El mes pasado en NVIDIA GTC 2019, NVIDIA presentó una nueva aplicación que convierte las bolas de colores simples dibujadas por el usuario en impresionantes imágenes fotorrealistas.
La aplicación se basa en la tecnología de
redes generativas competitivas (GAN), que se basa en el aprendizaje profundo. NVIDIA lo llama GauGAN, un juego de palabras destinado a referirse al artista Paul Gauguin. La funcionalidad de GauGAN se basa en el nuevo algoritmo SPADE.
En este artículo, explicaré cómo funciona esta obra maestra de ingeniería. Y para atraer tantos lectores interesados como sea posible, intentaré dar una descripción detallada de cómo funcionan las redes neuronales convolucionales. Dado que SPADE es una red generativa competitiva, le contaré más sobre ellos. Pero si ya está familiarizado con este término, puede ir de inmediato a la sección "Transmisión de imagen a imagen".
Generación de imagen
Comencemos a entender: en la mayoría de las aplicaciones modernas de aprendizaje profundo, se utiliza el tipo discriminante neural (discriminador) y SPADE es una red neuronal generativa (generador).
Discriminadores
El discriminador clasifica los datos de entrada. Por ejemplo, un clasificador de imágenes es un discriminador que toma una imagen y selecciona una etiqueta de clase adecuada, por ejemplo, define la imagen como "perro", "automóvil" o "semáforo", es decir, selecciona una etiqueta que describe la imagen completa. La salida obtenida por el clasificador generalmente se presenta como un vector de números
donde
Es un número del 0 al 1, que expresa la confianza de la red de que la imagen pertenece al seleccionado.
clase
El discriminador también puede compilar una lista de clasificaciones. Puede clasificar cada píxel de una imagen como perteneciente a la clase de "personas" o "máquinas" (la llamada "segmentación semántica").
 El clasificador toma una imagen con 3 canales (rojo, verde y azul) y la compara con un vector de confianza en cada clase posible que la imagen pueda representar.
El clasificador toma una imagen con 3 canales (rojo, verde y azul) y la compara con un vector de confianza en cada clase posible que la imagen pueda representar.Dado que la conexión entre la imagen y su clase es muy compleja, las redes neuronales la pasan a través de una pila de muchas capas, cada una de las cuales la procesa "ligeramente" y transfiere su salida al siguiente nivel de interpretación.
Generadores
Una red generativa como SPADE recibe un conjunto de datos y busca crear nuevos datos originales que parezcan pertenecer a esta clase de datos. Al mismo tiempo, los datos pueden ser cualquier cosa: sonidos, idioma u otra cosa, pero nos centraremos en las imágenes. En general, la entrada de datos en dicha red es simplemente un vector de números aleatorios, con cada uno de los posibles conjuntos de datos de entrada creando su propia imagen.
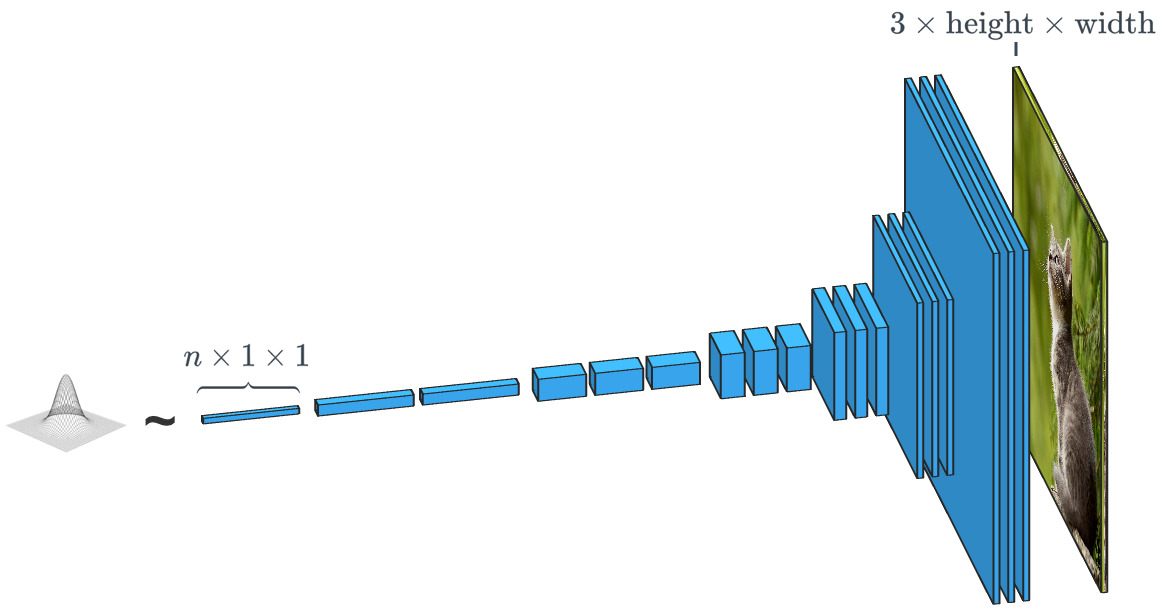 Un generador basado en un vector de entrada aleatorio funciona prácticamente opuesto al clasificador de imágenes. En los generadores de "clase condicional", el vector de entrada es, de hecho, el vector de una clase de datos completa.
