Acumular deudas técnicas puede llevar a su empresa a una crisis. Pero también puede convertirse en un poderoso impulsor de cambios masivos de procesos y ayudar con la adopción de prácticas de ingeniería. Te lo contaré en mi propio ejemplo.
 El equipo de TI de Dodo Pizza
El equipo de TI de Dodo Pizza creció de 2 desarrolladores que sirven a un país a 60 personas que atienden a 12 países en el transcurso de 7 años. Como Scrum Master y XP Coach, ayudé a los equipos a establecer procesos y adoptar prácticas de ingeniería, pero esta adopción fue demasiado lenta. Para mí fue un desafío hacer que los equipos mantuvieran una alta calidad de código cuando varios equipos trabajan en un solo producto. Caímos en la trampa de la preferencia por las características comerciales sobre la excelencia técnica y acumulamos demasiadas deudas técnicas arquitectónicas. Cuando el marketing lanzó una campaña publicitaria masiva en 2018, no pudimos soportar la carga y caímos. Fue una pena. Pero durante la crisis, nos dimos cuenta de que podemos trabajar muchas veces de manera más eficiente. La crisis nos ha empujado hacia cambios revolucionarios en los procesos y la rápida introducción de las prácticas de ingeniería más conocidas.
Antecedentes
Puede pensar que Dodo Pizza es una red de pizzerías normal. Pero en realidad
Dodo Pizza es una compañía de TI que vende pizza . Nuestro negocio se basa en
Dodo IS , una plataforma basada en la nube, que gestiona todos los procesos comerciales, comenzando desde la toma del pedido, luego cocinando y terminando hasta la gestión de inventario, la gestión de personas y la toma de decisiones. En solo 7 años hemos crecido de 2 desarrolladores que sirven a una sola pizzería a más de 70 desarrolladores que sirven a 470+ pizzerías en 12 países.
Cuando me uní a la compañía hace dos años, teníamos 6 equipos y unos 30 desarrolladores. La base de código Dodo IS tenía aproximadamente 1 millón de líneas de código. Tenía una arquitectura monolítica y muy poca cobertura de pruebas unitarias. No teníamos pruebas de API / UI para entonces. La calidad del código del sistema fue decepcionante. Lo sabíamos y soñamos con un futuro brillante cuando dividimos el monolito en una docena de servicios y reescribimos las partes más horribles del sistema. Incluso dibujamos el diagrama de "ser arquitectura", pero honestamente no hicimos casi nada hacia el estado futuro.
Mi objetivo principal era enseñar a los desarrolladores prácticas de ingeniería y construir un proceso de desarrollo, haciendo que 6 equipos trabajen en un solo producto .
A medida que el equipo creció, sufrimos la falta de procesos claros y prácticas de ingeniería más. Nuestros lanzamientos se hicieron más grandes y más largos porque cada vez más desarrolladores contribuyeron al sistema, pero no teníamos pruebas de regresión automatizadas y, por lo tanto, perdimos más tiempo en la regresión manual con cada lanzamiento. Sufrimos muchos cambios realizados por 6 equipos en sucursales separadas. Cuando un equipo fusionó sus cambios en una sola rama antes del lanzamiento, a veces solíamos perder hasta 4 horas resolviendo conflictos de fusión.
Mierda pasa
En 2018, Marketing lanzó nuestra primera campaña publicitaria federal en televisión . Fue un gran evento para nosotros. Gastamos 100 millones de rublos ($ 1.5 millones) financiando la campaña, una cantidad bastante significativa para nosotros. El equipo de TI también se preparó para la campaña. Automatizamos y simplificamos nuestra implementación: ahora con un solo botón en TeamCity podríamos implementar el monolito en 12 países. Investigamos pruebas de rendimiento y realizamos análisis de vulnerabilidad. Hicimos nuestro mejor esfuerzo pero encontramos problemas inesperados.
La campaña publicitaria fue excelente. Pasamos de 100 a 300 pedidos / minuto. Esta fue una buena noticia. La mala noticia es que Dodo IS no pudo soportar tal carga y murió. Alcanzamos nuestros límites de escala vertical y ya no podíamos manejar pedidos. El sistema se reinicia cada 3 horas. Cada minuto de tiempo de inactividad nos cuesta millones de dinero, así como la pérdida de respeto de los clientes furiosos.
