En febrero-marzo de 2019, se realizó una competencia para clasificar el feed de la red social SNA Hackathon 2019 , en el que nuestro equipo ocupó el primer lugar. En este artículo hablaré sobre la organización del concurso, los métodos que probamos y la configuración de catboost para el entrenamiento en big data.

SNA Hackathon
El hackathon bajo este nombre se lleva a cabo por tercera vez. Está organizado por la red social ok.ru, respectivamente, la tarea y los datos están directamente relacionados con esta red social.
SNA (análisis de redes sociales) en este caso se entiende mejor no como un análisis de un gráfico social, sino más bien como un análisis de una red social.
- En 2014, la tarea era predecir la cantidad de me gusta que ganaría la publicación.
- En 2016, el objetivo de la VVZ (tal vez esté familiarizado), más cerca del análisis del gráfico social.
- En 2019: clasificación del feed de un usuario según la probabilidad de que al usuario le guste la publicación.
No puedo decir sobre 2014, pero en 2016 y 2019, además de la capacidad de analizar datos, también se requerían habilidades para trabajar con big data. Creo que fue la combinación del aprendizaje automático y las tareas de procesamiento de big data lo que me atrajo a estos concursos, y la experiencia en estas áreas ayudó a ganar.
mlbootcamp
En 2019, la competencia se organizó en la plataforma https://mlbootcamp.ru .
La competencia comenzó en línea el 7 de febrero y consistió en 3 tareas. Todos podían registrarse en el sitio, descargar la línea de base y subir su automóvil durante varias horas. Al final de la etapa en línea el 15 de marzo, los 15 mejores de cada programa fueron invitados a la oficina de Mail.ru para la etapa fuera de línea, que tuvo lugar del 30 de marzo al 1 de abril.
Desafío
Los datos de origen proporcionan identificadores de usuario (userId) e identificadores de publicación (objectId). Si al usuario se le mostró una publicación, los datos contienen una línea que contiene userId, objectId, reacciones del usuario a esta publicación (comentarios) y un conjunto de varios signos o enlaces a imágenes y textos.
| ID de usuario | objectId | ID de propietario | retroalimentación | imágenes |
|---|
| 3555 | 22 | 5677 | [gustó, hizo clic] | [hash1] |
| 12842 | 55 | 32144 | [disgustado] | [hash2, hash3] |
| 13145 | 35 | 5677 | [hecho clic, compartido] | [hash2] |
El conjunto de datos de prueba contiene una estructura similar, pero falta el campo de retroalimentación. El objetivo es predecir la presencia de una reacción 'me gusta' en el campo de retroalimentación.
El archivo de envío tiene la siguiente estructura:
| ID de usuario | SortedList [objectId] |
|---|
| 123 | 78.13.54.22 |
| 128 | 35,61,55 |
| 131 | 35,68,129,11 |
Métrica: promedio de ROC AUC por usuarios.
Se puede encontrar una descripción más detallada de los datos en el sitio de perfección . También puede descargar datos allí, incluidas pruebas e imágenes.
Etapa en línea
En la etapa en línea, la tarea se dividió en 3 partes.
- Sistema colaborativo : incluye todos los signos, excepto imágenes y textos;
- Imágenes : incluye solo información sobre imágenes;
- Textos : incluye información solo sobre textos.
Etapa fuera de línea
En la etapa fuera de línea, los datos incluían todos los atributos, mientras que los textos e imágenes eran escasos. Había 1.5 veces más filas en el conjunto de datos, de las cuales ya había muchas.
Resolución de problemas
Como estoy haciendo CV en el trabajo, comencé mi viaje en esta competencia con la tarea "Imágenes". Los datos que se proporcionaron son userId, objectId, ownerId (el grupo en el que se publica la publicación), marcas de tiempo para crear y mostrar la publicación y, por supuesto, la imagen de esta publicación.
Después de generar varias características basadas en la marca de tiempo, la siguiente idea fue tomar la penúltima capa de la neurona pre-entrenada en imagenet y enviar estas incorporaciones para impulsar.
