Hola a todos Cada vez queda menos tiempo hasta el lanzamiento del curso
"Seguridad de los sistemas de información" , por lo que hoy continuamos compartiendo publicaciones dedicadas al lanzamiento de este curso. Por cierto, esta publicación es una continuación de estos dos artículos:
“Fundamentos de los motores de JavaScript: formularios generales y almacenamiento en caché en línea. Parte 1 " ,
" Conceptos básicos de los motores de JavaScript: formularios generales y almacenamiento en caché en línea. Parte 2 " .
El artículo describe los conceptos básicos clave. Son comunes a todos los motores de JavaScript, y no solo al
V8 en el que están trabajando los autores (
Benedict y
Matthias ). Como desarrollador de JavaScript, puedo decir que una comprensión más profunda de cómo funciona el motor de JavaScript lo ayudará a descubrir cómo escribir código eficiente.

En un
artículo anterior, discutimos cómo los motores JavaScript optimizan el acceso a objetos y matrices utilizando formularios y cachés en línea. En este artículo, veremos cómo optimizar los compromisos de la tubería y acelerar el acceso a las propiedades del prototipo.
Nota: si prefiere ver presentaciones que leer artículos, mire este video . De lo contrario, sáltelo y siga leyendo.
Niveles de optimización y compensacionesLa última vez, descubrimos que todos los motores JavaScript modernos, de hecho, tienen la misma tubería:
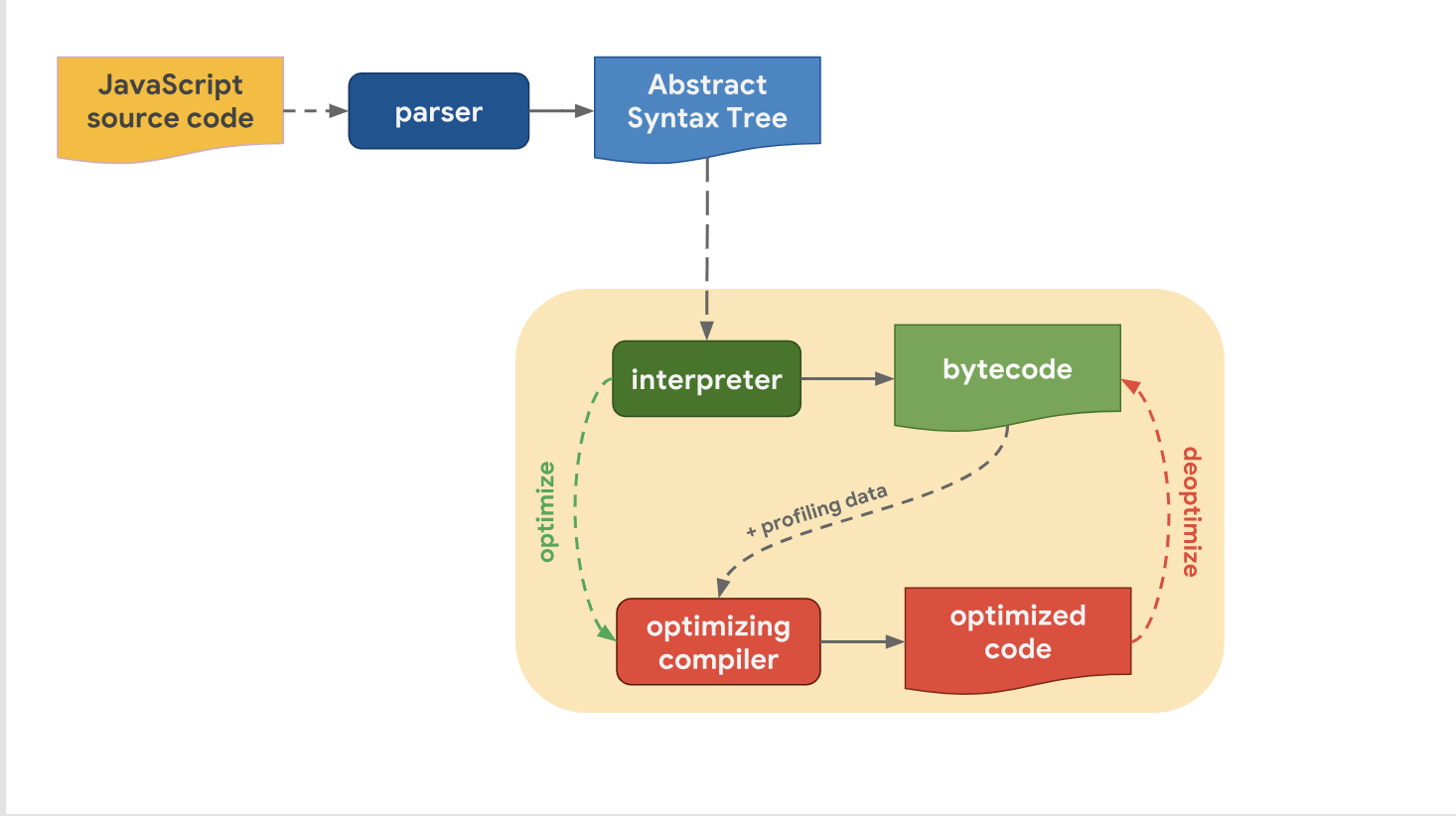
