
En nuestros proyectos utilizamos arquitectura de microservicios. Si surgen cuellos de botella en el rendimiento, se dedica mucho tiempo a monitorear y analizar registros. Cuando se registran los tiempos de las operaciones individuales en un archivo de registro, generalmente es difícil entender qué llevó a la invocación de estas operaciones, rastrear la secuencia de acciones o el desplazamiento de tiempo de una operación en relación con otra en diferentes servicios.
Para minimizar el trabajo manual, decidimos usar una de las herramientas de rastreo. Acerca de cómo y para qué es posible usar el rastreo y cómo lo hicimos, hablaremos de este artículo.
Qué problemas se pueden resolver con trace
- Encuentre cuellos de botella de rendimiento tanto en un solo servicio como en todo el árbol de ejecución entre todos los servicios participantes. Por ejemplo:
- Muchas llamadas cortas consecutivas entre servicios, por ejemplo, a geocodificación o a una base de datos.
- Larga espera para la entrada de entrada, por ejemplo, transferir datos a través de una red o leer desde el disco.
- Análisis de datos largo.
- Operaciones largas que requieren CPU.
- Piezas de código que no son necesarias para obtener el resultado final y se pueden eliminar o retrasar.
- Comprenda claramente en qué secuencia se llama y qué sucede cuando se realiza la operación.
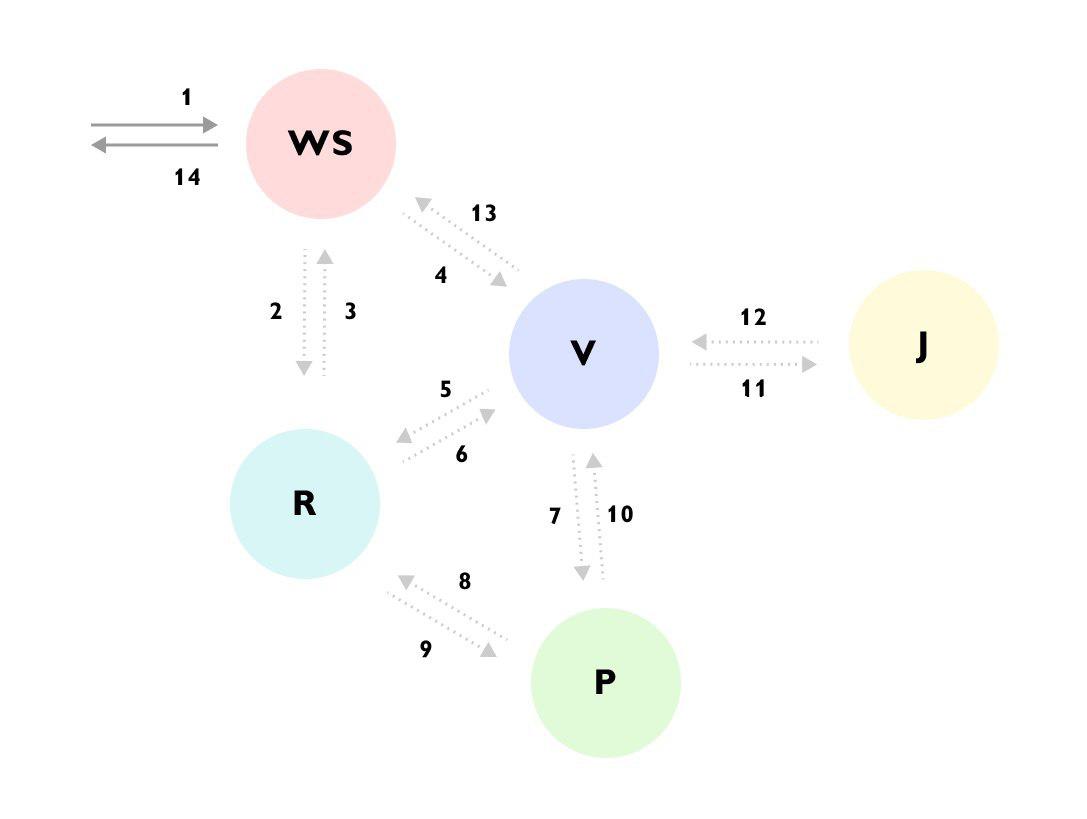
Se puede ver que, por ejemplo, la solicitud llegó al servicio WS -> el servicio WS complementó los datos a través del servicio R -> luego envió la solicitud al servicio V -> el servicio V cargó una gran cantidad de datos del servicio R -> fue al servicio P -> el servicio P se volvió a apagar al servicio R -> el servicio V ignoró el resultado y fue al servicio J -> y solo entonces devolvió la respuesta al servicio WS, mientras continuaba calculando algo más en segundo plano.
