Hola a todos, estamos compartiendo con ustedes la segunda parte de la publicación "Sistemas de archivos virtuales en Linux: ¿por qué son necesarios y cómo funcionan?" La primera parte se puede leer
aquí . Recuerde que esta serie de publicaciones está dedicada al lanzamiento de un nuevo hilo en el curso de
Administrador de Linux , que comenzará muy pronto.
Cómo ver VFS con herramientas eBPF y bccLa forma más fácil de comprender cómo funciona el núcleo en los archivos
sysfs es mirarlo en la práctica, y la forma más fácil de observar ARM64 es usar eBPF. eBPF (abreviatura de Berkeley Packet Filter) consiste en una máquina virtual que se ejecuta en el
núcleo que los usuarios privilegiados pueden
query desde la línea de comandos. Las fuentes del núcleo le dicen al lector lo que el núcleo puede hacer; Ejecutar herramientas eBPF en un sistema ocupado muestra lo que el núcleo hace realmente.

Afortunadamente, comenzar a usar eBPF es bastante fácil con las herramientas
bcc , que están disponibles como paquetes de la
distribución general de Linux y están documentadas en detalle por
Bernard Gregg .
bcc herramientas
bcc son scripts de Python con pequeñas inserciones de código C, lo que significa que cualquiera que esté familiarizado con ambos lenguajes puede modificarlos fácilmente. Hay 80 scripts de Python en
bcc/tools , lo que significa que lo más probable es que el desarrollador o administrador del sistema pueda elegir algo adecuado para resolver el problema.
Para tener una idea superficial de lo que hace VFS en un sistema en ejecución, pruebe
vfscount o
vfsstat . Esto mostrará, por ejemplo, que docenas de llamadas a
vfs_open() y "sus amigos" ocurren literalmente cada segundo.
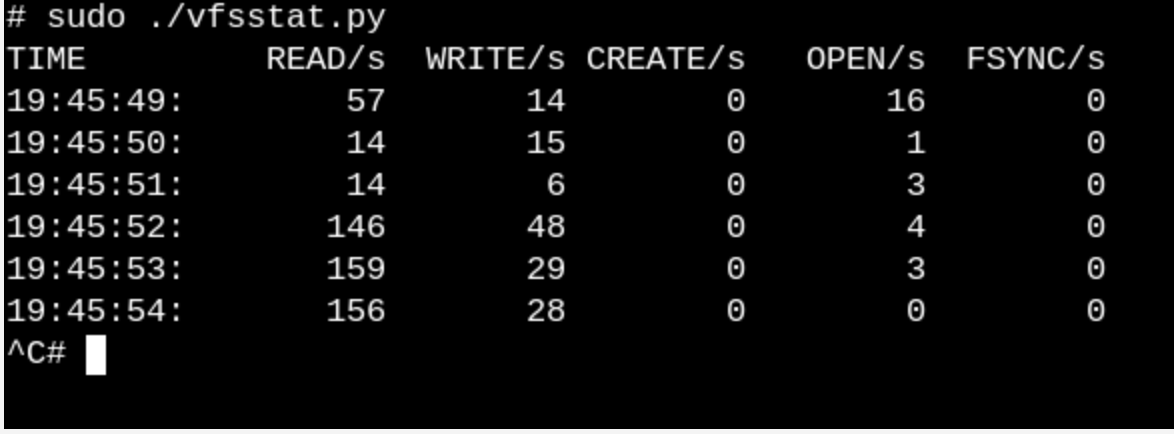
vfsstat.py es un script de Python con inserciones de código C que simplemente cuenta las llamadas a funciones VFS.
Damos un ejemplo más trivial y vemos qué sucede cuando insertamos una unidad flash USB en una computadora y el sistema la detecta.
