El procesamiento del lenguaje natural ahora no se usa, excepto en sectores muy conservadores. En la mayoría de las soluciones tecnológicas, el reconocimiento y el procesamiento de lenguajes "humanos" se ha introducido desde hace mucho tiempo: es por eso que el IVR habitual con opciones de respuesta codificadas se está convirtiendo gradualmente en algo del pasado, los chatbots comienzan a comunicarse de manera más adecuada sin la participación de un operador en vivo, los filtros de correo funcionan con una explosión, etc. ¿Cómo se reconoce el habla grabada, es decir, el texto? O más bien, ¿cuál será la base de las técnicas modernas de reconocimiento y procesamiento? Nuestra traducción adaptada de hoy responde bien a esto: debajo del corte encontrará un largo recorrido que cerrará las brechas en los conceptos básicos de la PNL. Que tengas una buena lectura!
¿Qué es el procesamiento del lenguaje natural?
Procesamiento del lenguaje natural (en adelante, PNL): el procesamiento del lenguaje natural es una subsección de la informática y la inteligencia artificial dedicada a cómo las computadoras analizan los lenguajes naturales (humanos). NLP permite el uso de algoritmos de aprendizaje automático para texto y voz.
Por ejemplo, podemos usar PNL para crear sistemas como reconocimiento de voz, generalización de documentos, traducción automática, detección de spam, reconocimiento de entidades con nombre, respuestas a preguntas, autocompletado, ingreso de texto predictivo, etc.
Hoy en día, muchos de nosotros tenemos teléfonos inteligentes de reconocimiento de voz: usan PNL para comprender nuestra voz. Además, muchas personas usan computadoras portátiles con reconocimiento de voz incorporado en el sistema operativo.
Ejemplos
Cortana
Windows tiene un asistente virtual Cortana que reconoce el habla. Con Cortana, puede crear recordatorios, abrir aplicaciones, enviar cartas, jugar juegos, conocer el clima, etc.
Siri
Siri es un asistente para el sistema operativo de Apple: iOS, watchOS, macOS, HomePod y tvOS. Muchas funciones también funcionan a través del control por voz: llamar / escribir a alguien, enviar un correo electrónico, configurar un temporizador, tomar una foto, etc.
Gmail
Un servicio de correo electrónico conocido sabe cómo detectar el correo no deseado para que no entre en la bandeja de entrada de su bandeja de entrada.
Dialogflow
Una plataforma de Google que te permite crear bots de PNL. Por ejemplo, puede hacer un bot de pedidos de pizza
que no necesite un IVR anticuado para aceptar su pedido .
NLTK Python Library
NLTK (Natural Language Toolkit) es una plataforma líder para crear programas de PNL en Python. Tiene interfaces fáciles de usar para muchos
cuerpos de lenguaje , así como bibliotecas para procesamiento de textos para clasificación, tokenización,
derivación ,
marcado , filtrado y
razonamiento semántico . Bueno, y este es un proyecto de código abierto gratuito que se está desarrollando con la ayuda de la comunidad.
Utilizaremos esta herramienta para mostrar los conceptos básicos de PNL. Para todos los ejemplos posteriores, supongo que NLTK ya está importado; esto se puede hacer con el
import nltkConceptos básicos de PNL para texto
En este artículo cubriremos temas:
- Tokenización por ofertas.
- Tokenización por palabras.
- Lematización y estampación del texto.
- Deja de palabras.
- Expresiones regulares
- Bolsa de palabras
- TF-IDF .
1. Tokenización por ofertas
La tokenización (a veces segmentación) de oraciones es el proceso de dividir un lenguaje escrito en oraciones componentes. La idea parece bastante simple. En inglés y en otros idiomas, podemos aislar una oración cada vez que encontramos un cierto signo de puntuación: un punto.
Pero incluso en inglés esta tarea no es trivial, ya que el punto también se usa en abreviaturas. La tabla de abreviaturas puede ser de gran ayuda durante el procesamiento de textos para evitar el mal posicionamiento de los límites de las oraciones. En la mayoría de los casos, las bibliotecas se utilizan para esto, por lo que realmente no tiene que preocuparse por los detalles de implementación.
Un ejemplo:Tome un breve texto sobre el juego de mesa de backgammon:
Backgammon is one of the oldest known board games. Its history can be traced back nearly 5,000 years to archeological discoveries in the Middle East. It is a two player game where each player has fifteen checkers which move between twenty-four points according to the roll of two dice.