Sin ese rastro o documentación detallada para todo el proceso, es muy difícil entender lo que está sucediendo la primera vez que mira el código, y el código está disperso en diferentes servicios y oculto detrás de un montón de contenedores e interfaces.
- Recopilación de información sobre el árbol de ejecución para su posterior análisis pendiente. En cada etapa de ejecución, puede agregar información a la traza que está disponible en esta etapa y luego averiguar qué datos de entrada condujeron a un escenario similar. Por ejemplo:
- ID de usuario
- Derechos
- Tipo de método seleccionado
- Error de registro o ejecución
- Convierta las trazas en un subconjunto de métricas y análisis posteriores como métricas.
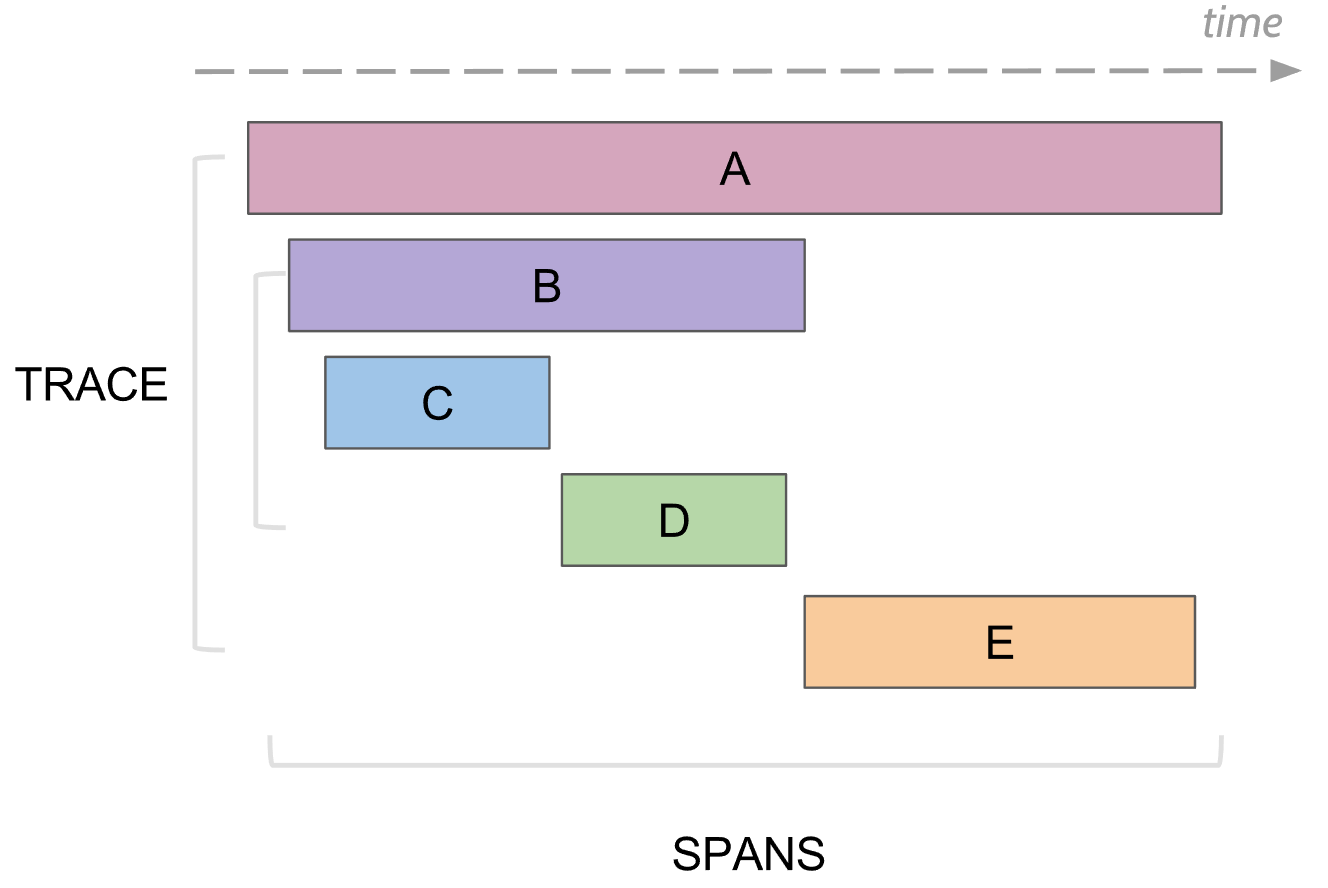
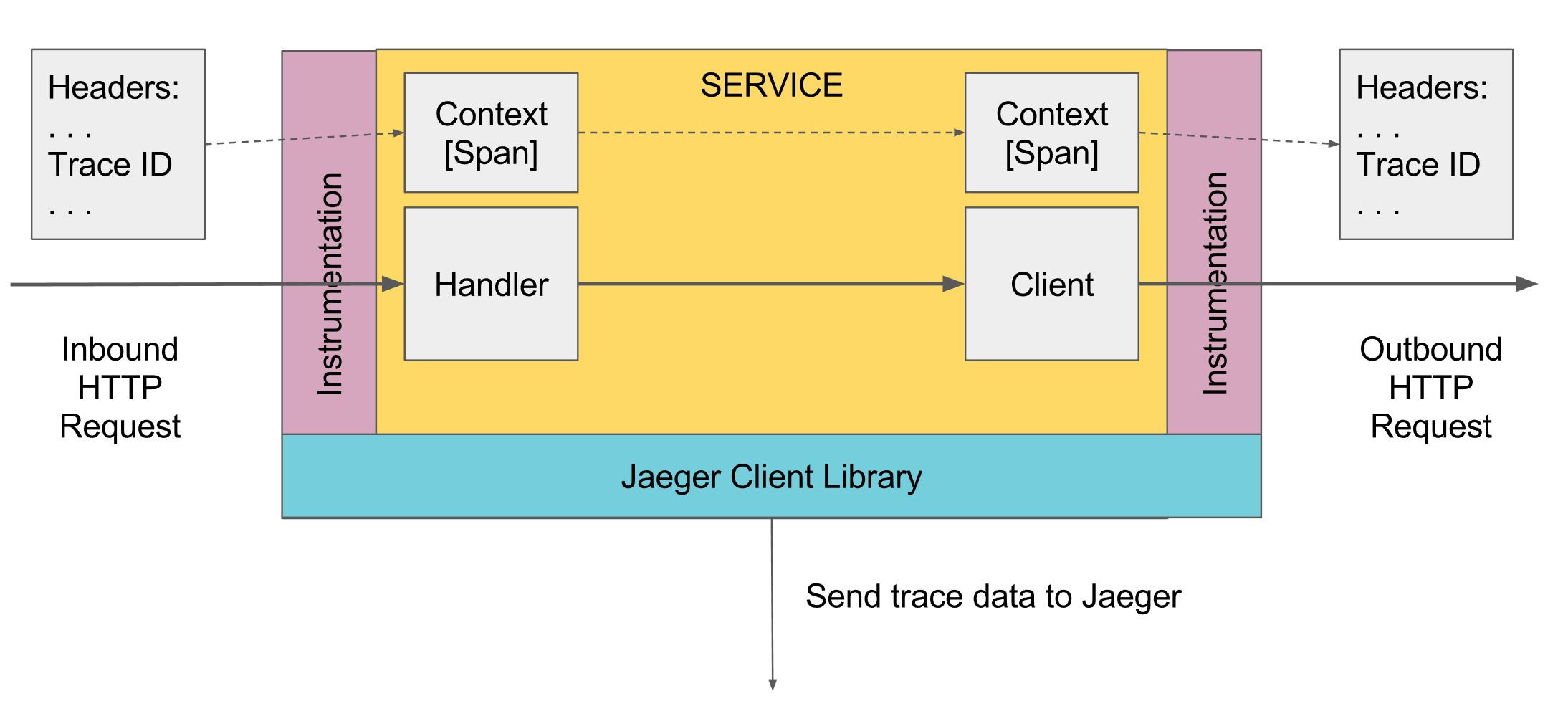
Lo que puede rastrear el registro. Span
En el rastreo, existe el concepto de span, este es un análogo de un registro en la consola. El lapso tiene:
- El nombre, generalmente el nombre del método que se ejecutó
- El nombre del servicio en el que se generó el lapso
- ID única y propia
- Alguna metainformación en forma de clave / valor, que se le prometió. Por ejemplo, los parámetros del método o el método terminaron con un error o no
- Los tiempos de inicio y finalización de este lapso.
