Prólogo
Muy a menudo, los usuarios, desarrolladores y administradores de los DBMS de MS SQL Server enfrentan problemas de rendimiento de la base de datos o DBMS en general, por lo tanto, el monitoreo de MS SQL Server es muy relevante.
Este artículo es una adición al artículo
Uso de Zabbix para monitorear la base de datos de MS SQL Server y examinará algunos aspectos de la supervisión de MS SQL Server, en particular: cómo determinar rápidamente qué recursos faltan, así como recomendaciones para establecer marcas de seguimiento.
Para que los siguientes scripts funcionen, debe crear el esquema inf en la base de datos deseada de la siguiente manera:
Crear un esquema infuse <_>; go create schema inf;
Método para detectar escasez de RAM
El primer indicador de falta de RAM es el caso cuando una instancia de MS SQL Server se come toda la RAM asignada.
Para hacer esto, cree la siguiente vista inf.vRAM:
Crear una vista inf.vRAM CREATE view [inf].[vRAM] as select a.[TotalAvailOSRam_Mb]
Luego puede determinar que la instancia de MS SQL Server consume toda la memoria asignada por la siguiente consulta:
select SQL_server_physical_memory_in_use_Mb, SQL_server_committed_target_Mb from [inf].[vRAM];
Si la métrica SQL_server_physical_memory_in_use_Mb es constantemente al menos SQL_server_committed_target_Mb, entonces debe verificar las estadísticas de expectativas.
Para determinar la falta de RAM a través de las estadísticas de expectativas, cree una vista inf.vWaits:
Crear una vista inf.vWaits CREATE view [inf].[vWaits] as WITH [Waits] AS (SELECT [wait_type],
En este caso, puede determinar la falta de RAM mediante la siguiente consulta:
SELECT [Percentage] ,[AvgWait_S] FROM [inf].[vWaits] where [WaitType] in ( 'PAGEIOLATCH_XX', 'RESOURCE_SEMAPHORE', 'RESOURCE_SEMAPHORE_QUERY_COMPILE' );
Aquí debe prestar atención al rendimiento de Percentage y AvgWait_S. Si son significativos en su totalidad, entonces hay una probabilidad muy alta de que la RAM no sea suficiente para una instancia de MS SQL Server. Los valores esenciales se determinan individualmente para cada sistema. Sin embargo, puede comenzar con la siguiente métrica: Porcentaje> = 1 y AvgWait_S> = 0.005.
Para enviar indicadores a un sistema de monitoreo (por ejemplo, Zabbix), puede crear las siguientes dos consultas:
- cuánto en porcentaje ocupan los tipos de expectativas para RAM (la suma de todos esos tipos de expectativas):
select coalesce(sum([Percentage]), 0.00) as [Percentage] from [inf].[vWaits] where [WaitType] in ( 'PAGEIOLATCH_XX', 'RESOURCE_SEMAPHORE', 'RESOURCE_SEMAPHORE_QUERY_COMPILE' );
- cuántos milisegundos ocupan los tipos de expectativas para RAM (el valor máximo de todos los retrasos promedio para todos esos tipos de expectativas):
select coalesce(max([AvgWait_S])*1000, 0.00) as [AvgWait_MS] from [inf].[vWaits] where [WaitType] in ( 'PAGEIOLATCH_XX', 'RESOURCE_SEMAPHORE', 'RESOURCE_SEMAPHORE_QUERY_COMPILE' );
En función de la dinámica de los valores obtenidos para estos dos indicadores, podemos concluir si hay suficiente RAM para la instancia de MS SQL Server.
Método de detección de sobrecarga de CPU
Para identificar la falta de tiempo de CPU, solo use la vista del sistema sys.dm_os_schedulers. Aquí, si el indicador runnable_tasks_count es constantemente mayor que 1, entonces hay una alta probabilidad de que el número de núcleos no sea suficiente para la instancia de MS SQL Server.
Para mostrar el indicador en un sistema de monitoreo (por ejemplo, Zabbix), puede crear la siguiente consulta:
select max([runnable_tasks_count]) as [runnable_tasks_count] from sys.dm_os_schedulers where scheduler_id<255;
En función de la dinámica de los valores obtenidos para este indicador, podemos concluir si hay suficiente tiempo de procesador (el número de núcleos de CPU) para una instancia de MS SQL Server.
Sin embargo, es importante recordar el hecho de que las solicitudes mismas pueden solicitar varios subprocesos a la vez. Y a veces el optimizador no puede evaluar correctamente la complejidad de la solicitud en sí. Entonces, a la solicitud se le pueden asignar demasiados hilos que en un momento dado no se pueden procesar simultáneamente. Y esto también provoca un tipo de espera asociado con la falta de tiempo de procesador y el crecimiento de la cola para los planificadores que usan núcleos de CPU específicos, es decir, el indicador runnable_tasks_count crecerá en tales condiciones.
