
Hola a todos! Con este artículo, AERODISK abre un blog sobre Habré. ¡Hurra, camaradas!
En artículos anteriores sobre Habr, se consideraron preguntas sobre la arquitectura y la configuración básica de los sistemas de almacenamiento. En este artículo, consideraremos una pregunta que no se cubrió anteriormente, pero que a menudo se hizo, sobre la tolerancia a fallas de los sistemas de almacenamiento AERODISK ENGINE. Nuestro equipo hará todo lo posible para que el sistema de almacenamiento AERODISK deje de funcionar, es decir rompiéndola
Dio la casualidad de que los artículos sobre la historia de nuestra empresa, sobre nuestros productos, así como un ejemplo de implementación exitosa, ya están pendientes de Habré, por lo que muchas gracias a nuestros socios: TS Solution y las compañías Softline.
Por lo tanto, no entrenaré las habilidades de gestión de copiar y pegar aquí, sino simplemente dar enlaces a los originales de estos artículos:
También quiero compartir las buenas noticias. Pero comenzaré, por supuesto, con el problema. Nosotros, como proveedores jóvenes, entre otros costos, enfrentamos constantemente el hecho de que muchos ingenieros y administradores son cursi y no saben cómo operar adecuadamente nuestros sistemas de almacenamiento.
Está claro que la administración de la mayoría de los sistemas de almacenamiento se ve aproximadamente igual desde el punto de vista del administrador, pero cada fabricante tiene sus propias características. Y no somos la excepción.
Por lo tanto, para simplificar la tarea de capacitar a profesionales de TI, decidimos dedicar este año a la educación gratuita. Para hacer esto, en muchas grandes ciudades de Rusia, estamos abriendo una red de Centros de Competencia AERODISK en los cuales cualquier especialista técnico interesado podrá tomar un curso de forma totalmente gratuita y recibir un certificado de administración de almacenamiento de AERODISK ENGINE.
En cada Centro de Competencias, instalaremos un soporte de demostración completo desde el sistema de almacenamiento AERODISK y un servidor físico en el que nuestro maestro llevará a cabo una capacitación a tiempo completo. El calendario de trabajo de los Centros de Competencia se publicará cuando aparezcan, pero ahora hemos abierto un centro en Nizhny Novgorod y la ciudad de Krasnodar es la siguiente en la fila. Puede inscribirse en la capacitación utilizando los enlaces a continuación. Traigo la información actualmente conocida sobre ciudades y fechas:
- Nizhny Novgorod (YA FUNCIONA: puede registrarse aquí https://aerodisk.promo/nn/ );
Hasta el 16 de abril de 2019, puede visitar el centro en cualquier horario de trabajo, y el 16 de abril de 2019 se organizará un gran curso de capacitación. - Krasnodar (PRÓXIMAMENTE - regístrese aquí https://aerodisk.promo/krsnd/ );
Del 9 al 25 de abril de 2019 puede visitar el centro en cualquier horario de trabajo, y el 25 de abril de 2019 se organizará un gran curso de capacitación. - Ekaterimburgo (APERTURA PRONTO, siga la información en nuestro sitio web o en Habré);
Mayo-junio de 2019. - Novosibirsk (siga la información en nuestro sitio web o en Habré);
Octubre 2019 - Krasnoyarsk (siga la información en nuestro sitio web o en Habré);
Noviembre 2019
Y, por supuesto, si Moscú no está lejos de usted, puede visitar nuestra oficina en Moscú en cualquier momento y recibir una capacitación similar.
Eso es todo. Atado al marketing, ¡ve a la técnica!
En Habré publicaremos periódicamente artículos técnicos sobre nuestros productos, pruebas de estrés, comparaciones, características de uso e implementaciones interesantes.
AERODISK ENGINE N2 Pruebas de choque de almacenamiento, prueba de resistencia
ACHTUNG! Después de leer el artículo, puede decir: bueno, por supuesto, el vendedor se revisará a sí mismo para que todo salga "bien", las condiciones del invernadero, etc. Contestaré: ¡nada por el estilo! A diferencia de nuestros competidores extranjeros, estamos aquí, cerca de usted, y siempre puede venir a nosotros (en Moscú o en cualquier Comité Central) y probar nuestro sistema de almacenamiento de cualquier manera. Por lo tanto, no tiene mucho sentido ajustar los resultados a la imagen ideal del mundo, porque Somos muy fáciles de verificar. Para aquellos que son demasiado flojos para caminar y que no tienen tiempo, podemos organizar pruebas remotas. Tenemos un laboratorio especial para esto. Contacto
ACHTUNG-2! Esta prueba no es una prueba de carga porque aquí solo nos preocupa la tolerancia a fallas. En un par de semanas, prepararemos un stand más potente y realizaremos pruebas de carga de los sistemas de almacenamiento, publicando los resultados aquí (por cierto, se aceptan los deseos de pruebas).
Entonces, vamos a descansar.
Banco de pruebas
Nuestro stand consiste en el siguiente hierro:
- 1 x almacenamiento Aerodisk Engine N2 (2 controladores, 64 GB de caché, 8xFC puertos 8Gb / s, 4x puertos Ethernet 10Gb / s SFP +, 4x puertos Ethernet 1Gb / s); Los siguientes discos están instalados en el sistema de almacenamiento:
- 4 x disco SSD SAS de 900 GB;
- 12 x unidades SAS 10k de 1,2 TB;
- 1 x servidor físico con Windows Server 2016 (2xXeon E5 2667 v3, 96GB RAM, 2xFC puertos 8Gb / s, 2x puertos Ethernet 10Gb / s SFP +);
- 2 x conmutador SAN 8G;
- 2 x conmutador LAN 10G;
Conectamos el servidor al almacenamiento mediante conmutadores a través de FC y Ethernet 10G. Esquema del stand a continuación.