Cuando llegué a Dodo hace 2 años como Chief Agile Officer, tenía un gran deseo de hacer de nuestro pequeño equipo, unas 12 personas, un equipo de ensueño. Inmediatamente comencé a introducir prácticas de ingeniería. La mayoría de los equipos adoptaron programación de pares, pruebas de unidades y DDD muy pronto. Pero no todo fue fácil. Tuve que superar la resistencia de los desarrolladores, el propietario del producto y el equipo de soporte.
A diferencia de las prácticas de ingeniería, no todos favorecían la idea de equipos de características. Los desarrolladores estaban acostumbrados a pensar que un equipo centrado en un componente está escribiendo un mejor código. No estaba claro cómo combinar el rápido desarrollo de las características comerciales con la refactorización masiva de un sistema complejo. Un flujo continuo de errores también requiere atención constante. El equipo de soporte estuvo a favor de tener su propio equipo enfocado únicamente en la corrección de errores. Muchos equipos estaban acostumbrados a trabajar en sucursales separadas y tenían miedo de integrarse con frecuencia. Lanzamos no más de una vez por semana, y cada lanzamiento tomó bastante tiempo, requirió una gran cantidad de regresión manual y soporte de pruebas de IU. Traté de arreglarlo, pero los cambios en mi proceso fueron demasiado lentos y fragmentados.
La historia de caída y ascenso
Estado inicial: arquitectura monolítica
En pos de la velocidad de desarrollo de las características comerciales, no siempre hemos pensado bien en las soluciones técnicas. La falta de experiencia también nos afectó. Al principio, la compañía no podía permitirse contratar a los mejores desarrolladores. Trabajamos con entusiastas que aceptaron ayudar con la creación de Dodo IS, creyeron en el fundador de la compañía, Fedor, y trabajaron casi por comida (pizza, por supuesto). Los desarrolladores que se unieron al equipo luego siguieron la arquitectura establecida, que quedó obsoleta. Así que teníamos una aplicación monolítica con una sola base de datos, que contenía todos los datos de todos los componentes en un solo lugar. Rastreador, pago, sitio, API para páginas de destino: todos los componentes del sistema funcionaron con una sola base de datos, que se convirtió en un cuello de botella. Nuestra arquitectura monolítica creó problemas monolíticos. Una sola publicación en el blog provocó la interrupción del pago de un restaurante.
Historia verdadera
Para ilustrar cuán frágil es la arquitectura monolítica, daré solo un ejemplo. Una vez que todos nuestros restaurantes en Rusia dejaron de aceptar pedidos debido a una publicación de blog. ¿Cómo puede pasar esto?
Un día, nuestro CEO, Fedor, publicó una publicación en su blog. Esta publicación ganó popularidad rápidamente. Hay un mostrador en el sitio web del blog de Fedor que muestra una serie de pizzerías en nuestra cadena y los ingresos totales de todas las pizzerías. Cada vez que alguien lee el blog de Fedor, el servidor web envía una solicitud a la base de datos maestra para calcular los ingresos. Estas solicitudes sobrecargaron la base de datos y dejaron de atender solicitudes de la caja del restaurante. Entonces, una publicación de blog popular interrumpió el trabajo de toda la cadena de restaurantes. Solucionamos rápidamente el problema, pero fue una señal clara (entre muchas otras) de que nuestra arquitectura no puede satisfacer las necesidades comerciales y debe ser rediseñada. Pero ignoramos estos signos. Implementamos soluciones rápidas y fáciles (como agregar una réplica de solo lectura de la base de datos maestra), pero no teníamos ninguna hoja de ruta de rediseño técnico.
La arquitectura monolítica es buena para comenzar porque es simple. Pero no puede soportar que la alta carga sea un solo punto de falla.
Fallas tempranas en 2017
El 14 de febrero es un día de San Valentín . Todos aman estas vacaciones. Para que los amantes se feliciten, el 14 de febrero hacemos una pizza especial: pepperoni en forma de corazón. Recordaré el 14 de febrero de 2017 para siempre, porque en este día, cuando todas las pizzerías estaban funcionando a plena carga, Dodo IS comenzó a caer. En cada pizzería tenemos de 4 a 5 tabletas para rastrear el orden en el que un fabricante de pizza hace masa, pone ingredientes, hornea o envía a la entrega. El número de pizzerías alcanzó más de 300, cada tableta actualizó su estado varias veces por minuto. Todas estas solicitudes crearon una carga tan masiva en la base de datos que el servidor SQL dejó de resistir y la base de datos comenzó a fallar. Dodo se establece en el momento más inapropiado, durante el pico de las ventas. Había una temporada festiva muy ocupada: el 23 de febrero (Día del Ejército y la Armada), el 8 de marzo (Día Internacional de la Mujer), el 1 de mayo (Día de la Solidaridad Internacional de los Trabajadores) y el 9 de mayo (Día de la Victoria en la Segunda Guerra Mundial). Durante estas vacaciones, esperábamos un crecimiento de pedidos aún mayor.
