Hola A fines del año pasado, comenzamos a ocultar automáticamente los números de vehículos en fotografías en las tarjetas de anuncio de Avito. Sobre por qué hicimos esto, y cuáles son las formas de resolver tales problemas, lea el artículo.

Desafío
En Avito en 2018, se vendieron 2.5 millones de automóviles. Esto es casi 7000 por día. Todos los anuncios a la venta necesitan una ilustración: una foto de un automóvil. Pero por el número de estado en él, puede encontrar mucha información adicional sobre el automóvil. Y algunos de nuestros usuarios intentan cerrar la placa por su cuenta.
Las razones por las cuales los usuarios desean ocultar el número de placa pueden ser diferentes. Por nuestra parte, queremos ayudarlos a proteger sus datos. Y tratamos de mejorar los procesos de venta y compra para los usuarios. Por ejemplo, un servicio de números anónimos ha estado trabajando con nosotros durante mucho tiempo: cuando vende un automóvil, se crea un número celular temporal para usted. Bueno, para proteger los datos en las placas, anonimizamos las fotos.

Resumen de la solución
Para automatizar el proceso de protección de las fotos de los usuarios, puede usar redes neuronales convolucionales para detectar un polígono con una placa de matrícula.
Ahora, para la detección de objetos, se utilizan arquitecturas de dos grupos: redes de dos etapas, por ejemplo, Faster RCNN y Mask RCNN; Single-Stage (Singleshot) - SSD, YOLO, RetinaNet. La detección de un objeto es la derivación de las cuatro coordenadas del rectángulo en el que se inscribe el objeto de interés.
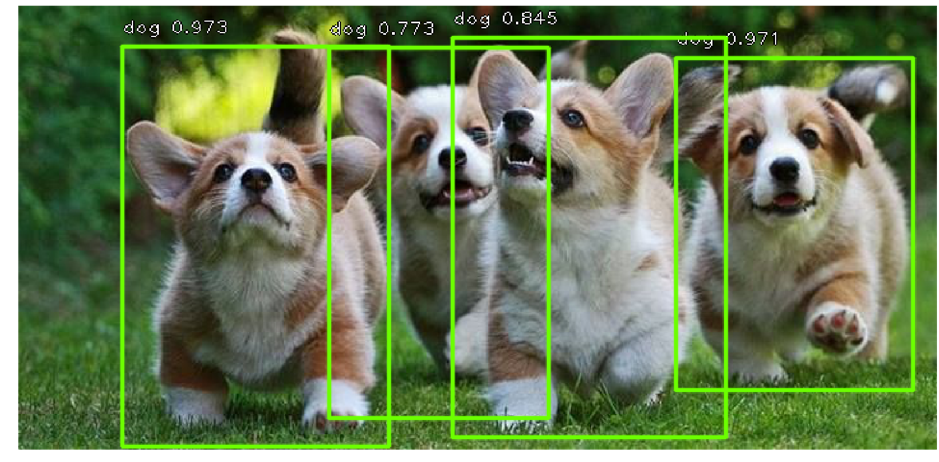
Las redes mencionadas anteriormente pueden encontrar muchos objetos de diferentes clases en imágenes, lo que ya es redundante para resolver el problema de búsqueda de matrículas, porque generalmente solo tenemos un automóvil en las imágenes (hay excepciones cuando las personas toman fotografías de su automóvil vendido y su vecino aleatorio) , pero esto ocurre muy raramente, por lo que esto podría descuidarse).
Otra característica de estas redes es que, por defecto, producen un cuadro delimitador con lados paralelos a los ejes de coordenadas. Esto sucede porque se utiliza un conjunto de tipos predefinidos de marcos rectangulares llamados cuadros de anclaje para la detección. Más precisamente, primero usando una red convolucional (por ejemplo, resnet34), se obtiene una matriz de atributos de la imagen. Luego, para cada subconjunto de atributos obtenidos usando la ventana deslizante, se produce una clasificación: hay un objeto para el cuadro de anclaje k o no, y se realiza una regresión en las cuatro coordenadas del marco, que ajustan su posición.
Lea más sobre esto
aquí .
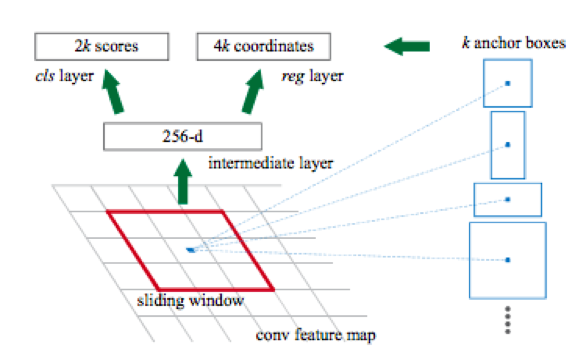
Después de eso, hay dos cabezas más:
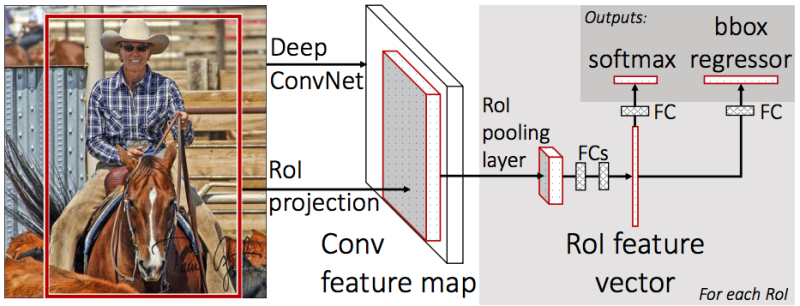
uno para clasificar el objeto (perro / gato / planta, etc.),
el segundo (regresor de bbox): para la regresión de las coordenadas del marco obtenido en el paso anterior para aumentar la relación del área del objeto al área del marco.
Para predecir el marco de boxeo girado, debe cambiar el regresor de bbox para que también obtenga el ángulo de rotación del marco. Si esto no se hace, entonces resultará de alguna manera.

