
Hola Habr! Continúo publicando el ciclo sobre el interior de la plataforma de pago RBK.money, que comenzó en esta publicación . Hoy hablaremos sobre el esquema de procesamiento lógico, los microservicios específicos y su relación entre ellos, cómo los servicios que procesan cada parte de la lógica de negocios están separados lógicamente, por qué el núcleo de procesamiento no sabe nada sobre los números de sus tarjetas de pago y cómo se ejecutan los pagos dentro de la plataforma. Además, con un poco más de detalle, revelaré el tema de cómo proporcionamos alta disponibilidad y escala para manejar altas cargas.
Visión general lógica y enfoques generales
En general, el esquema de los elementos básicos de esa parte del procesamiento responsable de los pagos se ve así.
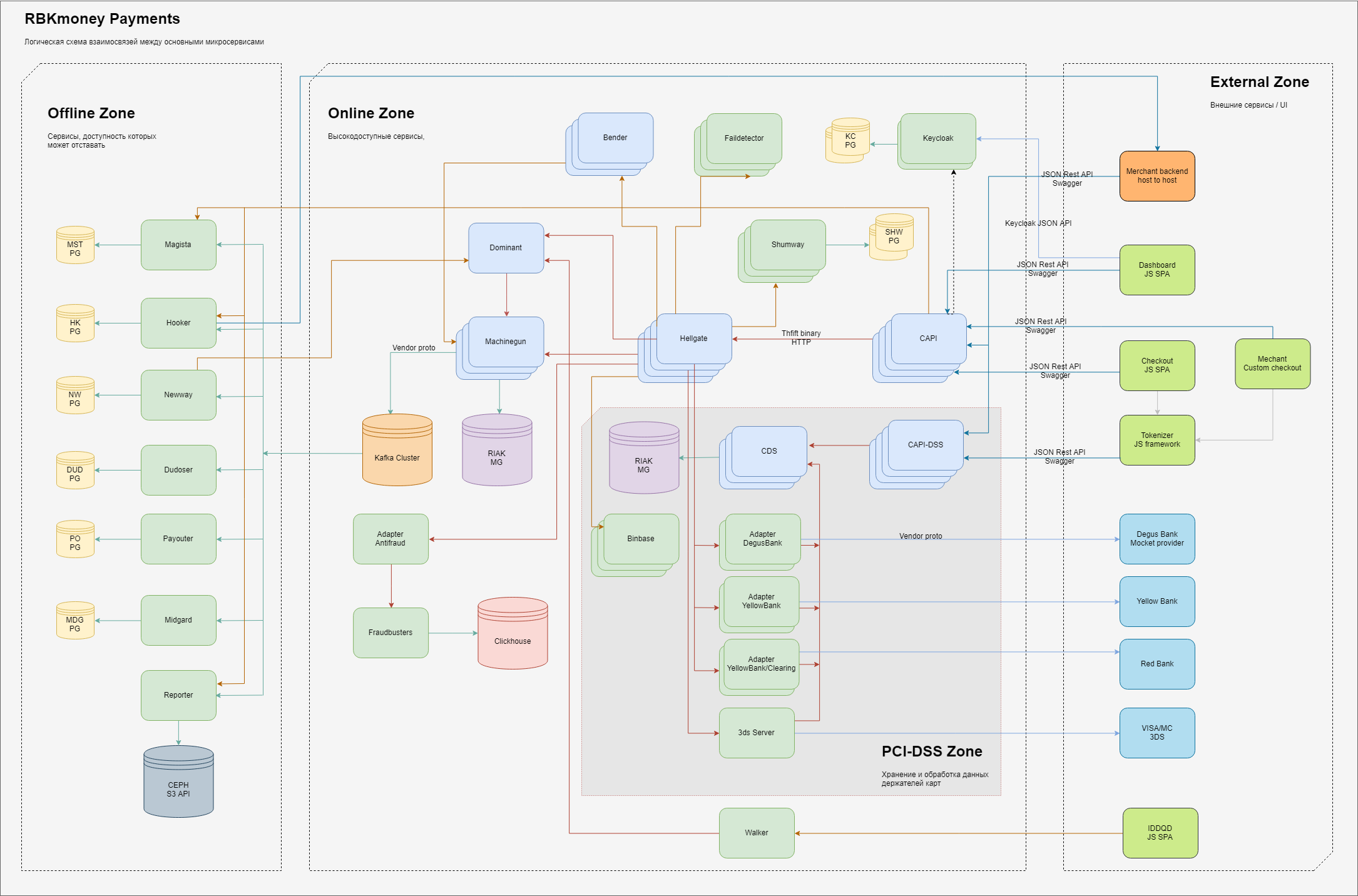
Lógicamente dentro de nosotros mismos, dividimos las áreas de responsabilidad en 3 dominios:
- zona externa, entidades que están en Internet, como aplicaciones JS de nuestro formulario de pago (ingrese los datos de su tarjeta allí), backends de nuestros clientes comerciales, así como pasarelas de procesamiento de nuestros bancos asociados y proveedores de otros métodos de pago;
- una zona interna altamente accesible, los microservicios viven allí, que proporcionan el trabajo de la pasarela de pago directamente y gestionan el débito de dinero, teniendo en cuenta en nuestro sistema y otros servicios en línea, que se caracterizan por el requisito "siempre debe estar disponible, a pesar de cualquier falla dentro de nuestros CD";
- Hay un área separada de servicios que trabaja directamente con los datos completos de los titulares de tarjetas; estos servicios tienen requisitos separados establecidos por el Ministerio de Ferrocarriles y sujetos a certificación obligatoria bajo los estándares PCI-DSS. Explicaremos con más detalle por qué tal separación a continuación;
- La zona interior, donde hay requisitos menores para la disponibilidad de los servicios prestados o el tiempo de su respuesta, en el sentido clásico, es un back office. Aunque, por supuesto, aquí también tratamos de garantizar el principio de "siempre disponible", simplemente dedicamos menos esfuerzo a esto;
Dentro de cada zona hay microservicios que realizan sus partes de procesamiento de lógica de negocios. Reciben llamadas RPC en la entrada, y en la salida, generan datos procesados utilizando algoritmos integrados, que también se ejecutan como llamadas de otros microservicios a lo largo de la cadena.
Para garantizar la escalabilidad, intentamos almacenar estados en el menor número de lugares posible. Los servicios sin estado en el diagrama no tienen conexiones con almacenes persistentes, con estado, respectivamente, están conectados a ellos. En general, utilizamos varios servicios limitados para el almacenamiento de estado persistente; para la parte principal del procesamiento, estos son clústeres Riak KV, para servicios relacionados: PostgreSQL, para el procesamiento de cola asíncrono, utilizamos Kafka.