Para realizar ofertas de tokenización utilizando NLTK, puede usar el método
nltk.sent_tokenize | text = "Backgammon is one of the oldest known board games. Its history can be traced back nearly 5,000 years to archeological discoveries in the Middle East. It is a two player game where each player has fifteen checkers which move between twenty-four points according to the roll of two dice." |
| sentences = nltk.sent_tokenize(text) |
| for sentence in sentences: |
| print(sentence) |
| print() |
A la salida, obtenemos 3 oraciones separadas:
Backgammon is one of the oldest known board games. Its history can be traced back nearly 5,000 years to archeological discoveries in the Middle East. It is a two player game where each player has fifteen checkers which move between twenty-four points according to the roll of two dice.
2. Tokenización según palabras
La tokenización (a veces segmentación) según las palabras es el proceso de dividir oraciones en palabras componentes. En inglés y en muchos otros idiomas que usan una versión particular del alfabeto latino, un espacio es un buen separador de palabras.
Sin embargo, pueden surgir problemas si usamos solo un espacio: en inglés, los sustantivos compuestos se escriben de manera diferente y, a veces, están separados por espacios. Y aquí las bibliotecas nos ayudan de nuevo.
Un ejemplo:Tomemos las oraciones del ejemplo anterior y apliquemos el método
nltk.word_tokenize | for sentence in sentences: |
| words = nltk.word_tokenize(sentence) |
| print(words) |
| print() |
Conclusión
['Backgammon', 'is', 'one', 'of', 'the', 'oldest', 'known', 'board', 'games', '.'] ['Its', 'history', 'can', 'be', 'traced', 'back', 'nearly', '5,000', 'years', 'to', 'archeological', 'discoveries', 'in', 'the', 'Middle', 'East', '.'] ['It', 'is', 'a', 'two', 'player', 'game', 'where', 'each', 'player', 'has', 'fifteen', 'checkers', 'which', 'move', 'between', 'twenty-four', 'points', 'according', 'to', 'the', 'roll', 'of', 'two', 'dice', '.']
3. Lematización y estampación del texto.
Por lo general, los textos contienen diferentes formas gramaticales de la misma palabra, y también pueden aparecer palabras de una raíz. El objetivo de la lematización y la derivación es llevar todas las formas de las palabras a una sola forma de vocabulario normal.
Ejemplos:Trayendo diferentes formas de palabras a una:
dog, dogs, dog's, dogs' => dog
Lo mismo, pero con referencia a toda la oración:
the boy's dogs are different sizes => the boy dog be differ size
La lematización y la derivación son casos especiales de normalización y difieren.
La derivación es un proceso heurístico crudo que corta el "exceso" de la raíz de las palabras, a menudo esto conduce a la pérdida de sufijos de construcción de palabras.
La lematización es un proceso más sutil que utiliza vocabulario y análisis morfológicos para finalmente llevar la palabra a su forma canónica: el lema.
La diferencia es que el stemmer (una implementación específica del algoritmo de stemming - comentario del traductor) funciona sin conocer el contexto y, en consecuencia, no comprende la diferencia entre palabras que tienen diferentes significados según la parte del discurso. Sin embargo, los Stemmers tienen sus propias ventajas: son más fáciles de implementar y funcionan más rápido. Además, una "precisión" más baja puede no importar en algunos casos.
Ejemplos:- La palabra bueno es un lema para la palabra mejor. Stemmer no verá esta conexión, ya que aquí debe consultar el diccionario.
- El juego de palabras es la forma básica del juego de palabras. Aquí, tanto la derivación como la lematización serán suficientes.
- La palabra reunión puede ser una forma normal de un sustantivo o una forma del verbo cumplir, según el contexto. A diferencia de la derivación, la lematización intentará elegir el lema correcto según el contexto.
Ahora que sabemos cuál es la diferencia, veamos un ejemplo:
| from nltk.stem import PorterStemmer, WordNetLemmatizer |
| from nltk.corpus import wordnet |
| |
| def compare_stemmer_and_lemmatizer(stemmer, lemmatizer, word, pos): |
| """ |
| Print the results of stemmind and lemmitization using the passed stemmer, lemmatizer, word and pos (part of speech) |
| """ |
| print("Stemmer:", stemmer.stem(word)) |
| print("Lemmatizer:", lemmatizer.lemmatize(word, pos)) |
| print() |
| |
| lemmatizer = WordNetLemmatizer() |
| stemmer = PorterStemmer() |
| compare_stemmer_and_lemmatizer(stemmer, lemmatizer, word = "seen", pos = wordnet.VERB) |
| compare_stemmer_and_lemmatizer(stemmer, lemmatizer, word = "drove", pos = wordnet.VERB) |
Conclusión
Stemmer: seen Lemmatizer: see Stemmer: drove Lemmatizer: drive
4. Detener palabras
Las palabras de detención son palabras que se eliminan del texto antes / después del procesamiento del texto. Cuando aplicamos el aprendizaje automático a los textos, tales palabras pueden agregar mucho ruido, por lo que debe deshacerse de las palabras irrelevantes.