Un generador basado en un vector de entrada aleatorio funciona prácticamente opuesto al clasificador de imágenes. En los generadores de "clase condicional", el vector de entrada es, de hecho, el vector de una clase de datos completa.Como ya hemos visto, SPADE utiliza mucho más que un simple "vector aleatorio". El sistema se guía por un tipo de dibujo llamado "mapa de segmentación". Este último indica qué y dónde publicar. SPADE lleva a cabo el proceso opuesto a la segmentación semántica que mencionamos anteriormente. En general, una tarea discriminatoria que convierte un tipo de datos en otro tiene una tarea similar, pero toma un camino diferente e inusual.
Los generadores y discriminadores modernos generalmente usan redes convolucionales para procesar sus datos. Para una introducción más completa a las redes neuronales convolucionales (CNN), vea la publicación
Chew on Karna o el
trabajo de Andrei Karpati .
Hay una diferencia importante entre el clasificador y el generador de imágenes, y radica en cómo cambian exactamente el tamaño de la imagen durante su procesamiento. El clasificador de imágenes debería reducirlo hasta que la imagen pierda toda la información espacial y solo queden las clases. Esto se puede lograr combinando capas o mediante el uso de redes convolucionales a través de las cuales se pasan píxeles individuales. El generador, por otro lado, crea una imagen usando el proceso inverso de "convolución", que se llama transposición convolucional. A menudo se le confunde con "deconvolución" o
"convolución inversa" .
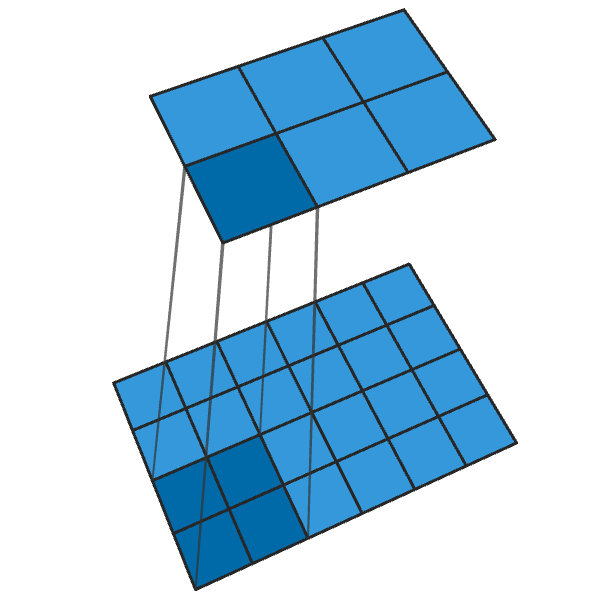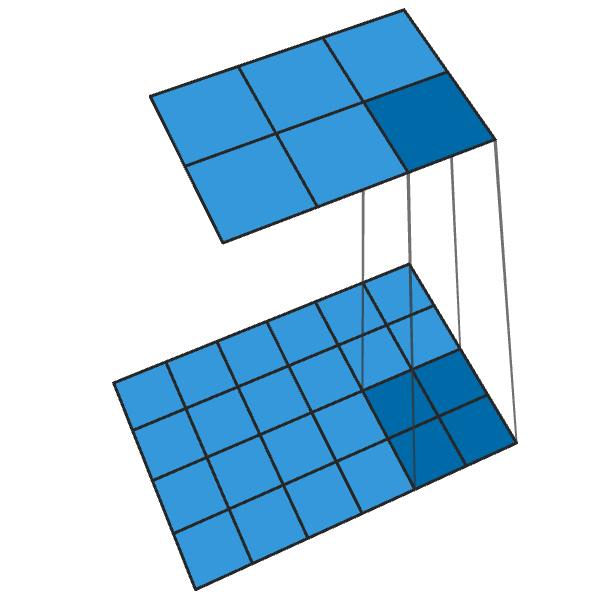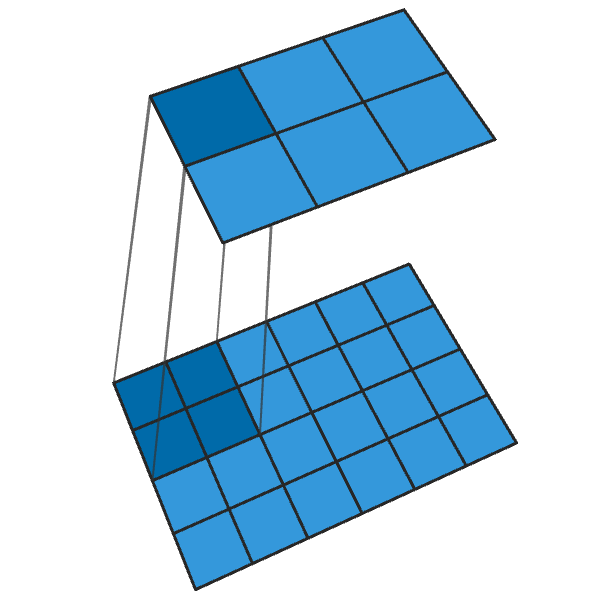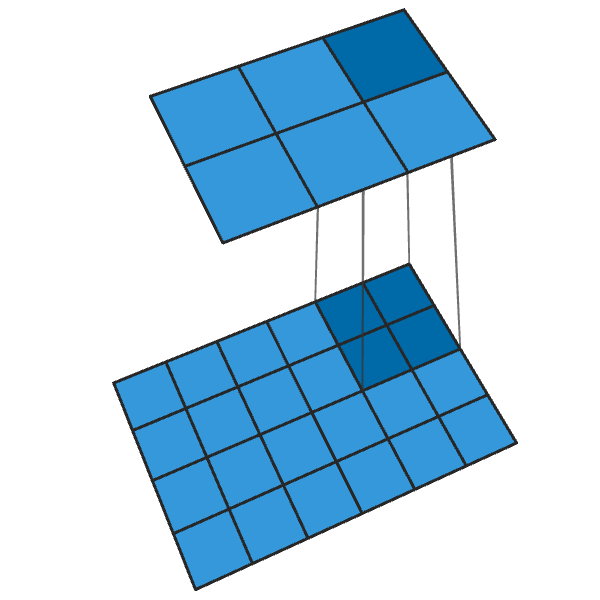
La convolución 2x2 convencional con un paso de "2" convierte cada bloque de 2x2 en un punto, reduciendo el tamaño de salida en 1/2.

