La gente aprende arquitectura de viejos libros que fueron escritos para Java. Los libros son buenos, pero proporcionan una solución a los problemas de esa época con instrumentos de esa época. El tiempo ha cambiado, C # es más similar a Light Scala que Java, y hay pocos libros nuevos y buenos.
En este artículo, examinaremos los criterios para el código bueno y el código malo, cómo y qué medir. Veremos una descripción general de las tareas y enfoques típicos, analizaremos los pros y los contras. Al final habrá recomendaciones y mejores prácticas para diseñar aplicaciones web.
Este artículo es una transcripción de mi informe de la conferencia DotNext 2018 Moscú. Además del texto, hay un video y un enlace a las diapositivas debajo del corte.

Diapositivas y página del informe en el sitio .
Brevemente sobre mí: soy de Kazán, trabajo para High Tech Group. Estamos desarrollando software para empresas. Recientemente, he estado impartiendo un curso en la Universidad Federal de Kazan llamado Desarrollo de software corporativo. De vez en cuando sigo escribiendo artículos sobre Habr sobre prácticas de ingeniería, sobre el desarrollo de software empresarial.
Como probablemente haya adivinado, hoy hablaré sobre el desarrollo de software empresarial, a saber, cómo estructurar aplicaciones web modernas:
- los criterios
- una breve historia del desarrollo del pensamiento arquitectónico (qué fue, qué se convirtió, qué problemas son);
- Resumen de los defectos de la arquitectura clásica de hojaldre
- la decision
- análisis paso a paso de la implementación sin sumergirse en detalles
- resultados.
Criterios
Formulamos los criterios. Realmente no me gusta cuando hablar de diseño es al estilo de "mi kung fu es más fuerte que tu kung fu". Una empresa tiene, en principio, un criterio específico llamado dinero. Todos saben que el tiempo es dinero, por lo que estos dos componentes suelen ser los más importantes.

Entonces, los criterios. En principio, la empresa nos pide con mayor frecuencia "tantas funciones como sea posible por unidad de tiempo", pero con una advertencia: estas funciones deberían funcionar. Y el primer paso donde podría romperse es la revisión del código. Es decir, parece que el programador dijo: "Lo haré en tres horas". Pasaron tres horas, la revisión entró en el código y el líder del equipo dijo: "Oh, no, rehaga". Hay tres más, y cuántas iteraciones ha pasado la revisión del código, tanto que necesita multiplicar tres horas.
El siguiente punto es el regreso de la etapa de prueba de aceptación. Lo mismo Si la función no funciona, entonces no se hace, estas tres horas se extienden durante una semana, dos, bueno, como de costumbre. El último criterio es el número de regresiones y errores, que sin embargo, a pesar de las pruebas y la aceptación, pasaron por la producción. Esto también es muy malo. Hay un problema con este criterio. Es difícil de rastrear, porque la conexión entre el hecho de que empujamos algo al repositorio y el hecho de que algo se rompió después de dos semanas puede ser difícil de rastrear. Pero, sin embargo, es posible.
Desarrollo de la arquitectura
Érase una vez, cuando los programadores comenzaban a escribir programas, todavía no había arquitectura, y todos hicieron todo lo que quisieron.

Por lo tanto, tenemos un estilo tan arquitectónico. Esto se llama "código de fideos" aquí, dicen "código de espagueti" en el extranjero. Todo está conectado con todo: cambiamos algo en el punto A: se rompe en el punto B, es completamente imposible entender qué está conectado con qué. Naturalmente, los programadores se dieron cuenta rápidamente de que esto no funcionaría, y había que hacer alguna estructura, y decidieron que algunas capas nos ayudarían. Ahora, si imagina que la carne picada es código, y la lasaña es tales capas, aquí hay una ilustración de la arquitectura en capas. La carne picada permaneció picada, pero ahora la carne picada de la capa No. 1 no puede simplemente ir y hablar con la carne picada de la capa No. 2. Le dimos alguna forma al código: incluso en la imagen se puede ver que la escalada está más enmarcada.
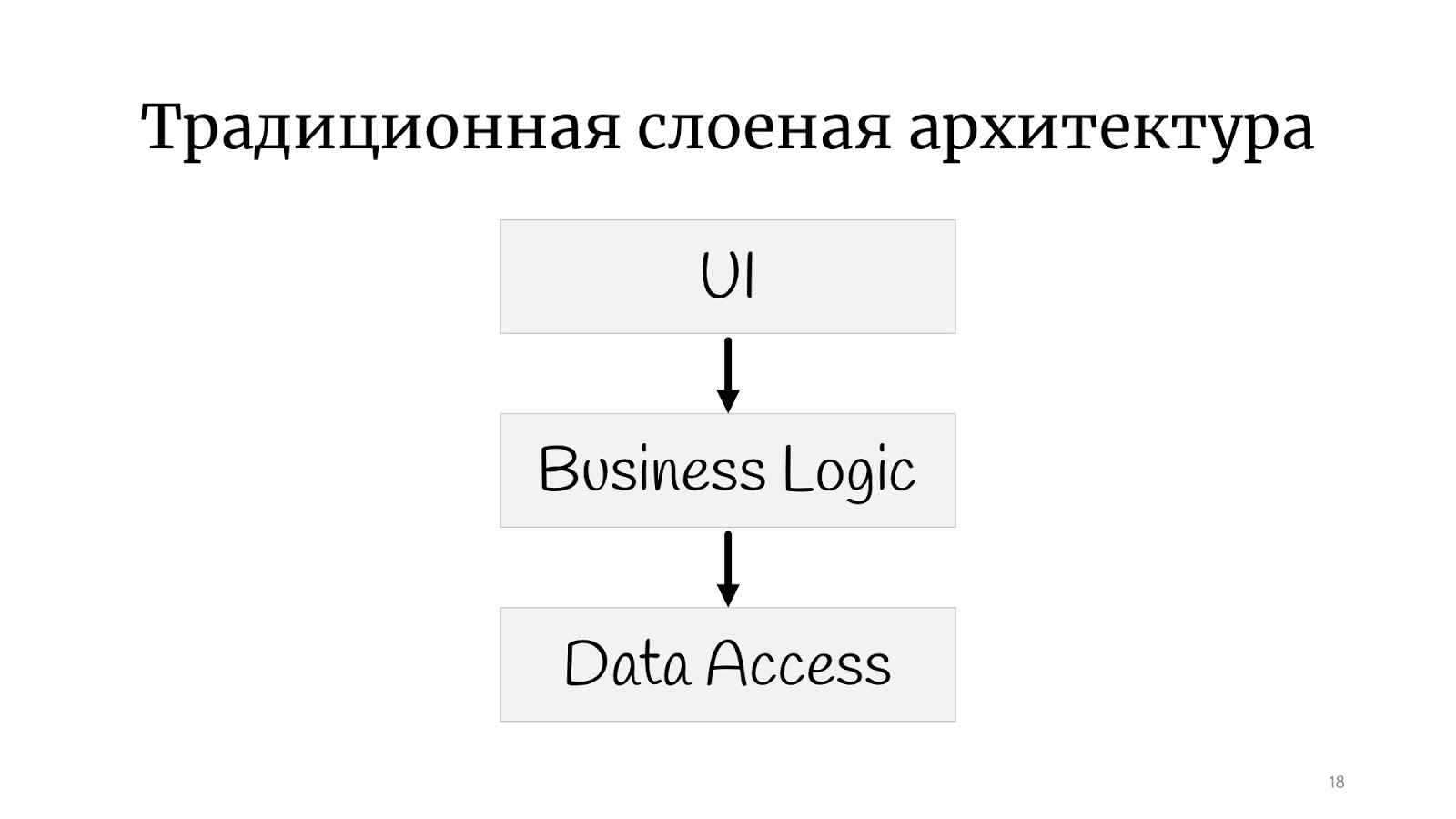
Probablemente todos estén familiarizados con la
arquitectura clásica en capas : hay una interfaz de usuario, hay una lógica de negocios y hay una capa de acceso a datos. Todavía hay todo tipo de servicios, fachadas y capas, nombrados por el arquitecto que dejó la empresa, puede haber un número ilimitado de ellos.

La siguiente etapa fue la llamada
arquitectura de cebolla . Parecería que hay una gran diferencia: antes había un pequeño cuadrado, y aquí había círculos. Parece ser completamente diferente.
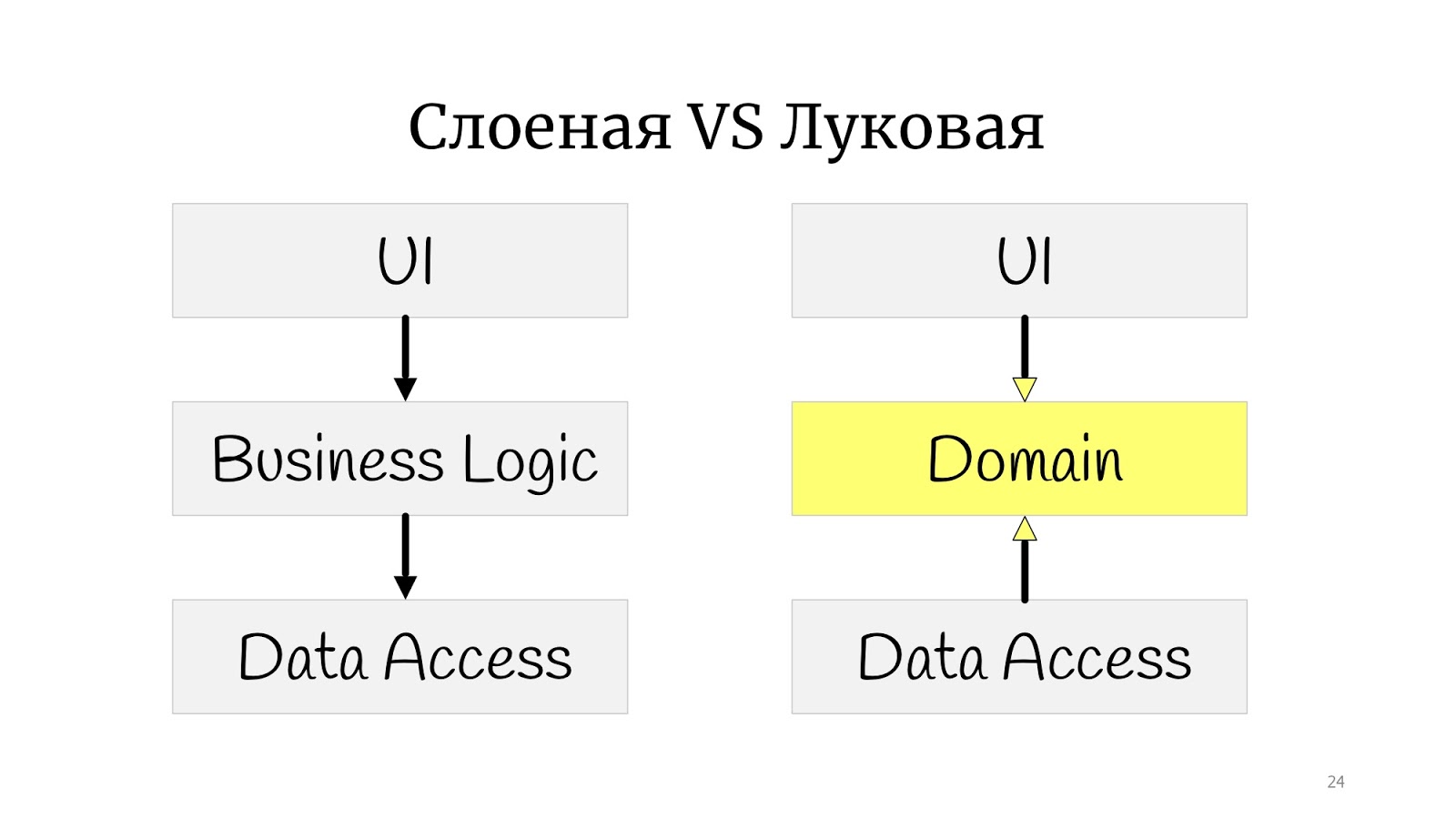
En realidad no La diferencia es que en algún momento en ese momento se formularon los principios de SOLID, y resultó que en la cebolla clásica hay un problema con la inversión de dependencia, porque el código de dominio abstracto por alguna razón depende de la implementación, en Data Access, por lo que decidimos implementar Data Access y tener acceso a datos dependen del dominio.

