El progreso en el campo de las redes neuronales en general y el reconocimiento de patrones en particular ha llevado al hecho de que puede parecer que crear una aplicación de red neuronal para trabajar con imágenes es una tarea rutinaria. En cierto sentido, lo es: si se te ocurrió una idea relacionada con el reconocimiento de patrones, no dudes que alguien ya escribió algo así. Todo lo que se requiere de usted es encontrar el código correspondiente en Google y "compilarlo" del autor.
Sin embargo, todavía hay numerosos detalles que hacen que la tarea no sea tan irresoluble como ... aburrida, diría yo. Lleva demasiado tiempo, especialmente si eres un principiante que necesita liderazgo, paso a paso, un proyecto llevado a cabo ante tus ojos y completado de principio a fin. Sin lo habitual en tales casos, excusas de "saltear esta parte obvia".
En este artículo, consideraremos la tarea de crear un Identificador de raza de perro: crearemos y entrenaremos una red neuronal, y luego la trasladaremos a Java para Android y la publicaremos en Google Play.
Si desea ver el resultado final, aquí está:
Aplicación NeuroDog en Google Play.
Sitio web con mi robótica (en progreso):
robotics.snowcron.com .
Sitio web con el programa en sí, que incluye una guía:
Guía del usuario de NeuroDog .
Y aquí hay una captura de pantalla del programa:
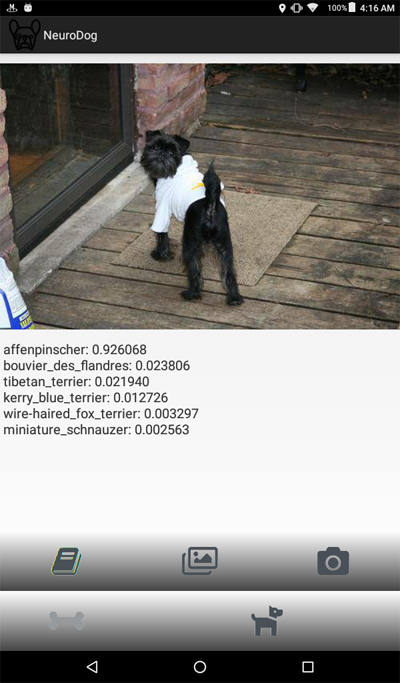
Declaración del problema.
Utilizaremos Keras: una biblioteca de Google para trabajar con redes neuronales. Esta es una biblioteca de alto nivel, lo que significa que es más fácil de usar en comparación con las alternativas que conozco. En todo caso, hay muchos libros de texto en Keras en la red, de alta calidad.
Utilizaremos CNN - Redes neuronales convolucionales. CNN (y configuraciones más avanzadas basadas en ellos) son el estándar de facto en reconocimiento de imágenes. Al mismo tiempo, entrenar una red de este tipo no siempre es fácil: debe elegir la estructura de red correcta, los parámetros de entrenamiento (todos estos índices de aprendizaje, impulso, L1 y L2, etc.). La tarea requiere importantes recursos informáticos y, por lo tanto, resolverla simplemente pasando por TODOS los parámetros fallará.
Esta es una de varias razones por las cuales en la mayoría de los casos usan el llamado "conocimiento de transferencia", en lugar del llamado enfoque "vainilla". Transfer Knowlege utiliza una red neuronal entrenada por alguien antes que nosotros (por ejemplo, Google) y generalmente para una tarea similar pero diferente. Tomamos las capas iniciales, reemplazamos las capas finales con nuestro propio clasificador, y funciona, y funciona muy bien.
Al principio, tal resultado puede ser sorprendente: ¿cómo es que tomamos una red de Google entrenada para distinguir gatos de sillas y reconoce razas de perros para nosotros? Para comprender cómo sucede esto, debe comprender los principios básicos del trabajo de las Redes neuronales profundas, incluidos los utilizados para el reconocimiento de patrones.
"Alimentamos" a la red una imagen (una matriz de números, es decir) como entrada. La primera capa analiza la imagen en busca de patrones simples, como "línea horizontal", "arco", etc. La siguiente capa recibe estos patrones como entrada, y produce patrones de segundo orden, como "pelaje", "esquina del ojo" ... En última instancia, obtenemos un rompecabezas desde el cual podemos reconstruir al perro: lana, dos ojos y una mano humana en los dientes.
