Continuando con la consideración de las tecnologías para acelerar las operaciones de E / S aplicadas a los sistemas de almacenamiento, que comenzó en el artículo anterior , uno no puede evitar detenerse en una opción tan popular como la nivelación automática. Aunque la ideología de esta función es muy similar a la de varios fabricantes de sistemas de almacenamiento, consideraremos las características de la implementación de desgarro utilizando el ejemplo del almacenamiento Qsan .
A pesar de la variedad de datos almacenados en el sistema de almacenamiento, estos mismos datos pueden dividirse en varios grupos según su relevancia (frecuencia de uso). Los datos más populares ("calientes") son extremadamente importantes para organizar el acceso más rápido, mientras que el procesamiento de datos menos populares ("fríos") se puede realizar con una prioridad más baja.
Para organizar dicho esquema, se utiliza el rasgado funcional. La matriz de datos en este caso no consiste en el mismo tipo de discos, sino en varios grupos de unidades que forman diferentes niveles de almacenamiento. Mediante un algoritmo especial, los datos se mueven automáticamente entre niveles para garantizar el máximo rendimiento final.
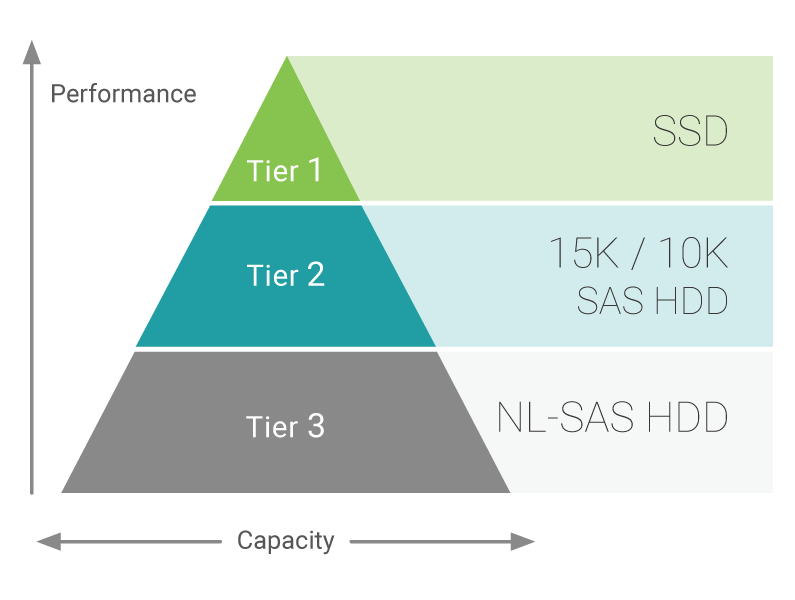
Los sistemas de almacenamiento Qsan admiten hasta tres niveles de almacenamiento:
- Nivel 1: SSD Máximo rendimiento
- Nivel 2: HDD SAS 10K / 15K, alto rendimiento
- Nivel 3: HDD NL-SAS 7.2K, capacidad máxima
El grupo de niveles automáticos puede contener los tres niveles y solo dos en cualquier combinación. Dentro de cada nivel, las unidades se combinan en grupos RAID familiares. Para una máxima flexibilidad, el nivel RAID en cada nivel puede ser diferente. Es decir, por ejemplo, nada le impide organizar una estructura como 4x SSD RAID10 + 6x HDD 10K RAID5 + 12 HDD 7.2K RAID6
Después de crear volúmenes (discos virtuales) en el grupo de Auto Tiering , comienza la recopilación de estadísticas en segundo plano sobre todas las operaciones de E / S. Para hacer esto, el espacio se "corta" en bloques de 1GB (el llamado sub LUN). Cada vez que accede a dicho bloque, se le asigna un coeficiente 1. Luego, con el tiempo, este coeficiente disminuye. Después de 24 horas, en ausencia de solicitudes de entrada / salida para esta unidad, ya será igual a 0.5 y continuará cayendo después de cada hora subsiguiente.
En un momento determinado (de forma predeterminada todos los días a la medianoche), los resultados recopilados se clasifican por actividad sub LUN en función de sus coeficientes. En base a esto, se toma una decisión sobre qué bloques mover y en qué dirección. Después de lo cual, de hecho, hay una reubicación de datos entre los niveles.
El sistema de almacenamiento Qsan implementa perfectamente el control del proceso de rasgado utilizando una variedad de parámetros, lo que le permitirá configurar de manera muy flexible el rendimiento final de la matriz.
Para determinar la ubicación inicial de los datos y la dirección de prioridad de su movimiento, se utilizan políticas que se establecen por separado para cada volumen:
- Nivelación automática : la política predeterminada, la ubicación inicial y la dirección de los movimientos se determina automáticamente, es decir Los datos "calientes" tienden al nivel más alto, y los datos "fríos" bajan. La ubicación inicial se selecciona en función del espacio disponible en cada nivel. Pero debe comprender que el sistema busca principalmente maximizar el uso de las unidades más rápidas. Por lo tanto, si hay espacio libre, los datos se colocarán en los niveles superiores. Esta política es adecuada para la mayoría de los escenarios cuando la demanda de datos no se puede predecir de antemano.
