Introducción a los sistemas operativos
Hola Habr! Quiero llamar su atención sobre una serie de artículos-traducciones de una literatura interesante en mi opinión: OSTEP. Este artículo analiza en profundidad el trabajo de los sistemas operativos tipo Unix, a saber, el trabajo con procesos, varios programadores, memoria y otros componentes similares que componen el sistema operativo moderno. El original de todos los materiales que puedes ver
aquí . Tenga en cuenta que la traducción se realizó de manera no profesional (con bastante libertad), pero espero haber conservado el significado general.
El trabajo de laboratorio sobre este tema se puede encontrar aquí:
Otras partes:
Y puedes mirar mi canal en
telegram =)
Alarma! ¡Hay un laboratorio para esta conferencia! ver
githubAPI de proceso
Considere un ejemplo de creación de un proceso en un sistema UNIX. Se produce a través de dos llamadas al sistema
fork () y
exec () .
Tenedor () llamada

Considere un programa que realiza una llamada fork (). El resultado de su implementación será el siguiente.
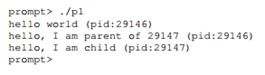
En primer lugar, ingresamos la función main () y ejecutamos la salida de la cadena a la pantalla. La cadena contiene el identificador de proceso, que en el original se llama
PID o identificador de proceso. Este identificador se utiliza en UNIX para referirse a un proceso. El siguiente comando llamará fork (). En este punto, se crea una copia casi exacta del proceso. Para el sistema operativo, parece que el sistema se ejecuta como si fueran 2 copias del mismo programa, que a su vez saldrá de la función fork (). El proceso hijo recién creado (relativo al proceso padre que lo creó) ya no se ejecutará, comenzando con la función main (). Debe recordarse que el proceso hijo no es una copia exacta del proceso padre, en particular, tiene su propio espacio de direcciones, sus propios registros, su propio puntero a instrucciones ejecutables y similares. Por lo tanto, el valor devuelto al llamador de la función fork () será diferente. En particular, el proceso padre recibirá el valor PID del proceso del niño como un retorno, y el niño recibirá un valor igual a 0. De acuerdo con estos códigos de retorno, ya es posible separar los procesos y obligar a cada uno de ellos a hacer su trabajo. Además, la ejecución de este programa no está estrictamente definida. Después de dividirse en 2 procesos, el sistema operativo también comienza a seguirlos y a planificar su trabajo. En el caso de la ejecución en un procesador de un solo núcleo, uno de los procesos continuará funcionando, en este caso el padre, y luego el proceso hijo recibirá el control. Cuando reinicia, la situación puede ser diferente.
Llamada en espera ()
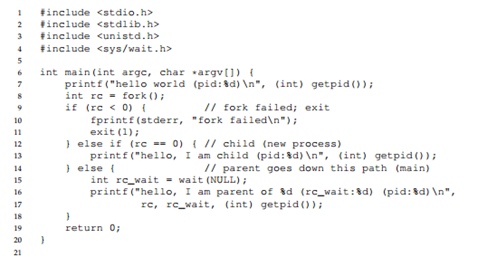
Considere el siguiente programa. En este programa, debido a la presencia de la llamada
wait () , el proceso padre siempre esperará a que el proceso hijo complete su trabajo. En este caso, obtenemos una salida de texto estrictamente definida en la pantalla.

Llamar a exec ()

Considere la llamada a
exec () . Esta llamada al sistema es útil cuando queremos ejecutar un programa completamente diferente. Aquí llamaremos a
execvp () para ejecutar el programa wc, que es un programa de conteo de palabras. ¿Qué sucede cuando se llama a exec ()? El nombre del archivo ejecutable y algunos parámetros se pasan a esta llamada como argumentos. Después de eso, el código y los datos estáticos de este archivo ejecutable se descargan y se sobrescribe su propio segmento con código. Las secciones restantes de la memoria, como la pila y el montón, se reinicializan. Después de lo cual el sistema operativo simplemente ejecuta el programa, pasándole un conjunto de argumentos. Por lo tanto, no creamos un nuevo proceso, simplemente transformamos el programa en ejecución actual en otro programa en ejecución. Después de ejecutar exec (), el descendiente da la impresión de que el programa original parecía no iniciarse en principio.
Esta complicación del lanzamiento es absolutamente normal para el shell Unix, y permite que este shell ejecute código después de llamar a
fork () , pero antes de llamar a
exec () . Un ejemplo de dicho código puede ser ajustar el entorno del shell a las necesidades del programa que se inicia, antes de iniciarlo directamente.
Shell es solo un programa de usuario. Ella te muestra la línea de aviso y espera a que le escribas algo. En la mayoría de los casos, si escribe el nombre del programa allí, el shell encontrará su ubicación, llamará al método fork () y luego, para crear un nuevo proceso, llamará a algunos de los tipos exec () y esperará a que se ejecute usando la llamada wait (). Cuando finaliza el proceso secundario, el shell regresa de la llamada wait () y muestra el mensaje nuevamente y espera a que se ingrese el siguiente comando.
Separar fork () y exec () permite que el shell haga lo siguiente, por ejemplo:
archivo wc> archivo_nuevo.En este ejemplo, la salida de wc se redirige a un archivo. La forma en que el shell logra esto es bastante simple: al crear un proceso hijo antes de llamar a
exec () , el shell cierra la secuencia de salida estándar y abre el archivo
new_file , por lo que toda la salida del programa
wc que se inicia se redirigirá al archivo en lugar de a la pantalla.
Las tuberías Unix se implementan de manera similar, con la diferencia de que usan la llamada pipe (). En este caso, la secuencia de salida del proceso se conectará a la cola de tubería ubicada en el núcleo al que se adjuntará la secuencia de entrada de otro proceso.