En esta publicación nos gustaría compartir una forma interesante de lidiar con la configuración de un sistema distribuido.
La configuración se representa directamente en lenguaje Scala de forma segura. Un ejemplo de implementación se describe en detalle. Se discuten varios aspectos de la propuesta, incluida la influencia en el proceso general de desarrollo.
( en ruso )
Introduccion
La construcción de sistemas distribuidos robustos requiere el uso de una configuración correcta y coherente en todos los nodos. Una solución típica es utilizar una descripción de implementación textual (terraform, ansible o similar) y archivos de configuración generados automáticamente (a menudo, dedicados para cada nodo / rol). También nos gustaría usar los mismos protocolos de las mismas versiones en cada nodo de comunicación (de lo contrario, experimentaríamos problemas de incompatibilidad). En el mundo JVM, esto significa que al menos la biblioteca de mensajería debe ser de la misma versión en todos los nodos comunicantes.
¿Qué hay de probar el sistema? Por supuesto, deberíamos realizar pruebas unitarias para todos los componentes antes de realizar las pruebas de integración. Para poder extrapolar los resultados de las pruebas en tiempo de ejecución, debemos asegurarnos de que las versiones de todas las bibliotecas se mantengan idénticas tanto en el tiempo de ejecución como en los entornos de prueba.
Al ejecutar pruebas de integración, a menudo es mucho más fácil tener el mismo classpath en todos los nodos. Solo necesitamos asegurarnos de que se use el mismo classpath en la implementación. (Es posible usar diferentes classpaths en diferentes nodos, pero es más difícil representar esta configuración y desplegarla correctamente). Entonces, para mantener las cosas simples, solo consideraremos classpaths idénticos en todos los nodos.
La configuración tiende a evolucionar junto con el software. Usualmente usamos versiones para identificar varios
etapas de la evolución del software. Parece razonable cubrir la configuración bajo la gestión de versiones e identificar diferentes configuraciones con algunas etiquetas. Si solo hay una configuración en producción, podemos usar una versión única como identificador. A veces podemos tener múltiples entornos de producción. Y para cada entorno podríamos necesitar una rama de configuración separada. Por lo tanto, las configuraciones pueden etiquetarse con rama y versión para identificar de manera única las diferentes configuraciones. Cada etiqueta y versión de rama corresponde a una combinación única de nodos distribuidos, puertos, recursos externos, versiones de biblioteca classpath en cada nodo. Aquí solo cubriremos la rama única e identificaremos configuraciones mediante una versión decimal de tres componentes (1.2.3), de la misma manera que otros artefactos.
En entornos modernos, los archivos de configuración ya no se modifican manualmente. Normalmente generamos
archivos de configuración en el momento de la implementación y nunca los toque después. Entonces, uno podría preguntarse por qué todavía usamos el formato de texto para los archivos de configuración. Una opción viable es colocar la configuración dentro de una unidad de compilación y beneficiarse de la validación de la configuración en tiempo de compilación.
En esta publicación examinaremos la idea de mantener la configuración en el artefacto compilado.
Configuración compilable
En esta sección discutiremos un ejemplo de configuración estática. Se están configurando e implementando dos servicios simples: el servicio de eco y el cliente del servicio de eco. Luego se instancian dos sistemas distribuidos diferentes con ambos servicios. Uno es para una configuración de un solo nodo y otro para la configuración de dos nodos.
Un sistema distribuido típico consta de unos pocos nodos. Los nodos podrían identificarse utilizando algún tipo:
sealed trait NodeId case object Backend extends NodeId case object Frontend extends NodeId
o solo
case class NodeId(hostName: String)
o incluso
object Singleton type NodeId = Singleton.type
Estos nodos desempeñan diversas funciones, ejecutan algunos servicios y deberían poder comunicarse con los otros nodos mediante conexiones TCP / HTTP.
