El artículo se publica en nombre de John Akhaltsev , Jiga.
Tinkoff.ru hoy no es solo un banco, es una empresa de TI. Proporciona no solo servicios bancarios, sino que también construye un ecosistema a su alrededor.
En Tinkoff.ru nos asociamos con varios servicios para mejorar la calidad del servicio al cliente y ayudar a mejorar los servicios. Por ejemplo, realizamos pruebas de carga y análisis de rendimiento de uno de esos servicios que ayudaron a encontrar cuellos de botella en el sistema, incluidas Transparent Huge Pages en la configuración del sistema operativo.
Si desea saber cómo realizar un análisis del rendimiento del sistema y de lo que vino con nosotros, bienvenido a cat.
Descripción del problema
Por el momento, la arquitectura de servicio es:
- Servidor web Nginx para manejar conexiones http
- Php-fpm para control de procesos php
- Redis para el almacenamiento en caché
- PostgreSQL para almacenamiento de datos
- Solución integral de compras
El principal problema que encontramos durante la próxima venta bajo alta carga fue la alta utilización de la CPU, mientras que el tiempo del procesador en modo kernel (tiempo del sistema) aumentó y fue más largo que el tiempo en modo de usuario (tiempo de usuario).
- Tiempo de usuario: el tiempo que el procesador dedica a las tareas del usuario. Esto es lo principal por lo que paga al comprar un procesador.
- Hora del sistema: la cantidad de tiempo que el sistema dedica a la paginación, el cambio de contexto, el inicio de tareas programadas y otras tareas del sistema.
Determinar las características principales del sistema.
Para comenzar, recopilamos un circuito de carga con recursos cercanos a los productivos y compilamos un perfil de carga correspondiente a una carga normal en un día típico.
Se eligió la versión 3 de Gatling como herramienta de bombardeo, y el bombardeo se llevó a cabo dentro de la red local a través de gitlab-runner. La ubicación de los agentes y objetivos en la misma red local se debe a la reducción de los costos de red, por lo que nos centramos en verificar la ejecución del código en sí, y no en el rendimiento de la infraestructura donde se implementa el sistema.
Al determinar las características principales del sistema, es adecuado un escenario con una carga que aumenta linealmente con una configuración http:
val httpConfig: HttpProtocolBuilder = http .baseUrl("https://test.host.ru") .inferHtmlResources()
En esta etapa, implementamos un script para abrir la página principal y descargar todos los recursos.

Los resultados de esta prueba mostraron un rendimiento máximo de 1500 rps, un aumento adicional en la intensidad de la carga condujo a la degradación del sistema asociado con el aumento del tiempo de softirq.


Softirq es un mecanismo de interrupción retardada y se describe en el archivo kernel / softirq.s. Al mismo tiempo, bloquean la cola de instrucciones para el procesador, evitando que hagan cálculos útiles en modo de usuario. Los controladores de interrupción también pueden retrasar el trabajo adicional con paquetes de red en subprocesos del sistema operativo (hora del sistema). Brevemente sobre el trabajo de la pila de red y las optimizaciones se pueden encontrar en un artículo separado .
La sospecha del problema principal no se confirmó, porque había un tiempo de sistema mucho más largo en el producto con menos actividad de red.
Guiones de usuario
El siguiente paso fue desarrollar scripts personalizados y agregar algo más que solo abrir una página con imágenes. El perfil incluye operaciones pesadas, que involucraron completamente el código del sitio y la base de datos, y no un servidor web que proporciona recursos estáticos.