El día en que morirás . Conociendo nuestros planes de crecimiento y el límite de la carga que podemos soportar, descubrimos cuánto tiempo podemos permanecer con vida, es decir, cuando la carga máxima de hoy se vuelve regular. La fecha estimada de Armagedón se espera en unos seis meses, en agosto o septiembre. ¿Cómo se siente vivir, sabiendo la fecha de tu muerte?
Detener el desarrollo de funciones por un año . Junto con el CEO Fedor, tuvimos que tomar una decisión ardua. Quizás una de las decisiones más difíciles en la historia de la empresa. Detuvimos el desarrollo de características comerciales. Pensamos que nos detendríamos por 3 meses, pero pronto nos dimos cuenta de que el volumen de la deuda técnica era tan grande que 3 meses no serían suficientes y tenemos que seguir trabajando en problemas técnicos y posponer la cartera de pedidos del negocio. De hecho, con 6 equipos hemos hecho una sola característica comercial durante el próximo año. El resto del tiempo, los equipos se dedicaron al reembolso de la deuda técnica. Esta deuda nos costó mucho, más de $ 1.5 millones.
Algunas mejoras después de un año.
Durante el año, tuvimos estos logros notables:
- Hemos automatizado y acelerado nuestro proceso de implementación. Anteriormente, el despliegue era semi-manual. Nos desplegamos en 10 países en aproximadamente 2 horas.
- Comenzó a partir un monolito. La parte más cargada del sistema, el rastreador, se dividió en un servicio separado, con su propia base de datos. Ahora el rastreador se comunica con el resto del sistema a través de una cola de eventos.
- Comenzamos a separar el Cajero de entrega, el segundo componente que crea una gran carga.
- Reescribió el sistema de autenticación de usuarios y dispositivos.
Nuestro arquitecto gestionó el atraso técnico. Utilizamos los cambios arquitectónicos para impulsar el trabajo atrasado. Cada equipo tenía la libertad de hacer lo correcto para crear una arquitectura útil. Para el año con los sextos equipos, creamos para el negocio solo una característica valiosa. El resto del tiempo, los equipos trabajaron en deuda técnica. Parece que podemos estar orgullosos de nosotros mismos. Pero delante de nosotros hubo una gran decepción.
Falla durante la campaña de marketing federal. La segunda crisis de confianza.
La deuda técnica es fácil de acumular, pero muy difícil de pagar. Es poco probable que pueda comprender de antemano cuánto le costará.
A pesar del hecho de que pasamos todo un año luchando contra la deuda técnica, no estábamos listos para una campaña de marketing masiva y nos equivocamos frente a nuestro negocio. Ganas confianza en las gotas, lo pierdes en cubos. Y tuvimos que ganarlo de nuevo.
Perdimos el momento en que era necesario reducir la velocidad del desarrollo de las características comerciales y abordar la deuda técnica. Era demasiado tarde cuando nos dimos cuenta. Nos acostamos bajo carga de nuevo. El sistema se bloqueó y reinició cada 3 horas. Nuestro negocio perdió decenas de millones de rublos.

Pero gracias a la crisis, vimos que en condiciones extremas podemos trabajar muchas veces de manera más eficiente. Lanzamos 20 veces al día. Todos trabajaron como un solo equipo, centrándose en un solo objetivo. Durante dos semanas de crisis, hemos hecho lo que temíamos comenzar antes porque creíamos que tomaría meses de trabajo. El orden asincrónico, las pruebas de rendimiento y los registros claros son solo una pequeña parte de lo que hicimos. Estábamos ansiosos por seguir trabajando con la misma eficacia, pero sin horas extras y sin estrés.