En este caso, antes de aumentar el número de núcleos de CPU, debe configurar correctamente las propiedades de paralelismo de la instancia de MS SQL Server y, a partir de la versión 2016, configurar correctamente las propiedades de paralelismo de las bases de datos requeridas:

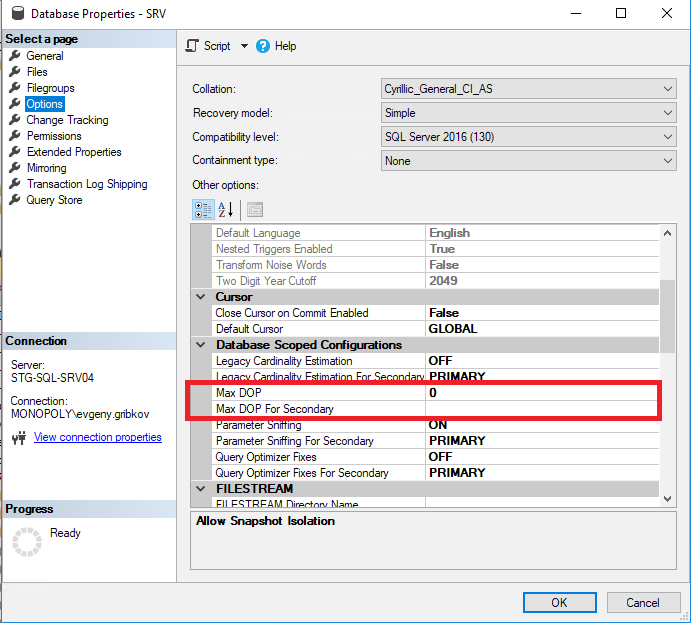
Aquí vale la pena prestar atención a los siguientes parámetros:
- Grado máximo de paralelismo: establece el número máximo de subprocesos que se pueden asignar a cada solicitud (el valor predeterminado es la restricción 0 solo para el sistema operativo y la edición MS SQL Server)
- Umbral de costo para paralelismo: costo estimado de paralelismo (el valor predeterminado es 5)
- Max DOP establece el número máximo de subprocesos que se pueden asignar a cada consulta en el nivel de la base de datos (pero no más que el valor de la propiedad "Grado máximo de paralelismo") (el valor predeterminado es la restricción 0 solo para el sistema operativo y la edición MS SQL Server, así como la restricción en la propiedad "Grado máximo de paralelismo" de toda la instancia de MS SQL Server)
Es imposible dar una receta igualmente buena para todos los casos, es decir, necesita analizar solicitudes difíciles.
Desde mi propia experiencia, recomiendo el siguiente algoritmo de acciones para sistemas OLTP para configurar propiedades de paralelismo:
- primero prohibir la concurrencia estableciendo el nivel de toda la instancia de Max Degree of Parallelism en 1
- analizar las solicitudes más difíciles y elegir el número óptimo de hilos para ellas
- establezca el Grado máximo de paralelismo en el número óptimo seleccionado de subprocesos obtenidos del elemento 2, y para bases de datos específicas establezca el valor DOP máximo obtenido del elemento 2 para cada base de datos
- Analice las solicitudes más difíciles e identifique el efecto negativo del subprocesamiento múltiple. Si es así, aumente el umbral de costo para paralelismo.
Para sistemas como 1C, Microsoft CRM y Microsoft NAV, en la mayoría de los casos, la prohibición de subprocesamiento múltiple es adecuada.
Además, si se instala la edición Standard, en la mayoría de los casos la prohibición de subprocesos múltiples es adecuada en vista del hecho de que esta edición está limitada por el número de núcleos de CPU.
Para los sistemas OLAP, el algoritmo descrito anteriormente no es adecuado.
Desde mi propia experiencia, recomiendo el siguiente algoritmo de acciones para sistemas OLAP para establecer propiedades de paralelismo:
- analizar las solicitudes más difíciles y elegir el número óptimo de hilos para ellas
- establezca el Grado máximo de paralelismo en el número óptimo seleccionado de subprocesos obtenidos del elemento 1, y también para bases de datos específicas establezca el valor DOP máximo obtenido del elemento 1 para cada base de datos
- analizar las solicitudes más difíciles e identificar el efecto negativo del límite de concurrencia. Si es así, reduzca el Umbral de costo para el valor de paralelismo o repita los pasos 1-2 de este algoritmo
Es decir, para sistemas OLTP pasamos de subprocesos simples a subprocesos múltiples, y para sistemas OLAP, por el contrario, pasamos de subprocesos múltiples a subprocesos simples. Por lo tanto, es posible seleccionar la configuración de concurrencia óptima tanto para una base de datos específica como para toda la instancia de MS SQL Server.
También es importante comprender que la configuración de las propiedades de concurrencia debe cambiarse con el tiempo en función de los resultados de la supervisión del rendimiento de MS SQL Server.
