Desde 1999, nuestro banco ha estado utilizando el sistema bancario BISKVIT integrado en la plataforma Progress OpenEdge para dar servicio a la oficina administrativa, que se usa ampliamente en todo el mundo, incluso en el sector financiero. El rendimiento de este DBMS le permite leer hasta un millón o más registros por segundo en una base de datos (DB). Nuestro Progress OpenEdge atiende a aproximadamente 1.5 millones de depósitos de personas físicas y aproximadamente 22.2 millones de contratos para productos activos (préstamos para automóviles e hipotecas), y también es responsable de todos los acuerdos con el regulador (CB) y SWIFT.

Al utilizar Progress OpenEdge, nos enfrentamos al hecho de que necesitamos hacer amigos con Oracle DBMS. Inicialmente, este paquete era el "cuello de botella" de nuestra infraestructura, hasta que instalamos y configuramos Pro2 CDC, un producto de Progress que le permite enviar datos de Progress DBMS a Oracle DBMS directamente, en línea. En esta publicación, explicaremos en detalle, con todas las dificultades, cómo hacer amigos de manera efectiva con OpenEdge y Oracle.
Cómo fue: cargar datos a QCD a través del intercambio de archivos
Primero, algunos datos sobre nuestra infraestructura. El número de usuarios activos de la base de datos es de aproximadamente 15 mil. El volumen de todas las bases de datos productivas, incluidas las réplicas y en espera, es de 600 TB, la base de datos más grande es de 16,5 TB. Al mismo tiempo, las bases de datos se reponen constantemente: solo en el último año, se han agregado aproximadamente 120 TB de datos productivos. El sistema proporciona 150 servidores front-end en la plataforma x86. Las bases de datos están alojadas en 21 servidores de la plataforma IBM.
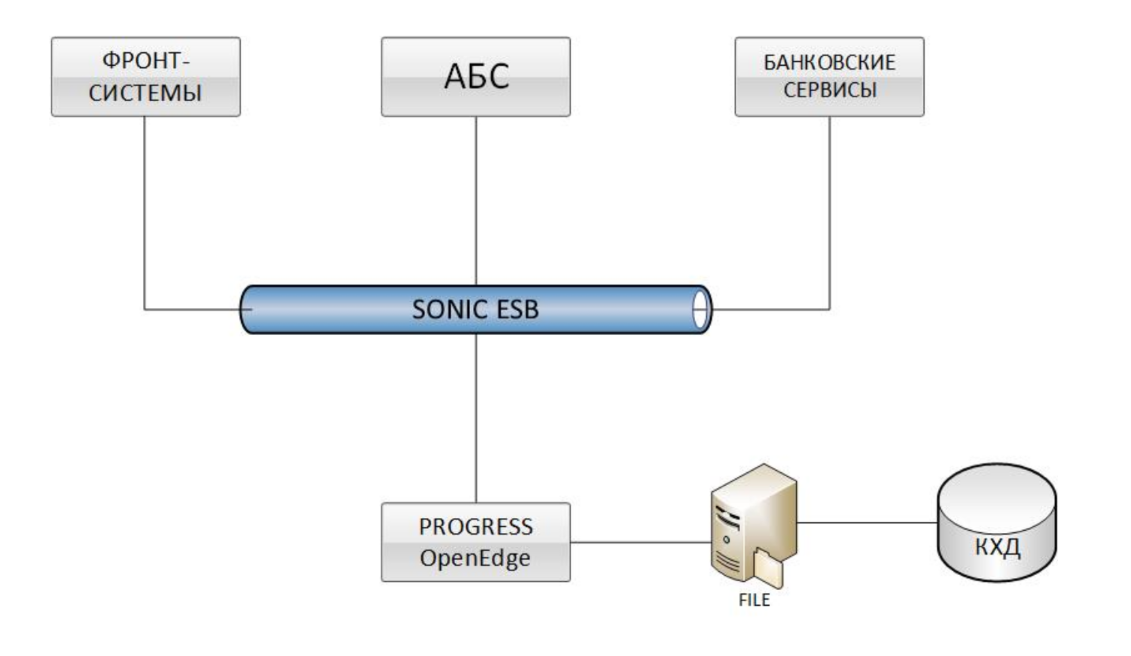
Los sistemas frontales, varios ABS y servicios bancarios están integrados con OpenEdge Progress (IBS BISQUIT) a través del bus Sonic ESB. Los datos se cargan a QCD a través del intercambio de archivos. Tal solución hasta cierto punto en el tiempo inmediatamente tuvo dos grandes problemas: el bajo rendimiento de cargar información en el almacén de datos corporativos (QCD) y el largo tiempo que lleva conciliar los datos (conciliación) con otros sistemas.