Además del Faster R-CNN de dos etapas, hay detectores de una etapa, como RetinaNet. Se diferencia de la arquitectura anterior en que predice inmediatamente la clase y el marco, sin la etapa preliminar de proponer secciones de la imagen que pueden contener objetos. Para predecir las máscaras rotadas, también debe cambiar el encabezado de la subred del cuadro.
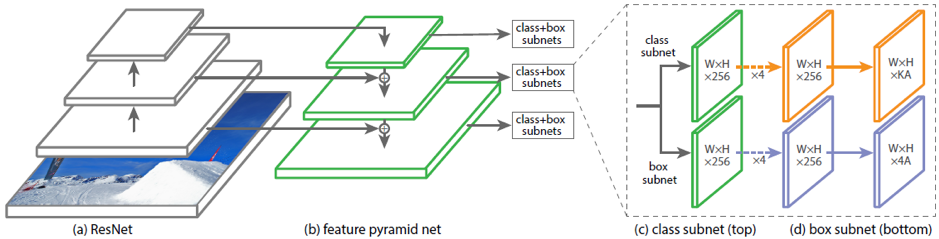
Un ejemplo de arquitecturas existentes para predecir cuadros delimitadores rotados es DRBOX. Esta red no utiliza la etapa preliminar de la propuesta de la región, como en RCNN más rápido; por lo tanto, es una modificación de los métodos de una etapa. Para entrenar esta red, se usa K rotado en ciertos ángulos. La red predice las probabilidades de que cada uno de K rbox contenga el objeto objetivo, las coordenadas, el tamaño de bbox y el ángulo de rotación.

Modificar la arquitectura y volver a entrenar una de las redes consideradas en los datos con cuadros delimitadores rotados es una tarea realizable. Pero nuestro objetivo se puede lograr más fácilmente, porque el alcance de la red que tenemos es mucho más limitado, solo para ocultar las placas.
Por lo tanto, decidimos comenzar con una red simple para predecir los cuatro puntos del número y, posteriormente, será posible complicar la arquitectura.
Datos
El ensamblaje del conjunto de datos se divide en dos pasos: para recolectar imágenes de automóviles y marcar el área con la placa de matrícula. La primera tarea ya se ha resuelto en nuestra infraestructura: almacenamos cuidadosamente todos los anuncios que se han colocado en Avito. Para resolver el segundo problema, usamos Toloka. En
toloka.yandex.ru/requester creamos una tarea:
La tarea dada una fotografía del coche. Es necesario resaltar la matrícula del automóvil utilizando un cuadrángulo. En este caso, el número de estado debe asignarse con la mayor precisión posible.

