
El 1 de abril, finalizó la final de SNA Hackathon 2019 , cuyos participantes compitieron en la clasificación de la red social utilizando tecnologías modernas de aprendizaje automático, visión por computadora, procesamiento de pruebas y sistemas de recomendación. La selección en línea y los dos días de duro trabajo con 160 gigabytes de datos no fueron en vano :). Hablamos sobre lo que ayudó a los participantes a alcanzar el éxito y sobre otras observaciones interesantes.
Sobre datos y tareas
La competencia presentó datos de los mecanismos para preparar el feed para los usuarios de la red social OK , que consta de tres partes:
- los registros de visualización de contenido en feeds de usuario con una gran cantidad de atributos que describen el usuario, el contenido, el autor y otras propiedades;
- textos relacionados con el contenido mostrado;
- cuerpos de imágenes utilizadas en el contenido.
La cantidad total de datos supera los 160 gigabytes, de los cuales más de 3 representan registros, 3 más para textos y el resto para imágenes. La gran cantidad de datos no asustó a los participantes: según las estadísticas de ML Bootcamp , casi 200 personas participaron en la competencia, quienes enviaron más de 3,000 envíos, y los más activos lograron romper el listón de 100 soluciones enviadas. Tal vez fueron motivados por el premio acumulado de 700,000 rublos + 3 tarjetas gráficas GTX 2080 Ti.

