En la
primera parte del artículo, usando Ghidra, analizamos automáticamente un simple programa de crack (que descargamos de crackmes.one). Descubrimos cómo cambiar el nombre de las funciones "incomprensibles" directamente en la lista del descompilador, y también entendimos el algoritmo del programa de "nivel superior", es decir. que se realiza por
main () .
En esta parte, como prometí, tomaremos el análisis de la función
_construct_key () , que, como descubrimos, es responsable de leer el archivo binario transferido al programa y verificar la lectura de datos.
Paso 5 - Descripción general de la función _construct_key ()
Veamos la lista completa de esta función de inmediato:
Listado _construct_key ()char ** __cdecl _construct_key(FILE *param_1) { int iVar1; size_t sVar2; uint uVar3; uint local_3c; byte local_36; char local_35; int local_34; char *local_30 [4]; char *local_20; undefined4 local_19; undefined local_15; char **local_14; int local_10; local_14 = (char **)__prepare_key(); if (local_14 == (char **)0x0) { local_14 = (char **)0x0; } else { local_19 = 0; local_15 = 0; _text(&local_19,1,4,param_1); iVar1 = _text((char *)&local_19,*(char **)local_14[1],4); if (iVar1 == 0) { _text(local_14[1] + 4,2,1,param_1); _text(local_14[1] + 6,2,1,param_1); if ((*(short *)(local_14[1] + 6) == 4) && (*(short *)(local_14[1] + 4) == 5)) { local_30[0] = *local_14; local_30[1] = *local_14 + 0x10c; local_30[2] = *local_14 + 0x218; local_30[3] = *local_14 + 0x324; local_20 = *local_14 + 0x430; local_10 = 0; while (local_10 < 5) { local_35 = 0; _text(&local_35,1,1,param_1); if (*local_30[local_10] != local_35) { _free_key(local_14); return (char **)0x0; } local_36 = 0; _text(&local_36,1,1,param_1); if (local_36 == 0) { _free_key(local_14); return (char **)0x0; } *(uint *)(local_30[local_10] + 0x104) = (uint)local_36; _text(local_30[local_10] + 1,1,*(size_t *)(local_30[local_10] + 0x104),param_1); sVar2 = _text(local_30[local_10] + 1); if (sVar2 != *(size_t *)(local_30[local_10] + 0x104)) { _free_key(local_14); return (char **)0x0; } local_3c = 0; _text(&local_3c,1,1,param_1); local_3c = local_3c + 7; uVar3 = _text(param_1); if (local_3c < uVar3) { _free_key(local_14); return (char **)0x0; } *(uint *)(local_30[local_10] + 0x108) = local_3c; _text(param_1,local_3c,0); local_10 = local_10 + 1; } local_34 = 0; _text(&local_34,4,1,param_1); if (*(int *)(*local_14 + 0x53c) == local_34) { _text("Markers seem to still exist"); } else { _free_key(local_14); local_14 = (char **)0x0; } } else { _free_key(local_14); local_14 = (char **)0x0; } } else { _free_key(local_14); local_14 = (char **)0x0; } } return local_14; }
Con esta función haremos lo mismo que antes con
main () : para empezar, repasaremos las llamadas a funciones "veladas". Como era de esperar, todas estas funciones provienen de las bibliotecas estándar de C. No describiré el procedimiento para cambiar el nombre de las funciones nuevamente; si es necesario, regrese a la primera parte del artículo. Como resultado del cambio de nombre, se "encontraron" las siguientes funciones estándar:
- fread ()
- strncmp ()
- strlen ()
- ftell ()
- fseek ()
- pone ()
Cambiamos el nombre de las funciones de contenedor correspondientes en nuestro código (las que el descompilador oculta descaradamente detrás de la palabra
_text ) agregando el índice 2 (para que no haya confusión con las funciones C originales). Casi todas estas funciones son para trabajar con secuencias de archivos. No es sorprendente: un vistazo rápido al código es suficiente para comprender que lee datos secuencialmente de un archivo (cuyo descriptor se pasa a la función como el único parámetro) y compara los datos leídos con una determinada matriz bidimensional de bytes
locales_14 .
Supongamos que esta matriz contiene datos para la verificación de claves. Llámalo, di
key_array . Como Hydra le permite cambiar el nombre no solo de las funciones, sino también de las variables, usaremos esto y
cambiaremos el nombre del incomprensible
local_14 a un
key_array más comprensible. Esto se hace de la misma manera que para las funciones: a través del menú del botón derecho del mouse (
Cambiar nombre local ) o con la tecla
L del teclado.