También nos dimos cuenta de que a pesar del hecho de que las tuberías de alto nivel de motor a motor son similares en estructura, hay una diferencia en la tubería de optimización. ¿Por qué es esto así? ¿Por qué algunos motores tienen más niveles de optimización que otros? La cuestión es hacer un compromiso entre una transición rápida a la etapa de ejecución del código o pasar un poco más de tiempo para ejecutar el código con un rendimiento óptimo.

El intérprete puede generar rápidamente bytecode, pero bytecode por sí solo no es lo suficientemente eficiente en términos de velocidad. Involucrar a un compilador de optimización en este proceso pasa una cierta cantidad de tiempo, pero permite un código de máquina más eficiente.
Echemos un vistazo a cómo el V8 maneja esto. Recuerde que en V8 el intérprete se llama Ignition y se considera el intérprete más rápido entre los motores existentes (en materia de velocidad de ejecución de bytecode sin formato). El compilador de optimización en V8 se llama TurboFan, y es él quien genera un código de máquina altamente optimizado.

La compensación entre el retraso de inicio y la velocidad de ejecución es la razón por la cual algunos motores de JavaScript prefieren agregar niveles de optimización adicionales entre los pasos. Por ejemplo, SpiderMonkey agrega un nivel de línea de base entre su intérprete y el compilador de optimización completo de IonMonkey:
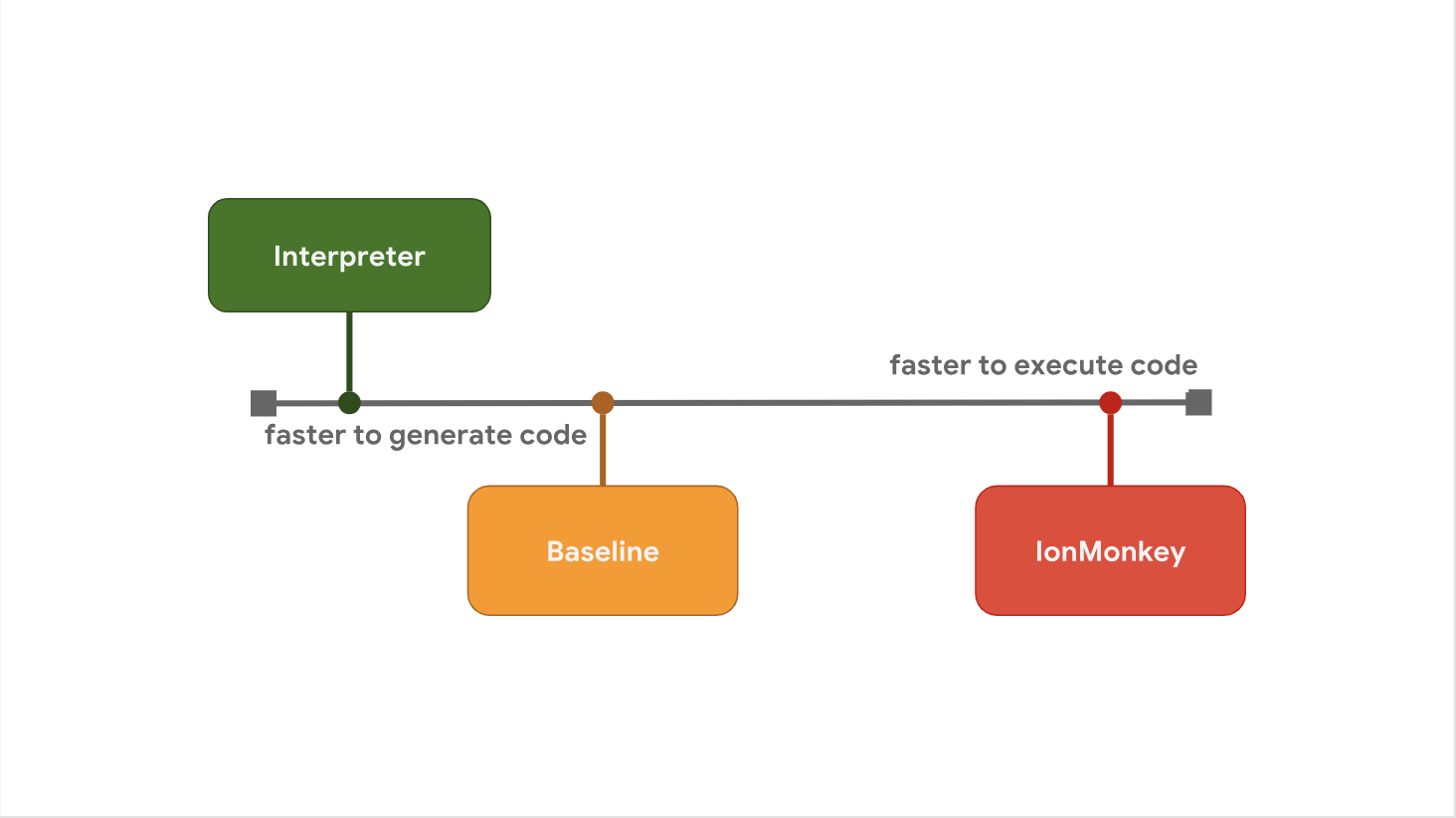
El intérprete genera rápidamente bytecode, pero el bytecode en sí es relativamente lento. La línea de base genera código un poco más, pero proporciona un rendimiento mejorado en tiempo de ejecución. Finalmente, el compilador de optimización IonMonkey pasa la mayor cantidad de tiempo generando código de máquina, pero dicho código es extremadamente eficiente.