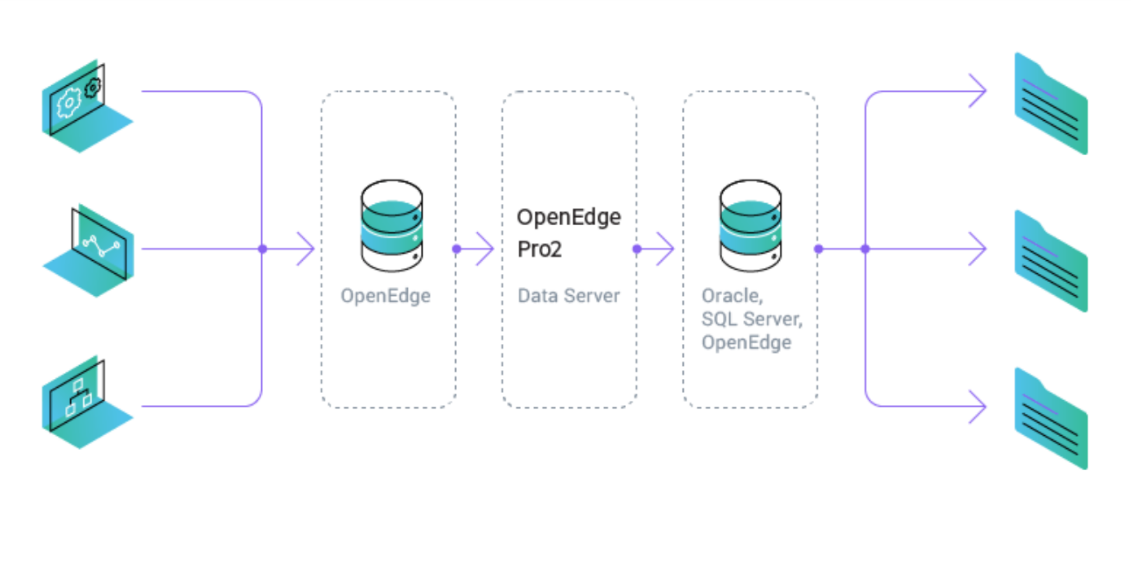
Por lo tanto, comenzamos a buscar una herramienta que pudiera acelerar estos procesos. La solución a ambos problemas fue precisamente el nuevo producto Progress OpenEdge: Pro2 CDC (Change Data Capture). Entonces comencemos.
Instalar Progress OpenEdge y Pro2Oracle
Para ejecutar Pro2 Oracle en la computadora Windows de un administrador, simplemente instale el Progress OpenEdge Developer Kit Classroom Edition, que se puede
descargar de forma gratuita. Directorios de instalación predeterminados de OpenEdge:
DLC: C: \ Progreso \ OpenEdge
WRK: C: \ OpenEdge \ WRKLos procesos ETL requieren licencias de Progress OpenEdge versión 11.7+, a saber, OE DataServer para Oracle y 4GL Development System. Estas licencias se incluyen con Pro2. Para el funcionamiento completo de DataServer para Oracle con una base de datos remota de Oracle, se instala Full Oracle Client.
En el servidor Oracle, debe instalar la versión de Oracle Database 12+, crear una base de datos vacía y agregar el usuario (llamémoslo
cdc ).
Para instalar Pro2Oracle, descargue el último paquete de distribución desde el centro de descarga de
Progress Software . Desempaquete el archivo en el directorio
C: \ Pro2 (se usa el mismo kit de distribución para configurar Pro2 en Unix y se aplican los mismos principios de configuración).
Crear una base de datos de replicación de cdc
Pro2 utiliza la base de datos de replicación
cdc (repl) para almacenar información de configuración, incluido el mapa de replicación, los nombres de las bases de datos replicadas y sus tablas. También contiene una cola de replicación que consta de notas sobre el hecho de que la fila de la tabla en la base de datos de origen ha cambiado. Los procesos ETL utilizan los datos de la cola de replicación para identificar las filas que deben copiarse a Oracle desde la base de datos de origen.
Cree una base de datos cdc separada.
Procedimiento para crear una base de datos- En el servidor de bases de datos, cree un directorio para la base de datos de cdc, por ejemplo, en / database / cdc / server.
- Cree un maniquí para la base del cdc: procopy $ DLC / empty cdc
- Habilite la compatibilidad con archivos grandes: proutil cdc -C EnableLargeFiles
- Preparamos el script para iniciar la base de datos cdc. Los parámetros de inicio deben ser similares a los parámetros de inicio de la base de datos replicada.