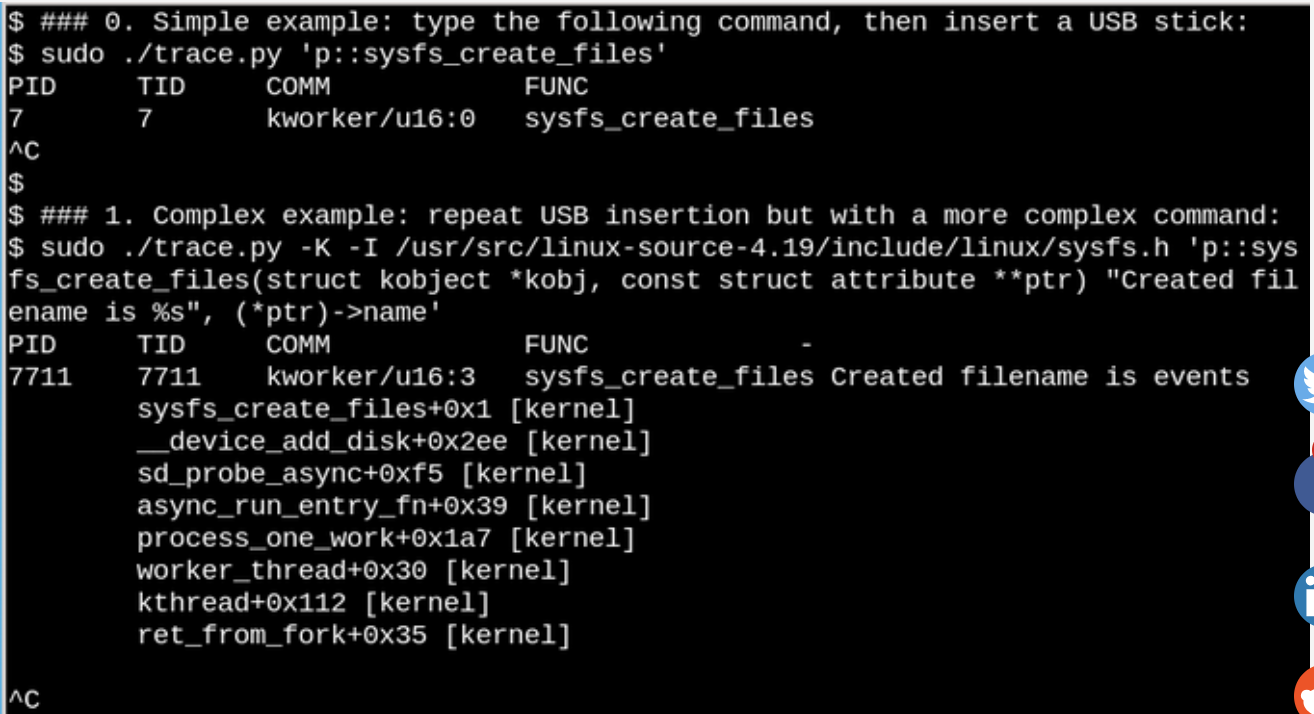
Con eBPF, puede ver lo que sucede en /sys cuando se inserta una unidad flash USB. Aquí se muestra un ejemplo simple y complejo.
En el ejemplo anterior, la herramienta
bcc trace.py muestra un mensaje cuando se
sysfs_create_files() comando
sysfs_create_files() . Vemos que
sysfs_create_files() se lanzó utilizando la secuencia de
kworker en respuesta a la unidad flash que se está insertando, pero ¿qué archivo se creó? El segundo ejemplo muestra todo el poder de eBPF. Aquí
trace.py muestra la
trace.py del núcleo (opción -K) y el nombre del archivo creado por
sysfs_create_files() . La inserción de una sola declaración es un código C que incluye una cadena de formato fácilmente reconocible proporcionada por un script Python que ejecuta el compilador LLVM
justo a tiempo . Compila y ejecuta esta línea en una máquina virtual dentro del núcleo. La firma completa de la función
sysfs_create_files () debe reproducirse en el segundo comando para que la cadena de formato pueda hacer referencia a uno de los parámetros. Los errores en este fragmento de código C dan como resultado errores reconocibles del compilador de C. Por ejemplo, si omite la opción -l, verá "Error al compilar el texto BPF". Los desarrolladores que estén familiarizados con C y Python encontrarán que las herramientas
bcc fáciles de expandir y modificar.
