
Como se menciona en el artículo de Radar Technology , Lamoda se está moviendo activamente hacia la arquitectura de microservicios. La mayoría de nuestros servicios se empaquetan con Helm y se implementan en Kubernetes. Este enfoque satisface plenamente nuestras necesidades en el 99% de los casos. El 1% permanece cuando la funcionalidad estándar de Kubernetes no es suficiente, por ejemplo, cuando necesita configurar una copia de seguridad o actualizar un servicio para un evento específico. Para resolver este problema, utilizamos el patrón del operador. En esta serie de artículos, yo, Grigory Mikhalkin, desarrollador del equipo de I + D de Lamoda, hablaré sobre las lecciones que aprendí de mi experiencia en el desarrollo de operadores de K8 utilizando el Marco del operador .
¿Qué es un operador?
Una forma de ampliar la funcionalidad de Kubernetes es crear sus propios controladores. Las principales abstracciones en Kubernetes son objetos y controladores. Los objetos describen el estado deseado del clúster. Por ejemplo, un Pod describe qué contenedores deben iniciarse y los parámetros de inicio, y el objeto ReplicaSet indica cuántas réplicas debe ejecutar un Pod determinado. Los controladores controlan el estado del clúster en función de la descripción de los objetos; en el caso descrito anteriormente, ReplicationController admitirá la cantidad de réplicas de Pod especificadas en ReplicaSet. Con la ayuda de nuevos controladores, puede implementar lógica adicional, como enviar notificaciones de eventos, recuperarse de una falla o administrar recursos de terceros .
Un operador es una aplicación kubernetes que incluye uno o más controladores que sirven a un recurso de terceros. El concepto fue inventado por el equipo CoreOS en 2016, y recientemente, la popularidad de los operadores ha estado creciendo rápidamente. Puede intentar encontrar el operador deseado en la lista en kubedex (más de 100 operadores disponibles públicamente se enumeran aquí), así como en OperatorHub . Existen 3 herramientas populares para el desarrollo de operadores: Kubebuilder , Operator SDK y Metacontroller . En Lamoda utilizamos el SDK del operador, por lo que hablaremos más adelante.
SDK de operador
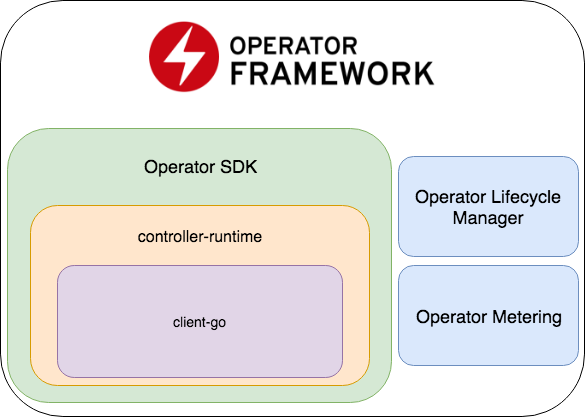
El SDK del operador es parte del marco del operador, que incluye dos partes más importantes: Operator Lifecycle Manager y Operator Metering.
- El SDK del operador es un contenedor para el tiempo de ejecución del controlador , una biblioteca popular para el desarrollo de controladores (que, a su vez, es un contenedor para el cliente-go ), un generador de código + marco para escribir pruebas E2E.
- Operator Lifecycle Manager : un marco para administrar operadores existentes; resuelve situaciones cuando el operador ingresa al modo zombie o se implementa una nueva versión.
- Medición del operador : como su nombre lo indica, recopila datos sobre el trabajo del operador y también puede generar informes basados en ellos.
Crea un nuevo proyecto
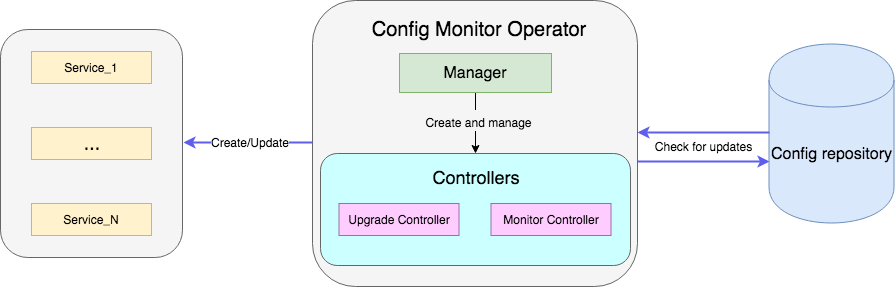
Un ejemplo es un operador que monitorea un archivo con configuraciones en el repositorio y, cuando se actualiza, reinicia la implementación del servicio con nuevas configuraciones. El código de muestra completo está disponible aquí .