Aquí practiqué el dibujo y dibujé la arquitectura de la cebolla, pero no de forma clásica con los "anillos". Tengo algo entre un polígono y círculos. Hice esto para mostrar simplemente que si te encuentras con las palabras "cebolla", "hexagonal" o "puertos y adaptadores", todos son lo mismo. El punto es que el dominio está en el centro, está envuelto en servicios, pueden ser servicios de dominio o aplicación, como lo desee. Y el mundo exterior en forma de interfaz de usuario, pruebas e infraestructura donde DAL se mudó: se comunican con el dominio a través de esta capa de servicio.
Un simple ejemplo. Actualización por correo electrónico
Veamos cómo se vería un caso de uso simple en tal paradigma: actualizar la dirección de correo electrónico del usuario.
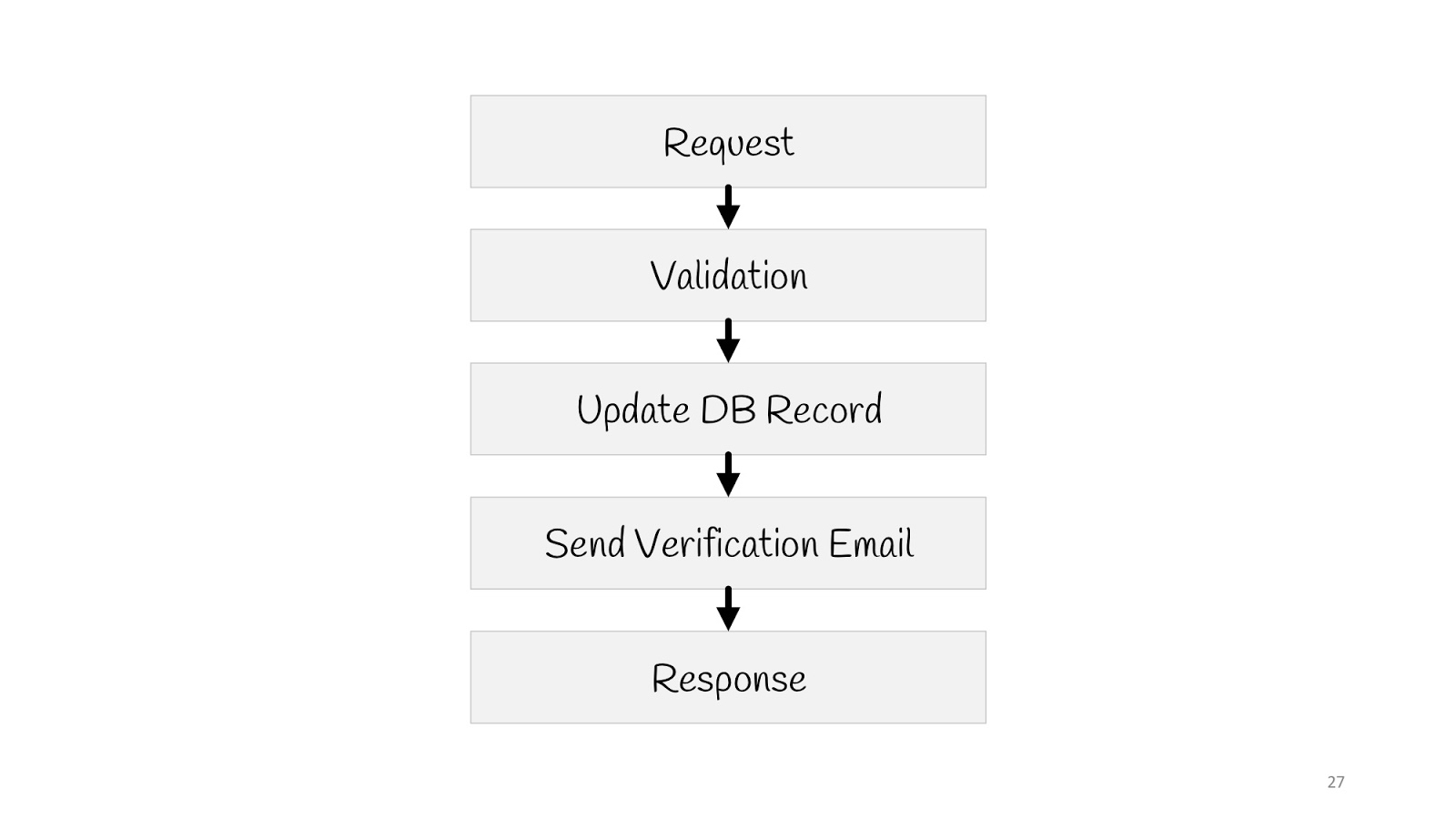
Necesitamos enviar una solicitud, validar, actualizar el valor en la base de datos, enviar una notificación a un nuevo correo electrónico: "Todo está en orden, usted cambió su correo electrónico, sabemos que todo está bien" y responder al navegador "200": todo está bien.
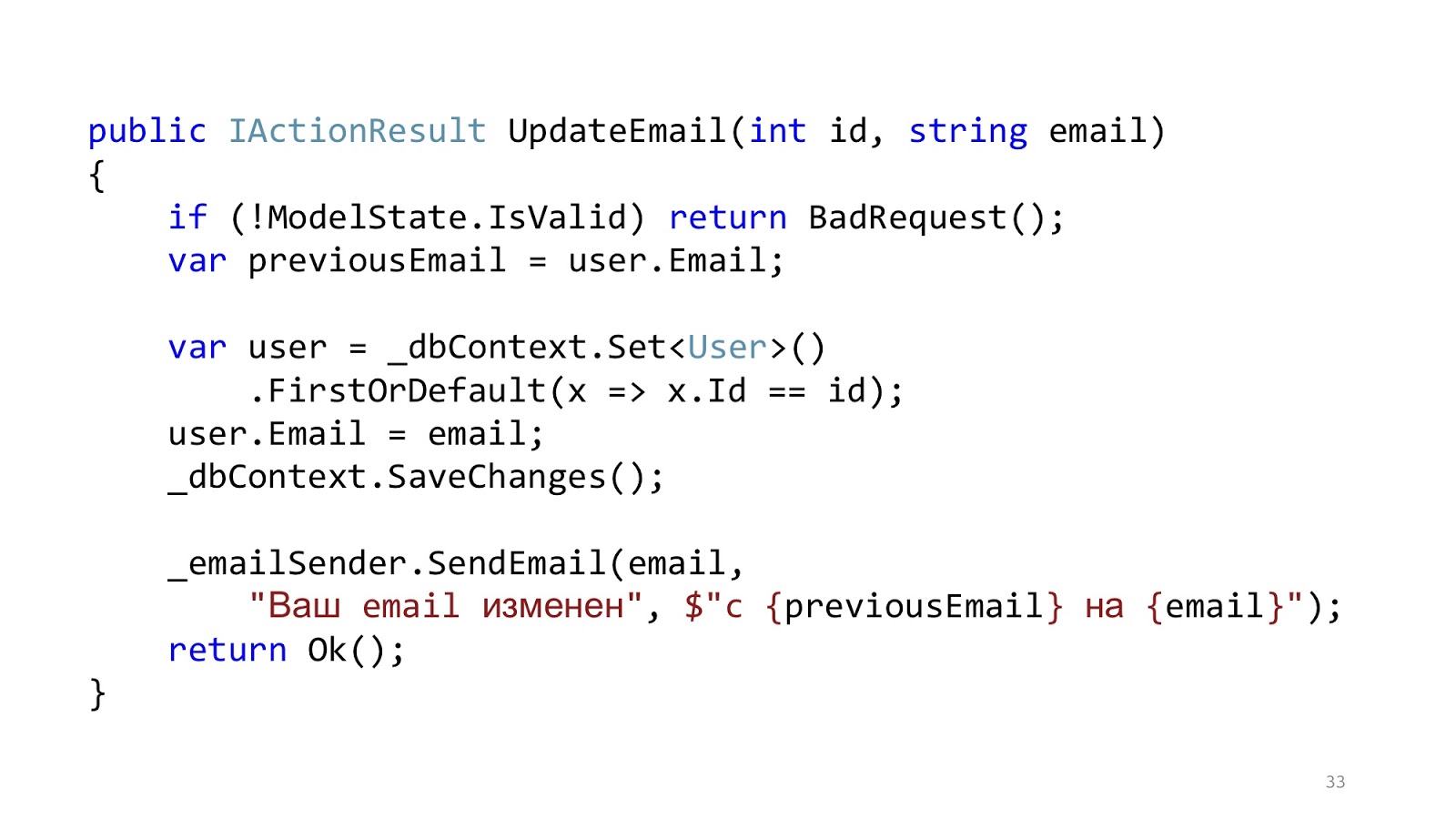
El código puede verse más o menos así. Aquí tenemos la validación estándar de
ASP.NET MVC, hay ORM para leer y actualizar los datos, y hay algún tipo de remitente de correo electrónico que envía una notificación. Parece que todo está bien, ¿verdad? Una advertencia: en un mundo ideal.
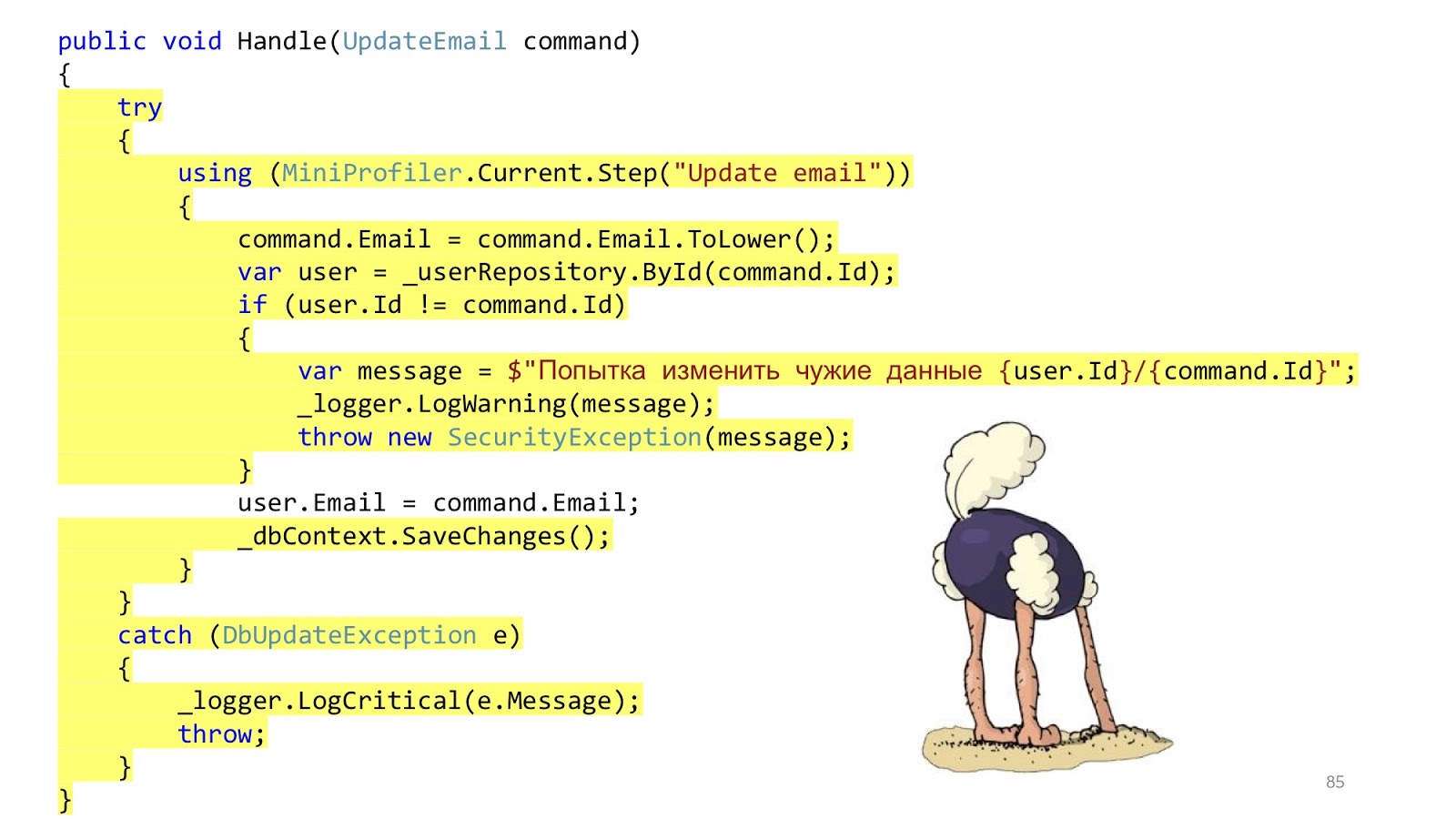
En el mundo real, la situación es ligeramente diferente. El punto es agregar autorización, verificación de errores, formateo, registro y creación de perfiles. Todo esto no tiene nada que ver con nuestro caso de uso, pero debería serlo. Y ese pequeño fragmento de código se hizo grande y aterrador: con mucho anidamiento, con mucho código, con el hecho de que es difícil de leer, y lo más importante, que hay más código de infraestructura que código de dominio.

"¿Dónde están los servicios?" - usted dice Escribí toda la lógica a los controladores. Por supuesto, esto es un problema, ahora agregaré servicios y todo estará bien.

