Hoy, la mayoría de los productos de software se desarrollan en equipos. Las condiciones de éxito para el desarrollo del equipo se pueden presentar en forma de un esquema simple.
Después de escribir el código, debe asegurarse de que:
- Funciona
- No rompe nada, incluido el código que escribieron sus colegas.
Si se cumplen ambas condiciones, entonces estás en el camino hacia el éxito. Para verificar fácilmente estas condiciones y no desactivar una ruta rentable, se les ocurrió la integración continua.
CI es un flujo de trabajo en el que integra su código en el código general del producto con la mayor frecuencia posible. Y no solo integrar, sino también comprobar constantemente que todo funciona. Como necesita verificar mucho y con frecuencia, debe pensar en la automatización. Puede verificar todo en tracción manual, pero no vale la pena, y es por eso.
- La gente es cara . Una hora de trabajo de cualquier programador es más costosa que una hora de trabajo de cualquier servidor.
- La gente está equivocada . Por lo tanto, pueden surgir situaciones cuando realizaron pruebas en la rama incorrecta o recopilaron la confirmación incorrecta para los evaluadores.
- La gente es perezosa . Periódicamente, cuando termino una tarea, tengo el pensamiento: “¿Pero qué hay para verificar? Escribí dos líneas: ¡stopudovo, todo funciona! Creo que para algunos de ustedes, tales pensamientos a veces vienen a la mente. Pero siempre debes comprobarlo.
Cómo se introdujo y desarrolló Continuous Integration en el equipo de desarrollo móvil de Avito, cómo alcanzaron de 0 a 450 ensamblajes por día, y que las máquinas de construcción recolectan 200 horas al día, dice Nikolay Nesterov (
nnesterov ), participante en todos los cambios evolutivos de la aplicación de Android CI / CD .
La historia se basa en el ejemplo del equipo de Android, pero la mayoría de los enfoques se aplican también en iOS.
Érase una vez, una persona trabajó en el equipo de Avito Android. Por definición, no necesitaba nada de la integración continua: no había nadie con quien integrarse.
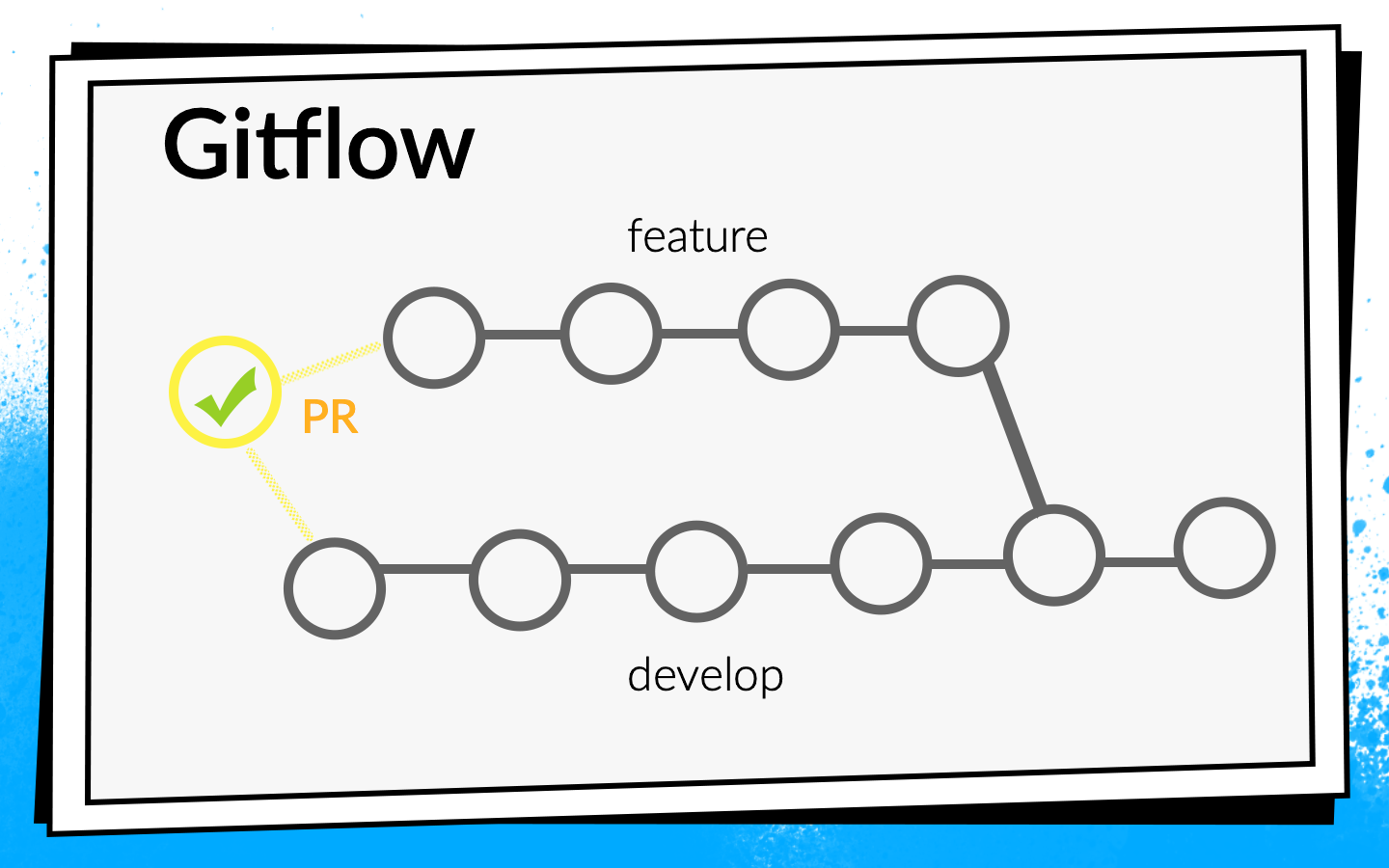
Pero la aplicación creció, aparecieron más y más tareas nuevas, respectivamente, el equipo creció. En algún momento, llegó el momento de establecer más formalmente el proceso de integración del código. Se decidió usar Git flow.

El concepto de flujo de Git es conocido: hay una rama de desarrollo común en el proyecto, y para cada nueva característica, los desarrolladores cortan una rama separada, la confirman, la envían, y cuando quieren inyectar su código en la rama de desarrollo, abren la solicitud de extracción. Para compartir conocimiento y discutir enfoques, introdujimos una revisión de código, es decir, los colegas deben verificar y confirmar el código del otro.
