Prólogo
Este artículo no es muy similar a los que se publicaron anteriormente sobre el escaneo de Internet de ciertos países, porque no perseguí los objetivos de escanear en masa un segmento específico de Internet en busca de puertos abiertos y la presencia de las vulnerabilidades más populares porque es ilegal.
Prefiero tener un interés ligeramente diferente: tratar de identificar todos los sitios relevantes en la zona de dominio BY utilizando diferentes métodos, determinar la pila de tecnologías utilizadas, a través de servicios como Shodan, VirusTotal, etc. para realizar un reconocimiento pasivo sobre IP y puertos abiertos y, en el apéndice, para recopilar un poco más de utilidad información para la formación de algunas estadísticas generales sobre el nivel de seguridad con respecto a los sitios y usuarios.
Introductorio y nuestro kit de herramientas
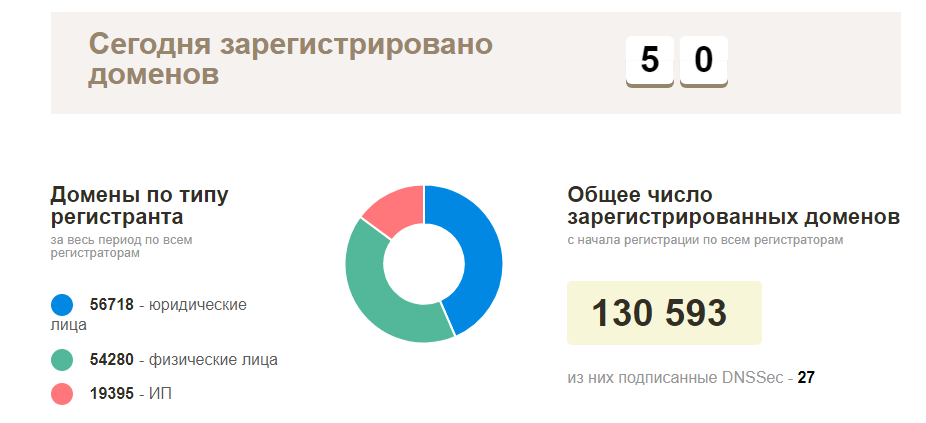
El plan al principio era simple: comuníquese con su registrador local para obtener una lista de los dominios registrados actuales, luego verifique la disponibilidad de todo y comience a explorar los sitios que funcionan. En realidad, todo resultó ser mucho más complicado: este tipo de información era natural, nadie quería proporcionarla, con la excepción de la página oficial de estadísticas de los nombres de dominio registrados reales en la zona BY (alrededor de 130 mil dominios). Si no existe dicha información, debe recopilarla usted mismo.
En términos de herramientas, de hecho, todo es bastante simple: miramos hacia el código abierto, siempre puede agregar algo, terminar algunas muletas mínimas. De las más populares, se utilizaron las siguientes herramientas:
Inicio de actividades: punto de partida
Como introducción, como dije antes, idealmente los nombres de dominio eran adecuados, pero ¿dónde puedo obtenerlos? Necesitamos comenzar desde algo más simple, en este caso las direcciones IP son adecuadas para nosotros, pero nuevamente, con búsquedas inversas no siempre es posible capturar todos los dominios, y al recopilar nombres de host, no siempre es el dominio correcto. En esta etapa, comencé a pensar en posibles escenarios para recopilar este tipo de información, una vez más: se tuvo en cuenta el hecho de que nuestro presupuesto era de $ 5 para el alquiler de VPS, todo lo demás debería ser gratuito.
Nuestras posibles fuentes de información:
- Direcciones IP (sitio de ubicación ip2 )
- Búsqueda de dominio por la segunda parte de la dirección de correo electrónico (¿pero dónde conseguirlos? Vamos a averiguarlo un poco más abajo)
- Algunos registradores / proveedores de alojamiento pueden proporcionarnos dicha información en forma de subdominios
- Subdominios y su posterior inversión (Sublist3r y Aquatone pueden ayudar aquí)
- Fuerza bruta y entrada manual (larga, triste, pero posible, aunque no utilicé esta opción)
Me adelantaré un poco y diré que con este enfoque logré recopilar alrededor de 50 mil dominios y sitios únicos, respectivamente (no logré procesar todo). Si él continuara recolectando información activamente, entonces seguramente en menos de un mes de trabajo mi transportador habría dominado toda la base de datos, o la mayor parte.
