucrado en varias tareas similares y tomó forma como un marco LSM interno separado en un .net limpio. Casi al mismo tiempo, LevelDB se hizo popular.
Pequeña observación sobre el árbol LSMLSM-Tree es un algoritmo bastante interesante, con buena justificación. Pero, en mi humilde opinión, había algo borroso del significado del término árbol. En el
artículo original
, se trataba de una cadena de árboles con la capacidad de transferir ramas. En implementaciones modernas, este no es siempre el caso. Entonces, nuestro marco finalmente se denominó LsmChain, es decir, la cadena de fragmentos lsm.
El algoritmo LSM en nuestro caso tiene características muy adecuadas:
- inserción / eliminación / actualización instantánea,
- carga reducida en SSD durante la actualización,
- formato de fragmentos simplificado,
- búsqueda selectiva solo en fragmentos viejos / nuevos,
- copia de seguridad trivial
- ¿Qué más quiere el alma?
- ...
En general, a veces es útil inventar bicicletas para el autodesarrollo.
Macro, micro, nano optimización
Y finalmente, compartiremos consejos técnicos sobre cómo nosotros en el antiplagio hacemos tales cosas en .Net (y no solo en él).
Tenga en cuenta de antemano que a menudo todo depende en gran medida de su hardware específico, datos o modo de uso. Después de retorcernos en un lugar, salimos del caché de la CPU, en otro, nos encontramos con el ancho de banda de la interfaz SATA, en el tercero, comenzamos a colgarnos en el GC. Y en algún lugar de la ineficiencia de la implementación de una llamada específica al sistema.

Fuente de la imagen: Wikipedia
Trabajar con archivo
El problema con el acceso al archivo no es exclusivo de nosotros. Hay un archivo grande de terabyte exabyte , cuyo volumen es muchas veces mayor que la cantidad de RAM. La tarea es leer el millón disperso a su alrededor de algunos pequeños valores aleatorios. Y hacerlo de forma rápida, eficiente y económica. Tenemos que exprimir, comparar y pensar mucho.
Comencemos con uno simple. Para leer el byte atesorado que necesita:
- Abrir archivo (nuevo FileStream);
- Muévase a la posición deseada (Posición o Búsqueda, sin diferencia);
- Lea la matriz de bytes deseada (Leer);
- Cierre el archivo (desechar).
Y esto es malo, porque es largo y triste. Mediante prueba, error y pasos repetidos en el rastrillo, identificamos el siguiente algoritmo de acciones:
Solo abierto, lectura múltiple
Si esta secuencia se realiza en la frente, por cada solicitud al disco, nos doblaremos rápidamente. Cada uno de estos elementos entra en una solicitud al núcleo del sistema operativo, que es costoso.
Obviamente, debe abrir el archivo una vez y leer de forma secuencial todos nuestros millones de valores, lo cual hacemos
Nada extra
Obtener el tamaño del archivo, la posición actual en él también es operaciones bastante difíciles. Incluso si el archivo no cambió.
Deben evitarse consultas como obtener el tamaño del archivo o la posición actual en él.
Filestreampool
Siguiente Por desgracia, FileStream es esencialmente de un solo subproceso. Si desea leer un archivo en paralelo, deberá crear / cerrar nuevas secuencias de archivos.
Hasta que crees algo como aiosync, tienes que inventar tus propias bicicletas.
Mi consejo es crear un grupo de secuencias de archivos por archivo. Esto evitará perder tiempo abriendo / cerrando un archivo. Y si lo combina con ThreadPool y tiene en cuenta que el SSD emite sus megaIOPS con un fuerte subprocesamiento múltiple ... Bueno, me comprende.
Unidad de asignación
Siguiente Los dispositivos de almacenamiento (HDD, SSD, Optane) y el sistema de archivos funcionan con archivos a nivel de bloque (clúster, sector, unidad de asignación). Puede que no coincidan, pero ahora casi siempre son 4096 bytes. Leer uno o dos bytes en el borde de dos de estos bloques en un SSD es aproximadamente una vez y media más lento que dentro del bloque mismo.