Una convolución transpuesta de 2x2 con un paso de "2" genera un bloque de 2x2 desde cada punto, aumentando el tamaño de salida en 2 veces.
Entrenamiento generador
Teóricamente, una red neuronal convolucional puede generar imágenes como se describió anteriormente. ¿Pero cómo la entrenamos? Es decir, si tenemos en cuenta el conjunto de datos de imagen de entrada, ¿cómo podemos ajustar los parámetros del generador (en nuestro caso, SPADE) para que cree nuevas imágenes que parezcan corresponder con el conjunto de datos propuesto?
Para hacer esto, debe comparar con los clasificadores de imágenes, donde cada uno de ellos tiene la etiqueta de clase correcta. Conociendo el vector de predicción de la red y la clase correcta, podemos usar el algoritmo de retropropagación para determinar los parámetros de actualización de la red. Esto es necesario para aumentar su precisión en la determinación de la clase deseada y reducir la influencia de otras clases.
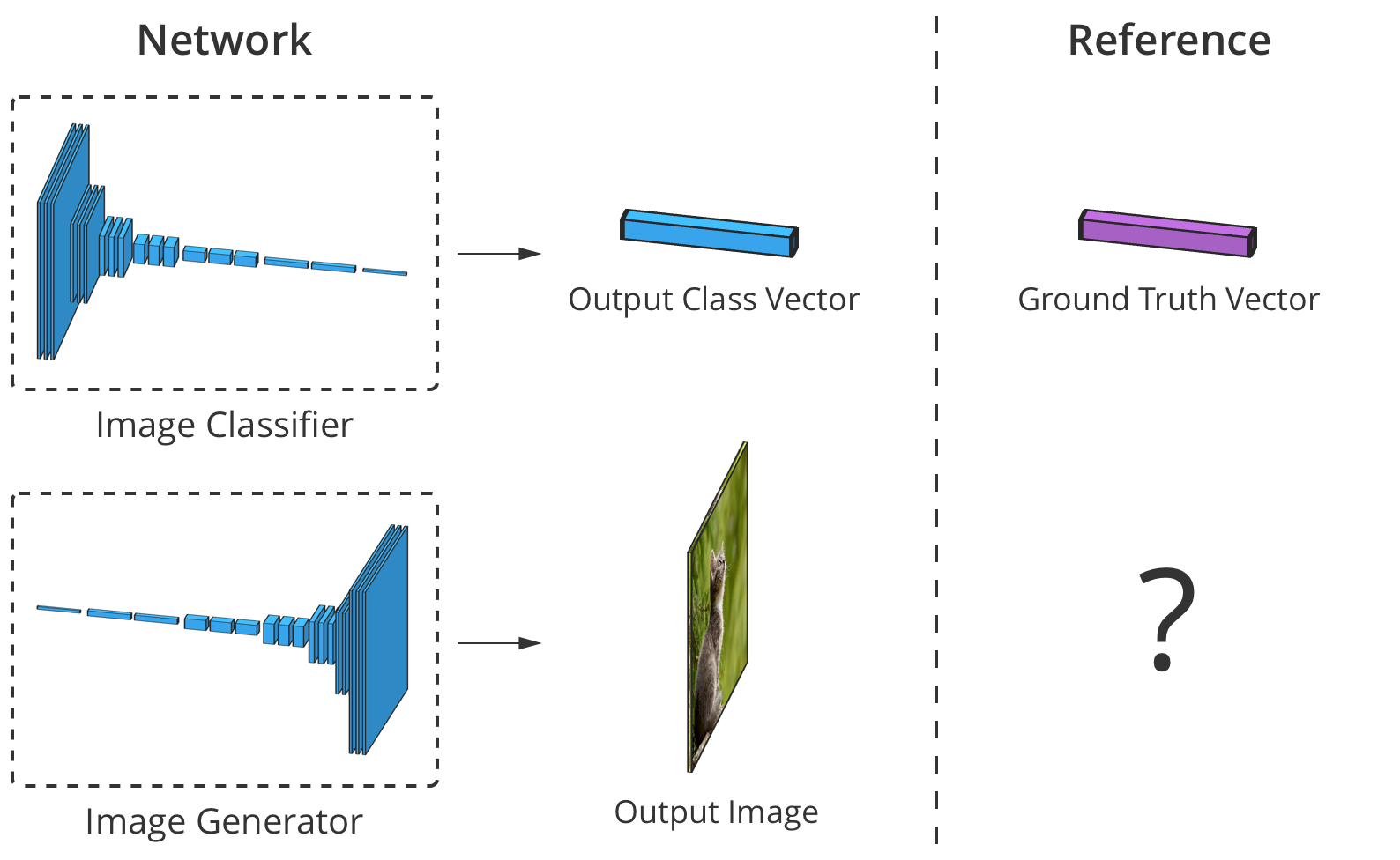 La precisión del clasificador de imágenes se puede estimar comparando su salida elemento por elemento con el vector de clase correcto. Pero para los generadores, no hay una imagen de salida "correcta".
La precisión del clasificador de imágenes se puede estimar comparando su salida elemento por elemento con el vector de clase correcto. Pero para los generadores, no hay una imagen de salida "correcta".El problema es que cuando el generador crea una imagen, no hay valores "correctos" para cada píxel (no podemos comparar el resultado, como en el caso de un clasificador basado en una base preparada previamente, aprox. Trans.). Teóricamente, cualquier imagen que parezca creíble y similar a los datos de destino es válida, incluso si sus valores de píxeles son muy diferentes de las imágenes reales.
