
En el último artículo, examinamos los fundamentos teóricos de la arquitectura reactiva. Es hora de hablar sobre flujos de datos, formas de implementar sistemas reactivos Erlang / Elixir y patrones de mensajes en ellos:
- Solicitar respuesta
- Solicitud de respuesta fragmentada
- Respuesta con solicitud
- Publicar-suscribirse
- Publicación-suscripción invertida
- Distribución de tareas
SOA, MSA y mensajería
SOA, MSA: arquitecturas de sistemas que definen las reglas para construir sistemas, mientras que la mensajería proporciona primitivas para su implementación.
No quiero promover esta o aquella arquitectura de los sistemas de construcción. Estoy a favor del uso de las prácticas más efectivas y útiles para un proyecto y negocio en particular. Cualquiera que sea el paradigma que elijamos, es mejor crear bloques de sistema con la vista puesta en Unix-way: componentes con conectividad mínima, que son responsables de las entidades individuales. Los métodos API realizan las acciones más simples con entidades.
Mensajería: como su nombre lo indica, es un agente de mensajes. Su objetivo principal es recibir y dar mensajes. Es responsable de las interfaces para enviar información, la formación de canales lógicos para transmitir información dentro del sistema, el enrutamiento y el equilibrio, así como el procesamiento de fallas a nivel del sistema.
El mensaje que se está desarrollando no está tratando de competir o reemplazar a rabbitmq. Sus características principales:
- Distribución
Se pueden crear puntos de intercambio en todos los nodos del clúster, lo más cerca posible del código que los usa. - Simplicidad
Concéntrese en minimizar el código repetitivo y la usabilidad. - El mejor rendimiento.
No estamos tratando de repetir la funcionalidad de rabbitmq, sino solo resaltar la capa arquitectónica y de transporte, que es lo más simple posible en OTP, minimizando los costos. - Flexibilidad
Cada servicio puede combinar muchas plantillas de intercambio. - Tolerancia a fallos inherente al diseño.
- Escalabilidad.
La mensajería crece con la aplicación. A medida que aumenta la carga, puede mover los puntos de intercambio a máquinas individuales.
Observación Desde el punto de vista de la organización del código, los metaproyectos son adecuados para sistemas complejos con Erlang / Elixir. Todo el código del proyecto está en un repositorio: un proyecto general. Al mismo tiempo, los microservicios están tan aislados como sea posible y realizan operaciones simples que son responsables de una entidad separada. Con este enfoque, es fácil admitir la API de todo el sistema, solo hacer cambios, es conveniente escribir unidades y pruebas de integración.
Los componentes del sistema interactúan directamente o a través de un intermediario. Desde la perspectiva de la mensajería, cada servicio tiene varias fases de vida:
- Inicialización del servicio.
En esta etapa, tiene lugar la configuración y el lanzamiento del servicio que ejecuta el proceso y las dependencias. - Creando un punto de intercambio.
El servicio puede usar el punto de intercambio estático especificado en la configuración del nodo, o crear puntos de intercambio dinámicamente. - Servicio de registro.
Para que un servicio pueda atender solicitudes, debe registrarse en el punto de intercambio. - Funcionamiento normal
El servicio produce trabajo útil. - Apagado
Hay 2 tipos de apagado: regular y de emergencia. Con un servicio regular, se desconecta del punto de intercambio y se detiene. En casos de emergencia, la mensajería ejecuta uno de los escenarios de conmutación por error.
Parece bastante complicado, pero no todo es tan aterrador en el código. Se darán ejemplos de código con comentarios en el análisis de plantillas un poco más tarde.
Intercambios
Un punto de intercambio es un proceso de mensajería que implementa la lógica de interactuar con componentes dentro de una plantilla de mensajería. En todos los ejemplos a continuación, los componentes interactúan a través de puntos de intercambio, cuya combinación forma mensajes.
Patrones de intercambio de mensajes (MEP)
A nivel mundial, los patrones de intercambio se pueden dividir en bidireccionales y unidireccionales. Lo primero implica una respuesta al mensaje recibido, lo segundo no. Un ejemplo clásico de un patrón bidireccional en una arquitectura cliente-servidor es el patrón Solicitud-respuesta. Considere la plantilla y sus modificaciones.
Solicitud - respuesta o RPC
RPC se usa cuando necesitamos obtener una respuesta de otro proceso. Este proceso puede iniciarse en el mismo sitio o ubicado en un continente diferente. A continuación se muestra un diagrama de la interacción del cliente y el servidor a través de la mensajería.
