En el campo del desarrollo de aplicaciones multiproceso o distribuidas altamente cargadas, a menudo surgen discusiones sobre programación asincrónica. Hoy nos sumergiremos en la asincronía en detalle y estudiaremos qué es cuando ocurre, cómo afecta el código y el lenguaje de programación que usamos. Averiguaremos por qué se necesitan Futuros y Promesas, y tocaremos corutinas y sistemas operativos. Esto hará que las compensaciones que surjan durante el desarrollo de software sean más explícitas.
El material se basa en una transcripción de un informe de Ivan Puzyrevsky, profesor de la Escuela de Análisis de Datos Yandex.

Grabación de video
1. Contenido
2. Introducción
Hola a todos, mi nombre es Ivan Puzyrevsky, trabajo para Yandex. Durante los últimos seis años he estado involucrado en la infraestructura de almacenamiento y procesamiento de datos, ahora cambié al producto, en busca de viajes, hoteles y boletos. Como trabajé durante mucho tiempo en la infraestructura, he adquirido mucha experiencia sobre cómo escribir diferentes aplicaciones cargadas. Nuestra infraestructura opera 24*7*365 todos los días sin parar, continuamente en miles de máquinas. Naturalmente, debe escribir código para que funcione de manera confiable y eficiente y resuelva las tareas que plantea la empresa.
Hoy hablaremos de asincronía. ¿Qué es la asincronía? Es una falta de coincidencia de algo con algo a tiempo. Según esta descripción, generalmente no está claro de qué hablaré hoy. Para aclarar de alguna manera el problema, necesito un ejemplo a la "¡Hola, mundo!". La asincronía generalmente ocurre en el contexto de la escritura de aplicaciones de red, por lo que tendré un análogo de red de "¡Hola, mundo!". Esta es una aplicación de ping-pong. El código se ve así:
socket s; string x; x = read_from_socket(s, 4); if (x == "ping") { write_to_socket(s, "pong"); } return;
Creo un socket, leo una línea desde allí y compruebo si es ping, luego escribo pong en respuesta. Muy simple y claro. ¿Qué sucede cuando ve ese código en la pantalla de su computadora? Pensamos en este código como una secuencia de estos pasos:
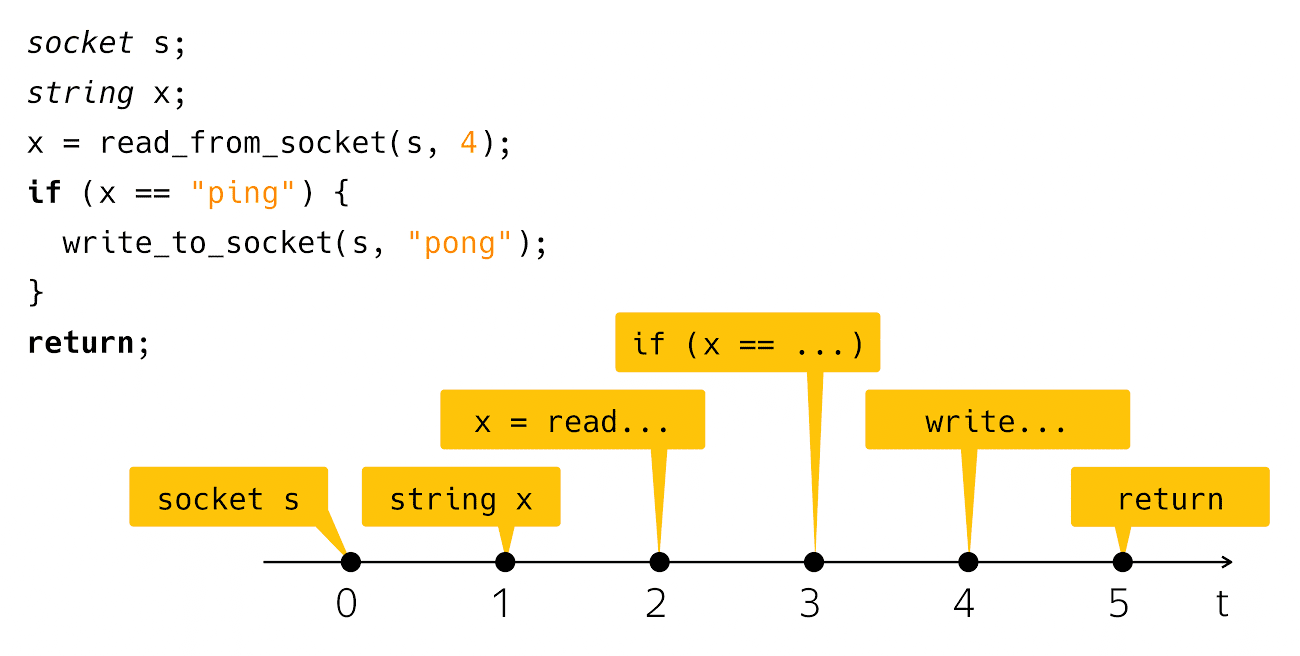
Desde el punto de vista del tiempo físico real, todo está un poco sesgado.