Entonces, ¿cómo podemos decirle al generador en qué píxeles debería cambiar su salida y cómo puede crear imágenes más realistas (es decir, cómo dar una "señal de error")? Los investigadores reflexionaron mucho sobre esta pregunta y, de hecho, es bastante difícil. La mayoría de las ideas, como el cálculo de una "distancia" promedio a imágenes reales, producen imágenes borrosas y de baja calidad.
Idealmente, podríamos "medir" cuán realistas se ven las imágenes generadas mediante el uso de un concepto de "alto nivel", como "¿Qué tan difícil es distinguir esta imagen de la real?" ...
Redes adversas generativas
Esto es exactamente lo que se implementó como parte de
Goodfellow et al., 2014 . La idea es generar imágenes usando dos redes neuronales en lugar de una: una red -
generador, el segundo es un clasificador de imagen (discriminador). La tarea del discriminador es distinguir las imágenes de salida del generador de las imágenes reales del conjunto de datos primario (las clases de estas imágenes se designan como "falsas" y "reales"). El trabajo del generador es engañar al discriminador creando imágenes que sean lo más similares posible a las imágenes del conjunto de datos. Podemos decir que el generador y el discriminador son oponentes en este proceso. De ahí el nombre:
red generativa-adversaria .
¿Cómo nos ayuda esto? Ahora podemos usar un mensaje de error basado únicamente en la predicción del discriminador: un valor de 0 ("falso") a 1 ("real"). Dado que el discriminador es una red neuronal, podemos compartir sus conclusiones sobre los errores con el generador de imágenes. Es decir, el discriminador puede decirle al generador dónde y cómo debe ajustar sus imágenes para "engañar" mejor al discriminador (es decir, cómo aumentar el realismo de sus imágenes).
En el proceso de aprender a encontrar imágenes falsas, el discriminador le da al generador una mejor y mejor retroalimentación sobre cómo este último puede mejorar su trabajo. Por lo tanto, el discriminador realiza una función de
"aprender una pérdida" para el generador.