Todo lo anterior se realizó con la ayuda de capas pre-entrenadas obtenidas por nosotros (por ejemplo, de Google). A continuación, agregamos nuestras capas y les enseñamos a extraer información de raza de estos patrones. Suena lógico
Para resumir, en este artículo crearemos CNN "vainilla" y varias variantes de "aprendizaje de transferencia" de diferentes tipos de redes. En cuanto a "vainilla": lo crearé, pero no planeo configurarlo seleccionando parámetros, ya que es mucho más fácil entrenar y configurar redes "pre-entrenadas".
Como planeamos enseñar a nuestra red neuronal a reconocer razas de perros, debemos "mostrarle" muestras de varias razas. Afortunadamente, hay un conjunto de fotografías creadas
aquí para una tarea similar (el
original está aquí ).
Entonces planeo portar la mejor de las redes recibidas para Android. Portar redes Kerasov a Android es relativamente simple, bien formalizado y haremos todos los pasos necesarios, por lo que no será difícil reproducir esta parte.
Luego publicaremos todo esto en Google Play. Naturalmente, Google resistirá, por lo que se utilizarán trucos adicionales. Por ejemplo, el tamaño de nuestra aplicación (debido a una red neuronal voluminosa) será mayor que el tamaño permitido del APK de Android aceptado por Google Play: tendremos que usar paquetes. Además, Google no mostrará nuestra aplicación en los resultados de búsqueda, esto se puede solucionar registrando etiquetas de búsqueda en la aplicación, o simplemente esperando ... una o dos semanas.
Como resultado, obtenemos una aplicación "comercial" completamente funcional (entre comillas, como se presenta de forma gratuita) para Android y que utiliza redes neuronales.
Entorno de desarrollo
Puede programar Keras de manera diferente, dependiendo del sistema operativo que utilice (se recomienda Ubuntu), la presencia o ausencia de una tarjeta de video, etc. No hay nada malo en el desarrollo en la computadora local (y, en consecuencia, su configuración), excepto que esta no es la forma más fácil.
Primero, instalar y configurar una gran cantidad de herramientas y bibliotecas lleva tiempo, y luego, cuando se lanzan nuevas versiones, tendrá que pasar tiempo nuevamente. En segundo lugar, las redes neuronales requieren una gran potencia informática para el entrenamiento. Puede acelerar (10 veces o más) este proceso si usa una GPU ... al momento de escribir este artículo, las GPU más adecuadas para este trabajo cuestan $ 2,000 - $ 7,000. Y sí, también deben configurarse.
Entonces iremos por el otro lado. El hecho es que Google permite que los erizos pobres como nosotros usen GPU de su clúster: de forma gratuita, para los cálculos relacionados con las redes neuronales, también proporciona un entorno totalmente configurado, todo junto, esto se llama Google Colab. El servicio le da acceso a Jupiter Notebook con python, Keras y una gran cantidad de otras bibliotecas ya configuradas. Todo lo que tiene que hacer es obtener una cuenta de Google (obtenga una cuenta de Gmail y esto le dará acceso a todo lo demás).
Por el momento, Colab puede ser contratado
aquí , pero conociendo Google, esto puede cambiar en cualquier momento. Simplemente google Google Colab.
El problema obvio con el uso de Colab es que es un servicio WEB. ¿Cómo accedemos a nuestros datos? ¿Guardar la red neuronal después del entrenamiento, por ejemplo, descargar datos específicos de nuestra tarea, etc.?
Hay varias (al momento de escribir este artículo, tres) diferentes formas, utilizamos la que creo que es más conveniente: usamos Google Drive.
Google Drive es un almacenamiento de datos basado en la nube que funciona de manera muy similar a un disco duro normal, y puede mapearse en Google Colab (consulte el código a continuación). Después de eso, puede trabajar con él como lo haría con archivos en un disco local. Es decir, por ejemplo, para acceder a las fotos de perros para entrenar nuestra red neuronal, necesitamos subirlos a Google Drive, eso es todo.
Crear y entrenar una red neuronal
A continuación doy el código en Python, bloque por bloque (del cuaderno de Júpiter). Puede copiar este código en su Jupiter Notebook y ejecutarlo, bloque por bloque, también, ya que los bloques se pueden ejecutar de forma independiente (por supuesto, las variables definidas en el bloque inicial pueden ser necesarias en el último, pero esta es una dependencia obvia).