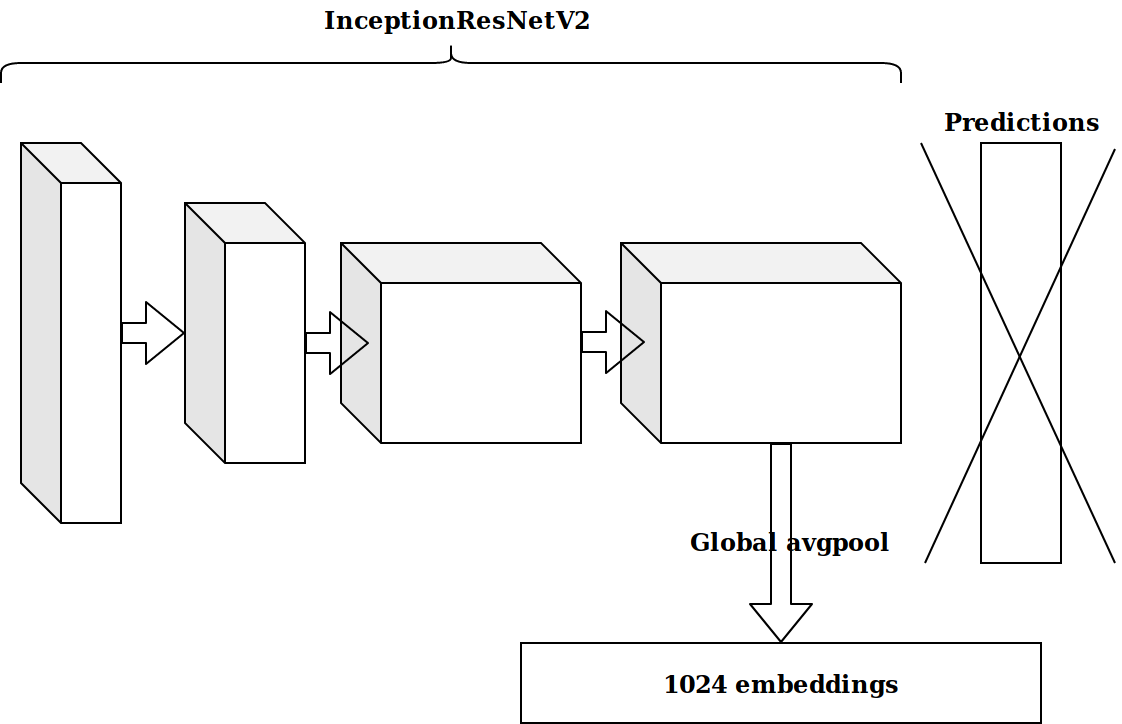
Los resultados no fueron impresionantes. Las incrustaciones de la neurona imagenet son irrelevantes, pensé, necesito archivar mi codificador automático.
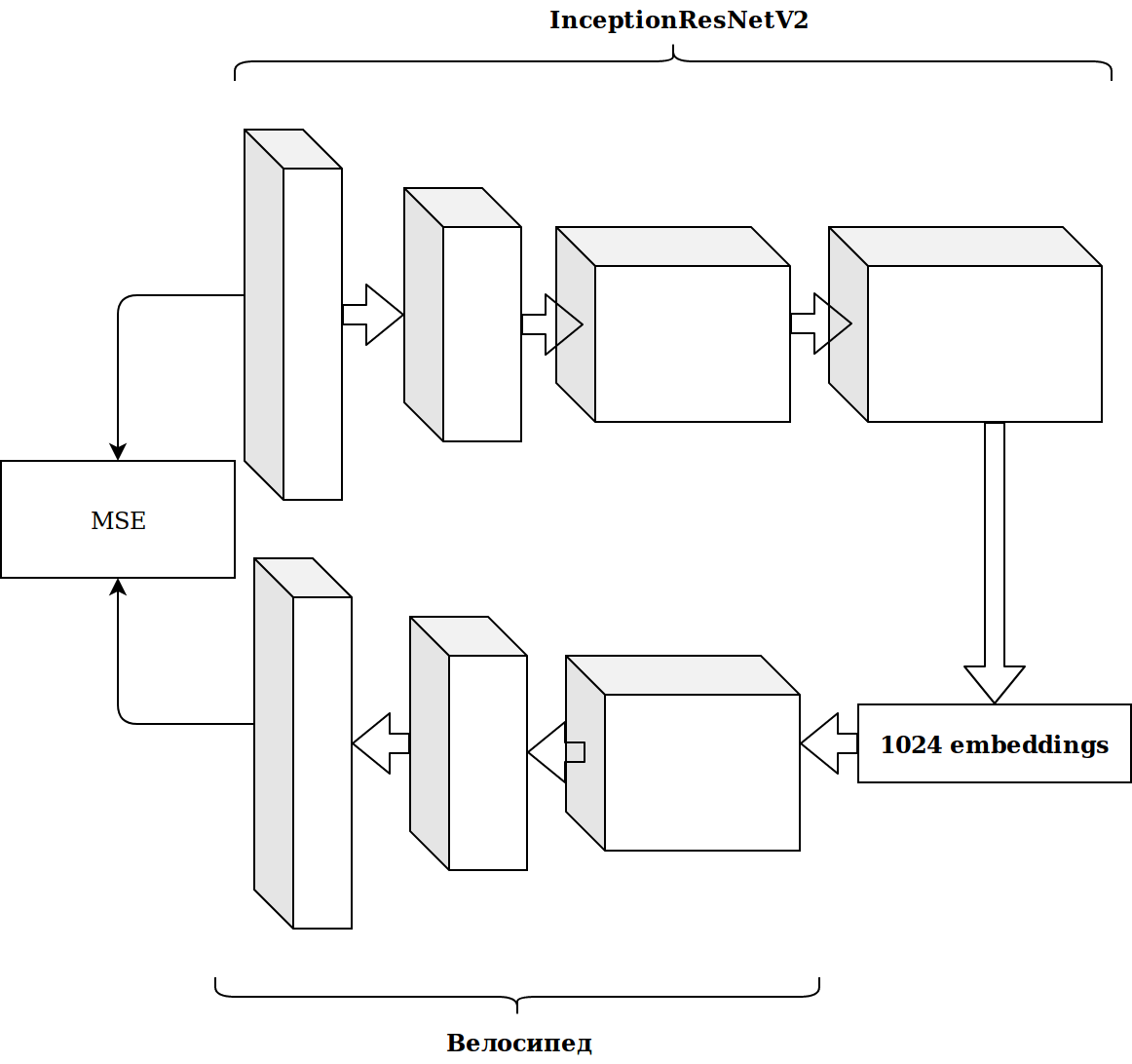
Tomó mucho tiempo y el resultado no mejoró.
Generación de funciones
Trabajar con imágenes lleva mucho tiempo, y decidí hacer algo más simple.
Como puede ver de inmediato, hay varios signos categóricos en el conjunto de datos, y para no molestar mucho, simplemente tomé catboost. La solución fue excelente, sin ninguna configuración, inmediatamente llegué a la primera línea de la tabla de clasificación.
Hay muchos datos y se presentan en formato de parquet, así que sin pensarlo dos veces, tomé scala y comencé a escribir todo con chispa.
Las características más simples, que dieron más crecimiento que las incrustaciones de imágenes:
- cuántas veces objectId, userId y ownerId se encontraron en los datos (debería correlacionarse con la popularidad);
- cuántas publicaciones userId vio el ownerId (debe correlacionarse con el interés del usuario en el grupo);
- cuántos ID de usuario únicos miraron publicaciones por ownerId (refleja el tamaño de la audiencia del grupo).
A partir de las marcas de tiempo, era posible obtener la hora del día en que el usuario miraba la cinta (mañana / día / tarde / noche). Al combinar estas categorías, puede continuar generando características:
- cuántas veces userId inició sesión en la noche;
- a qué hora se muestra a menudo esta publicación (objectId), etc.
Todo esto gradualmente mejoró la métrica. Pero el tamaño del conjunto de datos de capacitación es de aproximadamente 20 millones de registros, por lo que agregar funciones ralentizó en gran medida el aprendizaje.