Entonces, inmediatamente después de la declaración de variables locales, se
llama a una determinada función
_prepare_key () :
key_array = (char **)__prepare_key(); if (key_array == (char **)0x0) { key_array = (char **)0x0; }
Volveremos a
_prepare_key () , este es el tercer nivel de anidamiento en nuestra jerarquía de llamadas:
main () -> _construct_key () -> _prepare_key () . Mientras tanto, aceptamos que crea y de alguna manera inicializa esta matriz bidimensional de "prueba". Y solo si esta matriz no está vacía, la función continúa su trabajo, como lo demuestra el bloque
else inmediatamente después de la condición anterior.
Luego, el programa lee los primeros 4 bytes del archivo y lo compara con la sección correspondiente de la matriz
key_array . (El siguiente código es después de cambiar el nombre, incluida la variable
local_19, renombré first_4bytes ).
first_4bytes = 0; fread2(&first_4bytes,1,4,param_1); iVar1 = strncmp2((char *)&first_4bytes,*(char **)key_array[1],4); if (iVar1 == 0) { ... }
Por lo tanto, la ejecución adicional se produce solo si los primeros 4 bytes coinciden (recuerde esto). Luego leemos 2 bloques de 2 bytes del archivo (y el mismo
key_array se usa como búfer para escribir datos):
fread2(key_array[1] + 4,2,1,param_1); fread2(key_array[1] + 6,2,1,param_1);
Y de nuevo, además, la función solo funciona si la siguiente condición es verdadera:
if ((*(short *)(key_array[1] + 6) == 4) && (*(short *)(key_array[1] + 4) == 5)) {
Es fácil ver que el primero de los bloques de 2 bytes leídos anteriormente debe ser el número 5, y el segundo debe ser el número 4 (el tipo de datos
corto solo ocupa 2 bytes en plataformas de 32 bits).
Lo siguiente es esto:
local_30[0] = *key_array;
Aquí vemos que la matriz
local_30 (declarada como char * local_30 [4]) contiene los desplazamientos del puntero
key_array . Es decir,
local_30 es una matriz de líneas de marcador en la que probablemente se leerán los datos del archivo. Bajo esta suposición,
cambié el nombre de
local_30 a
marcadores . En esta sección de código, solo la última línea parece un poco sospechosa, donde la asignación del último desplazamiento (en el índice 0x430, es decir, 1072) no se realiza por el siguiente elemento de
marcadores , sino por una variable
local_20 separada (
char * ). Pero aún lo resolveremos, pero por ahora, ¡sigamos adelante!
A continuación estamos esperando un ciclo:
i = 0;
Es decir Solo 5 iteraciones de 0 a 4 inclusive. En el bucle, la lectura del archivo y la verificación del cumplimiento de nuestra matriz de
marcadores comienza de inmediato:
char c_marker = 0;
Es decir, el siguiente byte del archivo se lee en la variable
c_marker (en el código descompilado original -
local_35 ) y se verifica el cumplimiento del primer carácter del elemento de
marcadores i-th. En caso de una falta de coincidencia, la matriz
key_array se pone a cero y se devuelve un puntero doble vacío. Más adelante en el código, vemos que esto se hace cuando los datos leídos no coinciden con los datos de verificación.
Pero aquí, como dicen, "el perro está enterrado". Echemos un vistazo más de cerca a este ciclo. Tiene 5 iteraciones, como descubrimos. Puede verificar esto si lo desea mirando el código del ensamblador:


De hecho, el comando CMP compara el valor de la variable
local_10 (ya tenemos
i ) con el número 4 y si el valor es
menor o igual a 4 (el comando JLE), se realiza la transición a la etiqueta
LAB_004017eb , es decir. comienzo del cuerpo del ciclo. Es decir la condición se cumplirá para
i = 0, 1, 2, 3 y 4, ¡solo 5 iteraciones! Todo estaría bien, pero los
marcadores también
están indexados por esta variable en un bucle, y después de todo, esta matriz se declara con solo 4 elementos:
char *markers [4];
Entonces, alguien claramente está tratando de engañar a alguien :) ¿Recuerdas que dije que esta línea es dudosa?