Cuando se inserta una unidad USB, un
kworker núcleo mostrará que PID 7711 es la secuencia de
kworker que creó el archivo de
«events» en
sysfs . En consecuencia, una llamada con
sysfs_remove_files() mostrará que al eliminar la unidad se ha eliminado el archivo de
events , que está en línea con el concepto general de conteo de referencias. Al mismo tiempo, ver
sysfs_create_link () con eBPF mientras inserta una unidad USB mostrará que se crean al menos 48 enlaces simbólicos.
Entonces, ¿cuál es el significado del archivo de eventos? El uso de
cscope para buscar
__device_add_disk () muestra que llama a
disk_add_events () , y se puede escribir
"media_change" o
"eject_request" en el archivo de evento. Aquí, la capa de bloque del núcleo informa al espacio de usuario de la apariencia y extracción del "disco". Tenga en cuenta cuán informativo es este método de investigación con el ejemplo de insertar una unidad USB en comparación con tratar de descubrir cómo funciona todo, exclusivamente desde la fuente.
Los sistemas de archivos raíz de solo lectura permiten dispositivos integradosPor supuesto, nadie apaga el servidor o su computadora, desconectando el enchufe. Pero por que? Y todo porque los sistemas de archivos montados en dispositivos de almacenamiento físico pueden tener registros pendientes, y las estructuras de datos que registran su estado pueden no estar sincronizadas con los registros en el almacenamiento. Cuando esto sucede, los propietarios del sistema tienen que esperar al próximo arranque para ejecutar la utilidad de
fsck filesystem-recovery y, en el peor de los casos, perder datos.
Sin embargo, todos sabemos que muchos dispositivos IoT, así como enrutadores, termostatos y automóviles ahora están ejecutando Linux. Muchos de estos dispositivos prácticamente no tienen interfaz de usuario, y no hay forma de apagarlos "limpiamente". Imagínese arrancar un automóvil con una batería descargada, cuando la potencia del dispositivo de control en
Linux sube y baja constantemente. ¿Cómo es que el sistema arranca sin un
fsck largo cuando el motor finalmente comienza a funcionar? Y la respuesta es simple. Los dispositivos integrados se basan en un sistema de archivos raíz de solo lectura (abreviado como
ro-rootfs (sistema de archivos raíz de solo lectura)).
ro-rootfs ofrece muchos beneficios que son menos obvios que los genuinos. Una ventaja es que el malware no puede escribir en
/usr o
/lib si ningún proceso de Linux puede escribir allí. Otra es que un sistema de archivos en gran parte inmutable es crítico para el soporte de campo para dispositivos remotos, ya que el personal de soporte utiliza sistemas locales que son nominalmente idénticos a los sistemas locales. Quizás la ventaja más importante (pero también la más insidiosa) es que ro-rootfs obliga a los desarrolladores a decidir qué objetos del sistema no cambiarán, incluso en la etapa de diseño del sistema. Trabajar con ro-rootfs puede ser incómodo y doloroso, como suele ser el caso con las variables constantes en los lenguajes de programación, pero sus beneficios pueden cubrir fácilmente la sobrecarga adicional.
Crear
rootfs solo
rootfs requiere un esfuerzo adicional para los desarrolladores integrados, y ahí es donde VFS entra en escena. Linux requiere que los archivos en
/var sean editables, y además, muchas aplicaciones populares que ejecutan sistemas embebidos intentarán crear
dot-files configuración en
$HOME . Una de las soluciones para los archivos de configuración en el directorio de inicio suele ser su generación y ensamblaje preliminar en
rootfs . Para
/var uno de los enfoques posibles es montarlo en una sección separada que se pueda escribir, mientras que
/ mount en sí es de solo lectura. Otra alternativa popular es usar montajes de unión o superposición.