- ID de intervalo principal
Cada intervalo se envía al recopilador de intervalo para guardarlo en la base de datos para su posterior visualización tan pronto como haya completado su ejecución. En el futuro, puede construir un árbol de todos los tramos conectándose mediante la identificación principal. En el análisis, puede encontrar, por ejemplo, todos los tramos en algún servicio que tomó más de un tiempo. Además, yendo a un lapso específico, vea el árbol completo arriba y abajo de este lapso.
Opentracing, Jagger y cómo lo implementamos para nuestros proyectos
Existe un estándar general de
Opentracing que describe cómo y qué debe ensamblarse sin estar vinculado a una implementación específica en ningún idioma. Por ejemplo, en Java, todo el trabajo con trazas se realiza a través de la API general de Opentracing, y debajo de ella, por ejemplo, Jaeger o una implementación predeterminada vacía que no hace nada puede ocultarse.
Usamos
Jaeger como una implementación de Opentracing. Se compone de varios componentes:
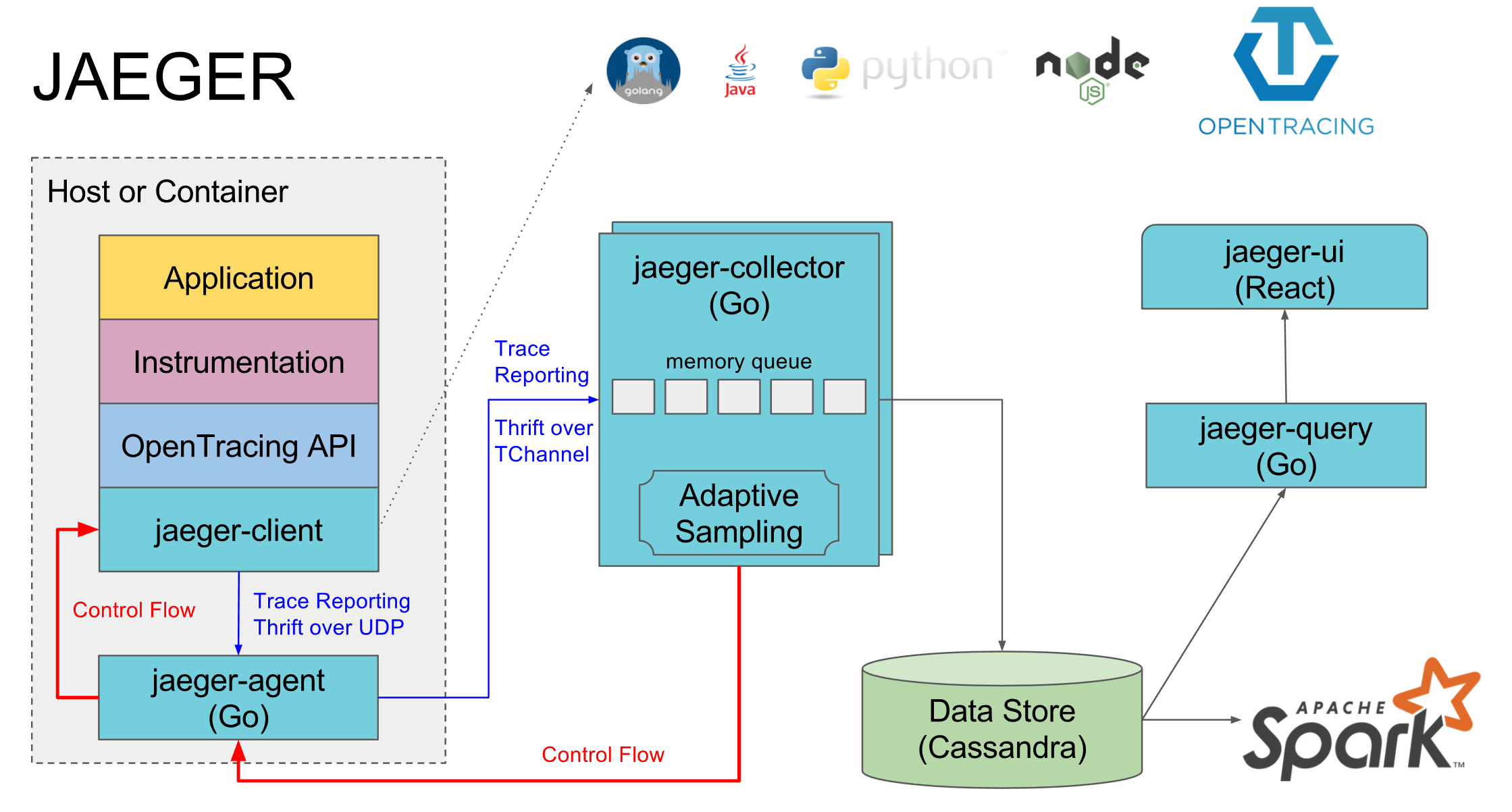
- Jaeger-agent es un agente local que generalmente se encuentra en cada máquina y los servicios se registran en el puerto predeterminado local. Si no hay agente, las trazas de todos los servicios en esta máquina generalmente se desactivan
- Jaeger-collector: todos los agentes le envían rastros recopilados y los coloca en la base de datos seleccionada
- La base de datos es su cassandra preferida, pero usamos elasticsearch, hay implementaciones para un par de otras bases de datos y una implementación en memoria que no guarda nada en el disco