Agregamos servicios, y realmente mejora, porque en lugar de un gran calzado, tenemos una pequeña línea hermosa.
¿Ha mejorado? Se ha convertido! Y ahora podemos reutilizar este método en diferentes controladores. El resultado es obvio. Veamos la implementación de este método.
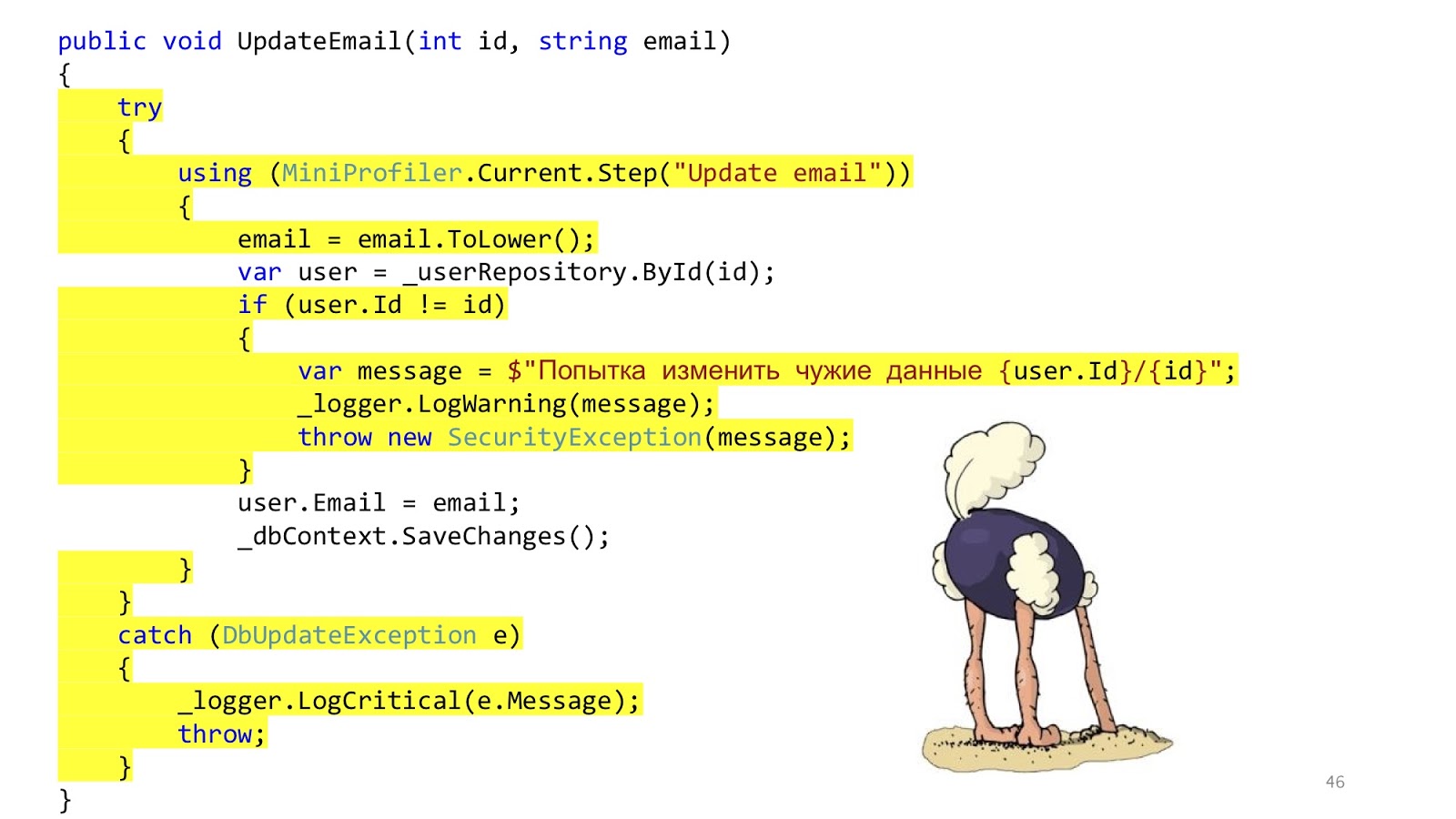
Pero aquí no todo es tan bueno. Este código todavía está aquí. Acabamos de transferir lo mismo a los servicios. Decidimos no resolver el problema, sino simplemente disfrazarlo y transferirlo a otro lugar. Eso es todo

Además de esto, surgen algunas otras preguntas. ¿Deberíamos hacer la validación en el controlador o aquí? Bueno, algo así como en el controlador. ¿Y si necesita ir a la base de datos y ver que existe una ID de este tipo o que no hay otro usuario con ese correo electrónico? Hmm, bueno, entonces en el servicio. ¿Pero el manejo de errores aquí? Este manejo de errores probablemente esté aquí, y el manejo de errores que responderá al navegador en el controlador. Y el método SaveChanges, ¿está en el servicio o necesita transferirlo al controlador? Puede ser así, porque si se llama a un servicio, es más lógico llamar al servicio, y si tiene tres métodos de servicios en el controlador que deben llamarse, entonces debe llamarlo fuera de estos servicios para que la transacción sea uno. Estas reflexiones sugieren que quizás las capas no resuelven ningún problema.

Y esta idea se le ocurrió a más de una persona. Si buscas en Google, al menos tres de estos maridos respetables escriben sobre lo mismo. De arriba a abajo: Stephen .NET Junkie (desafortunadamente, no sé su apellido, porque no aparece en ningún lugar de Internet), el autor del contenedor
Simple Injector IoC. Siguiente Jimmy Bogard es el autor de
AutoMapper . Y abajo está Scott Vlashin, autor de
F # por diversión y ganancias .
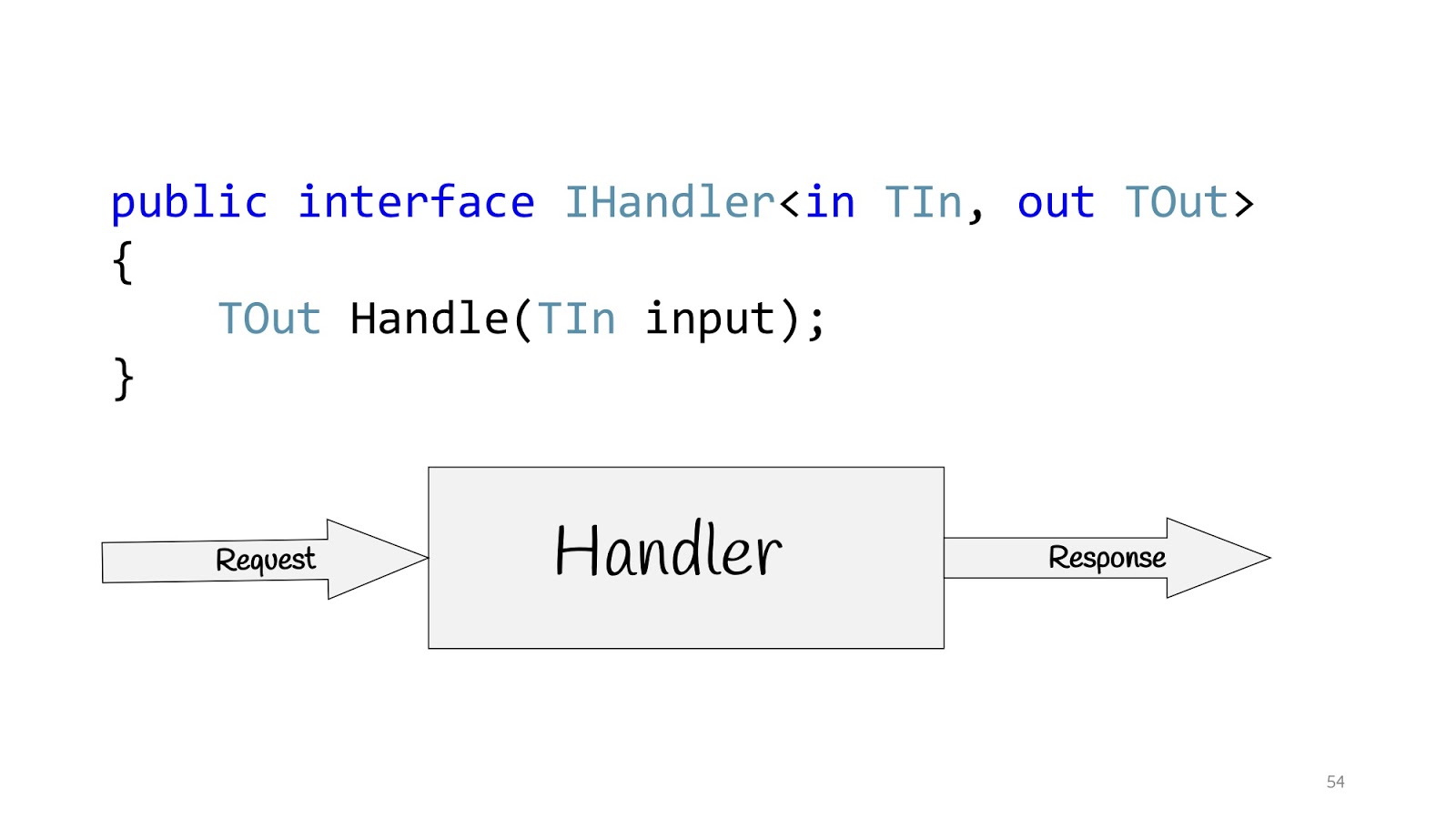
Todas estas personas están hablando de lo mismo y sugieren construir aplicaciones no sobre la base de capas, sino sobre la base de casos de uso, es decir, aquellos requisitos que la empresa nos solicita. En consecuencia, el caso de uso en C # se puede determinar utilizando la interfaz IHandler. Tiene valores de entrada, hay valores de salida y hay un método en sí mismo que realmente ejecuta este caso de uso.

Y dentro de este método puede haber un modelo de dominio o algún tipo de modelo desnormalizado para leer, tal vez usando Dapper o Elastic Search, si necesita buscar algo, y tal vez tenga Legacy -sistema con procedimientos almacenados, no hay problema, así como solicitudes de red, bueno, en general, cualquier cosa que pueda necesitar allí. Pero si no hay capas, ¿qué hacer?

Para comenzar, eliminemos UserService. Eliminamos el método y creamos una clase. Y lo eliminaremos, y lo eliminaremos nuevamente. Y luego tomar y eliminar la clase.

Pensemos, ¿son estas clases equivalentes o no? La clase GetUser devuelve datos y no cambia nada en el servidor. Esto, por ejemplo, sobre la solicitud "Dame la ID de usuario". Las clases UpdateEmail y BanUser devuelven el resultado de la operación y cambian el estado. Por ejemplo, cuando le decimos al servidor: "Cambie el estado, debe cambiar algo".
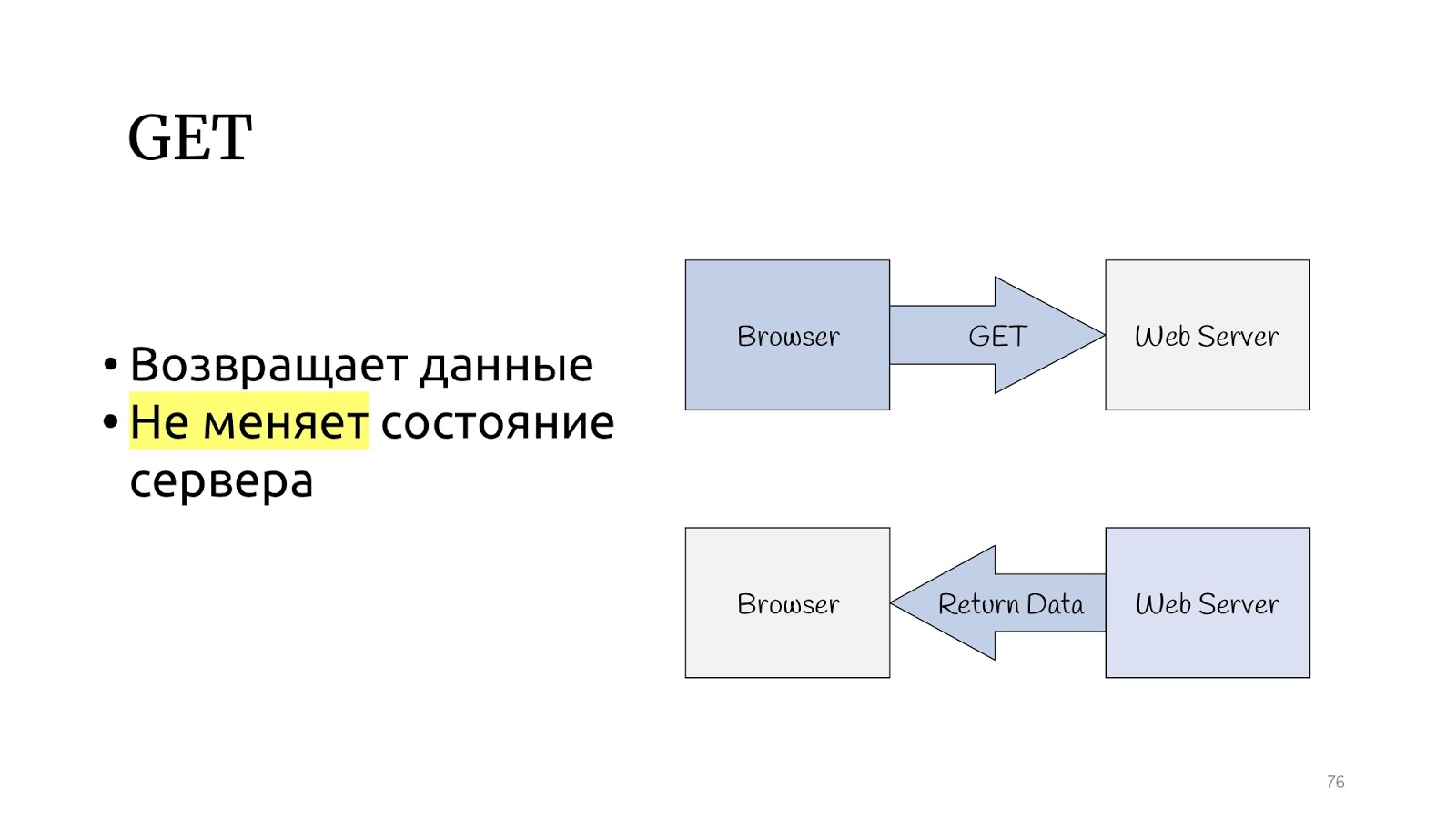
Veamos el protocolo HTTP. Existe un método GET que, de acuerdo con la especificación del protocolo HTTP, debe devolver datos y no cambiar el estado del servidor.

Y hay otros métodos que pueden cambiar el estado del servidor y devolver el resultado de la operación.