Cree un proyecto con un nuevo operador:
operator-sdk new config-monitor
El generador de código creará código para el operador que trabaja en el espacio de nombres asignado. Este enfoque es preferible a dar acceso a todo el clúster, ya que en caso de errores, los problemas se aislarán dentro del mismo espacio de nombres. El operador de cluster-wide se puede generar agregando --cluster-scoped . Los siguientes directorios se ubicarán dentro del proyecto creado:
- cmd: contiene el
main package , en el que Manager inicializa y se inicia; - desplegar: contiene declaraciones del operador, CRD y los objetos necesarios para configurar el operador RBAC;
- pkg: aquí estará nuestro código principal para nuevos objetos y controladores.
Solo hay un archivo cmd/manager/main.go en cmd/manager/main.go .
Fragmento de código // Become the leader before proceeding err = leader.Become(ctx, "config-monitor-lock") if err != nil { log.Error(err, "") os.Exit(1) } // Create a new Cmd to provide shared dependencies and start components mgr, err := manager.New(cfg, manager.Options{ Namespace: namespace, MetricsBindAddress: fmt.Sprintf("%s:%d", metricsHost, metricsPort), }) ... // Setup Scheme for all resources if err := apis.AddToScheme(mgr.GetScheme()); err != nil { log.Error(err, "") os.Exit(1) } // Setup all Controllers if err := controller.AddToManager(mgr); err != nil { log.Error(err, "") os.Exit(1) } ... // Start the Cmd if err := mgr.Start(signals.SetupSignalHandler()); err != nil { log.Error(err, "Manager exited non-zero") os.Exit(1) }
En la primera línea: err = leader.Become(ctx, "config-monitor-lock") : se selecciona un líder. En la mayoría de los escenarios, solo se necesita una instancia activa de una declaración en el espacio de nombres / clúster. De forma predeterminada, el SDK del operador utiliza la estrategia Líder para toda la vida : la primera instancia lanzada del operador seguirá siendo el líder hasta que se elimine del clúster.
Después de que esta instancia de operador ha sido nombrada líder, se inicializa un nuevo Manager : mgr, err := manager.New(...) . Sus responsabilidades incluyen:
err := apis.AddToScheme(mgr.GetScheme()) - registro de nuevos esquemas de recursos;err := controller.AddToManager(mgr) - registro de controladores;err := mgr.Start(signals.SetupSignalHandler()) - err := mgr.Start(signals.SetupSignalHandler()) y controla los controladores.
Por el momento, no tenemos nuevos recursos ni controladores para el registro. Puede agregar un nuevo recurso con el comando:
operator-sdk add api --api-version=services.example.com/v1alpha1 --kind=MonitoredService
Este comando agregará la definición del esquema de recursos MonitoredService al directorio pkg/apis , así como yaml con la definición CRD en deploy/crds . De todos los archivos generados, debe cambiar manualmente solo la definición de esquema en monitoredservice_types.go . El tipo MonitoredServiceSpec define el estado deseado del recurso: lo que el usuario especifica en yaml con la definición del recurso. En el contexto de nuestro operador, el campo Size determina el número deseado de réplicas, ConfigRepo indica de dónde se pueden extraer las configuraciones actuales. MonitoredServiceStatus determina el estado observado del recurso, por ejemplo, almacena los nombres de Pods que pertenecen a este recurso y los Pods de spec actuales.
Después de editar el esquema, debe ejecutar el comando:
operator-sdk generate k8s
Actualizará la definición de CRD en deploy/crds .
Ahora creemos la parte principal de nuestro operador, el controlador:
operator-sdk add controller --api-version=services.example.com/v1alpha1 --kind=Monitor
El archivo monitor_controller.go aparecerá en el monitor_controller.go pkg/controller , en el que agregaremos la lógica que necesitamos.
Desarrollo de controlador
El controlador es la principal unidad de trabajo del operador. En nuestro caso, hay dos controladores:
- El controlador del monitor supervisa los cambios de configuración del servicio
- El controlador de actualización actualiza el servicio y lo mantiene en el estado deseado.