Redefiní el enfoque de uso de datos. Aunque los datos dependen del tiempo, no he visto ninguna filtración de información explícita en el futuro, sin embargo, por si acaso, la rompí así:
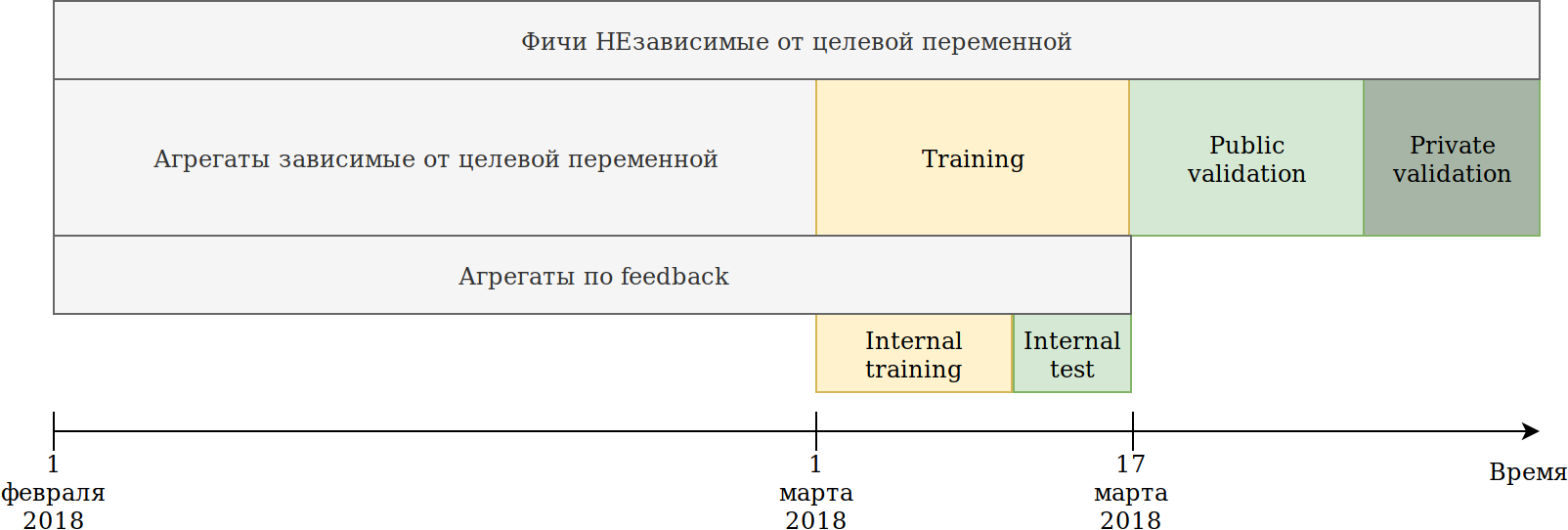
El conjunto de capacitación que se nos proporcionó (febrero y 2 semanas de marzo) se dividió en 2 partes.
Sobre los datos de los últimos N días, entrenó al modelo. Las agregaciones descritas anteriormente se construyeron sobre todos los datos, incluida la prueba. Al mismo tiempo, aparecieron datos sobre los que se pueden construir varios codificadores de la variable objetivo. El enfoque más simple es reutilizar el código que ya está creando nuevas características, y simplemente proporcionarle datos que no serán entrenados y objetivo = 1.
Por lo tanto, tenemos características similares:
- Cuántas veces userId ha visto una publicación en el grupo ownerId;
- Cuántas veces a userId le gustó la publicación en ownerId;
- El porcentaje de publicaciones que a userId le gustó ownerId.
Es decir, resultó la codificación objetivo media por parte del conjunto de datos de acuerdo con varias combinaciones de características categóricas. En principio, catboost también crea codificación de destino, y desde este punto de vista no hay ningún beneficio, pero, por ejemplo, se hizo posible contar el número de usuarios únicos a quienes les gustan las publicaciones en este grupo. Al mismo tiempo, se logró el objetivo principal: mi conjunto de datos disminuyó varias veces y fue posible continuar generando características.
Si bien catboost solo puede construir codificadores de acuerdo con la reacción que le gusta, la retroalimentación tiene otras reacciones: compartir, no me gusta, no me gusta, hacer clic, ignorar, lo que se puede hacer manualmente. Conté todo tipo de agregados y seleccioné las características con poca importancia, para no inflar el conjunto de datos.
En ese momento estaba en primer lugar por un amplio margen. La única vergüenza fue que la incrustación de las imágenes casi no dio ganancias. La idea surgió para dar todo a catboost. Agrupe las imágenes de Kmeans y obtenga una nueva característica categórica imageCat.