Para la conexión TCP, se requiere al menos un número de puerto. También queremos asegurarnos de que el cliente y el servidor estén hablando el mismo protocolo. Para modelar una conexión entre nodos, declaremos la siguiente clase:
case class TcpEndPoint[Protocol](node: NodeId, port: Port[Protocol])
donde Port es solo un Int dentro del rango permitido:
type PortNumber = Refined[Int, Closed[_0, W.`65535`.T]]
Tipos refinadosVer biblioteca refinada . En resumen, permite agregar restricciones de tiempo de compilación a otros tipos. En este caso, Int solo puede tener valores de 16 bits que pueden representar el número de puerto. No hay ningún requisito para usar esta biblioteca para este enfoque de configuración. Simplemente parece encajar muy bien.
Para HTTP (REST) también podríamos necesitar una ruta del servicio:
type UrlPathPrefix = Refined[String, MatchesRegex[W.`"[a-zA-Z_0-9/]*"`.T]] case class PortWithPrefix[Protocol](portNumber: PortNumber, pathPrefix: UrlPathPrefix)
Tipo fantasmaPara identificar el protocolo durante la compilación, estamos utilizando la función Scala de declarar el Protocol argumento de tipo que no se usa en la clase. Es un tipo llamado fantasma . En tiempo de ejecución raramente necesitamos una instancia de identificador de protocolo, por eso no la almacenamos. Durante la compilación, este tipo fantasma proporciona seguridad de tipo adicional. No podemos pasar el puerto con un protocolo incorrecto.
Uno de los protocolos más utilizados es REST API con serialización Json:
sealed trait JsonHttpRestProtocol[RequestMessage, ResponseMessage]
donde RequestMessage es el tipo base de mensajes que el cliente puede enviar al servidor y ResponseMessage es el mensaje de respuesta del servidor. Por supuesto, podemos crear otras descripciones de protocolo que especifiquen el protocolo de comunicación con la precisión deseada.
A los fines de esta publicación, utilizaremos una versión más simple del protocolo:
sealed trait SimpleHttpGetRest[RequestMessage, ResponseMessage]
En este protocolo, el mensaje de solicitud se agrega a la URL y el mensaje de respuesta se devuelve como una cadena simple.
Una configuración de servicio podría describirse por el nombre del servicio, una colección de puertos y algunas dependencias. Hay algunas formas posibles de cómo representar todos estos elementos en Scala (por ejemplo, HList , tipos de datos algebraicos). Para los fines de esta publicación, utilizaremos Cake Pattern y representaremos piezas combinables (módulos) como rasgos. (Cake Pattern no es un requisito para este enfoque de configuración compilable. Es solo una posible implementación de la idea).
Las dependencias podrían representarse utilizando el patrón de pastel como puntos finales de otros nodos:
type EchoProtocol[A] = SimpleHttpGetRest[A, A] trait EchoConfig[A] extends ServiceConfig { def portNumber: PortNumber = 8081 def echoPort: PortWithPrefix[EchoProtocol[A]] = PortWithPrefix[EchoProtocol[A]](portNumber, "echo") def echoService: HttpSimpleGetEndPoint[NodeId, EchoProtocol[A]] = providedSimpleService(echoPort) }
El servicio de eco solo necesita un puerto configurado. Y declaramos que este puerto es compatible con el protocolo de eco. Tenga en cuenta que no necesitamos especificar un puerto en particular en este momento, porque los rasgos permiten declaraciones de métodos abstractos. Si usamos métodos abstractos, el compilador requerirá una implementación en una instancia de configuración. Aquí hemos proporcionado la implementación ( 8081 ) y se usará como valor predeterminado si la omitimos en una configuración concreta.
Podemos declarar una dependencia en la configuración del cliente del servicio echo:
trait EchoClientConfig[A] { def testMessage: String = "test" def pollInterval: FiniteDuration def echoServiceDependency: HttpSimpleGetEndPoint[_, EchoProtocol[A]] }
La dependencia tiene el mismo tipo que echoService . En particular, exige el mismo protocolo. Por lo tanto, podemos estar seguros de que si conectamos estas dos dependencias, funcionarán correctamente.
