
El 28 de febrero, hice una presentación en el encuentro SphinxSearch , que se realizó en nuestra oficina. Habló sobre cómo procedimos de la reconstrucción regular de índices para la búsqueda de texto completo y el envío de actualizaciones en el código "en su lugar" a los índices de tiempo ferroviario y la sincronización automática del estado del índice y la base de datos MariaDB. Una grabación de video de mi informe está disponible a través del enlace , y para aquellos que prefieren leer a ver el video, escribí este artículo.
Comenzaré con cómo se organizó nuestra búsqueda y por qué comenzamos todo esto.
Nuestra búsqueda se organizó de acuerdo con un esquema completamente estándar.
Desde el principio, las solicitudes de los usuarios llegan al servidor de aplicaciones escrito en PHP, y él, a su vez, se comunica con la base de datos (tenemos MariaDB). Si necesitamos hacer una búsqueda, el servidor de aplicaciones recurre al equilibrador (tenemos haproxy), que lo conecta a uno de los servidores donde se está ejecutando la búsqueda, y ese servidor ya realiza una búsqueda y devuelve el resultado.
Los datos de la base de datos caen en el índice de una manera bastante tradicional: de acuerdo con el cronograma, reconstruimos el índice cada pocos minutos con aquellos documentos que se actualizaron relativamente recientemente, y reconstruimos el índice con los llamados documentos "archivados" (es decir, aquellos con los que Durante mucho tiempo no pasó nada). Hay un par de máquinas asignadas para la indexación, se ejecuta un script allí en una programación, que primero construye el índice, luego cambia el nombre de los archivos de índice de una manera especial y luego lo coloca en una carpeta separada. Y en cada uno de los servidores con búsqueda, rsync se inicia una vez por minuto, lo que copia archivos de esta carpeta a la carpeta de índices buscados y luego, si se ha copiado algo, ejecuta una solicitud RELOAD INDEX.
Sin embargo, para algunos cambios en currículums vitae y vacantes se requería que "alcanzaran" el índice lo antes posible. Por ejemplo, si una vacante publicada en el dominio público se elimina de la publicación, entonces es razonable esperar desde el punto de vista del usuario que desaparecerá del problema en unos segundos, no más. Por lo tanto, este tipo de cambios se envían directamente a través de búsquedas mediante consultas ACTUALIZAR. Y para que estos cambios se apliquen a todas las copias de índices en todos nuestros servidores, se configura un índice distribuido en cada búsqueda, que envía actualizaciones de atributos a todas las instancias buscadas. El servidor de aplicaciones aún se conecta al equilibrador y envía una solicitud para actualizar el índice distribuido; por lo tanto, no necesita saber de antemano ni la lista de servidores con búsqueda, ni llegará a qué servidor con búsqueda exactamente.
Todo esto funcionó bastante bien, pero hubo problemas.
- El retraso promedio entre la creación del documento (tenemos este currículum o vacante) y su entrada en el índice fue directamente proporcional a su número en nuestra base de datos.
- Como utilizamos el índice distribuido para distribuir actualizaciones de atributos, no teníamos garantía de que estas actualizaciones se aplicaran a todas las copias del índice.