Inicialización
En primer lugar, montemos Google Drive. Solo dos líneas. Este código debe ejecutarse solo una vez en una sesión de Colab (por ejemplo, una vez cada 6 horas). Si lo llama por segunda vez mientras la sesión aún está "activa", se omitirá ya que la unidad ya está montada.
from google.colab import drive drive.mount('/content/drive/')
Al principio, se le pedirá que confirme sus intenciones, no hay nada complicado. Así es como se ve:
>>> Go to this URL in a browser: ... >>> Enter your authorization code: >>> ·········· >>> Mounted at /content/drive/
Una sección de
inclusión completamente estándar; es posible que algunos de los archivos incluidos no sean necesarios, bueno ... lo siento. Además, dado que voy a probar diferentes redes neuronales, tendrá que comentar / descomentar algunos de los módulos incluidos para tipos específicos de redes neuronales: por ejemplo, para usar InceptionV3 NN, descomentar la inclusión de InceptionV3 y comentar, por ejemplo, ResNet50. O no: todo lo que cambia de esto es el tamaño de la memoria utilizada, y eso no es muy fuerte.
import datetime as dt import pandas as pd import seaborn as sns import matplotlib.pyplot as plt from tqdm import tqdm import cv2 import numpy as np import os import sys import random import warnings from sklearn.model_selection import train_test_split import keras from keras import backend as K from keras import regularizers from keras.models import Sequential from keras.models import Model from keras.layers import Dense, Dropout, Activation from keras.layers import Flatten, Conv2D from keras.layers import MaxPooling2D from keras.layers import BatchNormalization, Input from keras.layers import Dropout, GlobalAveragePooling2D from keras.callbacks import Callback, EarlyStopping from keras.callbacks import ReduceLROnPlateau from keras.callbacks import ModelCheckpoint import shutil from keras.applications.vgg16 import preprocess_input from keras.preprocessing import image from keras.preprocessing.image import ImageDataGenerator from keras.models import load_model from keras.applications.resnet50 import ResNet50 from keras.applications.resnet50 import preprocess_input from keras.applications.resnet50 import decode_predictions from keras.applications import inception_v3 from keras.applications.inception_v3 import InceptionV3 from keras.applications.inception_v3 import preprocess_input as inception_v3_preprocessor from keras.applications.mobilenetv2 import MobileNetV2 from keras.applications.nasnet import NASNetMobile
En Google Drive, creamos una carpeta para nuestros archivos. La segunda línea muestra su contenido:
working_path = "/content/drive/My Drive/DeepDogBreed/data/" !ls "/content/drive/My Drive/DeepDogBreed/data" >>> all_images labels.csv models test train valid
Como puede ver, las fotos de los perros (copiadas del conjunto de datos de Stanford (ver arriba) en Google Drive) se guardan primero en la carpeta
all_images . Más tarde, los copiaremos en los directorios de
trenes, válidos y de
prueba . Guardaremos modelos entrenados en la carpeta de
modelos . En cuanto al archivo labels.csv, esto es parte del conjunto de datos con fotos, contiene una tabla de correspondencia de los nombres de imágenes y razas de perros.
Hay muchas pruebas que puede ejecutar para comprender qué obtuvimos exactamente para el uso temporal de Google. Por ejemplo:
Como puede ver, la GPU está realmente conectada, y si no, necesita encontrar y habilitar esta opción en la configuración de Jupiter Notebook.
A continuación, debemos declarar algunas constantes, como el tamaño de las imágenes, etc. Utilizaremos imágenes con un tamaño de 256x256 píxeles, esta es una imagen lo suficientemente grande como para no perder detalles, y lo suficientemente pequeña como para que todo encaje en la memoria. Sin embargo, tenga en cuenta que algunos tipos de redes neuronales que utilizaremos esperan imágenes de 224x224 píxeles. En tales casos, comentamos 256 y descomentamos 224.
