 Publicado por Denis Tsyplakov , arquitecto de soluciones, DataArt
Publicado por Denis Tsyplakov , arquitecto de soluciones, DataArtDeclaración del problema.
Uno de los problemas al construir arquitecturas de microservicios y especialmente al migrar una arquitectura monolítica a microservicios es a menudo las transacciones. Cada microservicio es responsable de su propio grupo de funciones, posiblemente controla los datos asociados con este grupo y puede atender las solicitudes de los usuarios de manera autónoma o enviando solicitudes a otros microservicios. Todo esto funciona bien hasta que necesitemos garantizar la coherencia de los datos controlados por diferentes microservicios.
Por ejemplo, nuestra aplicación funciona en una gran tienda en línea. Entre otras cosas, tenemos tres áreas de negocio separadas, débilmente interconectadas:
- Almacén: qué, dónde, cómo y durante cuánto tiempo se ha almacenado, cuántos productos de cierto tipo están actualmente en stock, etc.
- Envío de productos: embalaje, envío, seguimiento de la entrega, análisis de quejas sobre su retraso, etc.
- Realización de informes de aduanas sobre el movimiento de mercancías si las mercancías se envían al extranjero (de hecho, no sé si en este caso es necesario elaborar algo especialmente, pero aun así conectaré los servicios estatales al proceso para agregar drama).
Cada una de estas tres áreas incluye muchas funciones disjuntas y puede representarse como varios microservicios.
Hay un problema Supongamos que una persona compra un producto, lo empaca y lo envía por mensajería. Entre otras cosas, debemos indicar que hay una unidad menos de bienes en el almacén, observar que el proceso de entrega de bienes ha comenzado, y si los bienes se envían, por ejemplo, a China, para encargarse de los documentos de aduanas. Si la aplicación se bloquea (por ejemplo, un nodo se bloquea) en la segunda o tercera etapa del proceso, nuestros datos llegarán a un estado inconsistente, y solo unas pocas fallas pueden provocar problemas bastante desagradables para el negocio (por ejemplo, una visita de los funcionarios de aduanas).
En una arquitectura monolítica clásica de este tipo, el problema se resuelve de manera simple y elegante mediante transacciones en la base de datos. Pero, ¿y si usamos microservicios? Incluso si usamos la misma base de datos de todos los servicios (que no es muy elegante, pero en nuestro caso es posible), trabajar con esta base de datos proviene de diferentes procesos, y no podremos extender la transacción entre los procesos.
Soluciones
El problema tiene varias soluciones:
- Por extraño que parezca, a veces el problema puede ser ignorado. Si sabemos que una falla no ocurre más de una vez al mes, y la eliminación manual de las consecuencias cuesta dinero aceptable para el negocio, no puede prestar atención al problema, por feo que parezca. No sé si es posible ignorar las reclamaciones del servicio de aduanas, pero se puede suponer que, en ciertas circunstancias, incluso esto es posible.
- La compensación (no se trata de una compensación monetaria a la aduana, por ejemplo, pagó una multa) es un grupo de varios pasos que complican la secuencia de procesamiento, pero le permiten detectar y procesar un proceso fallido. Por ejemplo, antes de comenzar la operación, le escribimos a un servicio especial que estamos comenzando la operación de envío, y al final marcamos que todo terminó bien. Luego verificamos periódicamente para ver si hay operaciones pendientes, y si hay alguna, mirando las tres bases de datos, tratamos de llevar los datos a un estado consistente. Este es un método completamente funcional, pero complica significativamente la lógica de procesamiento, y hacerlo para cada operación es bastante doloroso.
- Las transacciones de dos fases, estrictamente hablando, la especificación XA +, que le permite crear transacciones que se distribuyen en relación con las aplicaciones, es un mecanismo muy pesado que a pocas personas les gusta y, lo que es más importante, pocas personas pueden configurar. Además, con microservicios ligeros, es ideológicamente débilmente compatible.
- En principio, una transacción es un caso especial del problema de consenso, y se pueden utilizar numerosos sistemas de consenso distribuidos para resolver el problema (en términos generales, todo lo que es google con las palabras clave paxos, balsa, zookeeper, etcd, cónsul). Pero en la aplicación práctica de datos extensos y ramificados de la actividad del almacén, todo esto parece aún más complicado que las transacciones en dos fases.