Debe organizar sus datos para que los elementos restados se encuentren dentro de los límites del bloque de sector del clúster .
Sin tampón.
Siguiente FileStream utiliza de forma predeterminada un búfer de 4096 bytes. Y la mala noticia es que no puedes apagarlo. Sin embargo, si está leyendo más datos que el tamaño del búfer, este último será ignorado.
Para la lectura aleatoria, debe establecer el búfer en 1 byte (no funcionará menos) y luego considerar que no se usa.
Usar tampón.
Además de las lecturas aleatorias, también hay lecturas secuenciales. Aquí el búfer ya puede ser útil si no desea leer todo de una vez. Te aconsejo que comiences con este artículo . El tamaño del búfer para configurar depende de si el archivo está en el HDD o en el SSD. En el primer caso, 1 MB será óptimo; en el segundo, 4 KB estándar serán suficientes. Si el tamaño del área de datos a leer es comparable con estos valores, entonces es mejor restarlo de una vez, omitiendo el búfer, como en el caso de la lectura aleatoria. Los amortiguadores grandes no generarán ganancias en velocidad, pero comenzarán a afectar a GC.
Al leer secuencialmente grandes partes del archivo, debe establecer el búfer en 1 MB para HDD y 4 KB para SSD. Bueno, depende
MMF vs FileStream
En 2011, llegó un consejo a MemoryMappedFile, ya que este mecanismo se ha implementado desde .Net Framework v4.0. Primero, lo usaron cuando almacenaron en caché el filtro Bloom, que ya era inconveniente en el modo de 32 bits debido a la limitación de 4 GB. Pero cuando me mudé al mundo de 64 bits, quería más. Las primeras pruebas fueron impresionantes. Caché gratuito, velocidad anormal, interfaz de lectura de estructura conveniente. Pero hubo problemas:
- Primero, curiosamente, la velocidad. Si los datos ya están en caché, entonces todo está bien. Pero si no, la lectura de un byte del archivo fue acompañada por una "elevación" de una cantidad de datos mucho mayor de lo que sería con una lectura regular.
- En segundo lugar, curiosamente, la memoria. Cuando se calienta, la memoria compartida crece, funcionamiento, no, lo cual es lógico. Pero entonces los procesos vecinos comienzan a comportarse no muy bien. Pueden entrar en un intercambio o caerse accidentalmente de OoM. El volumen ocupado por el MMF en RAM, por desgracia, no se puede controlar. Y el beneficio del caché en el caso en que el archivo legible es un par de órdenes de magnitud mayor que la memoria deja de tener sentido.
El segundo problema aún podría ser combatido. Desaparece si el índice funciona en Docker o en una máquina virtual dedicada. Pero el problema de la velocidad fue fatal.
Como resultado, el MMF fue abandonado un poco más que completamente. El almacenamiento en caché en el antiplagio comenzó a hacerse de forma explícita, si es posible, manteniendo en la memoria las capas más utilizadas en las prioridades y límites dados.

Fuente de la imagen: Wikipedia
Bits / bytes
No bytes, el mundo es uno. A veces necesitas bajar al nivel de bits.
Por ejemplo: suponga que tiene un billón de números parcialmente ordenados, ansiosos por guardar y leer con frecuencia. ¿Cómo trabajar con todo esto?
- Simple BinaryWriter.Write? - Rápido pero lento. El tamaño sí importa. La lectura en frío depende principalmente del tamaño del archivo.
- ¿Otra variación de VarInt? - Rápido pero lento. La consistencia importa. El volumen comienza a depender de los datos, lo que requiere memoria adicional para el posicionamiento.
- Poco de embalaje? - Rápido pero lento. Tienes que controlar más cuidadosamente tus manos.
No existe una solución ideal, pero en el caso específico, simplemente comprimiendo el rango de 32 bits al necesario para almacenar las colas ahorró un 12% más (¡decenas de GB!) Que VarInt (ahorrando solo la diferencia de las vecinas, por supuesto), y eso es varias veces Opción básica.