La prueba con carga estable se lanzó a una intensidad inferior a la máxima, se agregó una transición de redireccionamiento a la configuración:
val httpConfig: HttpProtocolBuilder = http .baseUrl("https://test.host.ru") .inferHtmlResources()
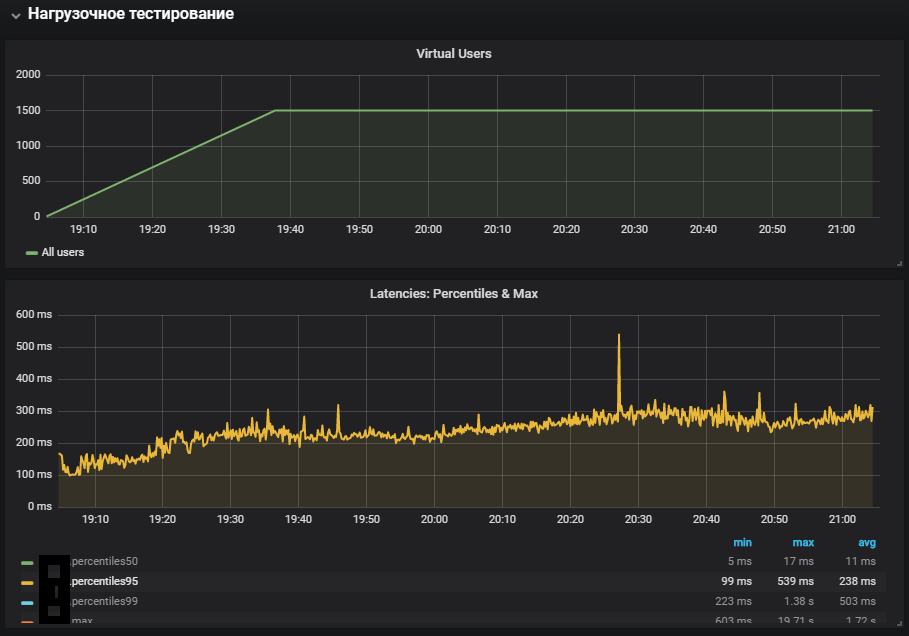

El uso más completo de los sistemas mostró un aumento en la métrica de tiempo del sistema, así como su crecimiento durante la prueba de estabilidad. Se reprodujo el problema con el entorno de producción.
Redes con Redis
Al analizar los problemas, es muy importante monitorear todos los componentes del sistema para entender cómo funciona y qué impacto tiene sobre él la carga suministrada.
Con el advenimiento del monitoreo de Redis, se hizo posible observar no las métricas generales del sistema, sino sus componentes específicos. El escenario para las pruebas de estrés también se modificó, lo que, junto con un monitoreo adicional, ayudó a abordar la localización del problema.

En el monitoreo, Redis vio una imagen similar con la utilización de la CPU, o más bien, el tiempo del sistema es significativamente más largo que el tiempo del usuario, mientras que la utilización principal de la CPU estaba en la operación SET, es decir, la asignación de RAM para almacenar el valor.

Para eliminar el efecto de la interacción de la red con Redis, se decidió probar la hipótesis y cambiar Redis a un socket UNIX en lugar de un socket tcp. Esto se hizo directamente en el marco a través del cual php-fpm se conecta a la base de datos. En el archivo /yiisoft/yii/framework/caching/CRedisCache.php, reemplazamos la línea del host: puerto con el código rígido redis.sock. Lea más sobre el rendimiento del socket en el artículo .
protected function connect() { $this->_socket=@stream_socket_client(
Desafortunadamente, esto no tuvo mucho efecto. La utilización de la CPU se estabilizó un poco, pero no resolvió nuestro problema: la mayor parte de la utilización de la CPU fue en la computación en modo kernel.
