Me gustaría contarles un mecanismo interesante para trabajar con una configuración de sistema distribuido. La configuración se presenta directamente en un lenguaje compilado (Scala) utilizando tipos seguros. En esta publicación, se analiza un ejemplo de dicha configuración y se consideran varios aspectos de la introducción de una configuración compilada en el proceso de desarrollo general.
( ingles )
Introduccion
La construcción de un sistema distribuido confiable implica que todos los nodos usan la configuración correcta, sincronizada con otros nodos. Por lo general, las tecnologías DevOps (terraform, ansible o algo así) se utilizan para generar automáticamente archivos de configuración (a menudo propios para cada nodo). También nos gustaría asegurarnos de que todos los nodos interactuantes usen protocolos idénticos (incluida la misma versión). De lo contrario, la incompatibilidad se integrará en nuestro sistema distribuido. En el mundo JVM, una consecuencia de este requisito es la necesidad de usar la misma versión de una biblioteca que contiene mensajes de protocolo en todas partes.
¿Qué pasa con las pruebas de sistema distribuido? Por supuesto, suponemos que se proporcionan pruebas unitarias para todos los componentes antes de pasar a las pruebas de integración. (Para que podamos extrapolar los resultados de la prueba al tiempo de ejecución, también debemos proporcionar un conjunto idéntico de bibliotecas en la etapa de prueba y en tiempo de ejecución).
Cuando se trabaja con pruebas de integración, a menudo es más fácil en todas partes usar un único classpath en todos los nodos. Solo tendremos que asegurarnos de que el mismo classpath esté involucrado en el tiempo de ejecución. (A pesar de que es bastante posible ejecutar diferentes nodos con diferentes classpaths, esto lleva a la complicación de toda la configuración y a dificultades con las pruebas de implementación e integración). Como parte de esta publicación, asumimos que se utilizará el mismo classpath en todos los nodos.
La configuración evoluciona con la aplicación. Para identificar las diversas etapas de la evolución de los programas, utilizamos versiones. Parece lógico identificar también diferentes versiones de las configuraciones. Y la configuración en sí misma debe colocarse en el sistema de control de versiones. Si solo hay una configuración en producción, entonces podemos usar el número de versión. Si se utilizan muchas instancias de producción, entonces necesitamos varias
ramas de configuración y una etiqueta adicional además de la versión (por ejemplo, el nombre de la rama). Por lo tanto, podemos identificar de forma única la configuración exacta. Cada identificador de configuración corresponde únicamente a una determinada combinación de nodos distribuidos, puertos, recursos externos, versiones de biblioteca. En el marco de esta publicación, procederemos del hecho de que solo hay una rama, y podemos identificar la configuración de la manera habitual usando tres números separados por un punto (1.2.3).
En entornos modernos, los archivos de configuración se crean de forma manual muy raramente. Más a menudo se generan durante la implementación y ya no se tocan (para no romper nada ). Surge una pregunta lógica, ¿por qué seguimos usando un formato de texto para almacenar la configuración? Una alternativa completamente viable es la capacidad de usar código regular para la configuración y obtener beneficios de las comprobaciones en tiempo de compilación.
En esta publicación, solo estamos explorando la idea de representar una configuración dentro de un artefacto compilado.
Configuración compilada
Esta sección describe un ejemplo de una configuración compilada estática. Se implementan dos servicios simples: el servicio de eco y el servicio de eco del cliente. En base a estos dos servicios, se ensamblan dos versiones del sistema. En una realización, ambos servicios están ubicados en el mismo nodo, en otra realización, en nodos diferentes.
Por lo general, un sistema distribuido contiene varios nodos. Los nodos se pueden identificar utilizando valores de algún tipo NodeId :
sealed trait NodeId case object Backend extends NodeId case object Frontend extends NodeId
o
case class NodeId(hostName: String)
o incluso
object Singleton type NodeId = Singleton.type
Los nodos juegan varios roles, los servicios se inician en ellos y las comunicaciones TCP / HTTP se pueden establecer entre ellos.