Cheques
Ver el código con los ojos es genial, pero no lo suficiente. Por lo tanto, se introducen las verificaciones automáticas.
- En primer lugar, verificamos el ensamblaje del ARC .
- Muchas pruebas de Junit .
- Consideramos la cobertura del código , ya que ejecutamos las pruebas.
Para comprender cómo deben ejecutarse estas comprobaciones, veamos el proceso de desarrollo en Avito.
Esquemáticamente, se puede representar de la siguiente manera:
- El desarrollador escribe el código en su computadora portátil. Puede ejecutar comprobaciones de integración aquí, ya sea con un enlace de confirmación o simplemente ejecutar comprobaciones en segundo plano.
- Después de que el desarrollador haya ejecutado el código, abre la solicitud de extracción. Para que su código entre en la rama de desarrollo, debe pasar por una revisión de código y recopilar el número requerido de confirmaciones. Puede habilitar comprobaciones y compilaciones aquí: hasta que todas las compilaciones sean exitosas, la solicitud de extracción no se puede fusionar.
- Después de fusionar la solicitud de extracción y de desarrollar el código, puede elegir un momento conveniente: por ejemplo, por la noche, cuando todos los servidores están libres, y realice las comprobaciones que desee.
A nadie le gustaba hacer pruebas en su computadora portátil. Cuando el desarrollador ha finalizado la función, quiere iniciarla rápidamente y abrir la solicitud de extracción. Si en ese momento se inician algunas comprobaciones largas, esto no solo no es muy agradable, sino que también ralentiza el desarrollo: mientras el portátil está comprobando algo, es imposible trabajar normalmente en él.
Realmente nos gustó hacer cheques por la noche, porque hay mucho tiempo y servidores, puedes dar un paseo. Pero, desafortunadamente, cuando se desarrolló el código de característica, el desarrollador ya tiene mucha menos motivación para reparar los errores que encontró CI. Periódicamente me sorprendía pensando cuando miraba en el informe de la mañana sobre todos los errores y descubrí que los solucionaría algún tiempo después, porque ahora en Jira se encuentra una nueva y genial tarea que solo quiero comenzar a hacer.
Si los controles bloquean la solicitud de extracción, entonces hay suficiente motivación, porque hasta que las compilaciones se vuelvan verdes, el código no se desarrollará, lo que significa que la tarea no se completará.