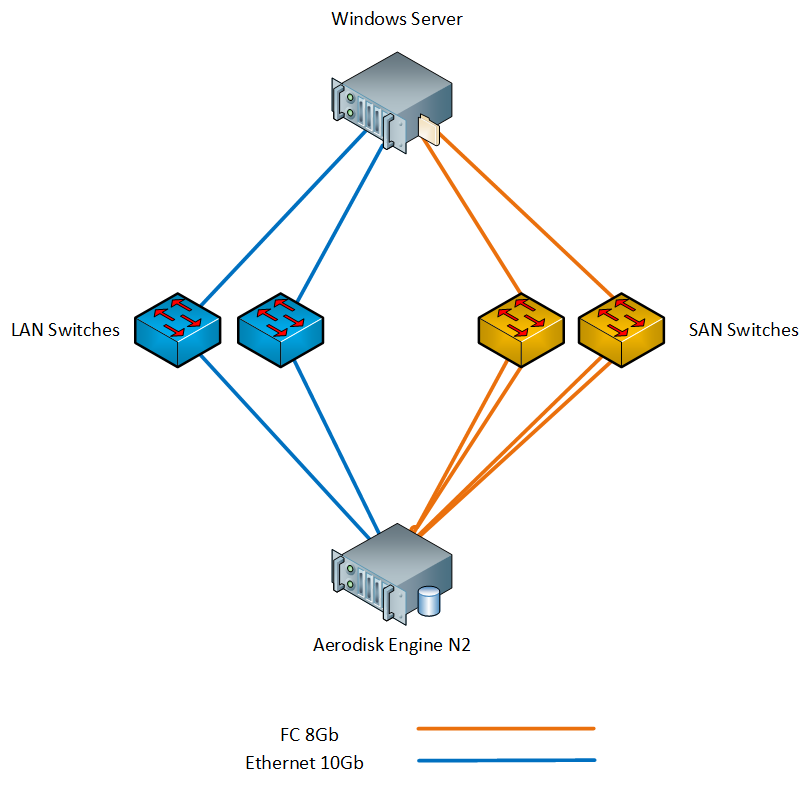
Los componentes necesarios, como MPIO e iniciador iSCSI, están instalados en Windows Server.
Las zonas se configuran en los conmutadores FC, las VLAN correspondientes se configuran en los conmutadores LAN y MTU 9000 se instala en los puertos de almacenamiento, los conmutadores y el host (cómo hacer todo esto se describe en nuestra documentación, por lo que no describiremos este proceso aquí).
Metodología de prueba
El plan de prueba de choque es el siguiente:
- Verificación de falla del puerto FC y Ethernet.
- Verificación de falla de energía.
- Comprobando la falla del controlador.
- Verifique la falla del disco en un grupo / grupo.
Todas las pruebas se realizarán en condiciones de carga sintética, que generaremos con IOMETER. Paralelamente, realizaremos las mismas pruebas, pero en condiciones de copiar archivos grandes al sistema de almacenamiento.
La configuración de IOmeter es la siguiente:
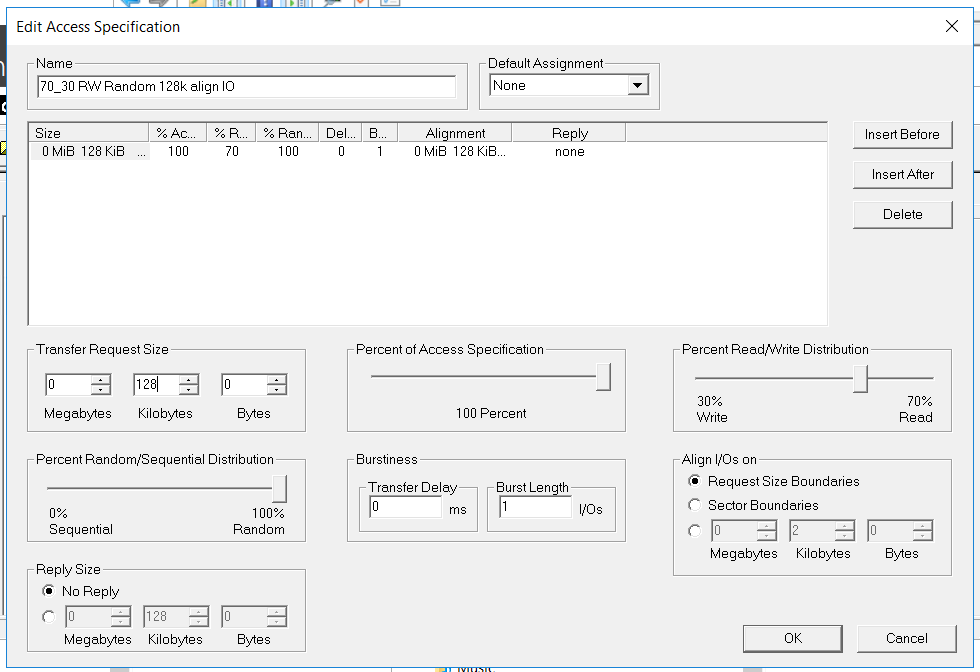
- Lectura / Escritura - 70/30
- Bloque: 128k (decidimos mojar el sistema de almacenamiento con bloques grandes)
- El número de subprocesos es 128 (que es muy similar a la carga de trabajo)
- Al azar completo
- Número de trabajadores: 4 (2 para FC, 2 para iSCSI)
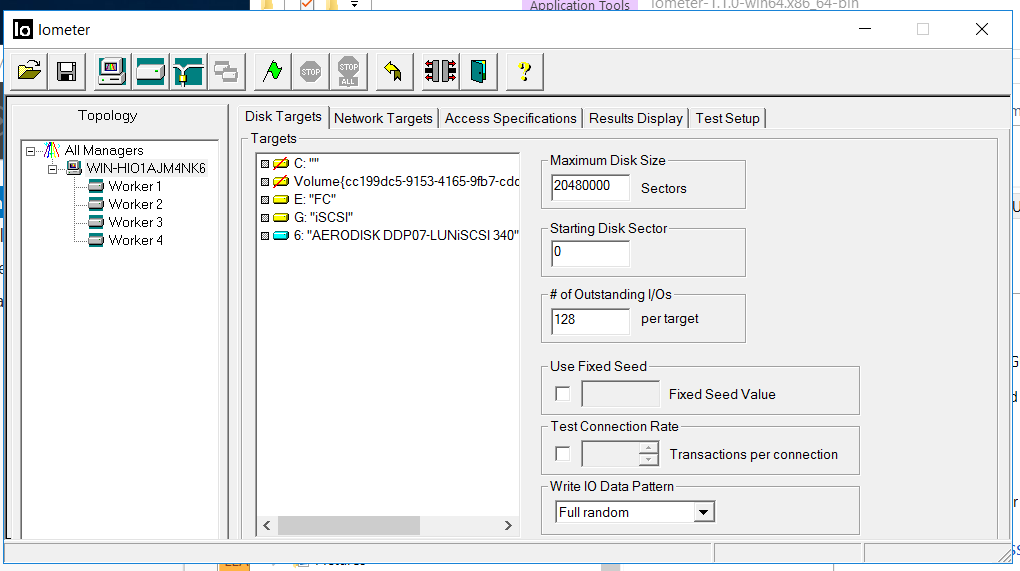
 La prueba tiene las siguientes tareas:
La prueba tiene las siguientes tareas:- Asegúrese de que la carga sintética y el proceso de copia no se interrumpan y no causen errores con varios modos de falla.