Para garantizar una alta disponibilidad, implementamos servicios en varios casos, generalmente de 3 a 5.
Es fácil escalar los servicios sin estado, simplemente aumentamos el número de instancias que necesitamos en diferentes máquinas virtuales, están registrados en Consul, están disponibles para resolver a través de la consola DNS y comienzan a recibir llamadas de otros servicios, procesan los datos recibidos y los envían más.
Los servicios con estado, o más bien es nuestro principal y se muestran en el diagrama como Machinegun, implementan una interfaz altamente accesible (la arquitectura distribuida se basa en la distribución de Erlang), y la sincronización a través de Consul KV se utiliza para garantizar el bloqueo en cola y distribuido. Esta es una descripción breve y detallada en una publicación separada.
Fuera de la caja, Riak proporciona un almacenamiento sin maestros persistente altamente accesible, no lo preparamos de ninguna manera, la configuración está casi predeterminada. Con el perfil de carga actual, tenemos 5 nodos en el clúster implementados en hosts separados. Una nota importante: prácticamente no utilizamos índices y muestras de datos grandes, trabajamos con claves específicas.
Cuando es demasiado costoso implementar el esquema KV, utilizamos bases de datos PostgeSQL con replicación, o incluso soluciones de modo único, ya que siempre podemos cargar los eventos necesarios en caso de falla de la parte en línea a través de Machinegun.
La separación de colores de los microservicios en el diagrama indica los idiomas en los que están escritos, verde claro, estas son aplicaciones Java, azul claro, Erlang.
Todos los servicios funcionan en contenedores Docker, que son artefactos de compilación de CI y se encuentran en el Registro local de Docker. Implementa servicios en la producción de SaltStack, cuya configuración se encuentra en el repositorio privado de Github.
Los desarrolladores realizan de forma independiente solicitudes de cambios en este repositorio, donde describen los requisitos para el servicio: indican la versión y los parámetros deseados, como el tamaño de la memoria asignada para el contenedor, transferida a las variables de entorno y otras cosas. Además, después de la confirmación manual de la solicitud de cambio por parte de los empleados autorizados (tenemos DevOps, soporte y seguridad de la información), el CD automáticamente acumula las instancias del contenedor con las nuevas versiones para los hosts del entorno del producto.
Además, cada servicio escribe registros en un formato comprensible para Elasticsearch. Filebeat recoge los archivos de registro, que los escribe en el clúster Elasticsearch. Por lo tanto, a pesar de que los desarrolladores no tienen acceso al entorno del producto, siempre tienen la oportunidad de depurar y ver qué sucede con sus servicios.
