
Soy un desarrollador líder de Java en Yandex.Money.
Cada mañana de trabajo en 2018, recibí unas 30 solicitudes de extracción esperando una revisión, y no tuve tiempo suficiente para ordenarlas todas en un día. Al final del verano, me fui de vacaciones, y cuando regresé, encontré una fila de 50 relaciones públicas que me asignaron. No había ganas de rastrillarlos, pero de hecho solo era la punta del iceberg, lo que vi con mis propios ojos. Ese día decidí que era hora de cambiar algo.
Esta es la historia de cómo aceleramos la revisión del código, descargamos a los principales desarrolladores y mejoramos las herramientas que usamos todos los días.
Revisión de código 1.0. ¿Cómo estuvo antes?
En Yandex.Money, una revisión de código ha sido durante mucho tiempo un paso de desarrollo obligatorio, y todos han estado acostumbrados a ella. Algunos se dieron cuenta de que esto era tan importante como las pruebas; otros consideraron esto como un mal necesario, y alguien encontró una revisión de código solo como el autor de las solicitudes de extracción, pero evitó la revisión de código de otra persona. Creo que muchos han viajado sucesivamente del último al primero, y esto es normal.
Para la revisión del código, utilizamos Bitbucket desde el principio. Para cada repositorio de componentes, se agregó una lista de 3-4 revisores predeterminados, que se agregaron a todos los RP. Por lo general, esta lista fue compilada y editada por el jefe del departamento, y a veces se agregaron allí voluntarios que ellos mismos querían revisar un componente en particular. En los repositorios de la biblioteca fue un poco más fácil: la lista de revisores fue la misma para todas las bibliotecas, y los desarrolladores senior se incluyeron allí.
Como resultado, casi toda la carga recayó en los revisores de los desarrolladores senior, que gradualmente dejaron de ser suficientes, teniendo en cuenta el crecimiento del departamento a 60 personas, un aumento en el número de repositorios (más de 60 componentes, más de 100 bibliotecas) y la aceleración de nuestro CI / CD.
Además de la gran carga de trabajo y la falta de recursos de los revisores, hubo otros problemas:
- en algunos componentes, uno podría esperar una reacción de los revisores por más de un día,
- alta carga de trabajo de los nombrados como revisores en varios componentes,
- es difícil atraer nuevos revisores, incluso debido al párrafo anterior,
- si el revisor principal se enfermó o estuvo de vacaciones, la revisión del código de tiempo de los componentes comenzó a aumentar notablemente,
- los revisores designados no siempre tenían experiencia real en el componente, debido a esto la calidad de la revisión del código sufrió.
Antes de resolver estos problemas, debe decidir qué esperamos generalmente de una revisión de código.
La revisión correcta del código es ¿cómo?
Hemos identificado cuatro puntos que deberían estar en la revisión de código actualizada:
- Validar la arquitectura de la solución . Cosa bastante obvia. Esperamos esto de los desarrolladores senior con experiencia en este componente.
- Verificación de la implementación técnica , que también esperamos de especialistas superiores y medios con experiencia en este componente.
- La transferencia de conocimiento , que consiste en el estudio de la lógica empresarial y la base del código por parte de principiantes y junio a través de revisiones de código.
- Capacidad para evaluar las habilidades difíciles de los desarrolladores . Quiero que a cada desarrollador se le asigne un mentor que evalúe el crecimiento, determine el vector de desarrollo, note algunas deficiencias, haga comentarios, etc. Por lo tanto, el mentor también debería ver el código de sus pupilos.
Quizás alguien vea otras metas o no esté de acuerdo con la nuestra: comparta en los comentarios. Mientras tanto, pasaré de la formulación de objetivos a la búsqueda de medios para alcanzarlos; decidimos que queremos alcanzarlos todos y (casi) de inmediato.
Revisión de código 2.0. Como es
¿Qué se nos ocurrió? Comenzamos a razonar paso a paso.
En Yandex.Money, los desarrolladores trabajan en equipos en áreas de negocios, generalmente de 2 a 4 desarrolladores en un equipo.