Se aplicará el mismo enfoque (comentario uno: descomentar) a los nombres de los modelos que guardamos, simplemente porque no queremos sobrescribir archivos que aún pueden ser útiles.
warnings.filterwarnings("ignore") os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' np.random.seed(7) start = dt.datetime.now() BATCH_SIZE = 16 EPOCHS = 15 TESTING_SPLIT=0.3
Carga de datos
En primer lugar,
carguemos el archivo
labels.csv y
divídalo en las partes de capacitación y validación. Tenga en cuenta que todavía no hay una parte de prueba, ya que voy a hacer trampa para obtener más datos de entrenamiento.
labels = pd.read_csv(working_path + 'labels.csv') print(labels.head()) train_ids, valid_ids = train_test_split(labels, test_size = TESTING_SPLIT) print(len(train_ids), 'train ids', len(valid_ids), 'validation ids') print('Total', len(labels), 'testing images') >>> id breed >>> 0 000bec180eb18c7604dcecc8fe0dba07 boston_bull >>> 1 001513dfcb2ffafc82cccf4d8bbaba97 dingo >>> 2 001cdf01b096e06d78e9e5112d419397 pekinese >>> 3 00214f311d5d2247d5dfe4fe24b2303d bluetick >>> 4 0021f9ceb3235effd7fcde7f7538ed62 golden_retriever >>> 7155 train ids 3067 validation ids >>> Total 10222 testing images
Luego, copie los archivos de imagen a las carpetas de capacitación / validación / prueba, de acuerdo con los nombres de los archivos. La siguiente función copia los archivos cuyos nombres transferimos a la carpeta especificada.
def copyFileSet(strDirFrom, strDirTo, arrFileNames): arrBreeds = np.asarray(arrFileNames['breed']) arrFileNames = np.asarray(arrFileNames['id']) if not os.path.exists(strDirTo): os.makedirs(strDirTo) for i in tqdm(range(len(arrFileNames))): strFileNameFrom = strDirFrom + arrFileNames[i] + ".jpg" strFileNameTo = strDirTo + arrBreeds[i] + "/" + arrFileNames[i] + ".jpg" if not os.path.exists(strDirTo + arrBreeds[i] + "/"): os.makedirs(strDirTo + arrBreeds[i] + "/")
Como puede ver, solo copiamos un archivo para cada raza de perro como
prueba . Además, al copiar, creamos subcarpetas, una para cada raza. En consecuencia, las fotografías se copian a las subcarpetas por raza.
Esto se hace porque Keras puede trabajar con un directorio de una estructura similar, cargando archivos de imagen según sea necesario, y no todos a la vez, lo que ahorra memoria. Cargar las 15,000 imágenes a la vez es una mala idea.
Tendremos que llamar a esta función solo una vez, ya que copia imágenes, y ya no es necesaria. En consecuencia, para uso futuro, debemos comentarlo:
Obtenga una lista de razas de perros:
breeds = np.unique(labels['breed']) map_characters = {}
Procesamiento de imagen
Vamos a utilizar la función de biblioteca de Keras llamada ImageDataGenerators. ImageDataGenerator puede procesar la imagen, escalar, rotar, etc. También puede aceptar una función de
procesamiento que puede procesar imágenes adicionalmente.
def preprocess(img): img = cv2.resize(img, (IMAGE_SIZE, IMAGE_SIZE), interpolation = cv2.INTER_AREA)
Presta atención al siguiente código:
Podemos normalizar (subdatos dentro del rango 0-1 en lugar del 0-255 original) en ImageDataGenerator. ¿Por qué entonces necesitamos un preprocesador? Como ejemplo, considere la llamada borrosa (comentada, no la uso): esta es la misma manipulación de imagen personalizada que puede ser arbitraria. Cualquier cosa, desde contraste hasta HDR.
Utilizaremos dos ImageDataGenerators diferentes, uno para capacitación y otro para validación. La diferencia es que para el entrenamiento necesitamos giros y escalas para aumentar la "variedad" de datos, pero para la validación, no necesitamos, al menos, no en esta tarea.
train_datagen = ImageDataGenerator( preprocessing_function=preprocess,
Crear una red neuronal
Como ya se mencionó, vamos a crear varios tipos de redes neuronales. Cada vez llamaremos a otra función para crear, incluir otros archivos y, a veces, determinar un tamaño de imagen diferente. Entonces, para cambiar entre diferentes tipos de redes neuronales, debemos comentar / descomentar el código apropiado.