Las palabras de parada generalmente se entienden por artículos, interjecciones, uniones, etc., que no llevan una carga semántica. Debe entenderse que no existe una lista universal de palabras de detención, todo depende del caso particular.
NLTK tiene una lista predefinida de palabras de detención. Antes del primer uso, deberá descargarlo:
nltk.download(“stopwords”) . Después de la descarga, puede importar el paquete de palabras
stopwords y mirar las palabras mismas:
| from nltk.corpus import stopwords |
| print(stopwords.words("english")) |
Conclusión
['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', "you're", "you've", "you'll", "you'd", 'your', 'yours', 'yourself', 'yourselves', 'he', 'him', 'his', 'himself', 'she', "she's", 'her', 'hers', 'herself', 'it', "it's", 'its', 'itself', 'they', 'them', 'their', 'theirs', 'themselves', 'what', 'which', 'who', 'whom', 'this', 'that', "that'll", 'these', 'those', 'am', 'is', 'are', 'was', 'were', 'be', 'been', 'being', 'have', 'has', 'had', 'having', 'do', 'does', 'did', 'doing', 'a', 'an', 'the', 'and', 'but', 'if', 'or', 'because', 'as', 'until', 'while', 'of', 'at', 'by', 'for', 'with', 'about', 'against', 'between', 'into', 'through', 'during', 'before', 'after', 'above', 'below', 'to', 'from', 'up', 'down', 'in', 'out', 'on', 'off', 'over', 'under', 'again', 'further', 'then', 'once', 'here', 'there', 'when', 'where', 'why', 'how', 'all', 'any', 'both', 'each', 'few', 'more', 'most', 'other', 'some', 'such', 'no', 'nor', 'not', 'only', 'own', 'same', 'so', 'than', 'too', 'very', 's', 't', 'can', 'will', 'just', 'don', "don't", 'should', "should've", 'now', 'd', 'll', 'm', 'o', 're', 've', 'y', 'ain', 'aren', "aren't", 'couldn', "couldn't", 'didn', "didn't", 'doesn', "doesn't", 'hadn', "hadn't", 'hasn', "hasn't", 'haven', "haven't", 'isn', "isn't", 'ma', 'mightn', "mightn't", 'mustn', "mustn't", 'needn', "needn't", 'shan', "shan't", 'shouldn', "shouldn't", 'wasn', "wasn't", 'weren', "weren't", 'won', "won't", 'wouldn', "wouldn't"]
Considere cómo puede eliminar las palabras vacías de una oración:
| stop_words = set(stopwords.words("english")) |
| sentence = "Backgammon is one of the oldest known board games." |
| |
| words = nltk.word_tokenize(sentence) |
| without_stop_words = [word for word in words if not word in stop_words] |
| print(without_stop_words) |
Conclusión
['Backgammon', 'one', 'oldest', 'known', 'board', 'games', '.']
Si no está familiarizado con las comprensiones de listas, puede encontrar más información
aquí . Aquí hay otra forma de lograr el mismo resultado:
| stop_words = set(stopwords.words("english")) |
| sentence = "Backgammon is one of the oldest known board games." |
| |
| words = nltk.word_tokenize(sentence) |
| without_stop_words = [] |
| for word in words: |
| if word not in stop_words: |
| without_stop_words.append(word) |
| |
| print(without_stop_words) |
Sin embargo, recuerde que las comprensiones de listas son más rápidas porque están optimizadas: el intérprete revela un patrón predictivo durante el ciclo.
Puede preguntar por qué convertimos la lista a
muchos . Un conjunto es un tipo de datos abstracto que puede almacenar valores únicos en un orden indefinido. Buscar por conjunto es mucho más rápido que buscar en una lista. Para un pequeño número de palabras, esto no importa, pero si estamos hablando de un gran número de palabras, entonces se recomienda estrictamente usar conjuntos. Si quieres saber un poco más sobre el tiempo que lleva realizar varias operaciones, mira
esta maravillosa hoja de trucos .