Implementación de serviciosUn servicio necesita una función para iniciarse y cerrarse con gracia. (La capacidad de cerrar un servicio es crítica para las pruebas). De nuevo, hay algunas opciones para especificar dicha función para una configuración dada (por ejemplo, podríamos usar clases de tipo). Para esta publicación usaremos nuevamente Cake Pattern. Podemos representar un servicio usando cats.Resource que ya proporciona bracketing y liberación de recursos. Para adquirir un recurso, debemos proporcionar una configuración y un contexto de tiempo de ejecución. Entonces la función de inicio del servicio podría verse así:
type ResourceReader[F[_], Config, A] = Reader[Config, Resource[F, A]] trait ServiceImpl[F[_]] { type Config def resource( implicit resolver: AddressResolver[F], timer: Timer[F], contextShift: ContextShift[F], ec: ExecutionContext, applicative: Applicative[F] ): ResourceReader[F, Config, Unit] }
donde
Config : tipo de configuración que requiere este iniciador de servicioAddressResolver : un objeto de tiempo de ejecución que tiene la capacidad de obtener direcciones reales de otros nodos (sigue leyendo para obtener más detalles).
los otros tipos provienen de cats :
F[_] - tipo de efecto (en el caso más simple F[A] podría ser solo () => A En esta publicación usaremos cats.IO )Reader[A,B] - es más o menos un sinónimo de una función A => Bcats.Resource : tiene formas de adquirir y liberarTimer : permite dormir / medir el tiempoContextShift - análogo de ExecutionContextApplicative : envoltorio de funciones en efecto (casi una mónada) (eventualmente podríamos reemplazarlo por otra cosa)
Usando esta interfaz podemos implementar algunos servicios. Por ejemplo, un servicio que no hace nada:
trait ZeroServiceImpl[F[_]] extends ServiceImpl[F] { type Config <: Any def resource(...): ResourceReader[F, Config, Unit] = Reader(_ => Resource.pure[F, Unit](())) }
(Consulte Código fuente para otras implementaciones de servicios: servicio echo ,
Cliente echo y controladores de por vida .)
Un nodo es un objeto único que ejecuta algunos servicios (Cake Pattern habilita el inicio de una cadena de recursos):
object SingleNodeImpl extends ZeroServiceImpl[IO] with EchoServiceService with EchoClientService with FiniteDurationLifecycleServiceImpl { type Config = EchoConfig[String] with EchoClientConfig[String] with FiniteDurationLifecycleConfig }
Tenga en cuenta que en el nodo especificamos el tipo exacto de configuración que necesita este nodo. El compilador no nos permitirá construir el objeto (Cake) con un tipo insuficiente, porque cada rasgo de servicio declara una restricción en el tipo de Config . Además, no podremos iniciar el nodo sin proporcionar una configuración completa.
Resolución de dirección de nodoPara establecer una conexión, necesitamos una dirección de host real para cada nodo. Puede ser conocido más tarde que otras partes de la configuración. Por lo tanto, necesitamos una forma de proporcionar un mapeo entre la identificación del nodo y su dirección real. Este mapeo es una función:
case class NodeAddress[NodeId](host: Uri.Host) trait AddressResolver[F[_]] { def resolve[NodeId](nodeId: NodeId): F[NodeAddress[NodeId]] }
Hay algunas formas posibles de implementar dicha función.
- Si conocemos las direcciones reales antes de la implementación, durante la creación de instancias de hosts de nodo, podemos generar código Scala con las direcciones reales y ejecutar la compilación después (que realiza comprobaciones de tiempo de compilación y luego ejecuta el conjunto de pruebas de integración). En este caso, nuestra función de mapeo se conoce estáticamente y se puede simplificar a algo así como un
Map[NodeId, NodeAddress] . - A veces obtenemos direcciones reales solo en un momento posterior cuando el nodo se inicia realmente, o no tenemos direcciones de nodos que aún no se han iniciado. En este caso, podríamos tener un servicio de descubrimiento que se inicia antes que todos los demás nodos y cada nodo podría anunciar su dirección en ese servicio y suscribirse a las dependencias.
- Si podemos modificar
/etc/hosts , podemos usar nombres de host predefinidos (como my-project-main-node y echo-backend ) y simplemente asociar este nombre con la dirección IP en el momento de la implementación.
En esta publicación no cubrimos estos casos con más detalles. De hecho, en nuestro ejemplo de juguete, todos los nodos tendrán la misma dirección IP: 127.0.0.1 .