Para describir las comunicaciones TCP, necesitamos al menos un número de puerto. También nos gustaría reflejar el protocolo que es compatible con este puerto para garantizar que tanto el cliente como el servidor usen el mismo protocolo. Describiremos la conexión usando esta clase:
case class TcpEndPoint[Protocol](node: NodeId, port: Port[Protocol])
donde Port es solo un entero Int con un rango de valores válidos:
type PortNumber = Refined[Int, Closed[_0, W.`65535`.T]]
Tipos refinadosVer biblioteca refinada y mi informe . En resumen, la biblioteca le permite agregar restricciones que se verifican en tiempo de compilación a los tipos. En este caso, los valores de número de puerto válidos son números enteros de 16 bits. Para una configuración compilada, el uso de la biblioteca refinada es opcional, pero puede mejorar la capacidad del compilador para verificar la configuración.
Para los protocolos HTTP (REST), además del número de puerto, también podemos necesitar una ruta al servicio:
type UrlPathPrefix = Refined[String, MatchesRegex[W.`"[a-zA-Z_0-9/]*"`.T]] case class PortWithPrefix[Protocol](portNumber: PortNumber, pathPrefix: UrlPathPrefix)
Tipos fantasmaPara identificar el protocolo en la etapa de compilación, usamos un parámetro de tipo que no se usa dentro de la clase. Esta decisión se debe al hecho de que en tiempo de ejecución no utilizamos una instancia de protocolo, pero nos gustaría que el compilador verifique la compatibilidad del protocolo. Gracias al protocolo, no podremos transferir el servicio inadecuado como una dependencia.
Un protocolo común es la API REST con serialización Json:
sealed trait JsonHttpRestProtocol[RequestMessage, ResponseMessage]
donde RequestMessage es el tipo de solicitud, ResponseMessage es el tipo de respuesta.
Por supuesto, puede usar otras descripciones de protocolos que brinden la precisión que requerimos.
Para los fines de esta publicación, utilizaremos una versión simplificada del protocolo:
sealed trait SimpleHttpGetRest[RequestMessage, ResponseMessage]
Aquí, la solicitud es una cadena agregada a la url, y la respuesta es la cadena devuelta en el cuerpo de la respuesta HTTP.
La configuración del servicio se describe por el nombre del servicio, los puertos y las dependencias. Estos elementos se pueden representar en Scala de varias maneras (por ejemplo, HList , tipos de datos algebraicos). Para los fines de esta publicación, utilizaremos el patrón de pastel y representaremos los módulos usando los trait . (Cake Pattern no es un elemento necesario del enfoque descrito. Es solo una de las posibles implementaciones).
Las dependencias entre servicios se pueden representar como métodos que devuelven EndPoint puertos de EndPoint de otros nodos:
type EchoProtocol[A] = SimpleHttpGetRest[A, A] trait EchoConfig[A] extends ServiceConfig { def portNumber: PortNumber = 8081 def echoPort: PortWithPrefix[EchoProtocol[A]] = PortWithPrefix[EchoProtocol[A]](portNumber, "echo") def echoService: HttpSimpleGetEndPoint[NodeId, EchoProtocol[A]] = providedSimpleService(echoPort) }
Para crear un servicio de eco, solo un número de puerto y una indicación de que este puerto admite el protocolo de eco son suficientes. No pudimos indicar un puerto específico, porque los rasgos le permiten declarar métodos sin implementación (métodos abstractos). En este caso, al crear una configuración específica, el compilador requerirá que proporcionemos una implementación de método abstracto y proporcionemos un número de puerto. Como implementamos el método, al crear una configuración específica, no podemos especificar otro puerto. Se usará el valor predeterminado.