local_20 = *key_array + 0x430;
Solo asi! Simplemente mire la lista completa de la función e intente encontrar al menos una referencia más a la variable
local_20 . Ella no esta ahi! Concluimos de esto: este desplazamiento también debe almacenarse en la matriz de
marcadores , y la matriz en sí misma debe contener 5 elementos. Vamos a arreglarlo Vaya a la declaración de variable,
presione Ctrl + L (Reescribir variable) y cambie audazmente el tamaño de la matriz a 5:
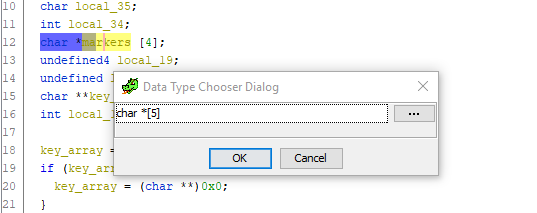
Listo Desplácese hacia abajo hasta el código para asignar desplazamientos de puntero a los
marcadores , y ¡he aquí! - una variable extra incomprensible desaparece y todo encaja:
markers[0] = *key_array; markers[1] = *key_array + 0x10c; markers[2] = *key_array + 0x218; markers[3] = *key_array + 0x324; markers[4] = *key_array + 0x430;
Volvemos a nuestro
ciclo while (en el código fuente, esto probablemente sea
para , pero no nos importa). A continuación, el byte del archivo se lee nuevamente y se verifica su valor:
byte n_strlen1 = 0;
OK, este
n_strlen1 debe ser distinto de cero. Por qué Verá ahora, pero al mismo tiempo comprenderá por qué le di a esta variable el siguiente nombre:
*(uint *)(markers[i] + 0x104) = (uint)n_strlen1; fread2(markers[i] + 1,1,*(size_t *)(markers[i] + 0x104),param_1); n_strlen2 = strlen2(markers[i] + 1);
Agregué comentarios en los que todo debería estar claro.
N_strlen1 bytes se leen del archivo y se guardan como una secuencia de caracteres (es decir, una cadena) en la matriz de
marcadores [i] , es decir, después del "símbolo de detención" correspondiente, que ya está escrito allí desde
key_array . Guardar el valor
n_strlen1 en los
marcadores [i] en el desplazamiento 0x104 (260) no juega ningún papel aquí (vea la primera línea en el código anterior). De hecho, este código se puede optimizar de la siguiente manera (y ciertamente este es el caso en el código fuente):
fread2(markers[i] + 1, 1, (size_t) n_strlen1, param_1); n_strlen2 = strlen2(markers[i] + 1); if (n_strlen2 != (size_t) n_strlen1) { ... }
También verifica que la longitud de la línea de lectura sea
n_strlen1 . Esto puede parecer innecesario, dado que este parámetro se pasó a la función
fread , pero
fread no lee
más que tantos bytes especificados y puede leer menos de lo indicado, por ejemplo, en el caso de cumplir con el marcador de fin de archivo (EOF). Es decir, todo es estricto: la longitud de la línea (en bytes) se indica en el archivo, luego la línea en sí va, y exactamente 5 veces. Pero nos estamos adelantando a nosotros mismos.
Además riega este código (que también comenté de inmediato):
uint n_pos = 0;
Todavía es más simple aquí: tomamos el siguiente byte del archivo, agregamos 7 y comparamos el valor resultante con la posición actual del cursor en la secuencia del archivo obtenida por la
función ftell () . El valor de
n_pos no debe ser menor que la posición del cursor (es decir, desplazamiento en bytes desde el comienzo del archivo).
La línea final en el bucle:
fseek2(param_1,n_pos,0);
Es decir reorganice el cursor del archivo (desde el principio) a la posición indicada por
n_pos por la función
fseek () . Bien, hacemos todas estas operaciones en el ciclo 5 veces. La función
_construct_key () termina con el siguiente código:
int i_lastmarker = 0;
Por lo tanto, el último bloque de datos en el archivo debe ser un valor entero de 4 bytes y debe ser igual al valor en
key_array [0] [1340] . En este caso, recibiremos un mensaje de felicitación en la consola. De lo contrario, la matriz vacía aún regresa sin ningún elogio :)
Paso 6 - Descripción general de la función __prepare_key ()
Solo nos queda una función sin ensamblar:
__prepare_key () . Ya hemos adivinado que es allí donde se generan los datos de verificación en forma de la matriz
key_array , que luego se utiliza en la función
_construct_key () para verificar los datos del archivo. ¡Queda por descubrir qué tipo de datos hay!