Los que realmente escribieron y ejecutaron dicho código saben que después del paso de lectura y después del paso
escribir es un intervalo de tiempo bastante notable cuando nuestro programa parece no estar haciendo nada desde el punto de vista de nuestro código, pero bajo el capó opera la maquinaria, que llamamos "entrada-salida".

Durante la E / S, los paquetes se intercambian a través de la red y todo el trabajo pesado de bajo nivel correspondiente. Hagamos un experimento mental: tome uno de esos programas, ejecútelo en un procesador físico y simule que no tenemos ningún sistema operativo, ¿qué sucederá? El procesador no puede detenerse, continúa tomando medidas sin seguir ninguna instrucción, solo desperdiciando energía en vano.
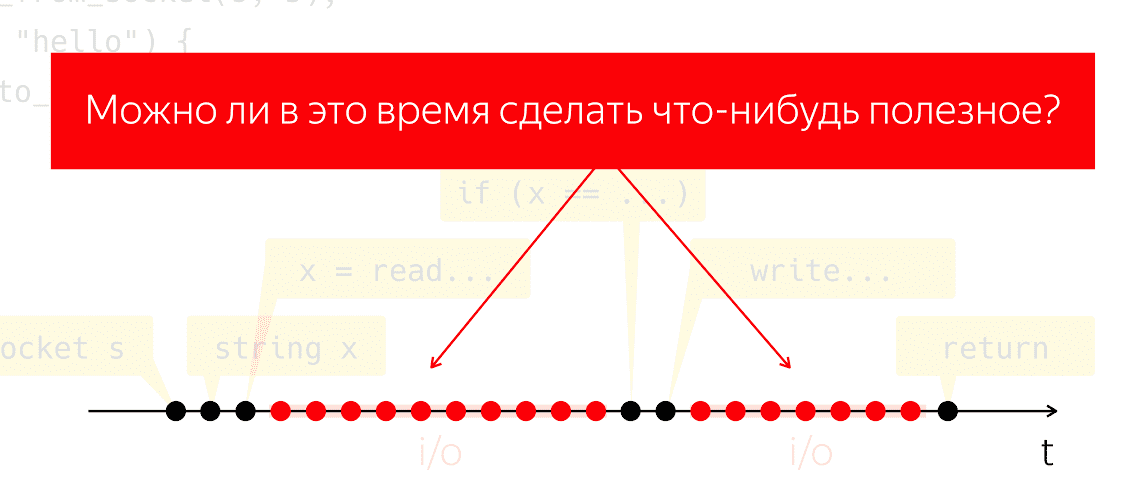
Se plantea la cuestión de si podemos hacer algo útil durante este período de tiempo. Esta es una pregunta muy natural, cuya respuesta nos permitiría ahorrar energía del procesador y usarla para algo útil, mientras que nuestra aplicación parece no hacer nada.
3. Conceptos básicos
3.1. Hilo de ejecución
¿Cómo podemos abordar esta tarea? Conciliemos los conceptos. Diré "flujo de ejecución", refiriéndome a una secuencia significativa de operaciones o pasos elementales. El significado estará determinado por el contexto en el que hablo del flujo de ejecución. Es decir, si estamos hablando de un algoritmo de subproceso único (Aho-Korasik, búsqueda de gráficos), entonces este algoritmo ya es un hilo de ejecución. Toma algunos pasos para resolver el problema.
Si estoy hablando de una base de datos, entonces un hilo de ejecución puede ser parte de las acciones realizadas por la base de datos para atender una solicitud entrante. Lo mismo ocurre con los servidores web. Si estoy escribiendo algún tipo de aplicación móvil o web, para servir la operación de un usuario, por ejemplo, hacer clic en un botón, interacciones de red, interacción con el almacenamiento local, etc. La secuencia de estas acciones desde el punto de vista de mi aplicación móvil también será un flujo de ejecución significativo por separado. Desde el punto de vista del sistema operativo, un proceso o hilo de proceso también es un hilo significativo de ejecución.
3.2. Multitarea y concurrencia
La piedra angular de la productividad es la capacidad de hacer tal truco: cuando tengo un hilo de ejecución que contiene vacíos en su exploración de tiempo físico, luego llene estos vacíos con algo útil: siga los pasos de otros hilos de ejecución.
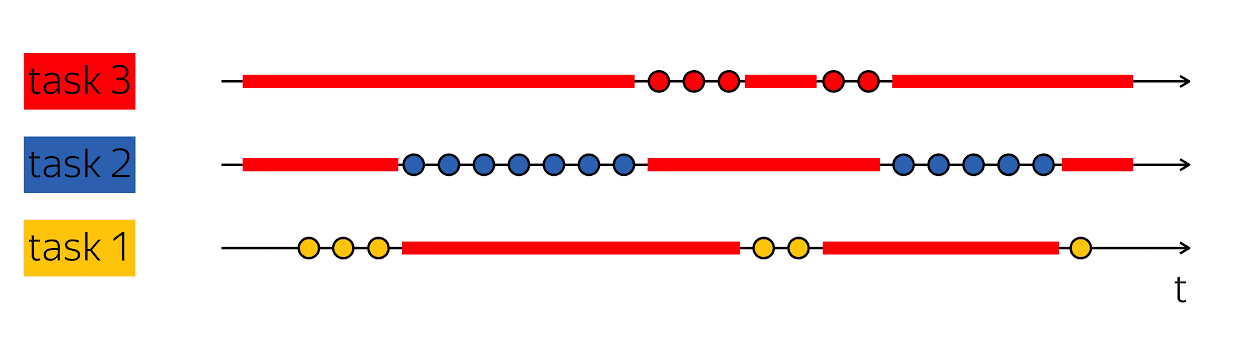
Las bases de datos generalmente sirven a muchos clientes al mismo tiempo. Si podemos combinar el trabajo en varios subprocesos de ejecución dentro del marco de un subproceso de ejecución de un nivel superior, esto se llama multitarea. Es decir, la multitarea es cuando realizo acciones dentro del marco de un flujo de ejecución más grande que está subordinado a la solución de tareas más pequeñas.
Es importante no confundir el concepto de multitarea con paralelismo. Concurrencia -
Estas son propiedades del entorno de tiempo de ejecución, lo que hace posible en un paso de tiempo, en un paso, avanzar en diferentes hilos de ejecución. Si tengo dos procesadores físicos, entonces en un ciclo de reloj pueden ejecutar dos instrucciones. Si el programa se ejecuta en un procesador, se necesitarán dos ciclos de reloj para ejecutar las mismas dos instrucciones.