Lecciones aprendidas
Después de la retrospectiva, reestructuramos completamente nuestros procesos. Tomamos el marco LeSS y lo complementamos con prácticas de ingeniería. En los próximos meses, hicimos un gran avance en la adopción de prácticas de ingeniería. Basado en el marco de LeSS, hemos implementado y seguimos utilizando:
- sola cartera de pedidos;
- equipos de funciones completamente funcionales y de componentes cruzados;
- programación de pares;
- Probar la programación de la mafia.
- Integración continua genuina, lo que significa múltiples integraciones de código de 9 equipos en una sola rama;
- gestión de configuración simplificada con desarrollo basado en troncales;
- lanzamientos frecuentes: Despliegue continuo para microservicios, lanzamientos múltiples por día para monolitos;
- no hay un equipo de control de calidad separado, los expertos en control de calidad forman parte de los equipos de desarrollo.
6 prácticas que elegimos después de la crisis
1. El poder del enfoque . Antes de la crisis, cada equipo trabajaba en su propia cartera de pedidos y se especializaba en su dominio. En el trabajo atrasado, hubo tareas finamente descompuestas, el equipo seleccionó varias tareas para un sprint. Pero durante la crisis, trabajamos de manera bastante diferente. Los equipos no tenían tareas específicas, sino que tenían un gran objetivo desafiante. Por ejemplo, una aplicación móvil y una API deben manejar 300 pedidos por minuto, pase lo que pase. Depende del equipo cómo lograr el objetivo. Los equipos mismos formulan hipótesis, las verifican rápidamente en Producción y las tiran. Y esto es exactamente lo que queríamos seguir haciendo. Los equipos no quieren ser codificadores tontos, quieren resolver problemas.
El poder del enfoque se manifestó en la resolución de problemas complejos. Por ejemplo, durante la crisis, creamos un conjunto de pruebas de rendimiento a pesar de que no teníamos experiencia. También hicimos la lógica de recibir una orden asincrónica. Lo hemos pensado y hablado durante mucho tiempo, y nos pareció que esta es una tarea muy difícil y larga. Pero resultó que el equipo es bastante capaz de hacerlo en 2 semanas, si no está distraído y completamente enfocado en el problema.
2. Hackatones regulares . Nos gustaba trabajar en el modo cuando todos los equipos apuntaban a un objetivo y decidimos a veces organizar tales "hackatones". No se puede decir que los llevemos a cabo regularmente, pero hubo un par de veces. Por ejemplo, hubo un hackathon de 500 errores cuando todos los equipos limpiaron los registros y eliminaron las causas de los 500 errores en el sitio y en la API. El objetivo era mantener limpios los registros. Cuando los registros están limpios, los nuevos errores son claramente visibles, puede configurar fácilmente los valores de umbral para las alertas. Es similar a las pruebas unitarias: no pueden ser un poco rojas.
Otro ejemplo de un hackathon son los errores. Solíamos tener una gran acumulación de errores, algunos de los errores habían estado en la cartera durante años. Parecía que nunca terminarían. Y cada día había nuevos. Tienes que combinar de alguna manera el trabajo en errores y en elementos regulares de la cartera de pedidos.
Introdujimos la política #zerobugspolicy en 4 pasos.- Limpieza inicial de errores basada en la fecha. Si el error está en la cartera de pedidos durante más de 3 meses, simplemente elimínelo. Lo más probable es que estuvo allí por años.
- Ahora, clasifique los defectos restantes según cómo afectan a los clientes. Seleccionamos cuidadosamente los errores restantes. Solo conservamos defectos que dificultan la vida de un gran grupo de usuarios. Si esto es solo algo que causa inconvenientes, pero puede lidiar con eso, elimine sin piedad. Entonces redujimos el número de errores a 25, lo cual es aceptable.
- Hackathon Todos los equipos pululan y arreglan todos los errores. Hicimos esto en unos pocos sprints. Cada sprint cada equipo tomó varios errores y lo arregló. Después de 2-3 sprints tuvimos una acumulación de errores clara. Ahora puede ingresar #zerobugspolicy.
- #zerobugspolicy. Cada nuevo error ahora tiene solo dos formas. Éter se cae en la cartera de pedidos, o no. Si entra en el backlog, lo arreglamos primero. Cualquier error en el backlog tiene mayor prioridad que cualquier otro elemento del backlog. Pero para entrar en la cartera de pedidos, el error debe ser grave. O causa un daño irreparable o afecta a un gran número de usuarios.