- Jaeger-query es un servicio que va a la base de datos y proporciona rastros ya recopilados para su análisis.
- Jaeger-ui es una interfaz web para buscar y ver trazas, va a jaeger-query
Un componente separado es la implementación de jaeger opentracing para lenguajes específicos, a través del cual se envían tramos a jaeger-agent.
Conectar Jagger en Java se reduce a simular la interfaz io.opentracing.Tracer, después de lo cual todos los rastros a través de él volarán al agente real.
También puede conectar
opentracing-spring-cloud-starter y una implementación de Jaeger
opentracing-spring-jaeger-cloud-starter que configurará automáticamente el seguimiento de todo lo que pasa a través de estos componentes, por ejemplo, solicitudes http a controladores, solicitudes de bases de datos a través de jdbc etc.
Seguimiento de registro en Java
En algún lugar del nivel más alto, se debe crear el primer Span, esto puede hacerse automáticamente, por ejemplo, por el controlador de resorte cuando se recibe una solicitud, o manualmente si no hay ninguno. Además, se transmite a través del alcance a continuación. Si algún método a continuación quiere agregar Span, toma el activeSpan actual de Scope, crea un nuevo Span y dice que su padre recibió activeSpan, y hace que el nuevo Span esté activo. Cuando se llaman servicios externos, el intervalo activo actual se transfiere a ellos, y esos servicios crean nuevos intervalos con referencia a este intervalo.
Todo el trabajo pasa por la instancia de Tracer, puede obtenerlo a través del mecanismo DI o GlobalTracer.get () como una variable global si el mecanismo DI no funciona. Por defecto, si el trazador no se inicializó, NoopTracer devolverá lo que no hace nada.