Veamos un ejemplo específico y veamos cómo las tuberías de varios motores abordan este problema. Aquí en el bucle activo, a menudo se repite el mismo código.
let result = 0; for (let i = 0; i < 4242424242; ++i) { result += i; } console.log(result);
V8 comienza iniciando el código de bytes en el intérprete de encendido. En algún momento, el motor determina que el código está activo y lanza la interfaz TurboFan, que integra datos de creación de perfiles y crea una representación de máquina básica del código. Luego se envía al optimizador TurboFan en otro hilo para una mejora adicional.

Mientras la optimización está en curso, V8 continúa ejecutando código en Ignition. En algún momento, cuando el optimizador ha terminado y hemos recibido el código de máquina ejecutable, inmediatamente pasa a la etapa de ejecución.
SpyderMonkey también comienza la ejecución de bytecode en el intérprete. Pero tiene un nivel de línea de base adicional, lo que significa que primero se envía el código activo. El compilador de línea de base genera código de línea de base en el hilo principal y continúa la ejecución al final de su generación.

Si el código de línea de base se ha estado ejecutando durante algún tiempo, SpiderMonkey finalmente lanza la interfaz IonMonkey (interfaz IonMonkey) y ejecuta el optimizador, el proceso es muy similar al V8. Todo esto continúa funcionando al mismo tiempo en Baseline, mientras que IonMonkey se dedica a la optimización. Finalmente, cuando el optimizador termina su trabajo, se ejecuta el código optimizado en lugar del código de línea de base.