En la configuración del cliente, declaramos una dependencia en el servicio echo:
trait EchoClientConfig[A] { def testMessage: String = "test" def pollInterval: FiniteDuration def echoServiceDependency: HttpSimpleGetEndPoint[_, EchoProtocol[A]] }
La dependencia es del mismo tipo que el servicio exportado echoService . En particular, en el cliente echo necesitamos el mismo protocolo. Por lo tanto, al conectar los dos servicios, podemos estar seguros de que todo funcionará correctamente.
Implementación del servicioPara iniciar y detener el servicio, se requiere una función. (La capacidad de detener el servicio es crítica para las pruebas). Nuevamente, hay varias opciones para implementar esta función (por ejemplo, podríamos usar clases de tipo basadas en el tipo de configuración). Para los fines de esta publicación, utilizaremos el patrón de pastel. Representaremos el servicio usando la clase cats.Resource , porque En esta clase, ya se proporcionan los medios para la liberación segura y segura de recursos en caso de problemas. Para obtener el recurso, necesitamos proporcionar una configuración y un contexto de tiempo de ejecución listo. La función para iniciar el servicio puede tener la siguiente forma:
type ResourceReader[F[_], Config, A] = Reader[Config, Resource[F, A]] trait ServiceImpl[F[_]] { type Config def resource( implicit resolver: AddressResolver[F], timer: Timer[F], contextShift: ContextShift[F], ec: ExecutionContext, applicative: Applicative[F] ): ResourceReader[F, Config, Unit] }
donde
Config - tipo de configuración para este servicioAddressResolver : un objeto de tiempo de ejecución que le permite encontrar las direcciones de otros nodos (ver más abajo)
y otros tipos de la biblioteca de cats :
F[_] - tipo de efecto (en el caso más simple, F[A] puede ser simplemente una función () => A En esta publicación usaremos cats.IO )Reader[A,B] : más o menos sinónimo de la función A => Bcats.Resource : un recurso que se puede obtener y liberarTimer : temporizador (le permite quedarse dormido por un tiempo y medir intervalos de tiempo)ContextShift - análogo de ExecutionContextApplicative : una clase de tipo de efecto que le permite combinar efectos individuales (casi una mónada). En aplicaciones más complejas, parece mejor usar Monad / ConcurrentEffect .
Usando esta firma de función, podemos implementar varios servicios. Por ejemplo, un servicio que no hace nada:
trait ZeroServiceImpl[F[_]] extends ServiceImpl[F] { type Config <: Any def resource(...): ResourceReader[F, Config, Unit] = Reader(_ => Resource.pure[F, Unit](())) }
(Consulte el código fuente para otros servicios: servicio echo , cliente echo
y controladores de por vida ).
Un nodo es un objeto que puede iniciar varios servicios (el patrón de pastel garantiza el inicio de la cadena de recursos):
object SingleNodeImpl extends ZeroServiceImpl[IO] with EchoServiceService with EchoClientService with FiniteDurationLifecycleServiceImpl { type Config = EchoConfig[String] with EchoClientConfig[String] with FiniteDurationLifecycleConfig }
Tenga en cuenta que indicamos el tipo exacto de configuración que se requiere para este nodo. Si olvidamos especificar uno de los tipos de configuración requeridos por un servicio separado, habrá un error de compilación. Además, no podremos iniciar el nodo si no proporcionamos algún objeto del tipo apropiado con todos los datos necesarios.
Resolución de nombre de hostPara conectarnos a un host remoto, necesitamos una dirección IP real. Es posible que la dirección se conozca más tarde que el resto de la configuración. Por lo tanto, necesitamos una función que asigne el identificador de nodo a la dirección:
case class NodeAddress[NodeId](host: Uri.Host) trait AddressResolver[F[_]] { def resolve[NodeId](nodeId: NodeId): F[NodeAddress[NodeId]] }
Puede ofrecer varias formas de implementar dicha función:
- Si conocemos las direcciones antes de la implementación, entonces podemos generar un código Scala con
direcciones y luego comenzar el montaje. Esto compilará y ejecutará las pruebas.
