No hace mucho tiempo, me encontré con una tarea bastante simple y al mismo tiempo interesante: implementar un terminal de solo lectura en una aplicación web. El interés en la tarea estuvo dado por tres aspectos importantes:
- soporte para secuencias de escape ANSI básicas
- soporte para al menos 50,000 líneas de datos
- mostrar datos a medida que estén disponibles.
En este artículo hablaré sobre cómo se implementó y cómo lo optimizó todo.
Descargo de responsabilidad: no soy un desarrollador web experimentado, por lo que algunas cosas pueden parecer obvias y las conclusiones o decisiones son incorrectas. Para correcciones y aclaraciones, se lo agradeceré.
¿Por qué fue hasta
Toda la tarea es la siguiente: se ejecuta un script en el servidor (bash, python, etc.) y escribe algo en stdout. Y esta conclusión debe mostrarse en la página web a medida que llega. Al mismo tiempo, debería verse como en el terminal (con formato, transferencias de cursor, etc.)
No controlo el script en sí y su salida de ninguna manera y lo visualizo en forma pura.
Por supuesto, entre la interfaz web y el script debe haber un intermediario: un servidor web. Y si no es para disimular, ya tengo una aplicación web y un servidor, y de alguna manera trabajo. El esquema se parece a esto:

Pero antes, el servidor era responsable del procesamiento y el formateo. Y quería mejorarlo por una gran cantidad de razones:
- doble procesamiento de datos: primero análisis en el servidor, luego transformación en componentes html en el cliente
- algoritmo no óptimo debido a la preparación de datos para el cliente
- carga pesada en el servidor: el procesamiento de la salida de un solo script podría cargar completamente un solo hilo en el servidor
- soporte incompleto para secuencias de escape ANSI
- errores sutiles
- al cliente le fue muy mal mostrando incluso 10k líneas formateadas
Por lo tanto, se decidió transferir toda la lógica de análisis a la aplicación web y dejar solo la transmisión de datos en bruto al servidor
Declaración del problema.
Partes del texto llegan al cliente. El cliente debe analizarlos en componentes: texto sin formato, avance de línea, retorno de carro y comandos ANSI especiales. No hay garantías en la integridad de las partes: un comando o una palabra pueden venir en diferentes paquetes.
Los comandos ANSI pueden afectar el formato del texto (color, fondo, estilo), la posición del cursor (desde donde se debe mostrar el texto posterior) o borrar parte de la pantalla.
Un ejemplo de cómo se ve:

Además, puede haber URL entre el texto que también deben reconocerse y resaltarse.
Tomamos la biblioteca terminada y ...
Comprendí que el procesamiento correcto y rápido de todos los comandos no es una tarea fácil. Por lo tanto, decidí buscar una biblioteca preparada. Y, he aquí , inmediatamente me topé con xterm.js . Un componente listo para usar del terminal, que ya se usa en muchos lugares y, además, "es realmente rápido, incluso incluye un procesador acelerado por GPU" . Este último fue el más importante para mí, porque Finalmente quería obtener un cliente muy rápido.
A pesar de que me gusta escribir mis propias bicicletas, me alegré muchísimo de poder no solo ahorrar tiempo, sino también obtener un montón de funcionalidades útiles de forma gratuita.
Me llevó 2 pm intentar conectar el terminal y no pude hacer frente. Absolutamente
Diferentes alturas de línea, selección torcida, tamaño adaptativo del terminal, una API muy extraña, falta de documentación sensata ...
Pero todavía tenía un poco de inspiración y creía que podía lidiar con estos problemas.
Hasta que alimente mis líneas de prueba de 10k a la terminal ... Murió. Y enterró conmigo los restos de mis esperanzas.
Descripción del algoritmo final.
En primer lugar, copié el algoritmo actual implementado en python y lo adapté para javascript (solo quité las llaves y otro para la sintaxis).
Conocía todos los principales pros y contras del antiguo algoritmo, por lo que solo necesitaba mejorar los lugares ineficaces en él.
Después de deliberación, prueba y error, me decidí por la siguiente opción: dividimos el algoritmo en 2 componentes:
- modelo para analizar texto y almacenar el estado actual de la "terminal"
- mapeo que traduce el modelo a HTML
Modelo (estructura y algoritmo)
- Todas las filas se almacenan en una matriz (número de fila = índice en la matriz)
- Los estilos de texto se almacenan en una matriz separada.
- La posición actual del cursor se almacena y se puede cambiar mediante comandos.
- El algoritmo mismo verifica los datos de entrada carácter por carácter:
- Si esto es solo texto, agréguelo a la línea actual
- Si se produce un salto de línea, aumente el índice de fila actual
- Si este es uno de los caracteres del comando, lo colocamos en el búfer del comando y esperamos el siguiente carácter
- Si el búfer de comando es correcto, ejecute este comando, de lo contrario, escribiremos este búfer como texto
- El modelo notifica a los oyentes qué líneas han cambiado después del procesamiento de texto entrante
En mi implementación, la complejidad del algoritmo es O ( n log n ), donde log n es la preparación de líneas cambiadas para notificación (unicidad y clasificación). Al momento de escribir esto, me di cuenta de que para un caso especial, puede deshacerse de log n , ya que las líneas se agregan con mayor frecuencia al final.
Display
- Muestra texto como elementos HTML.
- Si la cadena ha cambiado, reemplaza completamente todos los elementos de la cadena
- Rompe cada línea en función de los estilos: cada segmento estilizado tiene su propio elemento
Con tal estructura, la prueba es una tarea bastante simple: transferimos el texto al modelo (en un solo paquete o en partes) y simplemente verificamos el estado actual de todas las líneas y estilos en él. Y para mostrar solo algunas pruebas, porque siempre vuelve a dibujar las líneas cambiadas.
Una ventaja importante es también cierta pereza de la pantalla. Si en un texto sobrescribimos la misma línea (por ejemplo, barra de progreso), luego de que el modelo funcione, para mostrarlo se verá como una línea cambiada.
DOM vs lienzo
Me gustaría detenerme un poco en por qué elegí el DOM, aunque el objetivo era el rendimiento. La respuesta es simple: pereza. Para mí, representar todo en Canvas por mi cuenta parece una tarea bastante desalentadora. Mientras se mantiene la usabilidad: resaltar, copiar, cambiar el tamaño de la pantalla, verse ordenado, etc. El ejemplo de xterm.js me mostró claramente que esto no es nada fácil. Su representación en lienzo estaba lejos de ser ideal.
Además, la depuración del árbol DOM en el navegador y la capacidad de cubrir pruebas unitarias es una ventaja importante.
Al final, mi objetivo era 50k líneas, y sabía que el DOM tenía que lidiar con esto, basado en el trabajo del antiguo algoritmo.
Optimizaciones
El algoritmo estaba listo, depurado y funcionaba lenta pero seguramente. Era hora de abrir el perfilador y optimizarlo. Mirando hacia el futuro, diré que la mayoría de las optimizaciones fueron una sorpresa para mí (como suele suceder).
La creación de perfiles se realizó en 10k líneas, cada una de las cuales contenía elementos estilizados. El número total de elementos DOM es de aproximadamente 100k.
No se utilizaron enfoques y herramientas especiales. Solo Chrome Dev Tools y un par de lanzamientos para cada medición. En la práctica, en los lanzamientos, solo diferían los valores absolutos de las mediciones (cuántos segundos completar), pero no la proporción porcentual entre los métodos. Por lo tanto, considero esta técnica condicionalmente suficiente.
A continuación, me gustaría profundizar en más detalles sobre las mejoras más interesantes. Y para empezar, una gráfica de lo que fue:

Todos los gráficos de creación de perfiles se crearon después de la implementación, desoptimizando el código de la memoria.
string.trim
En primer lugar, me encontré con un string.trim incomprensible que consumía una cantidad muy notable de CPU (me parece que esto era alrededor del 10-20%)

trim () es la función básica del lenguaje. ¿Por qué está usando algún tipo de biblioteca? E incluso si se trata de algún tipo de polyfill, ¿por qué activó la última versión de Chrome?
Se busca un poco en Google y se encuentra la respuesta: https://babeljs.io/docs/en/babel-preset-env . Por defecto, habilita polyfill para un número bastante grande de navegadores, y lo hace en la etapa de compilación. La solución para mí fue especificar 'targets': '> 0.25%, not dead'
Pero al final, eliminé la llamada de recorte por completo, ya que no es necesario.
Vue.js
El año pasado, transferí el componente terminal a Vue.js. Ahora tuve que transferirlo de nuevo a vainilla, la razón está en la captura de pantalla a continuación (vea el número de líneas que involucran Vue.js):
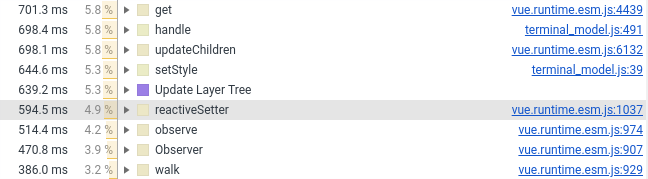
Dejé solo el envoltorio, los estilos y el procesamiento del mouse en el componente Vue. Todo lo relacionado con la creación de elementos DOM entró en JS puro, que está conectado al componente Vue como un campo normal (que no es monitoreado por el marco).
created() { this.terminalModel = new TerminalModel(); this.terminal = new Terminal(this.terminalModel); },
No considero esto un menos o un defecto en Vue.js. Es solo que los marcos y el rendimiento en sí mismos no se mezclan bien. Bueno, cuando sueltas decenas y cientos de miles de objetos en un marco reactivo, es muy difícil esperar que se procese en un par de milisegundos. Y para ser sincero, incluso me sorprende que Vue.js lo haya hecho bastante bien.
Agregar nuevos elementos
Aquí todo es simple: si tiene varios miles de elementos nuevos y desea agregarlos al componente principal, hacer appendChild no es una buena idea. El navegador tiene que hacer el procesamiento un poco más a menudo y dedicar más tiempo a la representación. Uno de los efectos secundarios en mi caso fue una desaceleración en el desplazamiento automático, ya que fuerza un recuento de todos los componentes agregados.

Para resolver el problema, hay un DocumentFragment. Primero, le agregamos todos los elementos, y luego lo agregamos al componente padre. El navegador se encargará de la línea de los componentes entrantes.
Este enfoque reduce la cantidad de tiempo que el navegador dedica a renderizar y organizar elementos.
También probé otras formas de acelerar la adición de elementos. Ninguno de ellos pudo agregar nada encima del DocumentFragment.
span vs div
De hecho, esto podría llamarse display:inline (span) vs display:block (div).
Inicialmente, tenía cada línea en el lapso y terminaba con un carácter de salto de línea. Sin embargo, en términos de rendimiento, esto no es muy efectivo: el navegador tiene que descubrir dónde comienza y dónde termina el elemento. Con display: block, tales cálculos son mucho más simples.
Reemplazar con una representación acelerada div por casi 2 veces.
Desafortunadamente, en el caso de display:block resaltar varias líneas de texto se ve peor:

Durante mucho tiempo no pude decidir cuál es mejor: 2 segundos adicionales de renderizado o selección humana. Como resultado, la practicidad venció a la belleza.
Asistente de CSS de nivel 10
Otro ~ 10% del tiempo de representación se cortó mediante la "optimización" CSS, que utilizo para formatear el texto.
La inexperiencia en el desarrollo web y la comprensión de los conceptos básicos jugaron en mi contra. Pensé que cuanto más precisos fueran los selectores, mejor, pero específicamente en mi caso, esto no fue así.
Para formatear el texto en el terminal, utilicé los siguientes selectores:
#script-panel-container .log-content > div > span.text_color_green,
Pero (en Chrome), la siguiente opción es un poco más rápida:
span.text_color_green
Realmente no me gusta este selector, porque demasiado global, pero el rendimiento es más costoso.
string.split
Si tiene un deja vu debido a uno de los puntos anteriores, entonces es falso. Esta vez no se trata de polyfill, sino de la implementación estándar en Chrome:

(Envolví string.split en defSplit para que la función aparezca en el generador de perfiles)
1% son insignificantes. Pero el ciclista idealista en mí estaba embrujado. En mi caso, la división siempre se realiza un personaje a la vez y sin ningún habitual. Por lo tanto, implementé una opción simple. Aquí está el resultado:

fastSplit function fastSplit(str, separatorChar) { if (str === '') { return ['']; } let result = []; let lastIndex = 0; for (let i = 0; i < str.length; i++) { const char = str[i]; if (char === separatorChar) { const chunk = str.substr(lastIndex, i - lastIndex); lastIndex = i + 1; result.push(chunk); } } if (lastIndex < str.length) { const lastChunk = str.substr(lastIndex, str.length - lastIndex); result.push(lastChunk); } return result; }
Creo que después de esto, están obligados a llevarme al equipo de Google Chrome sin una entrevista.
Optimización, epílogo
La optimización es un proceso sin fin y algo puede mejorarse indefinidamente. Especialmente considerando que diferentes casos de uso requieren optimizaciones diferentes (y conflictivas).
Para mi caso, elegí el caso de uso principal y optimicé su tiempo de operación de 15 segundos a 5 segundos. En esto decidí parar.

Todavía hay un par de lugares que planeo mejorar, pero esto es gracias a la experiencia adquirida.
Bono Prueba de mutación.
Dio la casualidad de que en los últimos meses a menudo me encontré con el término "pruebas mutacionales". Y decidí que esta tarea es una excelente manera de probar esta bestia. Especialmente después de que no obtuve cobertura de código en Webstorm, para pruebas de karma.
Dado que tanto la técnica como la biblioteca son nuevas para mí, decidí sobrevivir con un poco de sangre: probar solo un componente: el modelo. En este caso, puede indicar claramente qué archivo estamos probando y qué conjunto de pruebas está destinado para ello.
Pero sea lo que sea que uno diga, tuve que jugar mucho para lograr la integración con karma y webpack.
Al final, todo comenzó y después de media hora vi resultados tristes: aproximadamente la mitad de los mutantes sobrevivieron. Maté parte inmediatamente, parte restante para el futuro (cuando implementé los comandos ANSI faltantes).
Después de eso, la pereza ganó, y en este momento los resultados son los siguientes (para 128 pruebas):
Ran 79.04 tests per mutant on average. ------------------|---------|----------|-----------|------------|---------| File | % score | # killed | # timeout | # survived | # error | ------------------|---------|----------|-----------|------------|---------| terminal_model.js | 73.10 | 312 | 25 | 124 | 1 | ------------------|---------|----------|-----------|------------|---------| 23:01:08 (18212) INFO Stryker Done in 26 minutes 32 seconds.
En general, este enfoque me pareció muy útil (obviamente mejor que la cobertura del código) y divertido. Lo único negativo es un tiempo terriblemente largo: 30 minutos por clase es demasiado.
Y lo más importante, este enfoque me hizo pensar de nuevo sobre el 100% de cobertura y si vale la pena cubrir todo con pruebas: ahora mi opinión está aún más cerca de "sí" al responder esta pregunta.
Conclusión
La optimización del rendimiento, en mi opinión, es una buena manera de aprender algo más profundo. También es un buen ejercicio para el cerebro. Y es muy lamentable que esto rara vez sea realmente necesario (al menos en mis proyectos).
Y como siempre, el enfoque de "primer perfil, luego optimización" funciona mucho mejor que la intuición.
Referencias
Implementación anterior:
Nueva implementación:
Lamentablemente, no hay una demostración de componentes web, por lo que no podrá introducirla. Así que me disculpo de antemano
¡Gracias por su tiempo, me complacerá comentarios, sugerencias y críticas razonables!