En esencia, el controlador es un bucle de control, monitorea la cola con los eventos a los que está suscrito y los procesa:
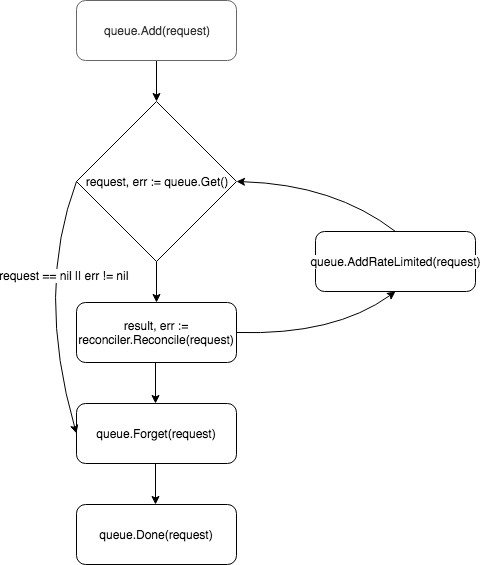
El administrador crea y registra un nuevo controlador en el método add :
c, err := controller.New("monitor-controller", mgr, controller.Options{Reconciler: r})
Usando el método Watch , lo suscribimos a eventos relacionados con la creación de un nuevo recurso o la actualización de Spec de un recurso MonitoredService existente:
err = c.Watch(&source.Kind{Type: &servicesv1alpha1.MonitoredService{}}, &handler.EnqueueRequestForObject{}, common.CreateOrUpdateSpecPredicate)
El tipo de evento se puede configurar utilizando los parámetros src y predicates . src acepta objetos de tipo Source .
Informer : sondea periódicamente el apiserver busca de eventos que coincidan con el filtro; si existe dicho evento, lo coloca en la cola del controlador. En controller-runtime este es un contenedor sobre SharedIndexInformer desde client-go .Kind también es un contenedor sobre SharedIndexInformer , pero, a diferencia de Informer , crea de forma independiente una instancia de informador basada en los parámetros pasados (esquema del recurso monitoreado).Channel : acepta el chan event.GenericEvent como parámetro, los eventos que lo atraviesan se colocan en la cola del controlador.
redicates espera objetos que satisfacen la interfaz Predicate . De hecho, este es un filtro adicional para eventos, por ejemplo, al filtrar UpdateEvent puede ver exactamente qué cambios se realizaron en la spec recurso.
Cuando llega un evento, un EventHandler acepta, el segundo argumento del método Watch , que envuelve el evento en el formato de solicitud que espera el Reconciler :
EnqueueRequestForObject : crea una solicitud con el nombre y el espacio de nombres del objeto que causó el evento;EnqueueRequestForOwner : crea una solicitud con los datos del padre del objeto. Esto es necesario, por ejemplo, si el Pod controlado por recursos Pod sido eliminado y necesita comenzar su reemplazo;EnqueueRequestsFromMapFunc : toma como parámetro la función de map que recibe un evento (envuelto en MapObject ) y devuelve una lista de solicitudes. Un ejemplo cuando se necesita este controlador : hay un temporizador, para cada tic del cual necesita extraer nuevas configuraciones para todos los servicios disponibles.
Las solicitudes se colocan en la cola del controlador, y uno de los trabajadores (de forma predeterminada, el controlador tiene una) extrae el evento de la cola y lo pasa a Reconciler .
Reconciler implementa solo un método: Reconcile , que contiene la lógica básica del procesamiento de eventos:
método de conciliación func (r *ReconcileMonitor) Reconcile(request reconcile.Request) (reconcile.Result, error) { reqLogger := log.WithValues("Request.Namespace", request.Namespace, "Request.Name", request.Name) reqLogger.Info("Checking updates in repo for MonitoredService") // fetch the Monitor instance instance := &servicesv1alpha1.MonitoredService{} err := r.client.Get(context.Background(), request.NamespacedName, instance) if err != nil { if errors.IsNotFound(err) { // Request object not found, could have been deleted after reconcile request. // Owned objects are automatically garbage collected. For additional cleanup logic use finalizers. // Return and don't requeue return reconcile.Result{}, nil } // Error reading the object - requeue the request. return reconcile.Result{}, err } // check if service's config was updated // if it was, send event to upgrade controller if podSpec, ok := r.isServiceConfigUpdated(instance); ok { // Update instance Spec instance.Status.PodSpec = *podSpec instance.Status.ConfigChanged = true err = r.client.Status().Update(context.Background(), instance) if err != nil { reqLogger.Error(err, "Failed to update service status", "Service.Namespace", instance.Namespace, "Service.Name", instance.Name) return reconcile.Result{}, err } r.eventsChan <- event.GenericEvent{Meta: &servicesv1alpha1.MonitoredService{}, Object: instance} } return reconcile.Result{}, nil }
El método acepta un objeto Request con el campo NamespacedName , por el cual el recurso se puede extraer de la memoria caché: r.client.Get(context.TODO(), request.NamespacedName, instance) . En el ejemplo, se realiza una solicitud al archivo con la configuración del servicio referenciada por el campo ConfigRepo en la spec recurso. Si la configuración se actualiza, se GenericEvent un nuevo evento del tipo GenericEvent y se envía al canal que escucha el controlador de Upgrade .