Es importante no confundir estos conceptos, ya que se dividen en diferentes categorías. La multitarea es una característica de su programa que está estructurada internamente como un trabajo variable en diferentes tareas. La concurrencia es una propiedad del entorno de tiempo de ejecución que le permite trabajar en varias tareas en un ciclo de reloj.
En muchos sentidos, el código asincrónico y la escritura de código asincrónico es escribir código multitarea. La principal dificultad es cómo codifico las tareas y cómo gestionarlas. Por lo tanto, hoy hablaremos de esto: escribir código multitarea.
4. Bloqueo y espera

Comencemos con un ejemplo simple. Volver a ping-pong:
socket s; string x; x = read_from_socket(s, 4); if (x == "ping") { write_to_socket(s, "pong"); } return;
Como ya hemos discutido, después de la lectura y las líneas blancas el hilo de ejecución se queda dormido, se bloquea. Por lo general, decimos "el flujo está bloqueado".
socket s; string x; x = read_from_socket(s, 4); if (x == "ping") { write_to_socket(s, "pong"); } return;
Esto significa que el flujo de ejecución ha alcanzado un punto donde cualquier evento es necesario para continuar. En particular, en el caso de nuestra aplicación de red, es necesario que los datos lleguen a través de la red o, por el contrario, tenemos un búfer libre para escribir datos en la red. Los eventos pueden ser diferentes. Si hablamos de aspectos de tiempo, podemos esperar a que se active el temporizador o la finalización de otro proceso. Los eventos aquí son una especie de cosa abstracta, sobre ellos es importante entender que pueden esperarse.

