El aprendizaje automático se utiliza en todo el ciclo de pedidos de automóviles Yandex.Taxi, y la cantidad de componentes de servicio que funcionan gracias a ML está en constante crecimiento. Para construirlos de manera uniforme, necesitábamos un proceso separado. Roman Khalkachev, Jefe del Servicio de Aprendizaje Automático y Análisis de Datos, habló sobre el preprocesamiento de datos, el uso de modelos en producción, el servicio de creación de prototipos y las herramientas relacionadas.
- En mi opinión, algunas cosas nuevas son mucho más fáciles de percibir cuando se mencionan en un ejemplo simple. Por lo tanto, para que el informe no fuera seco, decidí hablar sobre una de las tareas que estamos resolviendo. Usando su ejemplo, mostraré por qué actuamos de esta manera.
Formulemos el problema. Hay usuarios de Taxi que necesitan ir del punto A al punto B, y hay conductores que están listos por una cierta cantidad para entregar a estos usuarios del punto A al punto B. El usuario tiene varios estados en los que se encuentra. Llama a un taxi, selecciona el punto A, el punto B, la tarifa, etc., aterriza en un taxi, viaja y finalmente aterriza. Hoy me gustaría hablar sobre subir a un automóvil y los problemas que puedan surgir.

Como regla general, estos problemas están relacionados con el hecho de que una persona necesita elegir un lugar donde debe venir un taxi. Y aquí hay una serie de dificultades. Estas dificultades están relacionadas con cuatro cosas que he enumerado en la diapositiva.
En primer lugar, la ubicación puede no ser familiar para el usuario. Como ejemplo, puedes imaginarte a ti mismo que vino a un gran centro comercial, en el que no visitas con frecuencia. Quiere irse, y realmente no sabe dónde puede llamar un taxi aquí, dónde puede llamar el automóvil, pero dónde no puede hacerlo, por ejemplo, debido a la barrera. Hay problemas con el hecho de que en algunos lugares hay mucha gente, muchos automóviles y es difícil encontrar su automóvil. Hay lugares donde la gente suele subirse al automóvil, es más fácil llegar allí. Y es posible que no sepa, estar en un lugar nuevo, no necesariamente en el centro comercial, donde exactamente aterrizar. Las dificultades pueden estar relacionadas con el hecho de que el conductor no puede conducir hasta el lugar donde llamó al taxi: tiene prohibido viajar, hay una gran salida desde el centro comercial, frente a la cual no puede detenerse, etc.
Por otro lado, puede tener problemas como usuario. Llegó el conductor, todo está bien, pero te incomoda sentarte, porque todos desenterraron. Le pide al conductor que conduzca a otro lugar. Hay otras razones
El ejemplo más ilustrativo, la quintaesencia de todo lo anterior, es el aeropuerto, en el que se hace casi todo. Incluso si vuela fuera de Sheremetyevo con mucha frecuencia, sigue siendo una ubicación desconocida para usted, porque a menudo cambia mucho. Hay muchas personas, muchos autos, hay lugares convenientes para aterrizar, hay lugares incómodos, pero, por regla general, ninguno de nosotros recuerda esto.
La solución se lee del título de la diapositiva. Permítanos recomendar al usuario algunos lugares en los que, en nuestra opinión, es conveniente aterrizar. El pensamiento parece obvio, pero hay muchos matices aquí.
Para empezar, "conveniente" es un concepto subjetivo. Parece que antes de resolver el problema, es necesario formular algunos criterios para el hecho de que el problema se resolverá correctamente. Hemos formulado tres principales para nosotros mismos. El primer criterio es como en cualquier tarea de recomendaciones: probablemente, las recomendaciones son buenas si se usan. Si mostramos esos puntos de los que el usuario realmente se irá, estos son probablemente buenos puntos. Pero esto, por supuesto, no es todo, porque puedes aprender a recomendar algo, mostrarlo, alentar al usuario a usarlo, pero no puedes obtener ningún beneficio tangible (no lo conseguiremos como sistema, ni como usuario, ni como conductor). Por lo tanto, es muy importante mirar otras métricas. Hemos elegido dos.