Gloriosa pequeña GAN
La GAN considerada por nosotros en su trabajo sigue la lógica descrita anteriormente. Su discriminador
analiza la imagen
y obtiene el valor
de 0 a 1, lo que refleja su grado de confianza de que la imagen es real o falsa por el generador. Su generador
obtiene un vector aleatorio de números normalmente distribuidos
y muestra la imagen
eso puede ser engañado por el discriminador (de hecho, esta imagen
)
Una de las cuestiones que no discutimos es cómo capacitar a la GAN y qué
función de pérdida utilizan los desarrolladores para medir el rendimiento de la red. En general, la función de pérdida debería aumentar a medida que se entrena el discriminador y disminuir a medida que se entrena el generador. La función de pérdida de la fuente GAN utilizó los siguientes dos parámetros. El primero es
representa el grado en que el discriminador clasifica correctamente las imágenes reales como reales. El segundo es qué tan bien el discriminador detecta imágenes falsas:
$ inline $ \ begin {ecation *} \ mathcal {L} _ \ text {GAN} (D, G) = \ underbrace {E _ {\ vec {x} \ sim p_ \ text {data}} [\ log D ( \ vec {x})]} _ {\ text {precisión en imágenes reales}} + \ underbrace {E _ {\ vec {z} \ sim \ mathcal {N}} [\ log (1 - D (G (\ vec {z}))]} _ {\ text {precisión en falsificaciones}} \ end {ecuación *} $ en línea $
Discriminador
deriva su afirmación de que la imagen es real. Tiene sentido ya que
aumenta cuando el discriminador considera x real. Cuando el discriminador detecta mejor las imágenes falsas, el valor de la expresión también aumenta.
(comienza a esforzarse por 1), ya que
tenderá a 0.
En la práctica, evaluamos la precisión utilizando lotes completos de imágenes. Tomamos muchas (pero no todas) imágenes reales
y muchos vectores aleatorios
para obtener los promedios de acuerdo con la fórmula anterior. Luego seleccionamos errores comunes y un conjunto de datos.
Con el tiempo, esto lleva a resultados interesantes:
 Goodfellow GAN que simula conjuntos de datos MNIST, TFD y CIFAR-10. Las imágenes de contorno son las más cercanas en el conjunto de datos a las falsificaciones adyacentes.
Goodfellow GAN que simula conjuntos de datos MNIST, TFD y CIFAR-10. Las imágenes de contorno son las más cercanas en el conjunto de datos a las falsificaciones adyacentes.Todo esto fue fantástico hace solo 4,5 años. Afortunadamente, como muestran SPADE y otras redes, el aprendizaje automático continúa progresando rápidamente.
Problemas de entrenamiento
Las redes de competencia generacional son conocidas por su complejidad en la preparación y la inestabilidad del trabajo. Uno de los problemas es que si el generador está muy por delante del discriminador en el ritmo del entrenamiento, su selección de imágenes se reduce a aquellas que lo ayudan a engañar al discriminador. De hecho, como resultado, entrenar al generador se reduce a crear una imagen única y universal para engañar al discriminador. Este problema se llama "modo de colapso".

El modo de colapso de GAN es similar al de Goodfellow. Tenga en cuenta que muchas de estas imágenes de dormitorio se parecen mucho entre sí.
FuenteOtro problema es que cuando el generador efectivamente engaña al discriminador
, funciona con un gradiente muy pequeño, por lo tanto
no puede obtener suficientes datos para encontrar la respuesta verdadera, en la que esta imagen se vería más realista.
Los esfuerzos de los investigadores para resolver estos problemas apuntaban principalmente a cambiar la estructura de la función de pérdida. Uno de los cambios simples propuestos por
Xudong Mao et al., 2016 es el reemplazo de la función de pérdida
para un par de funciones simples
, que se basan en cuadrados de área más pequeña. Esto conduce a la estabilización del proceso de entrenamiento, obteniendo mejores imágenes y menos posibilidades de colapso usando gradientes no amortiguados.
Otro problema que los investigadores han encontrado es la dificultad de obtener imágenes de alta resolución, en parte porque una imagen más detallada le da al discriminador más información para detectar imágenes falsas. Las GAN modernas comienzan a entrenar la red con imágenes de baja resolución y agregan gradualmente más y más capas hasta alcanzar el tamaño de imagen deseado.
 La adición gradual de capas con mayor resolución durante el entrenamiento GAN aumenta significativamente la estabilidad de todo el proceso, así como la velocidad y la calidad de la imagen resultante.
La adición gradual de capas con mayor resolución durante el entrenamiento GAN aumenta significativamente la estabilidad de todo el proceso, así como la velocidad y la calidad de la imagen resultante.Difusión de imagen a imagen
Hasta ahora, hemos hablado sobre cómo generar imágenes a partir de conjuntos aleatorios de datos de entrada. Pero SPADE no solo usa datos aleatorios. Esta red utiliza una imagen llamada mapa de segmentación: asigna una clase de material a cada píxel (por ejemplo, hierba, madera, agua, piedra, cielo). A partir de esta imagen, la tarjeta es SPADE y genera lo que parece una foto. Esto se llama "transmisión de imagen a imagen".