Cuando escribimos código simple, implícitamente damos el control de la expectativa de eventos a un nivel superior. En nuestro caso, el sistema operativo. Ella, como entidad de un nivel superior, es responsable de elegir qué tarea se realizará a continuación, y también es responsable de rastrear la ocurrencia de eventos.
Nuestro código, que escribimos como desarrolladores, está estructurado al mismo tiempo con respecto al trabajo en una tarea. El fragmento de código del ejemplo maneja una conexión: lee ping de una conexión y escribe pong en una conexión.
El código es claro. Puede leerlo y comprender qué hace, cómo funciona, qué problema resuelve, qué invariantes tiene, etc. Al mismo tiempo, gestionamos muy mal la planificación de tareas en dicho modelo. En general, los sistemas operativos tienen conceptos de prioridades, pero si escribió sistemas de software en tiempo real, entonces sabe que las herramientas disponibles en Linux no son suficientes para crear sistemas en tiempo real suficientes.
Además, el sistema operativo es algo complicado, y cambiar el contexto de nuestra aplicación al kernel cuesta unos pocos microsegundos, lo que, con algunos cálculos simples, nos da una estimación de aproximadamente 20-100 mil cambios de contexto por segundo. Esto significa que si escribimos un servidor web, en un segundo podemos procesar aproximadamente 20 mil solicitudes, suponiendo que el procesamiento de solicitudes es diez veces más costoso que el sistema.

4.1. Espera sin bloqueo
Si se encuentra con la situación en la que necesita trabajar con la red de manera más eficiente, entonces comienza a buscar ayuda en Internet y utiliza select / epoll. En Internet está escrito que si desea servir miles de conexiones al mismo tiempo, necesita epoll, porque es un buen mecanismo, etc. Abre la documentación y ve algo como esto:
int select(int nfds, fd_set* readfds, fd_set* writefds, fd_set* exceptfds, struct timeval* timeout); void FD_CLR(int fd, fd_set* set); int FD_ISSET(int fd, fd_set* set); void FD_SET(int fd, fd_set* set); void FD_ZERO(fd_set* set); int epoll_ctl(int epfd, int op, int fd, struct epoll_event* event); int epoll_wait(int epfd, struct epoll_event* events, int maxevents, int timeout);
Funciones en las que la interfaz contiene muchos descriptores con los que trabaja (en el caso de select) o muchos eventos que pasan
a través de los límites de su aplicación, el núcleo del sistema operativo que necesita procesar (en el caso de epoll).
También vale la pena agregar que no puede venir a seleccionar / epoll, sino a una biblioteca como libuv, que no tendrá ningún evento en la API, pero tendrá muchas devoluciones de llamada. La interfaz de la biblioteca dirá: "Estimado amigo, proporcione una devolución de llamada para leer el socket, al que llamaré cuando aparezcan los datos".
int uv_timer_start(uv_timer_t* handle, uv_timer_cb cb, uint64_t timeout, uint64_t repeat); typedef void (*uv_timer_cb)(uv_timer_t* handle); int uv_read_start(uv_stream_t* stream, uv_alloc_cb alloc_cb, uv_read_cb read_cb); int uv_read_stop(uv_stream_t*); typedef void (*uv_read_cb)(uv_stream_t* stream, ssize_t nread, const uv_buf_t* buf); int uv_write(uv_write_t* req, uv_stream_t* handle, const uv_buf_t bufs[], unsigned int nbufs, uv_write_cb cb); typedef void (*uv_write_cb)(uv_write_t* req, int status);
¿Qué ha cambiado en comparación con nuestro código síncrono en el capítulo anterior? El código se ha vuelto asíncrono. Esto significa que tomamos la lógica en la aplicación para determinar el momento en el que se supervisan los eventos. Las llamadas explícitas select / epoll son los puntos donde le pedimos al sistema operativo información sobre los eventos que han ocurrido. También tomamos en nuestro código de aplicación la elección de qué tarea trabajar a continuación.