Digamos que voy a abrir una solicitud de extracción, es decir, soy su autor . Tengo mi equipo , cuyos desarrolladores son conscientes de la lógica empresarial de lo que estoy haciendo, porque todos participamos en proyectos comunes, a menudo sincronizamos y generalmente interactuamos activamente. Por lo tanto, primero quiero agregarlos a mis solicitudes de extracción, para que al menos estén al día con lo que estoy haciendo.
Cada componente en Yandex.Money tiene un equipo que es responsable y lo acompaña en la producción.
Si modifico un componente del que es responsable otro equipo, entonces parece lógico agregar desarrolladores de este equipo a los revisores: son responsables de este componente y deben monitorear la calidad de su código. Pero para no sobrecargar a los revisores, solo tomamos una persona aleatoria de este equipo; creemos que esto es suficiente.
Puede suceder que el equipo responsable del componente no tenga suficiente experiencia en él. Esto sucede cuando los recién llegados aparecen en el equipo o se les ha confiado este componente solo recientemente. Sin embargo, sé que tenemos expertos reales en esta compañía en este repositorio, ¡y sería genial si uno de ellos mirara mi código! Por supuesto, mi conocimiento es difícil de formalizar, pero puede tomar el historial del repositorio y calcular la revisión del código en función del número de RP y estadísticas, que trabajaron mucho en este código y / o lo revisaron mucho. Calculamos la métrica de experiencia en el repositorio, seleccionamos los mejores desarrolladores para esta métrica, los llamamos expertos y agregamos un experto aleatorio a los revisores.
En 2018, presentamos el instituto de mentoría en la empresa, por lo que ahora un mentor entre los desarrolladores senior está observando a cada equipo. Además, cada recién llegado a la empresa al principio tiene un mentor personal.
¡Deje que mi mentor mire mi código! Podrá ayudar en caso de problemas en la revisión del código, y también tendrá una idea de mis fortalezas y debilidades en las habilidades técnicas.
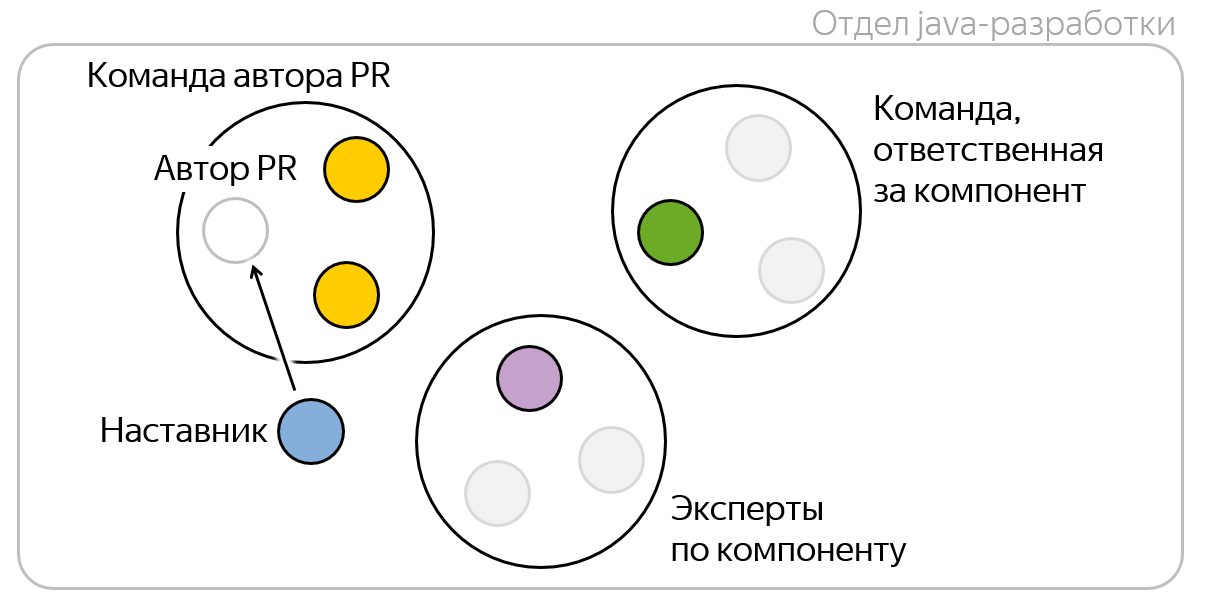
En total, se pueden agregar de cinco a seis personas a los revisores de cada solicitud de extracción. Pero, de hecho, generalmente son un poco más pequeños, porque se pueden combinar diferentes roles en una sola persona. Mi mentor puede ser un experto al mismo tiempo, y mi equipo puede ser responsable del componente. Subjetivamente, 3-4 revisores serían óptimos para las solicitudes de extracción.