Después de procesar la solicitud, Reconcile devuelve un objeto de tipo Result y error . Si el campo Result es Requeue: true o error != nil , el controlador devolverá la solicitud a la cola utilizando el método queue.AddRateLimited . La solicitud se devolverá a la cola con un retraso, que está determinado por RateLimiter . De forma predeterminada, ItemExponentialFailureRateLimiter utiliza ItemExponentialFailureRateLimiter , que aumenta el tiempo de retraso exponencialmente con un aumento en el número de "devoluciones" de la solicitud. Si el campo Requeue no Requeue configurado y no se produjo ningún error durante el procesamiento de la solicitud, el controlador llamará al método Queue.Forget , que eliminará la solicitud RateLimiter caché de RateLimiter (restableciendo así el número de devoluciones). Al final del procesamiento de la solicitud, el controlador lo elimina de la cola utilizando el método Queue.Done .
Lanzamiento del operador
Los componentes del operador se describieron anteriormente, y quedaba una pregunta: cómo iniciarlo. Primero debe asegurarse de que estén instalados todos los recursos necesarios (para pruebas locales, recomiendo configurar minikube ):
# Setup Service Account kubectl create -f deploy/service_account.yaml # Setup RBAC kubectl create -f deploy/role.yaml kubectl create -f deploy/role_binding.yaml # Setup the CRD kubectl create -f deploy/crds/services_v1alpha1_monitoredservice_crd.yaml # Setup custom resource kubectl create -f deploy/crds/services_v1alpha1_monitoredservice_cr.yaml
Una vez que se han cumplido los requisitos previos, hay dos formas fáciles de ejecutar la declaración para la prueba. Lo más fácil es iniciarlo fuera del clúster con el comando:
operator-sdk up local --namespace=default
La segunda forma es implementar el operador en el clúster. Primero necesita construir una imagen Docker con el operador:
operator-sdk build config-monitor-operator:latest
En el archivo deploy/operator.yaml , reemplace REPLACE_IMAGE con config-monitor-operator:latest :
sed -i "" 's|REPLACE_IMAGE|config-monitor-operator:latest|g' deploy/operator.yaml
Crear implementación con declaración:
kubectl create -f deploy/operator.yaml
Ahora en la lista de Pod en el clúster debería aparecer Pod con un servicio de prueba, y en el segundo caso, otro con un operador.
En lugar de una conclusión o mejores prácticas
Los problemas clave del desarrollo del operador en este momento son la escasa documentación de las herramientas y la falta de mejores prácticas establecidas. Cuando un nuevo desarrollador comienza a desarrollar un operador, prácticamente no tiene dónde mirar ejemplos de implementación de un requisito particular, por lo que los errores son inevitables. A continuación hay algunas lecciones que aprendimos de nuestros errores:
- Si hay dos aplicaciones relacionadas, debe evitar el deseo de combinarlas con un solo operador. De lo contrario, se viola el principio de los servicios de acoplamiento flexible.
- Debe recordar la separación de preocupaciones: no debe intentar implementar toda la lógica en un controlador. Por ejemplo, vale la pena difundir las funciones de monitoreo de configuraciones y crear / actualizar un recurso.
- El bloqueo de llamadas debe evitarse en el método
Reconcile . Por ejemplo, puede extraer configuraciones de una fuente externa, pero si la operación es más larga, cree una rutina para esto y envíe la solicitud nuevamente a la cola, indicando en la respuesta Requeue: true .
En los comentarios, sería interesante conocer su experiencia en el desarrollo de operadores. Y en la siguiente parte hablaremos sobre las pruebas del operador.