- Comience alto y, luego, nivelación automática : la diferencia con respecto al anterior solo está en la ubicación de datos original (en el nivel más rápido)
- El nivel más alto : los datos siempre se esfuerzan por ocupar el nivel más rápido. Si en el proceso se mueven hacia abajo, lo antes posible se mueven hacia atrás. Esta política es adecuada para datos que requieren el acceso más rápido.
- Nivel mínimo : los datos siempre se esfuerzan por ocupar el nivel más bajo. Esta política es perfecta para datos raramente utilizados (por ejemplo, archivos).
- Sin movimiento : el sistema determina automáticamente la ubicación inicial de los datos y no los mueve. Sin embargo, se siguen recopilando estadísticas en caso de que posteriormente se requiera su reubicación.
Vale la pena señalar que, a pesar del hecho de que las políticas se definen al crear cada volumen, se pueden cambiar repetidamente sobre la marcha durante el ciclo de vida del sistema.
Además de las políticas para el mecanismo de desgarro, también se configura la frecuencia y el ritmo del movimiento de datos entre niveles. Puede establecer un tiempo específico de movimiento: diariamente o en ciertos días de la semana, así como reducir el intervalo de recopilación de estadísticas a varias horas (la frecuencia mínima es de 2 horas). Si es necesario limitar el tiempo de ejecución de la operación de movimiento de datos, puede establecer el marco de tiempo (ventana para mover). Además, también se indica la velocidad de reubicación: 3 modos: rápido, medio, lento.
En caso de una necesidad de reubicación de datos inmediata, es posible ejecutarla en modo manual en cualquier momento por orden del administrador.
Está claro que cuanto más a menudo y más rápido se muevan los datos entre niveles, más flexible será el sistema de almacenamiento para adaptarse a las condiciones de operación actuales. Pero al mismo tiempo, vale la pena recordar que mover es una carga adicional (principalmente en discos), por lo que no es necesario "manejar" los datos sin una necesidad extrema. Es mejor planificar el movimiento para momentos de carga mínima. Si el trabajo de almacenamiento requiere constantemente un alto rendimiento las 24 horas, los 7 días de la semana, entonces vale la pena reducir al mínimo la tasa de reubicación.
La abundancia de configuraciones de rasgado indudablemente complacerá a los usuarios avanzados. Sin embargo, para aquellos que se enfrentan a dicha tecnología por primera vez, no hay nada de qué preocuparse. Es muy posible confiar en la configuración predeterminada (política de nivelación automática, moverse a la velocidad máxima una vez al día por la noche) y, a medida que se acumulan las estadísticas, ajustar ciertos parámetros para lograr el resultado deseado.
Al comparar el emparejamiento con una tecnología no menos popular para aumentar la productividad como el almacenamiento en caché de SSD , uno debe tener en cuenta los diferentes principios de sus algoritmos.
| Almacenamiento en caché SSD | Nivelación automática |
|---|
| Tasa de inicio del efecto | Casi al instante. Pero un efecto notable solo después de que el caché se "calienta" (minutos-horas) | Después de recopilar estadísticas (a partir de 2 horas, idealmente un día), más el tiempo para mover los datos |
| Duración del efecto | Hasta que los datos sean reemplazados por una nueva porción (minutos-horas) | Si bien la demanda de datos es relevante (día o más) |
| Indicaciones de uso | Aumente instantáneamente la productividad por un corto tiempo (bases de datos, entornos de virtualización) | Aumento de la productividad durante un largo período (archivos, web, servidores de correo) |
También una de las características del rasgado es la capacidad de usarlo no solo para escenarios como "SSD + HDD", sino también "HDD rápido + HDD lento" o los tres niveles en general, lo que es imposible en principio cuando se usa el almacenamiento en caché SSD.
Prueba
Para probar el funcionamiento de los algoritmos de desgarro, realizamos una prueba simple. Se creó un grupo de dos niveles de SSD (RAID 1) + HDD 7.2K (RAID1), en el que se colocó el volumen con la política de "nivel mínimo". Es decir los datos siempre deben ubicarse en discos lentos.
La interfaz de control muestra claramente la ubicación de los datos entre niveles.
Después de llenar el volumen con datos, cambiamos la política de ubicación a Nivelación automática y ejecutamos la prueba IOmeter.
Después de varias horas de pruebas, cuando el sistema pudo acumular estadísticas, comenzó el proceso de reubicación.
Al final del movimiento de datos, nuestro volumen de prueba se arrastró completamente al nivel superior (SSD).
El veredicto
La nivelación automática es una tecnología maravillosa que le permite aumentar la productividad del sistema de almacenamiento con el mínimo de costos de material y tiempo debido al uso más intensivo de unidades de alta velocidad. En relación con Qsan, la única inversión es una licencia, que se adquiere de una vez por todas sin limitación en el volumen / número de discos / estantes / etc. Esta funcionalidad está equipada con una configuración tan rica que puede satisfacer casi cualquier tarea empresarial. Y la visualización de los procesos en la interfaz le permitirá administrar de manera efectiva el dispositivo.