Aquí hay algunas clases después de filtrar y fusionar manualmente los clústeres obtenidos de KMeans.

Basado en imageCat generamos:
- Nuevas características categóricas:
- Qué imageCat parecía más frecuentemente userId;
- Qué imageCat se muestra con mayor frecuencia por ownerId;
- ¿Qué imageCat le gusta más a menudo userId;
- Varios contadores:
- Cuántos imageCat únicos parecían userId;
- Alrededor de 15 características similares más codificación de destino como se describe anteriormente.
Textos
Los resultados en el concurso de imágenes me convencieron y decidí probarme en los textos. Anteriormente, no trabajaba mucho con textos y, por estupidez, mataba un día en tf-idf y svd. Luego vi una línea de base con doc2vec, que hace justo lo que necesito. Habiendo ajustado ligeramente los parámetros de doc2vec, recibí incrustaciones de texto.
Y luego simplemente reutilizó el código para las imágenes, en el que reemplazó las incrustaciones de imágenes con incrustaciones de texto. Como resultado, llegué al segundo lugar en el concurso de texto.
Sistema colaborativo
Solo había una competencia en la que todavía no había "golpeado un palo", pero a juzgar por las AUC en la clasificación, los resultados de esta competencia en particular deberían haber tenido el mayor impacto en el escenario fuera de línea.
Tomé todos los signos que estaban en los datos de origen, seleccioné los categóricos y calculé los mismos agregados que para las imágenes, excepto las características de las imágenes mismas. Simplemente poniéndolo en catboost, llegué al segundo lugar.
Los primeros pasos para optimizar catboost
Un primer y dos segundos lugares me complacieron, pero entendí que no hice nada especial, lo que significa que podemos esperar una pérdida de posición.
La tarea de la competencia es clasificar las publicaciones dentro del marco del usuario, y todo este tiempo he estado resolviendo el problema de clasificación, es decir, he optimizado la métrica incorrecta.
Daré un ejemplo simple:
| ID de usuario | objectId | predicción | verdad fundamental |
|---|
| 1 | 10 | 0.9 | 1 |
| 1 | 11 | 0.8 | 1 |
| 1 | 12 | 0.7 | 1 |
| 1 | 13 | 0.6 | 1 |
| 1 | 14 | 0.5 0.5 | 0 0 |
| 2 | 15 | 0.4 0.4 | 0 0 |
| 2 | 16 | 0,3 | 1 |
Hacemos una pequeña permutación
| ID de usuario | objectId | predicción | verdad fundamental |
|---|
| 1 | 10 | 0.9 | 1 |
| 1 | 11 | 0.8 | 1 |
| 1 | 12 | 0.7 | 1 |
| 1 | 13 | 0.6 | 0 0 |
| 2 | 16 | 0.5 0.5 | 1 |
| 2 | 15 | 0.4 0.4 | 0 0 |
| 1 | 14 | 0,3 | 1 |
Obtenemos los siguientes resultados:
| Modelo | Auc | Usuario1 AUC | Usuario2 AUC | AUC medio |
|---|
| Opcion 1 | 0.8 | 1,0 | 0,0 | 0.5 0.5 |
| Opción 2 | 0.7 | 0,75 | 1,0 | 0.875 |
Como puede ver, mejorar la métrica general de AUC no significa mejorar la métrica promedio de AUC dentro del usuario.
Catboost puede optimizar las métricas de clasificación de forma inmediata. Leí sobre métricas de clasificación, historias de éxito cuando uso catboost y configuré YetiRankPairwise para estudiar durante la noche. El resultado no fue impresionante. Habiendo decidido que no había aprendido bien, cambié la función de error a QueryRMSE, que, a juzgar por la documentación de catboost, converge más rápido. Como resultado, obtuve los mismos resultados que durante el entrenamiento para la clasificación, pero los conjuntos de estos dos modelos dieron un buen aumento, lo que me llevó a los primeros lugares en las tres competiciones.
5 minutos antes del cierre de la etapa en línea en la competencia Collaborative Systems, Sergey Shalnov me trasladó al segundo lugar. La forma en que fuimos juntos.
Preparación para la fase fuera de línea
La victoria en la etapa en línea nos fue garantizada en la tarjeta de video RTX 2080 TI, pero el premio principal de 300,000 rublos y, más bien, incluso el primer lugar final nos obligó a trabajar estas 2 semanas.