Los participantes de la competencia necesitaban resolver el problema de clasificar la cinta: para cada usuario individual, clasifique los objetos mostrados de tal manera que aquellos que obtuvieron la marca “¡Clase!” Estuvieran más cerca del encabezado de la lista.
ROC-AUC se utilizó como medida de evaluación de calidad. Al mismo tiempo, la métrica no se consideró para todos los datos en su conjunto, sino por separado para cada usuario y luego se promedió. Esta opción de cálculo es notable porque los algoritmos que han aprendido a distinguir a los usuarios que ponen en muchas clases no reciben ventajas. Por otro lado, no existe tal opción en los paquetes estándar de Python, que revelaron algunos puntos interesantes, que se analizan a continuación.
Acerca de la tecnología
Tradicionalmente, SNA Hackathon no es solo algoritmos, sino también tecnologías: el volumen de datos enviados supera los 160 gigabytes, lo que coloca a los participantes frente a interesantes tareas técnicas.
Parquet vs. CSV
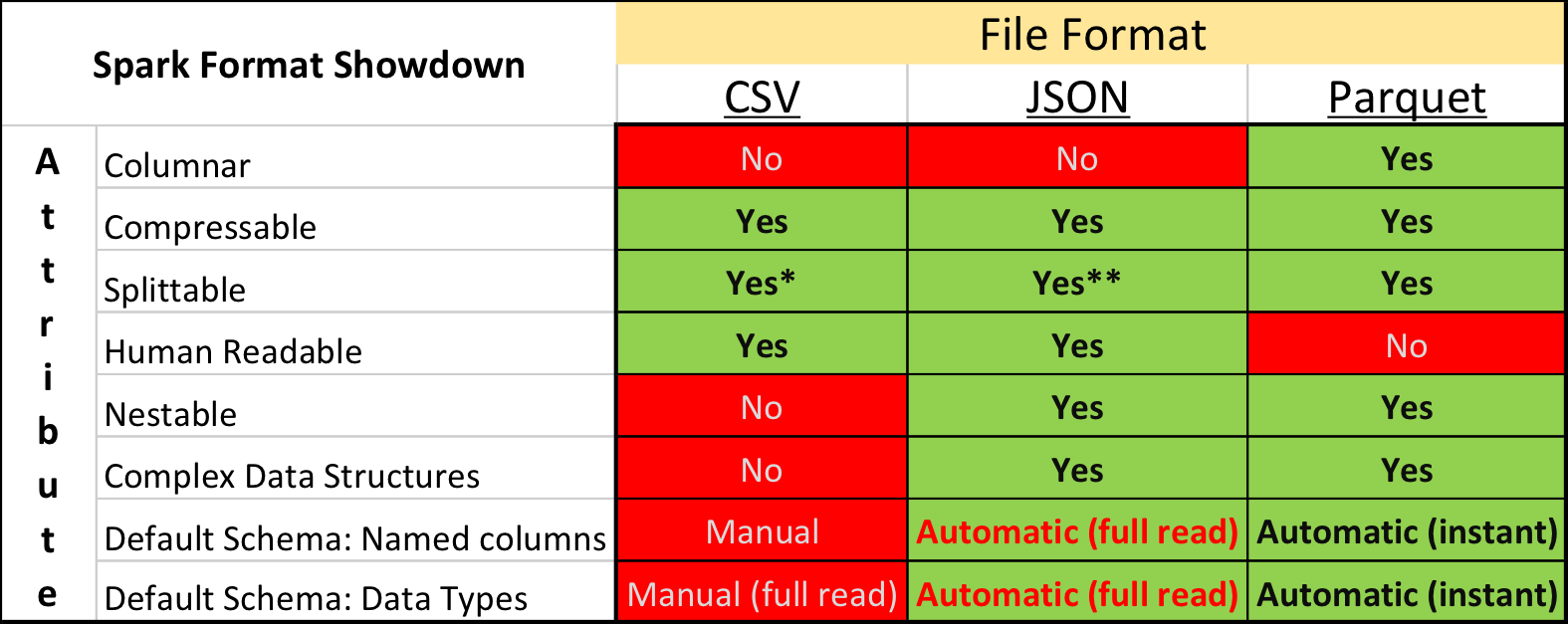
En la investigación académica y en Kaggle, el formato de datos dominante es CSV , así como otros formatos de texto sin formato. Sin embargo, la situación en la industria es algo diferente: se pueden lograr velocidades de procesamiento significativamente más compactas utilizando formatos de almacenamiento "binarios".
En particular, en el ecosistema construido sobre la base de Apache Spark , Apache Parquet es el más popular: un formato de almacenamiento de datos en columna con soporte para muchas características operativas importantes:
- un circuito explícitamente especificado con soporte de evolución;
- leer solo las columnas necesarias del disco;
- soporte básico para índices y filtros al leer;
- Compresión de cuerda.
Pero a pesar de las ventajas obvias, el envío de datos para la competencia en el formato Apache Parquet recibió severas críticas de algunos participantes. Además del conservadurismo y la falta de voluntad para pasar el tiempo desarrollando algo nuevo, hubo varios momentos realmente desagradables.
En primer lugar, el soporte para el formato en la biblioteca Apache Arrow , la herramienta principal para trabajar con Parquet de Python, está lejos de ser perfecto. Al preparar los datos, todos los campos estructurales tuvieron que expandirse a planos, y aún así, al leer textos, muchos participantes encontraron un error y se vieron obligados a instalar la biblioteca de la versión anterior 0.11.1 en lugar de la versión actual 0.12. En segundo lugar, no mirará el archivo Parquet utilizando utilidades de consola simples: cat, less, etc. Sin embargo, este inconveniente es relativamente fácil de compensar por el uso del paquete de herramientas de parquet .
Sin embargo, aquellos que inicialmente intentaron convertir todos los datos a CSV y luego trabajar en el entorno familiar, finalmente abandonaron esta idea; después de todo, Parquet funciona significativamente más rápido.
Impulso y GPU

En la conferencia SmartData en San Petersburgo, "ampliamente conocido en círculos estrechos", Alexey Natekin comparó el rendimiento de varias herramientas de refuerzo populares mientras trabajaba en la CPU / GPU y llegó a la conclusión de que la GPU no proporciona una ganancia tangible. Pero incluso entonces, esta conclusión condujo a una polémica activa, principalmente con los desarrolladores de la herramienta CatBoost doméstica.
En los últimos dos años, el progreso en el desarrollo de GPU y la adaptación de algoritmos no se detuvo y la final de SNA Hackathon puede considerarse un triunfo del par CatBoost + GPU: todos los ganadores lo usaron y sacaron la métrica principalmente debido a la capacidad de cultivar más árboles por unidad de tiempo.
La implementación integrada de la codificación objetivo media también contribuyó al alto resultado de las soluciones basadas en CatBoost, pero el número y la profundidad de los árboles dieron un aumento más significativo.
Otras herramientas de impulso se están moviendo en una dirección similar, agregando y mejorando el soporte de GPU. ¡Así que cultiva más árboles!
Spark vs. Pyspark