En este caso, la función se conocerá estáticamente y se puede representar en el código como una visualización de mapa Map[NodeId, NodeAddress] . - En algunos casos, una dirección válida se conoce solo después de que se inicia el nodo.
En este caso, podemos implementar un "servicio de descubrimiento" (descubrimiento), que se ejecuta antes que los otros nodos y todos los nodos se registrarán en este servicio y solicitarán las direcciones de otros nodos. - Si podemos modificar
/etc/hosts , entonces podemos usar nombres de host predefinidos (como my-project-main-node y echo-backend ) y solo vincular estos nombres
con direcciones IP durante la implementación.
En el marco de esta publicación, no consideraremos estos casos con más detalle. Para nuestro
En un ejemplo de juguete, todos los nodos tendrán una dirección IP: 127.0.0.1 .
A continuación, consideramos dos opciones para un sistema distribuido:
- Colocación de todos los servicios en un nodo.
- Y la ubicación del servicio de eco y el cliente de eco en diferentes nodos.
Configuración para un solo nodo :
Configuración de nodo único object SingleNodeConfig extends EchoConfig[String] with EchoClientConfig[String] with FiniteDurationLifecycleConfig { case object Singleton // identifier of the single node // configuration of server type NodeId = Singleton.type def nodeId = Singleton override def portNumber: PortNumber = 8088
El objeto implementa la configuración tanto del cliente como del servidor. La configuración de la vida útil también se utiliza para finalizar el programa después de una lifetime . (Ctrl-C también funciona y libera todos los recursos correctamente).
El mismo conjunto de rasgos de configuración e implementaciones se puede utilizar para crear un sistema que consta de dos nodos separados :
Configuración para dos nodos object NodeServerConfig extends EchoConfig[String] with SigTermLifecycleConfig { type NodeId = NodeIdImpl def nodeId = NodeServer override def portNumber: PortNumber = 8080 } object NodeClientConfig extends EchoClientConfig[String] with FiniteDurationLifecycleConfig {
Importante! Observe cómo se realiza el enlace del servicio. Indicamos el servicio implementado por un nodo como la implementación del método de dependencia de otro nodo. El compilador verifica el tipo de dependencia, porque contiene el tipo de protocolo. Cuando se inicia, la dependencia contendrá el identificador correcto del nodo de destino. Gracias a este esquema, indicamos el número de puerto exactamente una vez y siempre garantizamos que se refieren al puerto correcto.
Implementación de dos nodos del sistema.Para esta configuración, utilizamos la misma implementación de servicio sin cambios. La única diferencia es que ahora tenemos dos objetos que implementan diferentes conjuntos de servicios:
object TwoJvmNodeServerImpl extends ZeroServiceImpl[IO] with EchoServiceService with SigIntLifecycleServiceImpl { type Config = EchoConfig[String] with SigTermLifecycleConfig } object TwoJvmNodeClientImpl extends ZeroServiceImpl[IO] with EchoClientService with FiniteDurationLifecycleServiceImpl { type Config = EchoClientConfig[String] with FiniteDurationLifecycleConfig }
El primer nodo implementa el servidor y solo necesita la configuración del servidor. El segundo nodo lo implementa el cliente y utiliza otra parte de la configuración. Ambos nodos también necesitan administrar el tiempo de vida. El nodo del servidor se ejecuta indefinidamente hasta que SIGTERM lo detiene y el nodo del cliente termina después de un tiempo. Ver la aplicación de lanzamiento .