- Asegúrese de que el proceso de conmutación de puertos, controladores, etc., esté suficientemente automatizado y no requiera acciones del administrador en caso de fallas (es decir, con la conmutación por error, por supuesto, no se habla de fallas).
- Asegúrese de que la información se muestre correctamente en los registros.
Host y preparación de almacenamiento
Configuramos el acceso de bloque en el almacenamiento utilizando los puertos FC y Ethernet (FC e iSCSI, respectivamente). Cómo hacer esto, los chicos de TS Solution describieron en detalle en un artículo anterior ( https://habr.com/en/company/tssolution/blog/432876/ ). Bueno y, por supuesto, nadie canceló manuales y cursos.
Configuramos un grupo híbrido utilizando todas las unidades que tenemos. Se agregan 2 discos SSD a la memoria caché, se agregan 2 discos SSD como nivel de almacenamiento adicional (nivel en línea). Agrupamos 12 discos SAS10k en RAID-60P (triple paridad) para verificar la falla de tres discos en un grupo a la vez. Se dejó un disco para Autocorrección.
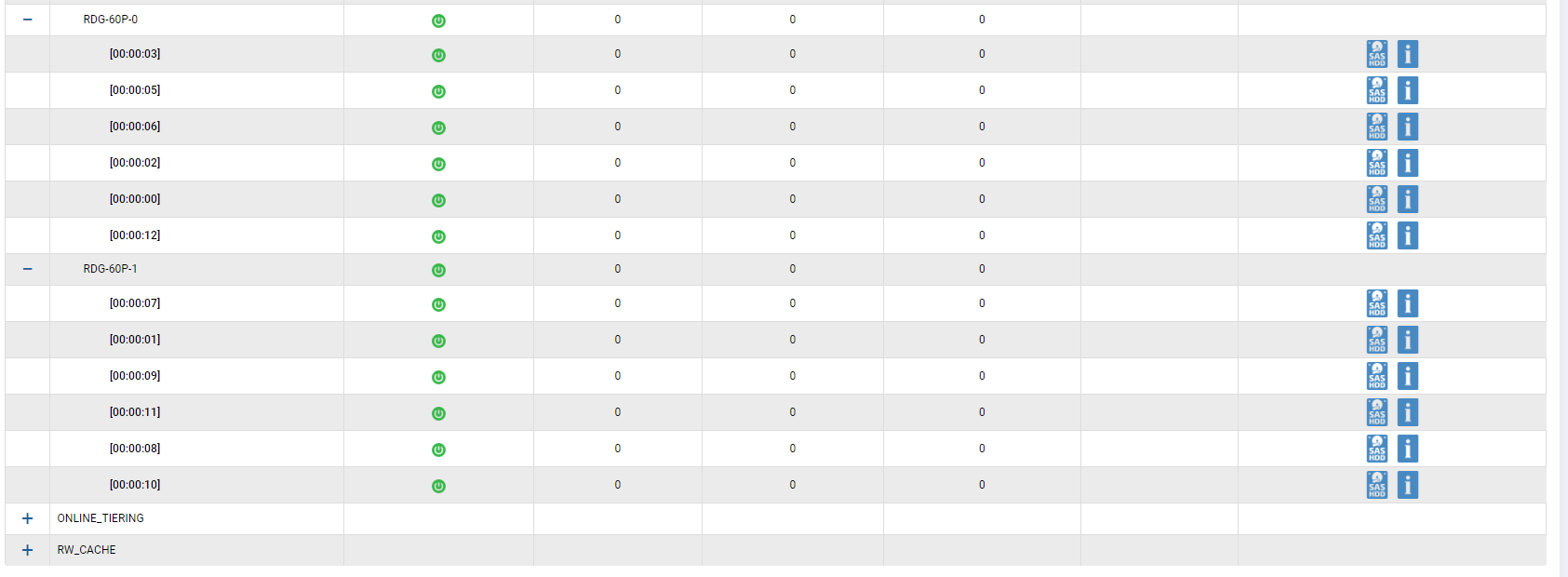
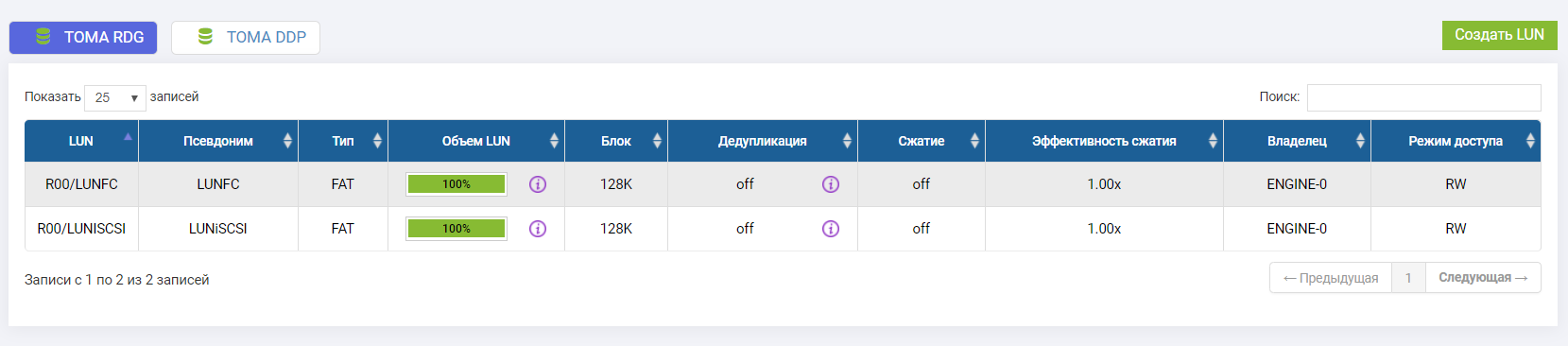
Conectamos dos LUN (uno en FC, uno en iSCSI).