La herramienta Apache Spark es un líder sólido en Data Science industrial, gracias en parte a la API de Python. Sin embargo, el uso de Python viene con una sobrecarga adicional para la integración entre diferentes tiempos de ejecución y trabajo de intérprete.
Esto en sí mismo no es un problema si el usuario es consciente de la medida en que la cantidad de costos adicionales conduce a una acción particular. Sin embargo, resultó que muchos no se dan cuenta de la magnitud del problema, a pesar de que los participantes no usaron Apache Spark, discusiones sobre Python vs. Scala apareció regularmente en el chat de hackathon, lo que condujo a la aparición de la publicación analizada correspondiente.
En resumen, la desaceleración del uso de Spark a través de Python en comparación con el uso de Spark a través de Scala / Java se puede dividir en los siguientes niveles:
- solo la API Spark SQL se usa sin funciones definidas por el usuario (UDF); en este caso, prácticamente no hay sobrecarga, ya que todo el plan de ejecución de consultas se calcula dentro del marco de la JVM;
- UDF se usa en Python sin llamar a paquetes con código C ++; en este caso, el rendimiento de la etapa en la que se calcula UDF cae 7-10 veces ;
- UDF se usa en Python con acceso al paquete C ++ (numpy, sklearn, etc.); en este caso, el rendimiento cae de 10 a 50 veces .
En parte, el efecto negativo se puede compensar mediante el uso de PyPy (JIT para Python) y UDF vectorizados , sin embargo, en estos casos, la diferencia en el rendimiento es múltiple, y la complejidad de la implementación y la implementación viene con una "bonificación" adicional.
Acerca de Algoritmos
Pero lo más interesante de los hackatones de Data Science es, por supuesto, no las tecnologías, sino nuevos algoritmos probados y de moda. CatBoost dominó SNA Hackathon este año, pero hubo varios enfoques alternativos. Hablaremos de ellos :).
Gráficos diferenciables

Una de las primeras publicaciones de decisiones basadas en los resultados de la ronda de clasificación se dedicó no a los árboles, sino a gráficos diferenciables (también llamados redes neuronales artificiales). El autor es un empleado de OK, por lo que no puede permitirse el lujo de perseguir premios, sino que disfruta creando una solución prometedora sobre la base de una base matemática sólida.
La idea principal de la solución propuesta era construir un único gráfico computacional diferenciable que traduzca las características disponibles en un pronóstico que tenga en cuenta varios aspectos de los datos de entrada:
- las uniones de objeto y usuario le permiten agregar un elemento de recomendaciones colaborativas clásicas;
- la transición de la inclusión escalar a la agregación a través de MLP le permite agregar características arbitrarias;
- La atención al valor de la clave de consulta permitió que el modelo se adaptara dinámicamente al comportamiento de incluso un usuario previamente desconocido que miraba su historial reciente.
Este modelo demostró ser muy bueno en la selección en línea para resolver el problema de recomendar contenido de texto, por lo que varios equipos trataron de jugarlo en la final a la vez, sin embargo, no tuvieron éxito. Esto se debió en parte al hecho de que esto requiere tiempo y experiencia, y en parte al hecho de que el número de atributos en la final fue mucho mayor y los métodos basados en árboles recibieron una ventaja significativa debido a ellos.
Dominante colaborativo

Por supuesto, al organizar el concurso, sabíamos que había una señal bastante fuerte en los registros, porque los signos recogidos allí reflejan una parte significativa del trabajo realizado en OK para clasificar el feed. Sin embargo, hasta el final, esperaban que los participantes tuvieran éxito en hacer frente a la "maldición del tercer personaje", situaciones en las que grandes recursos humanos y de máquinas invertidos en el desarrollo de un modelo para extraer atributos del contenido (textos y fotos) dan como resultado ganancias de calidad extremadamente modestas en comparación con las que ya existen. rasgos preparados, principalmente colaborativos.
Al conocer este problema, inicialmente dividimos la tarea en tres pistas en la ronda de clasificación y formamos un conjunto de datos combinados solo en la final, pero en el formato de hackathon con una métrica fija, los equipos que invirtieron en el desarrollo de modelos de contenido se encontraron en una situación de pérdida deliberada en comparación con los equipos que desarrollaron colaboración parte
El premio del jurado ayudó a compensar esta injusticia ...
Cluster profundo

