Por lo general, Nginx utiliza productos comerciales o alternativas de código abierto, como Prometheus + Grafana, para monitorear y analizar el rendimiento de Nginx. Esta es una buena opción para el monitoreo o el análisis en tiempo real, pero no es demasiado conveniente para el análisis histórico. En cualquier recurso popular, la cantidad de datos de los registros de nginx está creciendo rápidamente, y es lógico usar algo más especializado para analizar una gran cantidad de datos.
En este artículo, le diré cómo usar Athena para analizar registros utilizando Nginx como ejemplo, y le mostraré cómo compilar un tablero analítico a partir de estos datos usando el marco de código abierto cube.js. Aquí está la arquitectura completa de la solución:

TL: DR;
Enlace al tablero terminado .
Utilizamos Fluentd para recopilar información, AWS Kinesis Data Firehose y AWS Glue para el procesamiento, y AWS S3 para el almacenamiento. Con este paquete, puede almacenar no solo registros de nginx, sino también otros eventos, así como registros de otros servicios. Puede reemplazar algunas partes con partes similares para su pila, por ejemplo, puede escribir registros en kinesis directamente desde nginx, omitiendo fluentd o usar logstash para hacer esto.
Recopilando registros de Nginx
Por defecto, los registros de Nginx se ven así:
4/9/2019 12:58:17 PM1.1.1.1 - - [09/Apr/2019:09:58:17 +0000] "GET /sign-up HTTP/2.0" 200 9168 "https://example.com/sign-in" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36" "-" 4/9/2019 12:58:17 PM1.1.1.1 - - [09/Apr/2019:09:58:17 +0000] "GET /sign-in HTTP/2.0" 200 9168 "https://example.com/sign-up" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36" "-"
Se pueden analizar, pero es mucho más fácil arreglar la configuración de Nginx para que muestre registros en JSON:
log_format json_combined escape=json '{ "created_at": "$msec", ' '"remote_addr": "$remote_addr", ' '"remote_user": "$remote_user", ' '"request": "$request", ' '"status": $status, ' '"bytes_sent": $bytes_sent, ' '"request_length": $request_length, ' '"request_time": $request_time, ' '"http_referrer": "$http_referer", ' '"http_x_forwarded_for": "$http_x_forwarded_for", ' '"http_user_agent": "$http_user_agent" }'; access_log /var/log/nginx/access.log json_combined;
S3 para almacenamiento
Para almacenar los registros, usaremos S3. Esto le permite almacenar y analizar los registros en un solo lugar, ya que Athena puede trabajar con datos en S3 directamente. Más adelante en el artículo, le diré cómo plegar y procesar correctamente los registros, pero primero necesitamos un cubo limpio en S3, en el que no se almacenará nada más. Vale la pena pensar de antemano en qué región creará el depósito, porque Athena no está disponible en todas las regiones.
