El 26 de febrero, realizamos el mitap Apache Ignite GreenSource, donde se presentaron los colaboradores del proyecto de código abierto
Apache Ignite . Un evento importante en la vida de esta comunidad fue la reestructuración del componente
Ignite Service Grid , que le permite implementar microservicios personalizados directamente en el clúster Ignite.
Vyacheslav Daradur , desarrollador senior de Yandex y colaborador de Apache Ignite durante más de dos años, habló sobre este difícil proceso en la reunión.
Para empezar, qué es Apache Ignite en general. Esta es una base de datos que es un repositorio clave / valor distribuido con soporte para SQL, transaccional y almacenamiento en caché. Además, Ignite le permite implementar servicios de usuario directamente en el clúster Ignite. El desarrollador pone a disposición todas las herramientas que proporciona Ignite: estructuras de datos distribuidos, mensajería, transmisión, computación y cuadrícula de datos. Por ejemplo, cuando se usa la cuadrícula de datos, el problema de administrar una infraestructura separada para el almacén de datos y, como resultado, la sobrecarga resultante de esto desaparece.

Con la API de Service Grid, puede implementar un servicio simplemente especificando el esquema de implementación en la configuración y, en consecuencia, el servicio en sí.
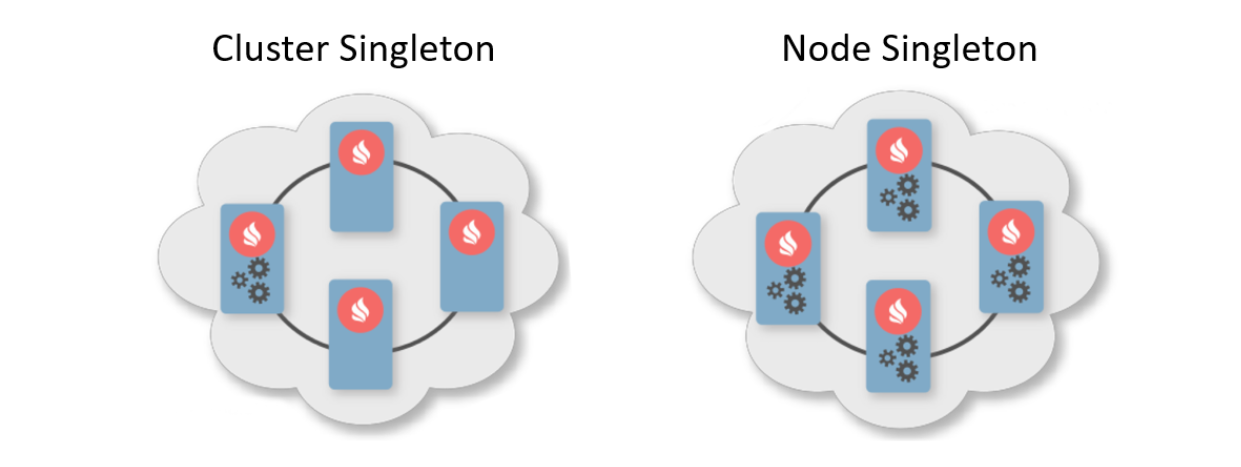
Por lo general, un patrón de implementación es una indicación del número de instancias que deben implementarse en los nodos del clúster. Hay dos patrones de implementación típicos. El primero es Cluster Singleton: en cualquier momento en el clúster, se garantizará que una instancia del servicio de usuario esté disponible. El segundo es Node Singleton: una instancia del servicio se implementa en cada nodo del clúster.
El usuario también puede especificar el número de instancias de servicio en todo el clúster y definir un predicado para filtrar nodos adecuados. En este escenario, Service Grid calculará la distribución óptima para la implementación de los servicios.
Además, existe una característica como el Servicio de afinidad. La afinidad es una función que define la relación de claves con particiones y la relación de partes con nodos en la topología. Con la clave, puede determinar el nodo primario en el que se almacenan los datos. Por lo tanto, puede asociar su propio servicio con la clave y el caché de la función de afinidad. Si la función de afinidad cambia, se producirá una reoperación automática. Por lo tanto, el servicio siempre se colocará junto a los datos que debe manipular y, en consecuencia, reducirá la sobrecarga de acceso a la información. Tal esquema se puede llamar una especie de computación colocada.
Ahora que hemos descubierto cuál es la belleza de Service Grid, le diremos sobre su historial de desarrollo.