- Colas y coherencia eventual (coherencia a largo plazo): dividimos la tarea en tres tareas asincrónicas, procesamos secuencialmente los datos, los pasamos entre los servicios de la cola a la cola y utilizamos el mecanismo de confirmación de entrega. En este caso, el código no es muy complicado, pero hay algunos puntos a tener en cuenta:
- La cola garantiza la entrega "una o más veces", es decir, cuando se vuelve a entregar el mismo mensaje, el servicio debe manejar correctamente esta situación y no enviar las mercancías dos veces. Esto se puede hacer, por ejemplo, a través del UUID único del pedido.
- Los datos en cualquier momento serán ligeramente inconsistentes. Es decir, los productos primero desaparecerán del almacén y solo entonces, con un ligero retraso, se creará un pedido para su envío. Más tarde, se procesarán los datos de aduanas. En nuestro ejemplo, esto es completamente normal y no causa problemas para el negocio, pero hay casos en que dicho comportamiento de los datos puede ser muy desagradable.
- Si, como resultado, el primer servicio tiene que devolver algunos datos al usuario, la secuencia de llamadas que finalmente entrega los datos al navegador del usuario puede ser bastante trivial. El principal problema es que el navegador envía solicitudes sincrónicamente y generalmente espera una respuesta sincrónica. Si realiza un procesamiento de solicitud asincrónico, debe generar una entrega asincrónica de la respuesta al navegador. Clásicamente, esto se realiza mediante sockets web o mediante solicitudes periódicas de nuevos eventos desde el navegador al servidor. Existen mecanismos, como SocksJS, por ejemplo, que simplifican algunos aspectos de la construcción de este enlace, pero aún habrá una complejidad adicional.
En la mayoría de los casos, la última opción es la más aceptable. No complica mucho la solicitud de procesamiento, aunque funciona varias veces más, pero, por regla general, esto es aceptable para este tipo de operación. También requiere una organización de datos un poco más compleja para cortar las solicitudes repetidas, pero esto tampoco tiene nada de complicado.
Esquemáticamente, una de las opciones para procesar transacciones usando colas y Consistencia eventual puede verse así:
- El usuario realizó una compra, se envía un mensaje al respecto a la cola (por ejemplo, el clúster RabbitMQ o, si trabajamos en Google Cloud Platform - Pub / Sub). La cola es persistente, garantiza la entrega una o más veces y es transaccional, es decir, si el servicio que procesa el mensaje cae repentinamente, el mensaje no se perderá, sino que se entregará nuevamente a una nueva instancia del servicio.
- El mensaje llega al servicio, que marca las mercancías en el almacén como preparadas para el envío y, a su vez, envía el mensaje "Las mercancías están listas para el envío" a la cola.
- En el siguiente paso, el servicio responsable del despacho recibe un mensaje sobre la preparación para el despacho, crea una tarea de despacho y luego envía un mensaje "se planea el despacho de mercancías".
- El siguiente servicio, después de haber recibido un mensaje de que el envío está planeado, comienza el proceso de trámites para la aduana.
Además, se verifica la unicidad de cada mensaje recibido por el servicio, y si un mensaje con tal UUID ya ha sido procesado, se ignora.
Aquí, la (s) base (s) de la base de datos en cada momento está en un estado ligeramente inconsistente, es decir, las mercancías en el almacén ya están marcadas como en proceso de entrega, pero la tarea de entrega en sí aún no está allí, aparecerá en un segundo o dos. Pero al mismo tiempo, tenemos el 99.999% (de hecho, este número es igual al nivel de confiabilidad del servicio de cola) garantiza que aparecerá la tarea de envío. Para la mayoría de las empresas, esto es aceptable.
¿De qué trata el artículo entonces?
En el artículo quiero hablar sobre otra forma de resolver el problema de transaccionalidad en aplicaciones de microservicio. A pesar del hecho de que los microservicios funcionan mejor cuando cada servicio tiene su propia base de datos, para sistemas pequeños y medianos, todos los datos, por regla general, encajan fácilmente en una base de datos relacional moderna. Esto es cierto para casi cualquier sistema empresarial interno. Es decir, a menudo no tenemos una necesidad estricta de compartir datos entre diferentes máquinas físicas. Podemos almacenar datos de diferentes microservicios en grupos no relacionados de tablas de la misma base de datos. Esto es especialmente conveniente si está dividiendo una aplicación antigua y monolítica en servicios y ya ha dividido el código, pero los datos aún viven en la misma base de datos. Sin embargo, el problema de la división de transacciones aún persiste: la transacción está rígidamente vinculada a la conexión de red y, en consecuencia, al proceso que abrió esta conexión, y tenemos procesos separados. Como ser
Más arriba, describí varias formas comunes de resolver el problema, pero además quiero ofrecer otra forma para un caso especial, cuando todos los datos están en la misma base de datos. No
recomiendo intentar implementar este método
en este proyecto , pero es lo suficientemente curioso como para
presentarlo en el artículo. Bueno, de repente será útil en algún caso especial.