Interacción con el mundo exterior.

Cualquier cambio en el estado de la plataforma con nosotros ocurre exclusivamente a través de llamadas a los métodos correspondientes de API públicas. No utilizamos aplicaciones web clásicas ni la generación de contenido del lado del servidor, de hecho, todo lo que ves como una interfaz de usuario son vistas JS sobre nuestras API públicas. En principio, cualquier acción en la plataforma se puede realizar con una cadena de llamadas curl desde la consola, que utilizamos. En particular, para escribir pruebas de integración (las hemos escrito en JS como una biblioteca), que en CI, durante cada ensamblaje, verifica todos los métodos públicos.
Además, este enfoque resuelve todos los problemas de integración externa con nuestra plataforma, lo que le permite obtener un protocolo único para el usuario final en forma de una hermosa forma de ingresar datos de pago y de host a host para la integración directa con el procesamiento de terceros utilizando la interacción exclusivamente entre servidores.
Además de la cobertura total de las pruebas de integración, utilizamos los enfoques de actualización por etapas, en una arquitectura distribuida es bastante fácil hacer esto, por ejemplo, implementando solo un servicio de cada grupo en una sola pasada, seguido de una pausa y análisis de registros y gráficos.
Esto nos permite implementar casi todo el día, incluso los viernes por la noche, desplegar algo que no funciona sin mucho miedo o retroceder rápidamente, haciendo un simple revertir el compromiso con un cambio, hasta que nadie se dé cuenta.

Antes de cualquier llamada al método público, debemos autorizar y autenticar al cliente. Para que un cliente aparezca en la plataforma, necesita un servicio que se encargará de toda la interacción con el usuario final, proporcionará interfaces para registrar, ingresar y restablecer contraseñas, control de seguridad y otros enlaces.
Aquí, no inventamos una bicicleta, sino que simplemente integramos la solución de código abierto de Redhat - Keycloak . Antes de comenzar cualquier interacción con nosotros, deberá registrarse en la plataforma, lo que, de hecho, ocurre a través de Keycloak.
Después de una autenticación exitosa en el servicio, el cliente recibe un JWT. Lo usaremos más tarde para la autorización: en el lado de Keycloak, puede especificar campos arbitrarios que describan roles que se integrarán como una estructura json simple en JWT y se firmarán con la clave privada del servicio.
Una de las características de JWT es que esta estructura está firmada por la clave privada del servidor; en consecuencia, para autorizar la lista de roles y sus otros objetos, no necesitamos acceder al servicio de autorización, el proceso está completamente desacoplado. Los servicios CAPI al inicio leen la clave pública Keycloak y la usan para autorizar llamadas a métodos API públicos.
A medida que se nos ocurrió el esquema de revocación de claves, la historia es independiente y merece su propia publicación.
Entonces, hemos recibido el JWT, podemos usarlo para la autenticación. Aquí entra en juego el grupo de microservicios Common API, en el diagrama indicado como CAPI y CAPI-DSS, que implementan las siguientes funciones:
- autorización de mensajes recibidos. Cada llamada API pública está precedida por un encabezado HTTP Authorizaion: Bearer {JWT}. Los servicios del grupo API común lo utilizan para verificar los datos firmados con la clave pública existente del servicio de autorización;
- validación de los datos recibidos. Dado que el esquema se describe como una especificación OpenAPI, también conocida como Swagger, la validación de datos puede ser muy fácil y con pocas posibilidades de recibir comandos de control en el flujo de datos. Esto tiene un efecto positivo en la seguridad del servicio en su conjunto;
- traducción de formatos de datos de REST JSON público a binario interno Thrift;
- enmarcando el enlace de transporte con datos como un único trace_id y pasando el evento más adentro de la plataforma a un servicio que gestiona la lógica de negocios y sabe qué es, por ejemplo, el pago.
Tenemos muchos de estos servicios, son bastante simples y no almacenan ningún estado, por lo que para el escalado de rendimiento lineal simplemente los implementamos en capacidades libres en las cantidades que necesitamos.
PCI-DSS y datos de tarjeta abierta

Como puede ver en el diagrama, tenemos dos de estos grupos de servicios: el principal, la API común, es responsable de procesar todos los flujos de datos que no tienen datos abiertos del titular de la tarjeta, y el segundo, la API común PCI-DSS, que funciona directamente con estas tarjetas. En el interior, son exactamente iguales, pero los separamos físicamente y los colocamos en diferentes piezas de hierro.