Lo cual fue casi unánimemente otorgado por el trabajo de reproducción y prueba del algoritmo Deep Cluster de Facebook. El método de marcado inicial simple y que no requiere la creación de clústeres e incrustaciones de imágenes impresas con ideas novedosas y resultados prometedores.
La esencia del método es extremadamente simple:
- calcular vectores de incrustación para imágenes con cualquier red neuronal significativa;
- agrupar los vectores en el espacio resultante con k-medias;
- entrenar a un clasificador de redes neuronales para predecir un grupo de imágenes;
- repita los pasos 2-3 hasta la convergencia (si tiene 800 GPU) o mientras haya suficiente tiempo.
Con un mínimo de esfuerzos, logramos obtener una agrupación de alta calidad de imágenes OK, buenas incorporaciones y un aumento métrico en el tercer dígito.
Mirar hacia el futuro

En cualquier dato puede encontrar "lagunas" para mejorar el pronóstico. Esto en sí mismo no es tan malo, es mucho peor si las lagunas se encuentran y durante mucho tiempo aparecen solo en forma de discrepancias incomprensibles entre los resultados de la validación de los datos históricos y las pruebas A / B.
Una de las lagunas más extendidas de este tipo es el uso de información del futuro. Dicha información es a menudo una señal muy fuerte y el algoritmo de aprendizaje automático, si está habilitado, comenzará a usarla con confianza. Cuando crea un modelo para su producto, intenta de todas las formas posibles evitar la filtración de información en el futuro, pero en el hackathon esta es una buena oportunidad para aumentar la métrica, que fue utilizada por los participantes.
La escapatoria más obvia fue la presencia de numLikes y numDislikes en estos campos con recuentos de reacciones en el objeto en el momento del espectáculo. Al comparar los dos eventos más cercanos en el tiempo relacionados con el mismo objeto, fue posible determinar con alta precisión cuál fue la reacción al objeto en el primero de ellos. Hubo varios contadores similares en los datos, y su uso dio una ventaja notable. Naturalmente, en el uso real, dicha información no estará disponible.
En la vida, se puede encontrar un problema similar sin darse cuenta, generalmente con resultados negativos. Por ejemplo, contando estadísticas sobre el número de marcas "¡Clase!" para el objeto de acuerdo con todos los datos y tomándolo como un atributo separado. O, como lo hicieron en uno de los equipos participantes, agregar un identificador de objeto al modelo como un atributo categórico. En un conjunto de entrenamiento, un modelo con tal característica funciona bien, pero no puede generalizarse a un conjunto de prueba.
En lugar de una conclusión

Todos los materiales del concurso, incluidos los datos y las presentaciones de las decisiones de los participantes, están disponibles en Mail.ru Cloud . Los datos están disponibles para su uso por proyectos de investigación sin restricciones, excepto por la disponibilidad de enlaces. Para la historia, dejemos la tabla final aquí con las métricas de los equipos finales:
- Scala agachada, ocultando Python - 0.7422, analizando la solución está disponible aquí , y el código está aquí y aquí .
- Ciudad Mágica - 0.7256
- Kéfir - 0.7226
- Equipo 6 - 0.7205
- Tres en un bote - 0.7188
- Pabellón # 14 - 0.7167 y premio del jurado
- BezSNA - 0.7147
- PONGA - 0.7117
- Equipo 5 - 0.7112
SNA Hackathon 2019, como los eventos anteriores de la serie, fue un éxito en todos los sentidos. Logramos reunir profesionales geniales en diferentes campos bajo un mismo techo y pasamos un tiempo fructífero, por lo que muchas gracias a los propios participantes y a todos los que ayudaron con la organización.
¿Se podría haber hecho algo aún mejor? Por supuesto que si! Cada competencia que se celebra nos enriquece con una nueva experiencia, que tenemos en cuenta al preparar la próxima y no nos detendremos allí. ¡Hasta pronto en el SNA Hackathon!