
¿Cómo escribir tu nombre en la historia para siempre? ¿El primero en volar a la luna? ¿El primero en encontrarse con una mente extraña? Tenemos una manera más simple: puede adaptarse al estándar de lenguaje C ++.
Eric Nibler, autor de C ++ Ranges, ofrece un buen ejemplo. “Recuerda esto. El 19 de febrero de 2019 es el día en que se habló por primera vez el término "nibloide" en la reunión del WG21 ", escribió en Twitter.
De hecho, si va a CppReference, en la sección cpp / algoritmo / rangoscpp / algoritmo / rangos , encontrará muchas referencias allí (niebloid). Para esto, incluso se ha creado una plantilla wiki dsc_niebloid separada.
Desafortunadamente, no encontré ningún artículo oficial completo sobre este tema y decidí escribir el mío. Este es un viaje pequeño pero fascinante hacia los abismos de la astronáutica arquitectónica, en el que podemos sumergirnos en el abismo de la locura ADL y familiarizarnos con los nibloides.
Importante: no soy un soldador real, sino un javista que a veces corrige errores en el código C ++ según sea necesario. Si se toma un poco de tiempo para ayudar a encontrar errores en el razonamiento, sería bueno. "Ayuda a Dasha, el viajero, a recoger algo razonable".
Buscar
Primero debes decidir sobre los términos. Estas son cosas bien conocidas, pero "lo explícito es mejor que lo implícito", por lo que las discutiremos por separado. No uso terminología real en ruso, sino que uso inglés. Esto es necesario porque incluso la palabra "restricción" en el contexto de este artículo puede asociarse con al menos tres versiones en inglés, cuya diferencia es importante para la comprensión.
Por ejemplo, en C ++ existe el concepto de búsqueda de nombres o, en otras palabras, una búsqueda: cuando se encuentra un nombre en un programa, se compila con su declaración durante la compilación.
Se puede calificar una búsqueda (si el nombre está a la derecha del operador de permisos del ámbito :: :), y no calificado en otros casos. Si la búsqueda es calificada, omitimos los miembros correspondientes de la clase, el espacio de nombres o la enumeración. Se podría llamar a esto la versión "completa" del registro (como parece hacerse en la traducción de Straustrup), pero es mejor dejar la ortografía original, porque se refiere a un tipo muy específico de integridad.
ADL
Si la búsqueda no está calificada, entonces debemos entender exactamente dónde buscar el nombre. Y aquí se incluye una característica especial llamada ADL: búsqueda dependiente de argumentos , o bien, la búsqueda de Koenig (el que acuñó el término "antipatrón", que es un poco simbólico a la luz del siguiente texto). Nicolai Josuttis en su libro "The C ++ Standard Library: A Tutorial and Reference" lo describe de la siguiente manera: "El punto es que no es necesario calificar el espacio de nombres de la función si al menos uno de los tipos de argumentos está definido en el espacio de nombres de esta función".
¿Cómo debería ser?
#include <iostream> int main() { // . // , operator<< , ADL , // std std::operator<<(std::ostream&, const char*) std::cout << "Test\n"; // . - . operator<<(std::cout, "Test\n"); // same, using function call notation // : // Error: 'endl' is not declared in this namespace. // endl(), ADL . std::cout << endl; // . // , ADL. // std, endl std. endl(std::cout); // : // Error: 'endl' is not declared in this namespace. // , - (endl) - . (endl)(std::cout); }
Vete al infierno con ADL
Parecería simple. O no? Primero, dependiendo del tipo de argumento, ADL funciona de nueve maneras diferentes , para matar con una escoba.
En segundo lugar, puramente práctico, imagine que tenemos algún tipo de función de intercambio. Resulta que std::swap(obj1,obj2); y using std::swap; swap(obj1, obj2); using std::swap; swap(obj1, obj2); puede comportarse de manera completamente diferente. Si ADL está habilitado, entonces de varios intercambios diferentes, ¡el que necesita ya está seleccionado en función de los espacios de nombres de los argumentos! Dependiendo del punto de vista, este modismo puede considerarse tanto un ejemplo positivo como negativo :-)
Si le parece que esto no es suficiente, puede dejar caer la leña en el horno del sombrero. Esto fue escrito recientemente por Arthur O'Dwyer . Espero que no me castigue por usar su ejemplo.