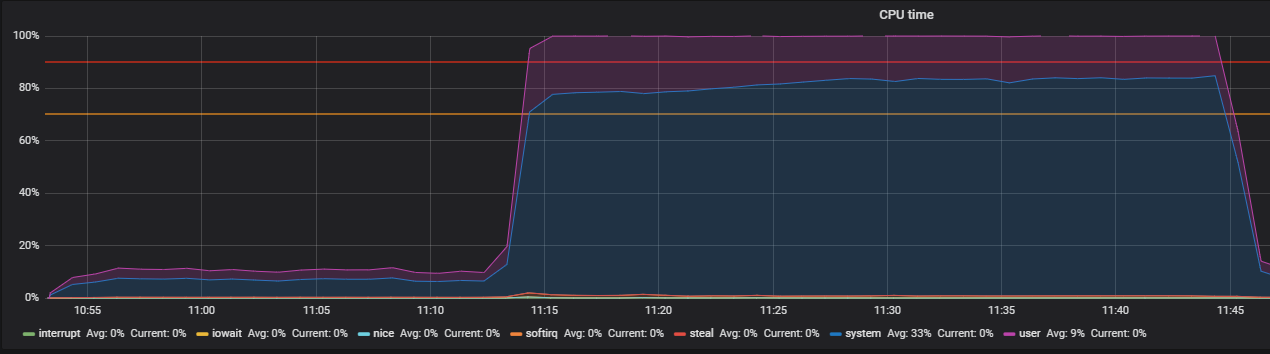
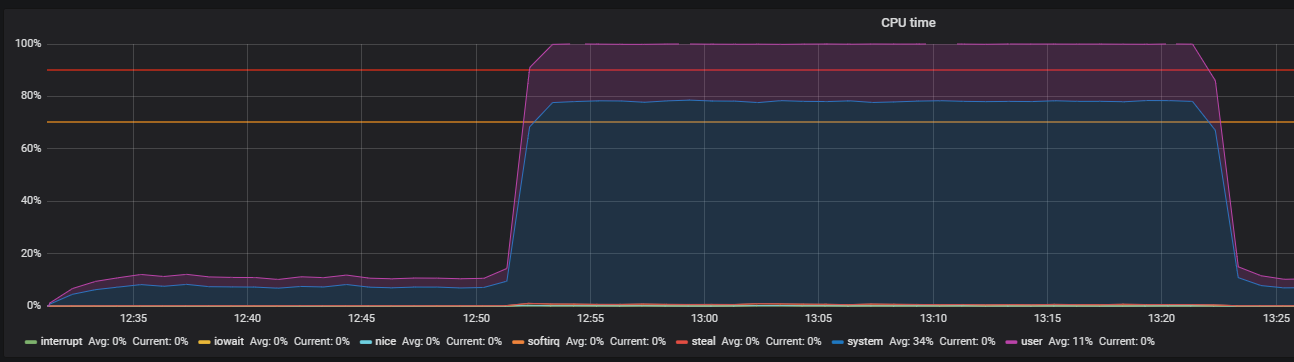
Punto de referencia sobre el estrés y la identificación de problemas de THP
La utilidad de estrés ayudó a localizar el problema: un generador de carga de trabajo simple para sistemas POSIX, que puede cargar componentes individuales del sistema, por ejemplo, CPU, Memoria, IO.
Las pruebas se suponen en la versión de hardware y sistema operativo:
Ubuntu 18.04.1 LTS
12 CPU Intel® Xeon®
La utilidad se instala usando el comando:
sudo apt-get install stress
Observamos cómo se utiliza la CPU bajo carga, ejecutamos una prueba que crea trabajadores para calcular raíces cuadradas con una duración de 300 segundos:
-c, --cpu N spawn N workers spinning on sqrt() > stress --cpu 12 --timeout 300s stress: info: [39881] dispatching hogs: 12 cpu, 0 io, 0 vm, 0 hdd
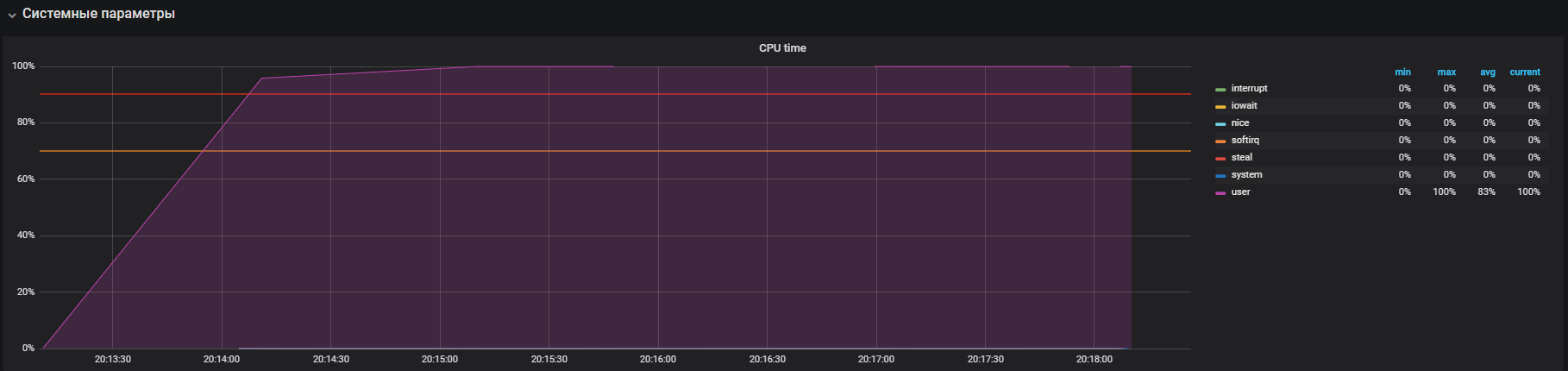
El gráfico muestra la utilización completa en modo de usuario; esto significa que se cargan todos los núcleos de procesador y se realizan cálculos útiles, no llamadas de servicio del sistema.
El siguiente paso es usar recursos cuando se trabaja intensamente con io. Ejecute la prueba durante 300 segundos con la creación de 12 trabajadores que ejecutan sync (). El comando de sincronización escribe datos almacenados en la memoria del disco. El núcleo almacena datos en la memoria para evitar operaciones frecuentes (generalmente lentas) de lectura y escritura en disco. El comando sync () asegura que todo lo almacenado en la memoria se escriba en el disco.
-i, --io N spawn N workers spinning on sync() > stress --io 12 --timeout 300s stress: info: [39907] dispatching hogs: 0 cpu, 0 io, 0 vm, 12 hdd

Vemos que el procesador se dedica principalmente al procesamiento de llamadas en modo kernel y un poco en iowait, también puede ver> 35k operaciones escritas en el disco. Este comportamiento es similar a un problema con un tiempo de sistema elevado, cuyas causas estamos analizando. Pero aquí hay varias diferencias: estos son iowait y iops son más grandes que en el circuito productivo, respectivamente, esto no se ajusta a nuestro caso.