Otro ejemplo. Tiene un enlace en un archivo a una serie de números. Enlace de 64 bits, archivo por terabyte. Todo parece estar bien. A veces hay muchos números en la matriz, a veces pocos. A menudo un poco Muy a menudo. Luego, simplemente tome y almacene toda la matriz en el enlace. Ganancia Empaca con cuidado pero no lo olvides.
Estructura, inseguro, procesamiento por lotes, microopciones
Bueno y otra microoptimización. No escribiré aquí sobre el banal "¿vale la pena guardar la longitud de la matriz en un bucle" o "que es más rápido, para o para siempre".
Hay dos reglas simples y las cumpliremos: 1. "comparar todo", 2. "más benchmark".
Estructura Usado en todas partes. No envíe GC. Y, como está de moda hoy, también tenemos nuestra propia ValueList mega-rápida.
Inseguro Permite estructuras mapit (y unmap) a una matriz de bytes cuando se usa. Por lo tanto, no necesitamos medios separados de serialización. Es cierto que hay preguntas para fijar y desfragmentar el montón, pero hasta ahora no se ha mostrado. Bueno, depende
Lote . El trabajo con muchos elementos debe realizarse a través de paquetes / grupos / bloques. Leer / escribir archivo, transferir entre funciones. Otro problema es el tamaño de estos paquetes. Por lo general, hay un óptimo, y su tamaño suele estar en el rango de 1kB a 8MB (tamaño de caché de CPU, tamaño de clúster, tamaño de página, tamaño de otra cosa). Intente bombear a través de la función IEnumerable <byte> o IEnumerable <byte [1024]> y sienta la diferencia.
Pooling Cada vez que escribes "nuevo", un gatito muere en algún lugar. Una vez nuevo byte [ 85000 ] - y el tractor montó una tonelada de gansos. Si no es posible usar stackalloc, cree un grupo de objetos y vuelva a usarlo.
En línea . ¿Cómo crear dos funciones en lugar de una puede acelerar todo diez veces? Simple Cuanto más pequeño sea el tamaño del cuerpo de la función (método), más probable será que esté en línea. Desafortunadamente, en el mundo dotnet todavía no hay forma de hacer una alineación parcial, por lo que si tiene una función activa que en el 99% de los casos sale después de procesar las primeras líneas, y las cien líneas restantes van a procesar el 1% restante, luego divídalo con seguridad dos (o tres), llevando la pesada cola a una función separada.
Que mas
Span <T> , Memoria <T> - prometedora. El código será más simple y quizás un poco más rápido. Estamos esperando el lanzamiento de .Net Core v3.0 y Std v2.1 para cambiar a ellos, porque nuestro núcleo en .Net Std v2.0, que normalmente no admite tramos.
Asíncrono / espera - hasta ahora controvertido. Los puntos de referencia de lectura aleatoria más simples mostraron que el consumo de CPU en realidad está disminuyendo, pero la velocidad de lectura también está disminuyendo. Debo mirar. Todavía no lo estamos usando dentro del índice.
Conclusión
Espero que mi lejanía le dé placer al comprender la belleza de algunas decisiones. Realmente nos gusta nuestro índice. Es eficiente, hermoso código, funciona muy bien. Una solución altamente especializada en el núcleo del sistema, el lugar crítico de su trabajo, es mejor que la general. Nuestro sistema de control de versiones recuerda las inserciones de ensamblador en código C ++. Ahora hay cuatro ventajas: solo C # puro, solo .Net. En él escribimos incluso los algoritmos de búsqueda más complejos y no nos arrepentimos en absoluto. Con la llegada de .Net Core, la transición a Docker, el camino hacia un futuro brillante de DevOps se ha vuelto más fácil y claro. A continuación está la solución del problema de la fragmentación y replicación dinámica sin reducir la efectividad y la belleza de la solución.
Gracias a todos los que leyeron hasta el final. Para todas las discrepancias y otras inconsistencias, escriba comentarios. Estaré encantado de cualquier consejo razonable y refutación en los comentarios.