A partir de los ejemplos de interfaces, puede ver que existen básicamente dos mecanismos para introducir la multitarea. Un tipo de "atracción" cuando
sacamos muchos de los eventos que estamos esperando y luego reaccionamos de alguna manera a ellos. En este enfoque, es fácil amortizar los gastos generales en uno
un evento y, por lo tanto, lograr un alto rendimiento en la comunicación sobre el conjunto de eventos que han ocurrido. Por lo general, todos los elementos de la red, como la interacción del núcleo con la tarjeta de red o la interacción entre usted y el sistema operativo, se basan en mecanismos de sondeo.
La segunda forma es un mecanismo de "empuje", cuando una determinada entidad externa entra claramente, interrumpe el flujo de ejecución y dice: "Ahora, maneje el evento que acaba de llegar". Este es un enfoque con devoluciones de llamada, con señales unix, con interrupciones a nivel de procesador, cuando una entidad externa invade claramente su hilo de ejecución y dice: "Ahora, por favor, estamos trabajando en este evento". Este enfoque ha aparecido para reducir el retraso entre la ocurrencia de un evento y la reacción al mismo.
¿Por qué los desarrolladores de C ++ que escribimos y resolvemos problemas específicos de la aplicación podríamos querer arrastrar un modelo de evento a nuestro código? Si arrastramos y soltamos el trabajo en muchas tareas en nuestro código y lo gestionamos, entonces debido a la falta de transición al kernel y viceversa, podemos trabajar un poco más rápido y realizar acciones más útiles por unidad de tiempo.
¿A qué conduce esto en términos del código que escribimos? Tome nginx, por ejemplo, un servidor HTTP de alto rendimiento, muy común. Si lee su código, se basa en un modelo asincrónico. El código es bastante difícil de leer. Cuando se pregunta qué sucede exactamente al procesar una sola solicitud HTTP, resulta que hay muchos fragmentos en el código, espaciados en diferentes archivos, en diferentes ángulos de la base del código. Cada fragmento realiza una pequeña cantidad de trabajo como parte del servicio de toda la solicitud HTTP. Por ejemplo:
static void ngx_http_request_handler(ngx_event_t *ev) { … if (c->close) { ngx_http_terminate_request(r, 0); return; } if (ev->write) { r->write_event_handler(r); } else { r->read_event_handler(r); } ... } typedef void (*ngx_http_event_handler_pt)(ngx_http_request_t *r); struct ngx_http_request_s { ngx_http_event_handler_pt read_event_handler; }; r->read_event_handler = ngx_http_request_empty_handler; r->read_event_handler = ngx_http_block_reading; r->read_event_handler = ngx_http_test_reading; r->read_event_handler = ngx_http_discarded_request_body_handler; r->read_event_handler = ngx_http_read_client_request_body_handler; r->read_event_handler = ngx_http_upstream_rd_check_broken_connection; r->read_event_handler = ngx_http_upstream_read_request_handler;
Hay una estructura de solicitud, que se reenvía al controlador de eventos cuando el socket señala acceso de lectura o escritura. Además, este controlador cambia constantemente en el curso del programa dependiendo del estado del procesamiento de la solicitud. O leemos los encabezados, o leemos el cuerpo de la solicitud, o pedimos datos aguas arriba; en general, hay muchos estados diferentes.
Este código es difícil de leer porque, en esencia, se describe en términos de reacción a los eventos. Estamos en tal y tal estado y reaccionamos de cierta manera a los eventos que han sucedido. No hay una imagen completa del proceso completo de procesamiento de una solicitud HTTP.
Otra opción, que a menudo se usa en JavaScript, es crear código basado en la devolución de llamada cuando reenviamos nuestra devolución de llamada a la llamada de interfaz, en la que generalmente hay otra devolución de llamada anidada para un evento, y así sucesivamente.
int LibuvStreamWrap::ReadStart() { return uv_read_start(stream(), [](uv_handle_t* handle, size_t suggested_size, uv_buf_t* buf) { static_cast<LibuvStreamWrap*>(handle->data)->OnUvAlloc(suggested_size, buf); }, [](uv_stream_t* stream, ssize_t nread, const uv_buf_t* buf) { static_cast<LibuvStreamWrap*>(stream->data)->OnUvRead(nread, buf); }); } for (p=data; p != data + len; p++) { ch = *p; reexecute: switch (CURRENT_STATE()) { case s_start_req_or_res: case s_res_or_resp_H: case s_res_HT: case s_res_HTT: case s_res_HTTP: case s_res_http_major: case s_res_http_dot:
El código nuevamente está muy fragmentado, no se comprende el estado actual de cómo trabajamos en la solicitud. Una gran cantidad de información se transmite a través de cierres, y debe realizar esfuerzos mentales para reconstruir la lógica de procesar una sola solicitud.
Por lo tanto, al introducir la multitarea en nuestro código (la lógica de elegir tareas de trabajo y multiplexarlas), obtenemos código efectivo y control sobre la priorización de tareas, pero perdemos muchos de ellos en la legibilidad. Este código es difícil de leer y de mantener.