Si le informamos sobre un lugar de aterrizaje al que el conductor puede conducir fácilmente, entonces el tiempo de entrega del vehículo debería reducirse. Por otro lado, si es más fácil para el usuario encontrar un automóvil en este lugar, es más fácil aterrizar, entonces se debe reducir el tiempo de espera del conductor. Esta es una de nuestras hipótesis, que damos por sentado, y estas son algunas métricas que observamos cuando hacemos estas recomendaciones. Pero, por supuesto, estas no son las únicas métricas a tener en cuenta. Puedes proponer una docena más. Creo que cada uno de ustedes puede llegar a cientos de estas métricas.
Aquí hay algunos ejemplos más. Esta puede ser la proporción de cancelaciones antes del viaje. En teoría, debería disminuir si es más fácil para el usuario aterrizar. Convencionalmente, estas son llamadas cuando un usuario llama al conductor tratando de encontrarlo o, por el contrario, el conductor llama al usuario antes de que comience el viaje. Este llamamiento es de apoyo, y con una docena más.
Hemos formulado el problema. Más o menos entendimos el criterio de que podemos resolver este problema. Ahora pensemos en cómo resolver este problema. Lo primero que viene a la mente: vamos a recomendar cualquier punto de aterrizaje comprobado y comprensible. Aquí en la diapositiva hay un ejemplo del Centro Comercial Europeo. Y sabemos con certeza que puede conducir hasta las salidas desde este centro comercial, y esta es una especie de pauta, gracias a la cual el usuario puede encontrar un controlador. Puede ser cualquier organización. Hay un ejemplo con el ABC del gusto en algún centro comercial. En mi opinión, esta es la Plaza de Ereván. Esta es también una especie de guía para el usuario y el conductor, sobre la cual sabemos que puede conducir allí.
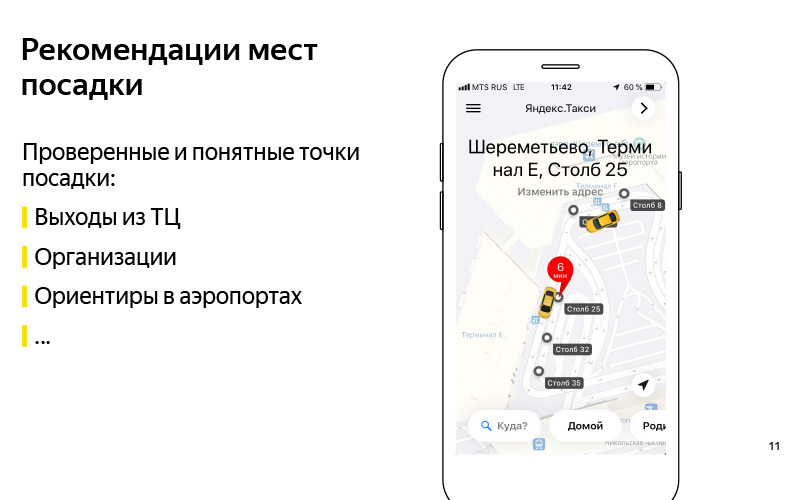
Estos pueden ser puntos de referencia en los aeropuertos de los que hablé. Convencionalmente, existen tales polos en Sheremetyevo con números. Es conveniente llamar a un taxi y subir al auto. Una buena solución, pero tiene un inconveniente de que no es muy escalable. Tenemos muchos países, cientos de ciudades, una gran cantidad de centros comerciales diferentes, aeropuertos, intercambios difíciles, lugares desconocidos para los que estos puntos son difíciles de establecer manualmente, y mantenerlos actualizados es aún más difícil. Es aquí donde viene en nuestra ayuda lo que se llama en voz alta "inteligencia artificial". Prefiero llamarlo minería de datos o aprendizaje automático.
El aprendizaje automático necesita algún tipo de datos, y en realidad tenemos esos datos. Otra forma de resolver el problema automáticamente es usar estos datos. La idea de alto nivel es que tenemos datos sobre GPS, registros de aplicaciones y hay un gráfico de carreteras. Y podemos entender dónde los usuarios realmente entran al automóvil. No los puntos donde llaman al auto, sino donde aterrizan. Y en base a esto, haz algo así.

Estos ya son puntos recibidos automáticamente para el centro de negocios Aurora, donde nuestro equipo Yandex.Taxi está actualmente sentado.
