Creé Kube Eagle, un exportador de Prometheus. Resultó ser algo genial que ayuda a comprender mejor los recursos de los grupos pequeños y medianos. Como resultado, ahorré más de cien dólares, porque seleccioné los tipos correctos de máquinas y configuré los límites de recursos de la aplicación para las cargas de trabajo.
Hablaré sobre los beneficios del Kube Eagle , pero primero explicaré por qué surgió el alboroto y por qué se necesitaba un monitoreo de calidad.
Logré varios grupos de 4-50 nodos. En cada clúster: hasta 200 microservicios y aplicaciones. Para hacer un mejor uso del hardware disponible, la mayoría de las implementaciones se configuraron con recursos de CPU y RAM que se pueden grabar. Por lo tanto, los pods pueden tomar los recursos disponibles, si es necesario, y al mismo tiempo no interferir con otras aplicaciones en este nodo. Bueno, ¿no es genial?
Y aunque el clúster consumió relativamente poca CPU (8%) y RAM (40%), constantemente tuvimos problemas para desplazar los hogares cuando intentaban asignar más memoria de la que está disponible en el nodo. Entonces solo teníamos un tablero para monitorear los recursos de Kubernetes. Aquí hay uno:
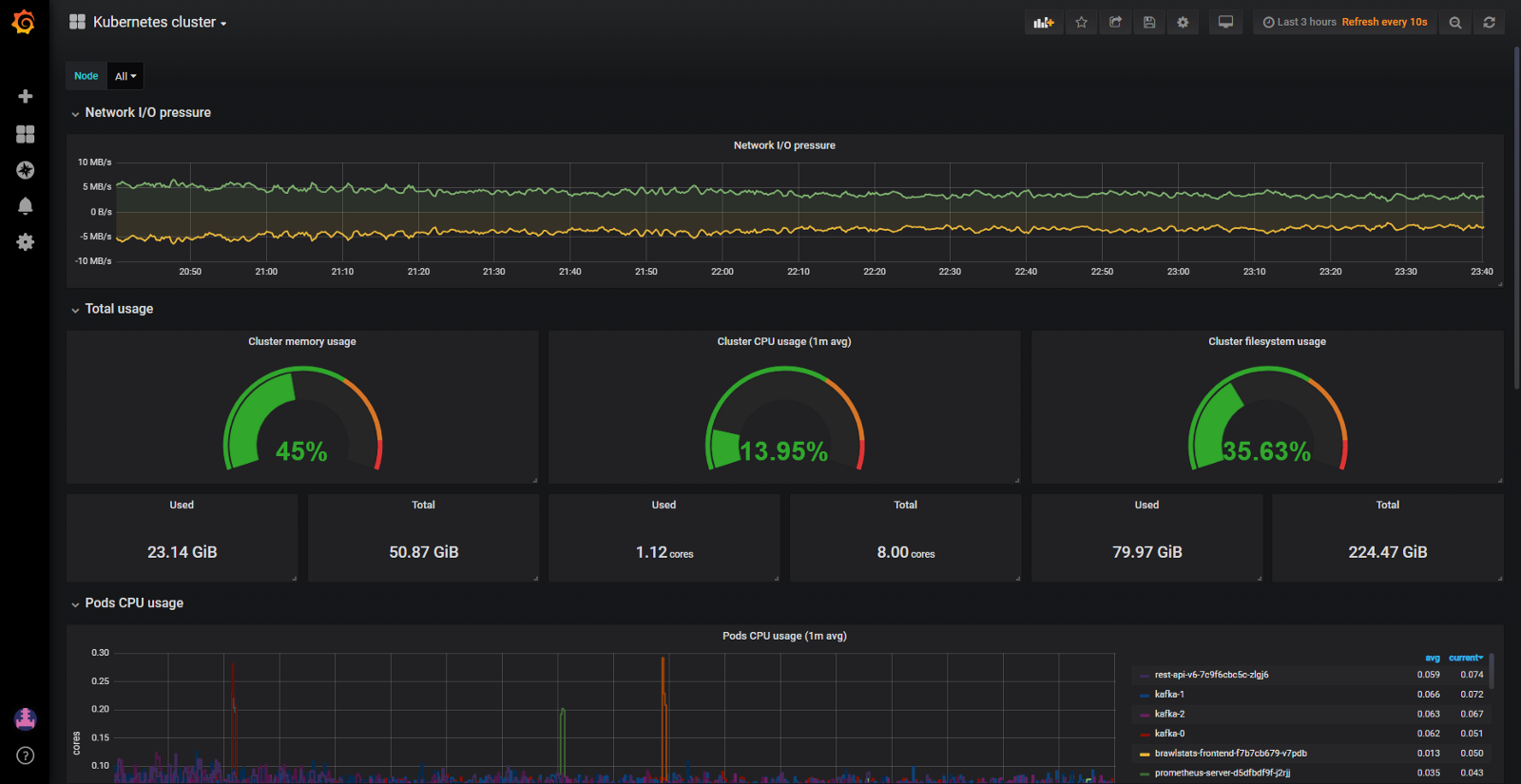
Tablero de Grafana con métricas de cAdvisor solamente