Por qué Supongamos que tengo un caso simple, por ejemplo, leo un archivo y lo transfiero a través de la red. En una versión sin bloqueo, este caso corresponderá a una máquina de estado lineal de este tipo:
- Estado inicial
- Comienza a leer un archivo,
- Esperando una respuesta del sistema de archivos,
- Escribir un archivo en un socket,
- Estado final
Ahora, digamos que quiero agregar información de la base de datos a este archivo. Una opción simple:
- estado inicial
- leyendo un archivo
- lee el archivo
- lectura de la base de datos
- leer de la base de datos,
- Yo trabajo con un enchufe
- escribió en el zócalo.
Parece un código lineal, pero el número de estados ha aumentado.
Entonces empiezas a pensar que sería bueno paralelizar los dos pasos: leer de un archivo y de una base de datos. Los milagros de la combinatoria comienzan: usted está en el estado inicial, solicitando leer el archivo y los datos de la base de datos. Entonces puede llegar a un estado donde hay datos de la base de datos, pero no hay archivo, o viceversa: hay datos del archivo, pero no de la base de datos. A continuación, debe entrar en un estado en el que tenga una de dos cosas. De nuevo, estos son dos estados. Entonces debes entrar en un estado en el que tengas ambos ingredientes. Luego escríbalos en el zócalo y así sucesivamente.
Cuanto más compleja es la aplicación, más estados, más fragmentos de código deben combinarse en su cabeza. Inconveniente O está escribiendo fideos de devolución de llamada, lo cual es inconveniente para leer. Si se escribe un sistema de ramificación, un día llega un momento en que ya no puede tolerarlo.
5. Futuros / Promesas
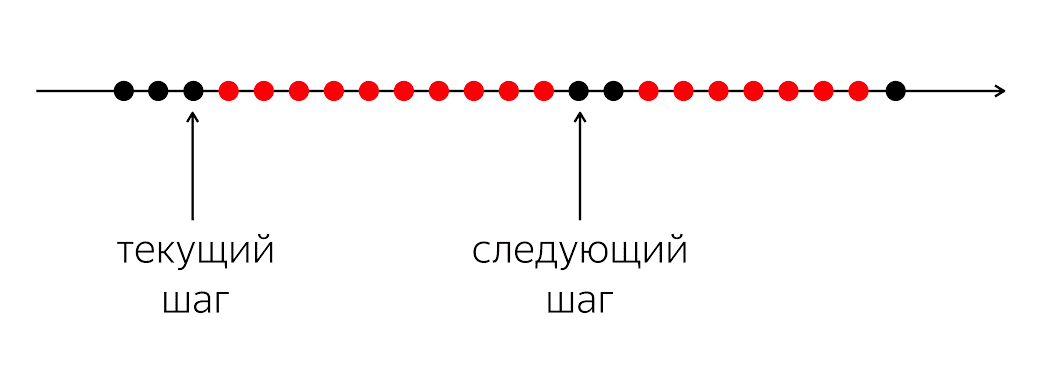
Para resolver el problema, debe ver la situación más fácilmente.

Hay un programa, tiene círculos negros y rojos. Nuestro flujo de ejecución es círculos negros; a veces se alternan con rojo cuando la secuencia no puede continuar su trabajo. El problema es que para nuestro hilo negro de ejecución necesita ingresar al siguiente círculo negro, que no se sabrá cuándo.
El problema es que cuando escribimos código en un lenguaje de programación, le explicamos a la computadora qué hacer en este momento. Una computadora es algo relativamente simple que espera instrucciones que escribimos en el lenguaje de programación. Está esperando instrucciones para el próximo círculo, y en nuestro lenguaje de programación no hay suficiente dinero para decir: "En el futuro, por favor, cuando ocurra algo, haga algo".