Con Toloka, puede crear tareas para marcar datos. Por ejemplo, evalúe la calidad de los resultados de búsqueda, marque diferentes clases de objetos (textos e imágenes), marque videos, etc. Los usuarios de Toloka los realizarán, por la tarifa que usted cobra. Por ejemplo, en nuestro caso, los tolokers deben resaltar el vertedero con el número de placa del automóvil en la foto. En general, es muy conveniente para marcar un gran conjunto de datos, pero obtener alta calidad es bastante difícil. Hay muchos robots en la multitud, cuya tarea es obtener dinero de usted dando respuestas al azar o utilizando algún tipo de estrategia. Para contrarrestar estos bots hay un sistema de reglas y controles. La verificación principal es la mezcla de preguntas de control: usted marca manualmente parte de las tareas utilizando la interfaz Toloki y luego las mezcla en la tarea principal. Si el marcado a menudo se confunde en las preguntas de control, lo bloquea y no tiene en cuenta el marcado.
Para la tarea de clasificación, es muy simple determinar si el marcado es incorrecto o no, y para el problema de resaltar una región, no es tan simple. La forma clásica es contar IoU.
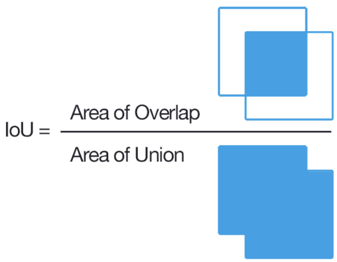
Si esta proporción es inferior a un cierto umbral para varias tareas, dicho usuario se bloquea. Sin embargo, para dos cuadrángulos arbitrarios, calcular IoU no es tan simple, especialmente porque en Tolok es necesario implementar esto en JavaScript. Hicimos un pequeño truco, y creemos que el usuario no se equivocó si para cada punto del polígono fuente en un vecindario pequeño hay un punto marcado con un escriba. También hay una regla de respuesta rápida para bloquear usuarios que responden demasiado rápido, captcha, discrepancia con la opinión de la mayoría, etc. Una vez configuradas estas reglas, puede esperar un marcado bastante bueno, pero si realmente necesita un marcado complejo y de alta calidad, debe contratar específicamente a escritores independientes. Como resultado, nuestro conjunto de datos ascendió a 4k imágenes marcadas, y todo costó $ 28 en Tolok.
Modelo
Ahora hagamos una red para predecir los cuatro puntos del área. Obtendremos los signos usando resnet18 (11.7M parámetros versus 21.8M parámetros para resnet34), luego haremos una cabeza para la regresión a cuatro puntos (ocho coordenadas) y una cabeza para la clasificación si hay una placa en la imagen o no. Se necesita la segunda cabeza, porque en los anuncios para la venta de automóviles, no todas las fotos con automóviles. La foto puede ser un detalle del automóvil.