- Los cambios "urgentes" que ocurrieron durante la reconstrucción del índice se perdieron cuando se ejecutó el comando
RELOAD INDEX (simplemente porque todavía no estaban en el índice recién construido), y solo entraron en el índice después de la próxima reindexación. 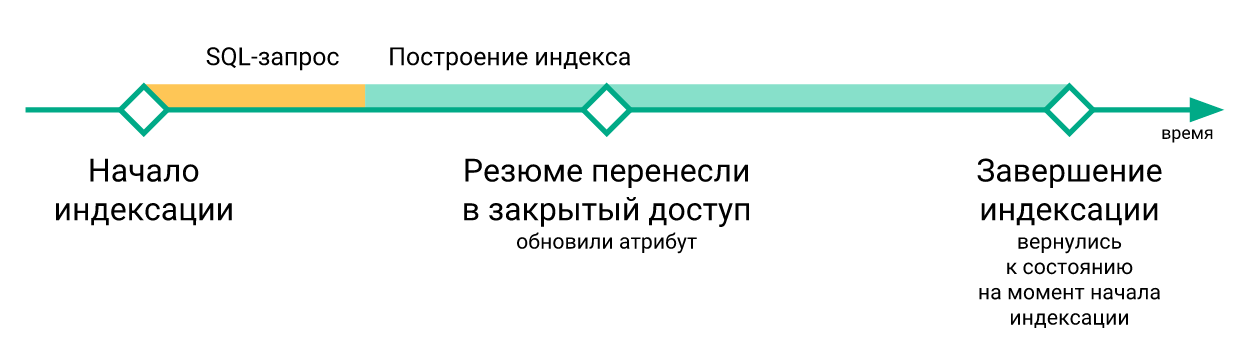
- Los scripts para actualizar índices en servidores con búsquedas se ejecutaron independientemente uno del otro, no hubo sincronización entre ellos. Debido a esto, el retraso entre la actualización del índice en diferentes servidores podría llegar a varios minutos.
- Si era necesario probar algo relacionado con la búsqueda, era necesario reconstruir el índice después de cada cambio.
Cada uno de estos problemas por separado no valía una reelaboración cardinal de la infraestructura de búsqueda, pero en conjunto arruinaron la vida de manera tangible.
Decidimos lidiar con los problemas anteriores utilizando los índices en tiempo real de Sphinx. Además, la transición a los índices RT no fue suficiente para nosotros. Para finalmente deshacerse de cualquier carrera de datos, era necesario asegurarse de que todas las actualizaciones de la aplicación al índice pasaran por el mismo canal. Además, era necesario guardar en algún lugar los cambios realizados en la base de datos mientras se reconstruía el índice (porque después de todo, a veces hay que reconstruirlo, pero el procedimiento no es instantáneo).
Decidimos hacer la conexión utilizando el protocolo de replicación MySQL, como un canal de transferencia de datos, y el binlog de MySQL es el lugar para guardar los cambios mientras se reconstruye el índice. Esta solución nos permitió deshacernos de escribir en Sphinx desde el código de la aplicación. Y dado que ya habíamos usado la replicación basada en filas con una identificación de transacción global para ese momento, el cambio entre las réplicas de la base de datos podría hacerse de manera bastante simple.
La idea de conectarse directamente a la base de datos para obtener cambios desde allí para enviarlos al índice, por supuesto, no es nueva: en 2016, los colegas de Avito hicieron una presentación donde describieron en detalle cómo resolvieron el problema de sincronizar datos en Sphinx con la base de datos principal. Decidimos usar su experiencia y crear un sistema similar para nosotros, con la diferencia de que no tenemos PostgreSQL, sino MariaDB y la antigua rama Sphinx (es decir, la versión 2.3.2).
Hicimos un servicio que se suscribe a los cambios en MariaDB y actualiza el índice en Sphinx. Sus responsabilidades son las siguientes:
- conexión al servidor MariaDB a través del protocolo de replicación y recepción de eventos desde el binlog;
- rastrear la posición actual de binlog y el número de la última transacción completada;
- filtrado de eventos binlog;
- averiguar qué documentos deben agregarse, eliminarse o actualizarse en el índice, y para documentos actualizados, qué campos deben actualizarse;
- solicitud de datos faltantes de MariaDB;
- generación y ejecución de solicitudes de actualización de índice;
- reconstruir el índice si es necesario.