En un lenguaje de programación, operamos con acciones momentáneas comprensibles: llamar a una función, operaciones aritméticas, etc. Describen el siguiente próximo paso específico. Al mismo tiempo, para procesar la lógica de la aplicación, es necesario describir no el siguiente paso físico, sino el siguiente paso lógico: qué debemos hacer cuando aparecen los datos de la base de datos, por ejemplo.
Por lo tanto, necesitamos algún mecanismo para combinar estos fragmentos. En el caso en que escribimos código sincrónico, ocultamos la pregunta completamente debajo del capó y dijimos que el sistema operativo se ocuparía de eso, le permitió interrumpir y reprogramar nuestros hilos.
En el nivel 1, abrimos esta caja de Pandora, y trajo muchos cambios, casos, condiciones, ramas, estados al código. Me gustaría un compromiso para que el código sea relativamente legible, pero conserva todas las ventajas del nivel 1.
Afortunadamente para nosotros, en 1988 las personas involucradas en sistemas distribuidos, Barbara Liskov y Luba Shirir, se dieron cuenta del problema y llegaron a la necesidad de cambios lingüísticos. Es necesario agregar construcciones al lenguaje de programación que permitan expresar relaciones temporales entre eventos, en el momento actual en el tiempo y en un momento incierto en el futuro.
Estas se llaman promesas. El concepto es genial, pero ha estado acumulando polvo en un estante durante veinte años. — , Twitter, Ruby on Rails Scala, , , , future . Your Server as a Function. , .
Scala, , ++ ?
, Future. T c : , - .
template <class T> class Future <T>
, , , . , «», , . Future «», Promise — «». ; , JavaScript, Promise — , Java – Future.
, . , , boost::future ( std::future) — , .
5.1. Future & Promise
template <class T> class Future { bool IsSet() const; const T& Get() const; T* TryGet() const; void Subscribe(std::function<void(const T&)> cb); template <class R> Future<R> Then( std::function<R(const T&)> f); template <class R> Future<R> Then( std::function<Future<R>(const T&)> f); }; template <class T> Future<T> MakeFuture(const T& value);
, , - , . , , , . , , — , , . Then, .
template <class T> class Promise { bool IsSet() const; void Set(const T& value); bool TrySet(const T& value); Future<T> ToFuture() const; }; template <class T> Promise<T> NewPromise();
. , . «, , , ».
5.2.
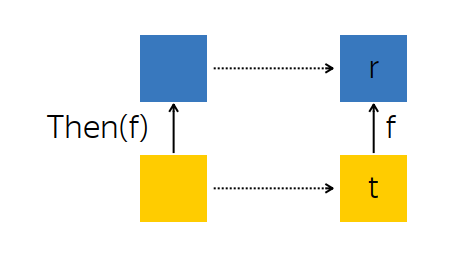
? , . Then — , .
, — future --, - t — . , , , f, - r.
t f. , , r.
: t, , r . :
template <class T> template <class R> Future<R> Future<T>::Then(std::function<R(const T&)> f) { auto promise = NewPromise<R>(); this->Subscribe([promise] (const T& t) { auto r = f(t); promise.Set(r); }); return promise.ToFuture(); }
:
Promise R ,Future<T> t ,- ,
r = f(t) , r Promise ,Promise .
f , R , Future<R> , R . :
template <class T> template <class R> Future<R> Future<T>::Then(std::function<Future<R>(const T&)> f) { auto promise = NewPromise<R>(); this->Subscribe([promise] (const T& t) { auto that = f(t); that.Subscribe([promise] (R r) { promise.Set(r); }); }); return promise.ToFuture(); }
, - t. f, r, . , , .