Similar a nosotros, por supuesto, no es necesario detectarlo.
Entrenamos dos objetivos al mismo tiempo agregando al conjunto de datos una foto sin una placa con un cuadro delimitador (0,0,0,0,0,0,0,0,0) y un valor para el clasificador "imagen con / sin placa" - (0, 1)
Luego puede crear una función de pérdida única para ambos objetivos como la suma de las siguientes pérdidas. Para la regresión a las coordenadas del polígono de matrícula, usamos una pérdida L1 suave.
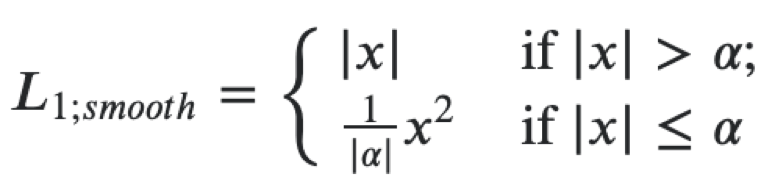
Se puede interpretar como una combinación de L1 y L2, que se comporta como L1 cuando el valor absoluto del argumento es grande y como L2 cuando el valor del argumento es cercano a cero. Para la clasificación, utilizamos softmax y pérdida por crossentropía. El extractor de funciones es resnet18, usamos pesos pre-entrenados en ImageNet, luego entrenaremos más el extractor y los cabezales en nuestro conjunto de datos. En este problema, utilizamos el framework mxnet, ya que es el principal para la visión por computadora en Avito. En general, la arquitectura de microservicio le permite no estar vinculado a un marco específico, pero cuando tiene una base de código grande, es mejor usarlo y no volver a escribir el mismo código.
Habiendo recibido una calidad aceptable en nuestro conjunto de datos, recurrimos a los diseñadores para obtener una placa con el logotipo de Avito. Al principio intentamos hacerlo nosotros mismos, por supuesto, pero no se veía muy hermoso. A continuación, debe cambiar el brillo de la placa de matrícula de Avito al brillo del área original con la placa de matrícula y puede superponer el logotipo en la imagen.

Lanzamiento en prod
El problema de la reproducibilidad de los resultados, el soporte y el desarrollo de proyectos, resuelto con algún error en el mundo del desarrollo de backend y frontend, sigue abierto cuando se requiere el uso de modelos de aprendizaje automático. Probablemente tenías que entender el modelo de código heredado. Es bueno si el archivo Léame tiene enlaces a artículos o repositorios de código abierto en los que se basó la solución. El script para iniciar el reentrenamiento puede fallar con errores, por ejemplo, la versión de cudnn ha cambiado, y esa versión de tensorflow ya no funciona con esta versión de cudnn, y cudnn ya no funciona con esta versión de controladores nvidia. Quizás para el entrenamiento usamos un iterador de acuerdo con los datos, y para probar en producción otro. Esto puede continuar por bastante tiempo. En general, existen problemas de reproducibilidad.
Intentamos eliminarlos utilizando el entorno nvidia-docker para modelos de entrenamiento, tiene todas las dependencias necesarias para cuda, y también instalamos dependencias para python allí. La versión de la biblioteca con un iterador de acuerdo con los datos, los aumentos y los modelos de inferencia es común para la etapa de capacitación / experimentación y para la producción. Por lo tanto, para entrenar el modelo en nuevos datos, debe bombear el repositorio al servidor, ejecutar el script de shell que recopilará el entorno de Docker, dentro del cual se levantará el cuaderno Jupyter. En el interior, tendrá todas las computadoras portátiles para capacitación y pruebas, que ciertamente no fallarán con un error debido al entorno. Es mejor, por supuesto, tener un archivo train.py, pero la práctica muestra que siempre debe mirar con los ojos lo que el modelo le da y cambiar algo en el proceso de aprendizaje, por lo que al final aún ejecutará jupyter.
Los pesos de los modelos se almacenan en git lfs: esta es una tecnología especial para almacenar archivos grandes en un git. Antes de eso, usábamos artefactos, pero usar git lfs es más conveniente, porque al descargar el repositorio con el servicio, obtienes de inmediato la versión actual de la balanza, como en la producción. Las pruebas automáticas se escriben para la inferencia del modelo, por lo que no podrá implementar un servicio con pesos que no los superen. El servicio en sí se inicia en la ventana acoplable dentro de la infraestructura de microservicios en el clúster de kubernetes. Para controlar el rendimiento, utilizamos grafana. Después de la implementación, aumentamos gradualmente la carga en las instancias de servicio con un nuevo modelo. Al implementar una nueva función, creamos pruebas a / b y emitimos un veredicto sobre el destino futuro de la función, en base a pruebas estadísticas.
Como resultado: lanzamos el glosado de números en anuncios en la categoría automática para comerciantes privados, el percentil 95 del tiempo de procesamiento de una imagen para ocultar el número es de 250 ms.