Como resultado, elegimos esta estrategia: en la noche manejamos el máximo conjunto de controles posible, y el más crítico de ellos y, lo más importante, rápido, ejecutamos una solicitud de extracción. Pero no nos detenemos allí: en paralelo, optimizamos la velocidad de pasar cheques de tal manera que los transfiera del modo nocturno a los cheques por solicitud de extracción.
En ese momento, todos nuestros ensamblajes fueron lo suficientemente rápidos, por lo que solo incluimos el ensamblaje ARC, las pruebas Junit y el cálculo de la cobertura del código con el bloqueador de solicitud de extracción. Lo encendieron, lo pensaron y abandonaron la cobertura del código porque pensaron que no lo necesitábamos.
Nos llevó dos días completar la configuración básica de CI (en adelante, una estimación temporal es aproximada, necesaria para la escala).Después de eso, comenzaron a pensar más: ¿lo estamos verificando correctamente? ¿Estamos lanzando compilaciones en la solicitud de extracción correctamente?
Comenzamos la compilación en el último commit de la rama con la que está abierta la solicitud de extracción. Pero las comprobaciones de esta confirmación solo pueden mostrar que el código que el desarrollador escribió funciona. Pero no prueban que no haya roto nada. De hecho, debe verificar el estado de la rama de desarrollo después de que la característica se haya inyectado en ella.
Para hacer esto, escribimos un script bash simple
premerge.sh:
Aquí, todos los últimos cambios desde el desarrollo simplemente se extraen y se fusionan en la rama actual. Agregamos el script premerge.sh como el primer paso de todas las compilaciones y comenzamos a verificar exactamente lo que queremos, es decir, la
integración .
Le llevó tres días localizar el problema, encontrar una solución y escribir este script.La aplicación se desarrolló, aparecieron más y más tareas, el equipo creció y premerge.sh a veces comenzó a decepcionarnos. En el desarrollo penetraron cambios conflictivos que rompieron la asamblea.
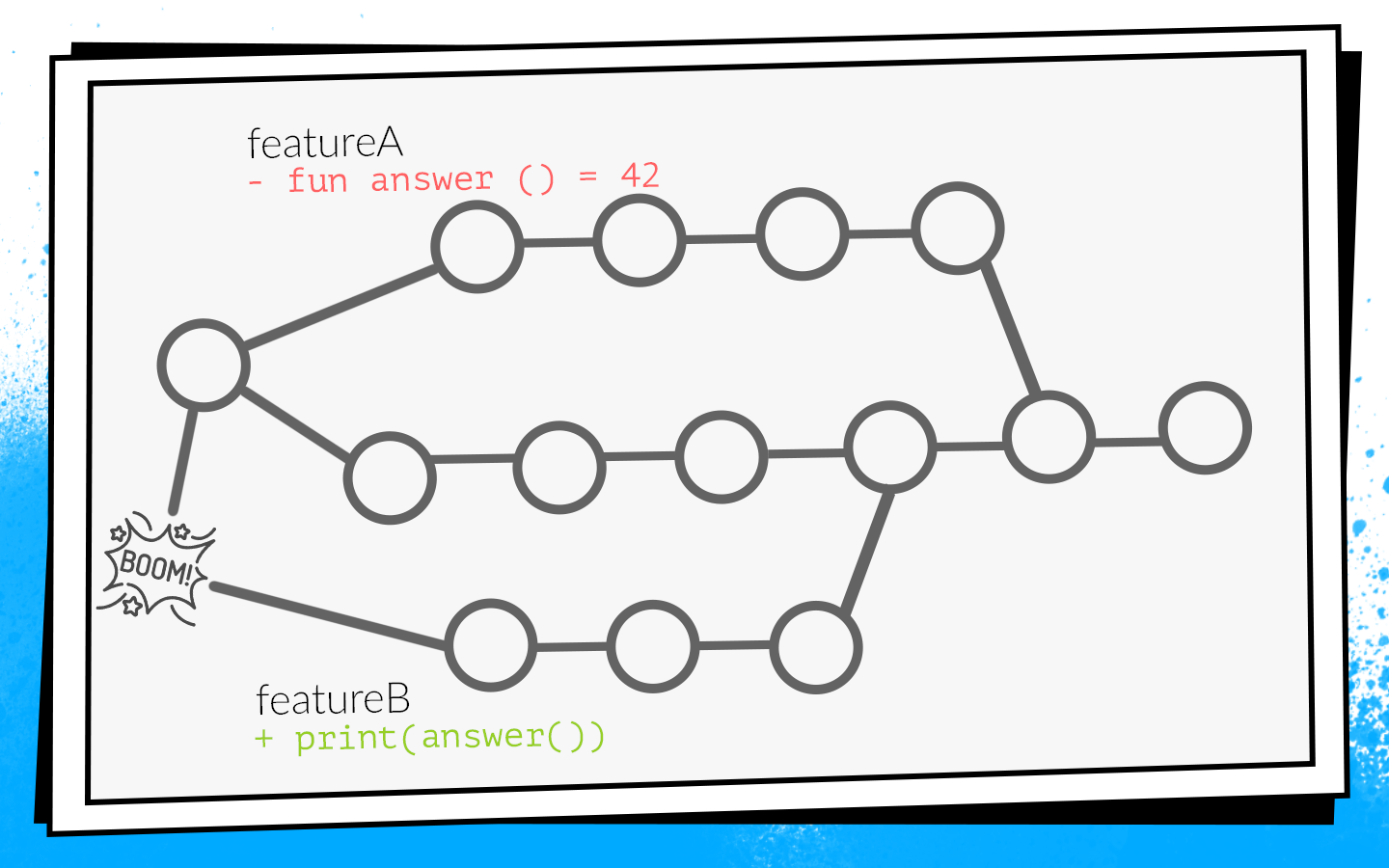
Un ejemplo de cómo sucede esto:

Dos desarrolladores al mismo tiempo comienzan a cortar las funciones A y B. El desarrollador de la función A descubre la función
answer() no utilizada en el proyecto y, como un buen explorador, la elimina. Al mismo tiempo, el desarrollador de la función B agrega una nueva llamada a esta función en su sucursal.
Los desarrolladores terminan el trabajo y al mismo tiempo abren la solicitud de extracción. Inicio de compilaciones, premerge.sh comprueba tanto la solicitud de extracción para un nuevo estado de desarrollo: todas las comprobaciones son verdes Después de que las características de solicitud de extracción A se fusionen, las características de solicitud de extracción B se fusionan ... ¡Auge! Desarrolle pausas porque en el código de desarrollo hay una llamada a una función inexistente.