Además, el alcance actual se obtiene del trazador a través de ScopeManager, se crea un nuevo alcance a partir del actual con el enlace del nuevo intervalo, y luego se cierra el alcance creado, que cierra el intervalo creado y devuelve el alcance anterior al estado activo. Scope está vinculado a una secuencia, por lo tanto, cuando la programación de subprocesos múltiples, no debe olvidar transferir el intervalo activo a otra secuencia, para una mayor activación del alcance de otra secuencia con referencia a este intervalo.
io.opentracing.Tracer tracer = ...;
Para la programación de subprocesos múltiples, también hay un TracedExecutorService y envoltorios similares que reenvían automáticamente el intervalo actual a la secuencia al iniciar tareas asincrónicamente:
private ExecutorService executor = new TracedExecutorService( Executors.newFixedThreadPool(10), GlobalTracer.get() );
Para solicitudes http externas, hay
TracingHttpClient HttpClient httpClient = new TracingHttpClientBuilder().build();
Los problemas que enfrentamos
- Beans y DI no siempre funcionan si el trazador no se usa en un servicio o componente, entonces Autowired Tracer puede no funcionar y tendrá que usar GlobalTracer.get ().
- Las anotaciones no funcionan si no es un componente o servicio, o si una llamada a un método proviene de un método vecino de la misma clase. Debe tener cuidado, verificar qué funciona y usar la creación manual de la traza si @Traced no funciona. También puede atornillar un compilador adicional para las anotaciones de Java, luego deberían funcionar en todas partes.
- En la antigua primavera y el arranque de la primavera, la configuración automática de la nube de primavera opentraing no funciona debido a errores en DI, entonces si desea que los rastros en los componentes de la primavera funcionen automáticamente, puede hacerlo por analogía con github.com/opentracing-contrib/java-spring-jaeger/blob/ master / opentracing-spring-jaeger-starter / src / main / java / io / opentracing / contrib / java / spring / jaeger / starter / JaegerAutoConfiguration.java
- Probar con recursos no funciona en groovy, debes usar try finalmente.
- Cada servicio debe tener su propio spring.application.name con el que se registrarán las trazas. ¿Qué significa un nombre separado para la venta y la prueba, para no interferir con ellos juntos?
- Si usa GlobalTracer y tomcat, entonces todos los servicios que se ejecutan en este tomcat tienen un GlobalTracer, por lo que todos tendrán el mismo nombre de servicio.
- Al agregar rastreos a un método, debe asegurarse de que no se invoque muchas veces en el ciclo. Es necesario agregar un seguimiento común para todas las llamadas, lo que garantiza el tiempo total de trabajo. De lo contrario, se creará un exceso de carga.
- Una vez en Jaeger-ui, hicieron pedidos demasiado grandes para una gran cantidad de rastros y, como no esperaron una respuesta, lo hicieron nuevamente. Como resultado, Jaeger-query comenzó a comer mucha memoria y a ralentizar el elástico. Ayudó a reiniciar jaeger-query
Muestreo, almacenamiento y visualización de trazas.
Hay tres tipos de
muestreo de
trazas :
- Const que envía y guarda todos los rastros.
- Probabilístico que filtra los rastros con alguna probabilidad dada.
- Ratelimitación que limita el número de trazas por segundo. Puede configurar estas opciones en el cliente, ya sea en el agente jaeger o en el recopilador. Ahora tenemos const 1 en la pila de evaluadores, ya que no hay muchas solicitudes, pero toman mucho tiempo. En el futuro, si esto ejercerá una carga excesiva en el sistema, puede limitarlo.
Si usa cassandra, por defecto almacena rastros en solo dos días. Utilizamos
elasticsearch y los rastros se almacenan todo el tiempo y no se eliminan. Se crea un índice separado para cada día, por ejemplo, jaeger-service-2019-03-04. En el futuro, debe configurar la limpieza automática de trazas antiguas.