Revisión de código 2.0. ¿Qué hay debajo del capó?
El punto es pequeño: haz que todo funcione. Aquí ayudó que todas nuestras alineaciones ya estuvieran configuradas en un sistema separado que proporciona la API REST para recibirlas. Por lo tanto, después de un par de semanas de desarrollo pausado en mi tiempo libre, nació la primera versión del complemento para Bitbucket, que se desarrolló gradualmente y adquirió todo el conjunto de funcionalidades necesarias durante el otoño.
Cómo funciona el complemento
Normalmente, al crear un PR, Bitbucket rellena previamente los visores que se especifican en la configuración del proyecto o repositorio. Desde el punto de vista del usuario, nada ha cambiado aquí: todos los revisores también se rellenan previamente cuando se abre esta página, excepto que se ha agregado un campo con una descripción de qué revisor en qué rol se agregó. Y los roles de los revisores han aparecido de la siguiente manera:
- teammate es miembro del equipo del autor de relaciones públicas, se agrega fácilmente gracias a la API REST con composiciones de equipo,
- propietario del repositorio: un miembro aleatorio del equipo responsable del componente; en la configuración del repositorio era necesario dar la oportunidad de elegir el equipo responsable,
- experto en repositorios - experto en repositorios aleatorio; Te contaré más sobre esto más tarde
- mentor: un mentor para un equipo o un principiante, también está disponible a través de la API REST de un servicio con composiciones de equipo.
Expertos en repositorios
Te contaré un poco más sobre cómo consideramos expertos. Todos los días, el complemento pasa por todos los repositorios, analiza todas las solicitudes de extracción del último año y considera dos métricas simples:
- la cantidad de solicitudes de extracción creadas por el desarrollador,
- el número de RP que revisó y estableció aprobar, necesita trabajo o rechazar.
Agregamos ponderaciones a estas métricas basadas en el hecho de que desde el punto de vista de la experiencia en el código, el refinamiento de este código es más importante que la revisión. Primero, estimamos el número de solicitudes de extracción creadas una vez y media más importante que una revisión, y luego aumentamos la proporción de tres a uno. Resumimos las métricas multiplicadas por sus pesos y obtenemos la calificación de desarrollador.
A continuación, clasificamos a todos estos desarrolladores por calificación, seleccionamos los 5 mejores, en el camino, cortamos a aquellos cuya calificación está por debajo del umbral para cortar a los transeúntes ocasionales. Y generalmente tenemos de tres a cinco expertos para cada repositorio.
Arriba, le describí el enfoque para la selección de revisores, que elegimos e implementamos, pero a lo largo del camino implementamos varias pequeñas mejoras a la vez, lo que hizo que el proceso de revisión del código sea aún más rápido, más conveniente y más agradable.
Prohibir solicitud de extracción de fusión hasta que la tarea se haya registrado en Jira
Una cosa tan obvia y necesaria que, desafortunadamente, no sale de la caja. Solo obtenemos código estable en dev, que no solo pasó las comprobaciones estáticas y las pruebas de desarrollador, sino también las pruebas de integración junto con otros servicios. El estado de tales pruebas para nosotros se refleja solo en la tarea de Jira y, por lo tanto, antes, los desarrolladores tenían que ver manualmente si la tarea estaba marcada para ralentizar la solicitud de extracción.