Su esencia es muy simple. Una transacción está asociada con una conexión de red, y la base de datos realmente no sabe quién está sentado en ese extremo de la conexión de red abierta. A ella no le importa, lo principal es que los comandos correctos se envían al socket. Está claro que generalmente un socket pertenece exclusivamente a un proceso en el lado del cliente, pero veo al menos tres formas de solucionarlo.
1. Cambiar el código de la base de datos
A nivel de código de base de datos para bases de datos, cuyo código podemos cambiar, haciendo nuestro propio ensamblaje de base de datos, implementamos el mecanismo para transferir transacciones entre conexiones. Cómo puede funcionar desde el punto de vista del cliente:
- Comenzamos la transacción, hacemos algunos cambios, es hora de transferir la transacción al siguiente servicio.
- Le decimos al DB que nos dé el UUID de la transacción y esperemos N segundos. Si durante este tiempo no llega otra conexión con este UUID, revierta la transacción, si es así, transfiera todas las estructuras de datos asociadas con la transacción a la nueva conexión y continúe trabajando con ella.
- Pasamos el UUID al siguiente servicio (es decir, a otro proceso, posiblemente a otra VM).
- En él, abra una conexión y dé el comando DB: continúe la transacción con el UUID especificado.
- Continuamos trabajando con la base de datos como parte de una transacción iniciada por otro proceso.
Este método es el más liviano de usar, pero requiere la modificación del código de la base de datos, los programadores de aplicaciones generalmente no lo hacen, requiere muchas habilidades especiales. Lo más probable es que sea necesario transferir datos entre los procesos de la base de datos y las bases de datos, cuyo código podemos cambiar de manera segura en general, uno: PostgreSQL. Además, esto funcionará solo para servidores no administrados, no lo utilizará en RDS o Cloud SQL.
Esquemáticamente, se ve así:

2. Manipulación de enchufes
La segunda cosa que viene a la mente es la manipulación sutil de las conexiones de la base de datos por sockets. Podemos hacer un "proxy de socket inverso", que dirige los comandos procedentes de varios clientes a un puerto específico en un flujo de comandos a la base de datos.
De hecho, esta aplicación es muy similar a pgBouncer, solo que, además de su funcionalidad estándar, realiza algunas manipulaciones con el flujo de bytes de los clientes y puede sustituir a un cliente en lugar de otro por comando.
No me gusta mucho este método, para su implementación es necesario limpiar los paquetes binarios que circulan entre el servidor y los clientes. Y todavía requiere mucha programación del sistema. Lo traje únicamente para completar.
3. Gateway JDBC
Podemos hacer un controlador JDBC de puerta de enlace: tomamos el controlador JDBC estándar para una base de datos específica, dejemos que sea PostgreSQL. Ajustamos la clase y hacemos interfaces HTTP a todos sus métodos externos (no HTTP, pero la diferencia es pequeña). A continuación, creamos otro controlador JDBC: una fachada, que redirige todas las llamadas a métodos a la puerta de enlace JDBC. Es decir, de hecho, estamos cortando el controlador existente en dos mitades y conectando estas mitades a través de la red. Obtenemos el siguiente diagrama de componentes:
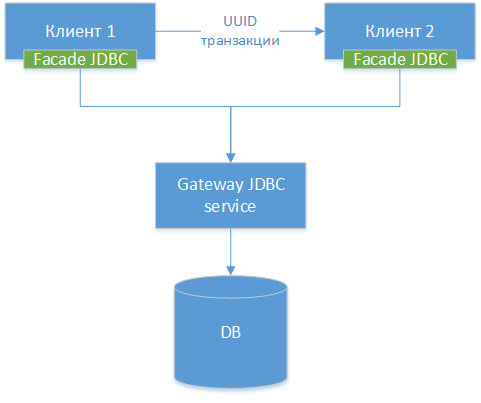 ¡NOTA!: Como podemos ver, las tres opciones son similares, la única diferencia es a qué nivel transferimos la conexión y qué herramientas usamos para esto.
¡NOTA!: Como podemos ver, las tres opciones son similares, la única diferencia es a qué nivel transferimos la conexión y qué herramientas usamos para esto.