Hicimos una conexión usando el protocolo de replicación usando la biblioteca go-mysql . Ella es responsable de establecer una conexión con MariaDB, leer los eventos de replicación y pasarlos a un controlador. Este controlador comienza en goroutine, que es controlado por la biblioteca, pero nosotros mismos escribimos el código del controlador. En el código del controlador, los eventos se verifican con una lista de tablas que nos interesan y los cambios en estas tablas se envían para su procesamiento. Nuestro controlador también almacena el estado de la transacción. Esto se debe al hecho de que los eventos en el protocolo de replicación están en orden: GTID (inicio de la transacción) -> ROW (cambio de datos) -> XID (final de la transacción), y solo el primero de ellos contiene información sobre el número de transacción. Es más conveniente para nosotros transferir el número de transacción junto con su finalización para guardar información sobre a qué posición en el binlog se han aplicado los cambios, y para esto necesitamos recordar el número de la transacción actual entre su inicio y finalización.
MySQL [(none)]> describe sync_state; +-----------------+--------+ | Field | Type | +-----------------+--------+ | id | bigint | | dummy_field | field | | binlog_position | uint | | binlog_name | string | | gtid | string | | flavor | string | +-----------------+--------+
Guardamos el número de la última transacción completada en un índice especial de un documento en cada servidor con búsqueda. Al inicio del servicio, verificamos que los índices se inicializan y tienen la estructura esperada, así como que la posición guardada en todos los servidores está presente y es la misma en todos los servidores. Luego, si estas comprobaciones fueron exitosas y pudimos comenzar a leer el binlog desde la posición guardada, comenzamos el procedimiento de sincronización. Si las comprobaciones fallan, o no fue posible comenzar a leer el binlog desde la posición guardada, restablecemos la posición guardada a la posición actual del servidor MariaDB y reconstruimos el índice.
El procesamiento de eventos de replicación comienza determinando qué documentos se ven afectados por un cambio particular en la base de datos. Para hacer esto, en la configuración de nuestro servicio, hicimos algo como enrutar los eventos de cambio de fila en las tablas que nos interesan, es decir, un conjunto de reglas para determinar cómo deberían indexarse los cambios en la base de datos.
[[ingest]] table = "vacancy" id_field = "id" index = "vacancy" [ingest.column_map] user_id = ["user_id"] edited_at = ["date_edited"] profession = ["profession"] latitude = ["latitude_deg", "latitude_rad"] longitude = ["longitude_deg", "longitude_rad"] [[ingest]] table = "vacancy_language" id_field = "vacancy_id" index = "vacancy" [ingest.column_map] language_id = ["languages"] level = ["languages"] [[ingest]] table = "vacancy_metro_station" id_field = "vacancy_id" index = "vacancy" [ingest.column_map] metro_station_id = ["metro"]
Por ejemplo, con este conjunto de reglas, los cambios en las vacancy_metro_station vacancy , vacancy_language y vacancy_metro_station deben estar en el índice de vacancy . El número de documento puede tomarse en el campo id para la tabla de vacancy y en el campo vacancy_id para las otras dos tablas. El campo column_map es una tabla de la dependencia de los campos de índice en los campos de diferentes tablas de bases de datos.
Además, cuando recibimos la lista de documentos afectados por los cambios, necesitamos actualizarlos en el índice, pero no lo hacemos de inmediato. Primero, acumulamos cambios para cada documento y enviamos los cambios al índice tan pronto como pase un breve período de tiempo (tenemos 100 milisegundos) desde el último cambio de este documento.
Decidimos hacer esto para evitar muchas actualizaciones de índice innecesarias, porque en muchos casos se produce un solo cambio lógico en un documento con la ayuda de varias consultas SQL que afectan a diferentes tablas y, a veces, se ejecutan en transacciones completamente diferentes.