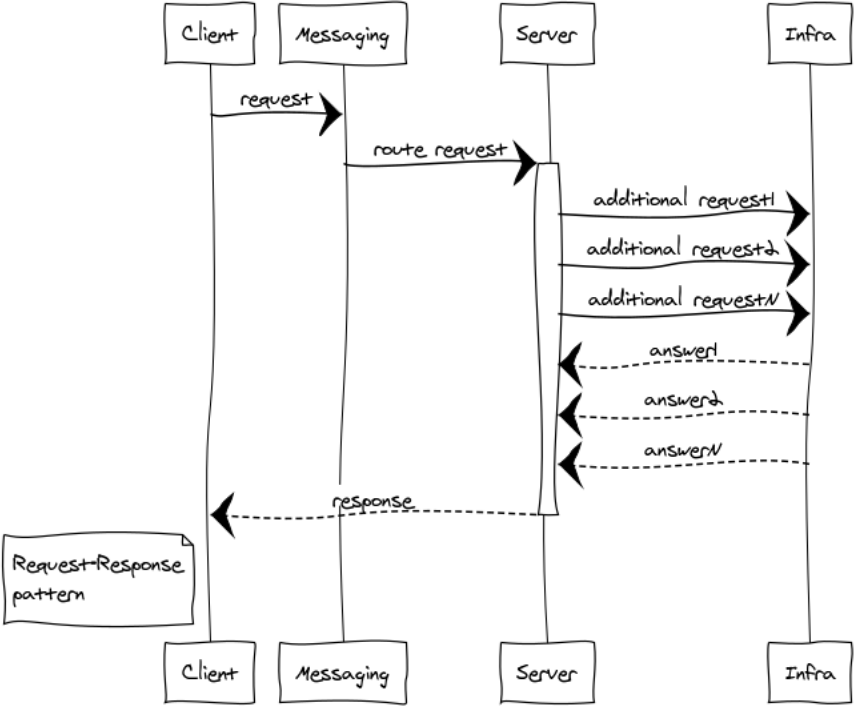
Dado que la mensajería es completamente asíncrona, para el cliente el intercambio se divide en 2 fases:
Solicitud de envío
messaging:request(Exchange, ResponseMatchingTag, RequestDefinition, HandlerProcess).
Intercambio : un nombre único para el punto de intercambio
ResponseMatchingTag : la etiqueta local para manejar la respuesta. Por ejemplo, en el caso de enviar varias solicitudes idénticas pertenecientes a diferentes usuarios.
RequestDefinition - cuerpo de solicitud
HandlerProcess : controlador PID. Este proceso recibirá una respuesta del servidor.
Procesamiento de respuesta
handle_info(#'$msg'{exchange = EXCHANGE, tag = ResponseMatchingTag,message = ResponsePayload}, State)
ResponsePayload : respuesta del servidor.
Para el servidor, el proceso también consta de 2 fases:
- Inicialización del punto de intercambio
- Procesando solicitudes entrantes
Vamos a ilustrar esta plantilla con código. Supongamos que necesitamos implementar un servicio simple que proporcione el único método de tiempo exacto.
Código del servidor
Saque la definición de la API de servicio en api.hrl:
Definir un controlador de servicio en time_controller.erl
Código de cliente
Para enviar una solicitud a un servicio, puede llamar a la API de solicitud de mensajería en cualquier parte del cliente:
case messaging:request(?EXCHANGE, tag, #time_req{opts = #{}}, self()) of ok -> ok; _ ->
En un sistema distribuido, la configuración de los componentes puede ser muy diferente y, en el momento de la solicitud, es posible que todavía no se inicie la mensajería o que el controlador de servicio no esté listo para atender la solicitud. Por lo tanto, debemos verificar la respuesta de la mensajería y manejar el caso de falla.
Después de un envío exitoso, el cliente recibirá una respuesta o error del servicio.
Maneje ambos casos en handle_info:
handle_info(#'$msg'{exchange = ?EXCHANGE, tag = tag, message = #time_resp{result = #time{unixtime = Utime}}}, State) -> ?debugVal(Utime), {noreply, State}; handle_info(#'$msg'{exchange = ?EXCHANGE, tag = tag, message = #time_resp{result = #time_error{code = ErrorCode}}}, State) -> ?debugVal({error, ErrorCode}), {noreply, State};
Solicitud de respuesta fragmentada
Mejor no permitir la transmisión de grandes mensajes. La capacidad de respuesta y el funcionamiento estable de todo el sistema dependen de esto. Si la respuesta a la solicitud ocupa mucha memoria, entonces es obligatorio un desglose en partes.