Es hora de revisar tu memoria. Lanzamos 20 trabajadores que asignarán y liberarán memoria durante 300 segundos con el comando:
-m, --vm N spawn N workers spinning on malloc()/free() > stress -m 20 --timeout 300s stress: info: [39954] dispatching hogs: 0 cpu, 0 io, 20 vm, 0 hdd
Inmediatamente vemos la alta utilización de la CPU en modo sistema y un poco en modo usuario, así como el uso de RAM de más de 2 GB.
Este caso es muy similar al problema con el producto, que se confirma por el gran uso de memoria en las pruebas de carga. Por lo tanto, el problema debe buscarse en la operación de memoria. La asignación y liberación de memoria ocurre con la ayuda de malloc y llamadas gratuitas, respectivamente, que eventualmente serán procesadas por las llamadas al sistema del núcleo, lo que significa que se mostrarán en la utilización de la CPU como hora del sistema.
En la mayoría de los sistemas operativos modernos, la memoria virtual se organiza mediante paginación, con este enfoque, toda el área de memoria se divide en páginas de una longitud fija, por ejemplo 4096 bytes (por defecto para muchas plataformas), y al asignar, por ejemplo, 2 GB de memoria, el administrador de memoria tendrá que operar Más de 500,000 páginas. En este enfoque, existen grandes gastos generales de gestión y páginas enormes y se inventaron tecnologías de páginas enormes transparentes para reducirlas, con su ayuda puede aumentar el tamaño de la página, por ejemplo, a 2 MB, lo que reducirá significativamente el número de páginas en el montón de memoria. La diferencia en la tecnología es solo que para las páginas enormes debemos configurar explícitamente el entorno y enseñar al programa cómo trabajar con ellos, mientras que las páginas enormes transparentes funcionan "transparentemente" para los programas.