La arquitectura de Chakra es muy similar a SpiderMonkey, pero Chakra está tratando de ejecutar más procesos al mismo tiempo para evitar bloquear el hilo principal. En lugar de ejecutar cualquier parte del compilador en el hilo principal, Chakra copia el bytecode y los datos de perfil que necesita el compilador y los envía al proceso dedicado del compilador.

Cuando el código generado está listo, el motor ejecuta este código SimpleJIT en lugar del código de bytes. Lo mismo sucede con FullJIT. La ventaja de este enfoque es que la pausa que ocurre durante la copia suele ser mucho más corta que iniciar un compilador completo (frontend). Por otro lado, este enfoque tiene un inconveniente. Se basa en el hecho de que la copia heurística puede omitir alguna información que será necesaria para la optimización, por lo que podemos decir que, en cierta medida, la calidad del código se sacrifica en aras de acelerar el trabajo.
En JavaScriptCore, todos los compiladores de optimización funcionan completamente en paralelo con la ejecución básica de JavaScript. No hay fase de copia. En cambio, el hilo principal simplemente comienza a compilarse en otro hilo. Los compiladores utilizan un complejo esquema de bloqueo para acceder a los datos de creación de perfiles desde el hilo principal.

La ventaja de este enfoque es que reduce la cantidad de basura que aparece después de la optimización en el hilo principal. La desventaja de este enfoque es que requiere resolver problemas complejos de subprocesos múltiples y algunos costos de bloqueo para diversas operaciones.
Hablamos sobre las compensaciones entre la generación rápida de código mientras el intérprete está en ejecución y la generación rápida de código utilizando el compilador de optimización. Pero hay un compromiso más, y se refiere al uso de la memoria. Para ilustrarlo, escribí un programa simple de JavaScript que agrega dos números.
function add(x, y) { return x + y; } add(1, 2);
Mire el código de bytes que genera el intérprete de encendido para la función de agregar en V8.
StackCheck Ldar a1 Add a0, [0] Return
No se preocupe por el código de bytes, no es necesario que pueda leerlo. Aquí es necesario prestar atención al hecho de que contiene
solo 4 instrucciones .
Cuando el código se calienta, TurboFan genera un código de máquina altamente optimizado, que se presenta a continuación:
leaq rcx,[rip+0x0] movq rcx,[rcx-0x37] testb [rcx+0xf],0x1 jnz CompileLazyDeoptimizedCode push rbp movq rbp,rsp push rsi push rdi cmpq rsp,[r13+0xe88] jna StackOverflow movq rax,[rbp+0x18] test al,0x1 jnz Deoptimize movq rbx,[rbp+0x10] testb rbx,0x1 jnz Deoptimize movq rdx,rbx shrq rdx, 32 movq rcx,rax shrq rcx, 32 addl rdx,rcx jo Deoptimize shlq rdx, 32 movq rax,rdx movq rsp,rbp pop rbp ret 0x18
Realmente hay muchos equipos aquí, especialmente en comparación con los cuatro que vimos en el código de bytes. En general, el código de bytes es mucho más amplio que el código de máquina y, en particular, el código de máquina optimizado. Bytecode, por otro lado, es ejecutado por el intérprete, mientras que el código optimizado puede ser ejecutado directamente por el procesador.
Esta es una de las razones por las cuales los motores de JavaScript no solo "optimizan todo". Como vimos anteriormente, generar código de máquina optimizado lleva mucho tiempo y, por lo tanto, requiere más memoria.
 Para resumir:
Para resumir: La razón por la cual los motores de JavaScript tienen diferentes niveles de optimización es para encontrar un compromiso entre la generación rápida de código usando el intérprete y la generación rápida de código usando el compilador de optimización. Agregar más niveles de optimización le permite tomar decisiones más informadas, en función del costo de la complejidad y los gastos generales adicionales durante la ejecución. Además, existe una compensación entre el nivel de optimización y el uso de memoria. Es por eso que los motores de JavaScript intentan optimizar solo las funciones activas.
Optimizar el acceso a las propiedades del prototipoLa última vez hablamos sobre cómo los motores JavaScript optimizan la carga de las propiedades de los objetos mediante formularios y cachés en línea. Recuerde que los motores almacenan las formas de los objetos por separado de los valores del objeto.