Al final resultó que, Sergey también usó catboost. Intercambiamos ideas y características, y descubrí el informe de Anna Veronika Dorogush en el que había respuestas a muchas de mis preguntas, e incluso a aquellas que aún no había aparecido.
Ver el informe me llevó a la idea de que es necesario devolver todos los parámetros al valor predeterminado y ajustar la configuración con mucho cuidado y solo después de corregir un conjunto de signos. Ahora, un entrenamiento tomó aproximadamente 15 horas, pero un modelo logró obtener la velocidad mejor que en el conjunto con la clasificación.
Generación de funciones
En la competencia "Sistemas de colaboración" se evalúa una gran cantidad de características como importantes para el modelo. Por ejemplo, auditweights_spark_svd es el atributo más importante y no hay información sobre lo que significa. Pensé que valía la pena contar las distintas unidades en función de signos importantes. Por ejemplo, el promedio auditweights_spark_svd por usuario, por grupo, por objeto. Lo mismo se puede calcular a partir de los datos en los que no se realiza el entrenamiento y target = 1, es decir, el promedio de auditweights_spark_svd por usuario para los objetos que le gustaron. Hubo varios signos importantes, además de auditweights_spark_svd . Aquí hay algunos de ellos:
- auditweightsCtrGender
- auditweightsCtrHigh
- userOwnerCounterCreateLikes
Por ejemplo, el valor promedio de auditweightsCtrGender por userId resultó ser una característica importante, así como el valor promedio de userOwnerCounterCreateLikes por userId + ownerId. Esto debería habernos hecho pensar en cómo entender el significado de los campos.
Otras características importantes fueron auditweightsLikesCount y auditweightsShowsCount . Al dividir uno en otro, se obtuvo una característica aún más importante.
Fugas de datos.
Los modelos de competencia y producción son tareas muy diferentes. Al preparar los datos, es muy difícil tener en cuenta todos los detalles y no transferir información no trivial sobre la variable objetivo en la prueba. Si creamos una solución de producción, intentaremos evitar el uso de fugas de datos al entrenar el modelo. Pero si queremos ganar el concurso, entonces las filtraciones de datos son las mejores características.
Después de examinar los datos, puede ver que según objectId, los valores de auditweightsLikesCount y auditweightsShowsCount cambian, lo que significa que la proporción de los valores máximos de estos signos reflejará la conversión posterior mucho mejor que la proporción en el momento de la entrega.
La primera fuga que encontramos fue auditweightsLikesCountMax / auditweightsShowsCountMax .
Pero, ¿qué pasa si observa los datos más de cerca? Ordenar por fecha de entrega y obtener:
| objectId | ID de usuario | auditweightsShowsCount | auditweightsLikesCount | objetivo (le gusta) |
|---|
| 1 | 1 | 12 | 3 | probablemente no |
| 1 | 2 | 15 | 3 | probablemente si |
| 1 | 3 | 16 | 4 4 | |
Fue sorprendente cuando encontré el primer ejemplo de este tipo y resultó que mi predicción no se hizo realidad. Pero, dado el hecho de que los valores máximos de estos signos dentro del marco del objeto aumentaron, no fuimos demasiado vagos y decidimos encontrar auditweightsShowsCountNext y auditweightsLikesCountNext , es decir, valores en el momento siguiente. Añadiendo característica
(auditweightsShowsCountNext-auditweightsShowsCount) / (auditweightsLikesCount-auditweightsLikesCountNext) hicimos un brusco salto durante todo el día.
Se podrían usar fugas similares si se encuentran los siguientes valores para userOwnerCounterCreateLikes dentro de userId + ownerId y, por ejemplo, auditweightsCtrGender dentro de objectId + userGender. Encontramos 6 campos similares con fugas y extrajimos información de ellos tanto como fue posible.
Para entonces, habíamos exprimido un máximo de información de los atributos de colaboración, pero no volvimos a los concursos de imágenes y textos. Hubo una gran idea para verificar: ¿cuánto dan las características directamente en las imágenes o textos en las competiciones correspondientes?