El paradigma CQRS parece estar diseñado específicamente para el protocolo HTTP. Las consultas son operaciones GET y los comandos PUT, POST, DELETE, sin necesidad de inventar nada.
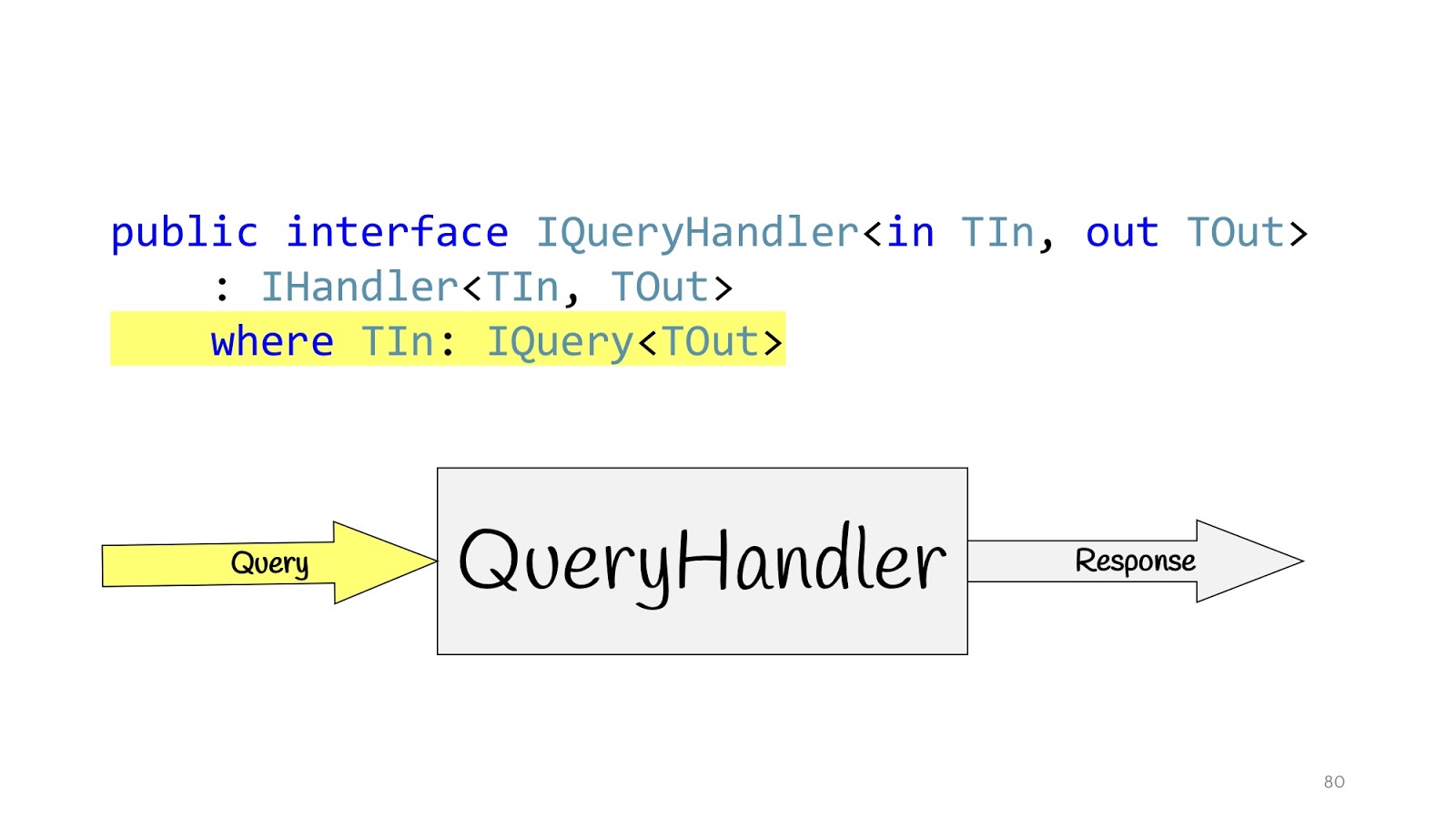
Redefinimos nuestro controlador y definimos interfaces adicionales. IQueryHandler, que solo difiere en que colgamos la restricción de que el tipo de valores de entrada es IQuery. IQuery es una interfaz de marcador, no tiene nada más que este genérico. Necesitamos el genérico para poner restricciones en el QueryHandler, y ahora, al declarar QueryHandler, no podemos pasar allí, no Query, pero al pasar el objeto Query allí, sabemos su valor de retorno. Esto es conveniente si solo tiene una interfaz, por lo que no tiene que buscar su implementación en el código, y nuevamente para no equivocarse. Escribe IQueryHandler, escribe una implementación allí, y en TOut no puede sustituir otro tipo de valor de retorno. Simplemente no se compila. Por lo tanto, puede ver de inmediato qué valores de entrada corresponden a qué datos de entrada.

La situación es completamente similar para CommandHandler con una excepción: este genérico es necesario para un truco más, que veremos un poco más adelante.
Implementación del controlador
Los controladores, anunciamos, ¿cuál es su implementación?
¿Hay algún problema, sí? Algo parece haber fallado.
Los decoradores corren al rescate
Pero no ayudó, porque todavía estamos en el medio del camino, necesitamos finalizar un poco más, y esta vez necesitamos usar el patrón
decorador , es decir, su maravillosa característica de diseño. El decorador se puede envolver en un decorador, envolver en un decorador, envolver en un decorador; continúe hasta que se aburra.
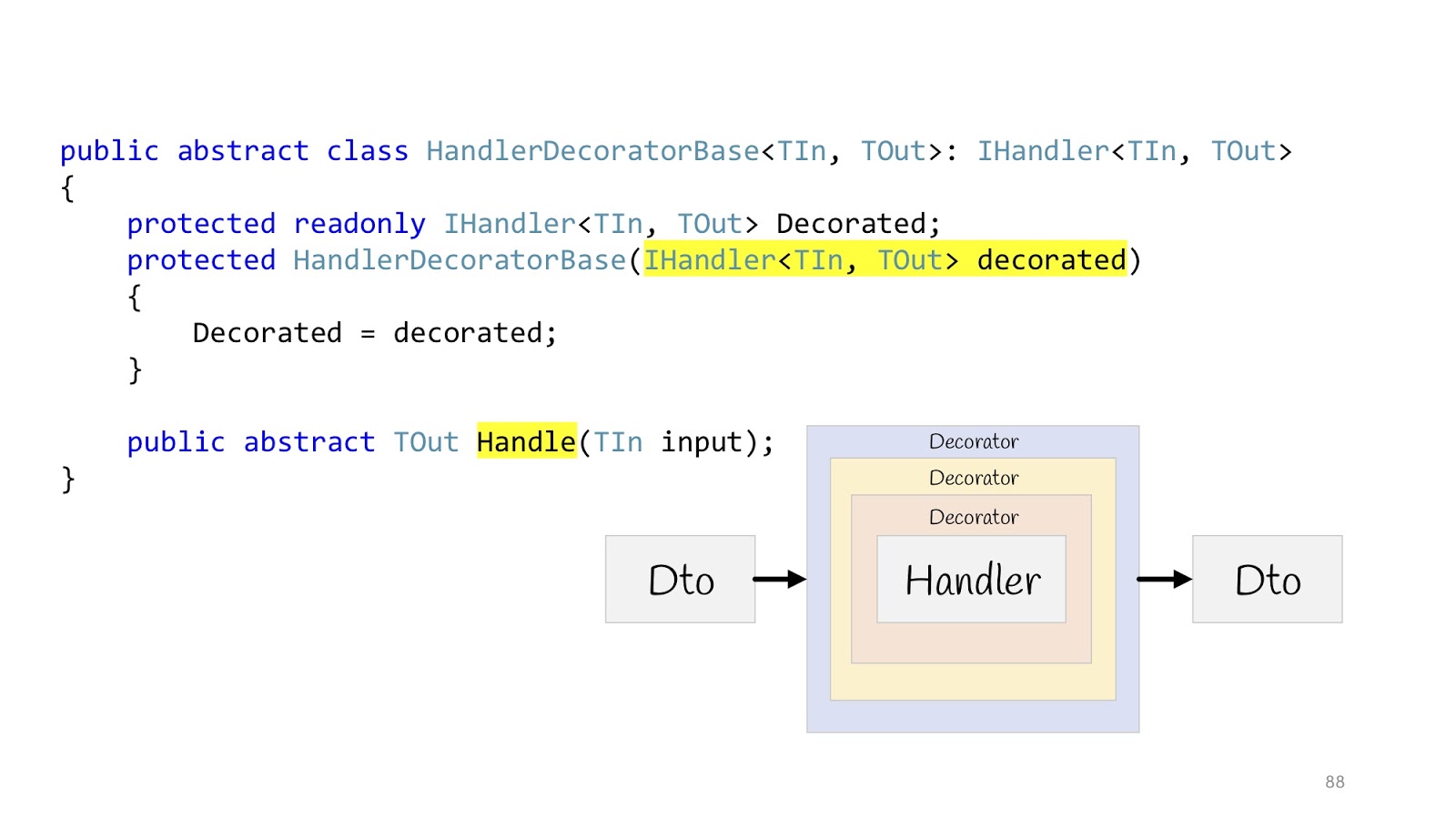
Entonces todo se verá así: hay una entrada Dto, ingresa al primer decorador, el segundo, el tercero, luego entramos en Handler y también salimos, pasamos por todos los decoradores y regresamos Dto en el navegador. Declaramos una clase base abstracta para luego heredar, el cuerpo de Handler se pasa al constructor y declaramos el método Handle abstracto, en el que se colgará la lógica decoradora adicional.
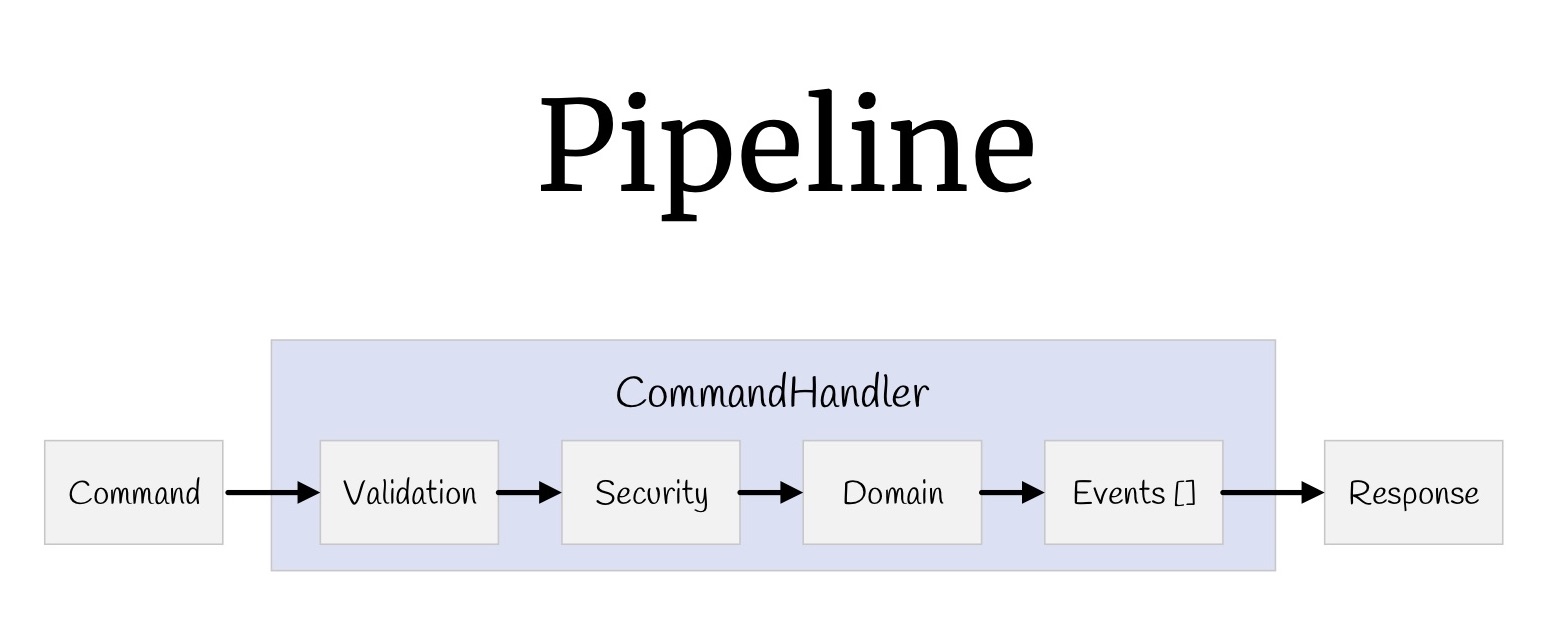
Ahora, con la ayuda de decoradores, puede construir una tubería completa. Comencemos con los equipos. Que tuvimos Valores de entrada, validación, verificación de derechos de acceso, la lógica en sí misma, algunos eventos que ocurren como resultado de esta lógica y valores de retorno.