Cuando no se va a desarrollar, este es un
desastre local . Todo el equipo no puede recolectar y dar nada para probar.
Dio la casualidad de que participaba con mayor frecuencia en tareas de infraestructura: análisis, red, bases de datos. Es decir, escribí las funciones y clases que usan otros desarrolladores. Debido a esto, muy a menudo me metí en tales situaciones. Incluso tuve una foto así a la vez.

Como esto no nos convenía, comenzamos a encontrar opciones sobre cómo prevenir esto.
Cómo no romper desarrollarse
Primera opción:
reconstruir todas las solicitudes de extracción cuando se desarrolle la actualización. Si en nuestro ejemplo, una solicitud de extracción con la función A se desarrolla por primera vez, la solicitud de extracción de la función B se reconstruirá y, en consecuencia, las comprobaciones fallarán debido a un error de compilación.
Para comprender cuánto tiempo llevará, considere un ejemplo con dos RP. Abrimos dos relaciones públicas: dos compilaciones, dos lanzamientos de prueba. Después de que el primer PR se vierta en desarrollo, el segundo debe ser reconstruido. En total, dos lanzamientos PR de cheques requieren tres RP: 2 + 1 = 3.
En principio, es normal. Pero observamos las estadísticas, y una situación típica en nuestro equipo fue de 10 RP abiertos, y luego el número de controles es la suma de la progresión: 10 + 9 + ... + 1 = 55. Es decir, para aceptar 10 RP, debes reconstruir 55 veces. Y esto se encuentra en una situación ideal, cuando todos los cheques pasan la primera vez, cuando nadie abre una solicitud de extracción adicional mientras se procesan estos diez.
Imagínese un desarrollador que necesita tiempo para presionar primero el botón "fusionar", porque si esto lo hace un vecino, tendrá que esperar hasta que todos los ensambles vuelvan a pasar ... No, eso no funcionará, ralentizará seriamente el desarrollo.
La segunda forma posible:
recopilar la solicitud de extracción después de la revisión del código. Es decir, abra la solicitud de extracción, recopile la cantidad necesaria de actualizaciones de colegas, arregle lo que necesita y luego ejecute las compilaciones. Si tienen éxito, la solicitud de extracción se fusiona con el desarrollo. En este caso, no hay reinicios adicionales, pero los comentarios se ralentizan mucho. Como desarrollador, cuando abro una solicitud de extracción, inmediatamente quiero ver si lo hará. Por ejemplo, si una prueba falla, debe corregirla rápidamente. En el caso de una construcción retrasada, la retroalimentación se ralentiza, lo que significa todo el desarrollo. Esto tampoco nos convenía.