, Then :
Promise ,Subscribe -,Promise , Future .
, . , , , .
, , , -. , , -, Subscribe. , , , - . , .
5.3. Ejemplos
AsyncComputeValue, GPU, . Then, , (2v+1) 2 .
Future<int> value = AsyncComputeValue();
. , : (2v+1) 2 . , .
, , . .
. : , ; ; .
Future<int> GetDbKey(); Future<string> LoadDbValue(int key); Future<void> SendToMars(string message); Future<void> ExploreOuterSpace() { return GetDbKey()
— ExploreOuterSpace. Then; — — , . ( ) . .
5.4. Any-
: Future , , . , , :
template <class T> Future<T> Any(Future<T> f1, Future<T> f2) { auto promise = NewPromise<T>(); f1.Subscribe([promise] (const T& t) { promise.TrySet(t); }); f2.Subscribe([promise] (const T& t) { promise.TrySet(t); }); return promise.ToFuture(); }
, Any-, Future : , . , , .
, , , , , . « DB1, DB2, — - ».
5.5. All-
. , , , ( T1 T2), T1 T2 , , .
template <class T1, class T2> Future<std::tuple<T1, T2>> All(Future<T1> f1, Future<T2> f2) { auto promise = NewPromise<std::tuple<T1, T2>>(); auto result = std::make_shared< std::tuple<T1, T2> >(); auto counter = std::make_shared< std::atomic<int> >(2); f1.Subscribe([promise, result, counter] (const T1& t1) { std::get<0>(*result) = t1; if (--(*counter) == 0) { promise.Set(*result)); } }); f2.Subscribe([promise, result, counter] (const T2& t2) { } return promise.ToFuture(); }
nginx. , , . nginx « », « », « » . All- , . .
5.6.
Future Promises — legacy-, . callback- , , : Future, , callback- Future.
: , Future .
6.
, , . .
Future<Request> GetRequest(); Future<Payload> QueryBackend(Request req); Future<Response> HandlePayload(Payload pld); Future<void> Reply(Request req, Response rsp);
. Request, - . , . , , , . , - .
, , . ? — , request payload, — , .
, Java Netty. , , . , , .
, GetRequest, QueryBackend, HandlePayload Reply , Future.
, , Future T — WaitFor.
Future<Request> GetRequest(); Future<Payload> QueryBackend(Request req); Future<Response> HandlePayload(Payload pld); Future<void> Reply(Request req, Response rsp); template <class T> T WaitFor(Future<T> future);
:
Future<Request> GetRequest(); Future<Payload> QueryBackend(Request req); Future<Response> HandlePayload(Payload pld); Future<void> Reply(Request req, Response rsp); template <class T> T WaitFor(Future<T> future); auto req = WaitFor(GetRequest()); auto pld = WaitFor(QueryBackend(req)); auto rsp = WaitFor(HandlePayload(pld)); WaitFor(Reply(req, rsp));
: Future, . . , . .
. . - 0, , , mutex+cvar future. . , .

6.1.
, . , , , , - , . , - .
— «» , , . . . : boost::asio boost::fiber.
, . Como hacerlo
6.2. WaitFor
, , boost::context, : , ; , . x86/64 , , .
, goto: , , , .
, - . Fiber — . +Future. , , Future, .
class Fiber { MachineContext context_; Future<void> future_; };
class Scheduler { void WaitFor(Future<void> future); void Loop(); MachineContext loop_context_; Fiber* current_fiber_; std::deque<Fiber*> run_queue_; };
Future , , , . : Loop, , , , , .
WaitFor?
thread_local Scheduler* ThisScheduler; template <class T> T WaitFor(Future<T> future) { ThisScheduler->WaitFor(future.As<void>()); return future.Get(); } void Scheduler::WaitFor(Future<void> future) { current_fiber_->future_ = future; SwitchContext(¤t_fiber_->context_, &loop_context_); }
: , - , , Future void, . .
Future<void> , , - .
WaitFor : : « Fiber Future», ( ) .
, :
ThisScheduler->WaitFor return future.Get() , .
? , Future, .
6.3.
- , , , - , . SwitchContext , 2 — .
void Scheduler::Loop() { while (true) {
? , , , Future, Future, , , .
void Scheduler::Loop() { while (true) {
, . :
WaitFor — .

Switch- .

Future ( ), , . - Fiber.

WaitFor Future , - , Future . :
Future<Request> GetRequest(); Future<Payload> QueryBackend(Request req); Future<Response> HandlePayload(Payload pld); Future<void> Reply(Request req, Response rsp); template <class T> T WaitFor(Future<T> future); auto req = WaitFor( GetRequest()); auto pld = WaitFor( QueryBackend(req)); auto rsp = WaitFor( HandlePayload(pld)); WaitFor( Reply(req, rsp));
, , , . , , .
6.4. Coroutine TS
? — . Coroutine TS, , WaitFor CoroutineWait, CoroutineTS — - . , - . , Waiter Co, , .
7. ?
. , , , . , , , .
— . , . . , . , , , , .
- , , . , . , , .

, ? , .
. , , , , . . , , , , .
nginx, , , , , . , , , future promises.
, , , , , , , .
futures, promises actors. . , .
: , , , . , , , , . ? , .
Minuto de publicidad. 19-20 C++ Russia 2019. , , Grimm Rainer «Concurrency and parallelism in C++17 and C++20/23» , C++ . , . , , - .