Hablé alto nivel sobre nuestra tarea. Ahora hablemos con más detalle sobre en qué etapas consiste la solución a este problema. Está claro que hay una etapa de preparación de datos.

¿Qué datos tenemos? En primer lugar, tenemos los datos GPS de nuestros usuarios y los datos GPS de nuestros conductores. Cuando usan nuestra aplicación, sabemos la ubicación aproximada de los usuarios. Está claro que el GPS tiene un gran error, en la región de 13-15 metros, pero sin embargo, hay algo. En segundo lugar, tenemos información contenida en los registros de la aplicación sobre cuándo el controlador cambió del estado "Estoy esperando al usuario" al estado "Estoy tomando al usuario". Se puede suponer que aproximadamente en este momento el conductor esperó al usuario, el usuario se metió en el automóvil y se fue. Alrededor de este lugar, se realizó un aterrizaje. Y tenemos un gráfico de carreteras. Un gráfico de carreteras no es solo un conjunto de bordes, calles, sino también metainformación adicional: barreras, información sobre estacionamiento, etc. Con base en estos datos, ya puede obtener algún tipo de puntos automáticos.
Esta fue la fuente de datos. Y a la salida, queremos dos cosas. Estos son algunos de los llamados candidatos de punto de aterrizaje. ¿Cómo se producen? Es una pena que no haya sido posible mostrar el video. Lo siguiente sucede aproximadamente. Tenemos muchos puntos GPS en los que sabemos que el conductor ha cambiado del estado "Esperando a un pasajero" al estado de "Vamos". Podemos, condicionalmente, dibujarlos en el gráfico, es decir, proyectarlos en el gráfico de la carretera, porque, como regla, el automóvil comienza a moverse desde alguna carretera. En este gráfico, realice algún tipo de agrupación de estos puntos. Y para obtener una gran cantidad de candidatos, estos son lugares en los que algunos usuarios se subieron al automóvil, y era normal, conveniente para ellos. No donde llamaron, sino donde terminaron sentados.
Después de eso, cuando tenemos muchos candidatos y tenemos algunos usuarios en línea, sabemos su ubicación, por lo que abrió la aplicación y quiere llamar a un taxi, luego podemos elegir los cinco mejores entre una gran cantidad de candidatos y mostrarlos. Los cinco mejores están determinados por un modelo de aprendizaje automático que aprende a clasificar a todos los candidatos de acuerdo con la probabilidad de que el usuario en este momento, teniendo en cuenta su ubicación y su historial de viajes, sea el más conveniente para irse. Y aproximadamente de esta manera podemos generar automáticamente estos puntos. Además, si en algún momento desenterran condicionalmente en algún lugar, es decir, se vuelve incómodo llamar a un taxi, o en algún lugar ponen un letrero que prohíbe una parada, y los conductores y usuarios realmente dejan de aterrizar en este lugar, entonces en algunos en el momento en que el algoritmo lo entienda, y los datos se actualizarán.
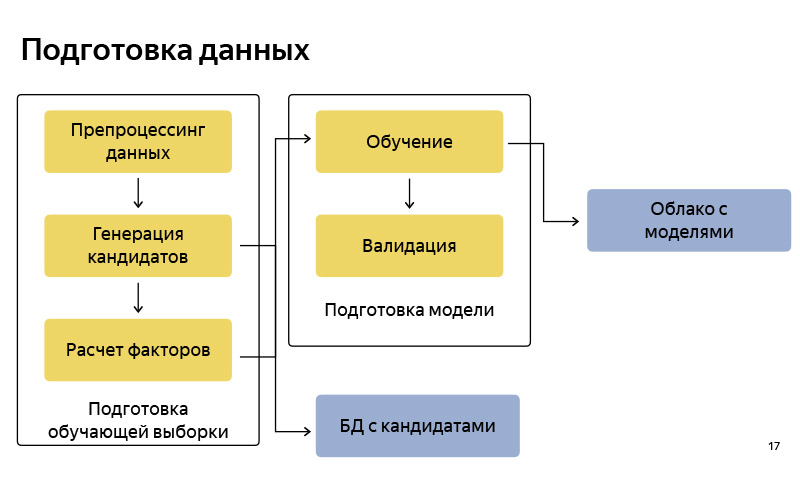
Este es aproximadamente el diagrama de bloques de cómo preparamos los datos. En consecuencia, es bastante estándar, como en cualquier canal de aprendizaje automático. Hay preparación de datos, hay una generación de candidatos según el algoritmo, le dije a una versión simplificada. Almacenamos estos candidatos en una determinada base de datos. Después de eso, preparamos un grupo de entrenamiento (muestra de entrenamiento), en el que hay, condicionalmente, un usuario, tiempo, metainformación, un conjunto de candidatos, y se sabe desde qué punto el usuario finalmente se fue. Sobre esto entrenamos el modelo de clasificación. Y luego, de acuerdo con las predicciones de probabilidad, clasificamos a los candidatos. Cuando el modelo está listo, lo cargamos a alguna nube, donde está bien almacenado.