Como resultado, solo quedaba la tercera opción: hacer un
ciclo . Todo nuestro código, todas nuestras fuentes se almacenan en el repositorio en el servidor Bitbucket. En consecuencia, tuvimos que desarrollar un complemento para Bitbucket.

Este complemento anula el mecanismo de combinación de solicitud de extracción. El comienzo es estándar: PR abre, todos los ensamblajes comienzan, la revisión de código pasa. Pero después de que la revisión del código ha pasado, y el desarrollador decide hacer clic en "fusionar", el complemento verifica en qué estado se ejecutaron las comprobaciones de desarrollo. Si, después de las compilaciones, el desarrollo logró actualizarse, el complemento no le permitirá fusionar dicha solicitud de extracción en la rama principal. Simplemente reiniciará las compilaciones en relación con el nuevo desarrollo.

En nuestro ejemplo con cambios conflictivos, tales compilaciones fallarán debido a un error de compilación. En consecuencia, el desarrollador de la función B tendrá que corregir el código, reiniciar las comprobaciones, luego el complemento aplicará automáticamente la solicitud de extracción.
Antes de implementar este complemento, teníamos un promedio de 2.7 ejecuciones de prueba por solicitud de extracción. Con el complemento hubo 3.6 lanzamientos. Nos convino.
Vale la pena señalar que este complemento tiene un inconveniente: reinicia la compilación solo una vez. Es decir, de todos modos, queda una pequeña ventana a través de la cual se pueden desarrollar cambios conflictivos. Pero la probabilidad de esto no es alta, e hicimos este compromiso entre el número de arranques y la probabilidad de falla. Durante dos años, se disparó solo una vez, por lo tanto, probablemente no en vano.
Nos llevó dos semanas escribir la primera versión del complemento para Bitbucket.Nuevos cheques
Mientras tanto, nuestro equipo continuó creciendo. Se agregaron nuevos controles.
Pensamos: ¿por qué reparar errores si pueden evitarse? Y entonces introdujeron
el análisis de código estático . Comenzamos con lint, que está incluido en el SDK de Android. Pero en ese momento no sabía cómo trabajar con el código de Kotlin, y ya tenemos el 75% de la aplicación escrita en Kotlin. Por lo tanto, los
controles integrados de
Android Studio se agregaron a lint
.Para hacer esto, tuve que ser muy pervertido: tomar Android Studio, empacarlo en Docker y ejecutarlo en CI con un monitor virtual para que creyera que se estaba ejecutando en una computadora portátil real. Pero funcionó.
También en este momento, comenzamos a escribir muchas
pruebas de
instrumentación e implementamos
pruebas de captura de pantalla . Esto es cuando se genera una captura de pantalla de referencia para una vista pequeña separada, y la prueba es que se toma una captura de pantalla de la vista y se compara directamente con la referencia píxel por píxel. Si hay una discrepancia, significa que un diseño se ha ido a algún lado o que algo está mal en los estilos.
Pero las pruebas de instrumentación y las pruebas de captura de pantalla deben ejecutarse en dispositivos: en emuladores o en dispositivos reales. Dado que hay muchas pruebas y que a menudo persiguen, necesita una granja completa. Iniciar su propia granja es demasiado laborioso, por lo que encontramos una opción ya preparada: Firebase Test Lab.
Laboratorio de pruebas de Firebase
Fue elegido porque Firebase es un producto de Google, es decir, debe ser confiable y es poco probable que muera. Los precios son asequibles: $ 5 por hora para un dispositivo real, $ 1 por hora para un emulador.
La implementación del Firebase Test Lab en nuestro CI tardó aproximadamente tres semanas.Pero el equipo continuó creciendo y Firebase, desafortunadamente, comenzó a decepcionarnos. En ese momento, no tenía SLA. A veces, Firebase nos hizo esperar hasta que la cantidad requerida de dispositivos para las pruebas quedara libre y no comenzara a ejecutarlos de inmediato, como queríamos. Esperar en línea tomó hasta media hora, y esto es mucho tiempo. Las pruebas de instrumentación se ejecutaron en cada RP, los retrasos ralentizaron mucho el desarrollo, y luego llegó una factura mensual con una suma redonda. En general, se decidió abandonar Firebase y se vio internamente, ya que el equipo ha crecido lo suficiente.