3. Equipos de proyectos temporales a equipos de características estables . Hubo una historia divertida con los equipos del proyecto. Durante la crisis, formamos equipos de tigres de personas que estaban mejor capacitadas para la tarea. Después de que terminó la crisis, los equipos decidieron continuar esta práctica y disolver los equipos. A pesar de que no me gustó esta idea, les dejé probar. En solo 2 semanas (un sprint), en la próxima retrospectiva, los equipos abandonaron esta práctica (esta decisión me hizo extremadamente feliz). Intentaron y entendieron por qué es mucho más cómodo trabajar en un equipo estable. Incluso si el equipo carece de algunas habilidades, pueden aprender gradualmente. Pero el espíritu de equipo, el apoyo y la asistencia mutua se forman durante mucho tiempo, lleva meses. Los equipos de proyectos a corto plazo están constantemente en fase de formación y tormenta. Puedes soportarlo durante un par de semanas, pero no puedes trabajar así todo el tiempo. Es bueno que los equipos hayan intentado y entendido los beneficios de los equipos con características estables.
4. Deshágase de la regresión manual . Antes de la crisis, lanzamos una vez por semana, y durante la crisis, docenas de veces al día. Nos encantó nuestra capacidad de liberar a menudo. Apreciamos lo conveniente que era hacer un pequeño cambio, implementarlo rápidamente e inmediatamente recibir comentarios de la producción. Por lo tanto, cambiamos nuestro enfoque hacia los lanzamientos, y esto afectó el enfoque hacia la programación y el diseño. Ahora lanzamos continuamente, cada 1-2 días. Todo en la rama de desarrollo entra en producción. Incluso si algunas funciones no están listas, esta no es razón para no publicar el código. Si no queremos mostrar a los usuarios algunas características que aún no están listas, las ocultamos con alternancia de funciones. Este enfoque nos ayudó a desarrollarnos en pequeños pasos.
Fijamos una meta para deshacernos de las regresiones manuales. Nos llevó 1,5 años alcanzarlo. Pero tener un objetivo ambicioso a largo plazo te hace pensar en los pasos que conducen al objetivo.
Lo hicimos en 3 pasos.- Automatiza la ruta crítica. En junio de 2017, formamos el equipo de control de calidad. La tarea del equipo era automatizar la regresión del funcional más crítico de Dodo IS: la toma de pedidos y la producción. Durante los próximos 6 meses, un nuevo equipo de control de calidad de 4 personas cubrió todo el camino crítico. Los desarrolladores de equipos de funciones los ayudaron activamente. Juntos escribimos un lenguaje específico de dominio (DSL) hermoso y comprensible, que era legible incluso para los clientes. Paralelamente a las pruebas de extremo a extremo, los desarrolladores cubrieron el código con pruebas unitarias. Algunos componentes nuevos fueron rediseñados con TDD. Después de eso, disolvimos el equipo de control de calidad. Los antiguos miembros del equipo de control de calidad se unieron a equipos de funciones para compartir experiencia sobre cómo apoyar y mantener las pruebas automáticas.
- Modo de sombra. Al tener pruebas automáticas, durante 5 lanzamientos hicimos regresiones manuales en modo sombra. Los equipos confiaron solo en el conjunto de pruebas automatizadas, pero cuando el equipo decidió "Estamos listos para lanzar", ejecutamos una regresión manual para verificar si nuestras pruebas automáticas fallan. Rastreamos cuántos errores fueron detectados manualmente y no detectados por las pruebas automáticas. Después de 5 lanzamientos, revisamos los datos y decidimos que podemos confiar en nuestras pruebas automáticas. No se perdieron errores importantes.
- Eliminar regresiones manuales. Cuando tuvimos suficientes pruebas para comenzar a confiar en ellas, abandonamos por completo las pruebas manuales. Cuanto más ejecutamos nuestras pruebas, más confiamos en ellas. Pero esto sucedió solo 1.5 años después de que comenzamos a automatizar las pruebas de regresión.
5. Prueba de rendimiento es parte de la prueba de regresión . Durante la crisis, creamos un conjunto de pruebas de rendimiento. Era un área completamente nueva para nosotros. Sin embargo, en solo 2 semanas, logramos crear algunas pruebas de rendimiento utilizando las herramientas de Visual Studio. Estas pruebas nos ayudaron no solo a detectar la degradación del rendimiento. Los usamos para agregar carga sintética al servidor de producción para identificar los límites de rendimiento. Por ejemplo, si la carga de producción orgánica es de 100 pedidos / min y agregamos 50 más pedidos / min con la ayuda de nuestras pruebas de rendimiento, podemos ver si los servidores de Producción pueden manejar el aumento de carga. Tan pronto como notamos excepciones o aumento de la latencia, detenemos la prueba. Al realizar estos experimentos, descubrimos la carga máxima que nuestros servidores de producción pueden manejar y cuál será el punto de acceso.