- Iniciamos la base de datos cdc.
- Nos conectamos a la base de datos cdc y cargamos el diagrama Pro2 del archivo cdc.df , que se incluye con el paquete Pro2.
- En la base de datos cdc, cree los siguientes usuarios:
pro2adm: para conectarse desde el panel de administración de Pro2;
pro2etl: para conectar procesos ETL (ReplBatch);
pro2cdc: para conectar procesos CDC (CDCBatch); Activando OpenEdge Change Data Capture
Ahora activemos el mecanismo CDC en sí mismo, a través del cual los datos se replicarán en un área tecnológica adicional. En cada base de datos de origen de Progress OpenEdge, debe agregar áreas de almacenamiento separadas en las que se duplicarán los datos de origen y activar el mecanismo en sí mediante el
comando proutil .
Procedimiento de ejemplo para la base de datos bisquit- Copie el archivo cdcadd.st del directorio C: \ Pro2 \ db al directorio de la base de datos de origen bisquit .
- Describimos en cdcadd.st extensiones de extensión fija para las áreas ReplCDCArea y ReplCDCArea_IDX . Puede agregar nuevas áreas de almacenamiento en línea: prostrct addonline bisquit cdcadd.st
- Active OpenEdge CDC:
proutil bisquit -C enablecdc area "ReplCDCArea" indexarea "ReplCDCArea_IDX"
- Se deben crear los siguientes usuarios en la base de datos de origen para identificar los procesos en ejecución:
a. pro2adm: para conectarse desde el panel de administración de Pro2.
b. pro2etl: para conectar procesos ETL (ReplBatch).
c. pro2cdc: para conectar procesos CDC (CDCBatch).
Crear un titular de esquema para DataServer para Oracle
Luego, necesitamos crear el titular del esquema de la base de datos en el servidor donde se replicarán los datos del Progress DBMS al Oracle DBMS. DataServer Schema Holder es una base de datos Progress OpenEdge vacía sin usuarios o datos de la aplicación, que contiene un mapa de correspondencia entre las tablas de origen y las tablas externas de Oracle.
La base de datos del titular del esquema para Progress OpenEdge DataServer para Oracle para Pro2 debe ubicarse en el servidor de procesos ETL; se crea por separado para cada rama.
Cómo crear un titular de esquema- Descomprima la distribución Pro2 en el directorio / pro2
- Cree y vaya al directorio / pro2 / dbsh
- Cree la base de datos del titular del esquema usando el comando $ DLC / empty bisquitsh de procopy
- Convertimos bisquitsh a la codificación necesaria, por ejemplo, en UTF-8 si las bases de datos Oracle están codificadas en UTF-8: proutil bisquitsh -C convchar convert UTF-8
- Después de crear una base de datos bisquitsh vacía, nos conectamos a ella en modo de usuario único: pro bisquitsh
- Vaya al Diccionario de datos: Herramientas -> Diccionario de datos -> Servidor de datos -> Utilidades ORACLE -> Crear esquema de servidor de datos
- Lanzar titular de esquema
- Configure el agente de Oracle DataServer:
a. Inicie AdminServer
proadsv -start
b. Inicio del broker Oracle DataServer
oraman -name orabroker1 -start
Configurar el panel de administración y el esquema de replicación
El panel de administración de Pro2 configura los ajustes de Pro2, incluida la configuración del esquema de replicación y la generación de programas de proceso ETL (Biblioteca de procesadores), programas de sincronización primarios (Procesador de copia masiva), disparadores de replicación y políticas OpenEdge CDC. También hay herramientas principales para monitorear y administrar procesos ETL y CDC. En primer lugar, configuramos los archivos de parámetros.
Cómo configurar archivos de parámetros- Vaya al directorio C: \ Pro2 \ bprepl \ Scripts
- Abra el archivo replProc.pf para editar
- Agregue los parámetros para conectarse a la base de datos de replicación de cdc:
# Base de datos de replicación
-db cdc -ld repl -H <nombre de host de la base de datos principal> -S <puerto del agente de base de datos cdc>
-U pro2admin -P <contraseña>
- Agregue los parámetros para conectarse a las bases de datos de origen y al titular del esquema en forma de archivos de parámetros a replProc.pf . El nombre del archivo de parámetros debe coincidir con el nombre de la base de datos de origen que se va a conectar.
# Conectarse a todas las fuentes replicadas BISQUIT
-pf bprepl \ scripts \ bisquit.pf
- Agregue los parámetros para conectarse al titular del esquema en replProc.pf.