Esto se hace para minimizar el número de ubicaciones para almacenar y procesar datos de tarjetas, reducir los riesgos de fuga de estos datos y el área de certificación PCI-DSS. Y esto, créanme, es un proceso bastante lento y costoso: como compañía de pagos, debemos someternos a una certificación paga para cumplir con los estándares MPS cada año, y cuantos menos servidores y servicios participen en él, más rápido y fácil será completar este proceso. Bueno, en seguridad esto se refleja de la manera más positiva.
Facturación y Tokenización
Por lo tanto, queremos comenzar el pago y cancelar el dinero de la tarjeta del pagador.
Imagine que la solicitud se realizó en forma de una cadena de llamadas a los métodos de nuestra API pública, que usted inició como pagador después de ir a la tienda en línea, recoger una cesta de productos, hacer clic en "Comprar" e ingresar los datos de su tarjeta en nuestro pago formulario y haga clic en el botón "Pagar".
Proporcionamos varios procesos comerciales para cancelar dinero, pero el más interesante es el proceso que utiliza cuentas por pagar. En nuestra plataforma, puede crear una factura para el pago, o una factura que será un contenedor para los pagos.
Dentro de una factura, puede intentar pagarla una por una, es decir, crear pagos hasta que el próximo pago sea exitoso. Por ejemplo, puede intentar pagar una factura desde diferentes tarjetas, billeteras y cualquier otro método de pago. Si no hay dinero en una de las tarjetas, puede probar con otra y así sucesivamente.
Esto tiene un efecto positivo en la conversión y la experiencia del usuario.
Máquina de estado de factura

Dentro de la plataforma, esta cadena se convierte en interacciones a lo largo de la siguiente ruta:
- Antes de entregar contenido a su navegador, nuestro cliente-comerciante se integró con nuestra plataforma, se registró con nosotros y recibió un JWT para autorización;
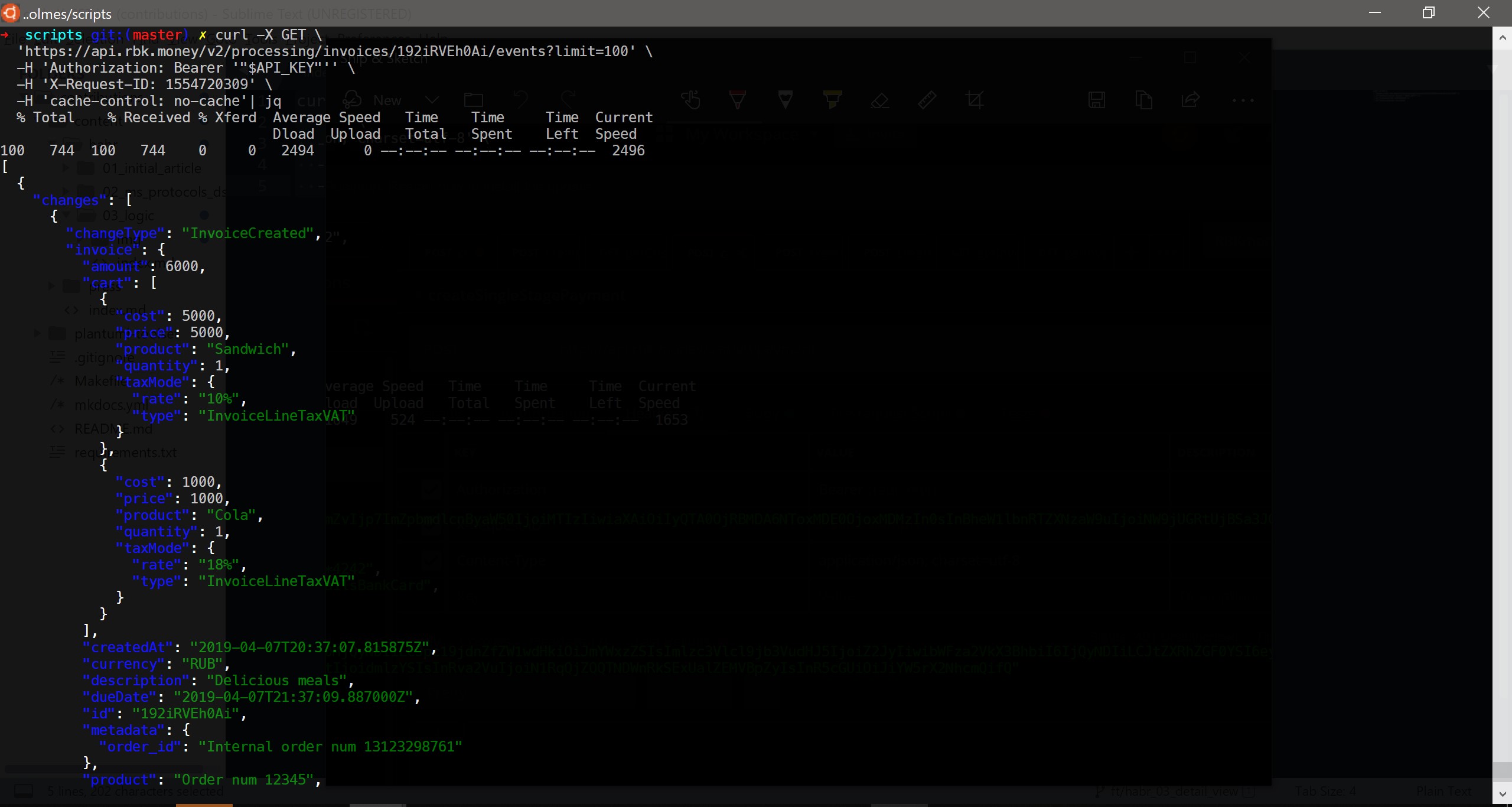
- desde su backend, el comerciante llamó al método createInvoice () , es decir, creó una factura para el pago en nuestra plataforma. De hecho, el backend del comerciante envió una solicitud HTTP POST del siguiente contenido a nuestro punto final:
curl -X POST \ https://api.rbk.money/v2/processing/invoices \ -H 'Authorization: Bearer {JWT}' \ -H 'Content-Type: application/json; charset=utf-8' \ -H 'X-Request-ID: 1554417367' \ -H 'cache-control: no-cache' \ -d '{ "shopID": "TEST", "dueDate": "2019-03-28T17:41:32.569Z", "amount": 6000, "currency": "RUB", "product": "Order num 12345", "description": "Delicious meals", "cart": [ { "price": 5000, "product": "Sandwich", "quantity": 1, "taxMode": { "rate": "10%", "type": "InvoiceLineTaxVAT" } }, { "price": 1000, "product": "Cola", "quantity": 1, "taxMode": { "rate": "18%", "type": "InvoiceLineTaxVAT" } } ], "metadata": { "order_id": "Internal order num 13123298761" } }'