El año que viene superamos las pruebas de rendimiento al equipo experimentado de PerformanceLab. Se reunieron con nuestros desarrolladores y personal de infraestructura, y nos ayudaron a crear un conjunto robusto de pruebas de rendimiento. Ahora ejecutamos estas pruebas semanalmente y proporcionamos comentarios rápidos a los equipos de desarrollo si el rendimiento se ve afectado.
Algunas de las prácticas de ingeniería fueron refinadas iterativamente. Por ejemplo, lanzamientos frecuentes. Comenzamos con ciclos de lanzamiento semanales, compatibles con pruebas manuales lentas y frágiles. Desarrollamos funciones durante una semana y probamos durante otra semana. Pero fue difícil mantener los cambios realizados por múltiples durante una semana. Luego probamos lanzamientos de equipos aislados, cuando solo se lanzaron los cambios realizados por un solo equipo. Pero este proceso falló porque cada equipo tuvo que esperar en la cola durante varias semanas. Luego, los equipos aprendieron los beneficios de la integración frecuente y comenzamos a practicar lanzamientos conjuntos de cambios de equipos múltiples. Los desarrolladores comenzaron a experimentar con la función de alternancia de funciones y a pasar a funciones sin terminar de producción. Finalmente, llegamos a Integración continua y múltiples versiones por día para monolitos e Implementación continua para microservicios.
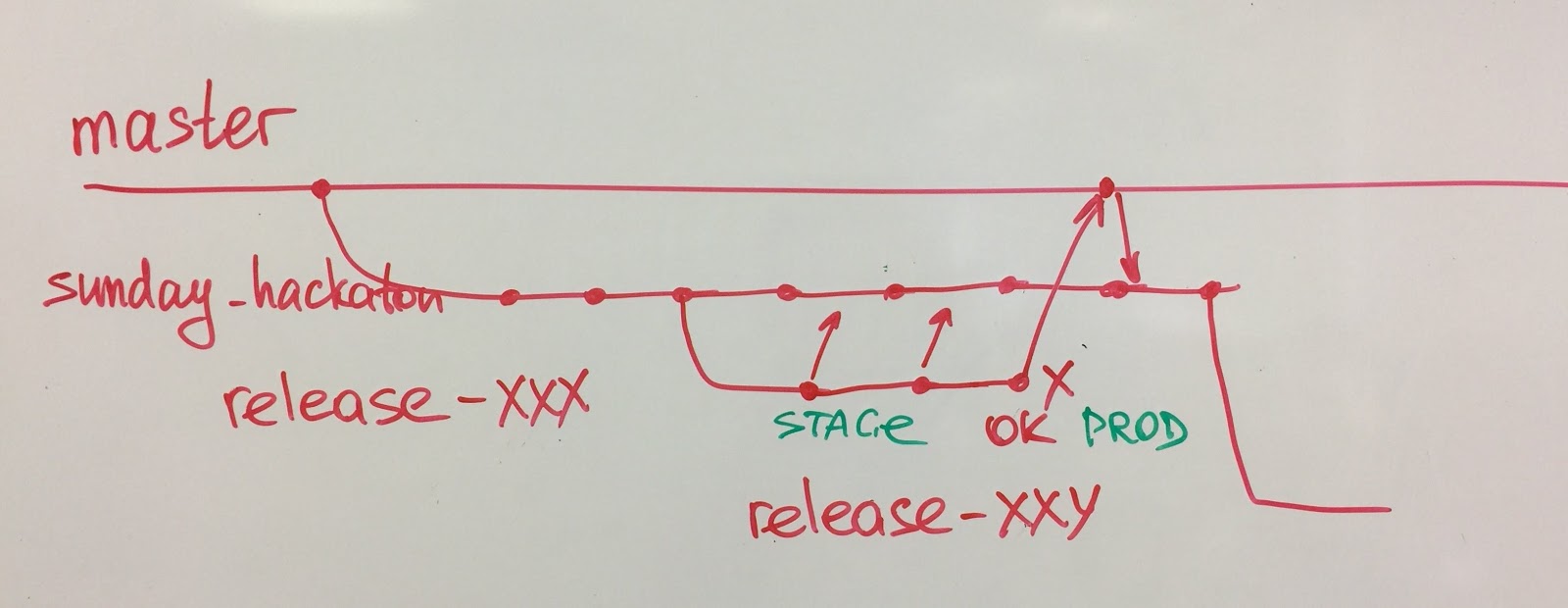
Otro caso interesante es con nuestro departamento de control de calidad. Antes no teníamos un equipo de control de calidad, sino que teníamos probadores manuales. Al darse cuenta de la necesidad de la automatización de pruebas, formamos un equipo de control de calidad, pero desde el primer día este equipo sabía que algún día se disolvería. Después de 6 meses, el equipo automatizó nuestros escenarios comerciales clave y, con la ayuda de los desarrolladores, escribió un lenguaje específico de dominio (DSL) conveniente para escribir pruebas. El equipo se separó y los ingenieros de calidad se unieron a los equipos de características. Ahora los propios equipos desarrollan y mantienen autotest.