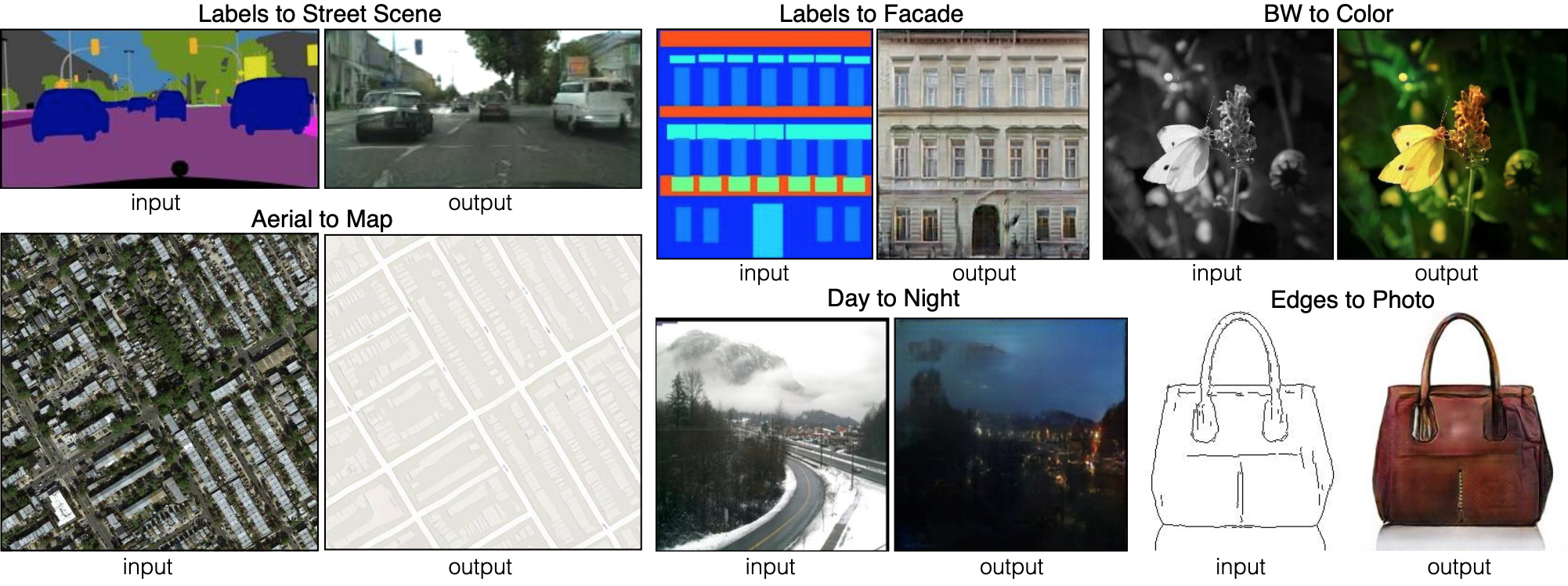 Seis tipos diferentes de transmisiones de imagen a imagen demostradas por pix2pix. Pix2pix es el predecesor de las dos redes, que discutiremos más a fondo: pix2pixHD y SPADE.
Seis tipos diferentes de transmisiones de imagen a imagen demostradas por pix2pix. Pix2pix es el predecesor de las dos redes, que discutiremos más a fondo: pix2pixHD y SPADE.Para que el generador aprenda este enfoque, necesita un conjunto de mapas de segmentación y las fotos correspondientes. Estamos modificando la arquitectura GAN para que tanto el generador como el discriminador reciban un mapa de segmentación. El generador, por supuesto, necesita un mapa para saber "qué forma de dibujar". El discriminador también lo necesita para asegurarse de que el generador coloca las cosas correctas en los lugares correctos.
Durante el entrenamiento, el generador aprende a no poner hierba donde se indica "cielo" en el mapa de segmentación, porque de lo contrario el discriminador puede detectar fácilmente una imagen falsa, y así sucesivamente.