Lo que era antes
La implementación anterior de Service Grid se basó en el caché del sistema transaccional replicado Ignite. La palabra "caché" en Ignite significa almacenamiento. Es decir, esto no es algo temporal, como podría pensar. A pesar de que el caché es replicable y cada nodo contiene el conjunto de datos completo, dentro del caché tiene una vista particionada. Esto se debe a la optimización del almacenamiento.

¿Qué sucedió cuando un usuario quería implementar un servicio?
- Todos los nodos del clúster se suscribieron para actualizar los datos en el repositorio utilizando el mecanismo de consulta continua incorporado.
- Un nodo iniciador bajo una transacción de lectura confirmada hizo un registro en la base de datos que contenía la configuración del servicio, incluida la instancia serializada.
- Al recibir la notificación de un nuevo registro, el coordinador calculó la distribución en función de la configuración. El objeto resultante se vuelve a escribir en la base de datos.
- Los nodos leen información sobre la nueva distribución y los servicios desplegados en
si es necesario
Lo que no nos convenía
En algún momento, llegamos a la conclusión: es imposible trabajar con servicios. Hubo varias razones.
Si se produjo algún tipo de error durante la implementación, entonces podría averiguarlo solo desde los registros del nodo donde sucedió todo. Solo hubo una implementación asincrónica, por lo que después de devolver el control del método de implementación al usuario, tomó un tiempo adicional para iniciar el servicio, y en ese momento el usuario no podía controlar nada. Para desarrollar aún más Service Grid, ver nuevas características, atraer nuevos usuarios y facilitar la vida de todos, debe cambiar algo.
Al diseñar una nueva Cuadrícula de servicios, en primer lugar queríamos proporcionar una garantía de implementación síncrona: tan pronto como el usuario devolviera el control de la API, podía usar los servicios de inmediato. También quería darle al iniciador la oportunidad de manejar los errores de implementación.
Además, quería facilitar la implementación, es decir, alejarme de las transacciones y el reequilibrio. A pesar de que el caché es replicable y no hay equilibrio, hubo problemas durante una implementación grande con muchos nodos. Al cambiar la topología, los nodos necesitan intercambiar información, y con una implementación grande, estos datos pueden pesar mucho.
Cuando la topología era inestable, el coordinador necesitaba recalcular la distribución de servicios. Y, en general, cuando tiene que trabajar con transacciones en una topología inestable, esto puede conducir a errores difíciles de predecir.
Los problemas
¿Qué cambios globales sin problemas de acompañamiento? El primero de ellos fue un cambio en la topología. Debe comprender que en cualquier momento, incluso en el momento de la implementación del servicio, un nodo puede entrar o salir de un clúster. Además, si en el momento de la implementación el nodo ingresa al clúster, será necesario transferir constantemente toda la información sobre los servicios al nuevo nodo. Y estamos hablando no solo de lo que ya se ha implementado, sino también de las implementaciones actuales y futuras.
Este es solo uno de los problemas que se pueden agrupar en una lista separada:
- ¿Cómo implementar servicios configurados estáticamente al iniciar un nodo?
- Salida de nodo del clúster: ¿qué sucede si los servicios de host del host?
- ¿Qué hacer si el coordinador ha cambiado?
- ¿Qué hacer si el cliente se reconectó al clúster?
- ¿Necesito procesar solicitudes de activación / desactivación y cómo?
- Pero, ¿qué pasa si llamaron al caché Destroy y tenemos servicios de afinidad vinculados a él?
Y eso no es todo.
Solución
Como objetivo, elegimos el enfoque Event Driven con la implementación de procesos de comunicación utilizando mensajes. Ignite ya ha implementado dos componentes que permiten a los nodos reenviar mensajes entre ellos: comunicación-spi y descubrimiento-spi.