THP y resolución de problemas
Si buscas en Google información sobre Transparent Huge Pages, puedes ver en los resultados de búsqueda muchas páginas con las preguntas "Cómo desactivar THP".
Al final resultó que, esta característica "genial" fue introducida por la corporación Red Hat en el kernel de Linux, la esencia de la característica es que las aplicaciones pueden trabajar de forma transparente con la memoria como si funcionaran con una página enorme real. Según los puntos de referencia, THP acelera la aplicación de resúmenes en un 10%, puede ver más detalles en la presentación, pero en realidad todo es diferente. En algunos casos, THP provoca un aumento irrazonable en el consumo de CPU en los sistemas. Para obtener más información, consulte las recomendaciones de Oracle.
Vamos y verificamos nuestro parámetro. Como resultó, THP está activado de forma predeterminada, lo desactivamos con el comando:
echo never > /sys/kernel/mm/transparent_hugepage/enabled
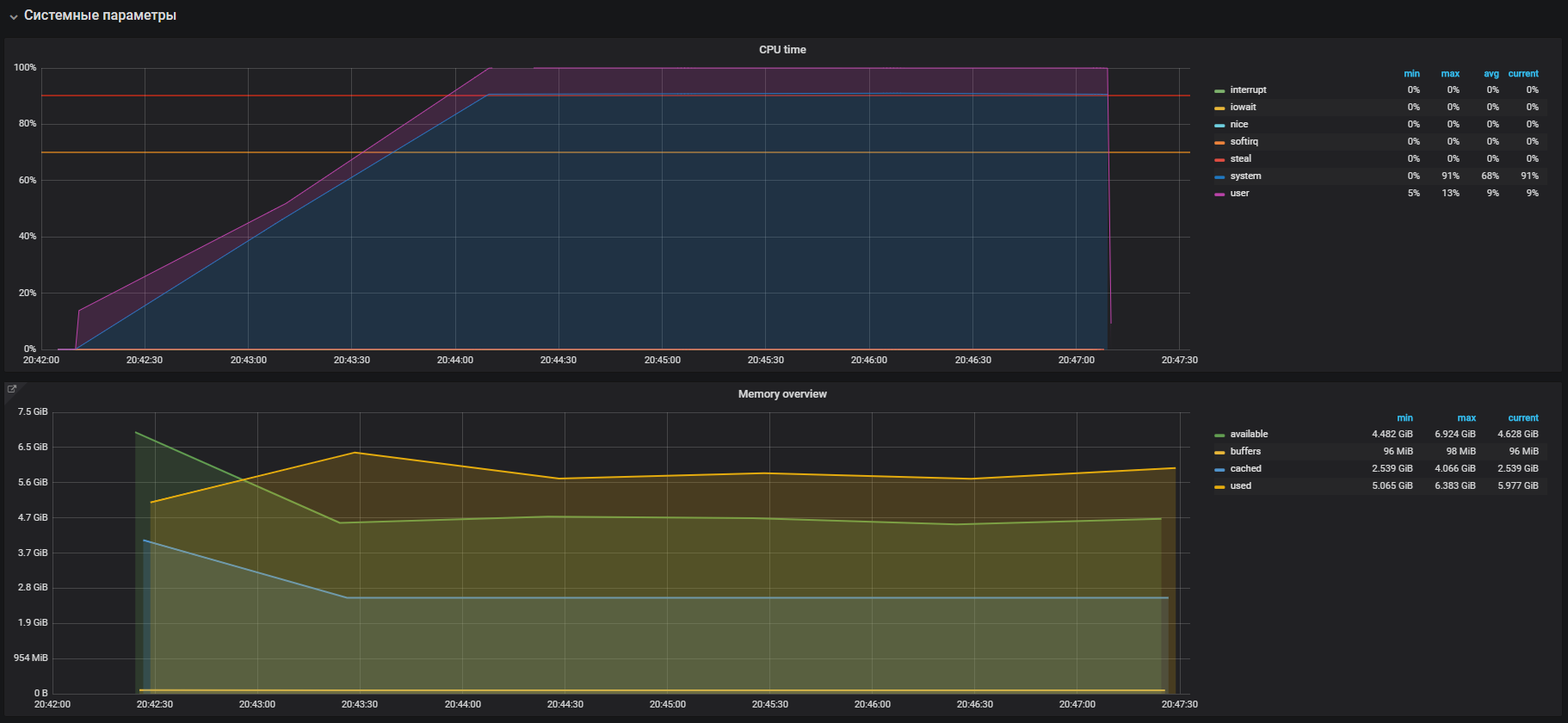
Confirmamos con la prueba antes de apagar THP y luego, en el perfil de carga:
setUp( MainScenario.inject( rampUsers(150) during (200 seconds)), Peak.inject( nothingFor(20 minutes), rampUsers(5000) during (30 minutes)) ).protocols(httpConfig)