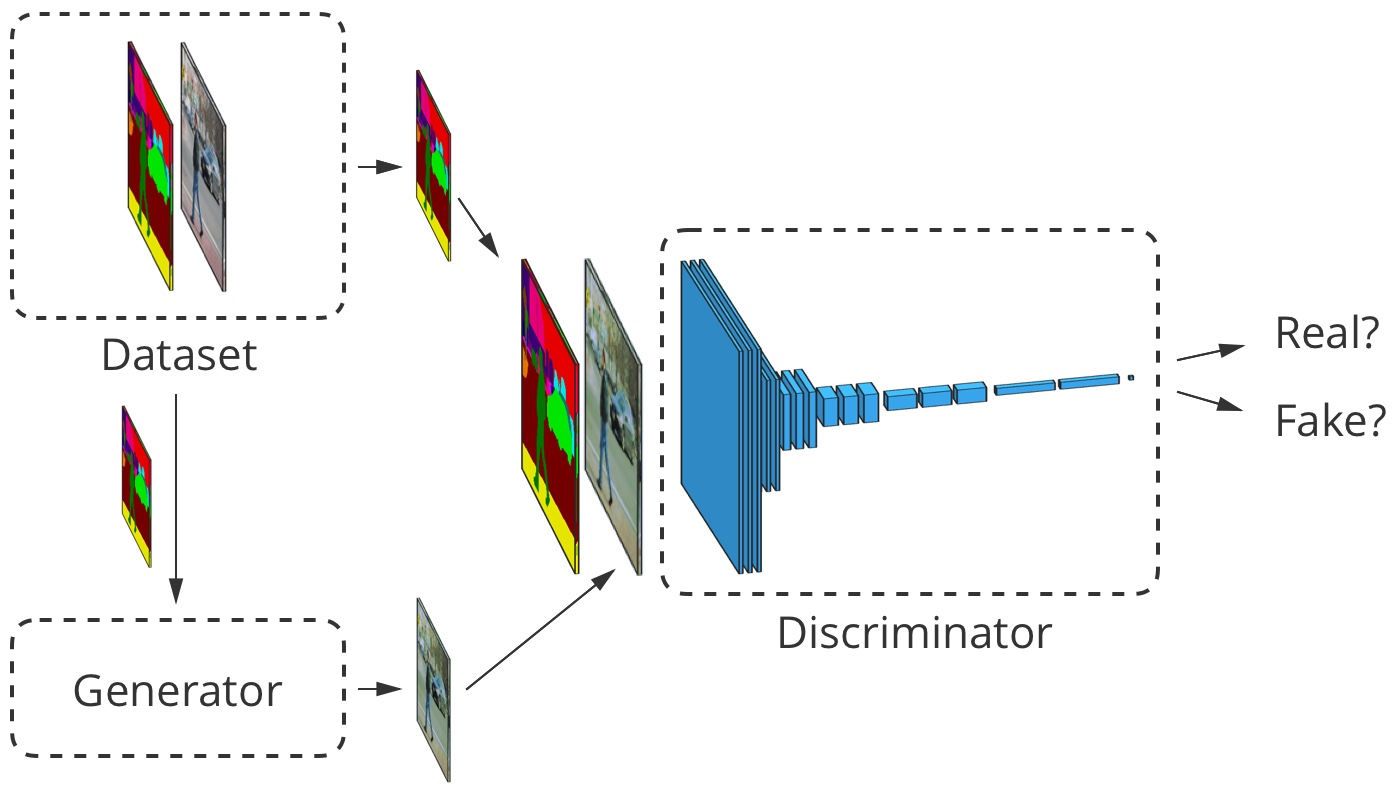 Para la traducción de imagen a imagen, la imagen de entrada es aceptada tanto por el generador como por el discriminador. El discriminador recibe adicionalmente la salida del generador o la salida real del conjunto de datos de entrenamiento. Ejemplo
Para la traducción de imagen a imagen, la imagen de entrada es aceptada tanto por el generador como por el discriminador. El discriminador recibe adicionalmente la salida del generador o la salida real del conjunto de datos de entrenamiento. EjemploDesarrollo de traductor de imagen a imagen
Veamos un traductor real de imagen a imagen:
pix2pixHD . Por cierto, SPADE está diseñado en su mayor parte en la imagen y semejanza de pix2pixHD.
Para un traductor de imagen a imagen, nuestro generador crea una imagen y la acepta como entrada. Podríamos usar un mapa de capa convolucional, pero dado que las capas convolucionales combinan valores solo en áreas pequeñas, necesitamos demasiadas capas para transmitir información de imagen de alta resolución.
pix2pixHD resuelve este problema de manera más eficiente con la ayuda del "Codificador", que reduce la escala de la imagen de entrada, seguido del "Decodificador", que aumenta la escala para obtener la imagen de salida. Como veremos pronto, SPADE tiene una solución más elegante que no requiere un codificador.
 Diagrama de red Pix2pixHD a un nivel "alto". Los bloques "residuales" y la "operación +" se refieren a la tecnología "omitir conexiones" de la red neuronal residual . Hay bloques de omisión en la red, que están interconectados en el codificador y decodificador.
Diagrama de red Pix2pixHD a un nivel "alto". Los bloques "residuales" y la "operación +" se refieren a la tecnología "omitir conexiones" de la red neuronal residual . Hay bloques de omisión en la red, que están interconectados en el codificador y decodificador.La normalización de lotes es un problema.
Casi todas las redes neuronales convolucionales modernas utilizan la normalización por lotes o uno de sus análogos para acelerar y estabilizar el proceso de entrenamiento. La activación de cada canal desplaza la media a 0 y la desviación estándar a 1 antes de un par de parámetros de canal.
y
deja que se desnormalicen nuevamente.
Desafortunadamente, la normalización por lotes perjudica a los generadores, lo que dificulta que la red implemente algunos tipos de procesamiento de imágenes. En lugar de normalizar un lote de imágenes, pix2pixHD utiliza un
estándar de normalización , que normaliza cada imagen individualmente.