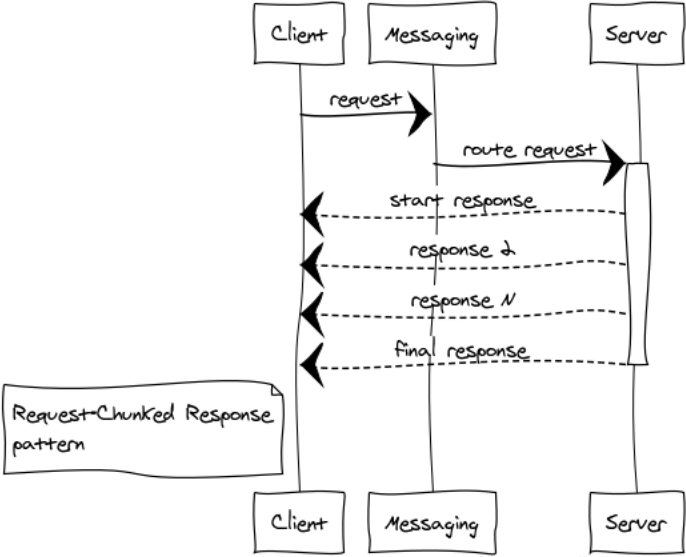
Daré un par de ejemplos de tales casos:
- Los componentes intercambian datos binarios, como archivos. El desglose de la respuesta en partes pequeñas ayuda a trabajar de manera eficiente con archivos de cualquier tamaño y no detectar desbordamientos de memoria.
- Listados Por ejemplo, necesitamos seleccionar todos los registros de una tabla enorme en la base de datos y transferirlos a otro componente.
Llamo a estas respuestas una locomotora. En cualquier caso, 1024 mensajes de 1 MB son mejores que un solo mensaje de 1 GB.
En el clúster Erlang, obtenemos una ganancia adicional, reduciendo la carga en el punto de intercambio y la red, ya que las respuestas se envían inmediatamente al destinatario, sin pasar por el punto de intercambio.
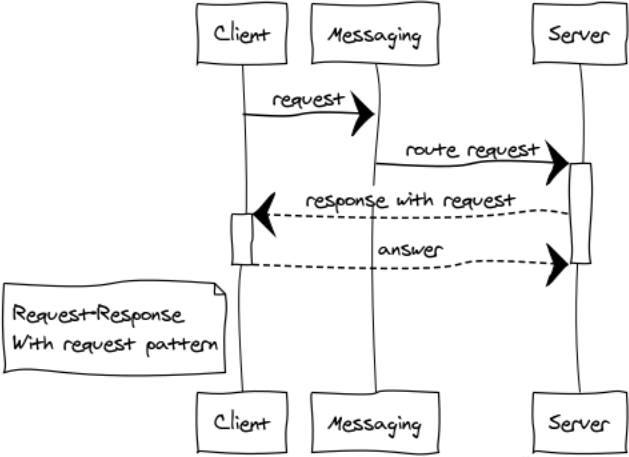
Respuesta con solicitud
Esta es una modificación bastante rara del patrón RPC para construir sistemas interactivos.
Publicar-suscribirse (árbol de distribución de datos)
Los sistemas orientados a eventos entregan datos a los consumidores a medida que los datos están disponibles. Por lo tanto, los sistemas son más propensos a empujar modelos que tirar o sondear. Esta característica le permite no desperdiciar recursos al consultar y esperar constantemente los datos.
La figura muestra el proceso de distribución de un mensaje a los consumidores que están suscritos a un tema específico.
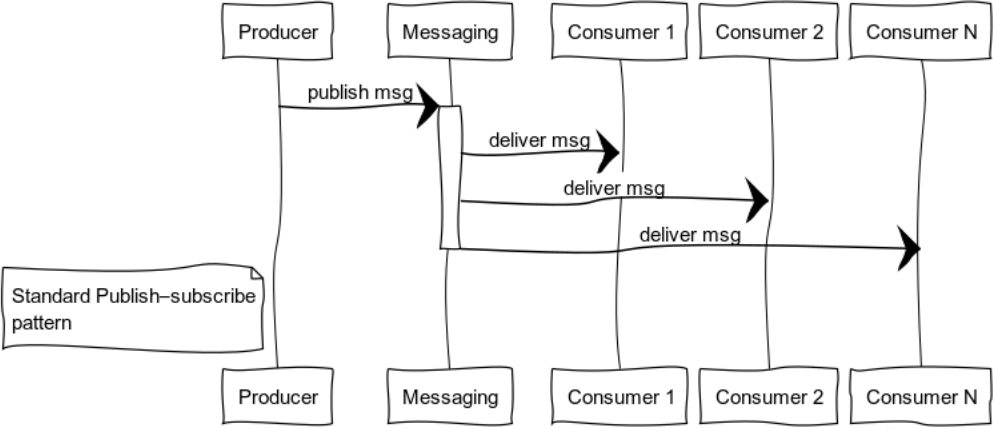
Ejemplos clásicos del uso de esta plantilla es la distribución del estado: el mundo de los juegos en los juegos de computadora, los datos del mercado en los intercambios, la información útil en los feeds de datos.