Solicitud de extracción automática de fusión
La solicitud de extracción puede pasar una parte considerable de su vida en un estado en el que nada le impide tomarse el tiempo, pero una persona se olvida de hacerlo o no lo hace de inmediato. Un ejemplo sorprendente es la expectativa de probar una tarea, sin la cual no la mantenemos en desarrollo. Aquí es donde resulta útil una fusión automática, que funciona de acuerdo con un principio simple: si las relaciones públicas pueden congelarse, entonces lo hacemos.
Todas las condiciones necesarias para la fusión están cubiertas por cheques. Verificamos el éxito del ensamblaje, el nivel de cobertura de la prueba, la ausencia de dependencias de instantáneas de las bibliotecas, el estado de la tarea en Jira y la presencia de todas las actualizaciones necesarias. Es decir, tenemos todo para usar dicha funcionalidad y olvidarnos de las relaciones públicas desde el momento de pasar la revisión del código y enviar la tarea a la prueba (a menos que, por supuesto, el control de calidad encuentre problemas en ella).
E implementamos esto de una manera bastante conveniente: introdujimos un bot especial AutoMergeBot, que solo necesitamos agregar a los revisores, para que pueda comenzar a monitorear esta solicitud de extracción y congelarla cuando llegue el momento.
Contabilización de la ausencia de revisores.
Si el propietario o experto del componente está de vacaciones o de baja por enfermedad, el revisor no lo agregará, y su lugar lo ocupará el que esté en el lugar de trabajo. Como beneficio adicional, una montaña de solicitudes de atracción de otras personas no caerá en este crítico al salir de las vacaciones. Darse cuenta de esto no fue difícil debido al hecho de que toda la falta de empleados con nosotros se presentó con solicitudes en Jira.
Contabilidad para el empleo de revisores
Alguien revisa diez relaciones públicas al día, y unos cinco. Alguien ya ha acumulado 20 relaciones públicas no vistas, mientras que alguien casi no tiene ninguno. Tomamos todo esto en cuenta para distribuir la carga de manera más uniforme en los revisores. Cuanta más carga, menos se agrega a los nuevos RP, todo es simple.
Marcar tamaños de relaciones públicas al crear
En la página de creación de solicitud de extracción, el autor puede elegir su tamaño aproximado: S, M o L. Esto ayuda a los revisores a estimar el tiempo aproximado que pasarán en la revisión del código. Por ejemplo, tengo 5 minutos libres, y entiendo que puedo lograr ver la solicitud de extracción de tamaño S. No tiene sentido abrir M o L, porque no tengo tiempo para verlos y la próxima vez tendré que empezar desde cero.
En el futuro, queremos tener en cuenta estos atributos al calcular las estadísticas de relaciones públicas.
Etiquetado Urgente PR
Además, al crear un PR, el autor puede indicar que la tarea es muy urgente al agregar dicho símbolo al nombre PR. Los revisores lo verán de inmediato e intentarán verlo primero. Parece ser un poco, pero muy útil y conveniente.
Seguimiento de revisión de código de inicio y finalización
Si al mejorar el proceso es imposible entender cuánto ha mejorado, entonces no tiene sentido comenzar.
Lo mismo ocurre con la revisión del código: podemos intentar mejorarlo tanto como queramos, pero ¿cómo nos aseguraremos de una dinámica positiva sin métricas y estadísticas? En nuestro caso, esta no es la tarea más fácil: fuera de la caja, Bitbucket y Jira no dieron la oportunidad de rastrear el tiempo de revisión del código. Solo teníamos la métrica de vida útil de relaciones públicas en servicio, lo que no nos convenía del todo, porque solo retiramos la solicitud después de que se completa la prueba de la tarea, por lo tanto, los indicadores extraños se mezclaron en esta métrica.
Jira almacena y le permite cargar todos los puntos de control del ciclo de vida de la tarea, por lo que pensamos que es correcto enriquecer estos datos con dos etiquetas adicionales: la hora de inicio y finalización de la revisión del código. Solo era necesario enseñarle al plugin para que Bitbucket pusiera estas etiquetas en Jira. Por lo tanto, Jira fue, y sigue siendo, un único punto de verdad para la tarea, y con este conjunto de datos podemos separar el tiempo de la revisión del código del momento de probar la tarea.