Docker + python + bash
Tomamos docker, introdujimos emuladores, escribimos un programa simple de Python que en el momento adecuado aumenta la cantidad correcta de emuladores en la versión correcta y los detiene cuando es necesario. Y, por supuesto, un par de scripts de bash, ¿dónde sin ellos?
Nos llevó cinco semanas crear nuestro propio entorno de prueba.Como resultado, cada solicitud de extracción tenía una extensa lista de comprobaciones de combinación de bloqueo:
- Asamblea del ARC;
- Pruebas Junit
- Pelusa
- Comprobaciones de Android Studio;
- Pruebas de instrumentación;
- Pruebas de captura de pantalla.
Esto evitó muchas posibles averías. Técnicamente, todo funcionó, pero los desarrolladores se quejaron de que la espera de los resultados fue demasiado larga.
¿Cuánto tiempo es demasiado? Subimos los datos de Bitbucket y TeamCity al sistema de análisis y nos dimos cuenta de que el
tiempo de espera promedio es de 45 minutos . Es decir, un desarrollador, al abrir una solicitud de extracción, en promedio espera resultados de compilación de 45 minutos. En mi opinión, esto es mucho, y no puedes trabajar así.
Por supuesto, decidimos acelerar todas nuestras compilaciones.
Acelerar
Al ver que a menudo las construcciones están en línea, lo primero que
compramos es hierro : el desarrollo extensivo es el más simple. Las construcciones dejaron de hacer cola, pero el tiempo de espera disminuyó solo un poco, porque algunos controles por sí mismos estuvieron persiguiéndolos durante mucho tiempo.
Eliminamos cheques demasiado largos
Nuestra integración continua podría detectar este tipo de errores y problemas.
- No voy a hacerlo CI puede detectar un error de compilación cuando, debido a cambios conflictivos, algo no va a suceder. Como dije, entonces nadie puede recolectar nada, el desarrollo aumenta y todos se ponen nerviosos.
- Un error en el comportamiento . Por ejemplo, cuando se crea la aplicación, pero cuando hace clic en el botón se bloquea o el botón no se presiona en absoluto. Esto es malo porque dicho error puede llegar al usuario.
- Error en el diseño . Por ejemplo, se presiona un botón, pero se mueve 10 píxeles hacia la izquierda.
- Aumento de la deuda técnica .
Al mirar esta lista, nos dimos cuenta de que solo los dos primeros puntos son críticos. Queremos atrapar tales problemas en primer lugar. Los errores en el diseño se detectan en la etapa de revisión del diseño y luego se solucionan fácilmente. Trabajar con deuda técnica requiere un proceso y una planificación por separado, por lo que decidimos no verificarlo para la solicitud de extracción.
Con base en esta clasificación, sacudimos la lista completa de controles.
Tachó Lint y pospuso su lanzamiento para la noche: solo para que dé un informe de cuántos problemas hay en el proyecto. Acordamos trabajar por separado con la deuda técnica, pero
rechazamos completamente los cheques de Android Studio . El estudio de Android de Docker para iniciar inspecciones parece interesante, pero trae muchos problemas de soporte. Cualquier actualización de las versiones de Android Studio es una lucha contra errores oscuros. También fue difícil mantener las pruebas de captura de pantalla, porque la biblioteca no funcionaba de manera muy estable, había falsos positivos.
Las pruebas de captura de pantalla se eliminaron de la lista de verificaciones .
Como resultado, nos queda:
- Asamblea del ARC;
- Pruebas Junit
- Pruebas de instrumentación.
Gradle caché remoto
Sin controles pesados, las cosas mejoraron. ¡Pero no hay límite para la perfección!
Nuestra aplicación ya se ha dividido en aproximadamente 150 módulos de gradle. Por lo general, en este caso, el caché remoto de Gradle funciona bien y decidimos probarlo.
Gradle remote cache es un servicio que puede almacenar en caché artefactos de construcción para tareas individuales en módulos separados. Gradle, en lugar de compilar el código, derriba el caché remoto a través de HTTP y pregunta si alguien ya ha realizado esta tarea. Si es así, simplemente descargue el resultado.
Iniciar Gradle Remote Cache es fácil porque Gradle proporciona una imagen Docker. Logramos hacer esto en tres horas.Todo lo que se necesitaba era iniciar Docker y registrar una línea en el proyecto. Pero aunque puede iniciarlo rápidamente para que todo funcione bien, tomará mucho tiempo.
A continuación se muestra un gráfico de errores de caché.