¿Qué herramientas utilizamos para preparar los datos? Básicamente, toda la preparación de datos que hemos escrito en Python, en la pila de Python: estos son NumPy, Pandas, Scikit-learn, etc. estándar. Tenemos muchos datos. Tenemos millones de viajes por mes. Una gran cantidad de datos sobre GPS, sobre pistas de controladores, registros de aplicaciones, por lo que debemos procesarlos todos en el clúster. Para hacer esto, utilizamos MapReduce de nuestra versión intra-Yandex, que se llama YT, y hay una biblioteca escrita en Python, que permite que se inicien algunos mapeadores y reductores, y hacer algunos cálculos en un clúster grande.
Finalmente, cuando la tubería está lista, necesitamos automatizarla para que los datos estén actualizados, y para esto usamos Nirvana y Hitman. Este es también el desarrollo intra-Yandex. Nirvana es un marco de gestión de computación en clúster. De hecho, ella sabe cómo ejecutar casi cualquier programa, ser tolerante a fallas, ser DC cruzada (00:14:53). Y en caso de que algo se caiga, ella sabe cómo reiniciarlo, para crear lanzamientos ante la ocurrencia de cualquier evento. etc.

Esto es más o menos como se ve la interfaz web de nuestro clúster MapReduce. Se puede ver aquí que tenemos muchas máquinas, tales nodos en los que se realizan los cálculos.
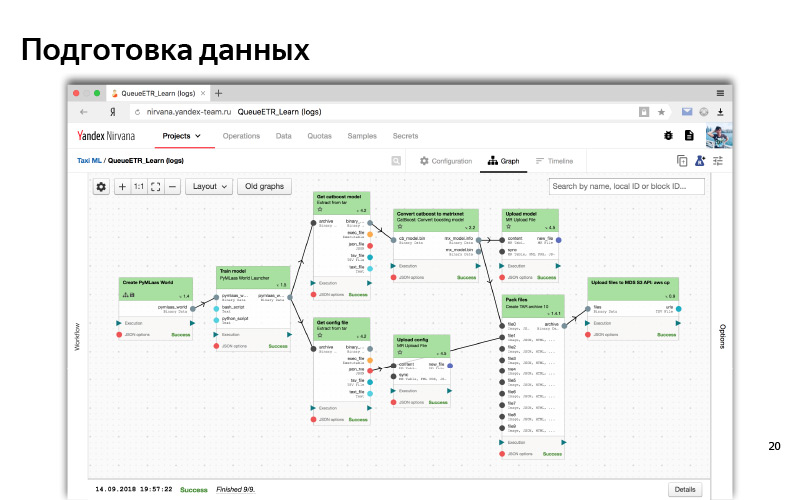
Y así, en la interfaz web, se ve un proceso típico de algún tipo de preprocesamiento de datos y capacitación de modelos. Este es un gráfico de dependencia. Las dependencias son como datos, cuando una parte (un cubo) está esperando datos de otro cubo; y dependencia lógica (primero preparamos todos los datos, luego comenzamos el entrenamiento). Este es algún tipo de sistema automatizado. Por todo esto, usualmente usamos Python.
Formulamos el problema, formulamos criterios de éxito, aprendimos a resolverlo de alguna manera fuera de línea, incluso hicimos algún tipo de modelo, y parece funcionar de acuerdo con algunas métricas fuera de línea: realmente predice los puntos desde los cuales el usuario se va y encuentra esos puntos lo cual, al parecer, debería reducir el tiempo de espera y la entrega del automóvil.

Probemos estos modelos, usemos estos datos. Para hacer esto, imagine lo que es el servicio Yandex.Taxi.