En esta publicación consideraremos dos diseños de sistemas distribuidos:
- Diseño de nodo único, donde todos los servicios se colocan en el nodo único.
- Diseño de dos nodos, donde el servicio y el cliente están en nodos diferentes.
La configuración para un diseño de nodo único es la siguiente:
Configuración de nodo único object SingleNodeConfig extends EchoConfig[String] with EchoClientConfig[String] with FiniteDurationLifecycleConfig { case object Singleton // identifier of the single node // configuration of server type NodeId = Singleton.type def nodeId = Singleton override def portNumber: PortNumber = 8088
Aquí creamos una configuración única que extiende la configuración del servidor y del cliente. También configuramos un controlador de ciclo de vida que normalmente terminará el cliente y el servidor después de que pase el intervalo de por lifetime .
Se puede usar el mismo conjunto de implementaciones y configuraciones de servicios para crear el diseño de un sistema con dos nodos separados. Solo necesitamos crear dos configuraciones de nodo separadas con los servicios apropiados:
Configuración de dos nodos object NodeServerConfig extends EchoConfig[String] with SigTermLifecycleConfig { type NodeId = NodeIdImpl def nodeId = NodeServer override def portNumber: PortNumber = 8080 } object NodeClientConfig extends EchoClientConfig[String] with FiniteDurationLifecycleConfig {
Vea cómo especificamos la dependencia. Mencionamos el servicio proporcionado por el otro nodo como una dependencia del nodo actual. El tipo de dependencia se verifica porque contiene un tipo fantasma que describe el protocolo. Y en tiempo de ejecución tendremos la identificación de nodo correcta. Este es uno de los aspectos importantes del enfoque de configuración propuesto. Nos brinda la capacidad de configurar el puerto solo una vez y asegurarnos de que estamos haciendo referencia al puerto correcto.
Implementación de dos nodosPara esta configuración, utilizamos exactamente las mismas implementaciones de servicios. No hay cambios en absoluto. Sin embargo, creamos dos implementaciones de nodos diferentes que contienen diferentes conjuntos de servicios:
object TwoJvmNodeServerImpl extends ZeroServiceImpl[IO] with EchoServiceService with SigIntLifecycleServiceImpl { type Config = EchoConfig[String] with SigTermLifecycleConfig } object TwoJvmNodeClientImpl extends ZeroServiceImpl[IO] with EchoClientService with FiniteDurationLifecycleServiceImpl { type Config = EchoClientConfig[String] with FiniteDurationLifecycleConfig }
El primer nodo implementa el servidor y solo necesita la configuración del lado del servidor. El segundo nodo implementa el cliente y necesita otra parte de la configuración. Ambos nodos requieren alguna especificación de por vida. A los efectos de este nodo de servicio posterior, tendrá una vida útil infinita que podría finalizar utilizando SIGTERM , mientras que el cliente de eco finalizará después de la duración finita configurada. Vea la aplicación de inicio para más detalles.
Proceso de desarrollo general
Veamos cómo este enfoque cambia la forma en que trabajamos con la configuración.
La configuración como código se compilará y producirá un artefacto. Parece razonable separar los artefactos de configuración de otros artefactos de código. A menudo podemos tener multitud de configuraciones en la misma base de código. Y, por supuesto, podemos tener múltiples versiones de varias ramas de configuración. En una configuración podemos seleccionar versiones particulares de bibliotecas y esto permanecerá constante cada vez que implementemos esta configuración.