Empecemos a trabajar
En artículos anteriores, la información sobre las direcciones IP se tomó del sitio IP2LOCATION, por razones obvias, no encontré estos artículos (ya que todas las acciones tuvieron lugar mucho antes), sino que también llegué a este recurso. Es cierto, en mi caso, el enfoque fue diferente: decidí no tomar la base de datos localmente para mí y no extraer información del CSV, pero decidí monitorear los cambios directamente en el sitio, de manera continua y como la base principal desde donde todos los scripts posteriores tendrán objetivos, hice una tabla con Direcciones IP en diferentes formatos: CIDR, lista "desde" y "hasta", marca de país (por si acaso), número AS, descripción AS.
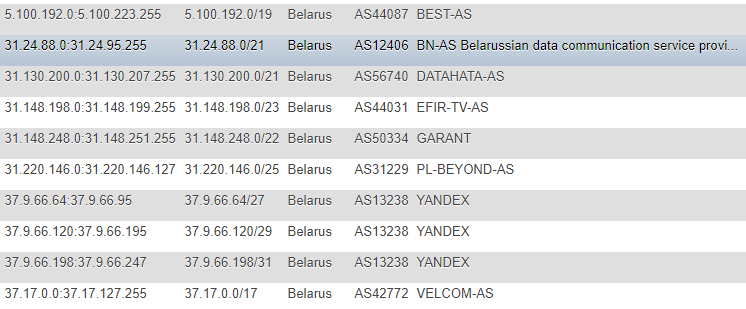
El formato no es el más óptimo, pero estaba muy contento con la demostración y la promoción única, y para no buscar constantemente información adicional como ASN, decidí registrarla por mi cuenta. Para obtener esta información,
recurrí al servicio
IpToASN , tienen una API conveniente (con restricciones), que de hecho solo necesita integrarse en usted mismo.
Código de análisis de IPfunction ipList() { $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, "https://lite.ip2location.com/belarus-ip-address-ranges"); curl_setopt($ch, CURLOPT_HEADER, 0); curl_setopt($ch, CURLOPT_USERAGENT,'Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.13) Gecko/20080311 Firefox/2.0.0.13'); curl_setopt($ch, CURLOPT_RETURNTRANSFER, true); curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false); curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false); $ipList = curl_exec($ch); curl_close ($ch); preg_match_all("/(\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}\<\/td\>\s+\<td\>\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})/", $ipList, $matches); return $matches[0]; } function iprange2cidr($ipStart, $ipEnd){ if (is_string($ipStart) || is_string($ipEnd)){ $start = ip2long($ipStart); $end = ip2long($ipEnd); } else{ $start = $ipStart; $end = $ipEnd; } $result = array(); while($end >= $start){ $maxSize = 32; while ($maxSize > 0){ $mask = hexdec(iMask($maxSize - 1)); $maskBase = $start & $mask; if($maskBase != $start) break; $maxSize--; } $x = log($end - $start + 1)/log(2); $maxDiff = floor(32 - floor($x)); if($maxSize < $maxDiff){ $maxSize = $maxDiff; } $ip = long2ip($start); array_push($result, "$ip/$maxSize"); $start += pow(2, (32-$maxSize)); } return $result; } $getIpList = ipList(); foreach($getIpList as $item) { $cidr = iprange2cidr($ip[0], $ip[1]); }
Después de descubrir la IP, necesitamos ejecutar toda nuestra base de datos a través de los servicios de búsqueda inversa, por desgracia, sin restricciones, esto es imposible, excepto por el dinero.
De los servicios que son excelentes para esto y convenientes de usar, quiero mencionar dos:
- VirusTotal: límite de frecuencia de llamadas desde una clave API
- Hackertarget.com (su API): limite el número de visitas desde una IP
Sin pasar por los límites, se obtuvieron las siguientes opciones:
- En el primer caso, uno de los escenarios es soportar tiempos de espera de 15 segundos, en total tendremos 4 llamadas por minuto, lo que puede afectar en gran medida nuestra velocidad y en esta situación será útil usar 2-3 de esas teclas, y recomendaría recurrir a las mismas proxy y cambiar usuario-agente.
- En el segundo caso, escribí un script para el análisis automático de la base de datos proxy en base a información disponible públicamente, su validación y uso posterior (pero más tarde dejé esta opción porque VirusTotal también era suficiente en esencia)
Vamos más allá y sin problemas vamos a las direcciones de correo electrónico. También pueden ser una fuente de información útil, pero ¿dónde recolectarlos? No tuve que buscar una solución por mucho tiempo, porque los usuarios ocupan poco en nuestro segmento de sitios personales, y la mayoría de ellos son organizaciones: los sitios web de perfil como directorios de tiendas en línea, foros y mercados condicionales se adaptarán a nosotros.