Proceso de desarrollo general
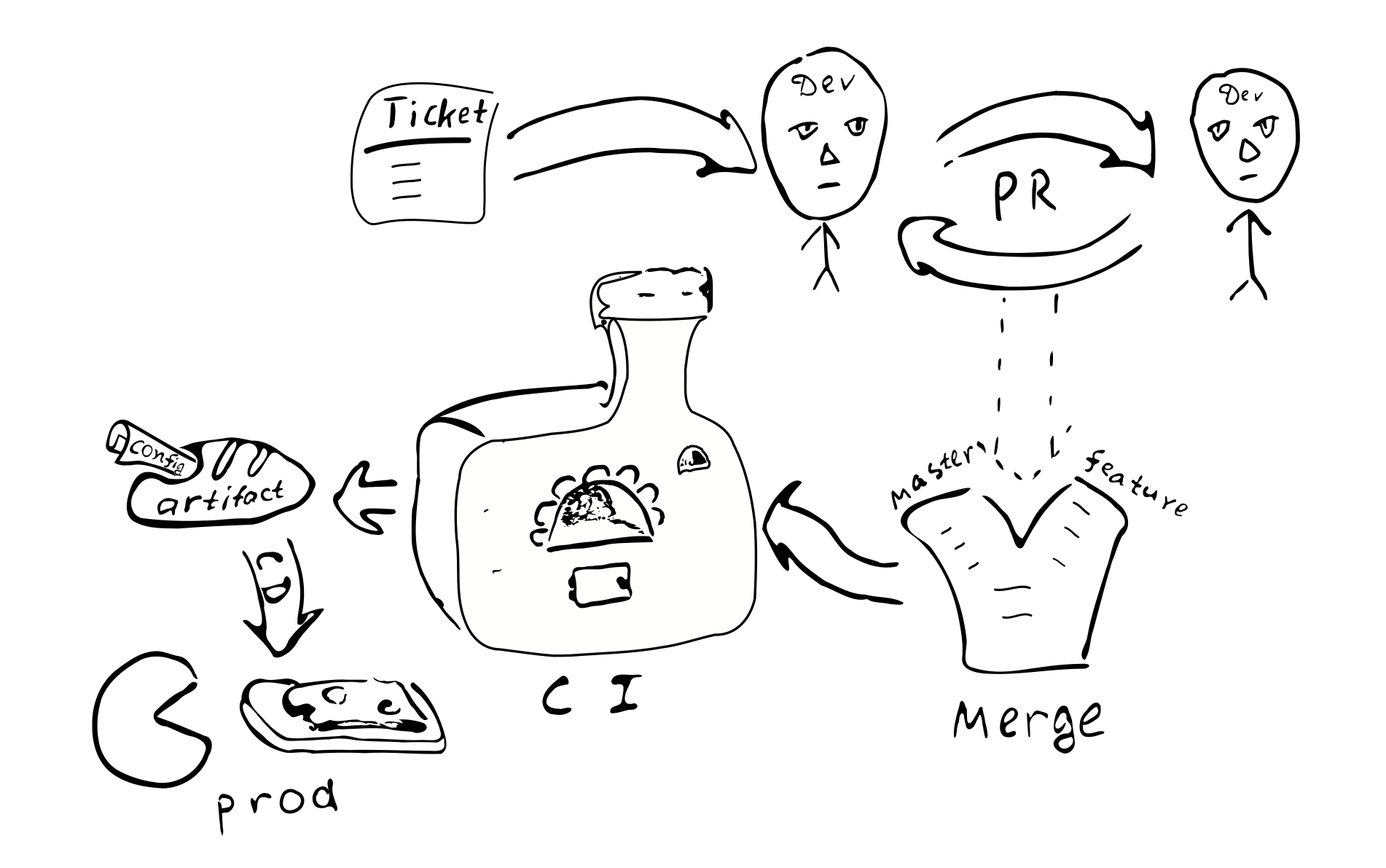
Veamos cómo este enfoque de configuración afecta el proceso de desarrollo general.