Daré un ejemplo simple. Supongamos que un usuario ha editado una vacante. El código responsable de guardar los cambios a menudo se escribe por simplicidad aproximadamente de esta manera:
BEGIN; UPDATE vacancy SET edited_at = NOW() WHERE id = 123; DELETE FROM vacancy_language WHERE vacancy_id = 123; INSERT INTO vacancy_language (vacancy_id, language_id, level) VALUES (123, 1, "fluent"), (123, 2, "technical"); DELETE FROM vacancy_metro_station WHERE vacancy_id = 123; INSERT INTO vacancy_metro_station (vacancy_id, metro_station_id) VALUES (123, 55); ... COMMIT;
En otras palabras, primero todos los registros antiguos se eliminan de las tablas vinculadas y luego se insertan los nuevos. Al mismo tiempo, seguirá habiendo entradas en el binlog sobre estas eliminaciones e inserciones, incluso si nada ha cambiado en el documento.
Para actualizar solo lo que se necesita, hicimos lo siguiente: clasificamos las líneas cambiadas para que para cada par índice-documento todos los cambios puedan recuperarse en orden cronológico. Luego, podemos aplicarlos a su vez para determinar qué campos en qué tablas han cambiado finalmente y cuáles no, y luego usar la tabla column_map obtener una lista de campos y atributos de índice que deben actualizarse para cada documento afectado. Además, los eventos relacionados con un documento pueden no llegar uno tras otro, sino como "de manera diferente" si se ejecutan en diferentes transacciones. Pero, en nuestra capacidad de determinar qué documentos han cambiado, esto no afectará.
Al mismo tiempo, este enfoque nos permitió actualizar solo los atributos del índice, si no hubo cambios en los campos de texto, así como combinar el envío de cambios a Sphinx.
Entonces, ahora podemos averiguar qué documentos deben actualizarse en el índice.
En muchos casos, los datos del binlog no son suficientes para generar una solicitud para actualizar el índice, por lo que obtenemos los datos faltantes del mismo servidor desde donde leemos el binlog. Para esto, hay una plantilla de solicitud para recibir datos en la configuración de nuestro servicio.
[data_source.vacancy] # # - id parts = 4 query = """ SELECT vacancy.id AS `:id`, vacancy.profession AS `profession_text:field`, GROUP_CONCAT(DISTINCT vacancy_language.language_id) AS `languages:attr_multi`, GROUP_CONCAT(DISTINCT vacancy_metro_station.metro_station_id) AS `metro:attr_multi` FROM vacancy LEFT JOIN vacancy_language ON vacancy_language.vacancy_id = vacancy.id LEFT JOIN vacancy_metro_station ON vacancy_metro_station.vacancy_id = vacancy.id GROUP BY vacancy.id """
En esta plantilla, todos los campos están marcados con alias especiales: [___]:___ .
Se usa tanto en la formación de una solicitud para recibir los datos faltantes como en la construcción del índice (más sobre esto más adelante).
Formamos una solicitud de este tipo:
SELECT vacancy.id AS `id`, vacancy.profession AS `profession_text`, GROUP_CONCAT(DISTINCT vacancy_language.language_id) AS `languages`, GROUP_CONCAT(DISTINCT vacancy_metro_station.metro_station_id) AS `metro` FROM vacancy LEFT JOIN vacancy_language ON vacancy_language.vacancy_id = vacancy.id LEFT JOIN vacancy_metro_station ON vacancy_metro_station.vacancy_id = vacancy.id WHERE vacancy.id IN (< id , >) GROUP BY vacancy.id
Luego, para cada documento, verificamos si es el resultado de esta solicitud. Si no, significa que se eliminó de la tabla principal, por lo que también se puede eliminar del índice (ejecutamos la consulta DELETE para este documento). Si es así, vea si necesitamos actualizar los campos de texto para este documento. Si los campos de texto no necesitan actualizarse, entonces hacemos una consulta de UPDATE para este documento, de lo contrario, REPLACE .
Vale la pena señalar aquí que la lógica de mantener la posición desde la cual puede comenzar a leer el binlog en caso de fallas tenía que ser complicada, porque ahora es posible una situación en la que no aplicamos todos los cambios leídos del binlog.