El punto más delgado aquí es cómo determinar cuándo finalizar una revisión de código. ¿Tal vez este es el momento de obtener la primera aplicación, tal vez la última, o tal vez este es el momento de los últimos cambios realizados por el autor de PR? No tengo una respuesta a esta pregunta, aquí solo necesito estar de acuerdo entre nosotros y elegir una cosa o cubrir los tres eventos con métricas y seguir las desviaciones.
Seguimiento de descargas de revisores
Otra métrica útil es la carga de trabajo de los revisores. Como escribí anteriormente, lo tenemos en cuenta al asignar revisores a nuevos RP, pero también publicamos esta información para monitorear la dinámica de los equipos, departamentos o empresas. A veces, esto ayuda a detectar anomalías y posibles problemas: si está claro que una o más personas en un equipo cuelgan 10 o más RP no vistos todos los días, entonces hay una razón para averiguar si todo está en orden.
Ver métricas en Grafana
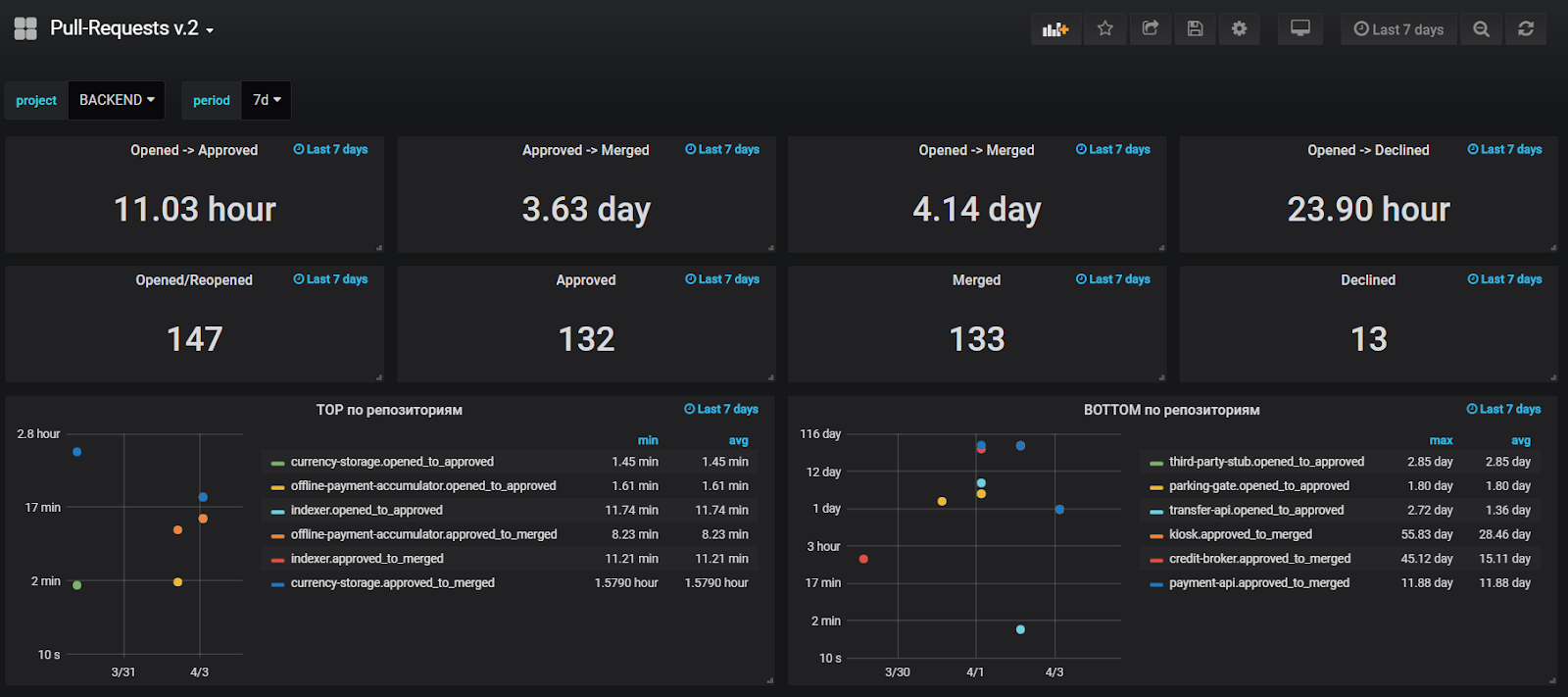
La creación de informes sobre datos de Jira es útil, pero no muy conveniente, por lo que también agregamos el envío de métricas para los principales eventos en StatsD con el fin de crear gráficos sobre datos operativos en Grafana. Monitoreamos el tiempo promedio hasta la primera prueba, el tiempo de vida promedio del RP, y también observamos los valores anómalos de estas métricas para encontrar y resolver problemas rápidamente.