Crea un diagrama en la consola Athena
Cree una tabla en Athena para registros. Es necesario tanto para escribir como para leer, si planea usar Kinesis Firehose. Abra la consola Athena y cree una tabla:
Creación de tablas SQL CREATE EXTERNAL TABLE `kinesis_logs_nginx`( `created_at` double, `remote_addr` string, `remote_user` string, `request` string, `status` int, `bytes_sent` int, `request_length` int, `request_time` double, `http_referrer` string, `http_x_forwarded_for` string, `http_user_agent` string) ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.orc.OrcSerde' STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat' LOCATION 's3://<YOUR-S3-BUCKET>' TBLPROPERTIES ('has_encrypted_data'='false');
Crear Kinesis Firehose Stream
Kinesis Firehose escribirá los datos recibidos de Nginx a S3 en el formato seleccionado, divididos en directorios en el formato AAAA / MM / DD / HH. Esto es útil al leer datos. Por supuesto, puede escribir directamente en S3 desde fluentd, pero en este caso debe escribir JSON, que es ineficiente debido al gran tamaño del archivo. Además, cuando se usa PrestoDB o Athena, JSON es el formato de datos más lento. Abra la consola de Kinesis Firehose, haga clic en "Crear flujo de entrega", seleccione "PUT directo" en el campo "entrega":
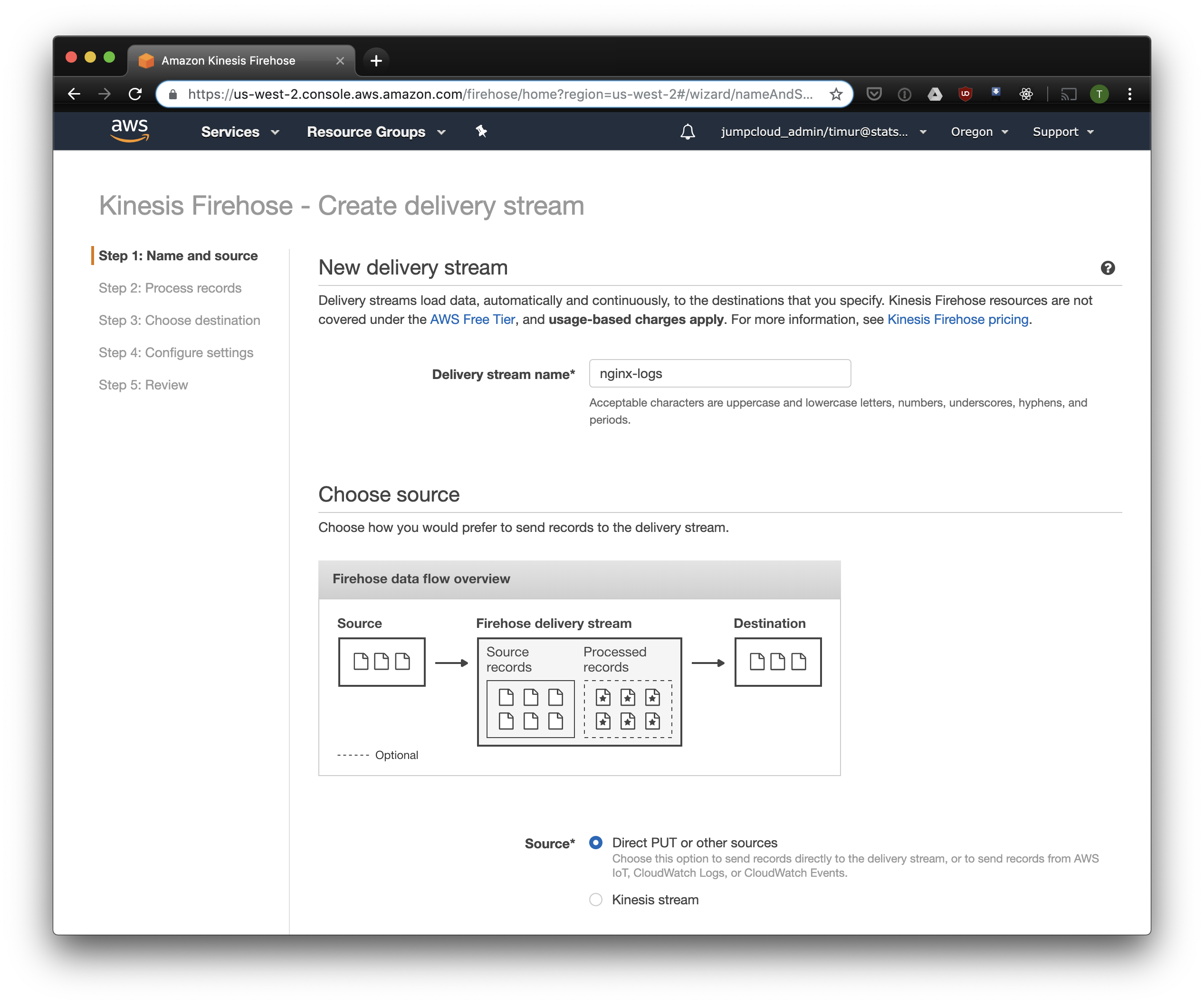
En la siguiente pestaña, seleccione "Conversión de formato de grabación" - "Activado" y seleccione "Apache ORC" como el formato para la grabación. Según algunos Owen O'Malley , este es el formato óptimo para PrestoDB y Athena. Como diagrama, indicamos la tabla que creamos arriba. Tenga en cuenta que puede especificar cualquier ubicación S3 en kinesis, solo se utiliza el esquema de la tabla. Pero si especifica otra ubicación S3, entonces leer estos registros de esta tabla no funcionará.