En primer lugar, cree una CNN "vainilla". No funciona bien, porque decidí no perder el tiempo depurándolo, pero al menos proporciona una base que se puede desarrollar si hay un deseo (por lo general, esta es una mala idea, ya que las redes pre-entrenadas dan el mejor resultado).
def createModelVanilla(): model = Sequential()
Cuando creamos redes utilizando
transferencia de aprendizaje , el procedimiento cambia:
def createModelMobileNetV2():
La creación de otros tipos de redes sigue el mismo patrón:
def createModelResNet50(): base_model = ResNet50(weights='imagenet', include_top=False, pooling='avg', input_shape=(IMAGE_SIZE, IMAGE_SIZE, 3)) x = base_model.output x = Dense(512)(x) x = Activation('relu')(x) x = Dropout(0.5)(x) predictions = Dense(NUM_CLASSES, activation='softmax')(x) model = Model(inputs=base_model.input, outputs=predictions)
Advertencia: ganador! Este NN mostró el mejor resultado:
def createModelInceptionV3():
Otro:
def createModelNASNetMobile():
Se pueden usar diferentes tipos de redes neuronales para diferentes tareas. Por lo tanto, además de los requisitos para la precisión de la predicción, el tamaño puede ser importante (el NN móvil es 5 veces más pequeño que Inception) y la velocidad (si necesitamos el procesamiento en tiempo real de una transmisión de video, entonces la precisión tendrá que ser sacrificada).
Entrenamiento de redes neuronales
En primer lugar, estamos
experimentando , por lo que deberíamos poder eliminar las redes neuronales que hemos guardado, pero que ya no usamos. La siguiente función elimina NN si existe:
La forma en que creamos y eliminamos redes neuronales es bastante simple y directa. Primero, elimine. Cuando llame a
borrar (solo), tenga en cuenta que el Jupiter Notebook tiene una función de "ejecutar selección", seleccione solo lo que desea usar y ejecútelo.
Luego creamos una red neuronal si su archivo no existía, o
cargamos la llamada si existe: por supuesto, no podemos llamar a "eliminar" y luego esperamos que NN exista, así que para usar una red neuronal guardada, no llame a
eliminar .
En otras palabras, podemos crear un nuevo NN, o usar el existente, dependiendo de la situación y de lo que estamos experimentando actualmente. Un escenario simple: entrenamos una red neuronal y luego nos fuimos de vacaciones. Regresaron y Google cerró la sesión, por lo que debemos cargar la guardada anteriormente: comentar "eliminar" y descomentar "cargar".
deleteSavedNet(working_path + strModelFileName)
Los puntos de control son un elemento muy importante de nuestro programa. Podemos crear una serie de funciones que deberían llamarse al final de cada era de entrenamiento y pasarlas al punto de control. Por ejemplo, puede guardar una red neuronal
si muestra resultados mejores que los ya guardados.
checkpoint = ModelCheckpoint(working_path + strModelFileName, monitor='val_acc', verbose=1, save_best_only=True, mode='auto', save_weights_only=False) callbacks_list = [ checkpoint ]
Finalmente, enseñamos la red neuronal en el conjunto de entrenamiento:
Los gráficos de precisión y pérdida para la mejor de las configuraciones son los siguientes:
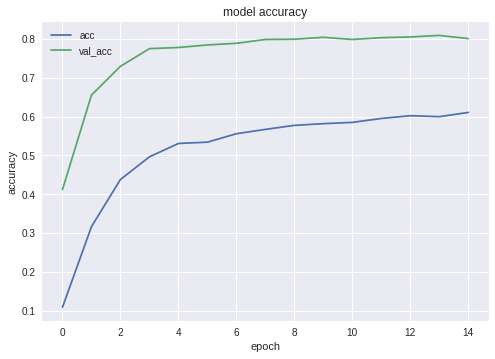

Como puede ver, la red neuronal está aprendiendo, y no está mal.
Prueba de red neuronal
Después de completar el entrenamiento, debemos probar el resultado; para esto, NN presenta imágenes que nunca había visto antes, las que copiamos en la carpeta de prueba, una para cada raza de perro.
Exportar una red neuronal a una aplicación Java
En primer lugar, necesitamos organizar la carga de la red neuronal desde el disco. La razón es clara: la exportación se lleva a cabo en otro bloque de código, por lo que lo más probable es que comencemos la exportación por separado, cuando la red neuronal esté en su estado óptimo. Es decir, inmediatamente antes de la exportación, en la misma ejecución del programa, no entrenaremos la red. Si usa el código que se muestra aquí, entonces no hay diferencia, se ha seleccionado la red óptima para usted. Pero si aprenderá algo propio, entonces entrenar todo de nuevo antes de ahorrar es una pérdida de tiempo, si antes de eso lo guardó todo.