La configuración se compilará junto con el resto del código y se generará un artefacto (.jar). Aparentemente, tiene sentido colocar la configuración en un artefacto separado. Esto se debe al hecho de que podemos tener muchas configuraciones basadas en el mismo código. Nuevamente, puede generar artefactos que corresponden a diferentes ramas de configuración. Junto con la configuración, se preservan las dependencias de versiones específicas de las bibliotecas y estas versiones se conservan para siempre, siempre que decidamos implementar esta versión de la configuración.
Cualquier cambio de configuración se convierte en un cambio de código. Y por lo tanto, cada uno de estos
El cambio estará cubierto por el proceso habitual de garantía de calidad:
Un ticket en el bugtracker -> PR -> review -> fusionarse con las ramas correspondientes ->
integración -> despliegue
Las principales consecuencias de implementar una configuración compilada:
La configuración se coordinará en todos los nodos del sistema distribuido. Debido al hecho de que todos los nodos reciben la misma configuración de una sola fuente.
Es problemático cambiar la configuración en solo uno de los nodos. Por lo tanto, la "deriva de configuración" es poco probable.
Se hace más difícil hacer pequeños cambios de configuración.
La mayoría de los cambios de configuración ocurrirán como parte del proceso de desarrollo general y serán revisados.
¿Necesito un repositorio separado para almacenar la configuración de producción? Dicha configuración puede contener contraseñas y otra información secreta, cuyo acceso nos gustaría restringir. En base a esto, parece tener sentido almacenar la configuración final en un repositorio separado. Puede dividir la configuración en dos partes: una que contiene la configuración de configuración pública y la otra que contiene la configuración de acceso restringido. Esto permitirá que la mayoría de los desarrolladores tengan acceso a parámetros comunes. Esta separación es fácil de lograr utilizando rasgos intermedios que contienen valores predeterminados.
Posibles variaciones
Intentemos comparar la configuración compilada con algunas alternativas comunes:
- Un archivo de texto en la máquina de destino.
- Almacenamiento centralizado de valor clave (
etcd / zookeeper ). - Componentes de proceso que se pueden reconfigurar / reiniciar sin reiniciar el proceso.
- Almacenamiento de la configuración fuera del control de artefactos y versiones.
Los archivos de texto proporcionan una flexibilidad significativa en términos de pequeños cambios. El administrador del sistema puede ir al nodo remoto, realizar cambios en los archivos correspondientes y reiniciar el servicio. Sin embargo, para sistemas grandes, tal flexibilidad puede ser indeseable. De los cambios realizados no hay rastros en otros sistemas. Nadie revisa los cambios. Es difícil establecer quién realizó los cambios y por qué motivo. Los cambios no se prueban. Si el sistema está distribuido, el administrador puede olvidarse de hacer el cambio correspondiente en otros nodos.
(También se debe tener en cuenta que el uso de una configuración compilada no bloquea la posibilidad de usar archivos de texto en el futuro. Será suficiente agregar un analizador y validador que proporcione el mismo tipo de Config como salida, y puede usar archivos de texto. De inmediato se deduce que la complejidad del sistema con la configuración compilada es algo menos que la complejidad de un sistema que usa archivos de texto, porque los archivos de texto requieren código adicional).
El almacenamiento centralizado de valores clave es un buen mecanismo para distribuir metaparámetros de una aplicación distribuida. Deberíamos decidir qué parámetros de configuración son y cuáles son solo datos. Supongamos que tenemos una función C => A => B , con los parámetros C rara vez cambiando, y los datos A menudo. En este caso, podemos decir que C son los parámetros de configuración y A son los datos. Parece que los parámetros de configuración difieren de los datos en que generalmente cambian con menos frecuencia que los datos. Además, los datos generalmente provienen de una fuente (del usuario) y los parámetros de configuración de otra (del administrador del sistema).