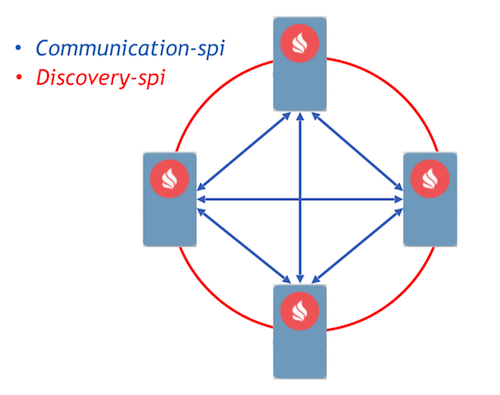
Communication-spi permite a los nodos comunicarse y reenviar mensajes directamente. Es muy adecuado para enviar grandes cantidades de datos. Discovery-spi le permite enviar un mensaje a todos los nodos del clúster. En una implementación estándar, esto se realiza de acuerdo con la topología de anillo. También hay integración con Zookeeper, en este caso se utiliza la topología en estrella. Otro punto importante que vale la pena señalar: discovery-spi garantiza que el mensaje se entregará en el orden correcto a todos los nodos.
Considere el protocolo de implementación. Todas las solicitudes de implementación y distribución de los usuarios se envían a través de discovery-spi. Esto ofrece las siguientes
garantías :
- La solicitud será recibida por todos los nodos del clúster. Esto le permitirá continuar procesando la solicitud cuando cambie el coordinador. También significa que en un mensaje cada nodo tendrá todos los metadatos necesarios, como la configuración del servicio y su instancia serializada.
- Un pedido estricto de entrega de mensajes le permite resolver conflictos de configuración y solicitudes competidoras.
- Dado que la entrada del nodo a la topología también es procesada por discovery-spi, todos los datos necesarios para trabajar con los servicios llegarán al nuevo nodo.
Al recibir la solicitud, los nodos del clúster la validan y forman tareas para su procesamiento. Estas tareas se ponen en cola y un trabajador independiente las procesa en otro subproceso. Esto se implementa de esta manera, porque una implementación puede llevar un tiempo considerable y retrasar un flujo de descubrimiento costoso es inaceptable.
El gestor de despliegue procesa todas las solicitudes de la cola. Tiene un trabajador especial que saca una tarea de esta cola y la inicializa para comenzar el despliegue. Después de esto, se producen las siguientes acciones:
- Cada nodo calcula independientemente la distribución gracias a una nueva función de asignación determinista.
- Los nodos forman un mensaje con los resultados de la implementación y lo envían al coordinador.
- El coordinador agrega todos los mensajes y genera el resultado de todo el proceso de implementación, que se envía a través de discovery-spi a todos los nodos del clúster.
- Al recibir el resultado, se completa el proceso de implementación, después de lo cual la tarea se elimina de la cola.
 Nuevo diseño basado en eventos: org.apache.ignite.internal.processors.service.IgniteServiceProcessor.java
Nuevo diseño basado en eventos: org.apache.ignite.internal.processors.service.IgniteServiceProcessor.javaSi se produjo un error en el momento de la implementación, el nodo incluye inmediatamente este error en el mensaje, que lo envía al coordinador. Después de la agregación de mensajes, el coordinador tendrá información sobre todos los errores durante la implementación y enviará este mensaje a través de discovery-spi. La información de error estará disponible en cualquier nodo del clúster.
Según este algoritmo, se procesan todos los eventos importantes en la cuadrícula de servicios. Por ejemplo, un cambio de topología también es un mensaje de descubrimiento-spi. Y en general, en comparación con lo que era, el protocolo resultó ser bastante ligero y confiable. Tanto como para manejar cualquier situación durante el despliegue.
¿Qué pasará después?
Ahora sobre los planes. Cualquier desarrollo importante en el proyecto Ignite se lleva a cabo como una iniciativa para mejorar Ignite, el llamado IEP. El rediseño de la red de servicio también tiene un IEP -
IEP No. 17 con el nombre de bromas "Cambio de aceite en la red de servicio". Pero, de hecho, no cambiamos el aceite del motor, sino todo el motor.
Dividimos las tareas en IEP en 2 fases. La primera es una fase importante, que consiste en alterar el protocolo de implementación. Ya está vertido en el asistente, puede probar el nuevo Service Grid, que aparecerá en la versión 2.8. La segunda fase incluye muchas otras tareas:
- Redención en caliente
- Servicio de versiones
- Mayor resistencia
- Cliente delgado
- Herramientas para monitorear y contar varias métricas
Finalmente, podemos aconsejarle a Service Grid para construir sistemas de alta disponibilidad tolerantes a fallas. También lo invitamos a
la lista de desarrolladores y la
lista de usuarios para compartir su experiencia. Su experiencia es realmente importante para la comunidad, lo ayudará a comprender a dónde ir a continuación, cómo desarrollar el componente en el futuro.