Por la misma razón, para no saltar el código, incluyo los archivos necesarios para exportar aquí. Nadie te molesta en moverlos al comienzo del programa si tu sentido de la belleza lo requiere:
from keras.models import Model from keras.models import load_model from keras.layers import * import os import sys import tensorflow as tf
Una pequeña prueba después de cargar una red neuronal, solo para asegurarse de que todo esté cargado: funciona:
img = image.load_img(working_path + "test/affenpinscher.jpg")

Luego, necesitamos obtener los nombres de las capas de entrada y salida de la red (ya sea esta o la función de creación, debemos “nombrar” explícitamente las capas, lo que no hicimos).
model.summary() >>> Layer (type) >>> ====================== >>> input_7 (InputLayer) >>> ______________________ >>> conv2d_283 (Conv2D) >>> ______________________ >>> ... >>> dense_14 (Dense) >>> ====================== >>> Total params: 22,913,432 >>> Trainable params: 1,110,648 >>> Non-trainable params: 21,802,784
Usaremos los nombres de las capas de entrada y salida más tarde cuando importamos la red neuronal en una aplicación Java.
Otro código de itinerancia en la red para obtener estos datos:
def print_graph_nodes(filename): g = tf.GraphDef() g.ParseFromString(open(filename, 'rb').read()) print() print(filename) print("=======================INPUT===================") print([n for n in g.node if n.name.find('input') != -1]) print("=======================OUTPUT==================") print([n for n in g.node if n.name.find('output') != -1]) print("===================KERAS_LEARNING==============") print([n for n in g.node if n.name.find('keras_learning_phase') != -1]) print("===============================================") print()
Pero no me gusta y no lo recomiendo.El siguiente código exportará la red neuronal Keras a formato pb , el que capturaremos desde Android. def keras_to_tensorflow(keras_model, output_dir, model_name,out_prefix="output_", log_tensorboard=True): if os.path.exists(output_dir) == False: os.mkdir(output_dir) out_nodes = [] for i in range(len(keras_model.outputs)): out_nodes.append(out_prefix + str(i + 1)) tf.identity(keras_model.output[i], out_prefix + str(i + 1)) sess = K.get_session() from tensorflow.python.framework import graph_util from tensorflow.python.framework graph_io init_graph = sess.graph.as_graph_def() main_graph = graph_util.convert_variables_to_constants( sess, init_graph, out_nodes) graph_io.write_graph(main_graph, output_dir, name=model_name, as_text=False) if log_tensorboard: from tensorflow.python.tools import import_pb_to_tensorboard import_pb_to_tensorboard.import_to_tensorboard( os.path.join(output_dir, model_name), output_dir)
Llamando a estas funciones para exportar una red neuronal:
model = load_model(working_path + strModelFileName) keras_to_tensorflow(model, output_dir=working_path + strModelFileName, model_name=working_path + "models/dogs.pb") print_graph_nodes(working_path + "models/dogs.pb")
La última línea imprime la estructura de la red neuronal resultante.Crear una aplicación de Android usando una red neuronal
La exportación de redes neuronales en Android está bien formalizada y no debería causar dificultades. Hay, como siempre, de varias maneras, las más populares (al momento de escribir).En primer lugar, usamos Android Studio para crear un nuevo proyecto. Vamos a "cortar esquinas" porque nuestra tarea no es un tutorial de Android. Entonces la aplicación contendrá solo una actividad. Como puede ver, agregamos la carpeta "activos" y copiamos nuestra red neuronal (la que exportamos anteriormente).