Si los parámetros que cambian raramente necesitan actualizarse sin reiniciar el programa, esto a menudo puede llevar a una complicación del programa, porque tendremos que entregar de alguna manera los parámetros, almacenar, analizar y verificar, procesar valores incorrectos. Por lo tanto, desde el punto de vista de reducir la complejidad del programa, tiene sentido reducir la cantidad de parámetros que pueden cambiar durante el programa (o no admitir dichos parámetros).
Desde el punto de vista de esta publicación, distinguiremos entre parámetros estáticos y dinámicos. Si la lógica del servicio requiere cambiar los parámetros durante el programa, llamaremos dinámicos a dichos parámetros. De lo contrario, los parámetros son estáticos y se pueden configurar mediante una configuración compilada. Para la reconfiguración dinámica, es posible que necesitemos un mecanismo para reiniciar partes del programa con nuevos parámetros, similar a cómo se reinician los procesos del sistema operativo. (En nuestra opinión, es recomendable evitar la reconfiguración en tiempo real, ya que la complejidad del sistema aumenta. Si es posible, es mejor utilizar las capacidades estándar del sistema operativo para reiniciar los procesos).
Un aspecto importante del uso de una configuración estática que obliga a las personas a considerar la reconfiguración dinámica es el tiempo que tarda el sistema en reiniciarse después de una actualización de la configuración (tiempo de inactividad). De hecho, si necesitamos hacer cambios en la configuración estática, tendremos que reiniciar el sistema para que los nuevos valores surtan efecto. El problema del tiempo de inactividad tiene una gravedad diferente para diferentes sistemas. En algunos casos, puede programar un reinicio en un momento en que la carga sea mínima. Si desea proporcionar un servicio continuo, puede implementar las "conexiones de drenaje" (drenaje de conexión de AWS ELB) . Al mismo tiempo, cuando necesitamos reiniciar el sistema, lanzamos una instancia paralela de este sistema, cambiamos el balanceador y esperamos hasta que se completen las conexiones anteriores. Después de que se hayan completado todas las conexiones anteriores, apagamos la instancia del sistema anterior.
Consideremos ahora el problema de almacenar la configuración dentro o fuera del artefacto. Si almacenamos la configuración dentro del artefacto, al menos tuvimos la oportunidad durante el ensamblaje del artefacto para asegurarnos de que la configuración fuera correcta. Si la configuración está fuera del artefacto controlado, es difícil rastrear quién y por qué realizó cambios en este archivo. ¿Qué tan importante es esto? En nuestra opinión, para muchos sistemas de producción es importante tener una configuración estable y de alta calidad.
La versión del artefacto le permite determinar cuándo se creó, qué valores contiene, qué funciones están habilitadas / deshabilitadas, quién es responsable de cualquier cambio en la configuración. Por supuesto, almacenar la configuración dentro del artefacto requiere algo de esfuerzo, por lo que debe tomar una decisión informada.
Los pros y contras
Me gustaría hacer hincapié en los pros y los contras de la tecnología propuesta.
Los beneficios
La siguiente es una lista de las características principales de una configuración de sistema distribuido compilado:
- Comprobación de configuración estática. Le permite estar seguro de que
La configuración es correcta. - . . Scala , . ,
trait' , , val', (DRY) . ( Seq , Map , ). - DSL. Scala , DSL. , , , . , , .
- . , , , , . , . , .
- . , , .
- . , .
- . , . . ( , , , , -.) — . , , , , .
- . , . , , . . . , production'.
- . , . , , — . production- .
- Pruebas mock-, , .
- . . , , , .
. :
- . production', . . . .
- . , , .
- . , , . / .
- . DevOps . .
- . (CI/CD). .
, :
- , , . , Cake Pattern' , ,
HList (case class') . - , : (
package , import , ; override def ' , ). , DSL. , (, XML), . - .
Conclusión
Scala. xml- . , Scala, ( Kotlin, C#, Swift, ...). , , , , , .
, . .
:
- .
- DSL .
- . , , (1) ; (2) .
, .