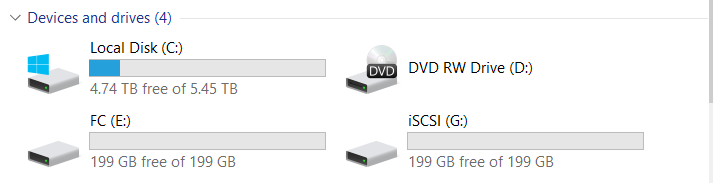
Ambos LUN son propiedad del controlador Engine-0.
Comience la prueba
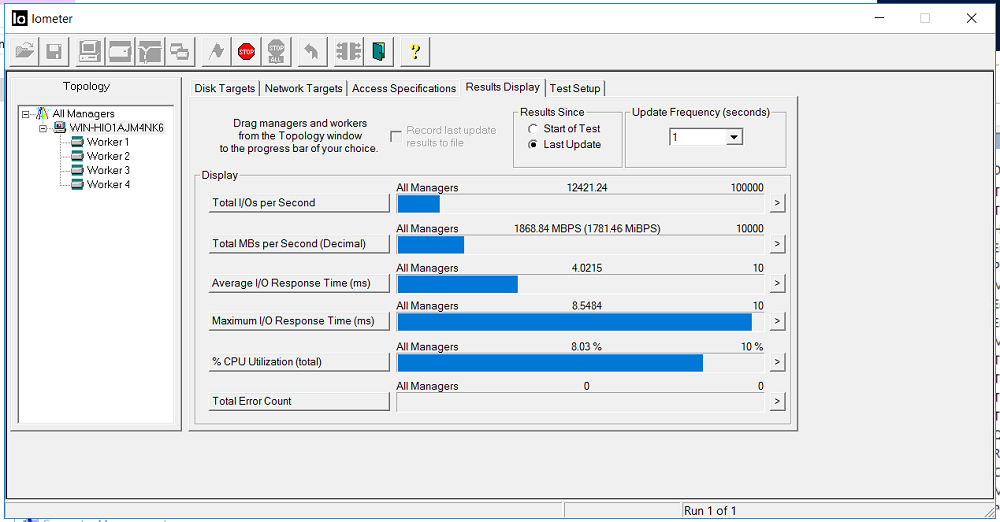
Encienda IOMETER con la configuración anterior.
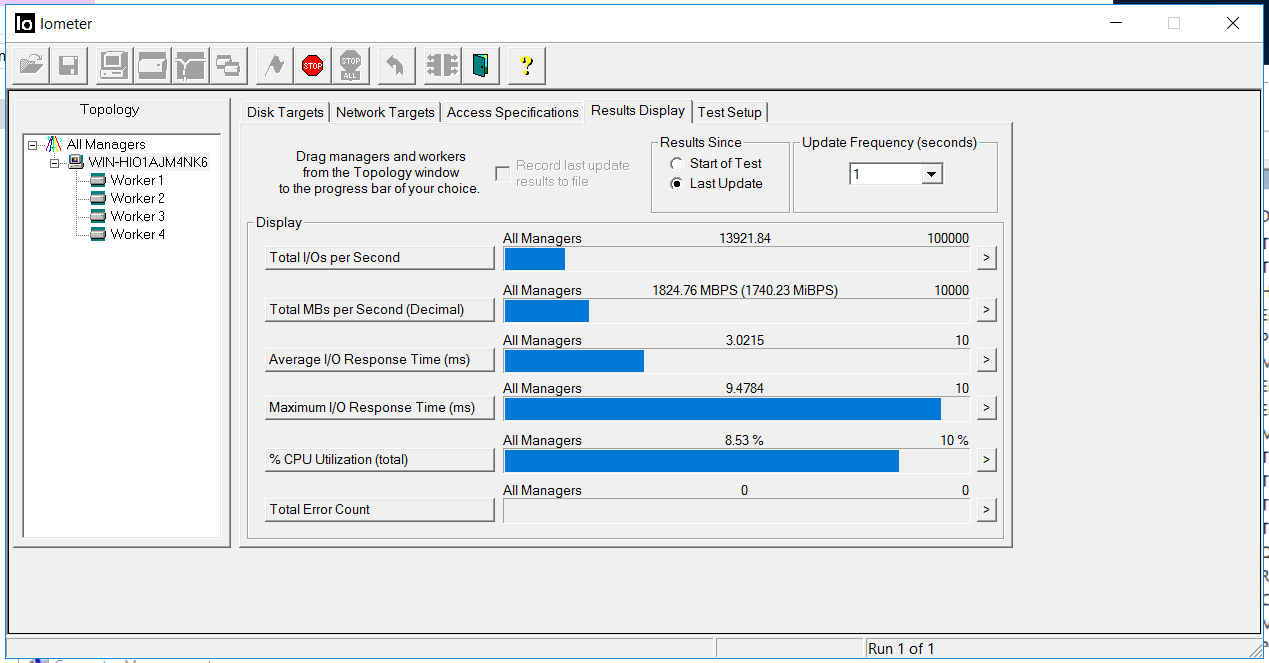
Arreglamos el ancho de banda de 1.8 GB / sy un retraso de 3 milisegundos. No hay errores (recuento total de errores).