Hoy tenemos una única cartera de pedidos en la que están trabajando 9 equipos de características. Los equipos de características son equipos estables, multifuncionales y de componentes cruzados. La mayoría de nuestros equipos son equipos de características.
6. Centrarse en las prácticas de ingeniería . Todos nuestros equipos usan programación en pares. Considero que la programación de pares es una de las prácticas más simples pero poderosas que ayuda a implementar otras prácticas de ingeniería. Si no sabe qué práctica de ingeniería comenzar, le recomiendo programar la pareja.
Resultados
El principal resultado que nos dio la crisis es una sacudida. Nos despertamos y comenzamos a actuar. La crisis nos ha ayudado a ver el máximo de nuestras oportunidades. Vimos que podemos trabajar muchas veces de manera más eficiente y alcanzar rápidamente nuestros objetivos. Pero esto requiere cambiar la forma habitual de trabajar. Hemos dejado de tener miedo de hacer experimentos audaces. Como resultado de estos experimentos, durante el año pasado hemos mejorado significativamente la calidad y la estabilidad de Dodo IS. Si durante las vacaciones de primavera en 2018 nuestras pizzerías no pudieron funcionar debido a Dodo IS, entonces en 2019, con un crecimiento de 300 a 450 pizzerías, Dodo IS funcionó a la perfección. En silencio, experimentamos el pico de ventas en el Año Nuevo, durante la segunda Campaña de Marketing y las vacaciones de primavera. Por primera vez en mucho tiempo, confiamos en la calidad del sistema y dormimos bien por la noche. Este es el resultado del uso constante de las prácticas de ingeniería y el enfoque en la excelencia técnica.
Resultados para empresas
Las prácticas de ingeniería no son necesarias por sí mismas si no benefician a su negocio. Como resultado del enfoque en la excelencia técnica, mejoramos la calidad del código y desarrollamos características comerciales con una velocidad predecible. Los lanzamientos se han convertido en un evento regular para nosotros. Lanzamos el monolito cada 2 días y servicios más pequeños cada pocos minutos. Esto significa que podemos ofrecer rápidamente valor comercial a nuestros usuarios y recopilar comentarios más rápido. Gracias a la flexibilidad de los equipos de características, obtenemos una alta velocidad de desarrollo.
Hoy tenemos 480 pizzerías en línea, 400 de las cuales están en Rusia. Durante las vacaciones de mayo de este año, hubo problemas con el procesamiento de pedidos en nuestras pizzerías nuevamente. Pero esta vez el cuello de botella fue el servicio al cliente en las pizzerías. Dodo IS funcionaba como un reloj, a pesar del creciente número de pizzerías y pedidos.
Resultados para los equipos
Hoy utilizamos una amplia gama de prácticas de ingeniería:
- Equipos con funciones totalmente funcionales y de componentes cruzados.
- Programación en pareja / Programación de mobs.
- Integración continua genuina, lo que significa múltiples integraciones de código de 9 equipos en una sola rama.
- Gestión de configuración simplificada con desarrollo basado en troncales.
- Objetivo común para múltiples equipos.
- El experto en la materia está en el equipo.
- No hay un equipo de control de calidad separado, los expertos en control de calidad son parte de los equipos de desarrollo.
- Reemplazo manual de regresión manual con autotest.