Imagine que tiene un programa de este tipo:
#include <stdio.h> namespace A { struct A {}; void call(void (*f)()) { f(); } } void f() { puts("Hello world"); } int main() { call(f); }
Por supuesto, no se compila con un error:
error: use of undeclared identifier 'call'; did you mean 'A::call'? call(f); ^~~~ A::call
Pero si agrega una sobrecarga completamente no utilizada de la función f , ¡entonces todo funcionará!
#include <stdio.h> namespace A { struct A {}; void call(void (*f)()) { f(); } } void f() { puts("Hello world"); } void f(A::A); // UNUSED int main() { call(f); }
En Visual Studio todavía se romperá, pero ese es su destino, no funciona.
¿Cómo sucedió esto? Profundicemos en el estándar (sin traducción, porque dicha traducción sería una mezcolanza de palabras de moda excepcionalmente monstruosa):
Si el argumento es el nombre o la dirección de un conjunto de funciones y / o plantillas de funciones sobrecargadas, sus entidades y espacios de nombres asociados son la unión de los asociados con cada uno de los miembros del conjunto, es decir, las entidades y espacios de nombres asociados con su parámetro tipos y tipo de retorno. [...] Además, si el conjunto de funciones sobrecargadas mencionado anteriormente se nombra con una plantilla-id, sus entidades y espacios de nombres asociados también incluyen los de su tipo plantilla-argumentos y su plantilla plantilla-argumentos.
Ahora tome un código como este:
#include <stdio.h> namespace B { struct B {}; void call(void (*f)()) { f(); } } template<class T> void f() { puts("Hello world"); } int main() { call(f<B::B>); }
En ambos casos, se obtienen argumentos que no tienen tipo. f y f<B::B> son los nombres de los conjuntos de funciones sobrecargadas (de la definición anterior), y dicho conjunto no tiene tipo. Para colapsar una sobrecarga en una sola función, debe comprender qué tipo de puntero de función es más adecuado para la mejor sobrecarga de call . Por lo tanto, debe recopilar un conjunto de candidatos para la call , lo que significa iniciar una búsqueda de la call nombre. ¡Y para esto comenzará ADL!
¡Pero generalmente para ADL debemos conocer los tipos de argumentos! Y aquí Clang, ICC y MSVC se rompen erróneamente de la siguiente manera (pero GCC no):
[build] ..\..\main.cpp(15,5): error: use of undeclared identifier 'call'; did you mean 'B::call'? [build] call(f<B::B>); [build] ^~~~ [build] B::call [build] ..\..\main.cpp(4,10): note: 'B::call' declared here [build] void call(void (*f)()) { [build] ^
Incluso los creadores de compiladores con ADL tienen una relación un poco tensa.
Bueno, ¿ADL todavía parece una buena idea? Por un lado, ya no necesitamos escribir un código tan servil de una manera educada:
std::cout << "Hello, World!" << std::endl; std::operator<<(std::operator<<(std::cout, "Hello, World!"), "\n");
Por otro lado, intercambiamos por brevedad el hecho de que ahora hay un sistema que funciona de una manera completamente inhumana. Una historia trágica y majestuosa sobre cómo la facilidad de escribir Halloworld puede afectar todo el idioma en una escala de décadas.
Rangos y conceptos
Si abre la descripción de la biblioteca de Nibler Rangers , incluso antes de mencionar los nibloides, tropezará con muchos otros marcadores llamados (concepto) . Esto ya es algo bonito, pero por si acaso (para los viejos y los javists) te recordaré lo que es .
Los conceptos se denominan conjuntos de restricciones con nombre que se aplican a los argumentos de plantilla para seleccionar las mejores sobrecargas de funciones y las especializaciones de plantilla más adecuadas.
template <typename T> concept bool HasStringFunc = requires(T a) { { to_string(a) } -> string; }; void print(HasStringFunc a) { cout << to_string(a) << endl; }
Aquí hemos impuesto una restricción de que el argumento debe tener una función to_string que devuelva una cadena. Si tratamos de poner algún juego dentro de la print que no esté sujeto a las restricciones, entonces dicho código simplemente no se compilará.