Al principio, el porcentaje de fallas más allá del caché era de aproximadamente 65. Tres semanas después, logramos llevar este valor al 20%. Resultó que las tareas que recopila la aplicación de Android tienen dependencias transitivas extrañas, por lo que Gradle perdió el caché.
Al conectar el caché, aceleramos enormemente el ensamblaje. Pero aparte del ensamblaje, las pruebas de instrumentación aún persiguen y persiguen durante mucho tiempo. Quizás no todas las pruebas necesitan ser perseguidas para cada solicitud de extracción. Para averiguarlo, utilizamos el análisis de impacto.
Análisis de impacto
En la solicitud de extracción, creamos git diff y encontramos los módulos Gradle modificados.

Tiene sentido ejecutar solo las pruebas de instrumentación que prueban los módulos modificados y todos los módulos que dependen de ellos. No tiene sentido ejecutar pruebas para módulos vecinos: el código no ha cambiado allí y nada puede romperse.
Las pruebas de instrumentación no son tan simples, ya que deben ubicarse en el módulo de Aplicación de nivel superior. Aplicamos una heurística de análisis de código de bytes para comprender a qué módulo pertenece cada prueba.
Tomó alrededor de ocho semanas actualizar las pruebas de instrumentación para probar solo los módulos involucrados.Las medidas de aceleración de verificación han funcionado con éxito. A partir de los 45 minutos llegamos a aproximadamente 15. Un cuarto de hora para esperar la construcción ya es normal.
Pero ahora los desarrolladores han comenzado a quejarse de que no les queda claro qué compilaciones se están lanzando, dónde se verá el registro, por qué la compilación es roja, qué prueba cayó, etc.
Los problemas de retroalimentación retrasan el desarrollo, por lo que intentamos proporcionar la información más comprensible y detallada sobre cada RP y compilación. Comenzamos con comentarios en Bitbucket para relaciones públicas, indicando qué versión cayó y por qué, escribimos mensajes específicos en Slack. Al final, crearon un panel para la página de relaciones públicas con una lista de todas las compilaciones que se están ejecutando actualmente y su estado: en línea, comienza, se bloquea o termina. Puede hacer clic en la compilación y acceder a su registro.
 Se pasaron seis semanas en comentarios detallados.
Se pasaron seis semanas en comentarios detallados.Planes
Pasamos a la última historia. Una vez resuelta la cuestión de los comentarios, pasamos a un nuevo nivel: decidimos construir nuestra propia granja de emuladores. Cuando hay muchas pruebas y emuladores, son difíciles de administrar. Como resultado, todos nuestros emuladores se trasladaron a un clúster k8s con administración de recursos flexible.
Además, hay otros planes.
- Devolver pelusa (y otros análisis estáticos). Ya estamos trabajando en esta dirección.
- Ejecute todas las pruebas de extremo a extremo en el bloqueador de PR en todas las versiones del SDK.
Entonces, rastreamos la historia del desarrollo de la Integración Continua en Avito. Ahora quiero dar algunos consejos desde el punto de vista de los experimentados.
Consejos
Si pudiera dar solo un consejo, este sería este:
¡Tenga cuidado con los scripts de shell!
Bash es una herramienta muy flexible y poderosa, es muy conveniente y rápido escribir scripts en ella. Pero con él puedes caer en la trampa, y nosotros, desafortunadamente, caímos en ella.
Todo comenzó con scripts simples que se ejecutaban en nuestras máquinas de compilación:
Pero, como saben, todo se desarrolla y se complica con el tiempo: ejecutemos un script a partir de otro, pasemos algunos parámetros allí, al final tuve que escribir una función que determine en qué nivel de anidación bash estamos ahora, para sustituir las citas necesarias, para que todo comience.

Puedes imaginar el trabajo involucrado en el desarrollo de tales guiones. Te aconsejo que no caigas en esta trampa.
¿Qué se puede reemplazar?
- Cualquier lenguaje de script. Escribir en Python o Kotlin Script es más conveniente porque es programación, no scripts.
- O describa toda la lógica de compilación en forma de tareas de gradle personalizadas para su proyecto.
Decidimos elegir la segunda opción, y ahora estamos eliminando sistemáticamente todos los scripts de bash y escribiendo muchos gradle shuffles personalizados.
Consejo # 2: mantenga su infraestructura en código.Es conveniente cuando la configuración de Integración continua se almacena no en la interfaz de usuario de Jenkins o TeamCity, etc., sino como archivos de texto directamente en el repositorio del proyecto. Esto le da versatilidad. No será difícil revertir o recopilar código en otra sucursal.