5. Expresiones regulares.
Una expresión regular (regex, regexp, regex) es una secuencia de caracteres que define un patrón de búsqueda. Por ejemplo:
- . - cualquier carácter excepto el avance de línea;
- \ w es una palabra;
- \ d - un dígito;
- \ s - un espacio;
- \ W es una NO palabra;
- \ D - un no dígito;
- \ S - un no espacio;
- [abc]: encuentra que cualquiera de los caracteres especificados coincide con cualquiera de a, b o c;
- [^ abc]: encuentra cualquier carácter excepto los especificados;
- [ag] - Encuentra un personaje en el rango de a a g.
Extracto de la
documentación de Python :
Las expresiones regulares usan la barra invertida (\) para indicar formas especiales o para permitir el uso de caracteres especiales. Esto contradice el uso de la barra diagonal inversa en Python: por ejemplo, para denotar literalmente la barra diagonal inversa, debe escribir '\\\\' como patrón de búsqueda, ya que la expresión regular debe verse como \\ , donde se debe escapar cada barra diagonal inversa.
La solución es usar notación de cadena sin formato para patrones de búsqueda; las barras invertidas no se procesarán especialmente si se usan con el prefijo 'r' . Por lo tanto, r”\n” es una cadena con dos caracteres ('\' 'n') , y “\n” es una cadena con un carácter (avance de línea).
Podemos usar clientes habituales para filtrar aún más nuestro texto. Por ejemplo, puede eliminar todos los caracteres que no son palabras. En muchos casos, la puntuación no es necesaria y es fácil de eliminar con la ayuda de clientes habituales.
El módulo
re en Python representa operaciones de expresión regular. Podemos usar la función
re.sub para reemplazar todo lo que se ajuste al patrón de búsqueda con la cadena especificada. Por lo tanto, puede reemplazar todas las no palabras con espacios:
| import re |
| sentence = "The development of snowboarding was inspired by skateboarding, sledding, surfing and skiing." |
| pattern = r"[^\w]" |
| print(re.sub(pattern, " ", sentence)) |
Conclusión
'The development of snowboarding was inspired by skateboarding sledding surfing and skiing '
Los habituales son una herramienta poderosa que se puede utilizar para crear patrones mucho más complejos. Si desea saber más sobre las expresiones regulares, le puedo recomendar estas 2 aplicaciones web:
regex ,
regex101 .
6. Bolsa de palabras
Los algoritmos de aprendizaje automático no pueden funcionar directamente con texto sin formato, por lo que debe convertir el texto en conjuntos de números (vectores). Esto se llama
extracción de características .
Una bolsa de palabras es una técnica de extracción de características popular y simple que se utiliza cuando se trabaja con texto. Describe las ocurrencias de cada palabra en el texto.
Para usar el modelo, necesitamos:
- Definir un diccionario de palabras conocidas (tokens).
- Elija el grado de presencia de palabras famosas.
Cualquier información sobre el orden o la estructura de las palabras se ignora. Es por eso que se llama una BOLSA de palabras. Este modelo intenta comprender si una palabra conocida aparece en un documento, pero no sabe exactamente dónde aparece.
La intuición sugiere que
documentos similares tienen
contenido similar . Además, gracias al contenido, podemos aprender algo sobre el significado del documento.
Un ejemplo:Considere los pasos para crear este modelo. Usamos solo 4 oraciones para entender cómo funciona el modelo. En la vida real, encontrarás más datos.
1. Descargar datos
Imagine que estos son nuestros datos y queremos cargarlos como una matriz:
I like this movie, it's funny. I hate this movie. This was awesome! I like it. Nice one. I love it.
Para hacer esto, solo lea el archivo y divídalo por línea:
| with open("simple movie reviews.txt", "r") as file: |
| documents = file.read().splitlines() |
| |
| print(documents) |
Conclusión
["I like this movie, it's funny.", 'I hate this movie.', 'This was awesome! I like it.', 'Nice one. I love it.']
2. Defina un diccionario
Recopilaremos todas las palabras únicas de 4 oraciones cargadas, ignorando mayúsculas, signos de puntuación y tokens de un carácter. Este será nuestro diccionario (palabras famosas).
Para crear un diccionario, puede usar la clase
CountVectorizer de la biblioteca sklearn. Ve al siguiente paso.