- Política de cero errores.
- Retraso técnico de la deuda.
- Detenga la línea como un controlador para la aceleración de la tubería de implementación.
Ayudan a 9 equipos a trabajar en un código común y un único producto que incluye docenas de componentes: un sitio móvil y de escritorio, una aplicación móvil en iOS y Android, y un back office gigante con caja registradora, seguimiento, exhibición de restaurantes, cuenta personal , análisis y pronósticos.
Que puede ser mejor
Puede parecer que ya hemos hecho un buen progreso en las prácticas de ingeniería, pero solo estamos al principio, todavía tenemos espacio para crecer. Por ejemplo, intentamos, pero hasta ahora de manera poco sistemática, la programación de la mafia. Estudiamos el enfoque de escritura de prueba BDD. Todavía tenemos espacio para crecer en CI, entendemos que la integración, incluso una vez al día, no es suficiente. Y cuando crezcamos hasta 30 equipos, será necesario integrarnos más a menudo. Todavía estamos en progreso de la transición de TDD a ATDD. Tenemos que crear un proceso de toma de decisiones arquitectónicas sostenible y escalable.
Lo más importante es que nos dirigimos hacia el fortalecimiento de la Excelencia Técnica.
Debido al hecho de que los 9 equipos están trabajando en una cartera de pedidos común y en un producto, los equipos tienen un fuerte deseo de cooperar entre sí. Aprendieron a tomar decisiones fuertes ellos mismos.
Por ejemplo, las siguientes prácticas han sido propuestas e implementadas por los propios equipos.- Detenga la línea como un controlador para la aceleración de la tubería de implementación (consulte el informe de mi experiencia "Detenga la línea para racionalizar su tubería de implementación").
- Reemplace las pruebas de IU con pruebas de API.
- Implementación automatizada con un solo clic.
- Anfitrión de Kubernetes.
- El equipo de desarrollo se implementa en producción.
Algunos equipos mostraron su deseo de usar las 12 prácticas de XP y me pidieron ayuda como XP Coach y Scrum Master.
Lo que aprendimos
Desearía no dejar que la crisis suceda. Como desarrollador, sentí la responsabilidad personal de acumular una deuda técnica demasiado grande y no levantar una bandera roja antes:
- Las prácticas de ingeniería protegen a las empresas de las crisis.
- No acumule deuda técnica. Puede ser demasiado tarde y costar demasiado.
- Los cambios evolutivos tardan varias veces más que los revolucionarios.
- La crisis no siempre es algo malo. Utiliza la crisis para revolucionar los procesos.
- Sin embargo, se requiere una larga preparación evolutiva de antemano.
- No implementes ciegamente todas las prácticas que te gustan. Algunas prácticas están esperando en las alas, y cuando él venga, los equipos las usarán sin resistencia. Espera el momento correcto.
- Refina y adapta las prácticas a tu contexto.
- Con el tiempo, los propios equipos comienzan a tomar decisiones firmes y a implementarlas. Bríndeles un ambiente seguro para probar, fallar y aprender sobre los errores.
La deuda técnica nos lleva a la crisis. Pero de la crisis, tanto los desarrolladores como las personas de negocios aprendieron la importancia del enfoque en la excelencia técnica y las prácticas de ingeniería. Utilizamos la crisis como un desencadenante para el cambio masivo de organización y procesos.
Agradecimientos
Me gustaría dar las gracias a todas las personas que me ayudaron en mi viaje desde la crisis hasta la transformación de LeSS. Constantemente siento tu apoyo.
Muchas gracias a nuestro CEO, Fedor Ovchinnikov por la confianza. Eres el verdadero líder de la empresa con una cultura ágil genuina.
Muchas gracias a Dmitry Pavlov, nuestro Product Owner, mi viejo amigo y co-entrenador.
Gracias Alex Andronov y Andrey Morevsky por apoyarme en mi papel.
Muchas gracias a Dasha Bayanova, nuestro primer Scrum Master a tiempo completo, que me creyó y siempre me ayuda y apoya con toda nuestra iniciativa. Su ayuda es difícil de sobreestimar.
Muchas gracias a Johanna Rothman, quien me ayudó a escribir este informe en cualquier condición: estar de vacaciones, recuperarse después de una enfermedad. Johanna, fue un placer trabajar contigo. Su ayuda, consejo, atención a los detalles y diligencia son muy apreciados.