#Target Pro DB Schema Holder
-db bisquitsh -ld bisquitsh
-H <nombre de host de procesos ETL>
-S <puerto de intermediario biskuitsh>
-db bisquitsql
-ld bisquitsql
-dt ORACLE
-S 5162 -H <nombre de host del intermediario de Oracle>
-DataService orabroker1
- Guarde el archivo de parámetros replProc.pf
- A continuación, debe crear y abrir para editar los archivos de parámetros para cada base de datos de origen conectada en el directorio C: \ Pro2 \ bprepl \ Scripts: bisquit.pf . Cada archivo pf contiene parámetros para conectarse a la base de datos correspondiente, por ejemplo:
-db bisquit -ld bisquit -H <nombre de host> -S <puerto de intermediario>
-U pro2admin -P <contraseña>
Para configurar los accesos directos de Windows, vaya al
directorio C: \ Pro2 \ bprepl \ Scripts y edite el acceso directo "Pro2 - Administración". Para hacer esto, abra las propiedades del acceso directo y en la línea
Iniciar en indique el directorio de instalación Pro2. Es necesario realizar una operación similar para las etiquetas "Pro2 - Editor" y "RunBulkLoader".
Configuración de la administración Pro2: descarga de la configuración primaria
Lanzamos la consola.
Vaya al "Mapa de DB".

Para vincular las bases de datos en Pro2 - Administración, vaya a la pestaña
Mapa DB . Agregamos mapeo de bases de datos de origen -
Esquema Holder - Oracle .

Vaya a la pestaña
Asignación . En la lista
Base de datos de origen , la primera base de datos de origen conectada se selecciona de forma predeterminada. A la derecha de la lista debe estar
Todas las bases de datos conectadas : las bases de datos seleccionadas están conectadas. Una lista de las tablas de Progreso de bisquit debería estar visible a la izquierda. A la derecha hay una lista de tablas de la base de datos Oracle.
Crear esquemas SQL y bases de datos en Oracle
Para crear un mapa de replicación, primero debe generar el
esquema SQL en Oracle. En Pro2 Administration, ejecute el elemento de menú
Herramientas -> Generar código -> Esquema de destino , luego, en el cuadro de diálogo
Seleccionar base de datos ,
seleccione una o más bases de datos de origen y transfiéralas a la derecha.

Haga clic en Aceptar y seleccione el directorio para guardar los esquemas SQL.
A continuación, creamos la base. Esto se puede hacer, por ejemplo, a través de
Oracle SQL Developer . Para hacer esto, conéctese a la base de datos Oracle y cargue el esquema para agregar tablas. Después de cambiar la composición de las tablas de Oracle, debe actualizar los esquemas SQL en el titular del esquema.

Después de que la descarga se complete con éxito, salga de la base de datos bisquitsh y abra el panel de administración de Pro2. Las tablas de la base de datos Oracle deberían aparecer en la pestaña Asignación a la derecha.
Tablas de mapeo
Para crear un mapa de replicación en el panel de administración de Pro2, vaya a la pestaña Asignación, seleccione la base de datos de origen. Hacemos clic en Tablas de mapas, seleccionamos a la izquierda las tablas Seleccionar cambios que deben replicarse en Oracle, las transferimos a la derecha y confirmamos la selección. Se creará un mapa automáticamente para las tablas seleccionadas. Repita la operación para crear un mapa de replicación para otras bases de datos de origen.
Generación de la biblioteca del procesador de replicación Pro2 y los programas del procesador de copia masiva
La biblioteca de procesadores está diseñada para procesos especiales de replicación (ETL) que procesan la cola de replicación Pro2 y envían los cambios a la base de datos Oracle. Después de la generación, los programas de la biblioteca del procesador de replicación se guardan automáticamente en el
directorio bprepl / repl_proc (parámetro PROC_DIRECTORY) . Para generar la biblioteca del procesador de replicación, vaya a
Herramientas -> Generar código -> Biblioteca del procesador. Una vez completada la generación, los programas aparecerán en el
directorio bprepl / repl_proc .
Los programas de procesador masivo se utilizan para sincronizar las bases de datos de Progress de origen con la base de datos de Oracle de destino basada en el lenguaje de programación Progress ABL (4GL). Para generarlos, vaya al elemento de menú
Herramientas -> Generar código -> Procesador de copia masiva . En el cuadro de diálogo Seleccionar base de datos, seleccione la base de datos de origen, transfiérala al lado derecho de la ventana y haga
clic en
Aceptar . Una vez completada la generación, los programas aparecerán en el
directorio bprepl \ repl_mproc .
