Anuncio
Colegas, a mediados del verano planeo publicar otra serie de artículos sobre el diseño de sistemas de colas: "Experimento VTrade", un intento de escribir un marco para los sistemas de negociación. El ciclo analizará la teoría y la práctica de construir un intercambio, subasta y tienda. Al final del artículo, propongo votar por los temas que más le interesen.

Este es el artículo final del ciclo de aplicación reactiva distribuida Erlang / Elixir. En el primer artículo, puede encontrar los fundamentos teóricos de la arquitectura reactiva. El segundo artículo ilustra los patrones y mecanismos básicos para construir tales sistemas.
Hoy vamos a plantear cuestiones sobre el desarrollo de la base del código y los proyectos en general.
Organización de servicio
En la vida real, al desarrollar un servicio, a menudo tiene que combinar varios patrones de interacción en un controlador. Por ejemplo, el servicio de usuarios, que resuelve las tareas de administrar los perfiles de usuario para un proyecto, debe responder a las solicitudes de solicitud de respuesta y reportar actualizaciones de perfil a través de pub-sub. Este caso es bastante simple: detrás de la mensajería hay un controlador que implementa la lógica del servicio y publica actualizaciones.
La situación se complica cuando necesitamos implementar un servicio distribuido tolerante a fallas. Supongamos que los requisitos de los usuarios han cambiado:
- ahora el servicio debería procesar solicitudes en 5 nodos del clúster,
- ser capaz de realizar tareas de procesamiento en segundo plano,
- y poder administrar dinámicamente sus listas de suscripción de actualización de perfil.
Nota: No consideramos el problema del almacenamiento consistente y la replicación de datos. Suponga que estos problemas se han resuelto antes y que el sistema ya tiene una capa de almacenamiento confiable y escalable, y los controladores tienen mecanismos para interactuar con ella.
La descripción formal del servicio del usuario se ha vuelto más complicada. Desde el punto de vista del programador, el uso de cambios en la mensajería es mínimo. Para satisfacer el primer requisito, necesitamos ajustar el equilibrio en el punto de intercambio req-resp.
A menudo surge el requisito de manejar tareas en segundo plano. En los usuarios, esto puede ser verificar documentos del usuario, procesar archivos multimedia descargados o sincronizar datos con los servicios sociales. redes. Estas tareas deben distribuirse de alguna manera dentro del clúster y controlar el progreso. Por lo tanto, tenemos dos soluciones: usar la plantilla de distribución de tareas del artículo anterior o, si no encaja, escribir un programador de tareas personalizado que será necesario para que podamos administrar el conjunto de controladores.
El punto 3 requiere una extensión de la plantilla pub-sub. Y para la implementación, después de crear el punto de intercambio pub-sub, necesitamos lanzar adicionalmente el controlador de este punto como parte de nuestro servicio. Por lo tanto, parece que tomamos la lógica de procesar la suscripción y la cancelación de la suscripción de la capa de mensajería en la implementación de los usuarios.
Como resultado, la descomposición de la tarea mostró que para cumplir con los requisitos, necesitamos ejecutar 5 instancias de servicio en diferentes nodos y crear una entidad adicional: el controlador pub-sub responsable de la suscripción.
Para ejecutar 5 controladores, no necesita cambiar el código de servicio. La única acción adicional es establecer reglas de equilibrio en el punto de intercambio, del que hablaremos más adelante.
Además, apareció una complejidad adicional: el controlador pub-sub y el programador de tareas personalizado deberían funcionar en una sola copia. Nuevamente, el servicio de mensajería, como fundamental, debería proporcionar un mecanismo para seleccionar un líder.
Elección del líder
En sistemas distribuidos, la elección de un líder es el proceso de nombrar el único proceso responsable de planificar el procesamiento distribuido de una carga.
En los sistemas que no son propensos a la centralización, se utilizan algoritmos de consenso universal, como paxos o balsa.
Dado que la mensajería es un agente y un elemento central, él conoce todos los controladores de servicio, candidatos para el liderazgo. La mensajería puede designar a un líder sin voto.
Después de iniciar y conectarse al punto de intercambio, todos los servicios reciben el mensaje del sistema #'$leader'{exchange = ?EXCHANGE, pid = LeaderPid, servers = Servers} . Si LeaderPid coincide con el pid proceso actual, se le asigna como líder y la lista de Servers incluye todos los nodos y sus parámetros.
Cuando aparece un nuevo nodo del clúster y se desconecta, todos los controladores de servicio reciben #'$slave_up'{exchange = ?EXCHANGE, pid = SlavePid, options = SlaveOpts} y #'$slave_down'{exchange = ?EXCHANGE, pid = SlavePid, options = SlaveOpts} respectivamente.