No hubo fugas en los concursos de imágenes y textos, pero para ese momento había devuelto los parámetros predeterminados de catboost, peiné el código y agregué algunas características. Resultado total:
| Solución | velocidad |
|---|
| Máximo con imágenes | 0.6411 |
| Máximo sin imágenes | 0.6297 |
| Resultado del segundo lugar | 0.6295 |
| Solución | velocidad |
|---|
| Máximo con textos | 0,666 |
| Máximo sin textos | 0.660 |
| Resultado del segundo lugar | 0,656 |
| Solución | velocidad |
|---|
| Máximo en colaboración | 0,745 |
| Resultado del segundo lugar | 0,723 |
Se hizo evidente que era improbable que muchos textos e imágenes se eliminaran, y después de probar algunas de las ideas más interesantes, dejamos de trabajar con ellos.
La generación adicional de características en sistemas colaborativos no dio crecimiento, y comenzamos a clasificar. En la etapa en línea, el conjunto de clasificación y clasificación me dio un pequeño aumento, ya que resultó que tenía una clasificación poco entrenada. Ninguna de las funciones de error, incluido YetiRanlPairwise, incluso dio resultados cercanos que LogLoss dio (0.745 contra 0.725). Había esperanza de que QueryCrossEntropy no se pudiera iniciar.
Etapa fuera de línea
En la etapa fuera de línea, la estructura de datos se ha mantenido igual, pero ha habido pequeños cambios:
- los identificadores userId, objectId, ownerId se han aleatorizado nuevamente;
- Se eliminaron varios letreros y se cambió el nombre de varios.
- los datos se han convertido en 1,5 veces más.
Además de las dificultades enumeradas, hubo una gran ventaja: se asignó un gran servidor con RTX 2080TI al equipo. Disfruté htop por mucho tiempo.
La idea era una: solo reproducir lo que ya está allí. Después de pasar un par de horas configurando el entorno en el servidor, gradualmente comenzamos a verificar que los resultados se estaban reproduciendo. El principal problema que enfrentamos es el aumento en el volumen de datos. Decidimos reducir ligeramente la carga y establecer el parámetro catboost ctr_complexity = 1. Esto reduce un poco la velocidad, pero mi modelo comenzó a funcionar, el resultado fue bueno: 0.733. Sergei, a diferencia de mí, no dividió los datos en 2 partes y se capacitó en todos los datos, aunque esto dio el mejor resultado en la etapa en línea, hubo muchas dificultades en la etapa fuera de línea. Si tomamos todas las características que hemos generado y tratamos de ponerlo en catboost “en la frente”, entonces nada hubiera sucedido en la etapa en línea. Sergey sí optimizó los tipos, por ejemplo, convirtiendo los tipos float64 en float32. En este artículo puede encontrar información sobre cómo optimizar la memoria en pandas. Como resultado, Sergey se entrenó en la CPU en todos los datos y resultó aproximadamente 0.735.
Estos resultados fueron suficientes para ganar, pero ocultamos nuestra velocidad real y no podíamos estar seguros de que otros equipos no estuvieran haciendo lo mismo.
Batalla hasta el final
Tuning catboost
Nuestra solución se reprodujo por completo, agregamos características de datos de texto e imágenes, por lo que todo lo que quedaba era ajustar los parámetros de catboost. Sergey estudió en la CPU con un pequeño número de iteraciones, y yo estudié con ctr_complexity = 1. Solo quedaba un día, y si solo agrega iteraciones o aumenta ctr_complexity, por la mañana podría obtener una velocidad aún mejor y caminar todo el día.
En la etapa fuera de línea, los puntajes podrían ser muy fáciles de ocultar, simplemente eligiendo no la mejor solución en el sitio. Esperábamos cambios bruscos en la clasificación en los últimos minutos antes del cierre de las presentaciones y decidimos no parar.
Del video de Anna, aprendí que para mejorar la calidad del modelo, es mejor seleccionar los siguientes parámetros:
- learning_rate : el valor predeterminado se calcula en función del tamaño del conjunto de datos. Con una disminución en la tasa de aprendizaje, para mantener la calidad, es necesario aumentar el número de iteraciones.
- l2_leaf_reg : coeficiente de regularización, valor predeterminado de 3, preferiblemente de 2 a 30. Una disminución en el valor conduce a un aumento en el sobreajuste.