Esto simplifica enormemente el código. Por ejemplo, vea cómo Nibler clasificó en rangos-v3 , que funciona en C ++ 14/11/17. Hay un código maravilloso como este:
#define CONCEPT_PP_CAT_(X, Y) X ## Y #define CONCEPT_PP_CAT(X, Y) CONCEPT_PP_CAT_(X, Y)
Para que luego puedas hacer:
struct Sortable_ { template<typename Rng, typename C = ordered_less, typename P = ident, typename I = iterator_t<Rng>> auto requires_() -> decltype( concepts::valid_expr( concepts::model_of<concepts::ForwardRange, Rng>(), concepts::is_true(ranges::Sortable<I, C, P>()) )); }; using Sortable = concepts::models<Sortable_, Rng, C, P>; template<typename Rng, typename C = ordered_less, typename P = ident, CONCEPT_REQUIRES_(!Sortable<Rng, C, P>())> void operator()(Rng &&, C && = C{}, P && = P{}) const { ...
Espero que ya haya querido ver todo esto y simplemente usar conceptos preparados en un compilador nuevo.
Puntos de personalización
La siguiente cosa interesante que se puede encontrar en el estándar es personalización.punto.objeto . Se usan activamente en la biblioteca de Nibler Ranges.
El punto de personalización es una función utilizada por la biblioteca estándar para que se pueda sobrecargar para los tipos de usuario en el espacio de nombres del usuario, y estas sobrecargas se pueden encontrar utilizando ADL.
Los puntos de personalización están diseñados con los siguientes principios arquitectónicos en cust ( cust es el nombre de algún punto de personalización imaginario):
- El código que llama a
cust escribe en la forma calificada std::cust(a) o en la no calificada: using std::cust; cust(a); using std::cust; cust(a); . Ambas entradas deben comportarse de manera idéntica. En particular, deben encontrar cualquier sobrecarga de usuarios en el espacio de nombres asociado con los argumentos. - Código que usa
cust en forma de una std::cust; cust(a); std::cust; cust(a); no debería poder eludir las restricciones impuestas a std::cust . - Las llamadas de punto personalizadas deberían funcionar de manera eficiente y óptima en cualquier compilador bastante moderno.
- La decisión no debe crear nuevas infracciones de la Regla de definición única (ODR) .
Para entender de qué se trata, puede echar un vistazo al N4381 . A primera vista, parecen una forma de escribir sus propias versiones de begin , swap , data y similares, y la biblioteca estándar los recoge usando ADL.
La pregunta es, ¿cómo difiere esto de la práctica anterior, cuando el usuario escribe una sobrecarga para que algunos begin por su propio tipo y espacio de nombres? ¿Y por qué son incluso objetos?
De hecho, estas son instancias de objetos funcionales en el std . Su propósito es primero extraer comprobaciones de tipo (diseñadas como conceptos) en todos los argumentos en una fila, y luego enviar la llamada a la función correcta en el std o std a la venta en ADL.
De hecho, este no es el tipo de cosa que usaría en un programa regular que no sea de biblioteca. Esta es una característica de la biblioteca estándar, que le permitirá agregar la verificación de conceptos en futuros puntos de extensión, lo que a su vez conducirá a la visualización de errores más hermosos y comprensibles si arruina algo en las plantillas.
El enfoque actual de los puntos de personalización tiene un par de problemas. En primer lugar, es muy fácil romperlo todo. Imagina este código:
template<class T> void f(T& t1, T& t2) { using std::swap; swap(t1, t2); }
Si accidentalmente hacemos una llamada calificada a std::swap(t1, t2) entonces nuestra propia versión de swap nunca se iniciará, sin importar lo que hayamos puesto allí. Pero, lo que es más importante, no hay forma de adjuntar centralmente verificaciones de conceptos a tales implementaciones de funciones personalizadas. En N4381 escriben:
“Imagine que algún día en el futuro, std::begin requerirá que su argumento se modele como un concepto Range . Agregar tal restricción simplemente no tendrá ningún efecto en el código idiomáticamente usando std::begin :
using std::begin; begin(a);
Después de todo, si la llamada de begin se envía a la versión sobrecargada creada por el usuario, entonces las restricciones en std::begin simplemente se ignoran ".