Comencemos con la validación. Declaramos un decorador. IEnumerable de los validadores de tipo T entra en el constructor de este decorador. Los ejecutamos todos, verificamos si la validación falla y el tipo de retorno es
IEnumerable<validationresult> , luego podemos devolverlo porque los tipos coinciden. Y si se trata de otro Hander, entonces tienes que lanzar una Excepción, porque aquí no hay ningún resultado, el tipo de otro valor de retorno.
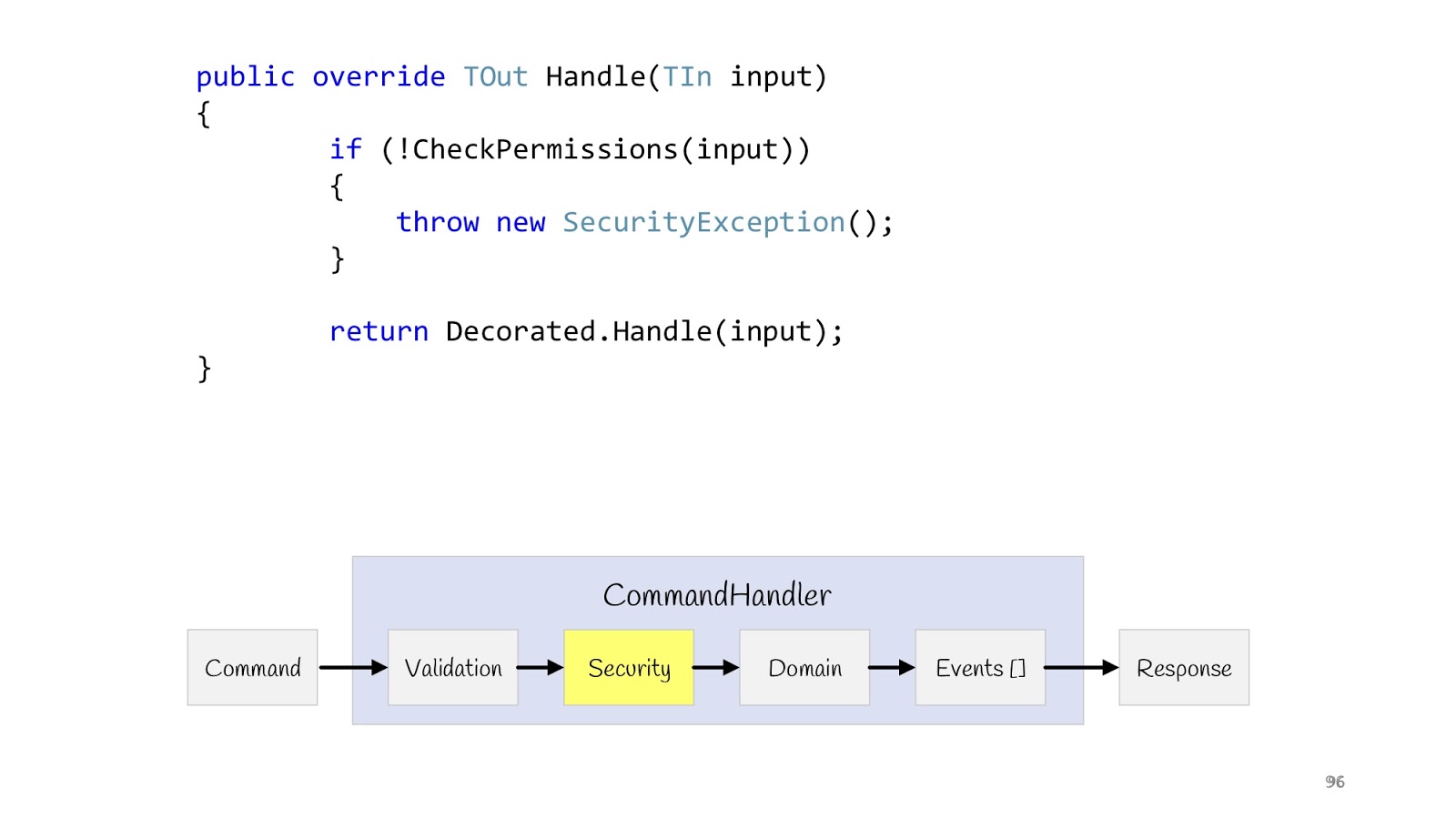
El siguiente paso es la seguridad. También declaramos el decorador, hacemos el método CheckPermission y verificamos. Si de repente algo salió mal, todo, no continuamos. Ahora, después de haber completado todas las verificaciones y estar seguros de que todo está bien, podemos cumplir con nuestra lógica.
Antes de mostrar la implementación de la lógica, quiero comenzar un poco antes, es decir, con los valores de entrada que vienen allí.
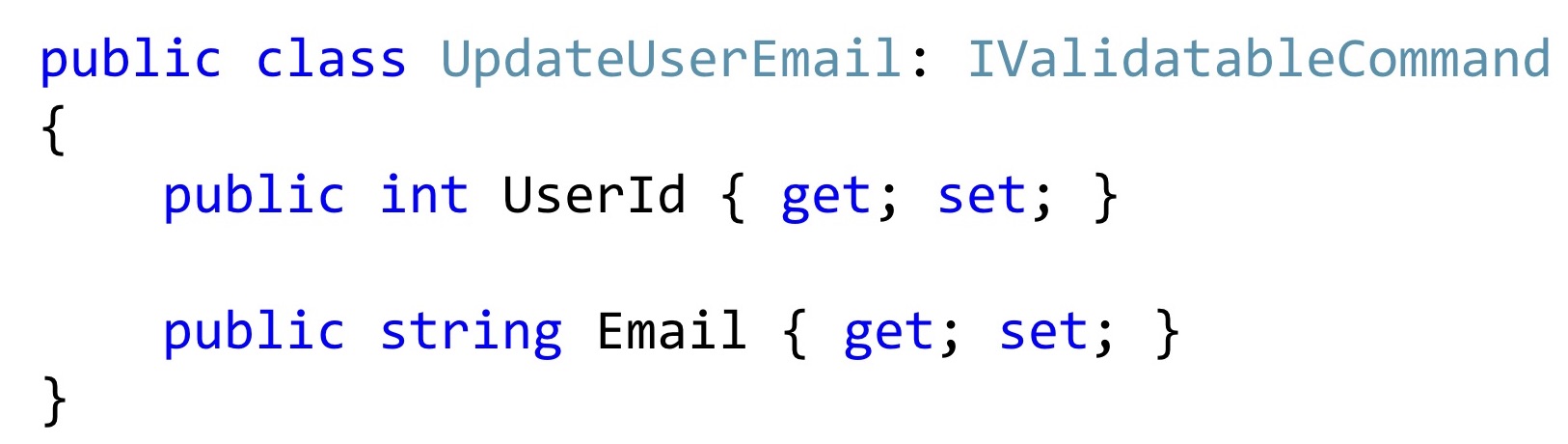
Ahora, si seleccionamos una clase de este tipo, la mayoría de las veces puede verse así. Al menos el código que veo en el trabajo diario.
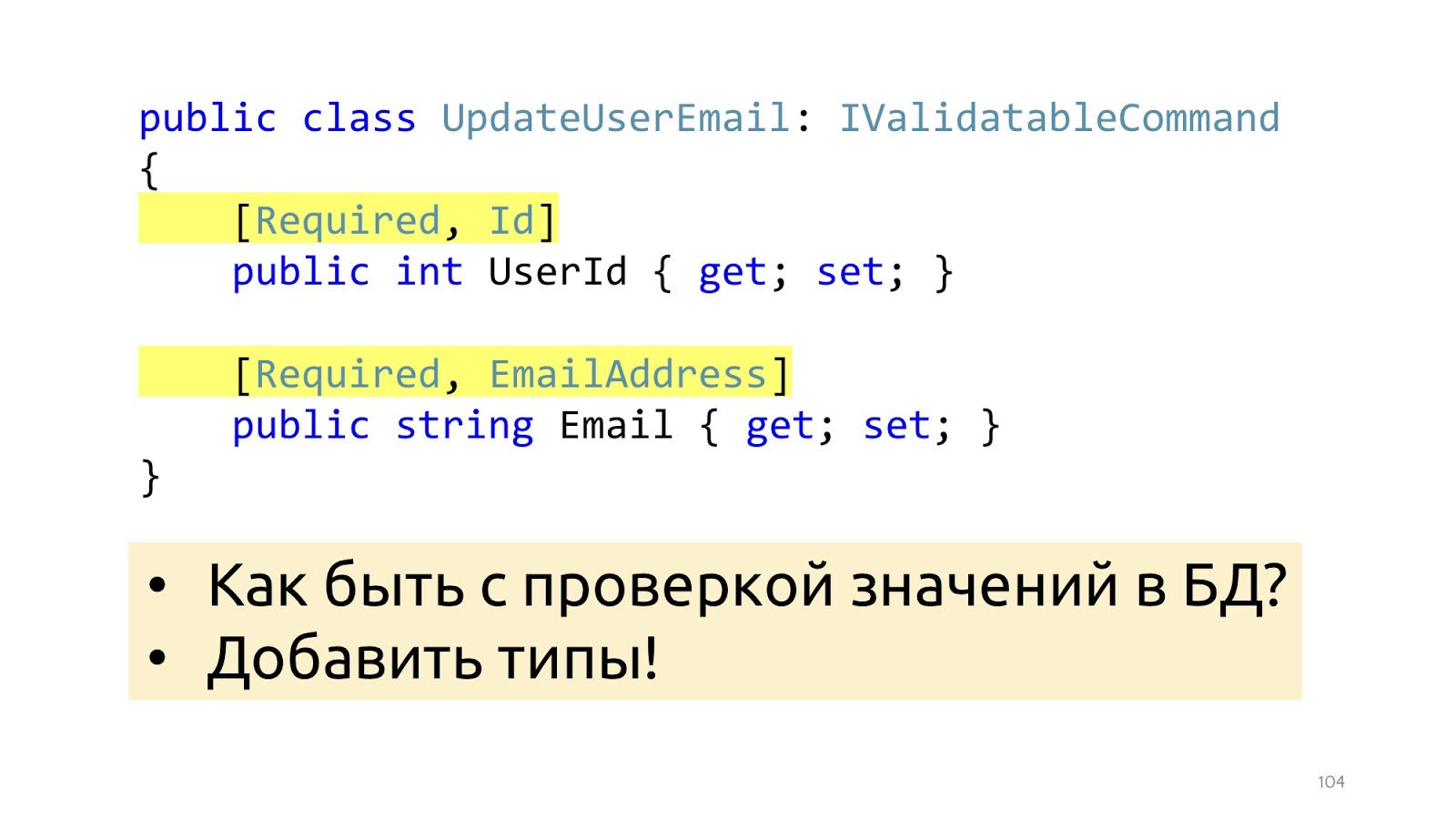
Para que la validación funcione, agregamos algunos atributos aquí que le indican qué tipo de validación es. Esto ayudará desde el punto de vista de la estructura de datos, pero no ayudará con la validación como verificar los valores en la base de datos. Es solo EmailAddress, no está claro cómo, dónde verificar cómo usar estos atributos para ir a la base de datos. En lugar de atributos, puede ir a tipos especiales, luego se resolverá este problema.

En lugar de la primitiva
int , declaramos un tipo de Id que tiene un genérico que es una determinada entidad con una clave int. O bien pasamos esta entidad al constructor, o pasamos su Id, pero al mismo tiempo debemos pasar una función que por Id puede tomar y devolver, verificar si es nula o no nula.
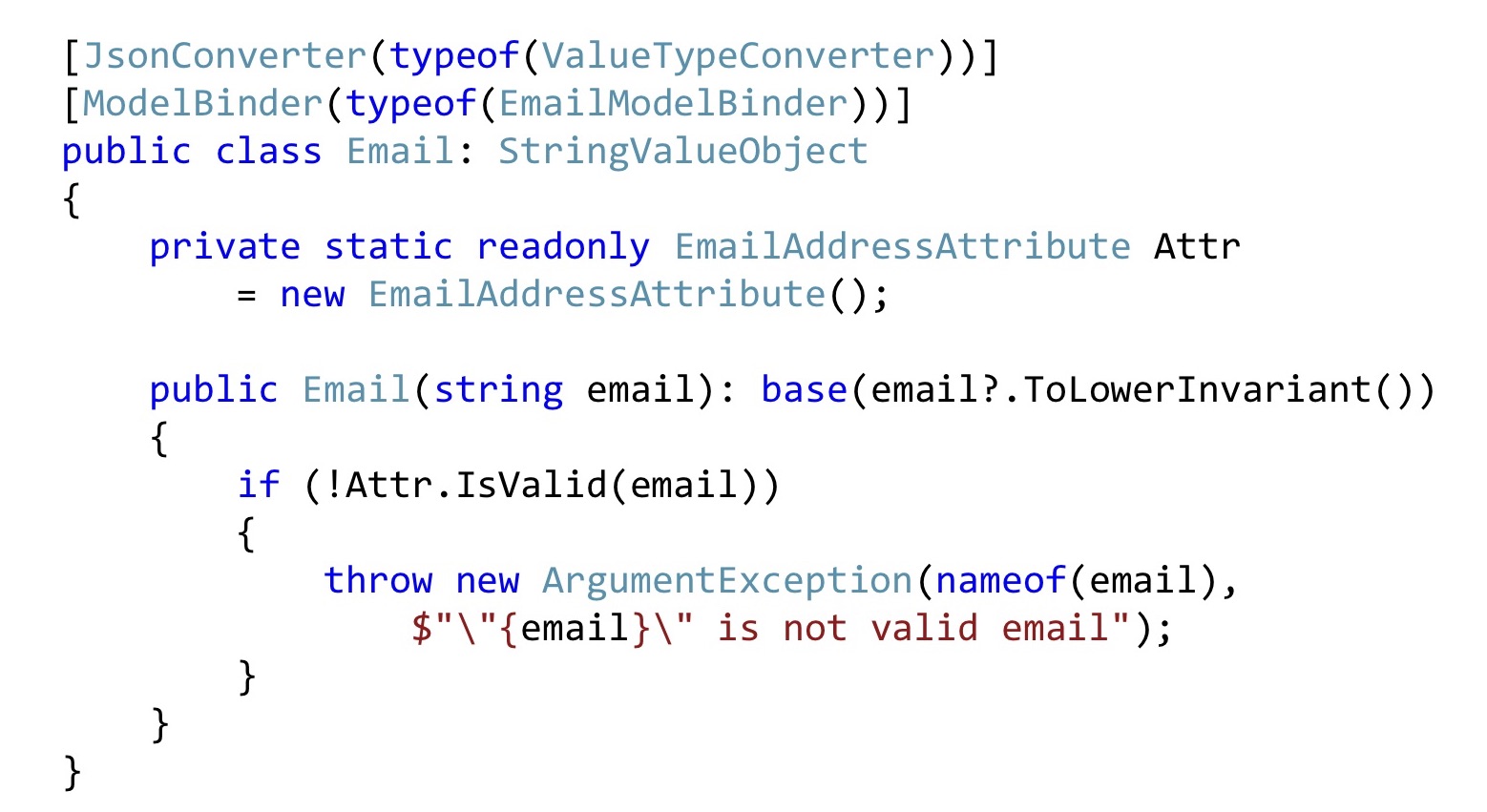
Hacemos lo mismo con el correo electrónico. Convierta todos los correos electrónicos a la línea de fondo para que todo se vea igual para nosotros. A continuación, tomamos el atributo Correo electrónico, lo declaramos como estático por compatibilidad con la validación ASP.NET, y aquí simplemente lo llamamos. Es decir, esto también se puede hacer. Para que la infraestructura ASP.NET detecte todo esto, debe modificar ligeramente la serialización y / o ModelBinding. No hay mucho código allí, es relativamente simple, así que no me detendré allí.
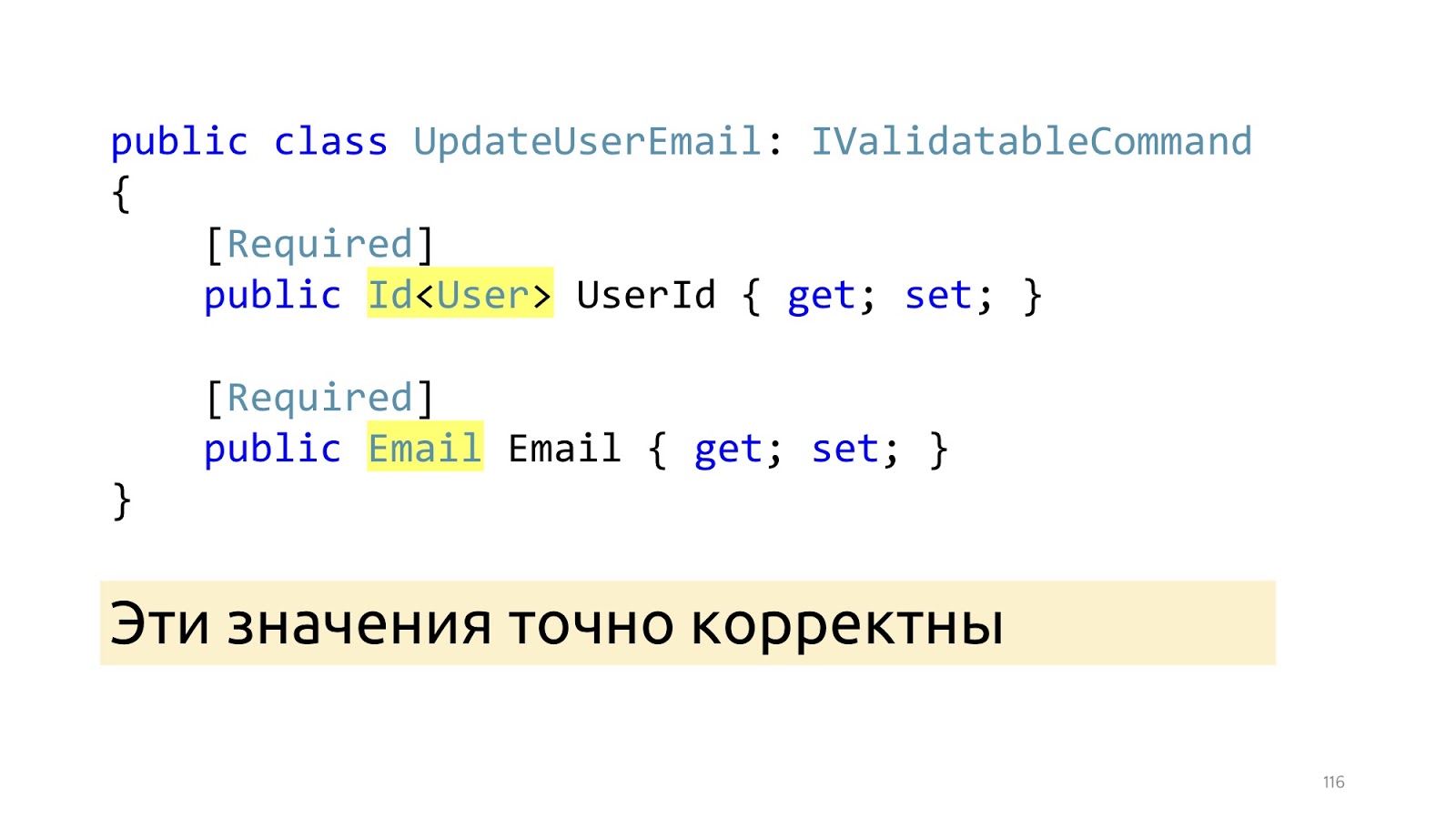
Después de estos cambios, en lugar de los tipos primitivos, aparecen aquí los tipos especializados: Id y Correo electrónico. Y después de que estos ModelBinder y el deserializador actualizado hayan funcionado, sabemos con certeza que estos valores son correctos, incluso que dichos valores están en la base de datos. "Invariantes"