3. Crear vectores de documentos
Luego, necesitamos evaluar las palabras en el documento. En este paso, nuestro objetivo es convertir el texto sin formato en un conjunto de números. Después de eso, usamos estos conjuntos como entrada para el modelo de aprendizaje automático. El método de puntuación más simple es observar la presencia de palabras, es decir, poner 1 si hay una palabra y 0 si está ausente.
Ahora podemos crear una bolsa de palabras utilizando la clase CountVectorizer mencionada anteriormente.
| # Import the libraries we need |
| from sklearn.feature_extraction.text import CountVectorizer |
| import pandas as pd |
| |
| # Step 2. Design the Vocabulary |
| # The default token pattern removes tokens of a single character. That's why we don't have the "I" and "s" tokens in the output |
| count_vectorizer = CountVectorizer() |
| |
| # Step 3. Create the Bag-of-Words Model |
| bag_of_words = count_vectorizer.fit_transform(documents) |
| |
| # Show the Bag-of-Words Model as a pandas DataFrame |
| feature_names = count_vectorizer.get_feature_names() |
| pd.DataFrame(bag_of_words.toarray(), columns = feature_names) |
Conclusión
Estas son nuestras sugerencias. Ahora vemos cómo funciona el modelo de "bolsa de palabras".
Algunas palabras sobre la bolsa de palabras
La complejidad de este modelo es cómo determinar el diccionario y cómo contar la aparición de palabras.
Cuando aumenta el tamaño del diccionario, el vector del documento también crece. En el ejemplo anterior, la longitud del vector es igual al número de palabras conocidas.
En algunos casos, podemos tener una cantidad increíblemente grande de datos y luego el vector puede constar de miles o millones de elementos. Además, cada documento puede contener solo una pequeña parte de las palabras del diccionario.
Como resultado, habrá muchos ceros en la representación vectorial. Los vectores con muchos ceros se denominan vectores dispersos, requieren más memoria y recursos computacionales.
Sin embargo, podemos reducir la cantidad de palabras conocidas cuando usamos este modelo para reducir la demanda de recursos informáticos. Para hacer esto, puede usar las mismas técnicas que ya consideramos antes de crear una bolsa de palabras:
- ignorando el caso de las palabras;
- ignorando la puntuación;
- expulsar palabras de parada;
- reducción de palabras a sus formas básicas (lematización y derivación);
- corrección de palabras mal escritas.
Otra forma más complicada de crear un diccionario es usar palabras agrupadas. Esto cambiará el tamaño del diccionario y le dará a la bolsa de palabras más detalles sobre el documento. Este enfoque se llama "
N-gram ".
N-gram es una secuencia de cualquier entidad (palabras, letras, números, números, etc.). En el contexto de los cuerpos lingüísticos, el N-gramo generalmente se entiende como una secuencia de palabras. Un unigrama es una palabra, un bigrama es una secuencia de dos palabras, un trigrama son tres palabras, y así sucesivamente. El número N indica cuántas palabras agrupadas se incluyen en el N-gramo. No todos los N-gramos posibles entran en el modelo, pero solo los que aparecen en el caso.
Un ejemplo:Considere la siguiente oración:
The office building is open today
Aquí están sus bigrams:
- la oficina
- edificio de oficinas
- el edificio es
- está abierto
- abierto hoy
Como puede ver, una bolsa de bigrams es un enfoque más efectivo que una bolsa de palabras.
Evaluación (puntuación) de palabrasCuando se crea un diccionario, se debe evaluar la presencia de palabras. Ya hemos considerado un enfoque binario simple (1: hay una palabra, 0: no hay una palabra).
Existen otros métodos:
- Cantidad Se calcula cuántas veces aparece cada palabra en el documento.
- Frecuencia Se calcula con qué frecuencia cada palabra aparece en el texto (en relación con el número total de palabras).
7. TF-IDF
La puntuación de frecuencia tiene un problema: las palabras con la frecuencia más alta tienen, respectivamente, la calificación más alta. En estas palabras puede que no haya tanta
ganancia informativa para el modelo como en palabras menos frecuentes. Una forma de rectificar la situación es reducir la puntuación de palabras, que a menudo se encuentra
en todos los documentos similares . Esto se llama
TF-IDF .
TF-IDF (abreviatura de frecuencia de término - frecuencia de documento inversa) es una medida estadística para evaluar la importancia de una palabra en un documento que forma parte de una colección o corpus.
La puntuación por TF-IDF aumenta en proporción a la frecuencia de aparición de una palabra en un documento, pero esto se compensa con el número de documentos que contienen esta palabra.