Por ejemplo, una inspección rápida de uno de estos sitios mostró que muchos usuarios agregan su correo electrónico directamente a su perfil público y, en consecuencia, este negocio puede analizarse cuidadosamente para su uso futuro.
No entraré en los detalles de analizar cada sitio, en algún lugar es más conveniente adivinar la identificación del usuario por fuerza bruta, en algún lugar es más fácil analizar un mapa del sitio, obtener información sobre las páginas de la compañía y luego recopilar direcciones de ellos. Después de recopilar las direcciones, nos queda por realizar varias operaciones simples, inmediatamente clasificándolas por la zona de dominio, preservando las "colas" y ejecutándolas para excluir duplicados de la base de datos existente.
En esta etapa, creo que con la formación del alcance, podemos terminar y pasar a la inteligencia. La inteligencia, como ya sabemos, puede ser de dos tipos: activa y pasiva, en nuestro caso, el enfoque pasivo será más relevante. Pero, de nuevo, solo acceder al sitio en el puerto 80 o 443 sin carga maliciosa y explotar vulnerabilidades es una acción bastante legítima. Nuestro interés son las respuestas del servidor a una sola solicitud, en algunos casos puede haber dos solicitudes (redireccionar de http a https), en casos más raros, hasta tres (cuando se usa www).
Inteligencia
Usando dicha información como un dominio, podemos recopilar los siguientes datos:
- Registros DNS (NS, MX, TXT)
- Encabezados de respuesta
- Identificar la pila tecnológica utilizada
- Comprenda por qué protocolo funciona el sitio.
- Intente identificar puertos abiertos (basados en la base de datos Shodan / Censys) sin escaneo directo
- Intente identificar vulnerabilidades basadas en la correlación de información de Shodan / Censys con la base de datos de Vulners
- ¿Está en la base de datos de malware de Navegación segura de Google?
- Recopile las direcciones de correo electrónico por dominio, así como las coincidencias ya encontradas y verifique por Have I Been Pwned, además, enlace a las redes sociales
- En algunos casos, un dominio no solo es la cara de la empresa, sino también el producto de sus actividades, direcciones de correo electrónico para el registro de servicios, etc., respectivamente: puede buscar información asociada con ellos en recursos como GitHub, Pastebin, Google Dorks (Google CSE )
Siempre puede continuar y usar masscan o nmap, zmap como una opción, configurándolos primero a través de Tor con el lanzamiento al azar o incluso desde varias instancias, pero tenemos otros objetivos y el nombre implica que no hice escaneos directos.
Recopilamos registros DNS, verificamos la posibilidad de amplificación de solicitudes y errores de configuración como AXFR:
Un ejemplo de recopilación de registros del servidor NS dig ns +short $domain | sed 's/\.$//g' | awk '{print $1}'
Ejemplo de recopilación de registros MX (vea NS, simplemente reemplace 'ns' con 'mx'
Verifique si hay AXFR (aquí hay muchas soluciones, aquí hay otra muleta, pero no seguridad, que se usa para ver las salidas) $digNs = trim(shell_exec("dig ns +short $domain | sed 's/\.$//g' | awk '{print $1}'")); $ns = explode("\n", $digNs); foreach($ns as $target) { $axfr = trim(shell_exec("dig -t axfr $domain @$target | awk '{print $1}' | sed 's/\.$//g'")); $axfr = preg_replace("/\;/", "", $axfr); if(!empty(trim($axfr))) { $axfr = preg_replace("/\;/", "", $axfr); $res = json_encode(explode("\n", trim($axfr)));
Verifique la amplificación de DNS dig +short test.openresolver.com TXT @$dns
En mi caso, los servidores NS se tomaron de la base de datos, por lo que al final de la variable, puede sustituir cualquier servidor de hecho. Con respecto a la exactitud de los resultados de este servicio, no puedo estar seguro de que todo funcione sin problemas allí y que los resultados siempre sean válidos, pero espero que la mayoría de los resultados sean reales.
Si por algún motivo necesitamos mantener una URL final completa del sitio, para esto utilicé cURL:
curl -I -L $target | awk '/Location/{print $2}'
Él mismo realizará la redirección completa y mostrará la última, es decir URL actual del sitio. En mi caso, fue extremadamente útil para el uso posterior de herramientas como WhatWeb.