Al momento de escribir, nuestro tablero se ve así:
¿Qué obtuviste al final?
Desafortunadamente, todos somos fuertes en retrospectiva, por lo que no presentamos las métricas de revisión de código mencionadas anteriormente antes de que el proceso en sí comenzara a cambiar (septiembre-octubre de 2018), pero ya en el camino, por lo que solo podemos rastrear de manera confiable las mejoras o deterioros desde principios de diciembre de 2018 ¿Qué logramos notar?
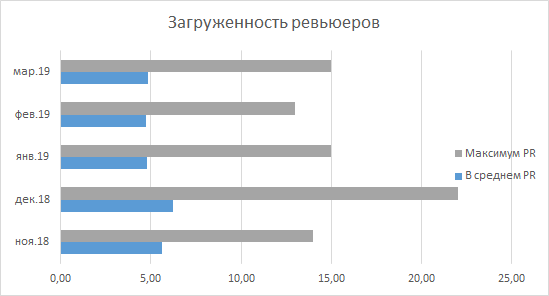
Lo primero que llama la atención es la reducción de la carga en los revisores superiores, y sentí esto con mi propio ejemplo. Como ya mencioné, era normal para mí ver unos 30 RP en línea por la mañana, pero ahora este número fluctúa entre 10 y 15. Las estadísticas del departamento lo confirman: desde diciembre de 2018, nadie ha aumentado el número máximo de RP que esperan una revisión. arriba 15. En promedio, observamos una imagen que sugiere que, en promedio, cada desarrollador espera de 4 a 5 relaciones públicas no vistas por la mañana, lo que parece ser un número bastante adecuado.
En cuanto a la relevancia de la selección de revisores y la calidad de la revisión del código, aquí solo podemos confiar en indicadores subjetivos. De acuerdo con las encuestas de colegas, realmente comenzamos a obtener una excelente selección de revisores, ahora nadie tiene que agregar manualmente y no se dejan abandonados ni olvidados los RP.
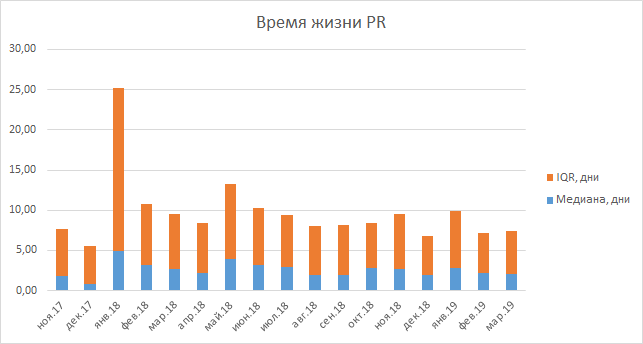
Si hablamos sobre el tiempo que lleva pasar la revisión del código, entonces es demasiado pronto para calcular estadísticas sobre este indicador, porque comenzamos a recopilarlo recientemente. A nuestra disposición solo existe el tiempo de vida de las solicitudes de extracción, que en realidad no aumentó ni disminuyó. Esta métrica incluye el tiempo de prueba de la tarea, por lo que es difícil sacar conclusiones claras al respecto, además, al cambiar el código de revisión, no lo hicimos más largo.