Después de eso, le enseñamos a nuestro controlador a hacer esencialmente el mismo truco con la transacción UUID que se describe en el método 1.
En el código de la aplicación Java, el uso de este método podría verse así.
Servicio A - inicio de transacción
A continuación se muestra el código de algún servicio que inicia una transacción, realiza cambios en la base de datos y la pasa a otro servicio para completarla. En el código, usamos trabajo directo con clases JDBC. Por supuesto, nadie hace esto en 2019, pero por simplicidad, el código se simplifica.
Servicio B - finalización de transacción
Interacción con otros componentes y marcos.
Considere los posibles efectos secundarios de tal solución arquitectónica.
Pool de conexiones
Dado que en realidad tendremos un grupo de conexiones real dentro de la puerta de enlace JDBC, es mejor desactivar los grupos de conexiones en los servicios, ya que capturarán y mantendrán una conexión dentro del servicio que podría ser utilizada por otro servicio.
Además, después de recibir el UUID y esperar la transferencia a otro proceso, la conexión esencialmente no funciona, y desde el punto de vista de la interfaz JDBC, se cierra automáticamente, y desde el punto de vista de la puerta de enlace JDBC, debe mantenerse sin dar a nadie más que a quién vendrá con el UUID deseado.
En otras palabras, la gestión dual del grupo de conexiones en Gateway JDBC y dentro de cada uno de los servicios puede producir errores sutiles y desagradables.
Jpa
Con JPA, veo dos posibles problemas:
- Gestión de transacciones. Al cometer un JPA, el motor puede pensar que ha guardado todos los datos, mientras que no se ha guardado. Lo más probable es que la gestión manual de transacciones y flush () antes de transferir la transacción resuelvan el problema.
- Es probable que el caché de segundo nivel funcione incorrectamente, pero en sistemas distribuidos su uso es limitado en cualquier caso.
Transacciones de primavera
El mecanismo de administración de transacciones de Spring, tal vez, no se puede activar, y tendrá que administrarlos manualmente. Estoy casi seguro de que se puede expandir, por ejemplo, para escribir un alcance personalizado, pero para decirlo con certeza, necesitamos estudiar cómo se organiza la extensión Spring Transactions allí, pero aún no he buscado allí.
Pros y contras
Pros
- Prácticamente no requiere modificación del código monolítico existente al aserrar.
- Puede escribir transacciones complejas entre servidores prácticamente sin complejidad de código.
- Le permite hacer un seguimiento de la ejecución de transacciones entre servicios.
- La solución es bastante flexible, puede usar transacciones clásicas donde no se requiere distribución y compartir la transacción solo para aquellas operaciones donde se requiere interacción entre servicios.
- El equipo del proyecto no está obligado a dominar por la fuerza las nuevas tecnologías. Las nuevas tecnologías son, por supuesto, buenas, pero la tarea - es imperativa y urgente (¡hasta ayer!) Enseñar a 20 desarrolladores el concepto de construir sistemas reactivos - puede ser muy poco trivial. Sin embargo, no hay garantía de que las 20 personas completarán la capacitación a tiempo.
Contras
- No escalable y, de hecho, no modular a nivel de base de datos, en contraste con una solución en cola. Todavía tiene una base de datos en la que convergen todas las consultas y toda la carga. En este sentido, la solución es un callejón sin salida: si luego desea aumentar la carga o hacer que la solución sea modular de acuerdo con los datos, tendrá que rehacer todo.
- Debe tener mucho cuidado al transferir una transacción entre procesos, especialmente procesos escritos en marcos. Las sesiones tienen su propia configuración, y para varios marcos, un cambio repentino en la conexión con la base de datos puede conducir a una operación incorrecta. Consulte, por ejemplo, la configuración de sesión y las transacciones para PostgreSQL.
- Cuando dije la idea en el chat de nuestro arquitecto local en DataArt, lo primero que me preguntaron mis colegas fue si estaba bebiendo (¡no, no bebiendo!). Pero admito que la idea, digamos, no es la más extendida, y si la implementa en su proyecto, será muy inusual para sus otros participantes.
- Requiere un controlador JDBC personalizado. Escribirlo lleva tiempo, debe depurarlo, buscar errores en él, incluidos los causados por errores de comunicación de red, etc.
Advertencia
Te lo advierto una vez más:
no intentes repetir este truco en casa en este proyecto, a menos que tengas una explicación muy clara de por qué lo necesitas, y pruebas convincentes de que no hay otra manera.
Todo desde el primero de abril!