Un cambio de configuración se convierte en cambio de código. Por lo tanto, debe estar cubierto por el mismo proceso de garantía de calidad:
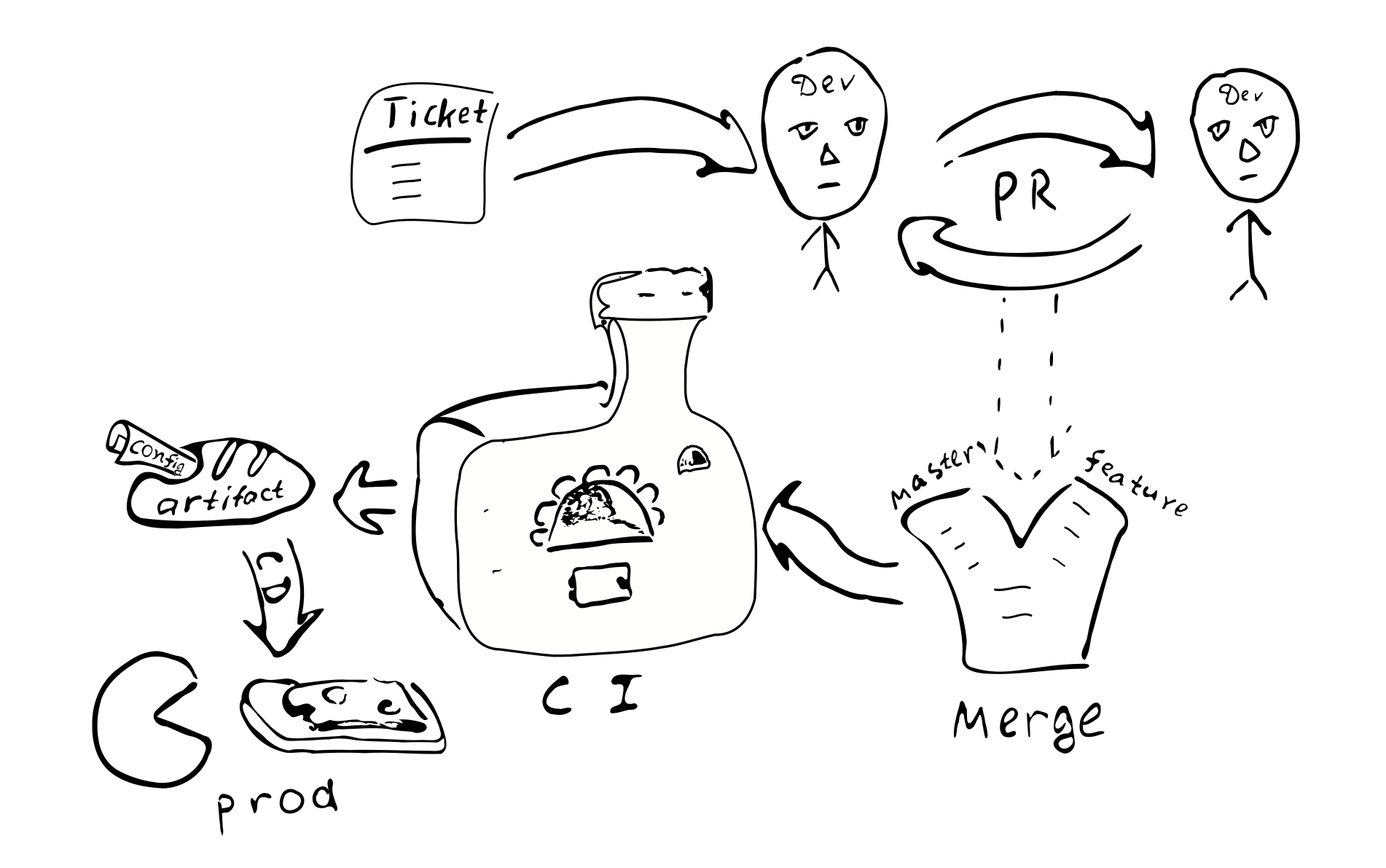
Ticket -> PR -> revisión -> fusión -> integración continua -> despliegue continuo
Existen las siguientes consecuencias del enfoque:
La configuración es coherente para la instancia de un sistema particular. Parece que no hay forma de tener una conexión incorrecta entre nodos.
No es fácil cambiar la configuración solo en un nodo. Parece poco razonable iniciar sesión y cambiar algunos archivos de texto. Entonces la deriva de la configuración se vuelve menos posible.
Pequeños cambios de configuración no son fáciles de hacer.
La mayoría de los cambios de configuración seguirán el mismo proceso de desarrollo y pasarán algunas revisiones.