No analizaré esta función en detalle e inmediatamente daré una lista completa con comentarios después de todo el cambio de nombre necesario de las variables:
__Prepare_key () listado de funciones void ** __prepare_key(void) { void **key_array; void *pvVar1; key_array = (void **)calloc2(1,8); if (key_array == (void **)0x0) { key_array = (void **)0x0; } else { pvVar1 = calloc2(1,0x540); *key_array = pvVar1; pvVar1 = calloc2(1,8); key_array[1] = pvVar1; *(undefined4 *)key_array[1] = 0x404024; *(undefined2 *)((int)key_array[1] + 4) = 5; *(undefined2 *)((int)key_array[1] + 6) = 4; *(undefined *)*key_array = 0x62; *(undefined4 *)((int)*key_array + 0x104) = 3; *(undefined *)((int)*key_array + 0x218) = 0x57; *(undefined *)((int)*key_array + 0x324) = 0x70; *(undefined *)((int)*key_array + 0x10c) = 0x6c; *(undefined *)((int)*key_array + 0x430) = 0x98; *(undefined4 *)((int)*key_array + 0x53c) = 0x462; } return key_array; }
El único lugar que vale la pena considerar es esta línea:
*(undefined4 *)key_array[1] = 0x404024;
¿Cómo entiendo que aquí se encuentra la línea "ANULAR"? El hecho es que 0x404024 es la dirección en el espacio de direcciones del programa que conduce a la sección
.rdata . Hacer doble clic en este valor nos permite ver claramente qué hay allí:

Por cierto, lo mismo se puede entender del código del ensamblador para esta línea:
004015da c7 00 24 MOV dword ptr [EAX], .rdata = 56h V
40 40 00
Los datos correspondientes a la línea VOID se encuentran al comienzo de la sección
.rdata (con un desplazamiento cero de la dirección correspondiente).
Entonces, a la salida de esta función, se debe formar una matriz bidimensional con los siguientes datos:
[0] [0]:'b' [268]:'l' [536]:'W' [804]:'p' [1072]:152 [1340]:1122
[1] [0-3]:"VOID" [4-5]:5 [6-7]:4
Paso 7 - Prepara el binario para el crack
Ahora podemos comenzar la síntesis del archivo binario. Todos los datos iniciales en nuestras manos:
1) datos de verificación ("símbolos de parada") y sus posiciones en la matriz de verificación;
2) la secuencia de datos en el archivo
Vamos a restaurar la estructura del archivo deseado de acuerdo con el algoritmo de la función
_construct_key () . Entonces, la secuencia de datos en el archivo será la siguiente:
Estructura de archivo- 4 bytes == key_array [1] [0 ... 3] == "ANULADO"
- 2 bytes == key_array [1] [4] == 5
- 2 bytes == key_array [1] [6] == 4
- 1 byte == key_array [0] [0] == 'b' (token)
- 1 byte == (longitud de la línea siguiente) == n_strlen1
- n_strlen1 bytes == (cualquier cadena) == n_strlen1
- 1 byte == (+7 == siguiente token) == n_pos
- 1 byte == key_array [0] [0] == 'l' (token)
- 1 byte == (longitud de la línea siguiente) == n_strlen1
- n_strlen1 bytes == (cualquier cadena) == n_strlen1
- 1 byte == (+7 == siguiente token) == n_pos
- 1 byte == key_array [0] [0] == 'W' (token)
- 1 byte == (longitud de la línea siguiente) == n_strlen1
- n_strlen1 bytes == (cualquier cadena) == n_strlen1
- 1 byte == (+7 == siguiente token) == n_pos
- 1 byte == key_array [0] [0] == 'p' (token)
- 1 byte == (longitud de la línea siguiente) == n_strlen1
- n_strlen1 bytes == (cualquier cadena) == n_strlen1
- 1 byte == (+7 == siguiente token) == n_pos
- 1 byte == key_array [0] [0] == 152 (token)
- 1 byte == (longitud de la línea siguiente) == n_strlen1
- n_strlen1 bytes == (cualquier cadena) == n_strlen1
- 1 byte == (+7 == siguiente token) == n_pos
- 4 bytes == (key_array [1340]) == 1122
Para mayor claridad, hice en Excel una tableta con los datos del archivo deseado:

Aquí en la séptima línea, los datos en forma de caracteres y números, en la sexta línea, sus representaciones hexadecimales, en la octava línea, el tamaño de cada elemento (en bytes), en la novena línea, el desplazamiento relativo al comienzo del archivo. Esta vista es muy conveniente porque le permite ingresar cualquier línea en el archivo futuro (marcado con un relleno amarillo), mientras que los valores de las longitudes de estas líneas, así como los desplazamientos de posición del siguiente símbolo de parada, se calculan mediante fórmulas automáticamente, según lo requiera el algoritmo del programa. Arriba (en las líneas 1-4), se
muestra la estructura de la
matriz de verificación
key_array .