Por lo tanto, todos los componentes son conscientes de todos los cambios, y en el clúster en un momento dado se garantiza un líder.
Intermediarios
Para la implementación de procesos complejos de procesamiento distribuido, así como en la optimización de una arquitectura existente, es conveniente utilizar intermediarios.
Para no cambiar el código de servicios y resolver, por ejemplo, las tareas de procesamiento adicional, enrutamiento o mensajes de registro, puede habilitar un procesador proxy antes del servicio, que realizará todo el trabajo adicional.
Un ejemplo clásico de optimización de pub-sub es una aplicación distribuida con un kernel empresarial que genera eventos de actualización, por ejemplo, un cambio en el precio de mercado y una capa de acceso: servidores N que proporcionan API websocket para clientes web.
Si decide "frente", el servicio al cliente es el siguiente:
- El cliente establece conexiones con la plataforma. En el lado del servidor, finalizando el tráfico, comienza el proceso que sirve esta conexión.
- En el contexto del proceso de servicio, se lleva a cabo la autorización y suscripción a las actualizaciones. El proceso llama al método de suscripción para temas.
- después de que el evento se genera en el kernel, se entrega a los procesos que sirven a las conexiones.
Imagine que tenemos 50,000 suscriptores al tema "noticias". Los suscriptores se distribuyen de manera uniforme en 5 servidores. Como resultado, cada actualización, que llega al punto de intercambio, se replicará 50,000 veces: 10,000 veces a cada servidor, de acuerdo con el número de suscriptores. No es un esquema efectivo, ¿verdad?
Para mejorar la situación, presentamos un proxy que tiene el mismo nombre con el punto de intercambio. El registrador de nombre global debería poder devolver el proceso más cercano por nombre, esto es importante.
Ejecute este proxy en los servidores de la capa de acceso, y todos nuestros procesos que sirven a la API websocket se suscribirán a él, y no al punto de intercambio pub-sub original en el núcleo. Proxy se suscribe al kernel solo en el caso de una suscripción única y replica el mensaje entrante a todos sus suscriptores.
Como resultado, se enviarán 5 mensajes entre el kernel y los servidores de acceso, en lugar de 50,000.
Enrutamiento y equilibrio
Req-resp
En la implementación actual de mensajería, hay 7 estrategias de distribución de consultas:
default La solicitud se pasa a todos los controladores.round-robin Itera y distribuye cíclicamente las solicitudes entre los controladores.consensus . Los controladores que sirven al servicio se dividen en líderes y seguidores. Las solicitudes se pasan solo al líder.consensus & round-robin . Hay un líder en el grupo, pero las solicitudes se distribuyen entre todos los miembros.sticky La función hash se calcula y se asigna a un controlador específico. Las solicitudes posteriores con esta firma van al mismo controlador.sticky-fun Cuando se inicializa el punto de intercambio, la función de cálculo hash para el equilibrio fijo se transfiere adicionalmente.fun Es similar a Sticky-Fun, solo que además puedes redirigirlo, rechazarlo o preprocesarlo.
La estrategia de distribución se establece cuando se inicializa el punto de intercambio.
Además de equilibrar la mensajería, le permite etiquetar entidades. Considere los tipos de etiquetas en el sistema:
- Etiqueta de conexión Le permite comprender a través de qué conexión llegaron los eventos. Se utiliza cuando el proceso del controlador se conecta al mismo punto de intercambio, pero con diferentes claves de enrutamiento.
- Etiqueta de servicio Permite un solo servicio para agrupar procesadores y ampliar las capacidades de enrutamiento y equilibrio. Para el patrón req-resp, el enrutamiento es lineal. Enviamos una solicitud al punto de intercambio, luego la pasa al servicio. Pero si necesitamos dividir los controladores en grupos lógicos, la división se lleva a cabo mediante etiquetas. Al especificar una etiqueta, la solicitud se dirigirá a un grupo específico de controladores.
- Solicitar etiqueta. Permite distinguir respuestas. Dado que nuestro sistema es asíncrono, para procesar respuestas de servicio, debe poder especificar una Etiqueta de solicitud al enviar una solicitud. De él podemos entender la respuesta a la que nos llegó la solicitud.
Pub sub
Para pub-sub, las cosas son un poco más fáciles. Tenemos un punto de intercambio para el cual se publican los mensajes. El punto de intercambio distribuye mensajes entre suscriptores que se suscriben a las claves de enrutamiento que necesitan (podemos decir que esto es análogo a esos).
Escalabilidad y resistencia
La escalabilidad del sistema en su conjunto depende del grado de escalabilidad de las capas y componentes del sistema:
- Los servicios se escalan agregando nodos adicionales al clúster con controladores para este servicio. Durante la operación de prueba, puede elegir la política de equilibrio óptima.