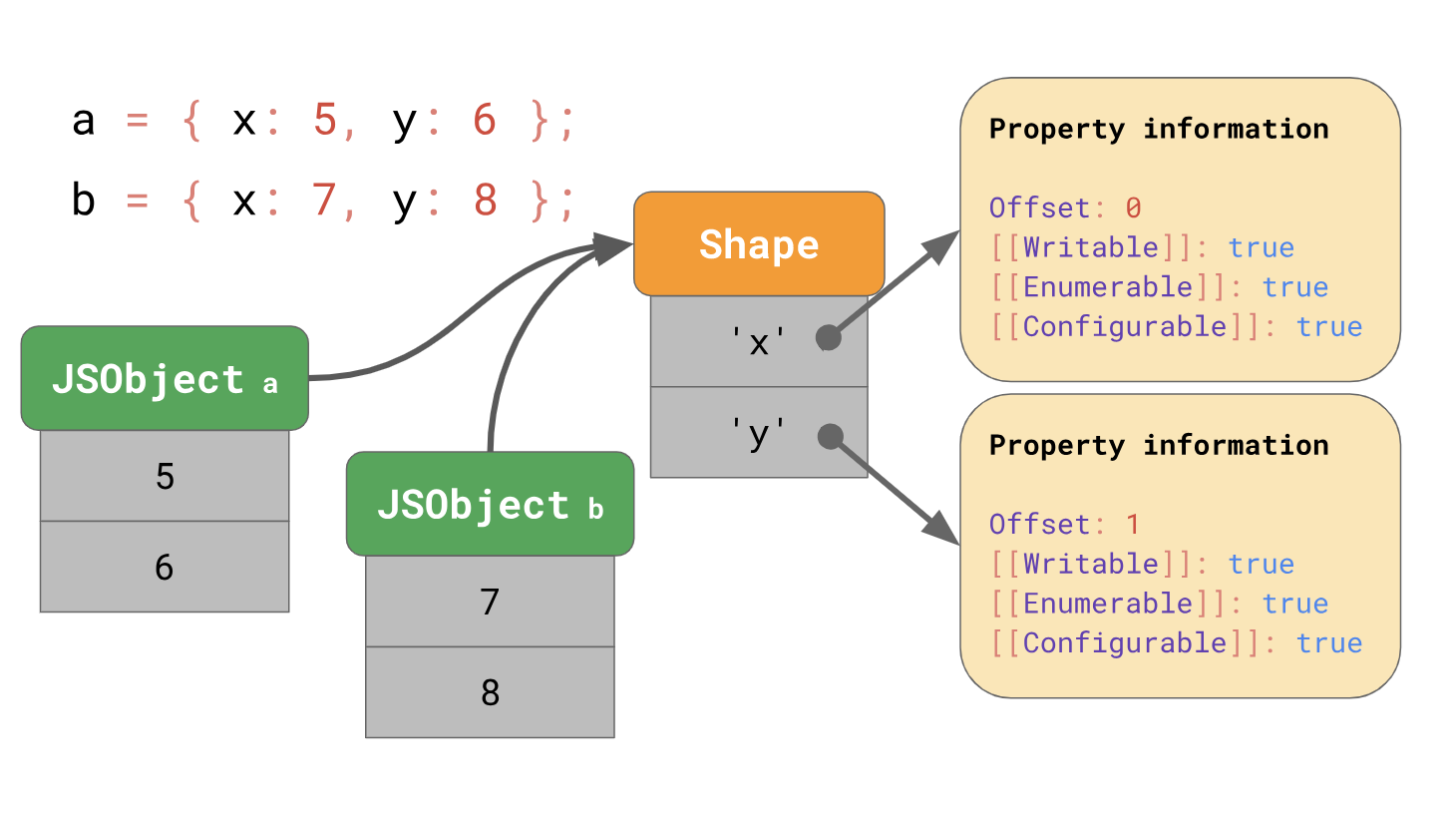
Los formularios le permiten utilizar la optimización utilizando cachés en línea o circuitos integrados abreviados. Al trabajar juntos, los formularios y los circuitos integrados pueden acelerar el acceso repetido a las propiedades desde el mismo lugar en su código.