Configurar procesos de replicación en Pro2
Dividir las tablas en conjuntos atendidos por un hilo de replicación separado puede mejorar el rendimiento y la eficiencia de Oracle Pro2. De forma predeterminada, todas las conexiones creadas en el mapa de replicación para las nuevas tablas de replicación están vinculadas al flujo número 1. Se recomienda que las tablas se dividan en diferentes flujos.
La información sobre el estado de los flujos de replicación se muestra en la pantalla Administración de Pro2 en la pestaña Monitor en la sección Estado de replicación. Se puede encontrar una descripción detallada de los valores de los parámetros en la documentación de Pro2 (directorio C: \ Pro2 \ Docs).
Crear y activar políticas de CDC
Las políticas son un conjunto de reglas para el mecanismo OpenEdge CDC, según el cual se realiza un seguimiento de los cambios en las tablas. Al momento de escribir, Pro2 solo admite políticas CDC con nivel 0, es decir, solo se realiza
un seguimiento del hecho de
un cambio de registro .
Para crear una política de CDC en el panel administrativo, vaya a la pestaña Asignación, seleccione la base de datos de origen y haga clic en el botón Agregar o quitar políticas. En la ventana Seleccionar cambios que se abre, seleccione en el lado izquierdo y transfiérala a la tabla derecha para la que necesita crear o eliminar una política de CDC.
Para activar, abra nuevamente la pestaña Asignación, seleccione la base de datos de origen y haga clic en el botón
(In) Activar políticas . Seleccione y transfiera al lado derecho de la tabla cuyas políticas necesita activar, haga clic en Aceptar. Después de eso están marcados en verde. Usando
(In) Activar Políticas , también puede desactivar las políticas de CDC. Todas las operaciones se realizan en línea.

Después de activar la política de CDC, las notas sobre los registros modificados se guardan en el área de almacenamiento
"ReplCDCArea" de acuerdo con la base de datos original. Estas notas serán procesadas por un proceso especial de
CDCBatch , que en su base creará notas en la cola de replicación Pro2 en la base de datos
cdc (repl) .
Por lo tanto, tenemos dos colas para la replicación. La primera etapa es CDCBatch: desde la base de datos original, los datos primero van a la base de datos CDC intermedia. La segunda etapa es cuando los datos se vierten desde la base de datos de CDC a Oracle. Esta es una característica de la arquitectura actual y del producto en sí, mientras que los desarrolladores no han podido establecer la replicación directa.
Sincronización principal
Después de activar el mecanismo CDC y configurar el servidor de replicación Pro2, debemos iniciar la sincronización primaria. Comando de inicio de sincronización principal:
/pro2/bprepl/Script/replLoad.sh bisquit nombre-tablaUna vez completada la sincronización inicial, se pueden iniciar los procesos de replicación.
Iniciar procesos de replicación
Para iniciar los procesos de replicación, debe ejecutar el script
replbatch.sh . Antes de comenzar, asegúrese de que haya scripts replbatch para todos los hilos: replbatch1, replbatch2, etc. Si todo está en su lugar, abra la línea de comando (por ejemplo,
proenv) , vaya al directorio
/ bprepl / scripts e inicie el script. En el panel administrativo, verificamos que el proceso correspondiente haya recibido el estado EN EJECUCIÓN.

Resultados
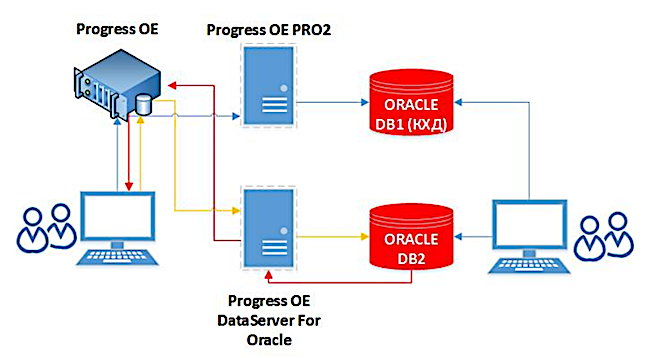
Después de la implementación, hemos acelerado enormemente la carga de información al almacén de datos corporativos. Los datos en sí mismos van a Oracle en línea. No es necesario dedicar tiempo a algunas consultas de larga duración para recopilar datos de diferentes sistemas. Además, en esta solución, el proceso de replicación puede comprimir datos, lo que también tiene un efecto positivo en la velocidad. Ahora, la reconciliación diaria del sistema BISKVIT con otros sistemas comenzó a tomar 15-20 minutos en lugar de 2-2.5 horas, y la reconciliación completa, varias horas en lugar de dos días.