La industria se ha centrado en acelerar la multiplicación de matrices, pero mejorar el algoritmo de búsqueda puede conducir a un aumento más serio en el rendimiento

En los últimos años, la industria de la computación ha estado ocupada tratando de acelerar los cálculos necesarios para las redes neuronales artificiales, tanto para el entrenamiento como para sacar conclusiones de su trabajo. En particular, se hizo un gran esfuerzo en el desarrollo de hierro especial sobre el cual se pueden realizar estos cálculos. Google desarrolló la
Unidad de procesamiento de tensor , o TPU, que se
presentó por primera
vez al público en 2016. Posteriormente, Nvidia presentó la Unidad de procesamiento de gráficos
V100 , describiéndola como un chip diseñado específicamente para la capacitación y el uso de IA, así como para otras necesidades informáticas de alto rendimiento. Lleno de otras startups, concentrándose en otros tipos de
aceleradores de
hardware .
Quizás todos cometen un gran error.
Esta idea se expresó en el
trabajo , que apareció a mediados de marzo en el sitio arXiv. En ella, sus autores,
Beidi Chen ,
Tarun Medini y
Anshumali Srivastava de la Universidad de Rice, sostienen que quizás el equipo especial desarrollado para el funcionamiento de las redes neuronales se está optimizando para el algoritmo incorrecto.
La cuestión es que el trabajo de las redes neuronales generalmente depende de la rapidez con que el equipo puede realizar la multiplicación de las matrices utilizadas para determinar los parámetros de salida de cada neutrón artificial, su "activación", para un conjunto dado de valores de entrada. Las matrices se usan porque cada valor de entrada para una neurona se multiplica por el parámetro de peso correspondiente, y luego se suman, y esta multiplicación con la suma es la operación básica de la multiplicación de matrices.
Los investigadores de la Universidad de Rice, como algunos otros científicos, se dieron cuenta de que la activación de muchas neuronas en una capa particular de la red neuronal es demasiado pequeña y no afecta el valor de salida calculado por las capas posteriores. Por lo tanto, si sabe cuáles son estas neuronas, simplemente puede ignorarlas.
Puede parecer que la única forma de descubrir qué neuronas en una capa no están activadas es realizar primero todas las operaciones de multiplicación de matrices para esta capa. Pero los investigadores se dieron cuenta de que en realidad puedes decidir sobre esta forma más eficiente si miras el problema desde un ángulo diferente. "Enfocamos este problema como una solución al problema de búsqueda", dice Srivastava.
Es decir, en lugar de calcular las multiplicaciones de la matriz y observar qué neuronas se activaron para una entrada determinada, puede ver qué tipo de neuronas hay en la base de datos. La ventaja de este enfoque en el problema es que puede usar una estrategia generalizada que los científicos informáticos han mejorado durante mucho tiempo para acelerar la búsqueda de datos en la base de datos: hashing.
Hashing le permite verificar rápidamente si hay un valor en la tabla de la base de datos, sin tener que pasar por cada fila en una fila. Utiliza un hash, que se calcula fácilmente aplicando una función hash al valor deseado, que indica dónde se debe almacenar este valor en la base de datos. Luego puede verificar solo un lugar para averiguar si este valor está almacenado allí.
Los investigadores hicieron algo similar para los cálculos relacionados con las redes neuronales. El siguiente ejemplo ayudará a ilustrar su enfoque:
Supongamos que hemos creado una red neuronal que reconoce la entrada manuscrita de números. Suponga que la entrada es píxeles grises en una matriz de 16x16, es decir, un total de 256 números. Alimentamos estos datos a una capa oculta de 512 neuronas, cuyos resultados de activación son alimentados por la capa de salida de 10 neuronas, una para cada uno de los números posibles.