Las secuencias de comandos se pueden almacenar en el proyecto. ¿Y qué hacer con el medio ambiente?
Consejo # 3: Docker puede ayudar con el medio ambiente.Definitivamente ayudará a los desarrolladores de Android, iOS aún no, desafortunadamente.
Este es un ejemplo de un archivo acoplable simple que contiene jdk y android-sdk:
FROM openjdk:8 ENV SDK_URL="https://dl.google.com/android/repository/sdk-tools-linux-3859397.zip" \ ANDROID_HOME="/usr/local/android-sdk" \ ANDROID_VERSION=26 \ ANDROID_BUILD_TOOLS_VERSION=26.0.2 # Download Android SDK RUN mkdir "$ANDROID_HOME" .android \ && cd "$ANDROID_HOME" \ && curl -o sdk.zip $SDK_URL \ && unzip sdk.zip \ && rm sdk.zip \ && yes | $ANDROID_HOME/tools/bin/sdkmanager --licenses # Install Android Build Tool and Libraries RUN $ANDROID_HOME/tools/bin/sdkmanager --update RUN $ANDROID_HOME/tools/bin/sdkmanager "build-tools;${ANDROID_BUILD_TOOLS_VERSION}" \ "platforms;android-${ANDROID_VERSION}" \ "platform-tools" RUN mkdir /application WORKDIR /application
Después de escribir este archivo acoplable (te diré un secreto, no puedes escribirlo, pero sácalo de GitHub) y recopila la imagen, obtienes una máquina virtual en la que puedes construir la aplicación y ejecutar pruebas de Junit.
Los dos argumentos principales por los que esto tiene sentido son la escalabilidad y la repetibilidad. Con Docker, puede generar rápidamente una docena de agentes de compilación que tendrán exactamente el mismo entorno que el anterior. Esto facilita la vida de los ingenieros de CI. Empujar android-sdk en Docker es bastante simple, con emuladores un poco más complicados: tienes que ejercitarte un poco (bueno, o descargar el terminado nuevamente desde GitHub).
Consejo número 4: no olvide que los cheques no se realizan por el bien de los cheques, sino por las personas.La retroalimentación rápida y, lo más importante, clara es muy importante para los desarrolladores: lo que rompieron, qué prueba cayó, dónde se encuentra el registro de compilación.
Consejo # 5: Sea pragmático con la integración continua.Comprenda claramente qué tipos de errores desea evitar, cuánto está dispuesto a gastar recursos, tiempo, tiempo en la computadora. Los cheques demasiado largos pueden, por ejemplo, reprogramarse durante la noche. Y aquellos que atrapan errores no muy importantes deben ser completamente abandonados.
Consejo número 6: use herramientas listas para usar.Ahora hay muchas compañías que proporcionan CI en la nube.

Para equipos pequeños, esta es una buena salida. No necesita mantener nada, solo pague algo de dinero, recopile su aplicación e incluso realice pruebas de instrumentación.
Consejo # 7: en un equipo grande, las soluciones internas son más rentables.Pero tarde o temprano, con el crecimiento del equipo, las soluciones internas serán más rentables. Hay un punto con estas decisiones. En economía, existe una ley de rendimientos decrecientes: en cualquier proyecto, cada mejora posterior se hace más difícil, requiere más y más inversión.
La economía describe toda nuestra vida, incluida la integración continua. Construí un cronograma de trabajo para cada etapa de nuestro desarrollo de Integración Continua.

Se puede ver que cualquier mejora es cada vez más difícil. Mirando este gráfico, podemos entender que el desarrollo de la Integración Continua debe ser consistente con el crecimiento del tamaño del equipo. Para un equipo de dos personas, pasar 50 días desarrollando una granja de emuladores internos es una idea regular. Pero al mismo tiempo, para un gran equipo no hacer Integración Continua es una mala idea, debido a problemas de integración, arreglando comunicaciones, etc. Tomará aún más tiempo.
Comenzamos con el hecho de que la automatización es necesaria porque las personas son caras, están equivocadas y son flojas. Pero la gente también se automatiza. Por lo tanto, todos estos mismos problemas se aplican a la automatización.
- Automatizar es costoso. Recuerda el horario de trabajo.
- En automatización, las personas cometen errores.
- La automatización a veces es muy floja, porque todo funciona así. ¿Por qué más mejorar, por qué toda esta integración continua?
: 20% . , . , , , - , develop, . , , - .
Continuous Integration. ., , AppsConf . . 22-23 .