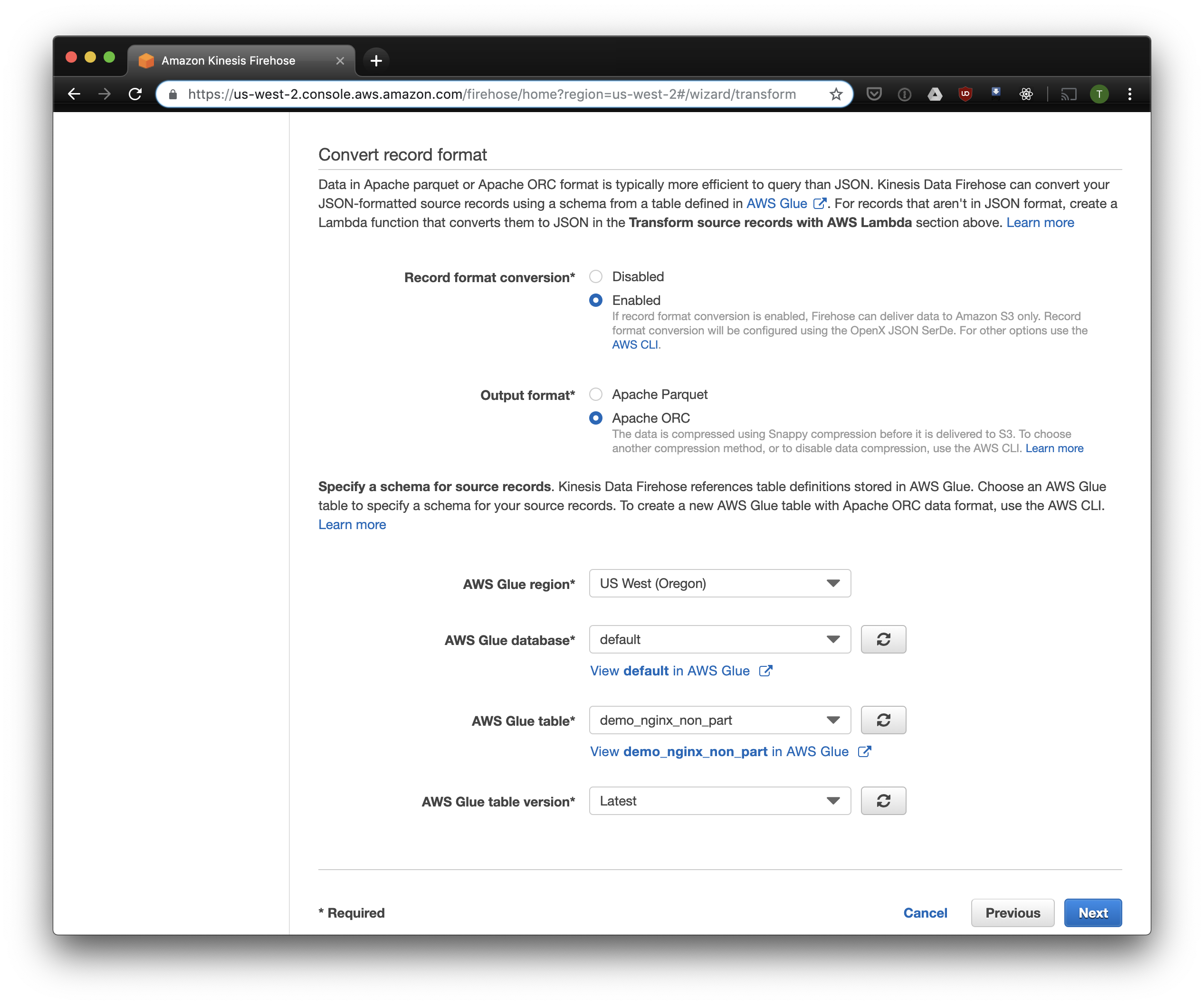
Elegimos S3 para el almacenamiento y el depósito que creamos anteriormente. Aws Glue Crawler, del que hablaré un poco más adelante, no sabe cómo trabajar con prefijos en el cubo S3, por lo que es importante dejarlo vacío.

