El tercer artículo de la serie y una pequeña rama de la serie principal: esta vez mostraré cómo se construye la biblioteca de pruebas de integración de Spring y cómo funciona, qué sucede cuando comienza la prueba y cómo puede ajustar la aplicación y su entorno para la prueba.
Un comentario de Hixon10 me pidió que escribiera este artículo sobre cómo usar una base real, como Postgres, en una prueba de integración. El autor del comentario sugirió utilizar la práctica biblioteca incluida todo incluido en la base de datos-spring-test . Y ya agregué un párrafo y un ejemplo de uso en el código, pero luego lo pensé. Por supuesto, tomar una biblioteca preparada es correcto y bueno, pero si el objetivo es comprender cómo escribir pruebas para una aplicación Spring, será más útil mostrar cómo implementar la misma funcionalidad usted mismo. En primer lugar, esta es una gran razón para hablar sobre lo que está bajo el capó de la Prueba de Primavera . Y en segundo lugar, creo que no puede confiar en bibliotecas de terceros, si no comprende cómo están organizadas en el interior, esto solo conduce al fortalecimiento del mito de la "magia" de la tecnología.
Esta vez no habrá una función de usuario, pero habrá un problema que debe resolverse: quiero iniciar la base de datos real en un puerto aleatorio y conectar la aplicación a esta base de datos temporal automáticamente, y después de las pruebas, detengo y elimino la base de datos.
Al principio, como ya es habitual, una pequeña teoría. A las personas que no están demasiado familiarizadas con los conceptos de bin, contexto, configuración, les recomiendo actualizar el conocimiento, por ejemplo, en mi artículo El reverso de Spring / Habr .
Prueba de primavera
Spring Test es una de las bibliotecas incluidas en Spring Framework, de hecho, todo lo que se describe en la sección de documentación sobre pruebas de integración es casi todo. Las cuatro tareas principales que resuelve la biblioteca son:
- Administre los contenedores Spring IoC y su almacenamiento en caché entre pruebas
- Proporcionar inyección de dependencia para clases de prueba
- Proporcionar gestión de transacciones adecuada para pruebas de integración.
- Proporcionar un conjunto de clases base para ayudar al desarrollador a escribir pruebas de integración.
Recomiendo leer la documentación oficial, dice muchas cosas útiles e interesantes. Aquí daré un breve resumen y algunos consejos prácticos que es útil tener en cuenta.
Prueba de ciclo de vida
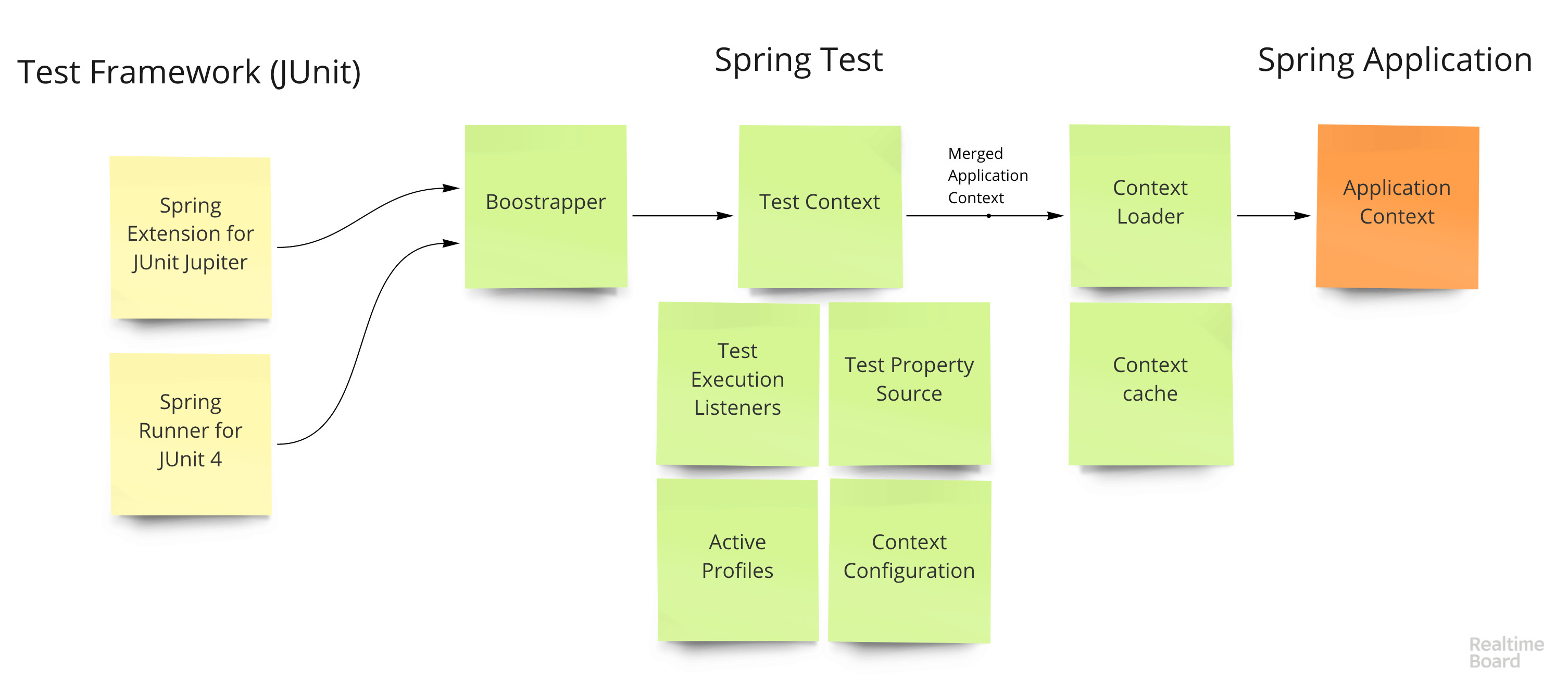
El ciclo de vida de una prueba se ve así:
- La extensión para el marco de prueba (
SpringRunner para JUnit 4 y SpringExtension para JUnit 5) llama a Test Context Bootstrapper - Boostrapper crea
TestContext , la clase principal que almacena el estado actual de la prueba y la aplicación. TestContext configura diferentes TestContext (como iniciar transacciones antes de la prueba y revertir después), inyecta dependencias en las clases de prueba (todos los campos @Autowired en las clases de prueba) y crea contextos- Se crea un contexto utilizando el Context Loader : toma la configuración básica de la aplicación y la combina con la configuración de prueba (propiedades superpuestas, perfiles, contenedores, inicializadores, etc.)