Al mismo tiempo, desde la unidad local "C" de nuestro host, simultáneamente comenzamos a copiar dos archivos grandes de 100 GB a los LUN FC e iSCSI del sistema de almacenamiento (discos E y G en Windows) utilizando otras interfaces.
Arriba está el proceso de copia a LUN FC, abajo está iSCSI.

Prueba No. 1. Desactivación de puertos de E / S
Nos acercamos a la parte posterior del sistema de almacenamiento))) y con un simple movimiento de muñeca sacamos todos los cables FC y Ethernet 10G del controlador Engine-0. Como si una señora de la limpieza con un trapeador pasara y decidiera lavar el piso justo donde mocos mentir los cables estaban tendidos (es decir, el controlador sigue funcionando, pero los puertos de E / S están muertos).

Nos fijamos en IOMETER y copia de archivos. El ancho de banda se redujo a 0.5 GB / s, pero rápidamente volvió a su nivel anterior (en aproximadamente 4-5 segundos). No hay errores
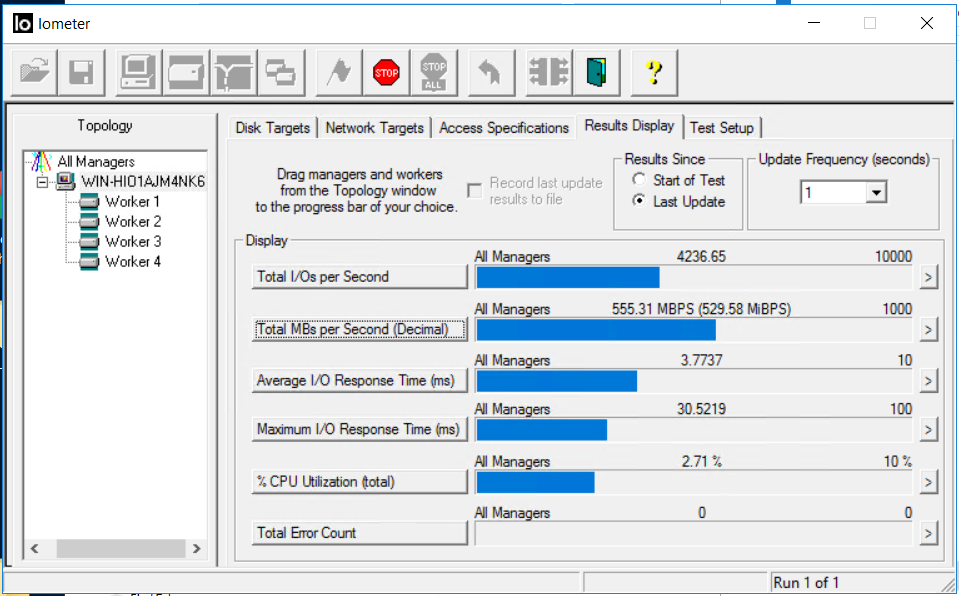
La copia de archivos no se detuvo, hay una reducción en la velocidad, pero no es crítica (de 840 MB / s se redujo a 720 MB / s). La copia no se detuvo.
Buscamos en los registros del sistema de almacenamiento y vemos un mensaje sobre la falta de disponibilidad de puertos y el movimiento automático del grupo.

Además, el tablero de instrumentos nos dice que no todo es muy bueno con los puertos FC.
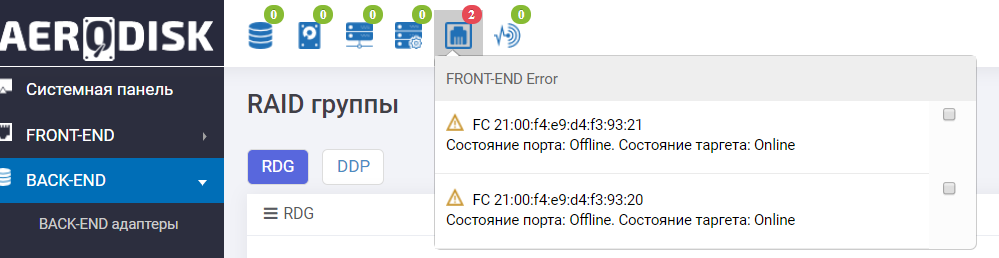
Los puertos de E / S de almacenamiento fallaron correctamente.
Prueba número 2. Deshabilitar el controlador de almacenamiento
Casi de inmediato (después de volver a enchufar los cables al sistema de almacenamiento), decidimos terminar el almacenamiento retirando el controlador del chasis.
Nuevamente, nos acercamos al sistema de almacenamiento desde atrás (nos gustó))) y esta vez sacamos el controlador Engine-1, que en este momento es el propietario de RDG (al cual el grupo se mudó).