Las opciones restantes se pueden cambiar dependiendo de su carga, por lo general uso las predeterminadas. Tenga en cuenta que la compresión S3 no está disponible, pero ORC usa la compresión nativa de forma predeterminada.
Fluido
Ahora que hemos configurado el almacenamiento y la recepción de registros, debe configurar el envío. Usaremos Fluentd porque amo a Ruby, pero puedes usar Logstash o enviar registros a kinesis directamente. Puede iniciar el servidor Fluentd de varias maneras, hablaré sobre Docker, porque es simple y conveniente.
Primero, necesitamos el archivo de configuración fluent.conf. Créalo y agrega la fuente:
escribe adelante
puerto 24224
vincular 0.0.0.0
Ahora puede iniciar el servidor Fluentd. Si necesita una configuración más avanzada, Docker Hub tiene una guía detallada, que incluye cómo ensamblar su imagen.
$ docker run \ -d \ -p 24224:24224 \ -p 24224:24224/udp \ -v /data:/fluentd/log \ -v <PATH-TO-FLUENT-CONF>:/fluentd/etc fluentd \ -c /fluentd/etc/fluent.conf fluent/fluentd:stable
Esta configuración utiliza la /fluentd/log para almacenar en caché los registros antes de enviarlos. Puede prescindir de esto, pero luego, cuando reinicie, puede perder todo el almacenamiento en caché debido al trabajo excesivo. También se puede usar cualquier puerto, 24224 es el puerto Fluentd predeterminado.
Ahora que tenemos Fluentd ejecutándose, podemos enviar registros de Nginx allí. Por lo general, ejecutamos Nginx en un contenedor Docker, en cuyo caso Docker tiene un controlador de registro nativo para Fluentd:
$ docker run \ --log-driver=fluentd \ --log-opt fluentd-address=<FLUENTD-SERVER-ADDRESS>\ --log-opt tag=\"{{.Name}}\" \ -v /some/content:/usr/share/nginx/html:ro \ -d \ nginx
Si ejecuta Nginx de manera diferente, puede usar los archivos de registro, Fluentd tiene un complemento de cola de archivo .
Agregue el análisis de registro configurado anteriormente a la configuración Fluent:
<filter YOUR-NGINX-TAG.*> @type parser key_name log emit_invalid_record_to_error false <parse> @type json </parse> </filter>
Y enviando registros a Kinesis usando el complemento kinesis firehose :
<match YOUR-NGINX-TAG.*> @type kinesis_firehose region region delivery_stream_name <YOUR-KINESIS-STREAM-NAME> aws_key_id <YOUR-AWS-KEY-ID> aws_sec_key <YOUR_AWS-SEC_KEY> </match>
Atenea
Si configuró todo correctamente, luego de un tiempo (de manera predeterminada, Kinesis escribe los datos recibidos cada 10 minutos) debería ver los archivos de registro en S3. En el menú de "monitoreo" de Kinesis Firehose, puede ver cuántos datos se escriben en S3, así como también los errores. No olvide dar acceso de escritura al S3 Bucket para el rol de Kinesis. Si Kinesis no pudo analizar algo, agregará errores en el mismo depósito.