La solicitud se equilibró en una de las aplicaciones erlang del grupo Common API, que verificó su validez, fue al servicio Bender, donde recibió la clave de idempotencia, la transfirió al tift y envió una solicitud al grupo de servicios Hellgate. La instancia de Hellgate realizó verificaciones comerciales, por ejemplo, se aseguró de que el propietario de este JWT no esté bloqueado en principio, pueda crear facturas y, en general, interactuar con la plataforma y comenzó a crear una factura.
Podemos decir que Hellgate es el núcleo de nuestro procesamiento, ya que es él quien opera con entidades comerciales, sabe cómo iniciar un pago, quién debe ser expulsado para que este pago se convierta en un cargo de dinero real, cómo calcular la ruta de este pago, a quién se le debe pedir que cancele el pago. reflejado en los balances, calcular comisiones y otros enlaces.
Por lo general, tampoco almacena ningún estado y también es fácilmente escalable. Pero no querríamos perder la factura ni obtener un doble cargo de dinero de la tarjeta en caso de una división de la red o la falla de Hellgate por cualquier motivo. Es necesario guardar persistentemente estos datos.
Aquí viene el tercer microservicio, a saber, Machinegun. Hellgate envía a Machinegun una llamada para "crear un autómata" con una carga útil en forma de parámetros de consulta. Machinegun organiza solicitudes concurrentes y, utilizando Hellgate, crea el primer evento a partir de los parámetros: InvoiceCreated. Que luego se escribe y escribe en Riak y colas. Después de eso, se devuelve una respuesta exitosa en el orden inverso a la solicitud inicial en la cadena.
En resumen, Machinegun es un DBMS con temporizadores sobre cualquier otro DBMS, en la versión actual de la plataforma, sobre Riak. Proporciona una interfaz que le permite controlar máquinas independientes y garantiza garantías de idempotencia y orden de grabación. Es MG el que no permitirá que el evento se escriba fuera de la cola automáticamente si varios HG llegan repentinamente con tal solicitud.
Un autómata es una entidad única dentro de la plataforma, que consta de un identificador, un conjunto de datos en forma de una lista de eventos y un temporizador. El estado final del autómata se calcula a partir del procesamiento de todos sus eventos que inician su transición al estado correspondiente. Utilizamos este enfoque para trabajar con entidades comerciales, describiéndolas como máquinas de estados finitos. De hecho, todas las facturas creadas por nuestros comerciantes, así como los pagos en ellas, son máquinas de estados finitos con su propia lógica de transición entre estados.