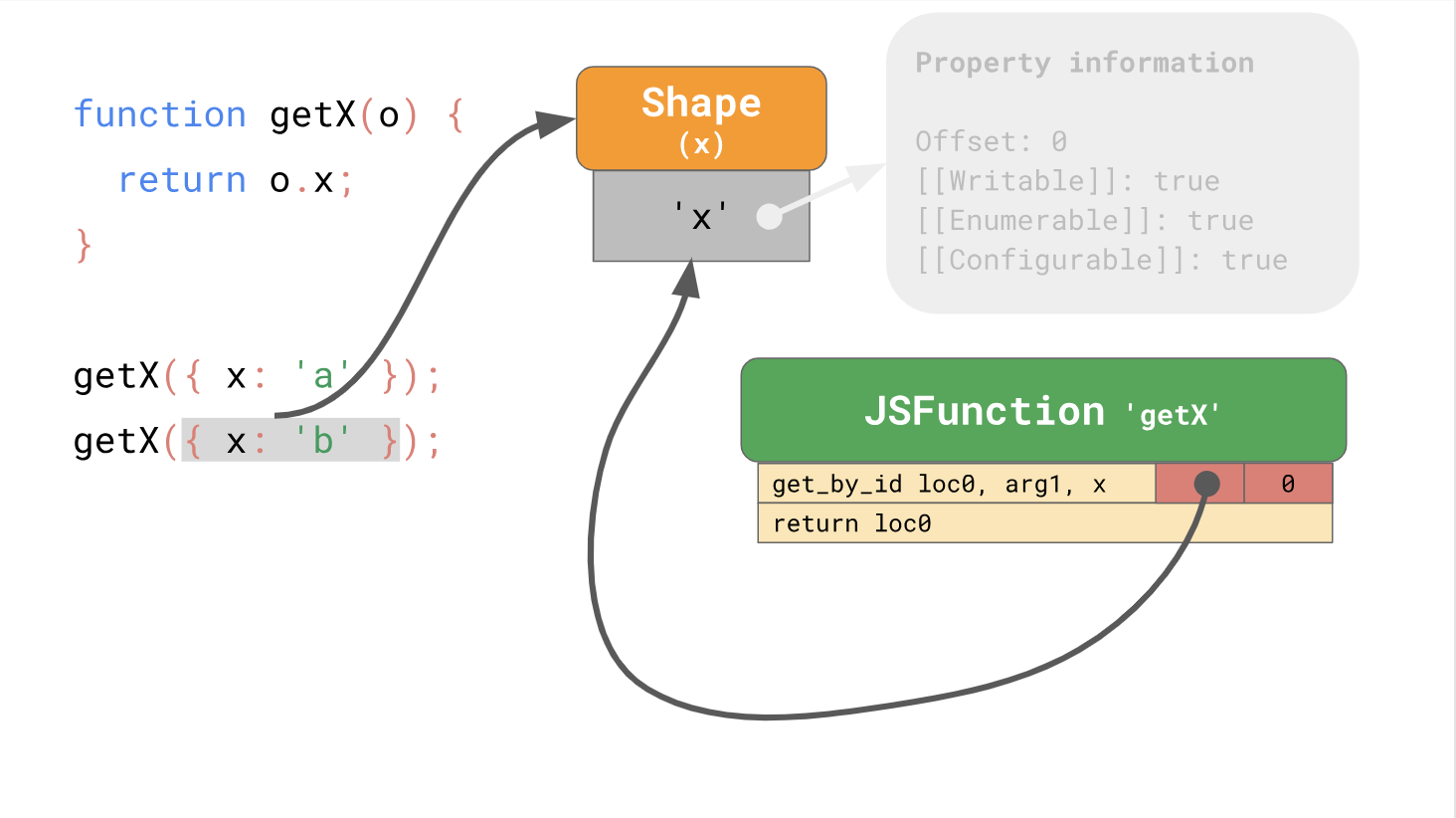
Así que la primera parte de la publicación llegó a su fin, y sobre las clases y la programación de prototipos se puede encontrar en la
segunda parte . Tradicionalmente, estamos esperando sus comentarios y discusiones tormentosas, así como lo invitamos a una
jornada de puertas abiertas en el curso "Seguridad de los sistemas de información".