Ahora puedes ver los datos en Athena. Encontremos algunas consultas nuevas a las que les dimos errores:
SELECT * FROM "db_name"."table_name" WHERE status > 499 ORDER BY created_at DESC limit 10;
Escanee todos los registros para cada solicitud
Ahora nuestros registros se procesan y apilan en S3 en ORC, comprimidos y listos para el análisis. Kinesis Firehose incluso los puso en directorios por cada hora. Sin embargo, aunque la tabla no está particionada, Athena cargará datos de todos los tiempos para cada consulta, con raras excepciones. Este es un gran problema por dos razones:
- La cantidad de datos crece constantemente, ralentizando las consultas;
- Athena se factura en función de la cantidad de datos escaneados, con un mínimo de 10 MB por cada solicitud.
Para solucionar esto, utilizamos AWS Glue Crawler, que escaneará los datos en S3 y registrará la información de la partición en el Metastore de Glue. Esto nos permitirá usar particiones como filtro para solicitudes en Athena, y solo escaneará los directorios especificados en la solicitud.
Personalizar rastreador de pegamento de Amazon
Amazon Glue Crawler escanea todos los datos en el bucket de S3 y crea tablas de particiones. Cree un rastreador de pegamento desde la consola de AWS Glue y agregue el depósito en el que almacena los datos. Puede usar un rastreador para varios