Considere el código de suscriptor:
init(_Args) ->
La fuente puede llamar a la función de publicación posterior en cualquier lugar conveniente:
messaging:publish_message(Exchange, Key, Message).
Intercambio : el nombre del punto de intercambio,
Clave - clave de enrutamiento
Mensaje : carga útil
Publicación-suscripción invertida
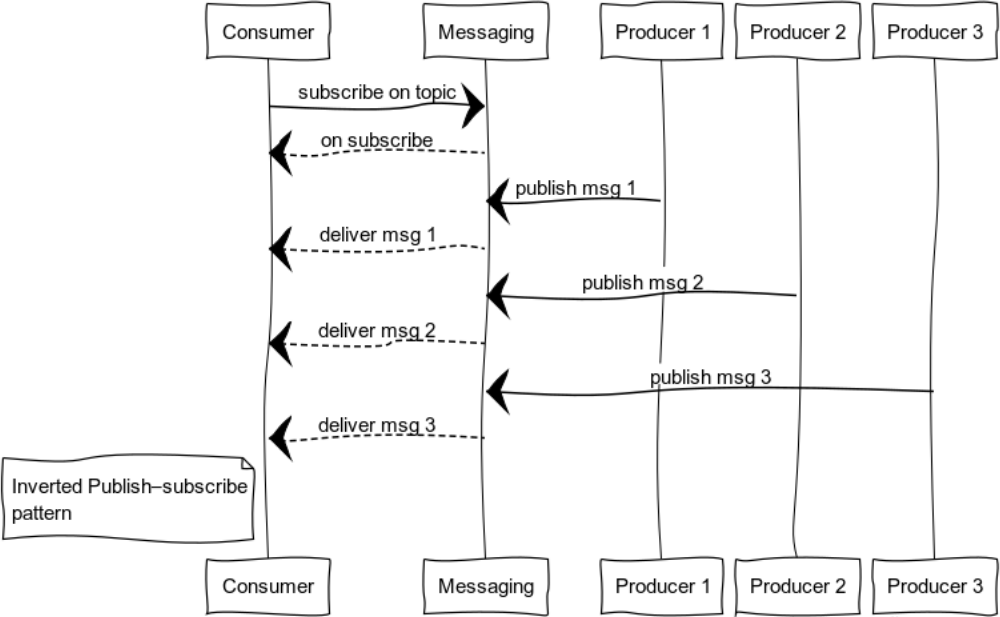
Al expandir pub-sub, puede obtener un patrón que sea conveniente para el registro. El conjunto de fuentes y consumidores puede ser completamente diferente. La figura muestra un caso con un consumidor y muchas fuentes.
Patrón de distribución de tareas
En casi todos los proyectos, surgen tareas de procesamiento diferido, como generar informes, entregar notificaciones, recibir datos de sistemas de terceros. El rendimiento de un sistema que realiza estas tareas es fácilmente escalable mediante la adición de controladores. Todo lo que nos queda es formar un grupo de controladores y distribuir uniformemente las tareas entre ellos.
Considere las situaciones que surgen con el ejemplo de 3 manejadores. Incluso en la etapa de distribución de tareas, surge la cuestión de la equidad de la distribución y el desbordamiento de los controladores. La distribución round-robin será responsable de la justicia, y para evitar una situación de desbordamiento de controladores, introducimos la restricción prefetch_limit . En modos transitorios, prefetch_limit evitará que un controlador reciba todas las tareas.
La mensajería gestiona las colas y la prioridad de procesamiento. Los manejadores reciben tareas a medida que están disponibles. La tarea puede tener éxito o fallar:
messaging:ack(Tack) - llamado en caso de procesamiento exitoso de mensajesmessaging:nack(Tack) : llamada en todas las situaciones de emergencia. Una vez que la tarea regrese, la mensajería la transferirá a otro controlador.