La solución descrita en el propozal resuelve ambos problemas, para esto utilizamos el enfoque de esta implementación especulativa de std::begin (puede ver godbolt ):
#include <utility> namespace my_std { namespace detail { struct begin_fn { /* , begin(arg) arg.begin(). - . */ template <class T> auto operator()(T&& arg) const { return impl(arg, 1L); } template <class T> auto impl(T&& arg, int) const requires requires { begin(std::declval<T>()); } { return begin(arg); } // ADL template <class T> auto impl(T&& arg, long) const requires requires { std::declval<T>().begin(); } { return arg.begin(); } // ... }; } // inline constexpr detail::begin_fn begin{}; }
Una llamada calificada de algunos my_std::begin(someObject) siempre pasa por my_std::detail::begin_fn , y eso es bueno. ¿Qué le sucede a una llamada no calificada? Leamos nuestro periódico nuevamente:
“En el caso de que se llame a begin sin calificación inmediatamente después de la aparición de my_std::begin dentro del alcance, la situación cambia un poco. En la primera etapa de la búsqueda, el nombre begin resolverá en el objeto global my_std::begin . Debido a que la búsqueda encontró un objeto, no una función, la segunda fase de la búsqueda no se realiza. En otras palabras, si my_std::begin es un objeto, entonces usando la construcción my_std::detail::begin_fn begin; begin(a); my_std::detail::begin_fn begin; begin(a); simplemente equivalente a std::begin(a); "Y como hemos visto, esto lanza ADL personalizado".
Es por eso que la validación de concepto se puede hacer en un objeto de función en el std antes de que ADL llame a la función proporcionada por el usuario. No hay forma de engañar a este comportamiento.
¿Cómo se personalizan los puntos de personalización?
De hecho, "objeto de punto de personalización" (CPO) no es un buen nombre. Por el nombre no está claro cómo se expanden, qué mecanismos están bajo el capó, qué funciones prefieren ...
Lo que nos lleva al término "nibloide". Un nibloide es un CPO que llama a la función X si está definida en la clase; de lo contrario, llama a la función X si hay una función libre adecuada; de lo contrario, intenta ejecutar una recuperación de la función X.
Entonces, por ejemplo, los ranges::swap nibloides ranges::swap cuando se llaman ranges::swap(a, b) primero intentarán llamar a a.swap(b) . Si no existe tal método, intentará llamar a swap(a, b) usando ADL. Si esto no funciona, intente auto tmp = std::move(a); a = std::move(b); b = std::move(tmp) auto tmp = std::move(a); a = std::move(b); b = std::move(tmp) auto tmp = std::move(a); a = std::move(b); b = std::move(tmp) .
Resumen
Como Matt bromeó en Twitter, Dave una vez sugirió hacer que los objetos funcionales "funcionen" con ADL al igual que las funciones normales, por razones de coherencia. La ironía es que su capacidad para desactivar ADL y ser invisible para él ahora se ha convertido en sus principales ventajas.
Todo este artículo fue una preparación para esto.
" Simplemente entendí todo, eso es todo. ¿Me escuchas ?
¿Alguna vez has mirado algo, y parecía una locura, y luego en una luz diferente en
¿Locos verlos normales?