Un diagrama muy superficial se ve así. Hay usuarios, tienen una aplicación, y hay controladores, también tienen una aplicación llamada "Taxímetro". Estas aplicaciones de alguna manera se comunican con el backend, y el backend es un conjunto de microservicios que se comunican entre sí. Ilya
habló sobre esto. Uno de los microservicios es nuestro servicio, nuestro equipo lo hace, se llama ML as a Service, MLaaS.

Todo lo que necesita saber sobre él es MLaaS escrito en C ++, basado en el llamado Fastcgi Daemon. Esta es una biblioteca de código abierto, que, en términos generales, es un marco para escribir un servidor web que puede recibir y publicar solicitudes, todo es estándar. Una vez fue escrito en Yandex, presentado en código abierto. Usamos la versión dopada. ¿Qué puede hacer este servicio? Él sabe cómo trabajar con modelos: aplíquelos, manténgalos en casa y, a veces, actualícelos, vaya a esta maravillosa nube, donde los modelos se actualizan, guardan y descargan regularmente.
Cada funcionalidad, por ejemplo, estos puntos de aterrizaje (en el interior los llamamos puntos de recogida) o, por ejemplo, los consejos de los puntos B sobre los que habló Ilya y que constantemente se rompen en el informe anterior, cada una de esas funciones, donde hay algún tipo de aprendizaje automático, corresponde a manejador, que almacena la lógica de recibir una solicitud, generar factores de aprendizaje automático y aplicar modelos y generar una respuesta. Por supuesto, este servicio no está aislado, pudiendo acceder a algunas fuentes de datos adicionales, bases de datos y otros microservicios.
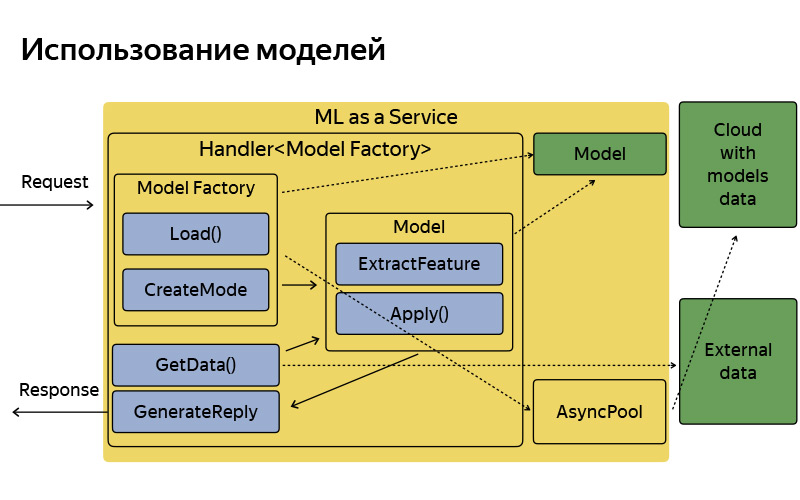
Así es como está organizado, tiene una arquitectura bastante simple. No quería detenerme en esta diapositiva en detalle, solo quería decir que, por convención, la arquitectura es muy simple. Llega la solicitud, hay una fábrica de modelos, que a veces descarga estos modelos desde la nube. En la memoria se almacenan en una sola copia. Para cada solicitud, se crea un objeto modelo bastante ligero, que extrae características, aplica y genera una respuesta.

Pero, ¿qué tenemos para el momento actual? Ya te dije que tenemos preparación de datos, capacitación, varios estudios, experimentos, y todo esto está escrito en Python Stack, y hay algo de producción que está escrito en C ++, simplemente porque tenemos grandes demandas de eficiencia y productividad. Cuando vives en un ecosistema así, surgen dos problemas.