¿Necesitamos un repositorio separado para la configuración de producción? La configuración de producción puede contener información confidencial que nos gustaría mantener fuera del alcance de muchas personas. Por lo tanto, podría valer la pena mantener un repositorio separado con acceso restringido que contendrá la configuración de producción. Podemos dividir la configuración en dos partes: una que contiene la mayoría de los parámetros abiertos de producción y otra que contiene la parte secreta de la configuración. Esto permitiría el acceso de la mayoría de los desarrolladores a la gran mayoría de los parámetros y restringiría el acceso a cosas realmente sensibles. Es fácil lograr esto usando rasgos intermedios con valores de parámetros predeterminados.
Variaciones
Veamos los pros y los contras del enfoque propuesto en comparación con las otras técnicas de administración de configuración.
En primer lugar, enumeraremos algunas alternativas a los diferentes aspectos de la forma propuesta de tratar con la configuración:
- Archivo de texto en la máquina de destino.
- Almacenamiento centralizado de valores clave (como
etcd / zookeeper ). - Componentes de subprocesos que podrían reconfigurarse / reiniciarse sin reiniciar el proceso.
- Configuración fuera del artefacto y control de versiones.
El archivo de texto ofrece cierta flexibilidad en términos de correcciones ad-hoc. El administrador de un sistema puede iniciar sesión en el nodo de destino, realizar un cambio y simplemente reiniciar el servicio. Esto podría no ser tan bueno para sistemas más grandes. No quedan rastros detrás del cambio. El cambio no es revisado por otro par de ojos. Puede ser difícil descubrir qué ha causado el cambio. No ha sido probado. Desde la perspectiva del sistema distribuido, un administrador puede simplemente olvidarse de actualizar la configuración en uno de los otros nodos.
(Por cierto, si eventualmente será necesario comenzar a usar archivos de configuración de texto, solo tendremos que agregar el analizador + validador que podría producir el mismo tipo de Config y eso sería suficiente para comenzar a usar configuraciones de texto. Esto también muestra que el La complejidad de la configuración en tiempo de compilación es un poco menor que la complejidad de las configuraciones basadas en texto, porque en la versión basada en texto necesitamos un código adicional).
El almacenamiento centralizado de valores clave es un buen mecanismo para distribuir los metaparámetros de la aplicación. Aquí debemos pensar en lo que consideramos valores de configuración y qué son solo datos. Dada una función C => A => B , generalmente llamamos a los valores que cambian raramente C "configuración", mientras que con frecuencia cambiamos los datos A , solo ingresamos datos. La configuración debe proporcionarse a la función antes que los datos A Dada esta idea, podemos decir que se espera que la frecuencia de los cambios se pueda utilizar para distinguir los datos de configuración de solo datos. Además, los datos generalmente provienen de una fuente (usuario) y la configuración proviene de una fuente diferente (administrador). Tratar con parámetros que pueden cambiarse después de la inicialización del proceso conduce a un aumento de la complejidad de la aplicación. Para tales parámetros tendremos que manejar su mecanismo de entrega, análisis y validación, manejando valores incorrectos. Por lo tanto, para reducir la complejidad del programa, será mejor que reduzcamos el número de parámetros que pueden cambiar en tiempo de ejecución (o incluso eliminarlos por completo).
Desde la perspectiva de esta publicación, debemos hacer una distinción entre parámetros estáticos y dinámicos. Si la lógica de servicio requiere un cambio raro de algunos parámetros en tiempo de ejecución, entonces podemos llamarlos parámetros dinámicos. De lo contrario, son estáticos y podrían configurarse utilizando el enfoque propuesto. Para la reconfiguración dinámica, podrían ser necesarios otros enfoques. Por ejemplo, partes del sistema podrían reiniciarse con los nuevos parámetros de configuración de manera similar a reiniciar procesos separados de un sistema distribuido.
(Mi humilde opinión es evitar la reconfiguración en tiempo de ejecución porque aumenta la complejidad del sistema.
Podría ser más sencillo confiar en el soporte del sistema operativo para reiniciar los procesos. Sin embargo, puede que no siempre sea posible).