No tengas miedo. No tengas miedo. Me siento muy bien de corazón. Todo estará bien No me he sentido tan bien por muchos años. Todo estará bien
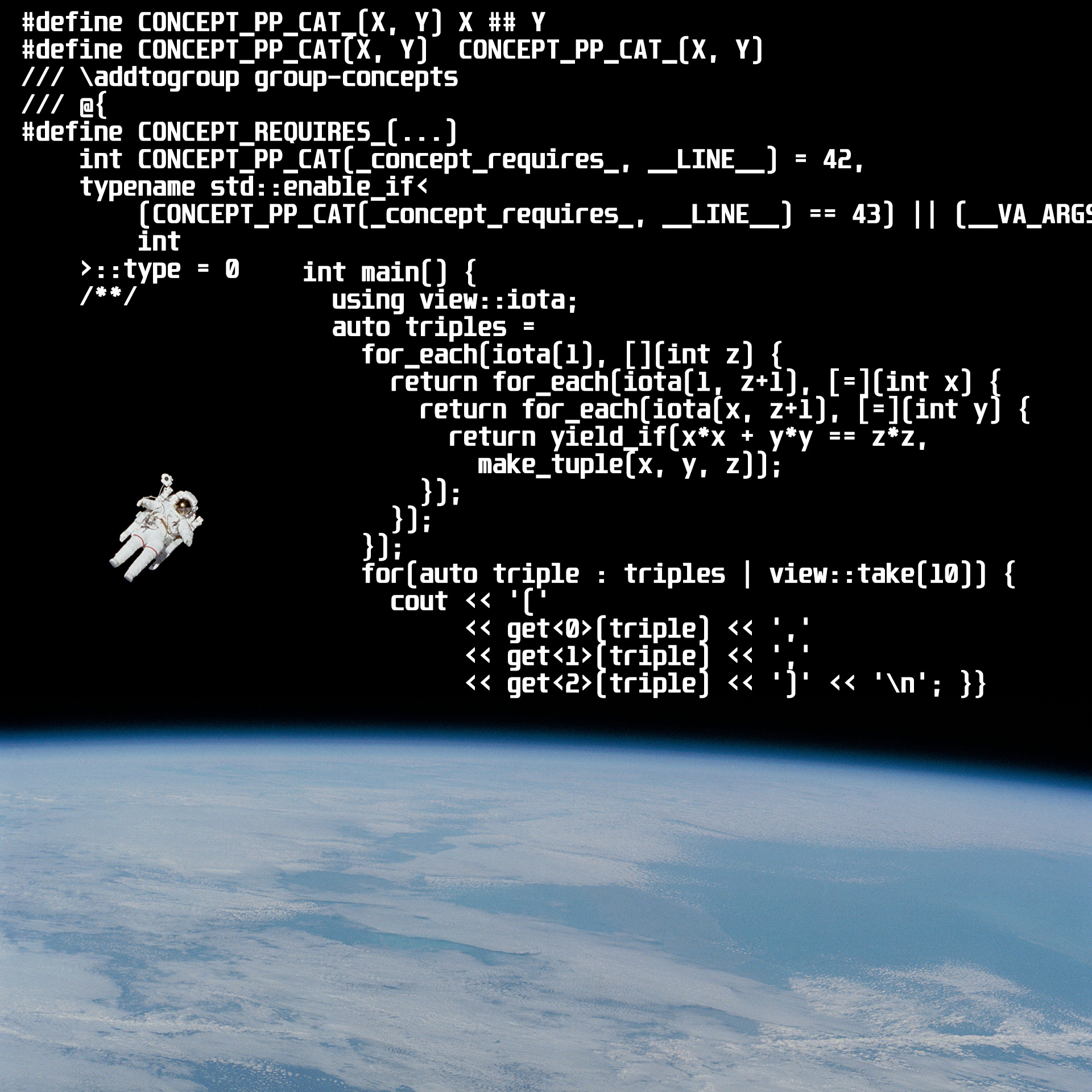
Minuto de publicidad. Ya esta semana , del 19 al 20 de abril, se llevará a cabo C ++ Rusia 2019, una conferencia llena de presentaciones hardcore tanto en el lenguaje como en temas prácticos como el subprocesamiento múltiple y el rendimiento. Por cierto, la conferencia está abierta por Nicolai Josuttis, autor de The C ++ Standard Library: A Tutorial and Reference , mencionado en el artículo. Puede familiarizarse con el programa y comprar boletos en el sitio web oficial . Queda muy poco tiempo, esta es la última oportunidad.