En primer lugar, este es un problema de experimentos. Por ejemplo, un científico de datos que trabaja en nuestro equipo tuvo una idea. Si ejecuta algún tipo de algoritmo de agrupamiento o clasificación con parámetros ligeramente diferentes, puede lograr una mejor calidad. Trató de probar su hipótesis fuera de línea, integrado en nuestro proceso de Python, lo calculó y realmente resulta. Y ahora quiere un experimento AB, es decir, parte de los usuarios para mostrar el nuevo algoritmo y medir algunas métricas que ya están en línea: el tiempo realmente se cae, espera, aumenta el uso. Para hacer esto, tiene condicionalmente cinco versiones de su algoritmo, en el que cree, que sin conexión proporcionan buena calidad: implementar en C ++ y llevar a cabo un experimento AB. Y después de este experimento AB, quizás los cinco se irán a la chatarra, es decir, la calidad de ellos en línea resultará peor de lo que estaba fuera de línea, es decir, peor que en producción. Es decir, el proceso de experimentación lleva mucho tiempo debido al hecho de que, condicionalmente, dos idiomas diferentes, dos tecnologías diferentes.
Esto es para funciones existentes. Y hay otros nuevos. Una vez que estos puntos de recogida también fueron ideas que quería comprobar rápidamente. No gaste dos meses de desarrollo: es recomendable obtener algo en tres semanas. Crear tal prototipo es bastante laborioso. Primero, escriba en Python la extracción de características, simplemente porque es conveniente: muévase rápido, como dicen. Puede construir cualquier prototipo en Python, hay muchas bibliotecas para el análisis de datos. Experimentó en su computadora portátil y ahora desea verificar los usuarios. Y hacer un prototipo resultó bastante difícil. Hemos llegado a la conclusión de que necesitamos algún servicio adicional para ensamblar dichos prototipos con bastante rapidez, condicionalmente, en una semana o incluso en un día, y también para realizar experimentos AB.
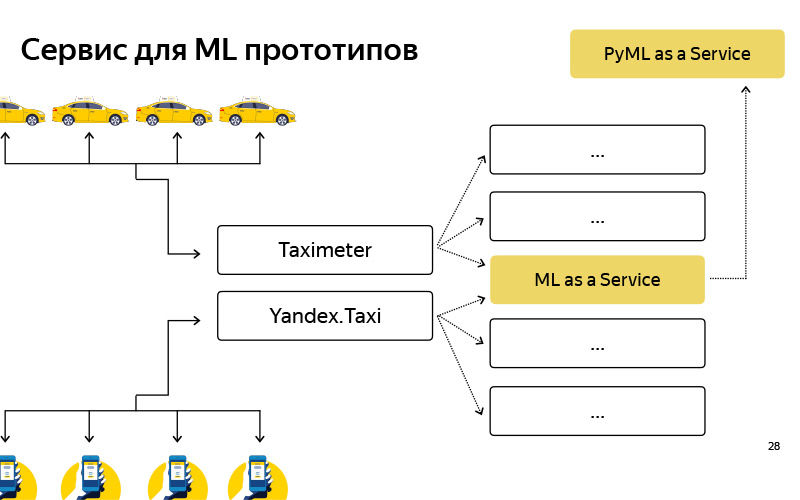
Creamos dicho servicio, lo llamamos PyMLaaS. ¿Cómo es él? De hecho, este es un análogo completo de MLaaS, del que hablé antes, pero escrito en Python basado en Flask, nginx y Gunicorn. La arquitectura es bastante simple, la misma que la de MLaaS, pero existe la oportunidad de profundizar rápidamente en algún prototipo de sus experimentos fuera de línea. Además, organizamos dicha representación en el nivel nginx, de modo que, condicionalmente, tuvimos la oportunidad de reenviar parte de la carga de MLaaS a PyMLaaS y, por lo tanto, experimentar.

Es decir, movimos algunos parámetros y queremos comprobar cómo afecta esto a los usuarios. Iniciamos el 5% de la carga en PyMLaaS y observamos lo que sucede en el experimento. Finalmente, es conveniente crear prototipos. Creé un prototipo de alguna característica nueva, lo vi en PyMLaaS y puedes probarlo inmediatamente en producción.
Nos gustó tanto que surgió la idea: ¿por qué no usarla todo el tiempo? Porque, condicionalmente, hay características que requieren una gran carga, 1000 RPS, grandes requisitos de memoria. Quiero tener un paralelismo bastante flexible. Pero para algunas características, para algunos productos o servicios que no tienen tan grandes demandas de carga, rendimiento, RPS, etc., estamos utilizando este servicio con bastante éxito.

Para resumir. , . . . , - , , , -, - . - PyMLaaS, AB-, . , MLaaS, , .
pickup points — . . , . 30% , . .