- El contexto se almacena en caché utilizando una clave compuesta que describe completamente la aplicación: un conjunto de contenedores, propiedades, etc.
- Pruebas de funcionamiento
Todo el trabajo sucio de administrar las pruebas se realiza, de hecho, mediante spring-test , y Spring Boot Test a su vez, agrega varias clases auxiliares, como las familiares @DataJpaTest y @SpringBootTest , utilidades útiles como TestPropertyValues para cambiar dinámicamente las propiedades del contexto. También le permite ejecutar la aplicación como un servidor web real, o como un entorno simulado (sin acceso a través de HTTP), es conveniente borrar los componentes del sistema usando @MockBean , etc.
Almacenamiento en caché de contexto
Quizás uno de los temas muy oscuros en las pruebas de integración que plantea muchas preguntas y conceptos erróneos es el almacenamiento en caché de contexto (ver el párrafo 5 anterior) entre las pruebas y su efecto sobre la velocidad de las pruebas. Un comentario frecuente que escucho es que las pruebas de integración son "lentas" y "ejecutan la aplicación para cada prueba". Entonces, corren, pero no para cada prueba. Cada contexto (es decir, instancia de aplicación) se reutilizará al máximo, es decir Si 10 pruebas usan la misma configuración de la aplicación, la aplicación se iniciará una vez para las 10 pruebas. ¿Qué significa la "misma configuración" de la aplicación? Para Spring Test, esto significa que el conjunto de beans, clases de configuración, perfiles, propiedades, etc., no ha cambiado. En la práctica, esto significa que, por ejemplo, estas dos pruebas utilizarán el mismo contexto:
@SpringBootTest @ActiveProfiles("test") @TestPropertySource("foo=bar") class FirstTest { } @SpringBootTest @ActiveProfiles("test") @TestPropertySource("foo=bar") class SecondTest { }
El número de contextos en el caché está limitado a 32; además, de acuerdo con el principio de LRSU, uno de ellos se eliminará del caché.
¿Qué puede evitar que Spring Test reutilice el contexto del caché y cree uno nuevo?
@DirtiesContext
La opción más fácil es si la prueba está marcada con anotaciones, el contexto no se almacenará en caché. Esto puede ser útil si la prueba cambia el estado de la aplicación y desea "restablecerla".
@MockBean
Una opción muy obvia, incluso lo rendericé por separado: @MockBean reemplaza el bean real en contexto con un simulacro que se puede probar a través de Mockito (en los siguientes artículos mostraré cómo usarlo). El punto clave es que esta anotación cambia el conjunto de beans en la aplicación y obliga a Spring Test a crear un nuevo contexto. Si tomamos el ejemplo anterior, por ejemplo, ya se crearán dos contextos aquí:
@SpringBootTest @ActiveProfiles("test") @TestPropertySource("foo=bar") class FirstTest { } @SpringBootTest @ActiveProfiles("test") @TestPropertySource("foo=bar") class SecondTest { @MockBean CakeFinder cakeFinderMock; }
@TestPropertySource
Cualquier cambio de propiedad cambia automáticamente la clave de caché y se crea un nuevo contexto.