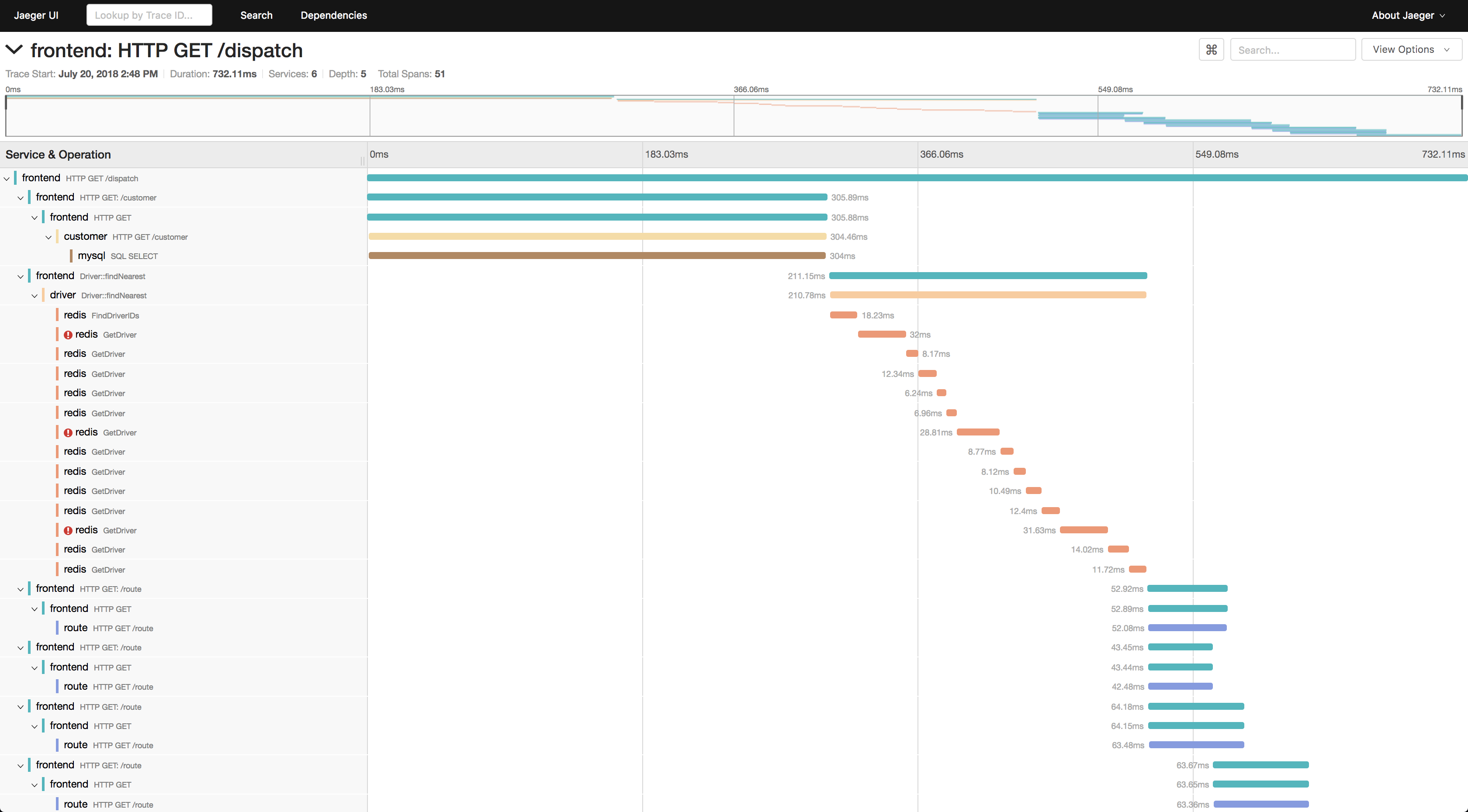
Para ver los cursos que necesitas:
- Elija un servicio por el que desee filtrar las trazas, por ejemplo, tomcat7-default para un servicio que se ejecuta en un tomate y no puede tener un nombre.
- A continuación, seleccione la operación, el intervalo de tiempo y el tiempo mínimo de operación, por ejemplo, de 10 segundos, para tomar solo carreras largas.