- El servicio de mensajería en sí, dentro de un solo clúster, generalmente se amplía moviendo puntos de intercambio especialmente cargados a nodos individuales del clúster o agregando procesos proxy a zonas especialmente cargadas del clúster.
- La escalabilidad de todo el sistema como característica depende de la flexibilidad de la arquitectura y la posibilidad de combinar grupos individuales en una entidad lógica común.
La simplicidad y la velocidad del escalado a menudo determinan el éxito de un proyecto. La mensajería en su rendimiento actual crece con la aplicación. Incluso si carecemos de un grupo de 50-60 automóviles, podemos recurrir a la federación. Desafortunadamente, el tema de la federación está más allá del alcance de este artículo.
Reserva
En el análisis del equilibrio de carga, ya hemos discutido la reserva de controladores de servicio. Sin embargo, la mensajería también debe reservarse. En el caso de un nodo o una falla de la máquina, la mensajería debería recuperarse automáticamente, y lo antes posible.
En mis proyectos, uso nodos adicionales que recogen la carga en caso de una caída. Erlang tiene una implementación de modo distribuido estándar para aplicaciones OTP. El modo distribuido, de hecho, realiza la recuperación en caso de falla al iniciar la aplicación bloqueada en otro nodo previamente lanzado. El proceso es transparente, después de una falla, la aplicación se mueve automáticamente al nodo de conmutación por error. Puede leer más sobre esta funcionalidad aquí .
Rendimiento
Intentemos al menos comparar aproximadamente el rendimiento de rabbitmq y nuestros mensajes personalizados.
Encontré los resultados oficiales de la prueba rabbitmq del equipo de OpenStack.
En la cláusula 6.14.1.2.1.2.2. El documento original presenta el resultado de RPC CAST:
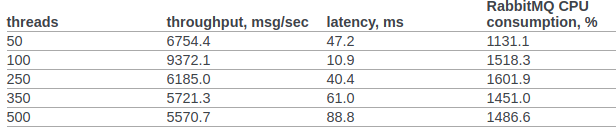
Anteriormente, no realizaremos ninguna configuración adicional en el kernel del sistema operativo o en la máquina virtual erlang. Condiciones de prueba:
- erl opta: + A1 + sbtu.
- La prueba dentro de un solo nodo erlang se ejecuta en una computadora portátil con un viejo i7 en rendimiento móvil.
- Las pruebas de clúster se realizan en servidores con una red 10G.
- El código funciona en contenedores acoplables. Red en modo NAT.
Código de prueba:
req_resp_bench(_) -> W = perftest:comprehensive(10000, fun() -> messaging:request(?EXCHANGE, default, ping, self()), receive #'$msg'{message = pong} -> ok after 5000 -> throw(timeout) end end ), true = lists:any(fun(E) -> E >= 30000 end, W), ok.
Escenario 1: la prueba se ejecuta en una computadora portátil con una antigua ejecución móvil i7. La prueba, la mensajería y el servicio se ejecutan en un nodo en un contenedor acoplable:
Sequential 10000 cycles in ~0 seconds (26987 cycles/s) Sequential 20000 cycles in ~1 seconds (26915 cycles/s) Sequential 100000 cycles in ~4 seconds (26957 cycles/s) Parallel 2 100000 cycles in ~2 seconds (44240 cycles/s) Parallel 4 100000 cycles in ~2 seconds (53459 cycles/s) Parallel 10 100000 cycles in ~2 seconds (52283 cycles/s) Parallel 100 100000 cycles in ~3 seconds (49317 cycles/s)
Escenario 2 : 3 nodos que se ejecutan en diferentes máquinas en Docker (NAT).
Sequential 10000 cycles in ~1 seconds (8684 cycles/s) Sequential 20000 cycles in ~2 seconds (8424 cycles/s) Sequential 100000 cycles in ~12 seconds (8655 cycles/s) Parallel 2 100000 cycles in ~7 seconds (15160 cycles/s) Parallel 4 100000 cycles in ~5 seconds (19133 cycles/s) Parallel 10 100000 cycles in ~4 seconds (24399 cycles/s) Parallel 100 100000 cycles in ~3 seconds (34517 cycles/s)
En todos los casos, la utilización de la CPU no superó el 250%
Resumen
Espero que este ciclo no parezca un tugurio de conciencia y mi experiencia traerá beneficios reales tanto para los investigadores de sistemas distribuidos como para los profesionales que están al comienzo del camino de construir arquitecturas distribuidas para sus sistemas comerciales y que miran a Erlang / Elixir con interés, pero dudan vale la pena ...
Foto por @chuttersnap