Un aspecto importante del uso de la configuración estática que a veces hace que las personas consideren la configuración dinámica (sin otras razones) es el tiempo de inactividad del servicio durante la actualización de la configuración. De hecho, si tenemos que hacer cambios en la configuración estática, tenemos que reiniciar el sistema para que los nuevos valores entren en vigencia. Los requisitos para el tiempo de inactividad varían para los diferentes sistemas, por lo que podría no ser tan crítico. Si es crítico, entonces tenemos que planificar con anticipación cualquier reinicio del sistema. Por ejemplo, podríamos implementar el drenaje de la conexión AWS ELB . En este escenario, siempre que necesitemos reiniciar el sistema, comenzamos una nueva instancia del sistema en paralelo, luego cambiamos a ELB, mientras dejamos que el sistema anterior complete el servicio de las conexiones existentes.
¿Qué hay de mantener la configuración dentro de artefactos versionados o afuera? Mantener la configuración dentro de un artefacto significa en la mayoría de los casos que esta configuración ha pasado el mismo proceso de garantía de calidad que otros artefactos. Por lo tanto, uno puede estar seguro de que la configuración es de buena calidad y confiable. Por el contrario, la configuración en un archivo separado significa que no hay rastros de quién y por qué realizó cambios en ese archivo. ¿Es esto importante? Creemos que para la mayoría de los sistemas de producción es mejor tener una configuración estable y de alta calidad.
La versión del artefacto permite saber cuándo se creó, qué valores contiene, qué características están habilitadas / deshabilitadas, quién fue el responsable de realizar cada cambio en la configuración. Puede requerir cierto esfuerzo mantener la configuración dentro de un artefacto y es una elección de diseño.
Pros y contras
Aquí nos gustaría resaltar algunas ventajas y discutir algunas desventajas del enfoque propuesto.
Ventajas
Características de la configuración compilable de un sistema distribuido completo:
- Comprobación estática de la configuración. Esto proporciona un alto nivel de confianza, que la configuración es correcta dadas las restricciones de tipo.
- Rico lenguaje de configuración. Típicamente, otros enfoques de configuración están limitados a, como máximo, una sustitución variable.
El uso de Scala one puede usar una amplia gama de características del lenguaje para mejorar la configuración. Por ejemplo, podemos usar rasgos para proporcionar valores predeterminados, objetos para establecer un alcance diferente, podemos referirnos a val definidos solo una vez en el alcance externo (DRY). Es posible usar secuencias literales o instancias de ciertas clases ( Seq , Map , etc.). - DSL Scala tiene un soporte decente para los escritores DSL. Se pueden usar estas características para establecer un lenguaje de configuración que sea más conveniente y fácil de usar para el usuario final, de modo que la configuración final sea al menos legible para los usuarios del dominio.
- Integridad y coherencia entre nodos. Uno de los beneficios de tener la configuración para todo el sistema distribuido en un solo lugar es que todos los valores se definen estrictamente una vez y luego se reutilizan en todos los lugares donde los necesitamos. También escribir declaraciones de puerto seguro asegura que en todas las configuraciones correctas posibles los nodos del sistema hablen el mismo idioma. Existen dependencias explícitas entre los nodos que hacen que sea difícil olvidar proporcionar algunos servicios.
- Alta calidad de cambios. El enfoque general de pasar los cambios de configuración a través del proceso normal de relaciones públicas establece altos estándares de calidad también en la configuración.
- Cambios de configuración simultáneos. Cada vez que realizamos cambios en la configuración, la implementación automática garantiza que todos los nodos se actualicen.
- Simplificación de la aplicación. La aplicación no necesita analizar y validar la configuración y manejar valores de configuración incorrectos. Esto simplifica la aplicación general. (Un cierto aumento de la complejidad está en la configuración en sí, pero es una compensación consciente hacia la seguridad). Es bastante sencillo volver a la configuración normal, solo agregue las piezas que faltan. Es más fácil comenzar con la configuración compilada y posponer la implementación de piezas adicionales para algunos momentos posteriores.
- Configuración versionada. Debido al hecho de que los cambios de configuración siguen el mismo proceso de desarrollo, como resultado obtenemos un artefacto con una versión única. Nos permite cambiar la configuración de nuevo si es necesario. Incluso podemos implementar una configuración que se utilizó hace un año y funcionará exactamente de la misma manera. La configuración estable mejora la previsibilidad y la fiabilidad del sistema distribuido. La configuración se fija en tiempo de compilación y no se puede manipular fácilmente en un sistema de producción.