Fórmula de puntuación para la palabra X en el documento Y:
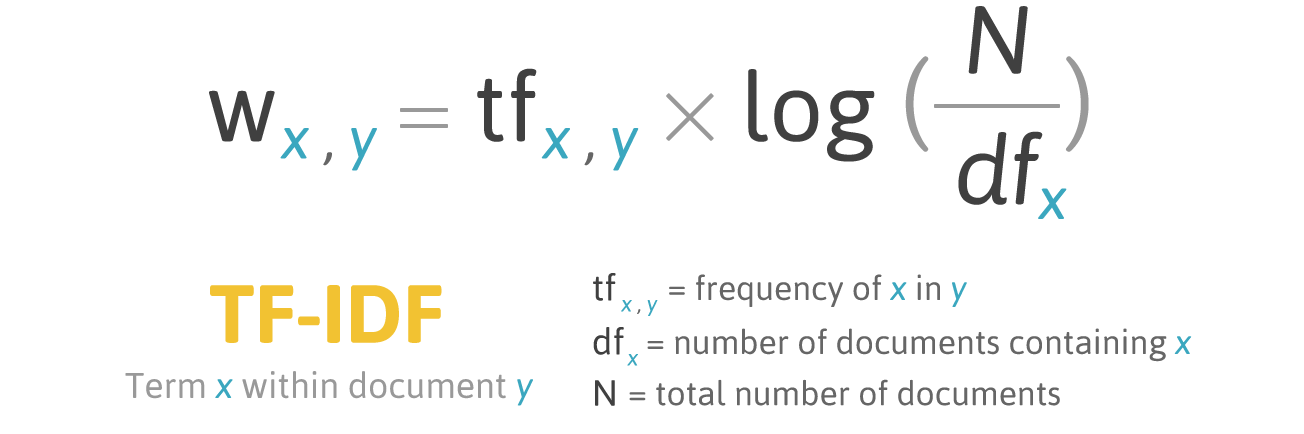 Fórmula TF-IDF. Fuente: filotechnologia.blogspot.com/2014/01/a-simple-java-class-for-tfidf-scoring.html
Fórmula TF-IDF. Fuente: filotechnologia.blogspot.com/2014/01/a-simple-java-class-for-tfidf-scoring.htmlTF (frecuencia de término) es la relación entre el número de apariciones de una palabra y el número total de palabras en un documento.
IDF (frecuencia de documento inversa) es la inversa de la frecuencia con la que aparece una palabra en los documentos de colección.
Como resultado, TF-IDF para el
término de palabra se puede calcular de la siguiente manera:
Un ejemplo:Puede usar la clase
TfidfVectorizer de la biblioteca sklearn para calcular TF-IDF. Hagamos esto con los mismos mensajes que usamos en el ejemplo de bolsa de palabras.
I like this movie, it's funny. I hate this movie. This was awesome! I like it. Nice one. I love it.
Código:
| from sklearn.feature_extraction.text import TfidfVectorizer |
| import pandas as pd |
| |
| tfidf_vectorizer = TfidfVectorizer() |
| values = tfidf_vectorizer.fit_transform(documents) |
| |
| # Show the Model as a pandas DataFrame |
| feature_names = tfidf_vectorizer.get_feature_names() |
| pd.DataFrame(values.toarray(), columns = feature_names) |
Conclusión
Conclusión
Este artículo ha cubierto los conceptos básicos de PNL para texto, a saber:
- NLP permite el uso de algoritmos de aprendizaje automático para texto y voz;
- NLTK (Natural Language Toolkit): una plataforma líder para crear programas NLP en Python;
- la tokenización de propuesta es el proceso de dividir un lenguaje escrito en oraciones componentes;
- la tokenización de palabras es el proceso de dividir oraciones en palabras componentes;
- La lematización y la derivación tienen como objetivo llevar todas las formas de palabras encontradas a una sola forma de vocabulario normal;
- las palabras de detención son palabras que se eliminan del texto antes / después del procesamiento del texto;
- regex (regex, regexp, regex) es una secuencia de caracteres que define un patrón de búsqueda;
- Una bolsa de palabras es una técnica de extracción de características popular y simple que se utiliza cuando se trabaja con texto. Describe las ocurrencias de cada palabra en el texto.
Genial Ahora que conoce los conceptos básicos de la extracción de características, puede usar las características como entrada para los algoritmos de aprendizaje automático.
Si desea ver todos los conceptos descritos en un gran ejemplo,
aquí está .