depósitos, en este caso creará tablas en la base de datos especificada con nombres que coincidan con los nombres de los depósitos. Si planea usar estos datos todo el tiempo, asegúrese de ajustar el cronograma de lanzamiento de Crawler para satisfacer sus necesidades. Utilizamos un rastreador para todas las tablas, que se ejecuta cada hora.
Tablas Particionadas
Después del primer inicio del rastreador, las tablas para cada depósito escaneado deberían aparecer en la base de datos especificada en la configuración. Abra la consola Athena y busque la tabla con los registros de Nginx. Intentemos leer algo:
SELECT * FROM "default"."part_demo_kinesis_bucket" WHERE( partition_0 = '2019' AND partition_1 = '04' AND partition_2 = '08' AND partition_3 = '06' );
Esta consulta seleccionará todos los registros recibidos de 6 a.m. a 7 a.m.el 8 de abril de 2019. Pero, ¿cuánto más efectivo que simplemente leer desde una tabla no particionada? Vamos a descubrir y seleccionar los mismos registros filtrándolos por marca de tiempo:
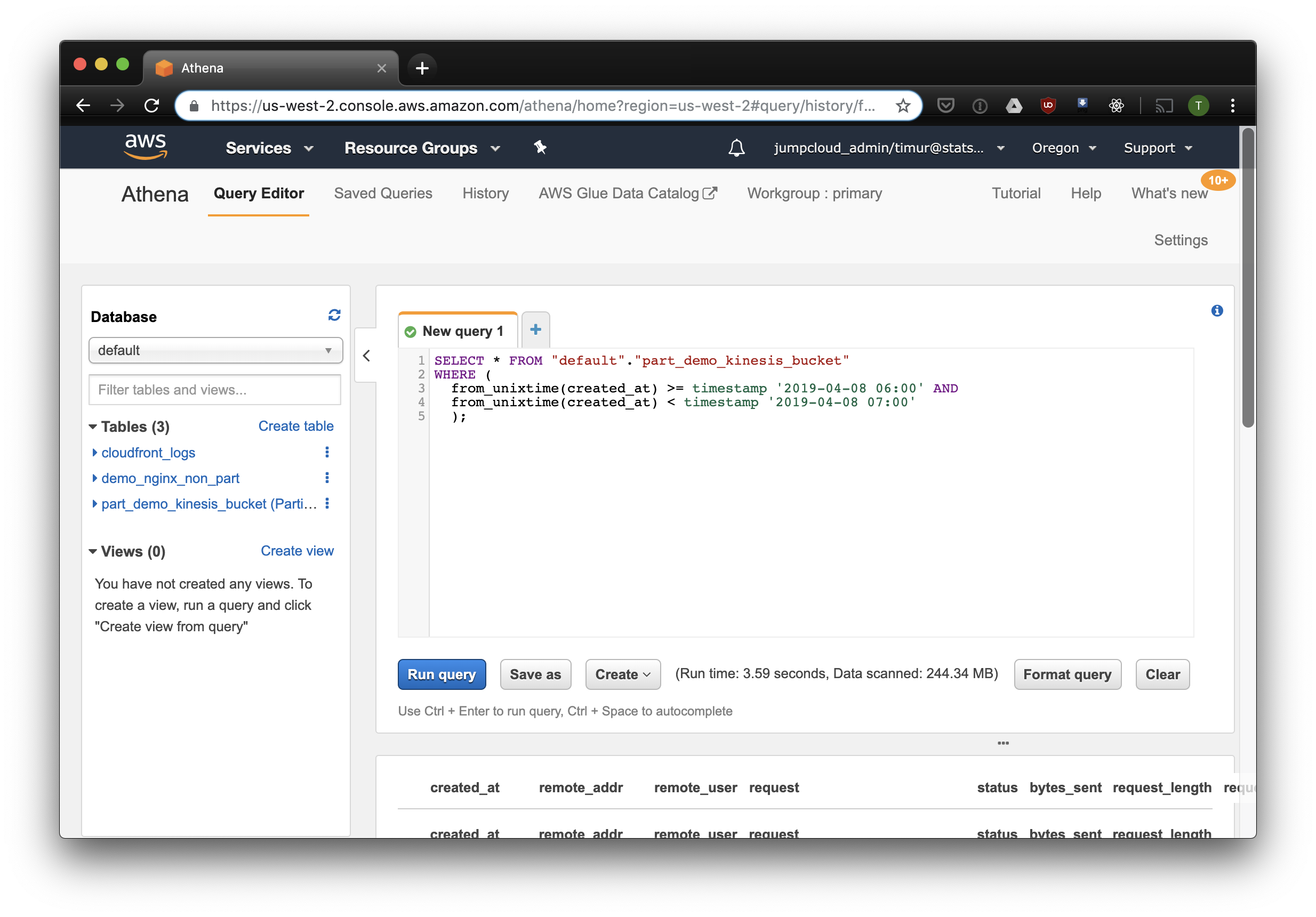
3.59 segundos y 244.34 megabytes de datos en el conjunto de datos, en el que solo hay una semana de registros. Probemos el filtro por particiones:
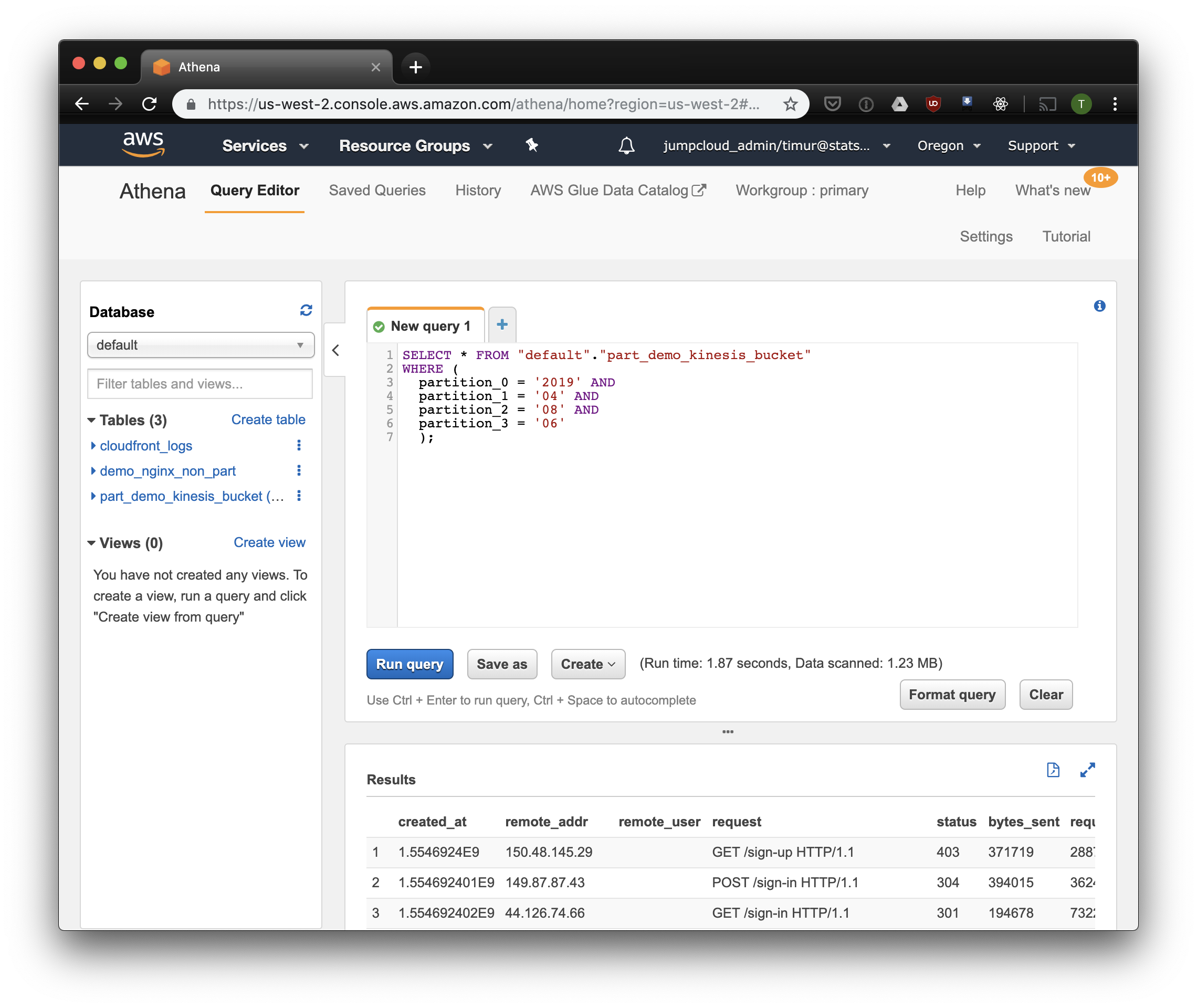