La interfaz para trabajar con temporizadores en Machinegun le permite recibir una solicitud del formulario "Quiero continuar procesando esta máquina en 15 años" de otro servicio junto con eventos para la grabación. Dichas tareas pendientes se implementan en temporizadores integrados. En la práctica, se usan con mucha frecuencia: llamadas periódicas al banco, acciones automáticas con pagos debido a una larga inactividad, etc.
Por cierto, los códigos fuente de Machinegun están abiertos bajo la licencia Apache 2.0 en nuestro repositorio público . Esperamos que este servicio pueda ser de utilidad para la comunidad.
Una descripción detallada del trabajo de Machinegun y, en general, cómo preparamos el sistema de distribución, se traslada a una publicación grande separada, por lo que no me detendré aquí con más detalle.
Los matices de autorización de clientes externos.

Después de un guardado exitoso, Hellgate devuelve los datos al CAPI, convierte la estructura trift binaria en un JSON bellamente diseñado, listo para ser enviado al backend comercial:
{ "invoice": { "amount": 6000, "cart": [ { "cost": 5000, "price": 5000, "product": "Sandwich", "quantity": 1, "taxMode": { "rate": "10%", "type": "InvoiceLineTaxVAT" } }, { "cost": 1000, "price": 1000, "product": "Cola", "quantity": 1, "taxMode": { "rate": "18%", "type": "InvoiceLineTaxVAT" } } ], "createdAt": "2019-04-04T23:00:31.565518Z", "currency": "RUB", "description": "Delicious meals", "dueDate": "2019-04-05T00:00:30.889000Z", "id": "18xtygvzFaa", "metadata": { "order_id": "Internal order num 13123298761" }, "product": "Order num 12345", "shopID": "TEST", "status": "unpaid" }, "invoiceAccessToken": { "payload": "{JWT}" } }
Parece que puede enviar contenido al pagador en el navegador e iniciar el proceso de pago, pero aquí pensamos que no todos los comerciantes estarían listos para implementar independientemente la autorización en el lado del cliente, por lo que lo implementamos nosotros mismos. El enfoque es que CAPI genera otro JWT que le permite iniciar procesos de tokenización de tarjetas y administrar una factura específica y la agrega a la estructura de la factura devuelta.
Un ejemplo de los roles descritos dentro de un JWT similar:
"resource_access": { "common-api": { "roles": [ "invoices.18xtygvzFaa.payments:read", "invoices.18xtygvzFaa.payments:write", "invoices.18xtygvzFaa:read", "payment_resources:write" ] } }
Este JWT tiene un número limitado de intentos de uso y la vida útil que configuramos, lo que le permite publicarlo en el navegador del pagador. Incluso si se intercepta, lo máximo que un atacante puede hacer es pagar la factura de otra persona o leer sus datos. Además, dado que la máquina de pago no funciona con datos de tarjetas abiertas, lo máximo que puede ver un atacante es un número de tarjeta enmascarada del tipo 4242 42** **** 4242 , el monto del pago y, opcionalmente, una cesta de mercancías.
La factura creada y la clave de acceso le permiten iniciar el proceso comercial de pago. Entregamos el ID de la factura y su JWT al navegador del pagador y transferimos el control a nuestras aplicaciones JS.
Nuestra aplicación Checkout JS implementa una interfaz para interactuar con usted como pagador: dibuja un formulario de ingreso de datos de pago, inicia un pago, recibe su estado final, muestra un punto divertido o triste.
Tokenización y datos de la tarjeta

Pero Checkout no funciona con los datos de la tarjeta. Como se mencionó anteriormente, queremos almacenar datos confidenciales en forma de datos del titular de la tarjeta en la menor cantidad de lugares posible. Para hacer esto, implementamos tokenización.
Aquí es donde entra en juego la biblioteca Tokenizer JS. Cuando ingresa su tarjeta en los campos de entrada y hace clic en "Pagar", intercepta estos datos y nos los envía de forma asíncrona para su procesamiento llamando al método createPaymentResource () .
Esta solicitud está equilibrada para aplicaciones CAPI-DSS individuales, que también autorizan la solicitud, solo verificando la factura JWT, validando los datos y enviándolos por adelantado al servicio de almacenamiento de datos de la tarjeta. En el diagrama, se indica como CDS - Almacenamiento de datos de tarjeta.
Los principales objetivos de este servicio:
- recibir datos confidenciales en una entrada, en nuestro caso, datos de su tarjeta;
- cifrar estos datos con una clave de cifrado de datos;
- generar algún valor aleatorio utilizado como clave;
- guardar datos cifrados en esta clave en su clúster Riak;
- devuelva la clave en forma de token de datos de pago al servicio CAPI-DSS.