@ActiveProfiles
Cambiar los perfiles activos también afectará la memoria caché.
@ContextConfiguration
Y, por supuesto, cualquier cambio de configuración también creará un nuevo contexto.
Empezamos la base
Así que ahora con todo este conocimiento intentaremos despegar Comprenda cómo y dónde puede ejecutar la base de datos. Aquí no hay una respuesta correcta única, depende de los requisitos, pero puede pensar en dos opciones:
- Ejecutar una vez antes de todas las pruebas en la clase.
- Ejecute una instancia aleatoria y una base de datos separada para cada contexto en caché (potencialmente más de una clase).
Dependiendo de los requisitos, puede elegir cualquier opción. Si en mi caso, Postgres comienza relativamente rápido y la segunda opción parece adecuada, entonces la primera puede ser adecuada para algo más difícil.
La primera opción no está vinculada a Spring, sino a un marco de prueba. Por ejemplo, puede hacer su Extensión para JUnit 5 .
Si reúne todo el conocimiento sobre la biblioteca de prueba, los contextos y el almacenamiento en caché, la tarea se reduce a lo siguiente: al crear un nuevo contexto de aplicación, debe ejecutar la base de datos en un puerto aleatorio y transferir los datos de conexión al contexto .
ApplicationContextInitializer interfaz ApplicationContextInitializer es responsable de realizar acciones con el contexto antes del lanzamiento en Spring.
ApplicationContextInitializer
La interfaz solo tiene un método de initialize , que se ejecuta antes de que el contexto se "inicie" (es decir, antes de que se llame al método de refresh ) y le permite realizar cambios en el contexto: agregar contenedores, propiedades.
En mi caso, la clase se ve así:
public class EmbeddedPostgresInitializer implements ApplicationContextInitializer<GenericApplicationContext> { @Override public void initialize(GenericApplicationContext applicationContext) { EmbeddedPostgres postgres = new EmbeddedPostgres(); try { String url = postgres.start(); TestPropertyValues values = TestPropertyValues.of( "spring.test.database.replace=none", "spring.datasource.url=" + url, "spring.datasource.driver-class-name=org.postgresql.Driver", "spring.jpa.hibernate.ddl-auto=create"); values.applyTo(applicationContext); applicationContext.registerBean(EmbeddedPostgres.class, () -> postgres, beanDefinition -> beanDefinition.setDestroyMethodName("stop")); } catch (IOException e) { throw new RuntimeException(e); } } }
Lo primero que sucede aquí es que Postgres incrustado se inicia desde la biblioteca yandex-qatools / postgresql-embedded . Luego, se crea un conjunto de propiedades: la URL JDBC para la base recién lanzada, el tipo de controlador y el comportamiento de Hibernate para el esquema (crear automáticamente). Una cosa no obvia es solo spring.test.database.replace=none : esto es lo que le decimos a DataJpaTest que no tenemos que intentar conectarnos a la base de datos integrada, como H2, y que no necesitamos reemplazar el contenedor DataSource (esto funciona).
Y otro punto importante es application.registerBean(…) . En general, este bean no puede, por supuesto, registrarse, si nadie lo usa en la aplicación, no es particularmente necesario. El registro solo es necesario para especificar el método de destrucción que Spring llamará cuando se destruya el contexto, y en mi caso, este método llamará a postgres.stop() y detendrá la base de datos.
En general, eso es todo, la magia terminó, si la hubo. Ahora registraré este inicializador en un contexto de prueba:
@DataJpaTest @ContextConfiguration(initializers = EmbeddedPostgresInitializer.class) ...
O incluso por conveniencia, puede crear su propia anotación, ¡porque a todos nos encantan las anotaciones!
@Target(ElementType.TYPE) @Retention(RetentionPolicy.RUNTIME) @DataJpaTest @ContextConfiguration(initializers = EmbeddedPostgresInitializer.class) public @interface EmbeddedPostgresTest { }
Ahora, cualquier prueba anotada por @EmbeddedPostgrestTest iniciará la base de datos en un puerto aleatorio y con un nombre aleatorio, configurará Spring para conectarse a esta base de datos y la detendrá al final de la prueba.
@EmbeddedPostgresTest class JpaCakeFinderTestWithEmbeddedPostgres { ... }
Conclusión
Quería mostrar que no hay magia misteriosa en Spring, solo hay muchos mecanismos internos "inteligentes" y flexibles, pero sabiendo que puedes obtener el control completo de las pruebas y la aplicación en sí. En general, en los proyectos de combate, no motivo a todos a escribir sus propios métodos y clases para configurar el entorno de integración para las pruebas, si hay una solución preparada, puede tomarla. Aunque si el método completo es de 5 líneas de código, probablemente arrastrar la dependencia al proyecto, especialmente sin comprender la implementación, es superfluo.
Enlaces a otros artículos de la serie.