Un poco más rápido, pero lo más importante: ¡solo 1.23 megabytes de datos! Sería mucho más barato si no fuera por el mínimo de 10 megabytes por solicitud en el precio. Pero de todos modos es mucho mejor, y en grandes conjuntos de datos la diferencia será mucho más impresionante.
Construye un tablero usando Cube.js
Para construir un tablero, usamos el marco analítico Cube.js. Tiene bastantes funciones, pero nos interesan dos: la capacidad de usar filtros automáticamente en particiones y la agregación previa de datos. Utiliza un esquema de datos escrito en Javascript para generar SQL y ejecutar una consulta de base de datos. Todo lo que se requiere de nosotros es indicar cómo usar el filtro de partición en el esquema de datos.
Creemos una nueva aplicación Cube.js. Como ya usamos AWS-stack, es lógico usar Lambda para la implementación. Puede usar la plantilla express para la generación si planea alojar el backend de Cube.js en Heroku o Docker. La documentación describe otros métodos de alojamiento .
$ npm install -g cubejs-cli $ cubejs create nginx-log-analytics -t serverless -d athena
Las variables de entorno se utilizan para configurar el acceso a la base de datos en cube.js. El generador creará un archivo .env en el que puede especificar sus claves para Athena .
Ahora necesitamos un esquema de datos en el que indiquemos cómo se almacenan nuestros registros. Allí puede especificar cómo leer las métricas para paneles.