Con tal panel, los nodos que consumen mucha memoria y CPU no son un problema. El problema es descubrir la razón. Para mantener los pods en su lugar, podría, por supuesto, configurar recursos garantizados en todos los pods (los recursos solicitados son iguales al límite). Pero este no es el uso más inteligente del hierro. Había varios cientos de gigabytes de memoria en el clúster, mientras que algunos nodos se estaban muriendo de hambre, mientras que otros tenían de 4 a 10 GB de reserva.
Resulta que el planificador de Kubernetes distribuyó las cargas de trabajo entre los recursos disponibles de manera desigual. El Programador de Kubernetes tiene en cuenta diferentes configuraciones: reglas de afinidad, contaminaciones y tolerancias, selectores de nodos que pueden limitar los nodos disponibles. Pero en mi caso no había nada de eso, y las cápsulas se planificaron en función de los recursos solicitados en cada nodo.
Para el hogar, se seleccionó un nodo que tiene la mayoría de los recursos libres y que satisface las condiciones de solicitud. Resultó que los recursos solicitados en los nodos no coinciden con el uso real, y aquí Kube Eagle y su capacidad para monitorear recursos vinieron al rescate.
Tengo casi todos los clústeres de Kubernetes rastreados solo con el exportador de nodos y las métricas de estado de Kube . Node Exporter proporciona estadísticas de E / S y de disco, CPU y RAM, y Kube State Metrics muestra las métricas de objetos de Kubernetes, como solicitudes y límites en recursos de CPU y memoria.
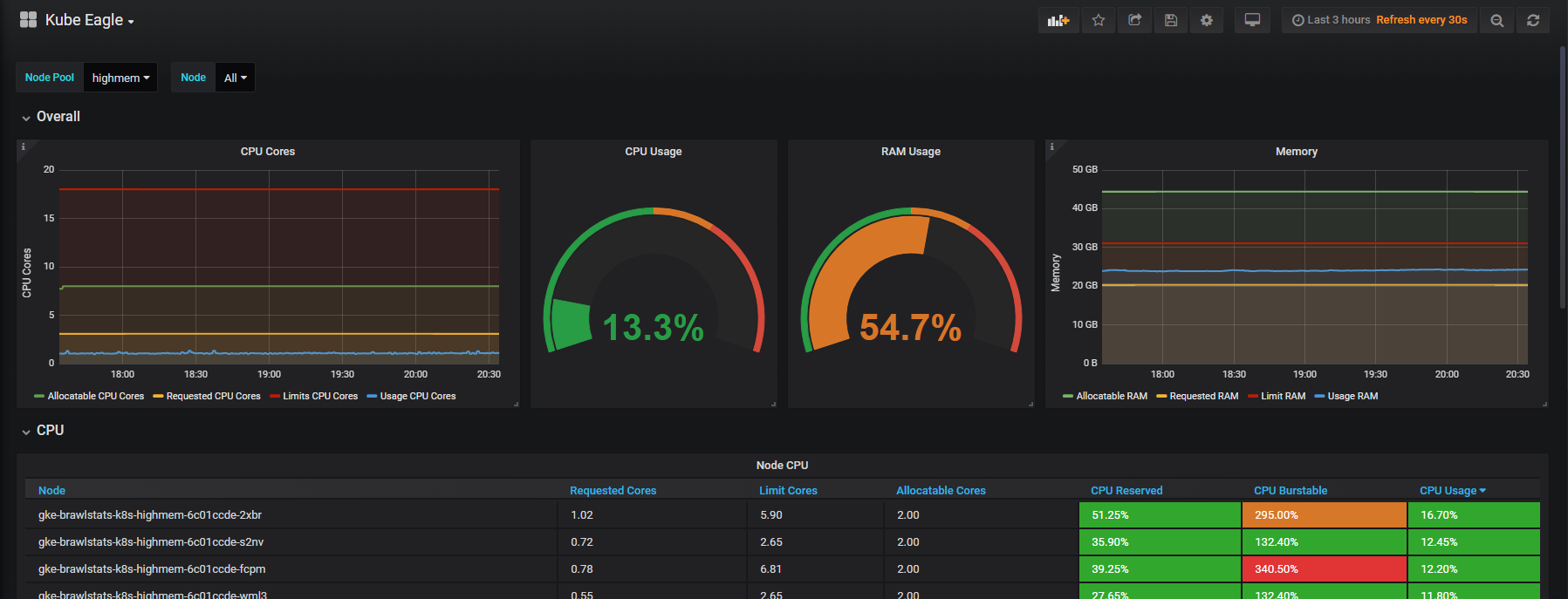
Necesitamos combinar las métricas de uso con la solicitud y limitar las métricas en Grafana, y luego obtenemos toda la información sobre el problema. Suena simple, pero de hecho en estas dos herramientas las etiquetas se llaman de manera diferente, y algunas métricas no tienen etiquetas de metadatos. Kube Eagle hace todo por sí mismo y el panel se ve así:
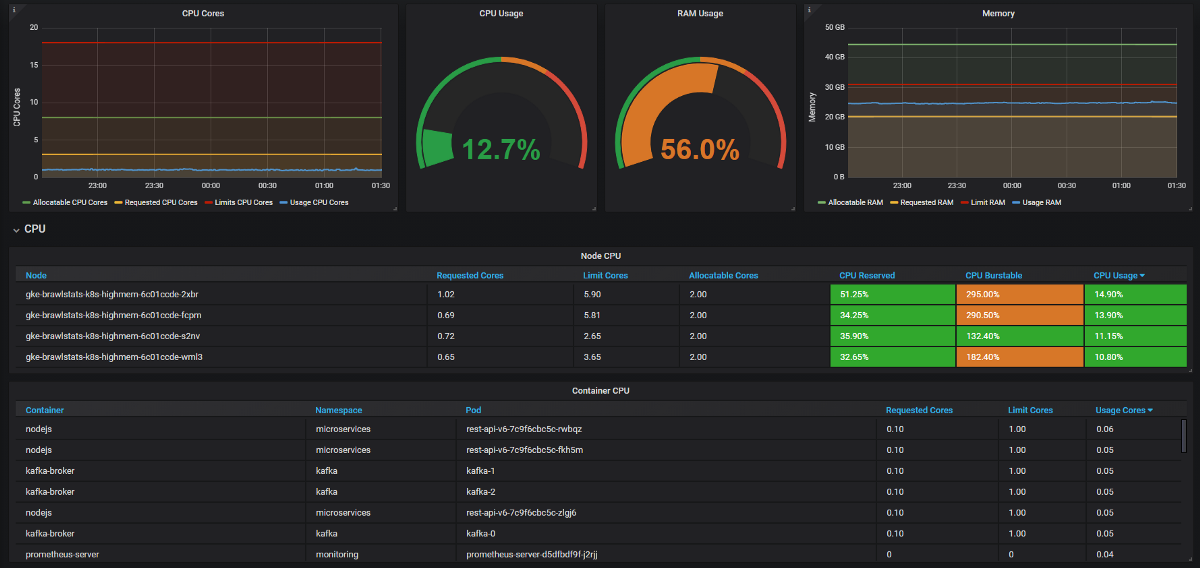
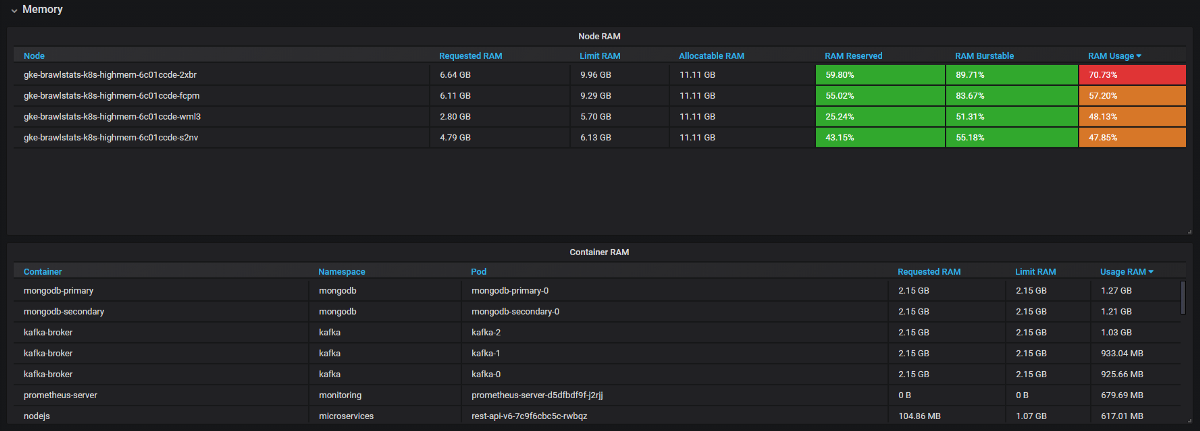
Kube Eagle Dashboard
Logramos resolver muchos problemas con los recursos y ahorrar equipo:
- Algunos desarrolladores no sabían cuántos recursos necesitaban los microservicios (o simplemente no se molestaron). No teníamos nada para encontrar las solicitudes de recursos incorrectas; para esto necesitamos conocer el consumo más las solicitudes y los límites. Ahora ven las métricas de Prometheus, monitorean el uso real y ajustan las consultas y los límites.
- Las aplicaciones JVM toman tanta RAM como toman. El recolector de basura libera memoria solo si está involucrado más del 75%. Y dado que la mayoría de los servicios tienen memoria burstable, la JVM siempre la ha ocupado. Por lo tanto, todos estos servicios de Java consumieron mucha más RAM de lo esperado.
- Algunas aplicaciones solicitaron demasiada memoria, y el planificador de Kubernetes no dio estos nodos a otras aplicaciones, aunque en realidad eran más libres que otros nodos. Un desarrollador agregó accidentalmente un dígito adicional en la solicitud y agarró una gran parte de RAM: 20 GB en lugar de 2. Nadie se dio cuenta. La aplicación tenía 3 réplicas, por lo que 3 nodos se vieron afectados.
- Introdujimos límites de recursos, volvimos a planificar los pods con las solicitudes correctas y obtuvimos el equilibrio perfecto del uso de hierro en todos los nodos. Un par de nodos generalmente podrían cerrarse. Y luego vimos que teníamos las máquinas equivocadas (orientadas a la CPU, no a la memoria). Cambiamos el tipo y eliminamos algunos nodos más.
Resumen
Con los recursos estables en un clúster, puede usar el hardware existente de manera más eficiente, pero el planificador de Kubernetes programa pods en solicitudes de recursos, lo cual es complicado. Para matar dos pájaros de un tiro: para evitar problemas y utilizar los recursos al máximo, se necesita un buen monitoreo. Kube Eagle (exportador Prometheus y tablero de Grafana) es útil para esto.