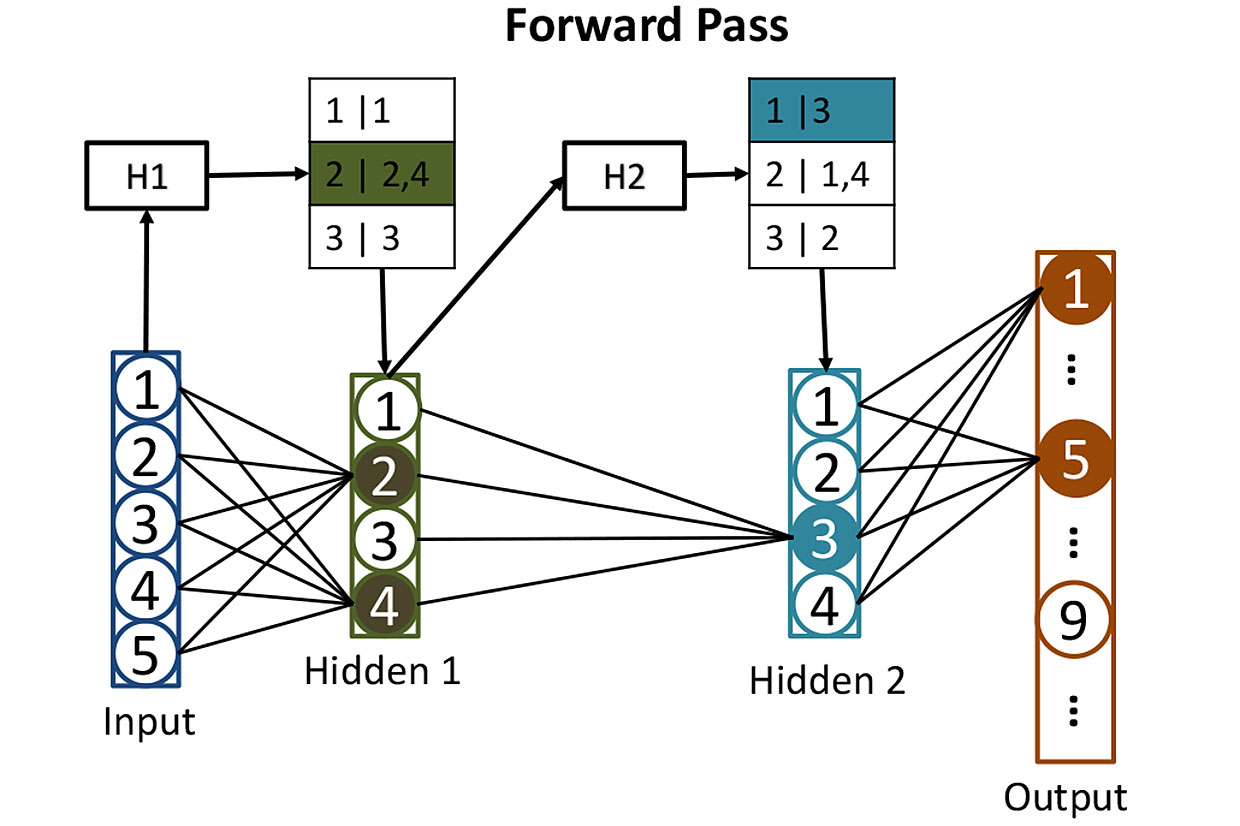 Tablas de redes: antes de calcular la activación de las neuronas en capas ocultas, usamos hashes para ayudarnos a determinar qué neuronas se activarán. Aquí, el hash de los valores de entrada H1 se usa para buscar las neuronas correspondientes en la primera capa oculta; en este caso, serán las neuronas 2 y 4. El segundo hash H2 muestra qué neuronas de la segunda capa oculta contribuirán. Dicha estrategia reduce la cantidad de activaciones que deben calcularse.
Tablas de redes: antes de calcular la activación de las neuronas en capas ocultas, usamos hashes para ayudarnos a determinar qué neuronas se activarán. Aquí, el hash de los valores de entrada H1 se usa para buscar las neuronas correspondientes en la primera capa oculta; en este caso, serán las neuronas 2 y 4. El segundo hash H2 muestra qué neuronas de la segunda capa oculta contribuirán. Dicha estrategia reduce la cantidad de activaciones que deben calcularse.Es bastante difícil entrenar una red de este tipo, pero por ahora omita este momento e imagine que ya hemos ajustado todos los pesos de cada neurona para que la red neuronal reconozca perfectamente los números escritos a mano. Cuando un número escrito legiblemente llega a su entrada, la activación de una de las neuronas de salida (correspondiente a este número) estará cerca de 1. La activación de las otras nueve estará cerca de 0. Clásicamente, el funcionamiento de dicha red requiere una multiplicación de matriz para cada una de 512 neuronas ocultas, y uno más para cada fin de semana, lo que nos da muchas multiplicaciones.
Los investigadores toman un enfoque diferente. El primer paso es calcular los pesos de cada una de las 512 neuronas en la capa oculta utilizando "hashing sensible a la localidad", una de cuyas propiedades es que los datos de entrada similares dan valores de hash similares. Luego puede agrupar las neuronas con hashes similares, lo que significaría que estas neuronas tienen conjuntos de pesos similares. Cada grupo puede almacenarse en una base de datos y determinarse por el hash de los valores de entrada que conducirán a la activación de este grupo de neuronas.
Después de todo este hashing, resulta fácil determinar qué neuronas ocultas se activarán mediante alguna nueva entrada. Debe ejecutar 256 valores de entrada a través de funciones hash calculadas fácilmente y usar el resultado para buscar en la base de datos las neuronas que se activarán. De esta forma, tendrá que calcular los valores de activación para solo unas pocas neuronas que importan. No es necesario calcular la activación de todas las demás neuronas en la capa solo para descubrir que no contribuyen al resultado.
La entrada de dicha red neuronal de datos puede representarse como la ejecución de una consulta de búsqueda en una base de datos que solicita encontrar todas las neuronas que se activarían por conteo directo. Obtiene la respuesta rápidamente porque usa hashes para buscar. Y luego simplemente puede calcular la activación de una pequeña cantidad de neuronas que realmente importan.
Los investigadores han utilizado esta técnica, que llamaron SLIDE (motor de aprendizaje profundo Sub-LInear), para entrenar una red neuronal, para un proceso que tiene más solicitudes computacionales de las que tiene para el propósito previsto. Luego compararon el rendimiento del algoritmo de aprendizaje con un enfoque más tradicional utilizando una GPU potente, específicamente, la GPU Nvidia V100. Como resultado, obtuvieron algo sorprendente: "Nuestros resultados muestran que, en promedio, la tecnología CPU SLIDE puede funcionar en órdenes de magnitud más rápido que la mejor alternativa posible, implementada en el mejor equipo y con cualquier precisión".
Es demasiado pronto para sacar conclusiones sobre si estos resultados (que los expertos aún no han evaluado) resistirán las pruebas y si obligarán a los fabricantes de chips a mirar de manera diferente el desarrollo de equipos especiales para el aprendizaje profundo. Pero el trabajo definitivamente enfatiza el peligro de arrastre de cierto tipo de hierro en los casos en que existe la posibilidad de un algoritmo nuevo y mejor para el funcionamiento de las redes neuronales.