El siguiente punto en el que me gustaría insistir es en el estado de los invariantes en la clase, porque a menudo se usa un
modelo anémico , en el que solo hay una clase, muchos captadores, no está completamente claro cómo deberían trabajar juntos. Trabajamos con una lógica empresarial compleja, por lo que es importante para nosotros que el código se documente automáticamente. En cambio, es mejor declarar el constructor real junto con vacío para ORM, puede declararse protegido para que los programadores en su código de aplicación no puedan llamarlo, y ORM sí. Aquí no pasamos el tipo primitivo, sino el tipo de correo electrónico, ya es correcto, si es nulo, seguimos lanzando una excepción. Puede usar un poco de Fody, PostSharp, pero pronto llegará C # 8. Por consiguiente, habrá un tipo de referencia no anulable, y es mejor esperar su soporte en el lenguaje. El próximo momento, si queremos cambiar el nombre y el apellido, lo más probable es que queramos cambiarlos juntos, por lo que debe haber un método público apropiado que los cambie juntos.

En este método público, también verificamos que la longitud de estas líneas coincida con lo que usamos en la base de datos. Y si algo está mal, entonces pare la ejecución. Aquí uso el mismo truco. Declaro un atributo especial y solo lo llamo en el código de la aplicación.
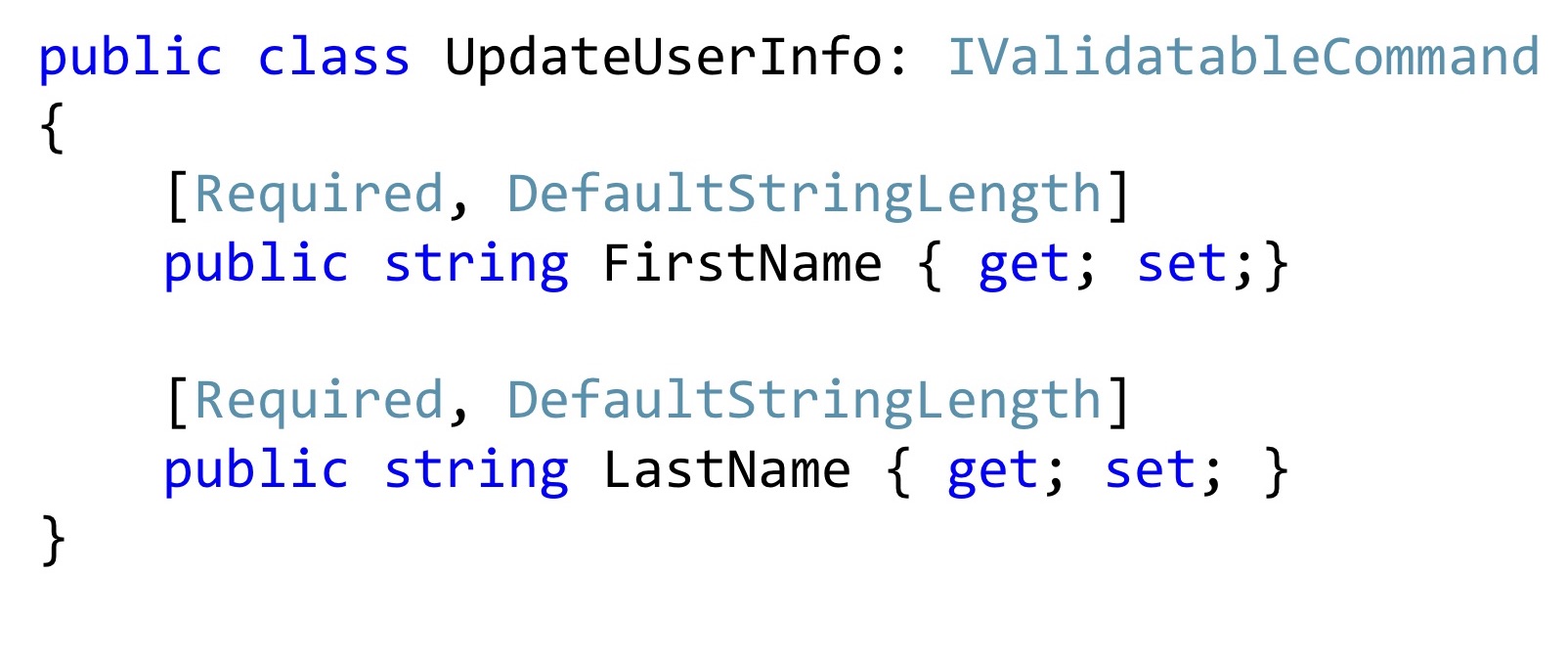
Además, dichos atributos se pueden reutilizar en Dto. Ahora, si quiero cambiar el nombre y el apellido, es posible que tenga ese comando de cambio. ¿Vale la pena agregar un constructor especial aquí? Parece valer la pena. Será mejor, nadie cambiará estos valores, no los romperá, serán exactamente correctos.

En realidad no realmente. El hecho es que los Dto no son realmente objetos en absoluto. Este es un diccionario en el que ponemos datos deserializados. Es decir, fingen ser objetos, por supuesto, pero tienen una sola responsabilidad: ser serializados y deserializados. Si tratamos de luchar contra esta estructura, comenzaremos a anunciar algunos ModelBinders con diseñadores, para hacer algo así es increíblemente agotador y, lo más importante, se romperá con nuevos lanzamientos de nuevos marcos. Todo esto fue bien descrito por Mark Simon en el artículo
"En los bordes del programa no están orientados a objetos" , si es interesante, es mejor leer su publicación, allí se describe en detalle.

En resumen, tenemos un mundo externo sucio, ponemos cheques en la entrada, lo convertimos a nuestro modelo limpio y luego lo transferimos de nuevo a la serialización, al navegador, nuevamente al mundo externo sucio.
Manejador
Después de que se hayan realizado todos estos cambios, ¿cómo se verá el Hander aquí?

Escribí dos líneas aquí para que sea más conveniente leer, pero en general se puede escribir en una. Los datos son exactamente correctos, porque tenemos un sistema de tipos, hay validación, es decir, los datos son de hormigón armado, no es necesario volver a verificarlos. Ese usuario también existe, no hay otro usuario con un correo electrónico tan ocupado, todo se puede hacer. Sin embargo, todavía no hay una llamada al método SaveChanges, no hay notificación y no hay registros ni perfiladores, ¿verdad? Seguimos adelante.
Eventos
Eventos de dominio

Probablemente la primera vez que este concepto fue popularizado por Udi Dahan en su publicación
"Eventos de dominio - Salvación" . Allí, sugiere simplemente declarar una clase estática con el método Raise y lanzar tales eventos. Un poco más tarde, Jimmy Bogard propuso una mejor implementación, se llama
"Un mejor patrón de eventos de dominio" .
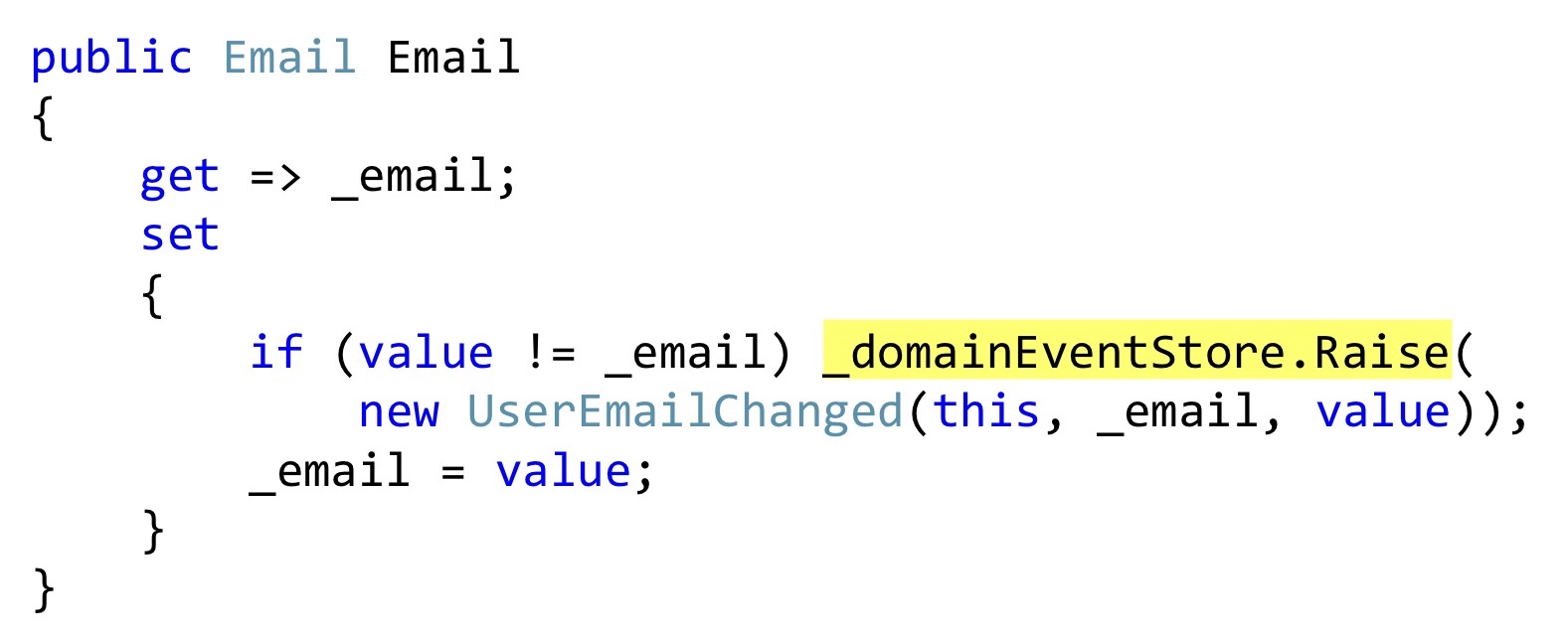
Mostraré la serialización de Bogard con un pequeño cambio, pero importante. En lugar de lanzar eventos, podemos declarar alguna lista, y en aquellos lugares donde debería tener lugar algún tipo de reacción, directamente dentro de la entidad para guardar estos eventos. En este caso, este captador de
email también es una clase de usuario, y esta clase, esta propiedad no pretende ser una propiedad con captadores y configuradores automáticos, pero realmente agrega algo a esto. Es decir, esto es encapsulación real, no blasfemias. Al cambiar, verificamos que el correo electrónico es diferente y lanzamos un evento. Este evento aún no ha llegado a ninguna parte; solo lo tenemos en la lista interna de entidades.