¿Por qué deberíamos usarlo? Para determinar el sistema operativo, el servidor web, el sitio CMS utilizado, algunos encabezados, módulos adicionales como bibliotecas / frameworks JS / HTML, así como el título del sitio por el que luego puede intentar filtrar por el mismo campo de actividad.
Una opción muy conveniente en este caso es exportar los resultados de la operación de la herramienta en formato XML para su posterior análisis e importarlos a la base de datos si hay un objetivo para procesarlo más tarde.
whatweb --no-errors https://www.mywebsite.com --log-xml=results.xml
Para mí, hice JSON como resultado de la salida y ya lo puse en la base de datos.
Hablando de encabezados, puede hacer casi lo mismo con cURL ordinario ejecutando una consulta del formulario:
curl -I https://www.mywebsite.com
En los encabezados, obtenga información sobre CMS y servidores web utilizando expresiones regulares, por ejemplo.
Además del útil, también podemos resaltar la posibilidad de recopilar información sobre puertos abiertos usando Shodan y luego usar los datos ya obtenidos, verificar la base de datos de Vulners usando su API (los enlaces a los servicios se dan en el encabezado). Por supuesto, puede haber problemas con la precisión en este escenario, pero esto no es un escaneo directo con validación manual, sino un "malabarismo" banal de datos de fuentes de terceros, pero al menos es mejor que nada.
Función PHP para Shodan function shodanHost($host) { $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, "https://api.shodan.io/shodan/host/".$host."?key=<YOUR_API_KEY>"); curl_setopt($ch, CURLOPT_HEADER, 0); curl_setopt($ch, CURLOPT_USERAGENT,'Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.13) Gecko/20080311 Firefox/2.0.0.13'); curl_setopt($ch, CURLOPT_RETURNTRANSFER, true); curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false); curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false); $shodanResponse = curl_exec($ch); curl_close ($ch); return json_decode($shodanResponse); }
Un ejemplo de tal análisis comparativo # 1 Sí, desde que comenzaron a hablar sobre la API, los Vulners tienen limitaciones y la solución más óptima sería usar su script Python, todo funcionará bien sin torsiones, en el caso de PHP, encontré algunas pequeñas dificultades (nuevamente, agregue. los tiempos de espera salvaron la situación).
Una de las últimas pruebas: estudiaremos la información sobre el firewall que se utiliza con un script como "wafw00f". Al probar esta maravillosa herramienta, noté una cosa interesante: no siempre era la primera vez que era posible determinar el tipo de firewall utilizado.
Para ver qué tipos de firewalls puede detectar potencialmente wafw00f, puede ingresar el siguiente comando:
wafw00f -l
Para determinar el tipo de firewall, wafw00f analiza los encabezados de respuesta del servidor después de enviar una solicitud estándar al sitio, si este intento no es suficiente, genera una solicitud de prueba simple adicional y, si esto no es suficiente nuevamente, el tercer método funciona con los datos después de los primeros dos intentos. .
Porque para las estadísticas, de hecho, no necesitamos la respuesta completa, cortamos todo el exceso con una expresión regular y dejamos solo el firewall de nombre:
/is\sbehind\sa\s(.+?)\n/
Bueno, como escribí anteriormente, además de la información sobre el dominio y el sitio, la información sobre las direcciones de correo electrónico y las redes sociales también se actualizó en modo pasivo:
Estadísticas por correo electrónico definidas en función del dominio Ejemplo de determinación del enlace de las redes sociales a la dirección de correo electrónico La forma más fácil fue lidiar con la validación de direcciones en Twitter (2 formas), con Facebook (1 forma) en este sentido resultó ser un poco más complicado debido a un sistema un poco más complejo para generar una sesión de usuario real.
Pasemos a las estadísticas secas.