En el camino, el servicio resuelve un montón de tareas importantes, como generar claves para cifrar claves, ingresar estas claves de forma segura, volver a cifrar datos, controlar la eliminación de CVV después del pago, etc., pero esto está más allá del alcance de esta publicación.
No fue sin protección contra la posibilidad de dispararte en el pie. Existe una probabilidad distinta de cero de que un JWT privado, diseñado para autorizar solicitudes del backend, se publique en la web en el navegador del cliente. Para evitar que esto suceda, incorporamos protección: puede llamar al método createPaymentResource () solo con la clave de autorización de la factura. Cuando intente utilizar una plataforma JWT privada, devolverá un error HTTP / 401.
Después de completar la solicitud de tokenización, el Tokenizer devuelve el token recibido a Checkout y finaliza su trabajo al respecto.
Proceso de negocio de máquina de pago

Checkout inicia el proceso de pago, es decir, llama al método createPayment () , pasa el token de la tarjeta previamente recibido como argumento e inicia el proceso de eventos de sondeo, de hecho, llama al método API getInvoiceEvents () una vez por segundo.
Estas solicitudes a través de CAPI se incluyen en Hellgate, que comienza a implementar un proceso comercial de pago, sin utilizar los datos de la tarjeta:
- En primer lugar, Hellgate va al servicio de administración de configuración - Dominante y recibe la revisión actual de la configuración del dominio. Contiene todas las reglas por las cuales se realizará este pago, para qué banco irá a autorización, qué tarifas de transacción se registrarán, etc.
- del servicio de gestión de miembros, ahora es parte de HG, aprende datos sobre los números internos de las cuentas del comerciante a favor de los cuales se realiza el pago, aplica el monto de las tarifas, prepara un plan de contabilización y lo pone en el servicio Shumway. Este servicio es responsable de administrar la información sobre el movimiento de dinero en las cuentas de los participantes en una transacción al realizar un pago. El plan de contabilización contiene la instrucción "para congelar el posible movimiento de fondos en las cuentas de los participantes en la transacción especificada en el plan";
- enriquece los datos de pago al referirse a servicios adicionales, por ejemplo, en Binbase para averiguar el país del banco emisor que emitió la tarjeta y su tipo, por ejemplo, "oro, crédito";
- llama al servicio del inspector, por lo general, esto es Antifraude para recibir la puntuación de pago y decidir la elección de una terminal que cubra el nivel de riesgo emitido por la puntuación. Por ejemplo, un terminal sin 3D-Secure puede usarse para pagos de bajo riesgo, y un pago que ha recibido un nivel de riesgo fatal terminará su vida con esto;
- llama al servicio de detección de errores, el Detector de fallas y, en función de los datos recibidos, selecciona la ruta de pago: el adaptador de protocolo bancario, que actualmente tiene la menor cantidad de errores y la mayor probabilidad de pago exitoso;
- envía una solicitud al adaptador de protocolo de banco seleccionado, deje que sea el adaptador de YellowBank, "autorice la cantidad especificada de este token" en este caso.
El adaptador de protocolo para el token recibido va a CDS, recibe los datos descifrados de la tarjeta, los transfiere a un protocolo específico del banco y, en general, recibe autorización, confirmación del banco adquirente de que la cantidad indicada se ha congelado en la cuenta del pagador.
Es en este momento que recibe un SMS con un mensaje sobre el débito de fondos de su tarjeta desde su banco, aunque de hecho los fondos solo se han congelado en su cuenta.
El adaptador notifica a HG de la autorización exitosa, su código CVV se elimina del servicio CDS y este es el final de la etapa de interacción. La gerencia vuelve a HG.

Dependiendo de la llamada createPayment () especificada por el comerciante del proceso comercial de pago, HG espera llamadas desde la API externa al método de captura de autorización, es decir, la confirmación del retiro de dinero de su tarjeta, o lo hace inmediatamente por su cuenta, si el comerciante elige el esquema Pago en una sola etapa.
Como regla general, la mayoría de los comerciantes utilizan un pago en una etapa, sin embargo, hay categorías de negocios que, en el momento de la autorización, aún no conocen el monto total adeudado. Esto sucede a menudo en la industria del turismo cuando reserva un tour por una cantidad, y después de confirmar la reserva, la cantidad se especifica y puede diferir de la autorizada al principio.
A pesar del hecho de que la cantidad de confirmación puede ser exclusivamente igual o menor que la cantidad de autorización, aquí hay dificultades. Imagine que paga por un producto o servicio desde una tarjeta en una moneda diferente de la moneda de su cuenta bancaria a la que está vinculada la tarjeta.