Para que la reanudación de la lectura del binlog funcione correctamente, hicimos lo siguiente: para cada evento de cambio de fila en la base de datos, recuerde la identificación de la última transacción completada en el momento en que ocurrió este evento. Después de enviar los cambios a Sphinx, actualizamos el número de transacción desde el que puede comenzar a leer de forma segura, de la siguiente manera. Si no procesamos todos los cambios acumulados (porque algunos documentos no fueron "rastreados" en la cola), tomamos el número de la transacción más temprana de aquellos relacionados con los cambios que aún no hemos podido aplicar. Y si sucedió que aplicamos todos los cambios acumulados, simplemente tomamos el número de la última transacción completada.
Lo que sucedió como resultado estuvo bien para nosotros, pero había un punto más importante: para que el rendimiento del índice en tiempo real se mantuviera en un nivel aceptable a lo largo del tiempo, era necesario que el tamaño y el número de "fragmentos" de este índice siguieran siendo pequeños. Para hacer esto, Sphinx tiene una solicitud FLUSH RAMCHUNK , que FLUSH RAMCHUNK un nuevo fragmento de disco, y una solicitud OPTIMIZE INDEX , que combina todos los fragmentos de disco en uno. Inicialmente, pensamos que lo realizaríamos periódicamente y eso es todo. Pero, desafortunadamente, resultó que en la versión 2.3.2 OPTIMIZE INDEX no funciona (es decir, con una probabilidad bastante alta conduce a una caída en la búsqueda). Por lo tanto, decidimos simplemente reconstruir completamente el índice una vez al día, especialmente porque de vez en cuando todavía tenemos que hacerlo (por ejemplo, si el esquema del índice o la configuración del tokenizer cambian).
El procedimiento para reconstruir el índice tiene lugar en varias etapas.
Generamos una configuración para indexador
Como se mencionó anteriormente, hay una plantilla de consulta SQL en la configuración del servicio. También se usa para formar la configuración del indexador.
También en la configuración hay otras configuraciones necesarias para construir el índice (configuraciones de tokenizer, diccionarios, varias restricciones en el consumo de recursos).
Guardar la posición actual de MariaDB
Desde esta posición, comenzaremos a leer el binlog, después de que el nuevo índice esté disponible en todos los servidores con búsqueda.
Empezamos indexador
indexer --config tmp.vacancy.indexer.0.conf --all comandos del indexer --config tmp.vacancy.indexer.0.conf --all y esperamos su finalización. Además, si el índice se divide en partes, entonces comenzamos la construcción de todas las partes en paralelo.
Cargamos archivos de índice en servidores
La descarga a cada servidor también ocurre en paralelo, pero naturalmente esperamos hasta que todos los archivos se carguen en todos los servidores. Para descargar archivos en la configuración del servicio, hay una sección con una plantilla de comando para descargar archivos.
[index_uploader] executable = "rsync" arguments = [ "--files-from=-", "--log-file=<<.DataDir>>/rsync.<<.Host>>.log", "--no-relative", "--times", "--delay-updates", ".", "rsync://<<.Host>>/index/vacancy/", ]
Para cada servidor, simplemente sustituimos su nombre en la variable Host y ejecutamos el comando resultante. Usamos rsync para la descarga, pero en principio cualquier programa o script que acepte una lista de archivos en stdin y descargue estos archivos a la carpeta donde searchd espera ver los archivos de índice.
Paramos la sincronización
Dejamos de leer el binlog, detuvimos a los gorutinos responsables de la acumulación de cambios.
Reemplace el índice antiguo por uno nuevo
Para cada servidor con búsqueda, realizamos consultas secuenciales RELOAD INDEX vacancy_plain , TRUNCATE INDEX vacancy_plain , ATTACH INDEX vacancy_plain TO vacancy . Si el índice se divide en partes, entonces ejecutamos estas consultas para cada parte secuencialmente. Al mismo tiempo, si estamos en un entorno de producción, antes de ejecutar estas consultas en cualquier servidor, eliminamos la carga a través del equilibrador (para que nadie haga consultas SELECT a los índices entre TRUNCATE y ATTACH ), y tan pronto una vez completada la última solicitud ATTACH , devolvemos la carga a este servidor.