- bagging_temperature : agrega aleatorización a los pesos de los objetos en la selección. El valor predeterminado es 1, en el que los pesos se seleccionan de la distribución exponencial. Una disminución en el valor conduce a un aumento en el sobreajuste.
- random_strength - Afecta la elección de divisiones para una iteración particular. Cuanto mayor sea random_strength, mayor será la posibilidad de que se seleccione una división de baja importancia. En cada iteración posterior, la aleatoriedad disminuye. Una disminución en el valor conduce a un aumento en el sobreajuste.
Otros parámetros afectan significativamente menos el resultado final, por lo que no intenté seleccionarlos. Una iteración de entrenamiento en mi conjunto de datos de GPU con ctr_complexity = 1 tomó 20 minutos, y los parámetros seleccionados en el conjunto de datos reducido fueron ligeramente diferentes de los óptimos en el conjunto de datos completo. Como resultado, hice unas 30 iteraciones en el 10% de los datos, y luego unas 10 iteraciones más en todos los datos. Resultó aproximadamente lo siguiente:
- Aumenté learning_rate en un 40% del valor predeterminado;
- l2_leaf_reg dejó lo mismo;
- bagging_temperature y random_strength reducido a 0.8.
Podemos concluir que con los parámetros predeterminados, el modelo está poco capacitado.
Me sorprendió mucho cuando vi el resultado en la tabla de clasificación:
| Modelo | modelo 1 | modelo 2 | modelo 3 | conjunto |
|---|
| Sin sintonización | 0.7403 | 0.7404 | 0.7404 | 0.7407 |
| Con afinación | 0.7406 | 0.7405 | 0.7406 | 0.7408 |
Llegué a la conclusión de que si no necesita una aplicación rápida del modelo, entonces es mejor reemplazar la selección de parámetros con un conjunto de varios modelos en parámetros no optimizados.
Sergey se ocupó de optimizar el tamaño del conjunto de datos para ejecutarlo en la GPU. — , :
- ( ), ;
- ;
- userId, ;
- userId, .
— .
, 0,742. ctr_complexity=2 30 5 . 4 , , 0,7433.
, , . predict(prediction_type='RawFormulaVal') scale_pos_weight=neg_count/pos_count.
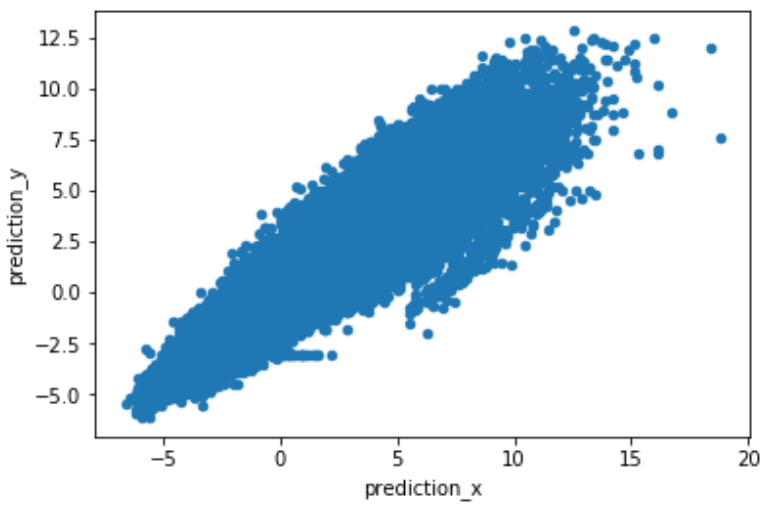
.
. , , , 2 .
Conclusión
:
- , target encoding, catboost.
- , , learning_rate iterations. — .
- GPU. Catboost GPU, .
- rsm~=0.2 (CPU only) ctr_complexity=1.
- A diferencia de otros equipos, el conjunto de nuestros modelos dio un gran aumento. Intercambiamos ideas y escribimos en diferentes idiomas. Teníamos un enfoque diferente para dividir los datos, y creo que todos tenían sus propios errores.
- No está claro por qué la optimización de clasificación arrojó peores resultados que la optimización de clasificación.
- Obtuve un poco de experiencia con textos y entendí cómo se hacen los sistemas de recomendación.

Gracias a los organizadores por las emociones, el conocimiento y los premios recibidos.