En el momento de la autorización, el monto bloqueado en su cuenta en función del tipo de cambio del día de la autorización. Dado que el pago puede estar en el estado de "autorizado" (a pesar de que el Ministerio de Ferrocarriles tiene recomendaciones para un período máximo y ahora es de 3 días) durante varios días, la captura de la autorización se realizará a la tasa del día en que se realizó.
Por lo tanto, asume riesgos cambiarios, que pueden ser tanto a su favor como en su contra, especialmente en una situación de alta volatilidad en el mercado de divisas.
Para capturar la autorización, se produce el mismo proceso de comunicación con el adaptador de protocolo que para su recepción, y si tiene éxito, HG aplica el plan de registro de cuenta dentro de Shumway y transfiere el pago al estado "Pagado". Es en este momento que nosotros, como sistema de pago, tenemos obligaciones financieras con los participantes en la transacción.
También vale la pena señalar que Hellgate registra en Machinegun cualquier cambio en el estado de la máquina de facturación, que incluye el proceso de pago, lo que garantiza la persistencia de los datos y enriquece la factura con nuevos eventos.
Sincronización de estado de una máquina de pago y UI
Mientras el proceso de pago en segundo plano se lleva a cabo dentro de la plataforma, Checkout vierte el proceso solicitando eventos. Al recibir ciertos eventos, dibuja el estado actual del pago de manera comprensible para una persona: dibuja un precargador, muestra la pantalla "Su pago se procesó con éxito" o "No se pudo recibir el pago", o redirige el navegador a la página de su banco emisor para ingresar la contraseña 3D-Secure;
Si falla, Checkout le ofrecerá elegir otro método de pago o volver a intentarlo, comenzando así un nuevo pago como parte de la factura.
Tal esquema con sondeo de eventos hace posible restaurar el estado incluso después de cerrar la pestaña del navegador; en caso de inicio repetido, Checkout recibirá la lista actual de eventos y dibujará el escenario actual de interacción del usuario, por ejemplo, ofrecerá ingresar el código 3D-Secure o mostrará que el pago ya se ha completado con éxito.
Replicación de eventos en la zona sin conexión
Junto con las interfaces de control de la máquina, Machinegun implementa un servicio responsable de desbordar el flujo de eventos a los servicios responsables de otras tareas menos en línea de la plataforma.
Como agente de colas en las finales, nos decidimos por Kafka, aunque anteriormente implementamos esta funcionalidad utilizando Machinegun. En el caso general, este servicio es la preservación de un flujo de eventos ordenado garantizado, o la emisión de una lista específica de eventos a pedido de otros consumidores.
Inicialmente, también implementamos un esquema de deduplicación de eventos, proporcionando garantías de que el mismo evento no se replicaría dos veces, sin embargo, la carga en Riak, que fue generada por uno similar, nos hizo rechazarlo; después de todo, buscar por índices no es lo mejor. Capacidad de almacenamiento de KV. Ahora, cada consumidor de servicios es responsable de la deduplicación de eventos de forma independiente.
En general, la replicación de eventos por parte de Machinegun termina con la confirmación del almacenamiento de datos en Kafka, y los consumidores ya están conectados a los temas de Kafka y descargan las listas de eventos que les interesan.
Plantilla típica de aplicación de zona sin conexión
Por ejemplo, el servicio Dudoser es responsable de enviarle una notificación por correo electrónico de un pago exitoso. Al inicio, genera una lista de eventos de pagos exitosos, toma información sobre la dirección y la cantidad desde allí, la guarda en una instancia local de PostgreSQL y la usa para el procesamiento posterior de la lógica comercial.
Todos los demás servicios similares funcionan de acuerdo con la misma lógica, por ejemplo, el servicio Magista, que es responsable de buscar facturas y pagos en la cuenta personal del comerciante o el servicio Hooker, que envía devoluciones de llamada asincrónicas al backend a los comerciantes que por una razón u otra no pueden organizar eventos de votación contactando directamente a la API de procesamiento.
Este enfoque nos permite liberar la carga del procesamiento, asignar los recursos máximos y proporcionar alta velocidad y disponibilidad de procesamiento de pagos, proporcionando una alta conversión. Las consultas pesadas como "los clientes comerciales quieren ver las estadísticas sobre los pagos durante el año pasado" son procesadas por servicios que no afectan la carga actual de la parte de procesamiento en línea y, por lo tanto, no lo afectan a usted, como pagadores y comerciantes, como nuestros clientes.
Quizás nos detendremos en esto para no convertir la publicación en un alargado demasiado largo. En futuros artículos, definitivamente le contaré sobre los matices de garantizar la atomicidad de los cambios, las garantías y el orden en un sistema distribuido cargado usando Machinegun, Bender, CAPI e Hellgate como ejemplos.
Bueno, sobre Salt Stack la próxima vez ¯\_(ツ)_/¯