El Excel en sí y otros materiales de origen para el artículo se pueden descargar
aquí .
Generación y validación de archivos binarios.
Lo único que queda es generar el archivo deseado en formato binario y alimentarlo con nuestro crack. Para generar el archivo, escribí un script simple de Python:
Script para generar el archivo import sys, os import struct import subprocess out_str = ['!', 'I', ' solved', ' this', ' crackme!'] def write_file(file_path): try: with open(file_path, 'wb') as outfile: outfile.write('VOID'.encode('ascii')) outfile.write(struct.pack('2h', 5, 4)) outfile.write('b'.encode('ascii')) outfile.write(struct.pack('B', len(out_str[0]))) outfile.write(out_str[0].encode('ascii')) pos = 10 + len(out_str[0]) outfile.write(struct.pack('B', pos - 6)) outfile.write('l'.encode('ascii')) outfile.write(struct.pack('B', len(out_str[1]))) outfile.write(out_str[1].encode('ascii')) pos += 3 + len(out_str[1]) outfile.write(struct.pack('B', pos - 6)) outfile.write('W'.encode('ascii')) outfile.write(struct.pack('B', len(out_str[2]))) outfile.write(out_str[2].encode('ascii')) pos += 3 + len(out_str[2]) outfile.write(struct.pack('B', pos - 6)) outfile.write('p'.encode('ascii')) outfile.write(struct.pack('B', len(out_str[3]))) outfile.write(out_str[3].encode('ascii')) pos += 3 + len(out_str[3]) outfile.write(struct.pack('B', pos - 6)) outfile.write(struct.pack('B', 152)) outfile.write(struct.pack('B', len(out_str[4]))) outfile.write(out_str[4].encode('ascii')) pos += 3 + len(out_str[4]) outfile.write(struct.pack('B', pos - 6)) outfile.write(struct.pack('i', 1122)) except Exception as err: print(err) raise def main(): if len(sys.argv) != 2: print('USAGE: {this_script.py} path_to_crackme[.exe]') return if not os.path.isfile(sys.argv[1]): print('File "{}" unavailable!'.format(sys.argv[1])) return file_path = os.path.splitext(sys.argv[1])[0] + '.dat' try: write_file(file_path) except: return try: outputstr = subprocess.check_output('"{}" -f "{}"'.format(sys.argv[1], file_path), stderr=subprocess.STDOUT) print(outputstr.decode('utf-8')) except Exception as err: print(err) if __name__ == '__main__': main()
El script toma la ruta a las grietas como un parámetro único, luego genera un archivo binario con la clave en el mismo directorio y llama a las grietas con el parámetro correspondiente, traduciendo la salida del programa a la consola.
Para convertir datos de texto a binario, use el paquete de
estructura . El método
pack () le permite escribir datos binarios en un formato en el que se indica el tipo de datos ("B" = "byte", "i" = int, etc.), y también puede especificar la secuencia (">" = "Big -endian "," <"=" Little-endian "). El orden predeterminado es Little-endian. Porque Ya determinamos en el primer artículo que este es exactamente nuestro caso, luego indicamos solo el tipo.
Todo el código en su conjunto reproduce el algoritmo de programa que encontramos. Como la línea a imprimir si tiene éxito, especifiqué "¡Resolví este crackme!" (puede modificar este script para que sea posible especificar cualquier línea).
Verifique la salida:

¡Hurra, todo funciona! Entonces, después de sudar un poco y haber resuelto un par de funciones, pudimos restaurar completamente el algoritmo del programa y "descifrarlo". Por supuesto, esto es solo un simple crack, un programa de prueba e incluso el del segundo nivel de dificultad (de los 5 ofrecidos en ese sitio). En realidad, trataremos con una compleja jerarquía de llamadas y docenas, cientos de funciones y, en algunos casos, secciones cifradas de datos, código basura y otras técnicas de ofuscación, hasta el uso de máquinas virtuales internas y código P ... Pero esto, como dicen, ya es Una historia completamente diferente.
Materiales para el artículo.