Como puede ver, agregamos la carpeta "activos" y copiamos nuestra red neuronal (la que exportamos anteriormente).Archivo Gradle
En este archivo, debe realizar varios cambios. En primer lugar, necesitamos importar la biblioteca tensorflow-android . Se utiliza para trabajar con Tensorflow (y, en consecuencia, Keras) de Java: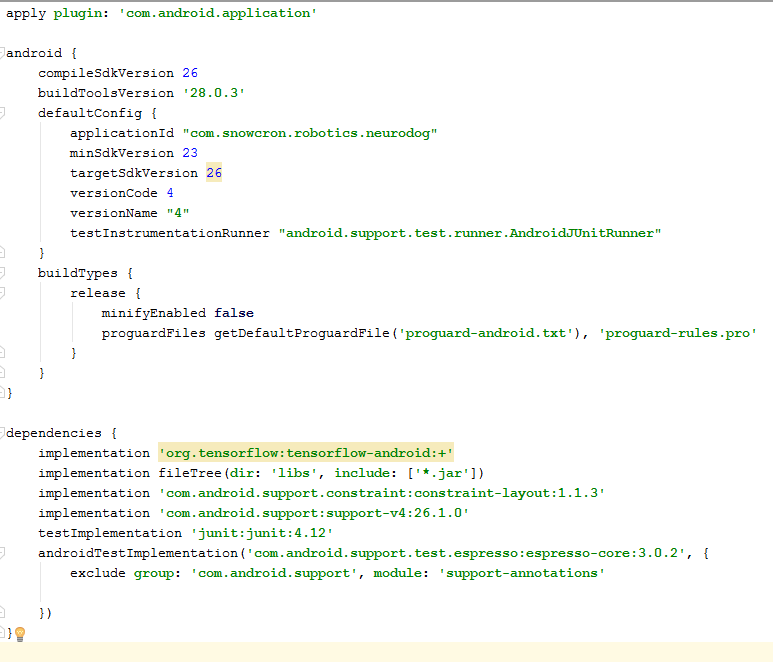 otro obstáculo obvio: versionCode y versionName . Cuando la aplicación cambie, deberá cargar nuevas versiones en Google Play. Sin cambiar las versiones en gdadle (por ejemplo, 1 -> 2 -> 3 ...) no puede hacer esto, Google dará un error "esta versión ya existe".
otro obstáculo obvio: versionCode y versionName . Cuando la aplicación cambie, deberá cargar nuevas versiones en Google Play. Sin cambiar las versiones en gdadle (por ejemplo, 1 -> 2 -> 3 ...) no puede hacer esto, Google dará un error "esta versión ya existe".Manifiesto
En primer lugar, nuestra aplicación será "pesada": la red neuronal de 100 Mb encajará fácilmente en la memoria de los teléfonos celulares modernos, pero abrir una instancia separada para cada foto "compartida" de Facebook es definitivamente una mala idea.Por lo tanto, prohibimos crear más de una instancia de nuestra aplicación: <activity android:name=".MainActivity" android:launchMode="singleTask">
Al agregar android: launchMode = "singleTask" a MainActivity, le decimos a Android que abra (active) una copia existente de la aplicación, en lugar de crear otra instancia.Luego, debemos incluir nuestra aplicación en la lista, que el sistema muestra cuando alguien "comparte" la imagen: <intent-filter> <action android:name="android.intent.action.SEND" /> <category android:name="android.intent.category.DEFAULT" /> <data android:mimeType="image/*" /> </intent-filter>
Finalmente, necesitamos solicitar características y permisos que utilizará nuestra aplicación: <uses-feature android:name="android.hardware.camera" android:required="true" /> <uses-permission android:name= "android.permission.WRITE_EXTERNAL_STORAGE" /> <uses-permission android:name="android.permission.READ_PHONE_STATE" tools:node="remove" />
Si está familiarizado con la programación para Android, esta parte no debería causar preguntas.Aplicación de diseño.
Crearemos dos diseños, uno para retrato y otro para paisaje. Así es como se ve el diseño de retrato .Lo que agregaremos: un campo grande (vista) para mostrar la imagen, una lista molesta de anuncios (que se muestra cuando se presiona el botón con un hueso), el botón Ayuda, botones para descargar una imagen de Archivo / Galería y capturar desde la cámara, y finalmente (inicialmente oculto) Botón "Proceso" para el procesamiento de imágenes.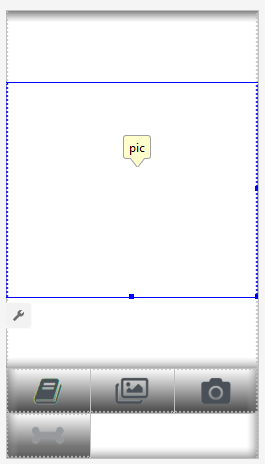 La actividad en sí contiene toda la lógica de mostrar y ocultar, así como habilitar / deshabilitar botones, según el estado de la aplicación.