Entrenamiento Pix2pixHD
Las GAN modernas, como pix2pixHD y SPADE, miden el realismo de sus imágenes de salida de manera un poco diferente de lo que se describió para el diseño original de las redes de contención generativa.
Para resolver el problema de generar imágenes de alta resolución, pix2pixHD utiliza tres discriminadores de la misma estructura, cada uno de los cuales recibe la imagen de salida en una escala diferente (tamaño normal, reducido en 2 veces y reducido en 4 veces).
Pix2pixHD utiliza
, y también incluye otro elemento diseñado para hacer que las conclusiones del generador sean más realistas (independientemente de si esto ayuda a engañar al discriminador). Este artículo
llamado "coincidencia de características": alienta al generador a hacer que la distribución de capas sea la misma al simular la discriminación entre datos reales y las salidas del generador, minimizando
entre ellos
Entonces, la optimización se reduce a lo siguiente:
$$ display $$ \ begin {ecation *} \ min_G \ bigg (\ lambda \ sum_ {k = 1,2,3} V_ \ text {LSGAN} (G, D_k) + \ big (\ max_ {D_1, D_2 , D_3} \ sum_ {k = 1,2,3} \ mathcal {L} _ \ text {FM} (G, D_k) \ big) \ bigg) \ end {ecuación *}, $$ display $$
donde las pérdidas se resumen por tres factores y coeficientes discriminatorios
, que controla la prioridad de ambos elementos.
 pix2pixHD utiliza un mapa de segmentación compuesto por un dormitorio real (a la izquierda en cada ejemplo) para crear un dormitorio falso (a la derecha).
pix2pixHD utiliza un mapa de segmentación compuesto por un dormitorio real (a la izquierda en cada ejemplo) para crear un dormitorio falso (a la derecha).Aunque los discriminadores reducen la escala de la imagen hasta que desmontan toda la imagen, se detienen en "puntos" de tamaño 70 × 70 (a las escalas apropiadas). Luego, simplemente resumen todos los valores de estos "puntos" para toda la imagen.
Y este enfoque funciona bien, ya que la función
, ,
. , .
 pix2pixHD . CelebA , .
pix2pixHD . CelebA , .pix2pixHD?
, . , pix2pixHD .
, pix2pixHD , , , . , . «» ()
. β- , : , «», «», «» - .
pix2pixHD . , , .— SPADE.
: SPADE
- : - () (SPADE).
SPADE , , γ, β, , . , 2 .
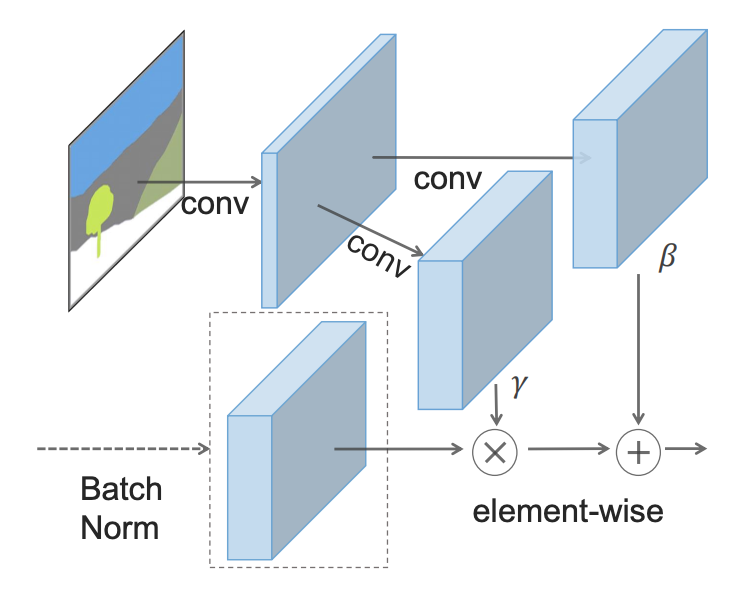 , SPADE .
, SPADE .SPADE « », ( ):
 SPADE pix2pixHD
SPADE pix2pixHD, «» , . GAN, . (« »). «» pix2pixHD, .
SPADE , pix2pixHD, :
hinge loss .
:
 SPADE pix2pixHD
SPADE pix2pixHD, SPADE . . GauGAN «» , . , - SPADE , «» , .
, SPADE , «» .
, , «». SPADE , , ? 55, «».
, , 5x5 . , .
SPADE , , , , pix2pixHD. , .
SPADE — (, , , ).
 SPADE , .
SPADE , .: ,
, . , , SPADE , , .
, . , ,
.
Así es como funciona SPADE / GaiGAN. Espero que este artículo haya satisfecho su curiosidad sobre cómo funciona el nuevo sistema NVIDIA. Puede contactarme a través de Twitter @AdamDanielKin o enviar un correo electrónico adam@AdamDKing.com.