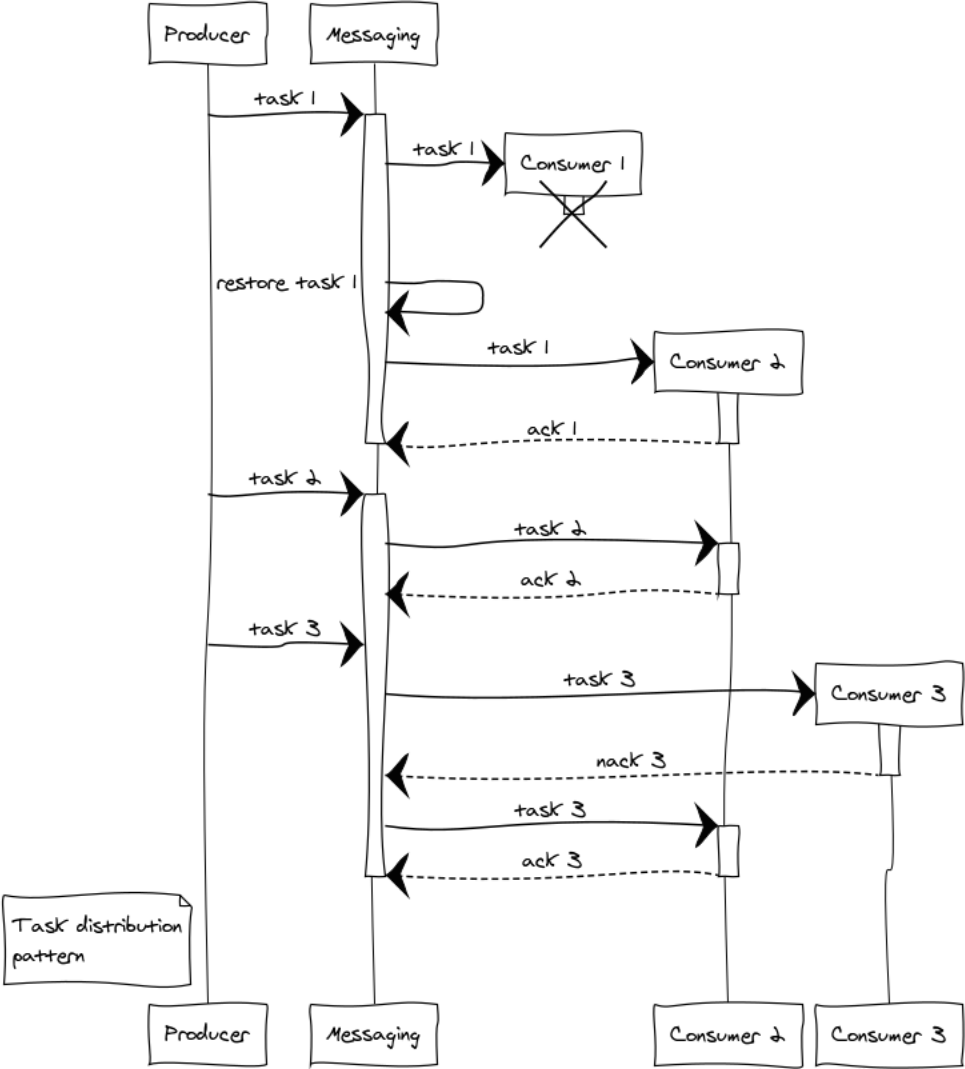
Supongamos que se produce una falla compleja durante el procesamiento de tres tareas: el controlador 1, después de recibir la tarea, se bloquea antes de que pueda comunicarse con el punto de intercambio. En este caso, el punto de intercambio después del vencimiento del tiempo de espera transferirá el trabajo a otro controlador. El controlador 3, por alguna razón, abandonó la tarea y envió un bloqueo, como resultado, la tarea también pasó a otro controlador que la completó con éxito.
Resultado preliminar
Desmontamos los componentes básicos de los sistemas distribuidos y obtuvimos una comprensión básica de su aplicación en Erlang / Elixir.
Al combinar patrones básicos, puede construir paradigmas complejos para resolver problemas emergentes.
En la parte final del ciclo, consideraremos los problemas generales de la organización de los servicios, el enrutamiento y el equilibrio, y también hablaremos sobre el lado práctico de la escalabilidad y la tolerancia a fallas de los sistemas.
El final de la segunda parte.
Foto Marius Christensen
Ilustraciones preparadas por websequencediagrams.com