La situación en IOmeter es la siguiente. La salida de entrada se detuvo durante unos 5 segundos. Los errores no se acumulan.
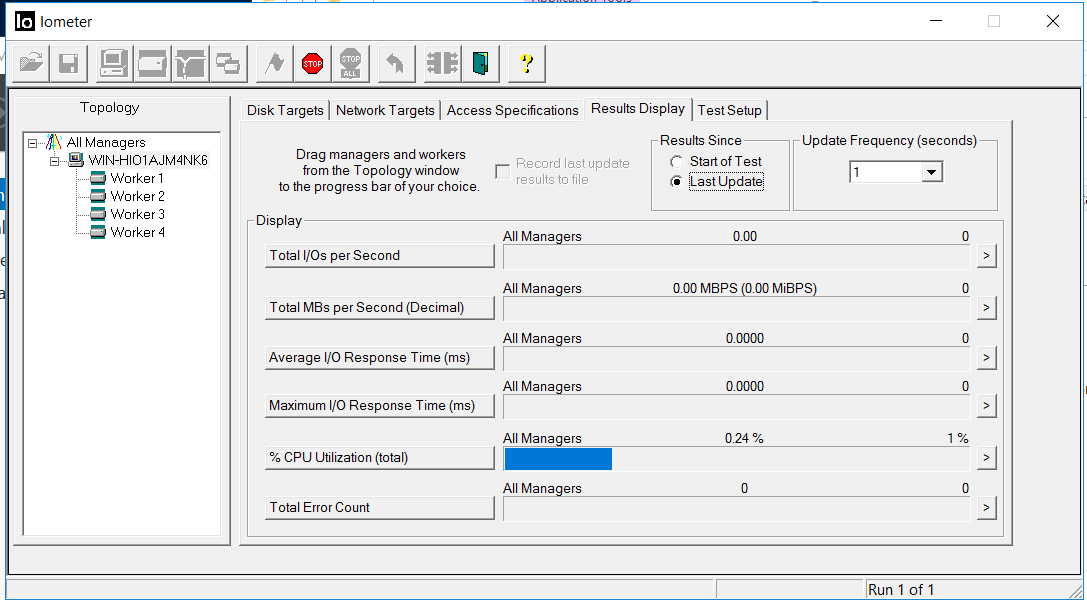
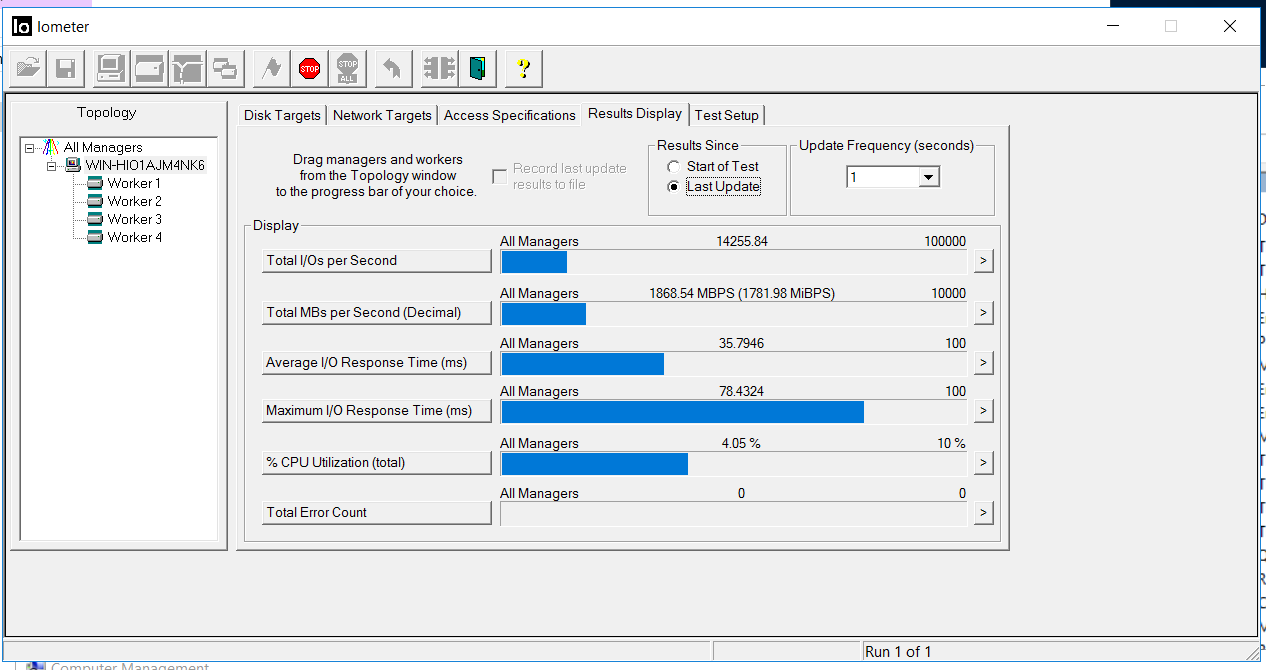
Después de 5 segundos, se reanudó la E / S, con aproximadamente las mismas tasas de rendimiento, pero con demoras de 35 milisegundos (las demoras se corrigieron después de unos minutos). Como se puede ver en las capturas de pantalla, el valor del recuento total de errores es 0, es decir, no hubo errores de escritura o lectura.