Además, en el momento en que llamaremos al método SaveChanges, tomamos ChangeTracker, para ver si hay entidades que implementen la interfaz, si tienen eventos de dominio. Y si lo hay, tomemos todos estos eventos de dominio y envíelos a algún despachador que sepa qué hacer con ellos.
La implementación de este despachador es un tema para otra discusión, existen algunas dificultades con el despacho múltiple en C #, pero esto también se hace. Con este enfoque, hay otra ventaja no obvia. Ahora, si tenemos dos desarrolladores, uno puede escribir código que cambie este correo electrónico y el otro puede hacer un módulo de notificación. No están absolutamente conectados entre sí, escriben código diferente, están conectados solo al nivel de este evento de dominio de una clase Dto. El primer desarrollador simplemente descarta esta clase en algún momento, el segundo responde y sabe que debe enviarse por correo electrónico, SMS, notificaciones automáticas al teléfono y todos los otros millones de notificaciones, teniendo en cuenta las preferencias de los usuarios que generalmente ocurren.
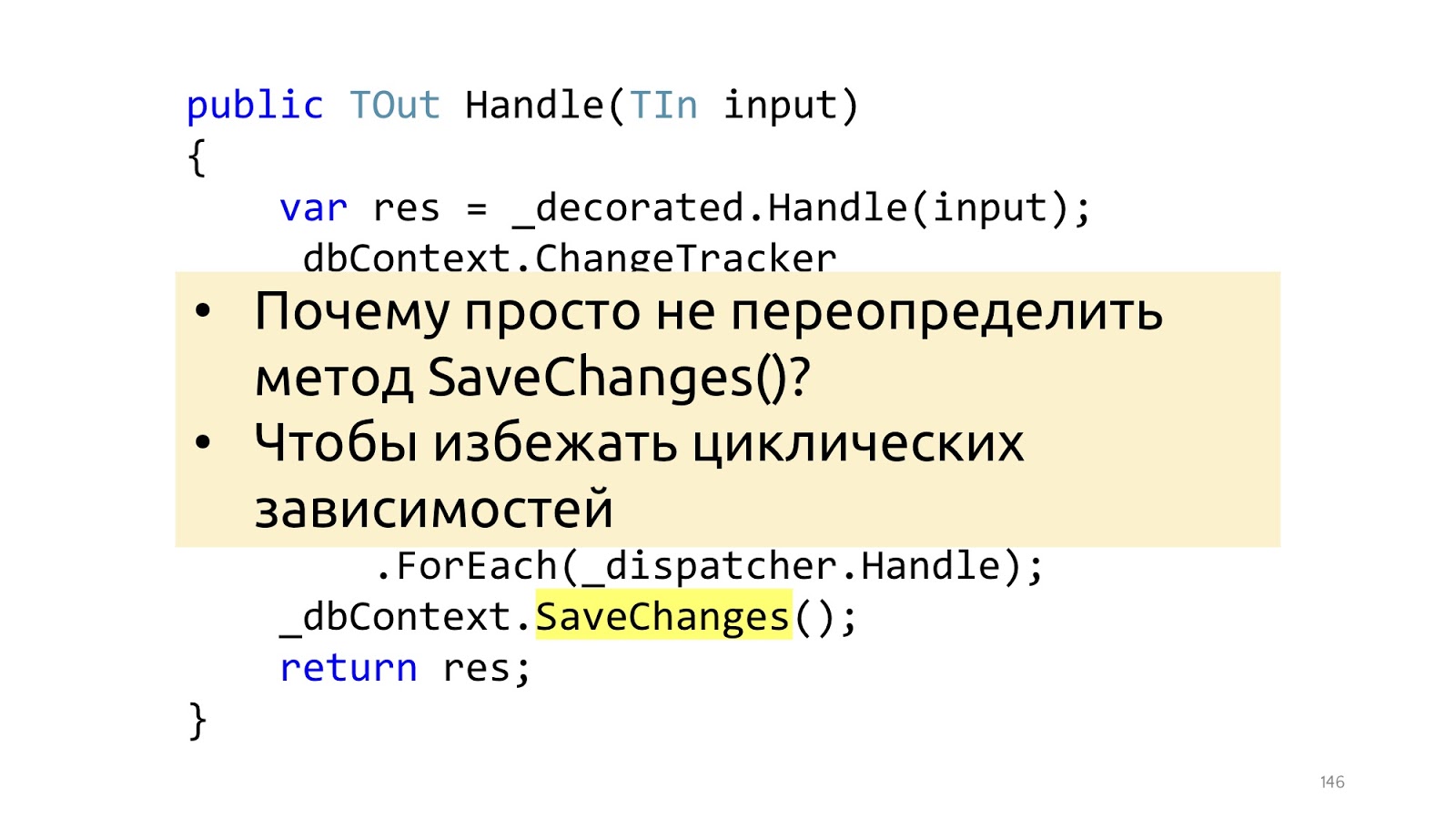
Aquí está el punto más pequeño, pero importante. El artículo de Jimmy usa una sobrecarga del método SaveChanges, y es mejor no hacerlo. Y es mejor hacerlo en el decorador, porque si sobrecargamos el método SaveChanges y necesitamos dbContext en Handler, obtendremos dependencias circulares. Puede trabajar con esto, pero las soluciones son un poco menos convenientes y un poco menos hermosas. Por lo tanto, si la tubería se basa en decoradores, entonces no veo ninguna razón para hacerlo de manera diferente.
Registro y perfilado

La anidación del código se mantuvo, pero en el ejemplo inicial primero usamos MiniProfiler, luego intentamos atrapar, luego si. Total había tres niveles de anidación, ahora cada nivel de anidación está en su propio decorador. Y dentro del decorador, que es responsable de la creación de perfiles, solo tenemos un nivel de anidamiento, el código se lee perfectamente. Además, está claro que en estos decoradores solo hay una responsabilidad. Si el decorador es responsable del registro, solo registrará, si para el perfil, respectivamente, solo el perfil, todo lo demás está en otros lugares.
Respuesta
Después de que toda la tubería ha funcionado, solo podemos tomar Dto y enviarlo al navegador más, serializar JSON.
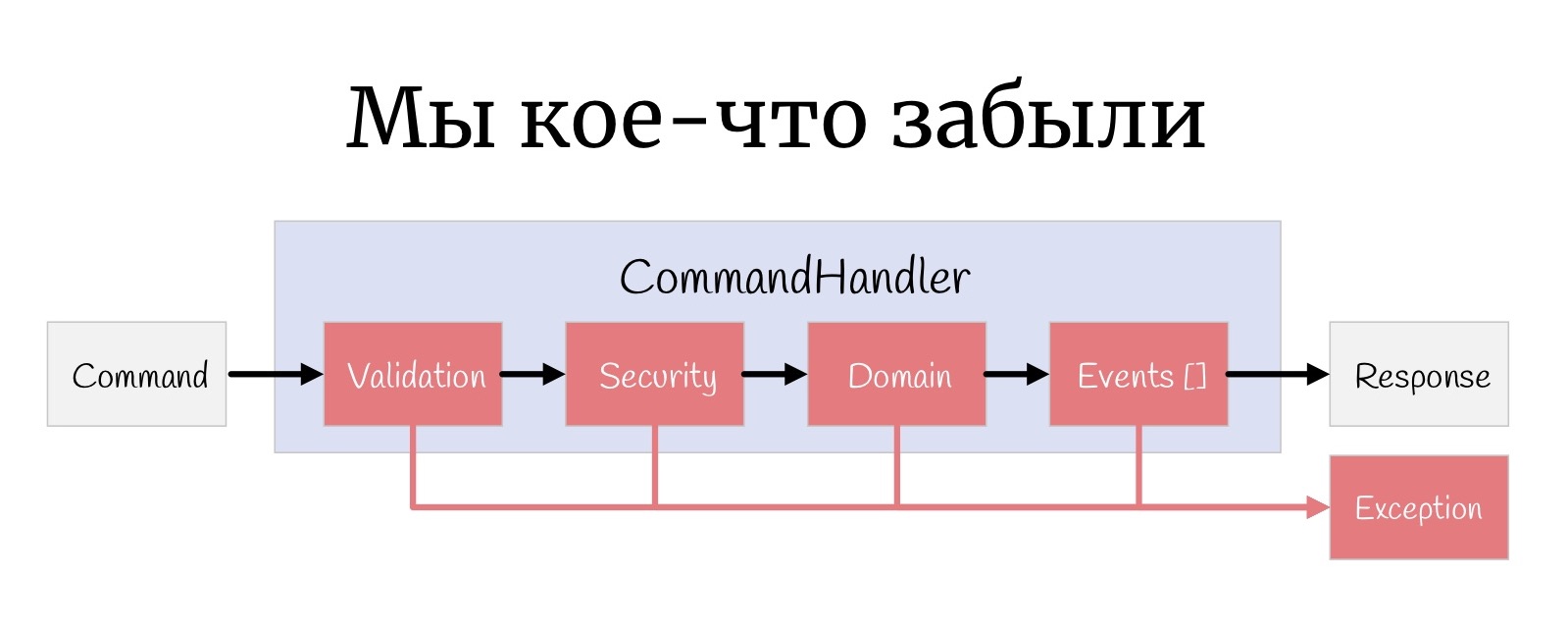
Pero una cosa más pequeña, algo que a veces se olvida: en cada etapa, una Excepción puede suceder aquí, y en realidad necesitas manejarla de alguna manera.

No puedo dejar de mencionar a Scott Vlashin y su informe
"Programación orientada al ferrocarril" aquí nuevamente. Por qué El informe original está completamente dedicado a trabajar con errores en el lenguaje F #, cómo organizar el flujo de manera un poco diferente y por qué este enfoque puede ser preferible a usar Exception'ov. En F #, esto realmente funciona muy bien, porque F # es un lenguaje funcional y Scott usa la funcionalidad de un lenguaje funcional.

Dado que, probablemente, la mayoría de ustedes todavía escriben en C #, si escriben
un análogo en C # , entonces este enfoque se verá más o menos así. En lugar de lanzar excepciones, declaramos una clase Result que tiene una rama exitosa y una rama no exitosa. En consecuencia, dos diseñadores. Una clase puede estar en un solo estado. Esta clase es un caso especial de tipo de unión, unión discriminada de F #, pero reescrita en C #, porque no hay soporte incorporado en C #.

En lugar de declarar captadores públicos que alguien podría no verificar nulos en el código, se utiliza Pattern Matching. Nuevamente, en F # sería un lenguaje de coincidencia de patrones incorporado, en C # tenemos que escribir un método separado en el que pasaremos una función que sepa qué hacer con el resultado exitoso de la operación, cómo convertirlo más abajo en la cadena y eso con un error. Es decir, no importa qué rama trabajó para nosotros, debemos convertir esto en un único resultado devuelto. En F #, todo esto funciona muy bien, porque hay una composición funcional, bueno, y todo lo demás que ya he enumerado. En .NET, esto funciona un poco peor, porque tan pronto como tiene más de un Resultado, pero mucho, y casi todos los métodos pueden fallar por una razón u otra, casi todos sus tipos de funciones resultantes se convierten en Tipos de Resultados, y los necesita como para combinar algo

La forma más fácil de combinarlos es
usar LINQ , porque de hecho LINQ funciona no solo con IEnumerable, si redefine los métodos SelectMany y Select de la manera correcta, entonces el compilador de C # verá que puede usar la sintaxis LINQ para estos tipos. En general, resulta papel de calco con la notación de Haskell o con las mismas expresiones de cálculo en F #. ¿Cómo se debe leer esto? Aquí tenemos tres resultados de la operación, y si todo está bien en los tres casos, tome estos resultados r1 + r2 + r3 y agréguelos. El tipo del valor resultante también será Resultado, pero el nuevo Resultado, que declaramos en Seleccionar. En general, este es incluso un enfoque de trabajo, si no uno, pero.

Para todos los demás desarrolladores, tan pronto como comience a escribir dicho código en C #, comenzará a parecerse a esto. “Estas son excepciones de miedo, ¡no las escribas! Son malvados! ¡Es mejor escribir código que nadie entienda y no pueda depurar!

C # no es F #, es algo diferente, no existen conceptos diferentes en función de los cuales se hace esto, y cuando intentamos tirar de un búho en el mundo, resulta, por decirlo suavemente, inusual.

En cambio, puede usar las
herramientas normales incorporadas que están documentadas, que todos conocen y que no causarán disonancia cognitiva entre los desarrolladores. ASP.NET tiene una excepción de controlador global.