Reanudando la sincronización desde una posición guardada
Tan pronto como reemplazamos todos los índices en tiempo real con los nuevos, reanudamos la lectura del binlog y sincronizamos los eventos del binlog, comenzando desde la posición que guardamos antes de que comenzara la indexación.
Aquí hay un ejemplo de un gráfico del retraso del índice del servidor MariaDB.

Aquí puede ver que, aunque el estado del índice después de la reconstrucción vuelve a tiempo, esto sucede muy brevemente.
Ahora que todo está más o menos listo, es hora de su lanzamiento. Lo hicimos gradualmente. Primero, vertimos un índice en tiempo real en un par de servidores, y el resto en ese momento funcionó de la misma manera. Al mismo tiempo, la estructura de los índices en los servidores "nuevos" no difería de los antiguos, por lo que nuestra aplicación PHP aún podía conectarse al equilibrador sin preocuparse de si la solicitud se procesaría en un índice en tiempo real o en un índice simple.
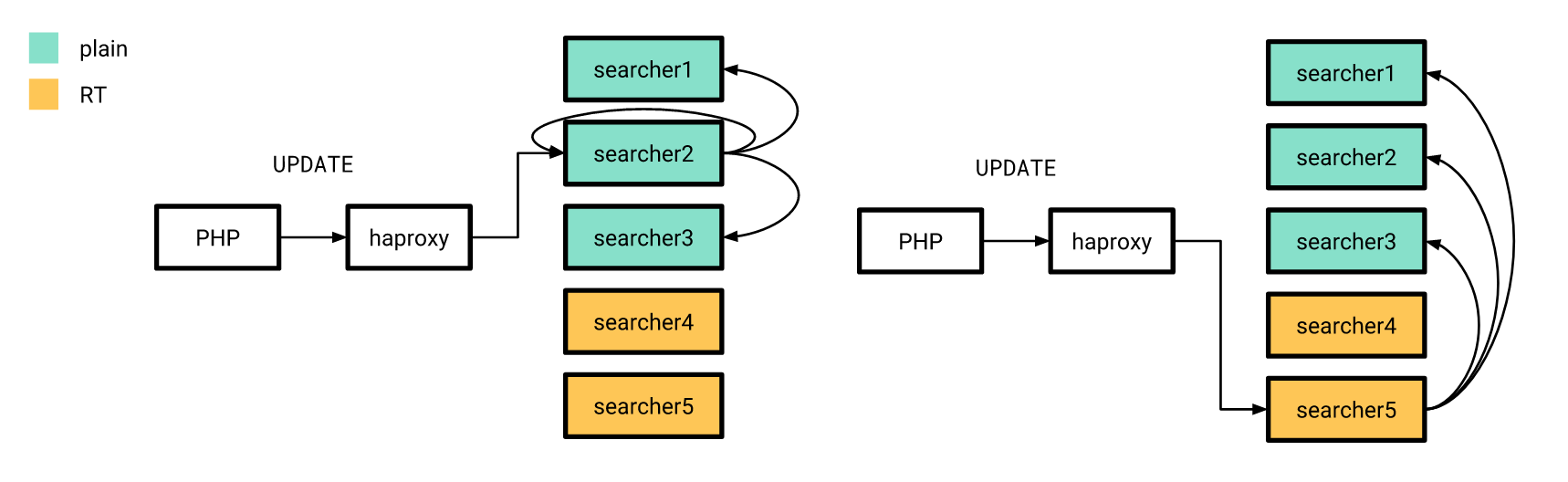
Las actualizaciones de atributos, de las que hablé antes, también se enviaron de acuerdo con el esquema anterior, con la diferencia de que el índice distribuido en todos los servidores estaba configurado para enviar consultas de ACTUALIZACIÓN solo a servidores con índices simples. Además, si la solicitud UPDATE de la aplicación llega al servidor con índices en tiempo real, entonces no ejecuta esta solicitud en el hogar, sino que la envía a los servidores configurados de la manera anterior.