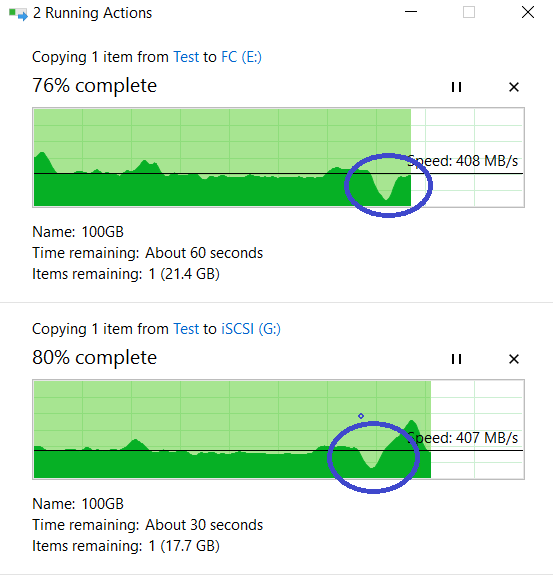
Buscamos copiar nuestros archivos. Como puede ver, no se interrumpió, hubo una pequeña reducción en el rendimiento, pero en general, todo volvió a los mismos ~ 800 MB / s.
Vamos al sistema de almacenamiento y vemos abuso en el panel de información de que el controlador Engine-1 no está disponible (por supuesto, lo golpeamos).
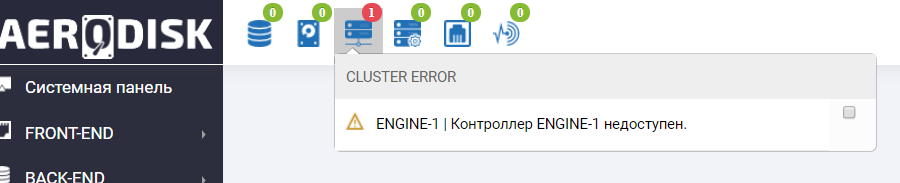
También vemos una entrada similar en los registros.

La falla del controlador de almacenamiento también ha sobrevivido con éxito.
Prueba número 3. Desconexión de la fuente de alimentación.
Por si acaso, comenzamos a copiar los archivos nuevamente, pero IOMETER no se detuvo.
Tiramos del BP-Schnick.

Se agregó otra alerta al almacenamiento en el panel de información.

También vemos en el menú de sensores que los sensores asociados con la fuente de alimentación extraída se vuelven rojos.

SHD continúa trabajando. La falla de BP-Schnick no afecta el funcionamiento del sistema de almacenamiento de ninguna manera, desde el punto de vista del host, la velocidad de copia y los indicadores IOMETER permanecieron sin cambios.
Prueba de falla de energía completada con éxito.
Antes de la prueba final, decidimos revivir un poco el SHD, volver a poner el controlador y el BP-shnik, y también poner las cosas en orden con los cables, que el SHD nos informó felizmente con iconos verdes en su panel de salud.

Prueba número 4. Fallo de tres discos en el grupo
Antes de esta prueba, realizamos un paso preparatorio adicional. El hecho es que el almacenamiento ENGINE proporciona algo muy útil: diferentes políticas de reconstrucción (reconstrucción). Anteriormente, TS Solution escribió sobre esta característica, pero recuerda su esencia. El administrador de almacenamiento puede especificar la prioridad de la asignación de recursos durante la reconstrucción. O en la dirección del rendimiento de E / S, es decir, una reconstrucción más larga, pero no hay reducción de rendimiento. O en la dirección de la velocidad de reconstrucción, pero el rendimiento se verá reducido. O una opción equilibrada. Dado que el rendimiento del almacenamiento durante la reconstrucción de un grupo de discos es siempre un dolor de cabeza para el administrador, probaremos la política con un sesgo hacia el rendimiento de E / S y en detrimento de la velocidad de la reconstrucción.

Ahora verifique el fallo de las unidades. También habilitamos la grabación en LUN (archivos e IOMETER). Dado que tenemos un grupo de triple paridad (RAID-60P), significa que el sistema debe soportar la falla de tres discos, y después de la falla debe funcionar el reemplazo automático, un disco debe estar en el RDG en lugar de uno de los fallidos, y la reconstrucción debe comenzar en él.
Nosotros comenzamos Primero, a través de la interfaz de almacenamiento, resalte los discos que queremos extraer (para no perder y no extraer el disco de reemplazo automático).

Verifique la indicación en la plancha. Todo está bien, vemos las tres unidades resaltadas.

Y saca estos tres discos.

Nos fijamos en el anfitrión. Y allí ... no pasó nada especial.
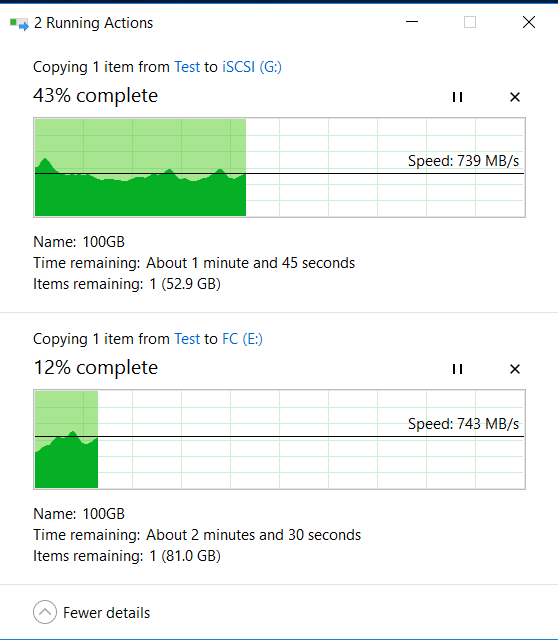
Las tasas de copia (son más altas que al principio, porque el caché se calentó) y el IOMETER no cambian mucho al extraer discos e iniciar la reconstrucción (dentro del 5-10%).
Nos fijamos en el almacenamiento.
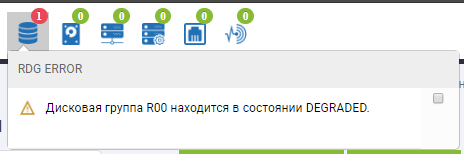
En el estado del grupo, vemos que el proceso de reconstrucción ha comenzado y está a punto de completarse.