En el directorio de schema , cree el archivo Logs.js Aquí hay un modelo de datos de ejemplo para nginx:
Código modelo const partitionFilter = (from, to) => ` date(from_iso8601_timestamp(${from})) <= date_parse(partition_0 || partition_1 || partition_2, '%Y%m%d') AND date(from_iso8601_timestamp(${to})) >= date_parse(partition_0 || partition_1 || partition_2, '%Y%m%d') ` cube(`Logs`, { sql: ` select * from part_demo_kinesis_bucket WHERE ${FILTER_PARAMS.Logs.createdAt.filter(partitionFilter)} `, measures: { count: { type: `count`, }, errorCount: { type: `count`, filters: [ { sql: `${CUBE.isError} = 'Yes'` } ] }, errorRate: { type: `number`, sql: `100.0 * ${errorCount} / ${count}`, format: `percent` } }, dimensions: { status: { sql: `status`, type: `number` }, isError: { type: `string`, case: { when: [{ sql: `${CUBE}.status >= 400`, label: `Yes` }], else: { label: `No` } } }, createdAt: { sql: `from_unixtime(created_at)`, type: `time` } } });
Aquí usamos la variable FILTER_PARAMS para generar una consulta SQL con un filtro de partición.
También especificamos las métricas y los parámetros que queremos mostrar en el tablero, y especificamos las agregaciones previas. Cube.js creará tablas adicionales con datos agregados previamente y actualizará automáticamente los datos a medida que estén disponibles. Esto no solo acelera las solicitudes, sino que también reduce el costo de usar Athena.
Agregue esta información al archivo de esquema de datos:
preAggregations: { main: { type: `rollup`, measureReferences: [count, errorCount], dimensionReferences: [isError, status], timeDimensionReference: createdAt, granularity: `day`, partitionGranularity: `month`, refreshKey: { sql: FILTER_PARAMS.Logs.createdAt.filter((from, to) => `select CASE WHEN from_iso8601_timestamp(${to}) + interval '3' day > now() THEN date_trunc('hour', now()) END` ) } } }
En este modelo, indicamos que es necesario agregar previamente los datos para todas las métricas usadas, y usar particiones mensuales. Particionar las agregaciones previas puede acelerar significativamente la recopilación y actualización de datos.
¡Ahora podemos armar un tablero!
El backend de Cube.js proporciona una API REST y un conjunto de bibliotecas de cliente para marcos front-end populares. Usaremos la versión React del cliente para construir el tablero. Cube.js solo proporciona datos, por lo que necesitamos una biblioteca para las visualizaciones. Me gustan los rechazos , pero puede usar cualquiera.
El servidor Cube.js acepta la solicitud en formato JSON , que indica las métricas necesarias. Por ejemplo, para calcular cuántos errores cometió Nginx por día, debe enviar la siguiente solicitud:
{ "measures": ["Logs.errorCount"], "timeDimensions": [ { "dimension": "Logs.createdAt", "dateRange": ["2019-01-01", "2019-01-07"], "granularity": "day" } ] }
Instale el cliente Cube.js y la biblioteca de componentes React a través de NPM:
$ npm i --save @cubejs-client/core @cubejs-client/react
Importamos componentes cubejs y QueryRenderer para descargar los datos y recopilamos el panel de control:
Código del tablero import React from 'react'; import { LineChart, Line, XAxis, YAxis } from 'recharts'; import cubejs from '@cubejs-client/core'; import { QueryRenderer } from '@cubejs-client/react'; const cubejsApi = cubejs( 'YOUR-CUBEJS-API-TOKEN', { apiUrl: 'http://localhost:4000/cubejs-api/v1' }, ); export default () => { return ( <QueryRenderer query={{ measures: ['Logs.errorCount'], timeDimensions: [{ dimension: 'Logs.createdAt', dateRange: ['2019-01-01', '2019-01-07'], granularity: 'day' }] }} cubejsApi={cubejsApi} render={({ resultSet }) => { if (!resultSet) { return 'Loading...'; } return ( <LineChart data={resultSet.rawData()}> <XAxis dataKey="Logs.createdAt"/> <YAxis/> <Line type="monotone" dataKey="Logs.errorCount" stroke="#8884d8"/> </LineChart> ); }} /> ) }
Las fuentes del tablero están disponibles en CodeSandbox .