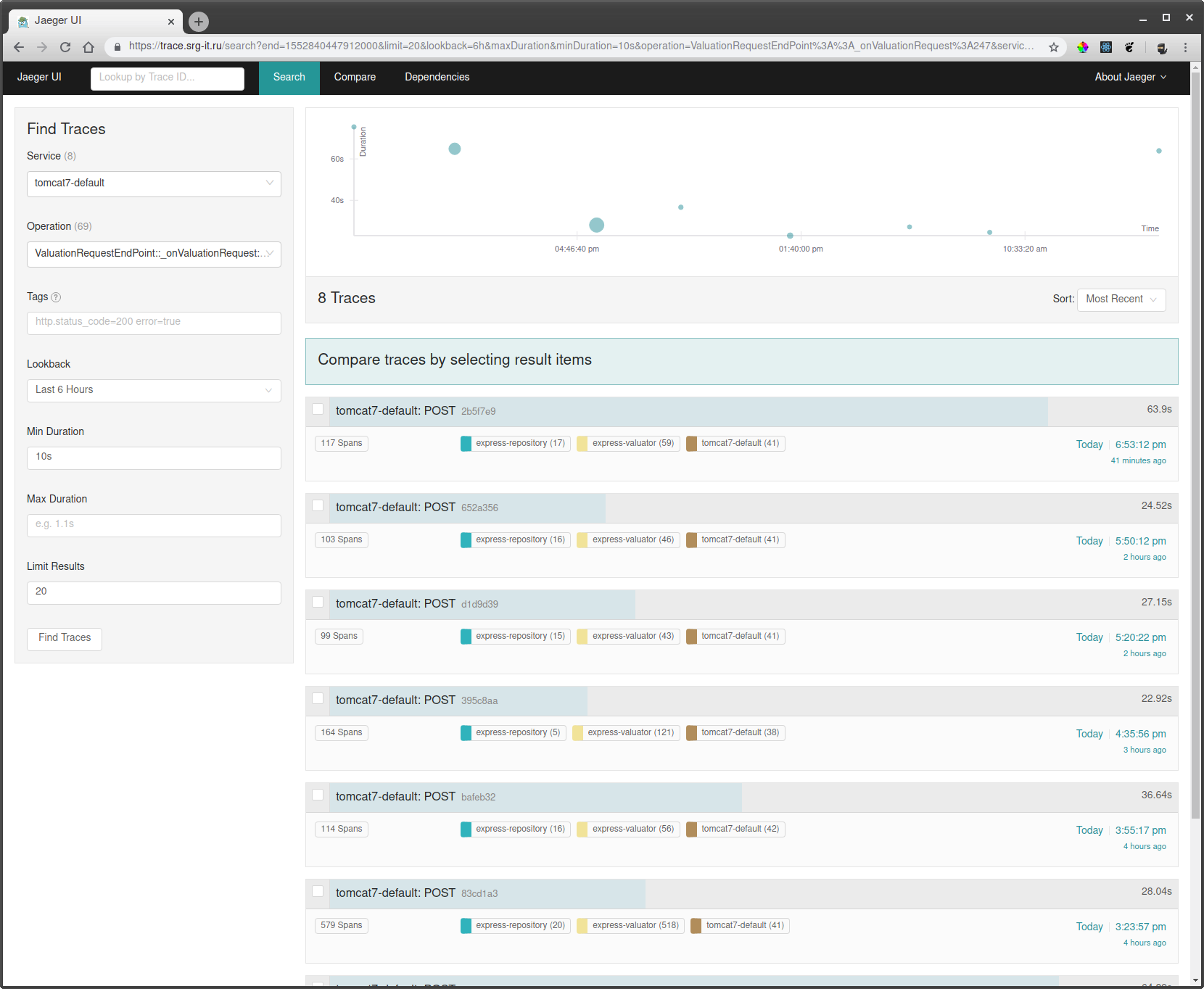
- Vaya a una de las pistas y vea qué estaba disminuyendo allí.

Además, si se conoce un id de solicitud, puede encontrar un seguimiento de este id a través de una búsqueda de etiquetas, si este id se registra en el intervalo de seguimiento.
La documentación
Artículos
Video