El esqueleto RDG muestra que 2 discos están en estado rojo y uno ya ha sido reemplazado. El disco de Autocorrección ya no está allí, reemplazó el tercer disco fallido. Rebild se ejecutó durante varios minutos, la grabación de archivos no se interrumpió cuando fallaron 3 discos, el rendimiento de E / S no cambió mucho.
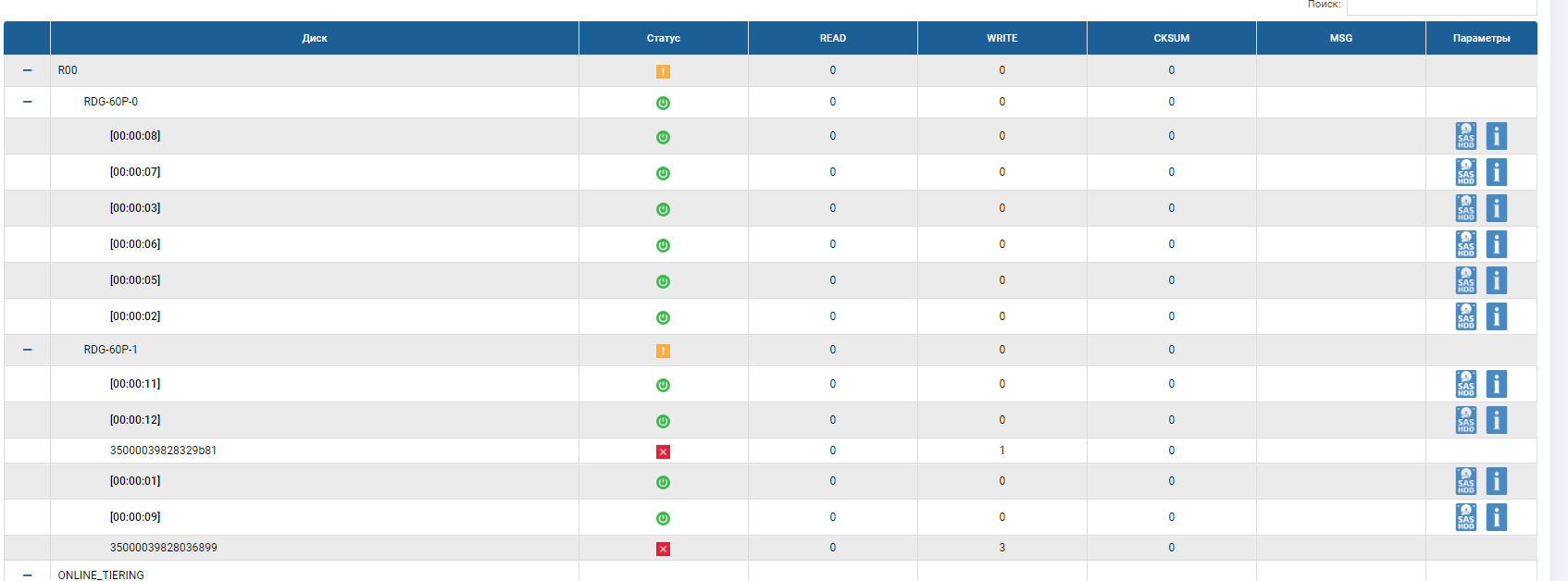
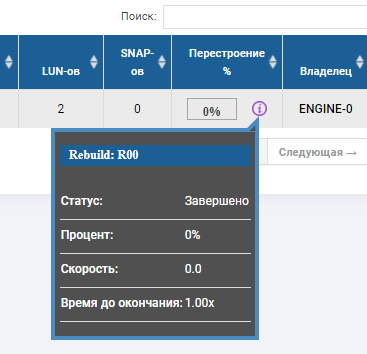
La prueba de falla del disco definitivamente ha sido exitosa.
Conclusión
Sobre esto, decidimos detener el abuso de los sistemas de almacenamiento. Para resumir:
- Verificación de falla de puerto FC - Exitosa
- Verificación de falla del puerto Ethernet - Exitosa
- Verificación de falla del controlador - exitosa
- Verificación de falla de energía: exitosa
- Verifique la falla del disco en el grupo \ pool - con éxito
Ninguna de las fallas detuvo la grabación y no causó errores de carga sintética, la reducción de rendimiento, por supuesto, fue (y sabemos cómo vencer esto, lo que haremos pronto), pero, dado que esto es segundos, es bastante aceptable. Conclusión: la tolerancia a fallas de todos los componentes de almacenamiento de AERODISK funcionó a nivel, no hay puntos de falla.
Obviamente, en el marco de un artículo, no podemos probar todos los escenarios de falla, pero tratamos de cubrir los más populares. Por lo tanto, envíe sus comentarios, deseos para las siguientes publicaciones y, por supuesto, críticas adecuadas. Estaremos encantados de debatir (y mejor asistir a la capacitación, por si acaso, duplicar el horario). Hasta nuevas pruebas!
- Nizhny Novgorod (YA FUNCIONA: puede registrarse aquí https://aerodisk.promo/nn/ );
Hasta el 16 de abril de 2019, puede visitar el centro en cualquier horario de trabajo, y el 16 de abril de 2019 se organizará un gran curso de capacitación. - Krasnodar (PRÓXIMAMENTE - regístrese aquí https://aerodisk.promo/krsnd/ );
Del 9 al 25 de abril de 2019 puede visitar el centro en cualquier horario de trabajo, y el 25 de abril de 2019 se organizará un gran curso de capacitación. - Ekaterimburgo (APERTURA PRONTO, siga la información en nuestro sitio web o en Habré);
Mayo-junio de 2019. - Novosibirsk (siga la información en nuestro sitio web o en Habré);
Octubre 2019 - Krasnoyarsk (siga la información en nuestro sitio web o en Habré);
Noviembre 2019