Estadísticas DNS
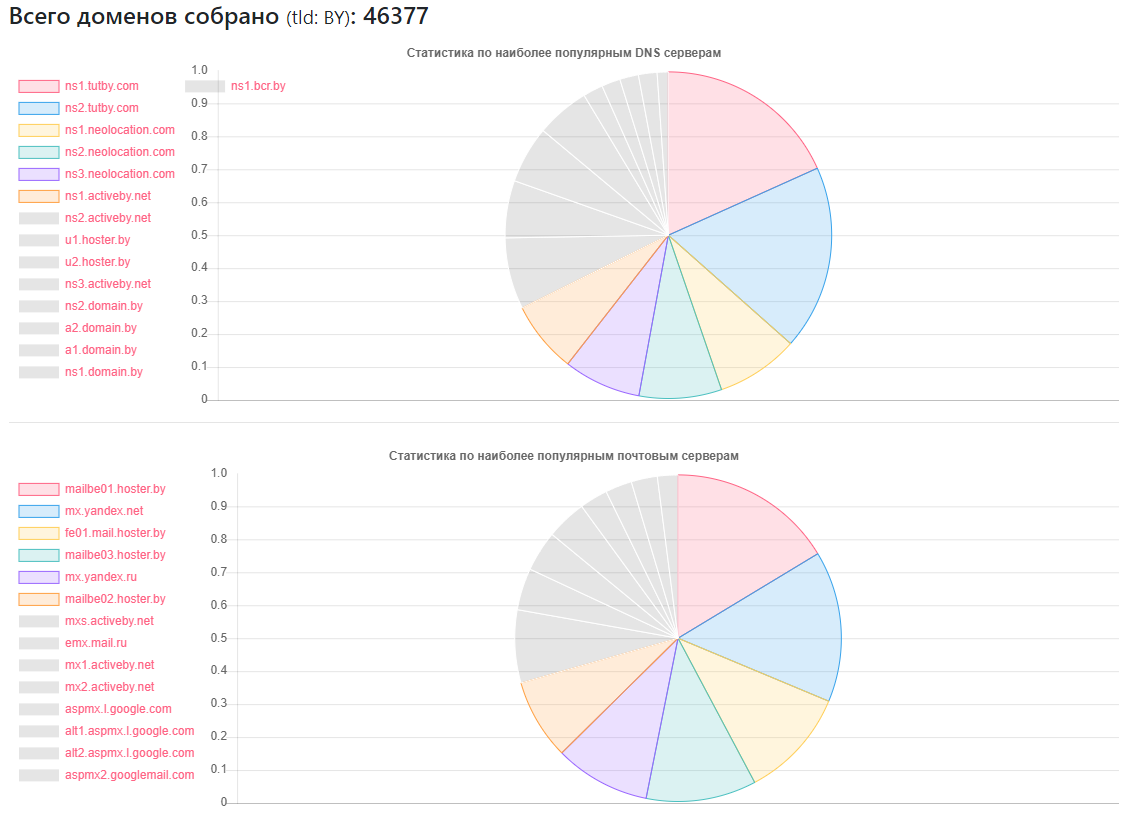 Proveedor: cuántos sitios
Proveedor: cuántos sitiosns1.tutby.com: 10899
ns2.tutby.com: 10899
ns1.neolocation.com: 4877
ns2.neolocation.com: 4873
ns3.neolocation.com: 4572
ns1.activeby.net: 4231
ns2.activeby.net: 4229
u1.hoster.by: 3382
u2.hoster.by: 3378
DNS único encontrado: 2462
Servidores únicos de MX (correo): 9175 (además de los servicios populares, hay un número suficiente de administradores que usan sus propios servicios de correo)
Afectado por la transferencia de zona DNS: 1011
Afectados por la amplificación de DNS: 531
Pocos fanáticos de CloudFlare: 375 (según los registros NS usados)
Estadísticas de CMS
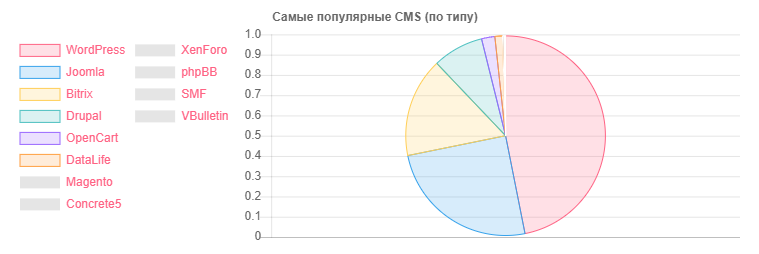 CMS - Cantidad
CMS - CantidadWordPress: 5118
Joomla: 2722
Bitrix: 1757
Drupal: 898
OpenCart: 235
DataLife: 133
Magento: 32
- Instalaciones de WordPress potencialmente vulnerables: 2977
- Instalaciones potencialmente vulnerables de Joomla: 212
- Utilizando el servicio Google SafeBrowsing, fue posible identificar sitios potencialmente peligrosos o infectados: alrededor de 10,000 (en diferentes momentos, alguien reparó, alguien aparentemente rompió, las estadísticas no son completamente objetivas)
- Acerca de HTTP y HTTPS: menos de la mitad de los sitios del volumen encontrado utilizan este último, pero teniendo en cuenta el hecho de que mi base de datos no está completa, pero solo el 40% del número total, es bastante posible que la mayoría de la segunda mitad de los sitios puedan comunicarse a través de HTTPS .