La actividad en sí contiene toda la lógica de mostrar y ocultar, así como habilitar / deshabilitar botones, según el estado de la aplicación.Mainactividad
Esta actividad hereda (extiende) la Actividad estándar de Android: public class MainActivity extends Activity
Considere el código responsable del funcionamiento de la red neuronal.En primer lugar, la red neuronal acepta Bitmap. Inicialmente, este es un mapa de bits grande (de tamaño arbitrario) de la cámara o de un archivo (m_bitmap), luego lo transformamos, lo que lleva a los 256x256 píxeles estándar (m_bitmapForNn). También almacenamos el tamaño del mapa de bits (256) en una constante: static Bitmap m_bitmap = null; static Bitmap m_bitmapForNn = null; private int m_nImageSize = 256;
Debemos decirle a la red neuronal los nombres de las capas de entrada y salida; los recibimos antes (ver listado), pero tenga en cuenta que en su caso pueden diferir: private String INPUT_NAME = "input_7_1"; private String OUTPUT_NAME = "output_1";
Luego declaramos una variable para contener el objeto TensofFlow. Además, almacenamos la ruta al archivo de red neuronal (que se encuentra en los activos):private TensorFlowInferenceInterface tf;
Cadena privada MODEL_PATH =
"archivo: ///android_asset/dogs.pb";
Almacenamos las razas de perros en la lista, para que luego se muestren al usuario, y no los índices de la matriz: private String[] m_arrBreedsArray;
Inicialmente, descargamos Bitmap. Sin embargo, la red neuronal espera una serie de valores RGB, y su salida es una serie de probabilidades de que esta raza sea lo que se muestra en la imagen. En consecuencia, debemos agregar dos matrices más (tenga en cuenta que 120 es el número de razas de perros presentes en nuestros datos de entrenamiento): private float[] m_arrPrediction = new float[120]; private float[] m_arrInput = null;
Descargar la biblioteca de inferencia de tensorflow: static { System.loadLibrary("tensorflow_inference"); }
Dado que las operaciones de la red neuronal toman tiempo, necesitamos ejecutarlas en un hilo separado, de lo contrario existe la posibilidad de que recibamos un mensaje del sistema "la aplicación no responde", sin mencionar a un usuario insatisfecho. class PredictionTask extends AsyncTask<Void, Void, Void> { @Override protected void onPreExecute() { super.onPreExecute(); }
En onCreate () de MainActivity, necesitamos agregar onClickListener para el botón "Proceso": m_btn_process.setOnClickListener(new View.OnClickListener() { @Override public void onClick(View v) { processImage(); } });
Aquí processImage () solo llama al hilo que describimos anteriormente: private void processImage() { try { enableControls(false);
Notas adicionales
No planeamos discutir los detalles de la programación de IU para Android, ya que esto ciertamente no se aplica a la tarea de portar redes neuronales. Sin embargo, una cosa aún vale la pena mencionar.Cuando impedimos la creación de instancias adicionales de nuestra aplicación, también rompimos el orden normal de creación y eliminación de actividad (flujo de control): si "comparte" una imagen de Facebook y luego comparte otra, la aplicación no se reiniciará. Esto significa que la forma "tradicional" de capturar los datos transferidos en onCreate no será suficiente, ya que no se llamará a onCreate.Aquí se explica cómo resolver este problema:1. En onCreate en MainActivity, llame a la función onSharedIntent: protected void onCreate( Bundle savedInstanceState) { super.onCreate(savedInstanceState); .... onSharedIntent(); ....
También agregamos un controlador para onNewIntent: @Override protected void onNewIntent(Intent intent) { super.onNewIntent(intent); setIntent(intent); onSharedIntent(); }
Aquí está la función onSharedIntent en sí: private void onSharedIntent() { Intent receivedIntent = getIntent(); String receivedAction = receivedIntent.getAction(); String receivedType = receivedIntent.getType(); if (receivedAction.equals(Intent.ACTION_SEND)) {
Ahora procesamos los datos transferidos en onCreate (si la aplicación no estaba en la memoria) o en onNewIntent (si se lanzó antes).Buena suerte
Si le gustó el artículo, por favor, haga clic en "Me gusta" en todas las formas posibles, también hay botones "sociales" en el sitio .