Sabemos que si hay algún problema con la validación, debe devolver el código 400 o 422 (Entidad no procesable). Si hay un problema con la autenticación y la autorización, hay 401 y 403. Si algo salió mal, entonces algo salió mal. Y si algo salió mal y desea decirle al usuario exactamente qué, defina su tipo de excepción, diga que es IHasUserMessage, declare un captador de mensajes en esta interfaz y simplemente verifique: si esta interfaz está implementada, puede recibir un mensaje desde la Excepción y pasarlo en JSON al usuario. Si esta interfaz no está implementada, significa que hay algún tipo de error del sistema, y simplemente les decimos a los usuarios que algo salió mal, ya lo estamos haciendo, todos lo sabemos, bueno, como siempre.
Tubería de consulta
Concluimos esto con los equipos y miramos lo que tenemos en la pila de lectura. En cuanto a la solicitud, validación, respuesta directa: esto es casi lo mismo, no nos detendremos por separado. Todavía puede haber una memoria caché adicional, pero en general tampoco hay grandes problemas con la memoria caché.
Seguridad
Veamos mejor un control de seguridad. También puede haber el mismo decorador de seguridad, que verifica si esta solicitud se puede hacer o no:

Pero hay otro caso en el que mostramos más de un registro y una lista, y para algunos usuarios necesitamos mostrar una lista completa (por ejemplo, para algunos superadministradores), y para otros usuarios tenemos que enumerar listas limitadas, en tercer lugar, limitadas a otro, bueno, y como suele ser el caso en las aplicaciones corporativas, los derechos de acceso pueden ser extremadamente sofisticados, por lo que debe asegurarse de que los datos que no se dirigen a estos usuarios no entren en estas listas.
El problema se resuelve de manera
bastante simple . Podemos redefinir la interfaz (IPermissionFilter) en la que llega el consultable original y regresa consultable. La diferencia es que para el consultable que regresa, ya hemos impuesto condiciones adicionales donde, verificamos al usuario actual y le dijimos: "Aquí, devuelva solo esos datos a ese usuario ...", y luego toda su lógica relacionada con los permisos . Nuevamente, si tiene dos programadores, un programador va a escribir permisos, él sabe que necesita escribir solo una gran cantidad de permisosFiltros y verificar que funcionen correctamente para todas las entidades. Y otros programadores no saben nada sobre permisos, en su lista los datos correctos simplemente siempre pasan, eso es todo. Debido a que reciben en la entrada, ya no se puede consultar el original de dbContext, sino que se limitan a los filtros. Dicho permissionFilter también tiene una propiedad de diseño, podemos agregar y aplicar todos los permissionFilters. Como resultado, obtenemos el permisoFilter resultante, que reducirá la selección de datos al máximo, teniendo en cuenta todas las condiciones que sean adecuadas para esta entidad.

¿Por qué no hacerlo con las herramientas integradas de ORM, por ejemplo, filtros globales en un marco de entidad? Una vez más, para no crear dependencias cíclicas para usted y no arrastrar ninguna historia adicional sobre su capa de negocio al contexto.
Tubería de consulta. Leer modelo
Queda por ver el modelo de lectura. El paradigma CQRS no utiliza el modelo de dominio en la pila de lectura, en su lugar, simplemente creamos inmediatamente el Dto que el navegador necesita en este momento.

Si escribimos en C #, lo más probable es que estemos usando LINQ, si no existen requisitos de rendimiento monstruosos, y si los hay, es posible que no tenga una aplicación corporativa. En general, este problema se puede resolver de una vez por todas con un LinqQueryHandler. Aquí hay una restricción bastante aterradora sobre el genérico: esta es Consulta, que devuelve una lista de proyecciones, y aún puede filtrar estas proyecciones y ordenar estas proyecciones. También trabaja solo con algunos tipos de entidades y sabe cómo convertir estas entidades en proyecciones y devolver la lista de tales proyecciones en forma de Dto al navegador.

La implementación del método Handle puede ser bastante simple. Por si acaso, verifique si este filtro TQuery se implementa para la entidad original. Además hacemos una proyección, es consultable la extensión AutoMapper'a. Si alguien aún no lo sabe, AutoMapper puede construir proyecciones en LINQ, es decir, aquellas que construirán el método Select y no lo mapearán en la memoria.
Luego aplicamos filtrado, clasificación y lo mostramos todo en el navegador. , DotNext, ,
, , , , expression' , .
. , DotNext', — SQL. Select , , , queryable- .
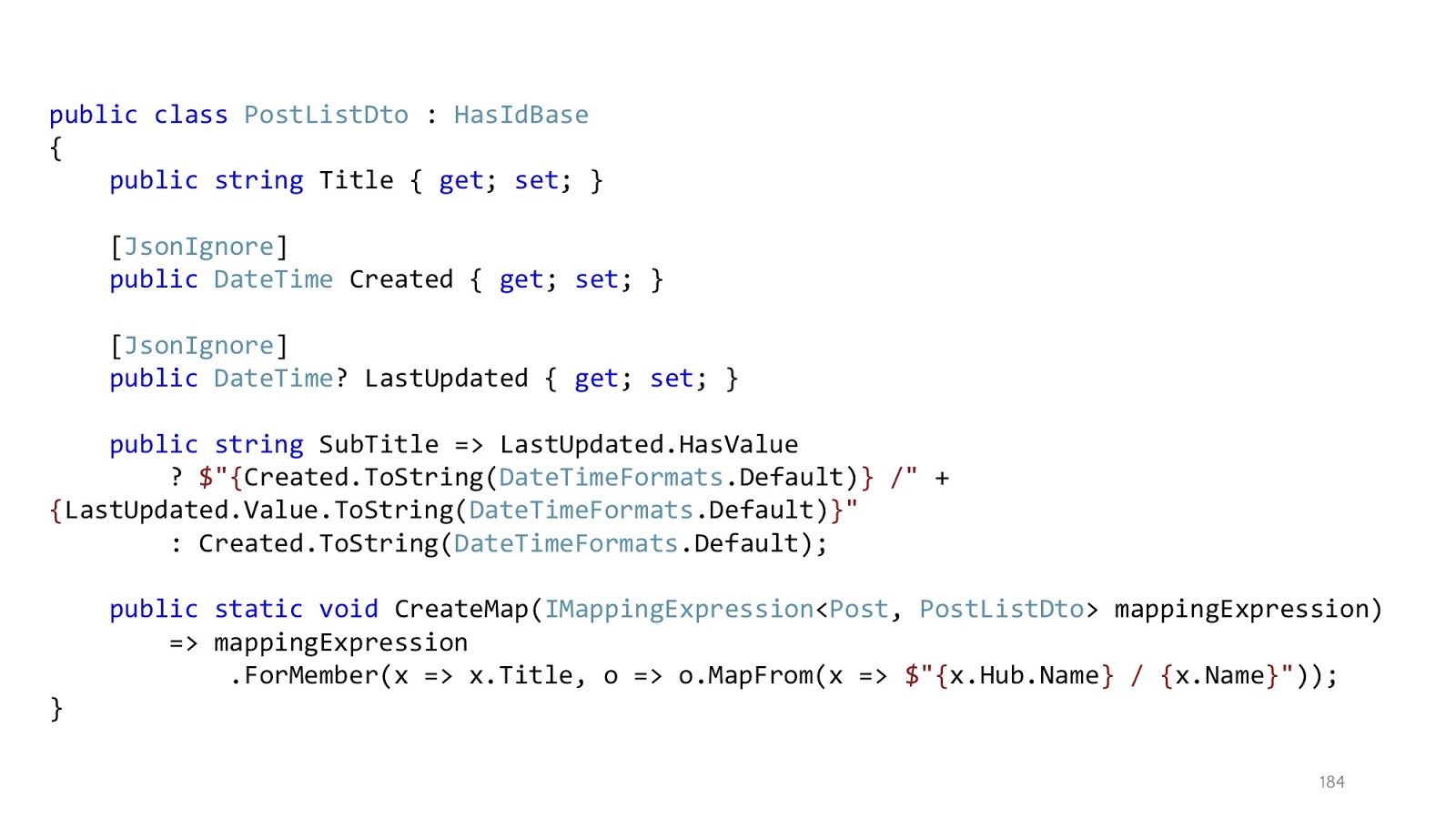
, . , Title, Title , . , . SubTitle, , , - , queryable- . , .
, . , , . , , . «JsonIgnore», . , , Dto. , , . JSON, , Created LastUpdated , SubTitle — , . , , , , , . , - .

. , -, , . , pipeline, . — , , . , SaveChanges, Query SaveChanges. , , , NuGet, .
. , - , , . , , , , , — . , , : « », — . .
, ?

- . .

, , , . MediatR , . , , — , MediatR pipeline behaviour. , Request/Response, RequestHandler' . Simple Injector, — .

, , , , TIn: ICommand.

Simple Injector' constraint' . , , , constraint', Handler', constraint. , constraint ICommand, SaveChanges constraint' ICommand, Simple Injector , constraint' , Handler'. , , , .
? Simple Injector MeriatR — , , Autofac', -, , , . , .
,
, «».
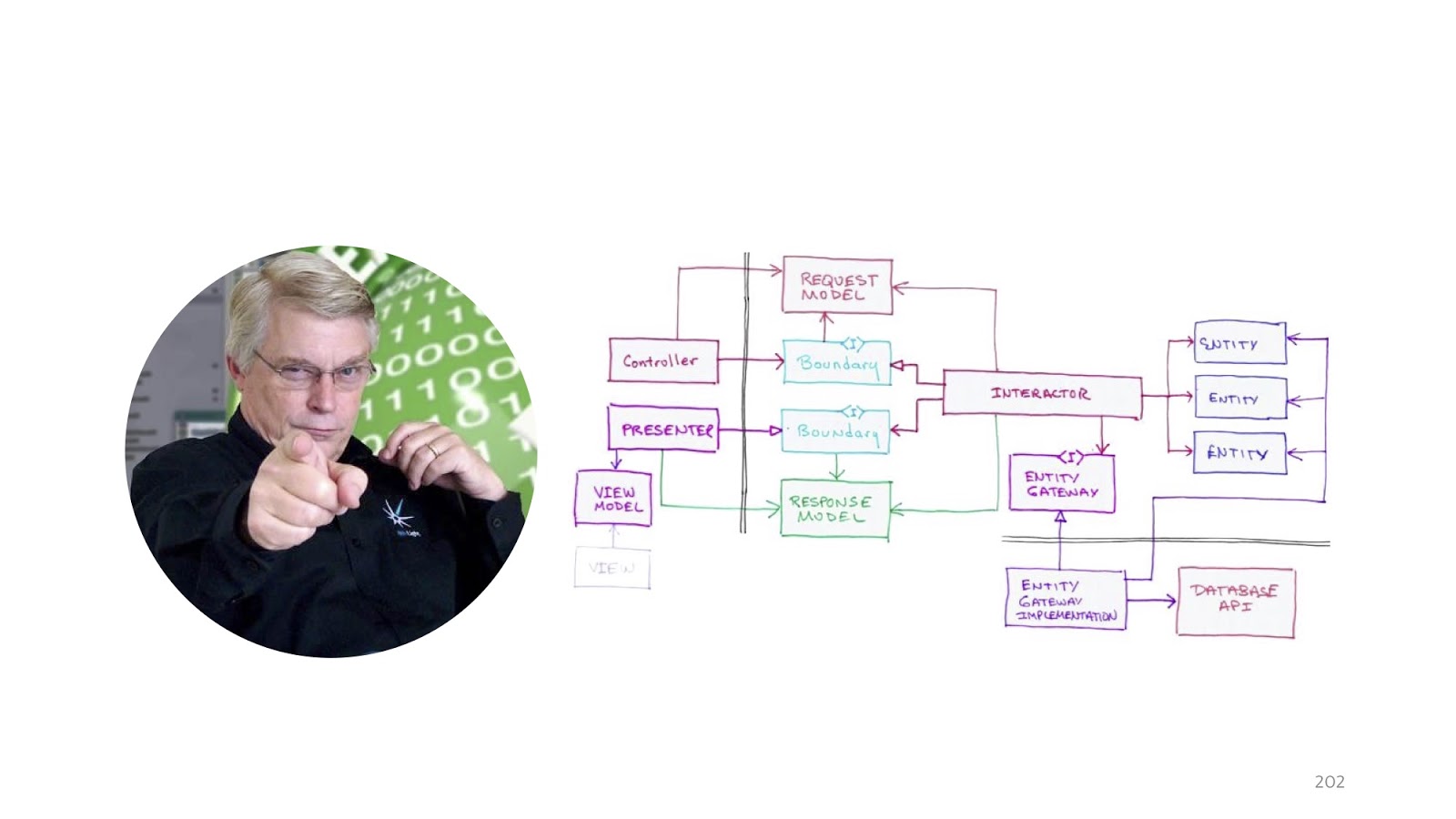
, «Clean architecture». .

- - , MVC, , .

, , , Angular, , , , . , : « — MVC-», : « Features, : , Blog - Import, - ».
, , , , MVC-, , - , . MVC . , , — . .


- , - -, .
-, , . , . , - , User Service, pull request', , User Service , . , - , - , . - , .
. , . , , , . , , , , , , , - . , ( , ), , «Delete»: , , . .
— «», , , , . , : , , , . , . , , . , , .
: . « », : , , . , , , , , , , . , . , - pull request , — , — - , . VCS : - , ? , - , , .

, , , . : . , . , , , , . , , , . , , . « », , . , , — , , .
: , - , . . - , , , , . - , - , , , , . .

. , IHandler . .
IHandler ICommandHandler IQueryHandler , . , , . , CommandHandler, CommandHandler', .
Por qué , Query , Query — . , , , Hander, CommandHandler QueryHandler, - use case, .
— , , , , : , .
, . , . , -.
C# 8, nullable reference type . , , , , .
ChangeTracker' ORM.
Exception' — , F#, C#. , - , - , . , , Exception', , LINQ, , , , , , Dapper - , , , .NET.
, LINQ, , permission' — . , , - , , . , — .
. :
- Vertical Slices
- Domain Events
- DDD
- ROP
- LINQ Expressions:
- Clean Architecture

— . . — «Domain Modeling Made Functional», F#, F#, , , , , . C# , , Exception'.
, , — «Entity Framework Core In Action». , Entity Framework, , DDD ORM, , ORM DDD .
Minuto de publicidad. 15-16 2019 .NET- DotNext Piter, . , .