Estadísticas de firewall:
 Cortafuegos - Número
Cortafuegos - NúmeroModSecurity: 4354
Seguridad de la aplicación web de IBM: 126
Mejor seguridad de WP: 110
CloudFlare: 104
Imperva SecureSphere: 45
Juniper WebApp Secure: 45
Estadísticas del servidor web
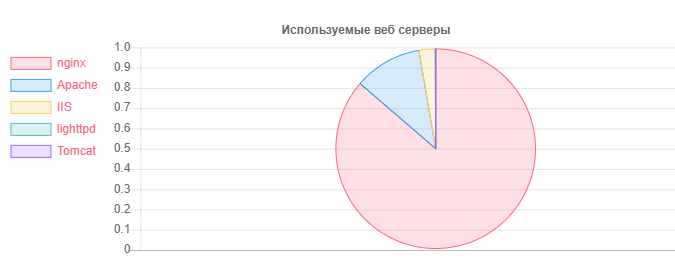 Servidor web: número
Servidor web: númeroNginx: 31752
Apache: 4042
IIS: 959
Instalaciones desactualizadas y potencialmente vulnerables de Nginx: 20966
Instalaciones obsoletas y potencialmente vulnerables de Apache: 995
A pesar de que hoster.by es el líder en dominios y hosting, por ejemplo, en general, Open Contact también se distinguió, pero la verdad está en la cantidad de sitios en una IP:
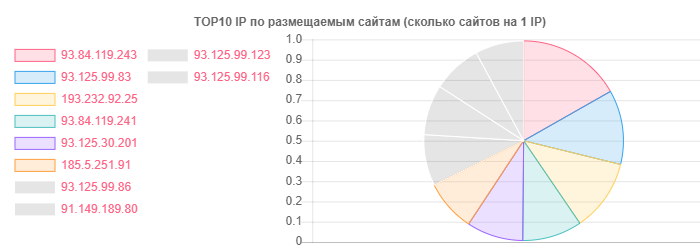 IP - Sitios
IP - Sitios93.84.119.243: 556
93.125.99.83: 399
193.232.92.25: 386
Por correo electrónico, las estadísticas detalladas realmente decidieron no ser extraídas, no ordenadas por la zona de dominio, más bien, fue interesante ver la ubicación de los usuarios a proveedores específicos:
- En el servicio TUT.BY: 38282
- En el servicio Yandex (por | ru): 28127
- En el servicio de Gmail: 33452
- Atado a Facebook: 866
- Atado a Twitter: 652
- Destacado en fugas según HIBP: 7844
- La inteligencia pasiva ayudó a identificar más de 13 mil direcciones de correo electrónico.
Como puede ver, la imagen general es bastante positiva, especialmente el uso activo de nginx por parte de los proveedores de alojamiento. Quizás esto se deba en gran parte a la popularidad entre los usuarios comunes: el tipo de alojamiento compartido.
Por el hecho de que realmente no me gustó, hay un número suficiente de proveedores de hosting de la mano media que han notado errores como AXFR, han usado versiones desactualizadas de SSH y Apache y algunos otros problemas menores. Aquí, por supuesto, la fase activa podría arrojar más luz sobre la situación, pero en este momento, en virtud de nuestra legislación, me parece imposible, y realmente no me gustaría alistarme en las filas de plagas para tales asuntos.
La imagen del correo electrónico es generalmente bastante rosada, si puede llamarlo así. Ah, sí, donde se indica el proveedor TUT.BY, esto significaba usar el dominio, porque Este servicio funciona sobre la base de Yandex.
Conclusión
Como conclusión, puedo decir una cosa: incluso con los resultados disponibles, puede comprender rápidamente que hay una gran cantidad de trabajo para los especialistas que están involucrados en la limpieza de sitios de virus, la configuración de WAF y la configuración / adición de diferentes CMS.
Bueno, en serio, como en los dos artículos anteriores, vemos que existen problemas en niveles absolutamente diferentes en absolutamente todos los segmentos de Internet y países, y algunos de ellos incluso realizan un estudio remoto del problema, sin utilizar métodos ofensivos, etc. e. utilizando información disponible públicamente para recopilar qué habilidades especiales no se requieren.