Después de la publicación, como esperábamos, resultó reducir significativamente la demora entre cómo un currículum o una vacante cambia en la base de datos y cómo los cambios correspondientes entran en el índice.
Después de cambiar a un índice en tiempo real, no había necesidad de reconstruir el índice después de cada cambio en los servidores de prueba. Y así fue posible escribir autotests de extremo a extremo con la participación de búsqueda de manera relativamente económica. Sin embargo, dado que procesamos los cambios del binlog de forma asíncrona (desde el punto de vista de los clientes que escriben en la base de datos), tuvimos que hacer posible esperar hasta que nuestro servicio procesara los cambios relacionados con el documento que participaba en la prueba automática y los enviara a la búsqueda .
Para hacer esto, creamos un punto final en nuestro servicio, que hace exactamente eso, es decir, espera hasta que se apliquen todos los cambios al número de transacción especificado. Para hacer esto, inmediatamente después de realizar los cambios necesarios en la base de datos, solicitamos a MariaDB @@gtid_current_pos y la transferimos al punto final de nuestro servicio. Si ya hemos aplicado todas las transacciones a esta posición en este momento, el servicio responde de inmediato que podemos continuar. De lo contrario, en la rutina que es responsable de aplicar los cambios, creamos una suscripción a este GTID, y tan pronto como se aplique (o cualquiera que lo siga), también permitimos que el cliente continúe con la prueba automática.
En el código PHP, se ve así:
<?php declare(strict_types=1); use GuzzleHttp\ClientInterface; use GuzzleHttp\RequestOptions; use PDO; class RiverClient { private const REQUEST_METHOD = 'post'; /** * @var ClientInterface */ private $httpClient; public function __construct(ClientInterface $httpClient) { $this->httpClient = $httpClient; } public function waitForSync(PDO $mysqlConnection, PDO $sphinxConnection, string $riverAddr): void { $masterGTID = $mysqlConnection->query('SELECT @@gtid_current_pos')->fetchColumn(); $this->httpClient->request( self::REQUEST_METHOD, "http://{$riverAddr}/wait", [RequestOptions::FORM_PARAMS => ['gtid' => $masterGTID]] ); } }
Resultados
Como resultado, pudimos reducir significativamente el retraso entre la actualización de MariaDB y Sphinx.


También nos hemos vuelto mucho más seguros de que todas las actualizaciones lleguen a tiempo a todos nuestros servidores Sphinx.
Además, las pruebas de búsqueda (tanto manuales como automáticas) se han vuelto mucho más agradables.
Desafortunadamente, esto no se nos dio de forma gratuita: el rendimiento del índice en tiempo real en comparación con el índice simple resultó ser ligeramente peor.
La distribución del tiempo de procesamiento de las consultas de búsqueda según el tiempo para un índice simple se muestra a continuación.

Y aquí está el mismo gráfico para el índice en tiempo real.

Puede ver que el porcentaje de solicitudes "rápidas" ha disminuido ligeramente, mientras que el porcentaje de solicitudes "lentas" ha aumentado.
En lugar de una conclusión
Queda por decir que el código del servicio descrito en este artículo, lo publicamos en el dominio público . Desafortunadamente, todavía no hay documentación detallada, pero si lo desea, puede ejecutar un ejemplo de uso de este servicio a través de docker-compose .
Referencias
- Video y diapositivas de informes
- Informe en video de Andrey Smirnov y Vyacheslav Kryukov en Highload ++
- Biblioteca go-mysql
- Código de servicio con ejemplo de uso