Monturas enlazables y superpuestas, su uso por contenedoresLa ejecución del comando
man mount es la mejor manera de aprender acerca de los montajes mapeados y superpuestos que brindan a los desarrolladores y administradores del sistema la capacidad de crear un sistema de archivos de una manera y luego proporcionarlo a las aplicaciones de otra. Para los sistemas integrados, esto significa la capacidad de almacenar archivos en
/var en una unidad flash de solo lectura, pero superponer o vincular la ruta de
tmpfs a
/var en el arranque permitirá que las aplicaciones escriban notas allí (garabato). La próxima vez que lo habilite, los cambios en
/var se perderán. Un montaje superpuesto crea una unión entre
tmpfs y el sistema de archivos subyacente y le permite modificar supuestamente los archivos existentes en
ro-tootf mientras que un montaje vinculado puede hacer que las nuevas carpetas
tmpfs vacías sean visibles como grabables en
ro-rootfs rutas de
ro-rootfs . Si bien
overlayfs es el tipo
proper de sistema de archivos, los montajes de enlace se implementan en el
espacio de nombres VFS .
Según la descripción de los montajes superpuestos y vinculados, a nadie le sorprende que
los contenedores de Linux los utilicen activamente. Observemos lo que sucede cuando usamos
systemd-nspawn para iniciar el contenedor con la herramienta
mountsnoop .

Una llamada a
system-nspawn inicia el contenedor mientras se
mountsnoop.py .
Veamos que pasó:
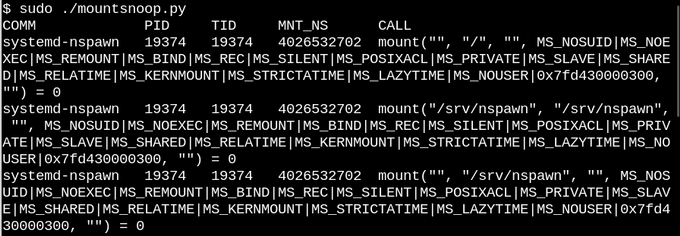
La ejecución de
mountsnoop durante el "arranque" del contenedor indica que el tiempo de ejecución del contenedor depende en gran medida del montaje que se está conectando (solo se muestra el comienzo de la salida larga).
Aquí,
systemd-nspawn proporciona los archivos seleccionados en los
procfs y
sysfs host al contenedor como rutas a sus
rootfs . Además del indicador
MS_BIND , que establece el montaje de enlace, algunos otros indicadores en el sistema montado determinan la relación entre los cambios en el espacio de nombres del host y el contenedor. Por ejemplo, un montaje vinculante puede omitir los cambios en
/proc y
/sys en un contenedor u ocultarlos según la llamada.
ConclusiónComprender la estructura interna de Linux puede parecer una tarea imposible, ya que el núcleo en sí contiene una gran cantidad de código, dejando a un lado las aplicaciones de espacio de usuario de Linux y las interfaces de llamada del sistema en bibliotecas C como
glibc . Una forma de avanzar es leer el código fuente de un subsistema del núcleo con énfasis en comprender las llamadas y encabezados del sistema que se enfrentan al espacio del usuario, así como las principales interfaces internas del núcleo, por ejemplo, la tabla
file_operations . Las operaciones de archivo proporcionan el principio de "todo es un archivo", por lo que administrarlas es especialmente agradable. Los archivos del núcleo de origen C en el directorio de nivel superior
fs/ representan la implementación de sistemas de archivos virtuales, que son una capa de shell que proporciona una compatibilidad amplia y relativamente simple de los sistemas de archivos y dispositivos de almacenamiento populares. El montaje con enlace y superposición a través de espacios de nombres de Linux es la magia de VFS que hace posible crear contenedores de solo lectura y sistemas de archivos raíz. En combinación con el aprendizaje del código fuente, la herramienta básica eBPF y su interfaz
bcchacer que la investigación de kernel sea más fácil que nunca.
Amigos, escribir este artículo fue útil para ustedes? Tal vez tienes algún comentario o comentarios? Y aquellos que estén interesados en el curso de Administrador de Linux, los invitamos a la
jornada de puertas abiertas , que tendrá lugar el 18 de abril.
La primera parte