Recomendaciones para establecer marcas de seguimiento
Desde mi propia experiencia y la experiencia de mis colegas, recomiendo configurar los siguientes indicadores de seguimiento en el nivel de inicio del servicio MS SQL Server para las versiones 2008-2016 para un rendimiento óptimo:
- 610 - Reducción del registro de inserciones en tablas indexadas. Puede ayudar con las inserciones en tablas con una gran cantidad de registros y muchas transacciones, con frecuentes expectativas largas de WRITELOG para cambios en los índices
- 1117 - Si un archivo en un grupo de archivos cumple con el umbral de crecimiento automático, todos los archivos en el grupo de archivos se expanden
- 1118: fuerza que todos los objetos se ubiquen en diferentes extensiones (prohibición de extensiones mixtas), lo que minimiza la necesidad de escanear la página SGAM, que se utiliza para rastrear extensiones mixtas
- 1224: deshabilita la escalada de bloqueo en función del número de bloqueos. El uso excesivo de memoria puede incluir la escalada de bloqueo.
- 2371: cambia el umbral para las actualizaciones de estadísticas automáticas fijas al umbral para las actualizaciones de estadísticas automáticas dinámicas. Es importante actualizar los planes de consulta para tablas grandes donde determinar incorrectamente el número de registros conduce a planes de ejecución erróneos.
- 3226 - Suprime los mensajes de respaldo exitosos en el registro de errores
- 4199: incluye cambios en el optimizador de consultas publicados en la actualización acumulativa y los paquetes de servicio de SQL Server
- 6532-6534: incluye un rendimiento de consulta mejorado para tipos de datos espaciales
- 8048 - Convierte objetos de memoria particionados NUMA en particiones de CPU
- 8780: habilita la asignación de tiempo adicional para programar una solicitud. Algunas solicitudes sin este indicador pueden rechazarse porque no tienen un plan de solicitud (error muy raro)
- 9389: incluye un búfer de memoria dinámico adicional provisto temporalmente para operadores en modo por lotes, que permite al operador en modo por lotes solicitar memoria adicional y evitar transferir datos a tempdb si hay memoria adicional disponible
Antes de la versión 2016, es útil incluir el indicador de seguimiento 2301, que incluye la optimización del soporte de decisiones ampliado y, por lo tanto, ayuda a elegir planes de consulta más correctos. Sin embargo, a partir de la versión 2016, a menudo tiene un efecto negativo en un tiempo de ejecución de consulta general bastante largo.
Además, para sistemas en los que hay muchos índices (por ejemplo, para bases de datos 1C), le recomiendo que habilite el indicador de traza 2330, que deshabilita la recopilación sobre el uso de índices, que generalmente tiene un efecto positivo en el sistema.
Obtenga más información sobre las marcas de seguimiento
aquí .
Usando el enlace anterior, también es importante considerar las versiones y ensamblajes de MS SQL Server, porque para las versiones más nuevas, algunos indicadores de rastreo están habilitados de manera predeterminada o no tienen ningún efecto. Por ejemplo, en la versión 2017, es relevante establecer solo los siguientes 5 indicadores de seguimiento: 1224, 3226, 6534, 8780 y 9389.
Puede habilitar o deshabilitar el indicador de rastreo utilizando los comandos DBCC TRACEON y DBCC TRACEOFF, respectivamente. Ver
aquí para más detalles.
Puede obtener el estado de las marcas de rastreo con el comando DBCC TRACESTATUS:
más .
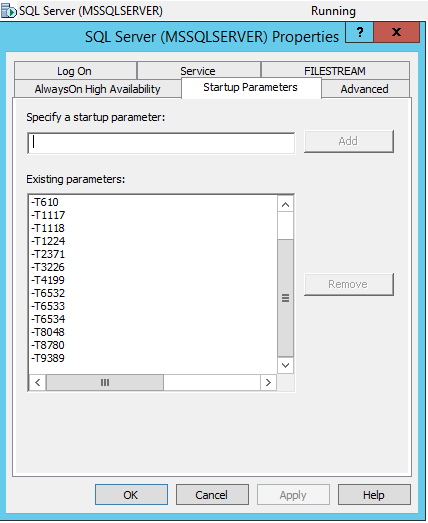
Para que los indicadores de seguimiento se incluyan en la ejecución automática del servicio MS SQL Server, debe ir al Administrador de configuración de SQL Server y agregar estos indicadores de seguimiento en las propiedades del servicio a través de -T:
Resumen
En este artículo, se examinaron algunos aspectos de la supervisión de MS SQL Server, con la ayuda de los cuales puede identificar rápidamente la falta de RAM y tiempo libre de CPU, así como una serie de otros problemas menos obvios. Se consideraron los indicadores de rastreo más utilizados.
Fuentes
»
Estadísticas en espera de SQL Server»
Estadísticas de expectativas de SQL Server o dígame dónde le duele»
Vista del sistema sys.dm_os_schedulers»
Usando Zabbix para rastrear la base de datos MS SQL Server»
Estilo de vida SQL»
Trazar banderas»
Sql.ru