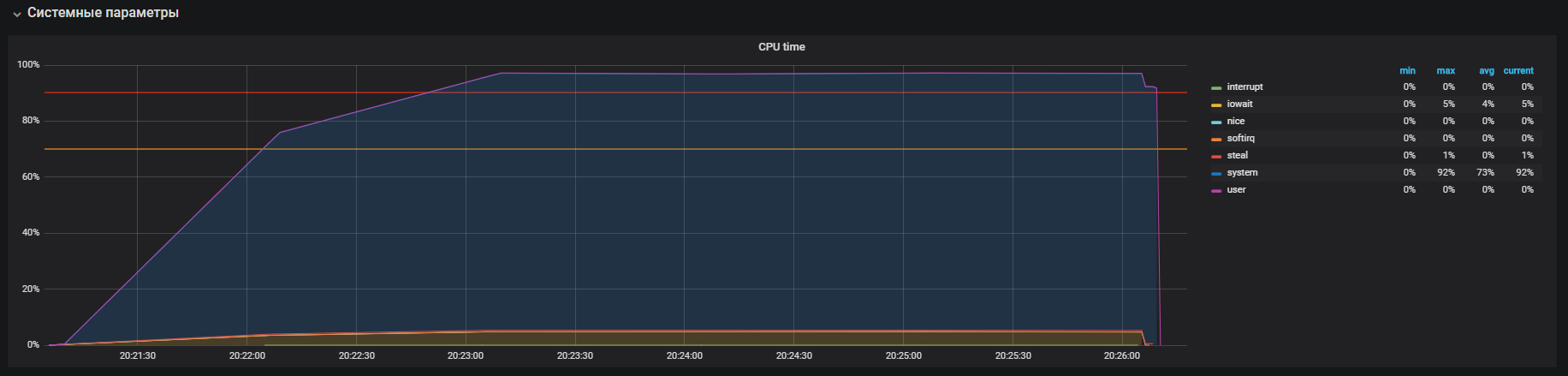
Vimos esta imagen antes de apagar THP

Después de desactivar THP, podemos observar una utilización de recursos ya reducida.
El principal problema fue localizado. El motivo estaba habilitado de forma predeterminada en el sistema operativo
mecanismo de páginas grandes transparentes. Después de deshabilitar la opción THP, la utilización de la CPU en modo sistema disminuyó al menos 2 veces, lo que liberó recursos para el modo de usuario. Durante el análisis del problema principal, también se encontraron "cuellos de botella" de interacción con la pila de red del sistema operativo y Redis, que es la razón de un estudio más profundo. Pero esta es una historia completamente diferente.
Conclusión
En conclusión, me gustaría dar algunos consejos para buscar con éxito problemas de rendimiento:
- Antes de investigar el rendimiento del sistema, comprenda cuidadosamente su arquitectura e interacciones de componentes.
- Configure el monitoreo para todos los componentes del sistema y realice un seguimiento, si no hay suficientes métricas estándar, profundice y amplíe.
- Lea los manuales de los sistemas utilizados.
- Compruebe la configuración predeterminada en los archivos de configuración del sistema operativo y los componentes del sistema.