- Modularidad El marco propuesto es modular y los módulos se pueden combinar de varias maneras para
admite diferentes configuraciones (configuraciones / diseños). En particular, es posible tener un diseño de nodo único a pequeña escala y una configuración de nodo múltiple a gran escala. Es razonable tener múltiples diseños de producción. - Prueba Para fines de prueba, uno podría implementar un servicio simulado y usarlo como una dependencia de una manera segura. Algunos diseños de prueba diferentes con varias partes reemplazadas por simulacros podrían mantenerse simultáneamente.
- Pruebas de integración. A veces, en sistemas distribuidos es difícil ejecutar pruebas de integración. Utilizando el enfoque descrito para escribir una configuración segura del sistema distribuido completo, podemos ejecutar todas las partes distribuidas en un único servidor de manera controlable. Es fácil emular la situación.
cuando uno de los servicios deja de estar disponible.
Desventajas
El enfoque de configuración compilada es diferente de la configuración "normal" y podría no satisfacer todas las necesidades. Estas son algunas de las desventajas de la configuración compilada:
- Configuración estática Puede que no sea adecuado para todas las aplicaciones. En algunos casos existe la necesidad de corregir rápidamente la configuración en producción sin pasar por todas las medidas de seguridad. Este enfoque lo hace más difícil. La compilación y la reasignación son necesarias después de realizar cualquier cambio en la configuración. Esta es la característica y la carga.
- Generación de configuración. Cuando una herramienta de automatización genera la configuración, este enfoque requiere una compilación posterior (que a su vez podría fallar). Puede requerir un esfuerzo adicional para integrar este paso adicional en el sistema de compilación.
- Instrumentos Hay muchas herramientas en uso hoy en día que dependen de configuraciones basadas en texto. Algunos de ellos
no será aplicable cuando se compila la configuración. - Se necesita un cambio de mentalidad. Los desarrolladores y DevOps están familiarizados con los archivos de configuración de texto. La idea de compilar la configuración puede parecerles extraña.
- Antes de introducir la configuración compilable, se requiere un proceso de desarrollo de software de alta calidad.
Existen algunas limitaciones del ejemplo implementado:
- Si proporcionamos una configuración adicional que no es requerida por la implementación del nodo, el compilador no nos ayudará a detectar la implementación ausente. Esto podría abordarse utilizando
HList o HList (clases de casos) para la configuración de nodos en lugar de rasgos y Cake Pattern. - Tenemos que proporcionar algunas repeticiones en el archivo de configuración: (
package , import , declaraciones de object ;
override def 's para los parámetros que tienen valores predeterminados). Esto podría abordarse parcialmente mediante un DSL. - En esta publicación no cubrimos la reconfiguración dinámica de clústeres de nodos similares.
Conclusión
En esta publicación hemos discutido la idea de representar la configuración directamente en el código fuente de una manera segura. El enfoque podría utilizarse en muchas aplicaciones como un reemplazo de xml y otras configuraciones basadas en texto. A pesar de que nuestro ejemplo se ha implementado en Scala, también podría traducirse a otros idiomas compilables (como Kotlin, C #, Swift, etc.). Uno podría probar este enfoque en un nuevo proyecto y, en caso de que no encaje bien, cambiar a la forma tradicional.
Por supuesto, la configuración compilable requiere un proceso de desarrollo de alta calidad. A cambio, promete proporcionar una configuración robusta de igual calidad.
Este enfoque podría extenderse de varias maneras:
- Se podrían usar macros para realizar la validación de la configuración y fallar en el momento de la compilación en caso de fallas en las restricciones de lógica de negocios.
- Se podría implementar un DSL para representar la configuración de una manera fácil de usar para el dominio.
- Gestión dinámica de recursos con ajustes automáticos de configuración. Por ejemplo, cuando ajustamos el número de nodos del clúster, podríamos querer (1) que los nodos obtengan una configuración ligeramente modificada; (2) administrador de clúster para recibir información de nuevos nodos.
Gracias
Quisiera agradecer a Andrey Saksonov, Pavel Popov, Anton Nehaev por brindar comentarios inspiradores sobre el borrador de esta publicación que me ayudaron a aclararlo.